任务目标: 爬取猎云网(https://www.lieyunwang.com)的新闻数据,包括标题、发布时间、作者、新闻内容、原始url等,以异步的方式存入MySQL数据库。
分析猎云网主页的新闻列表页url及新闻详情页url发现:
- 新闻列表页的url格式为 https://www.lieyunwang.com/latest/p2.html p2表示第二页,更改数字,即可获取其他页面的url
- 新闻详情页的url格式为 https://www.lieyunwang.com/archives/471624 471624表示新闻id,前面部分的url都是一样的
对于这种url高度类似的页面数据抓取,可以使用scrapy框架的CrawlSpider,CrawlSpider可以定义抓取规则,实现某一格式的url抓取
实现步骤:
第一步:创建scrapy项目,新建继承自CrawlSpider的爬虫类文件lieyunSpider.py
在需要创建项目的目录下,shift + 鼠标右键,点击在此处打开命令窗口,键入 scrapy startproject lieyun 创建一个scrapy项目
进入lieyun目录下: cd lieyun
键入 scrapy genspider -t crawl lieyunSpider www.leiyunwang.com 新建一个爬虫文件lieyunSpider.py,默认爬虫类继承自CrawlSpider
(如果没有加 -t crawl,创建的爬虫文件内的类默认继承自scrapy.Spider,此时也可以手动导入CrawlSpider及相关包【from scrapy.linkextractors import LinkExtractor 以及 from scrapy.spiders import CrawlSpider, Rule】,实现一样的功能和操作)
第二步:定义抓取字段,实现items.py文件
import scrapy
class LieyunItem(scrapy.Item):
title = scrapy.Field()
pub_time = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
origin_url = scrapy.Field()
第三步:分析网页结构,定义CrawlSpider抓取规则
# -*- coding: utf-8 -*-
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import LieyunItem
import re
class LieyunspiderSpider(CrawlSpider):
name = 'lieyunSpider'
allowed_domains = ['lieyunwang.com']
start_urls = ['https://www.lieyunwang.com/latest/p1.html']
rules = (
Rule(LinkExtractor(allow=r'/latest/pd+.html'), follow=True),
Rule(LinkExtractor(allow=r'/archives/d+'), callback='parse_item', follow=False)
)
def parse_item(self, response):
pass
rules = (Rule(LinkExtractor(allow='', follow=*** ......))) 该段语句为固定写法,表示定义抓取规则
一个 Rule(LinkExtractor()) 表示定义一个规则,allow 表示抓取的url所匹配的正则表达式, follow表示是否跟随抓取,即有相同规则的url时是否继续抓取,callback表示回调函数,用来处理符合该抓取规则的url
以上代码分别定义了新闻列表页和详情页的url规则以及相应处理方式(这些url规则需在start_urls的响应内容中存在,因为就是从start_urls的网页源代码中开始匹配的)
第四步:分析新闻详情页网页结构,完善爬虫文件lieyunSpider.py
# -*- coding: utf-8 -*-
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import LieyunItem
class LieyunspiderSpider(CrawlSpider):
name = 'lieyunSpider'
allowed_domains = ['lieyunwang.com']
start_urls = ['https://www.lieyunwang.com/latest/p1.html']
rules = (
Rule(LinkExtractor(allow=r'/latest/pd+.html'), follow=True),
Rule(LinkExtractor(allow=r'/archives/d+'), callback='parse_item', follow=False)
)
def parse_item(self, response):
item = LieyunItem()
item['title'] = "".join(response.xpath('//h1[@class="lyw-article-title-inner"]/text()').getall()).strip()
