本篇给大家分享baiziyu 写的HanLP 中的N-最短路径分词。以为下分享的原文,部分地方有稍作修改,内容仅供大家学习交流!
首先说明在HanLP对外提供的接口中没有使用N-最短路径分词器的,作者在官网中写到这个分词器对于实体识别来说会比最短路径分词稍好,但是它的速度会很慢。对此我有点个人看法,N-最短路径分词相较于最短路径分词来说只是考虑了每个节点下的N种最佳路径,在最后选出的至少N条路径中,作者并没有对他们进行筛选,而只是选择了一条最优的路径,只能说N-最短路径分词相较于最短路径分词对分词歧义会有一定作用,而对于未登录词它的效果应该和最短路径分词相差不多,这只是个人的猜测,并没有拿真实的语料验证。如果后边还有时间的话,我会把几种分词器在新闻语料上做一次对比评测。但是这种评测的意义可能不大,因为毕竟领域不同分词器的效果也会不同,同文本分类一样,至今依然没有一种普适的分词器。
前边已经提到,在最短路径分词中,若每个结点处记录N种最短路径值,则该方法称为N-最短路径算法。在HanLP中通过两个类ViterbiSegment和NshortSegment分别实现了最短路径分词和N-最短路径分词。这里要说明一下为什么说是N种而不是N个,原因是算法会在每个字节点处对所有到达该节点的路径计算路径值,然后按照路径值做排序,所谓的“种”指的是路径值的种类数,因此当存在相等路径值的路径时,节点处保留的路径就不只有N个了。
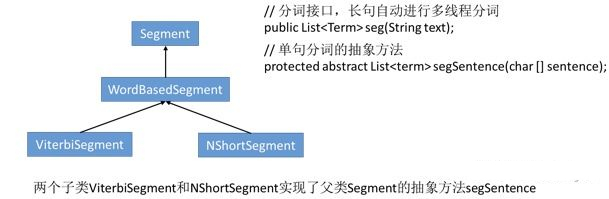
从上图的继承关系我们可以看到最短路径分词器和N最短路径分词器都继承了WordBasedSegment抽象类,也就是说他们从大类上讲都属于基于词语的分词器。后边我们还会介绍基于词典的分词器(极速词典分词器)以及基于字的分词器(感知机、条件随机场分词器)。这里再说明一下抽象类Segment它对外提供了分词方法Seg,所有HanLP中实现的分词方法类都继承了该抽象类,并且实现了抽象方法segSentence。Seg方法对输入的文本进行处理,当文本长度很长时,它会自动将其拆分为多个短文本,然后利用多线程技术,同步对多个短文本进行分词处理,最后得到分词后的文本,对于短文本Seg方法则直接用单线程处理。segSentence则会根据各种不同的分词方法对文本进行分词。这里Seg方法会调用segSentence方法,这就是两个方法的关系。拿我们现在的N-最短路径分词来说,segSentence实现的就是N-最短路径分词。如果是最短路径分词,则segSentence实现的是最短路径分词。写这些只是为了使刚接触面向对象编程方法的小伙伴能清楚。
下边我们还是以例句“他说的确实在理”为例来说明N-最短路径分词。程序对外表现就是计算出下边的表
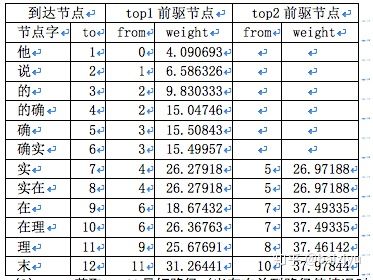
这里我们使N-最短路径分词中的N取2,可以看到算法从“实”字开始就开始有多种最优路径了,截取了前top2种,最后得到了下边的两种分词结果

至此,我们N-最短路径分词介绍结束,我们再来总结一下HanLP中两种方法的异同。
(1) 第1个区别是节点上保留的最优路径前驱节点数。具体来说,当某个节点存在两个以上前驱时,N-最短路径一定会保留topN种路径值的所有前驱节点,而最短路径只会保留一个最短路径值的前驱节点。
(2) HanLP在实现上对N-最短路径方法增加了数字、日期合并规则。
(3) HanLP的N-最短路径方法最终返回的还是一个最优路径,并未对topN个分词结果做筛选策略,虽然在有多个前驱的节点处保留了多个候选前驱,但是个人感觉两者相差应该不多,可能对分词歧义有效果,但是对未登录词应该作用不大。说白了它也还是基于词典中单个词语的概率做的,其他的文本信息都没有用到。
这里,还要再说明一下,我们看到了分词结果中含有了词性标注,关于词性标注我们会在后边继续介绍,它与分词方法是两个策略。程序也是先做了分词再根据用户配置做的词性标注。