从根开始按层次(第0层->第1层->第2层)遍历一颗二叉树,需要使用什么辅助数据结构?() queue
每一层遍历完后到下一层,这属于广度优先遍历,广度优先则需要队列。深度优先则需要栈。
设散列表的长度为10,散列函数H(n)=n mod 7,初始关键字序列为 (33,24,8,17,21,10),用链地址法作为解决冲突的方法,平均查找长度是 1.5
33%7=5(1次)、24%7=3(1次)、8%7=1(1次)、17%7=3(2次)、21%7=0(1次)、10%7=3(3次);
因此,比较次数为1+1+1+2+1+3=9次,一共六个数,9/6=1.5
在有n个结点的二叉链表中,值为非空的链域的个数为( )。
以二叉链表作为树的存储结构。链表中结点的两个链域分别指向该结点的第一个孩子结点和下一个兄弟结点。
在有N个结点的二叉链表中必定有2N个链域。
除根结点外,其余N-1个结点都有一个父结点。
所以,一共有N-1个非空链域,其余2N-(N-1)=N+1个为空链域。
we can recover the binary tree if given the output of? 二叉树还原需要什么遍历?
必须要有中序,没有中序,仅靠先序、后序是还原不了的
下列说法错误的是()
已知一颗二叉树的前序遍历顺序和后序遍历顺序,可以唯一确定这棵二叉树 需要中序
将一个递归算法改为非递归算法时,通常使用队列作为辅助结构 栈
二分查找法,平均时间复杂度为O(n) 平均时间复杂度为O(log2 N)
一个具有20个叶子节点的二叉树、它有多少个度为2的节点? 19
二叉树的度,指的是结点的孩子数,如果一个结点有两个孩子,那么他的度就是2.
其中。度为2的节点数=度为0的节点数-1;因此 20-1=19
已知一个二叉树中叶子数为50,仅有一个孩子的节点数为30,则总节点数为 129
叶子数为50,即n0=50,n2=49,n1=30 ,因此为129
循环队列的存储空间为 Q(1:100) ,初始状态为 front=rear=100 。经过一系列正常的入队与退队操作后, front=rear=99 ,则循环队列中的元素个数为( ) 0或100
循环队列做了不止一次了,这次要好好记住!
知识点:
队列: 队头指针:指向队首元素 队尾指针:指向队尾元素
循环队列: 队头指针:指向队首元素的前一个位置 队尾指针:指向队尾元素
循环栈: 队头指针:指向队首元素 队尾指针:指向队尾元素的后一个位置
队头指针在队尾指针的下一位置时,队满。 Q.front == (Q.rear + 1) % MAXSIZE 因为队头指针可能又重新从0位置开始,而此时队尾指针是MAXSIZE - 1,所以需要求余。
当队头和队尾指针在同一位置时,队空。 Q.front == Q.rear;
堆排序平均执行的时间复杂度和需要附加的存储空间复杂度分别是()
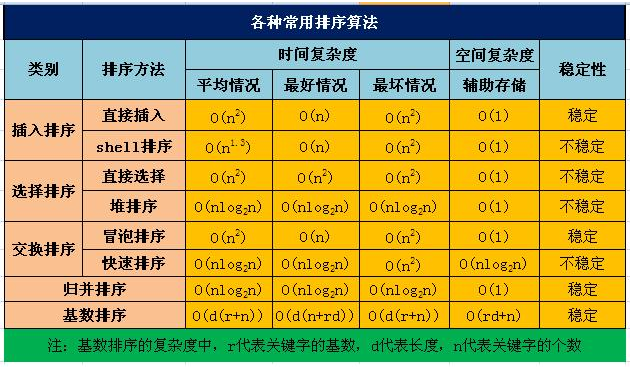
不稳定的排序:快shell选堆
假设线性表的长度为n,则在最坏情况下,冒泡排序需要的比较次数为多少次? n(n-1)/2
第一次将最大元素放最后,比较次数为n-1,第二次比较为n-2...以此类推,即n-1+n-2+n-3...+1,因此为n(n-1)/2;
求下面带权图的最小(代价)生成树时,可能是克鲁斯卡(Kruskal)算法第 2 次选中但不是普里姆(Prim)算法(从 V4 开始)第 2 次选中的边是 () 。
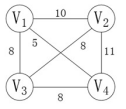
Kruskal算法是按权值选边,若选边后不形成回路,则保留作为一条边,若形成回路则除去
Prim算法是每次从当前的二叉树节点向外延伸的,选择权值最小的边
克鲁斯卡(Kruskal)算法和普里姆(Prim)算法(从 V4 开始)第1次选中的边都是(v4,v1) 。
Kruskal算法第二次可以选择(v1,v3), (v2,v3), (v3,v4);
