一、算法总体框架
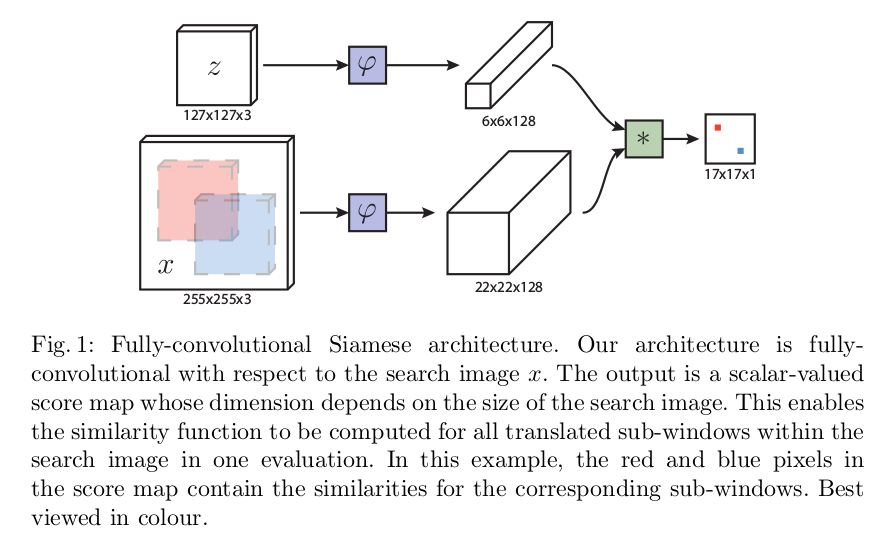
图1 算法总体框架
图中z代表的是模板图像,算法中使用的是第一帧的groundtruth;x代表的是search region,代表在后面的待跟踪帧中的候选框搜索区域;ϕϕ代表的是一种特征映射操作,将原始图像映射到特定的特征空间,文中采用的是CNN中的卷积层和pooling层;6*6*128代表z经过ϕϕ后得到的特征,是一个128通道6*6大小feature,同理,22*22*128是x经过ϕϕ后的特征;后面的*代表卷积操作,让22*22*128的feature被6*6*128的卷积核卷积,得到一个17*17的score map,代表着search region中各个位置与模板相似度值。
从图一和文章题目我们可以很容易理解算法的框架,算法本身是比较搜索区域与目标模板的相似度,最后得到搜索去区域的score map。其实从原理上来说,这种方法和相关性滤波的方法很相似。其在搜索区域中逐点的目标模板进行匹配,将这种逐点平移匹配计算相似度的方法看成是一种卷积,然后在卷积结果中找到相似度值最大的点,作为新的目标的中心。
上图所画的ϕϕ其实是CNN中的一部分,并且两个ϕϕ的网络结构是一样的,这是一种典型的孪生神经网络,并且在整个模型中只有conv层和pooling层,因此这也是一种典型的全卷积(fully-convolutional)神经网络。
二、具体实现
1、损失函数
在训练模型的时肯定需要损失函数,并通过最小化损失函数来获取最优模型。本文算法为了构造有效的损失函数,对搜索区域的位置点进行了正负样本的区分,即目标一定范围内的点作为正样本,这个范围外的点作为负样本,例如图1中最右侧生成的score map中,红色点即正样本,蓝色点为负样本,他们都对应于search region中的红色矩形区域和蓝色矩形区域。文章采用的是logistic loss,具体的损失函数形式如下:
对于score map中了每个点的损失:
其中vv是score map中每个点真实值,y∈{+1,−1}y∈{+1,−1}是这个点所对应的标签。
上面的是score map中每个点的loss值,而对于score map整体的loss,则采用的是全部点的loss的均值。即:
这里的u∈Du∈D代表score map中的位置。
有了损失函数,那就可以用SGD对模型进行训练啦~~