item['pub_time'] = response.xpath('//h1[@class="lyw-article-title-inner"]/span[@class="time"]/text()').get()
item['author'] = response.xpath('//div[@class="main-text"]/p/strong/text()').get()
item['content'] = "".join(response.xpath('//div[@class="main-text"]//text()').getall()).strip()
item['origin_url'] = response.url
return item
第五步:编写数据处理文件pipelines.py
由于使用pymysql直接进行数据插入这种同步的方式效率很低,这里使用异步的方式向MySQL数据库存储数据。
异步保存MySQL数据方法:
- 使用 twisted.enterprise.adbapi 创建连接池
- 使用 runInteraction 来运行插入sql语句的函数
- 在插入sql语句的函数中,第一个非self的参数就是cursor对象,通过该对象执行sql语句
在编写pipelines.py之前,需先在settings.py中配置数据库相关信息
MYSQL_CONFIG = {
'DRIVER': 'pymysql',
'HOST': '127.0.0.1',
'PORT': 3307,
'USER': 'root',
'PASSWORD': '123456',
'DATABASE': 'lieyun'
}
端口号(默认3306,整型)、用户名、密码等可根据实际情况修改,配置完成后,也需要在MySQL数据库中提前建好 lieyun 数据库,以及 lieyun_news 数据表,该数据表有6个字段,分别为 id(主键)、title(varchar)、pub_time(varchar)、author(varchar)、content(text)、origin_url(varchar)
编写pipelines.py,参考代码如下:
# -*- coding: utf-8 -*-
from twisted.enterprise import adbapi
class LieyunPipeline:
def __init__(self, mysql_config):
self.dbpool = adbapi.ConnectionPool(
mysql_config['DRIVER'],
host=mysql_config['HOST'],
port=mysql_config['PORT'],
user=mysql_config['USER'],
password=mysql_config['PASSWORD'],
db=mysql_config['DATABASE'],
charset='utf8'
)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error)
return item
@classmethod
def from_crawler(cls, crawler):
mysql_config = crawler.settings['MYSQL_CONFIG']
return cls(mysql_config)
def do_insert(self, cursor, item):
sql = 'insert into lieyun_news (title,pub_time,author,content,origin_url) values (%s,%s,%s,%s,%s)'
args = (item['title'], item['pub_time'], item['author'], item['content'], item['origin_url'])
cursor.execute(sql, args)
def handle_error(self, failure):
print('=' * 40)
print(failure)
print('=' * 40)
通过重写类方法from_crawler实现载入settings.py文件中对于MYSQL_CONFIG的配置,同时通过 adbapi.ConnectionPool 创建连接池,do_insert方法实现插入数据的操作,在处理方法process_item中使用连接池的runInteraction方法执行所有数据的插入,这样就可以实现异步的插入数据了。然后在settings.py中配置此pipeline
ITEM_PIPELINES = {
'lieyun.pipelines.LieyunPipeline': 300,
}
第六步:补齐settings.py文件,编写主执行文件main.py
补齐settings.py文件的常用属性:
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
编写爬虫运行文件main.py(在items.py同级目录下新建):
from scrapy import cmdline
cmdline.execute("scrapy crawl lieyunSpider".split())
第七步:运行爬虫程序,查看结果
运行main.py,查看运行结果及数据库信息:

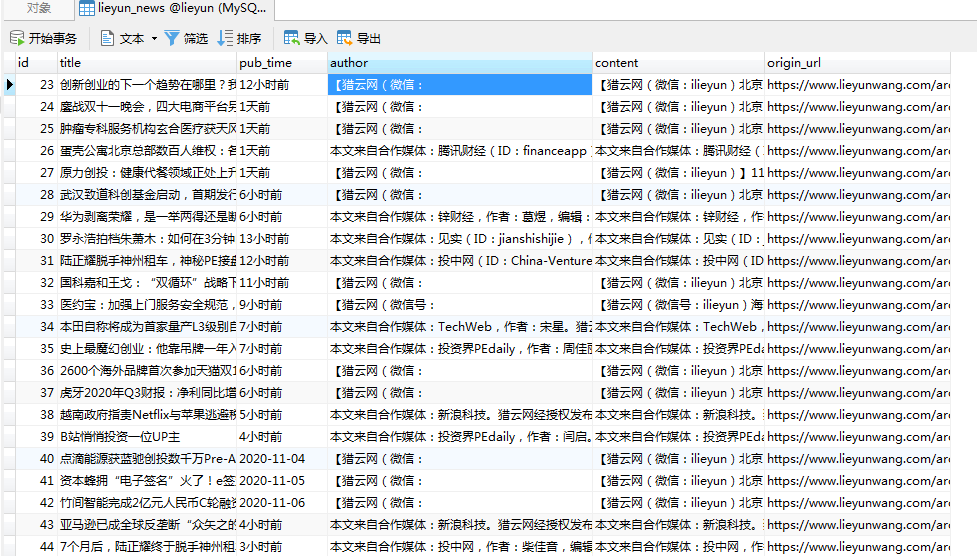
可以看到,爬虫成功爬取到了数据,且成功存储到MySQL数据库。
至此,项目结束