Prim算法第二次可以选择(v1,v3), (v3,v4)
递归函数中的形参是() 自动变量
递归是借助栈来实现的,自动变量是存储在栈里面的,随着递归的进行,自动创建和销毁。
外部变量和静态变量存放在静态存储区。外部变量和静态变量是不能作为递归函数的参数的。
设完全二叉树的第5层上有10个叶子结点,则二叉树最少有()个结点 25
最少有多少个节点,所以这里是总共5层,这是一个完全二叉树结点数最少的情况,所以前4层是一个满二叉树2^4-1=15个结点,前四层结点加上第五层的叶子结点共15+10=25个结点。
而最多的情况下,是第5层为倒数第二层,即1~5层构成一个满二叉树,第5层有(25)-1=31个结点,因为第5层有10个叶子结点,而2(5-1)=16,第5层最多结点的时候是16个,现在有10个叶子结点,也就是还有6个非叶子结点,这个非叶子结点在第6层有12个叶子结点,所以最多的时候就是31+12=43
以下哪个不属于路由算法
路由算法的典型算法:
LS算法
Dijkstra算法
链路向量选路算法
距离向量算法
泛洪算法 - 在实现路由算法的时候,每个路由器必须根据本地知识而不是网络的全貌做决策。
假设你只有100MB的内存,需要对1GB的数据进行排序,最合适的算法是? 归并排序
只有归并排序不需要一次性输入全部数据。
区分一个算法时,主要看它具有()等特点
算法的特性:输入输出、有穷性、确定性、可执行性
设计需要:正确性、底耦合高效率低存储、可读性、健壮性
一棵有n个结点的二叉树,从上到下,从左到右从1依次给予编号,则编号为i的结点的左儿子的编号为2i(2i<n),右儿子是2i+1(2i+1<n)()
错,完全二叉树则成立,如果不是完全二叉树,则不一定。
一个空栈,如果有顺序输入:a1,a2,a3。。。an(个数大于3),而且输出第一个为an-1,那么所有都出栈后,()
不能确定元素a1~an-2在输出顺序 ×
an-2一定比an-3先出 对
第一个出栈的是an-1,那么可以说明,a1-an-1都已经按顺序输入了,此时an还没有输入进去,所以an可以在之后的任意输出后在输入,因为a1-an-2已经有序,可以证明,an-2一定会比an-3先出,就如a3一定会比a2先出一般。
和顺序栈相比,链栈有一个比较明显的优势是 。
通常不会出现栈满的情况 √
链表的节点一般都是动态分配内存,如果在没有其他限制情况下,只有动态申请内存失败的时候才算是栈满!
给出以下定义:
Char x[]=”abcdefg”;
Char y[]={‘a’,’b’,’c’,’d’,’e’,’f’,’g’};
数组X的sizeof运算值大于数组Y的sizeof运算值 √
x如此定义会在后面添加�,所以x比y多一个结束符号。
下面关于二分查找的叙述争正确的是: ( )
表必须有序,且表只能以顺序方式存储
已知一棵完全二叉树中共有626个结点,叶结点的个数应为() ** 313**
结点数为偶数个,n2=n0-1,那么n0+n0-1+n1=偶数个,那么n1则为1,即2n0=626,因此叶结点数为313
在待排序的元素序列基本有序的前提下,效率最高的排序方法是______ 。 插入排序
归并排序只是减少了交换次数,时间复杂度固定为 O(n log2 n);
某段文本中各个字母出现的频率分别是{a:4,b:3,o:12,h:7,i:10},使用哈弗曼编码,则哪种是可能的编码?
a(001)b(000)h(01)i(10)o(11)
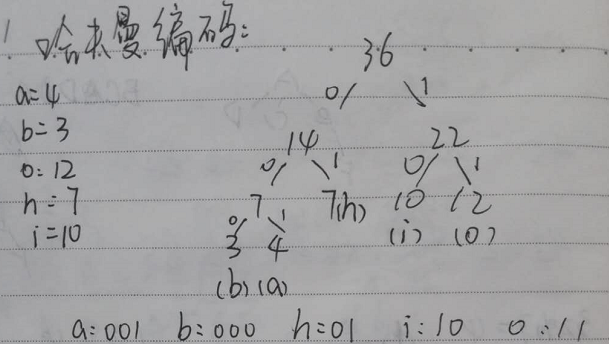
若使用枚举法求解TSP算法,则时间复杂度是() (n-1)!
TSP算法, 就是旅行商问题,假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路径的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。