今天刷水木看到一个问贴,如何下载喜马拉雅音频文件?
看了几个回帖,有人说app端可以下载,有人说需要解密,也有人说可以用录屏大师翻录一下
这里,我提出一个新的解决办法,就是从原网页中抽丝剥茧的找到源文件,直接右键下载到本地
当然,如果是批量下载的话需要借住python3爬虫,因为是格式化的json数据,找到了规则非常简单,可以参考我之前写的网易云歌曲的下载方法
这里就不再重复贴出代码了
首先打开喜马拉雅网页版,随便点击一个节目,这里我用平时常听的“早安英文”举例
https://www.ximalaya.com/waiyu/3373990/222313675
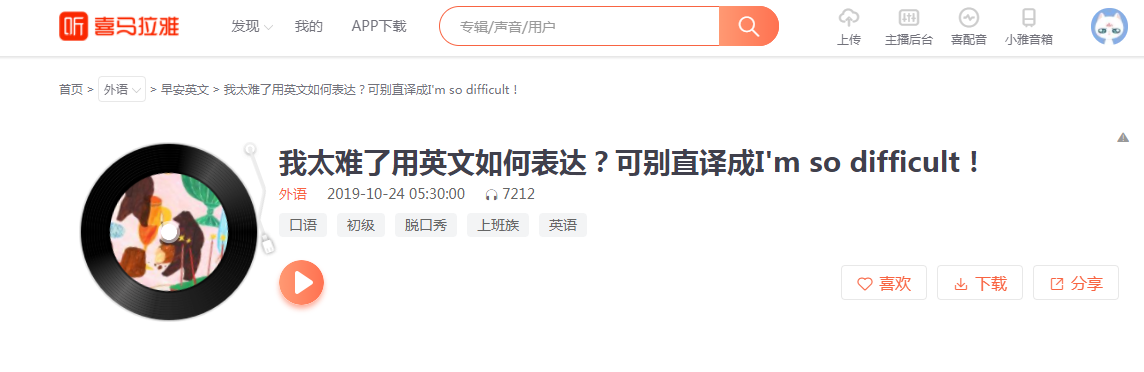
按F12打开开发者工具,然后选择network下的ALL或者XHL
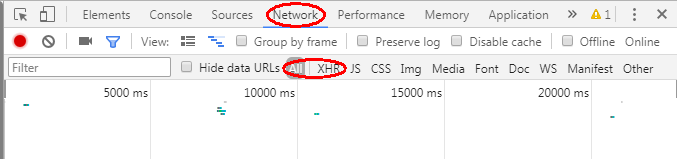
点击播放音频按键,观察开发者工具中的变化,可以发现迅速的刷新出来很多条
找到开头为audio的这一条(不要问我为什么不选其他的,这是爬多了的经验啊经验!)

单击这一条,观察右侧,copy出来框图的网址,在浏览器中打开此网址

这里推荐使用Chrome浏览器,并且使用FEhelper这个插件,因为网址中的数据是json格式的,用这个插件会自动美化

copy上图中src这个链接,通过浏览器打开会有惊喜呦,如下图所示:
点击旁边的“点点点”就下载就ok啦(不同的浏览器可能会略有区别)

