[完结]saliency filters精读之permutohedral lattice
勘误使于2017年3月19日
本文写于2012年硕士生阶段,有较多疏漏和误解,于今日起开始勘误,以最大限度的保留原始文章,同时更正其中错误。
一、背景碎碎念

 ,
,

本文思想
二、现有成果

三、Permutohedral Lattice
本文贡献
- 它不仅仅把一个点映射到格子中心表示,而是映射到单形格子的各个顶点上,这样子近似卷积的更加精确;
- 由于每个lattice具有同等形态,能够用质心差值插值映射到lattice的各个顶点上;
- 并且能够快速在此lattice上找到映射点四周的顶点,这样子两次映射(splat,slice)能够快速进行;
- blur阶段可以每一维离散进行,并且一个lattice顶点的周边顶点能够迅速确定,此阶段能够快速进行。
定义



网格性质
- 这个子平面被相同形状的单形填充,不留缝隙,没有重叠
- 子平面中任意一点所在的单形顶点都能以
的时间内定义
- 单形顶点周围所有的顶点也能以
生成特征值映射到子平面的点
首先将每个坐标点除了一个误差,是由splat,blur以及slice中产生的。然后映射到子平面上,注意此时的映射矩阵与上面的不同,因为上面的基向量不是正交的,并且此映射可以用举例bilateral filter,position由5-D向量组成,




查找单形顶点的所有相邻点对,即
Slice阶段:
同splat阶段步骤,利用权重b计算插值。由于在splat阶段建立了b的table,所以用时O(nd)。
本算法总计用时为O((n+l)d^2)。