测试了一下,可以正常播放,默认的文件格式是.m4a(我也不造这是啥格式嘛……)
至此,怎么下载单个音频文件搞定了。
总结一下规律,其实就是找到scr这个链接,但是发现这个链接音频的命名貌似并没有什么规律可循,因此还是要追溯到上一层级
https://www.ximalaya.com/revision/play/v1/audio?id=222313675&ptype=1
我们来看一下这个网址的规则,其实就是id不同,那么对于其他的节目而言,只要把id值更换即可
id值就是原网页中的啦https://www.ximalaya.com/waiyu/3373990/222313675 红色部分啦
bingo!
如果是想批量下载一个专辑的音频文件,怎么办呢?
首先还是回到“早安英文”首页上,红色的部分其实就是专辑ID
https://www.ximalaya.com/waiyu/3373990/
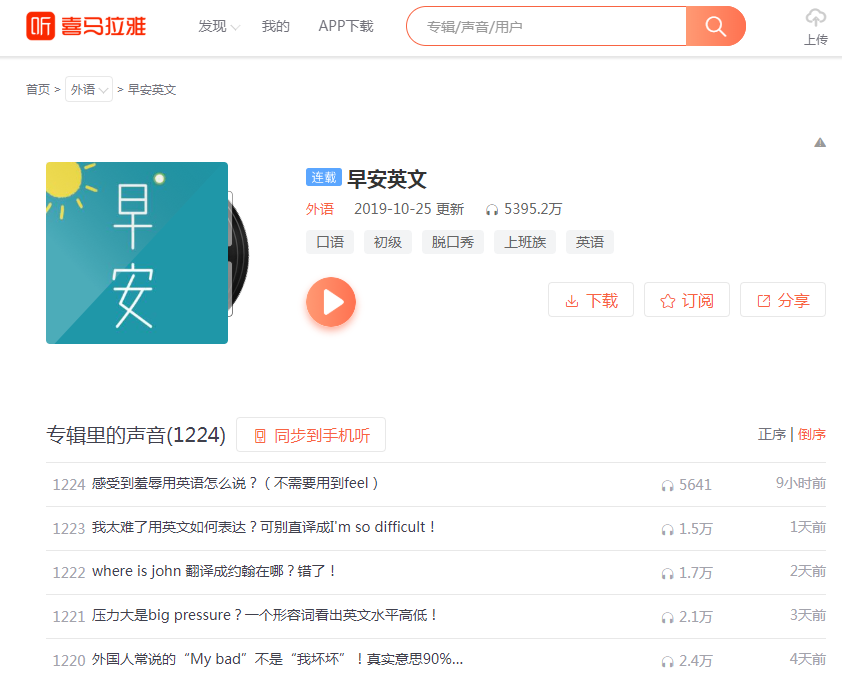
同样是按F12打开开发者工具,找到右侧框图里的网址

并通过浏览器打开https://www.ximalaya.com/revision/album/v1/getTracksList?albumId=3373990&pageNum=1
网址中红色部分就是专辑ID以及页码数
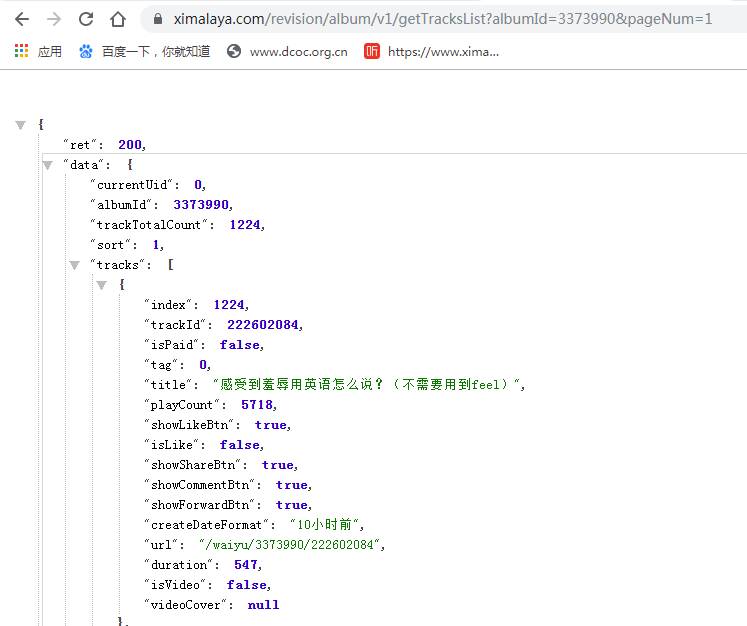
获取的json信息中可看到,单个的音频信息都在tracks中,其中trackId就是单个音频文件的id,也就是需要我们爬取下来的音频id
下拉到这个json信息的最后,可看到本页音频文件数量和页码数
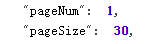
总结一下怎么批量下载一个专辑里的所有音频文件:
1. 找到这个专辑的ID号,通过打开浏览器网页观察

2.构建获取json数据的网址,格式如下:
https://www.ximalaya.com/revision/album/v1/getTracksList?albumId=专辑ID&pageNum=页码数
3. 获取json数据中每个音频文件的ID 即trackId
4. 构建每个音频文件的json数据网址,格式如下:
https://www.ximalaya.com/revision/play/v1/audio?id=单个音频文件ID&ptype=1
5. 通过浏览器打开步骤4的网页,即可下载文件
6. 遍历步骤2的每页