可以看到5-20维度时候permutohedral lattice根据filter size情况最优。
完结。
https://www.codetd.com/article/2771587
直接看第三章,bilateral convolution layers。这个词来自于文献[22]和[25]:
[22]Learning Sparse High Dimensional Filters:Image Filtering, Dense CRFs and Bilateral Neural Networks . CVPR2016
[25]Permutohedral Lattice CNNs. ICLR 2015
但是笔者去看了这两篇文章,感觉这里其实叫Permutohedral Lattice CNNs更贴切。文献[22]写得乱七八糟得,提出了Bilateral Neural Networks这么个词,其实根本就只是把文献[25]里的Permutohedral Lattice CNNs换了换名字、换了个场合。
接着看文章,为了讲解方便,我们就继续用文中BCL这个名词。
第三章比较重要,首先讲了BCL的输入。这里先区分两个词,input features 和lattice features ,前者是实打实的输入特征,其维度为df,既可以是低阶特征,也可以是神经网络提取的高阶特征,维度从几到几百均可;而后者是用来构造Permutohedral Lattice的特征,只用低阶特征,如位置、颜色、法线,维度一般为个位数。例如第四章文中给的SPLATNet3D 的实现结构,lattice features是位置,维度就只有3。
接着,就是文章的核心了,介绍了BCL的三个基本操作:Splat、Convolve、Slice,这里文章介绍的不细致,而且容易误导人,建议有时间的同学去看看文献[25]以及文献[1]“Fast High-Dimensional Filtering Using the Permutohedral Lattice”会有个更深入的理解。
Splat。
这个操作就是把欧式空间变换成另外一个空间,怎么变换?通过乘一个变换矩阵。变换矩阵一般是这样
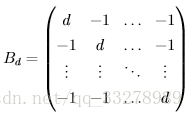
具体为什么定义成这样就是数学问题了,在此就不赘述了。这里d表示Permutohedral Lattice空间的维度。
为了便于理解,给一个例子:欧式空间定义三个点,分别是(0,0,0)、(1,0,0)、(1,1,0)。令Permutohedral Lattice维度取d=2,则
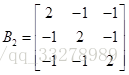
用B2乘坐标,得到经过变换后新的三点坐标(0,0,0)、(2,-1,-1)、(1,1,-2)。这一过程如下图所示:
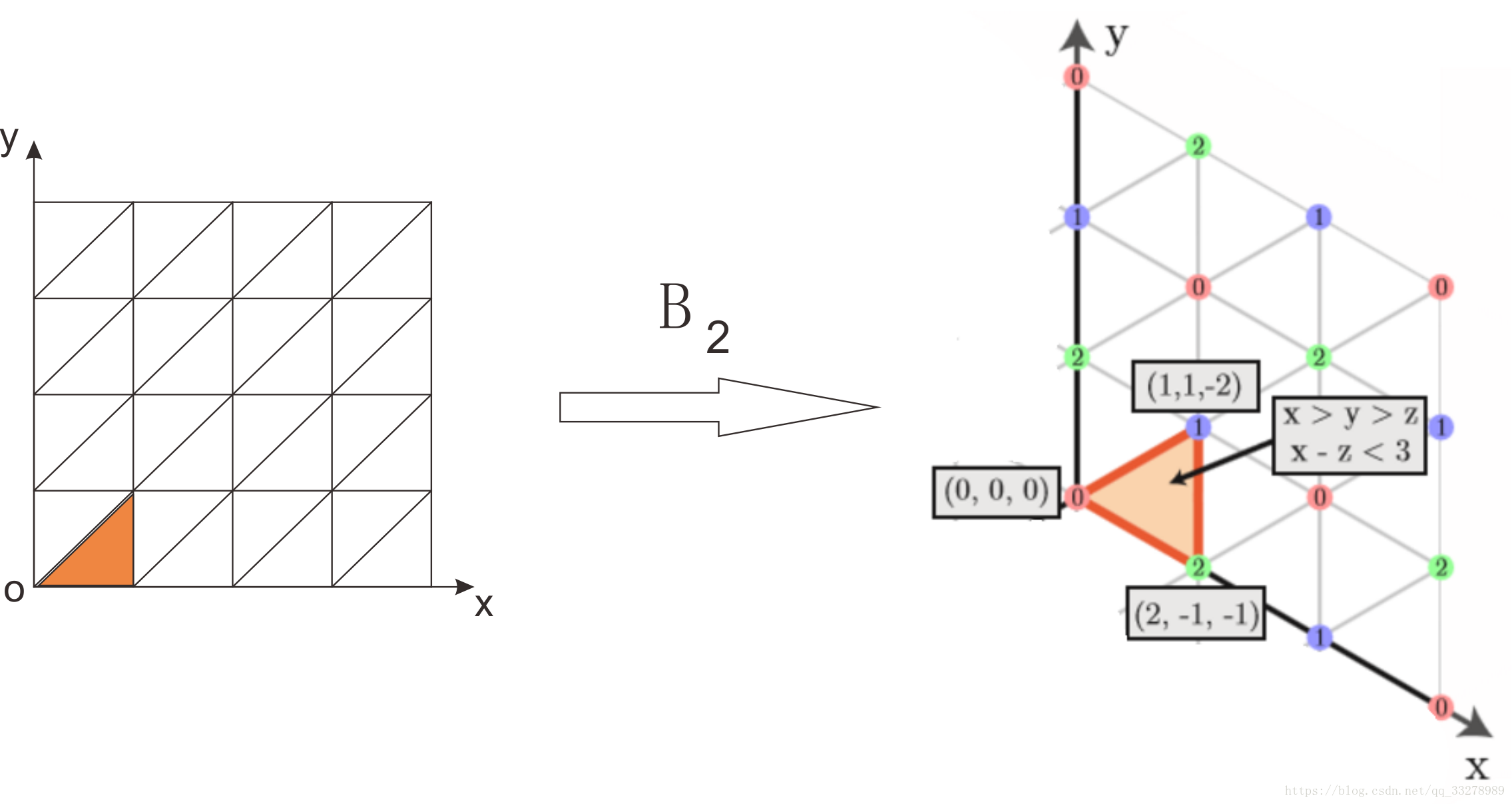
右图中,带颜色的数字0,1,2都是余数(即文献[1]中的remainder)。这个余数是怎么算的呢?举例说明,如(2,-1,-1)这个点,2和-1两个数对3进行取模运算,得到的余数都是2,所以这点就标成2;再比如(1,1,-2)对3取模,余数都是1,所以这点就标成1。在整个Permutohedral Lattice空间都遵循这种规则进行标注,后面做卷积运算时会根据这些余数进行相应操作。
如上图所示的那样,Permutohedral Lattice空间就是有多个单形不留缝隙地拼接而成,它不像欧式空间那样坐标轴互相垂直,而是成一定角度,分布在平面上。它具有以下特点:
- 平面中任意一点所在的单形顶点都能以
- 单形顶点周围所有的顶点也能以
- ...还有一些更专业,就不再列了。
关于这两点我的理解仅限于,这种空间对于稀疏无序的数据,能够更加高效地进行组织,便于查找和各种运算的进行。
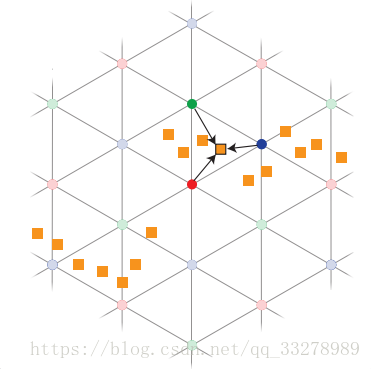
把欧式空间里的点变换到Permutohedral Lattice空间后,还要进行一步“炸裂”操作(这个名字是我杜撰的),如下图:
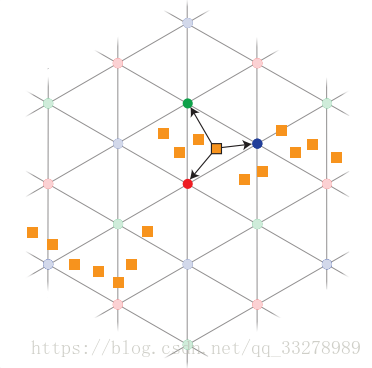
也就是把单形里的某个点的信息炸开到周围三个顶点上,当然了,这个点带的信息也就是它的特征,不管64维也好128维也好,都要炸开到周围三个顶点。这个所谓的“炸开”也是有一定依据的,会根据距离分配不同的权值,但是基本上炸开之后的特征维度是不变的。
至此,Splat操作完成。所以,现在大家应该能够体会到Splat的作用了,就是把原本在欧式空间中又稀疏、又不均匀的点按照一种新的形式组织了一下,方便进行后续运算。下面就是Convolve。
Convolve说起来就简单了,Splat操作之后,点的特征已经按照一定原则“分配”到各个单形的顶点上了,所以,位置也就很比较规整了,按照哈希表做索引,进行卷积操作就行了。
Slice。这是Splat的逆过程,把卷积运算后得到的Lattice顶点上的信息,“汇聚”到原来点的位置上。当然,如果“汇聚”到新的位置上也可以,新的点数也可以比原来的点数少,也可以分布在不同维度的欧式空间上。这就和卷积操作变换图片尺寸的效果有点类似。
至此,就把Permutohedral Lattice CNN模块讲完了,这就是BCL的核心内容了。
第四章就简单了,无非就是介绍网络的超参是如何设定的、网络结构如何设计的,都是比较容易理解了。
第五章介绍了2D-3D融合的实现版本,无非就是多加了几个concate的操作,网络更加复杂一些,根据语义分割的任务特点加了多层次信息融合等等,也都不难理解。
第六章是实验,证明了本文所提网络的有效性。
第七章总结。
附录部分——附录部分可以看看网络的设计参数,例如BCL的输出特征维度64-128-128-64-64-7等等,可以加深对网络的认识。我最开始搞不清楚Splat投影是做什么的,受到文中一句话的误导:

以为要把高维(如64,128)的特征映射到低维(如3,6),非常别扭。
直到看到附录部分关于BCL输出特征维度的介绍,维度还是很高的,就才恍然大悟,才知道Splat中的“炸开”是带着厚厚的特征一块“炸开”的。
直接看第三章,bilateral convolution layers。这个词来自于文献[22]和[25]:
[22]Learning Sparse High Dimensional Filters:Image Filtering, Dense CRFs and Bilateral Neural Networks . CVPR2016
[25]Permutohedral Lattice CNNs. ICLR 2015
但是笔者去看了这两篇文章,感觉这里其实叫Permutohedral Lattice CNNs更贴切。文献[22]写得乱七八糟得,提出了Bilateral Neural Networks这么个词,其实根本就只是把文献[25]里的Permutohedral Lattice CNNs换了换名字、换了个场合。
接着看文章,为了讲解方便,我们就继续用文中BCL这个名词。
第三章比较重要,首先讲了BCL的输入。这里先区分两个词,input features 和lattice features ,前者是实打实的输入特征,其维度为df,既可以是低阶特征,也可以是神经网络提取的高阶特征,维度从几到几百均可;而后者是用来构造Permutohedral Lattice的特征,只用低阶特征,如位置、颜色、法线,维度一般为个位数。例如第四章文中给的SPLATNet3D 的实现结构,lattice features是位置,维度就只有3。
接着,就是文章的核心了,介绍了BCL的三个基本操作:Splat、Convolve、Slice,这里文章介绍的不细致,而且容易误导人,建议有时间的同学去看看文献[25]以及文献[1]“Fast High-Dimensional Filtering Using the Permutohedral Lattice”会有个更深入的理解。
Splat。
这个操作就是把欧式空间变换成另外一个空间,怎么变换?通过乘一个变换矩阵。变换矩阵一般是这样
具体为什么定义成这样就是数学问题了,在此就不赘述了。这里d表示Permutohedral Lattice空间的维度。
为了便于理解,给一个例子:欧式空间定义三个点,分别是(0,0,0)、(1,0,0)、(1,1,0)。令Permutohedral Lattice维度取d=2,则
用B2乘坐标,得到经过变换后新的三点坐标(0,0,0)、(2,-1,-1)、(1,1,-2)。这一过程如下图所示:
右图中,带颜色的数字0,1,2都是余数(即文献[1]中的remainder)。这个余数是怎么算的呢?举例说明,如(2,-1,-1)这个点,2和-1两个数对3进行取模运算,得到的余数都是2,所以这点就标成2;再比如(1,1,-2)对3取模,余数都是1,所以这点就标成1。在整个Permutohedral Lattice空间都遵循这种规则进行标注,后面做卷积运算时会根据这些余数进行相应操作。
如上图所示的那样,Permutohedral Lattice空间就是有多个单形不留缝隙地拼接而成,它不像欧式空间那样坐标轴互相垂直,而是成一定角度,分布在平面上。它具有以下特点:
- 平面中任意一点所在的单形顶点都能以
- 单形顶点周围所有的顶点也能以
- ...还有一些更专业,就不再列了。
关于这两点我的理解仅限于,这种空间对于稀疏无序的数据,能够更加高效地进行组织,便于查找和各种运算的进行。
把欧式空间里的点变换到Permutohedral Lattice空间后,还要进行一步“炸裂”操作(这个名字是我杜撰的),如下图:
也就是把单形里的某个点的信息炸开到周围三个顶点上,当然了,这个点带的信息也就是它的特征,不管64维也好128维也好,都要炸开到周围三个顶点。这个所谓的“炸开”也是有一定依据的,会根据距离分配不同的权值,但是基本上炸开之后的特征维度是不变的。
至此,Splat操作完成。所以,现在大家应该能够体会到Splat的作用了,就是把原本在欧式空间中又稀疏、又不均匀的点按照一种新的形式组织了一下,方便进行后续运算。下面就是Convolve。
Convolve说起来就简单了,Splat操作之后,点的特征已经按照一定原则“分配”到各个单形的顶点上了,所以,位置也就很比较规整了,按照哈希表做索引,进行卷积操作就行了。
Slice。这是Splat的逆过程,把卷积运算后得到的Lattice顶点上的信息,“汇聚”到原来点的位置上。当然,如果“汇聚”到新的位置上也可以,新的点数也可以比原来的点数少,也可以分布在不同维度的欧式空间上。这就和卷积操作变换图片尺寸的效果有点类似。
至此,就把Permutohedral Lattice CNN模块讲完了,这就是BCL的核心内容了。
第四章就简单了,无非就是介绍网络的超参是如何设定的、网络结构如何设计的,都是比较容易理解了。
第五章介绍了2D-3D融合的实现版本,无非就是多加了几个concate的操作,网络更加复杂一些,根据语义分割的任务特点加了多层次信息融合等等,也都不难理解。
第六章是实验,证明了本文所提网络的有效性。
第七章总结。
附录部分——附录部分可以看看网络的设计参数,例如BCL的输出特征维度64-128-128-64-64-7等等,可以加深对网络的认识。我最开始搞不清楚Splat投影是做什么的,受到文中一句话的误导:
以为要把高维(如64,128)的特征映射到低维(如3,6),非常别扭。
直到看到附录部分关于BCL输出特征维度的介绍,维度还是很高的,就才恍然大悟,才知道Splat中的“炸开”是带着厚厚的特征一块“炸开”的。