我的环境:
win7 32bit
python3.7
PyCharm 2018 社区版
Chrome 75.0.3770.142(正式版本) (32 位)
主旨思想就是利用OCR技术将图片中的数字、字母、汉字等识别出来
“OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也因此而产生。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。” ——百度百科
在python中用到的库就是tesserocr,它是 Python 的一个 OCR 识别库 ,但其实是对 tesseract 做的一 层 Python API 封装,所以它的核心是 tesseract。因此,在安装 tesserocr 之前,我们需要先安装 tesseract 。tesseract
tesseract是google开源的OCR,专注字符识别;当然说到图像处理就不得不提opencv,从领域来说,opencv功能更加强大
tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
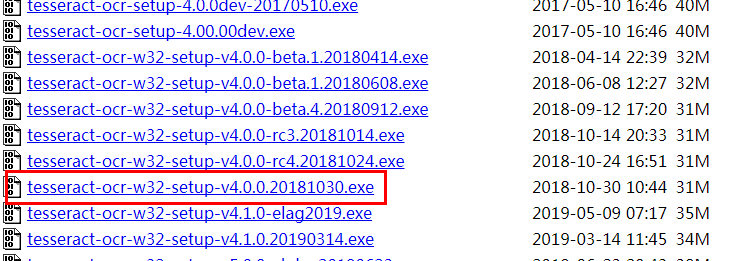
找到和自己相匹配的版本,最好不要用dev的(不稳定版本),亲测下载速度非常慢……这里也给出我下载的这个版本的百度网盘:
链接:https://pan.baidu.com/s/1eS5ZX8PYiUorA5duNVkseQ
提取码:leym
下载好之后双击安装即可,其中有一步
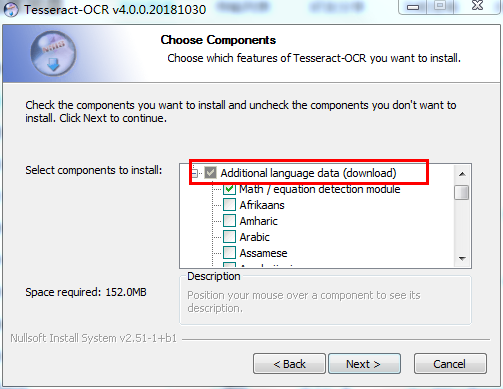
这里需要勾选红框里的Additional language data(download),这个选项是安装OCR识别支持的语言包,这样OCR就可以识别多国语言,然后再一路点击NEXT即可。勾选的语言越多,所安装的东西越多,花费的时间越大。这里可以只选择中文的就好。默认包含英文字库
安装后找到安装路径下目录,有一个tessdata文件夹,里面显示已安装的语言包;如果以后需要扩展可以单独下载语言包,然后放到这个文件夹里即可。
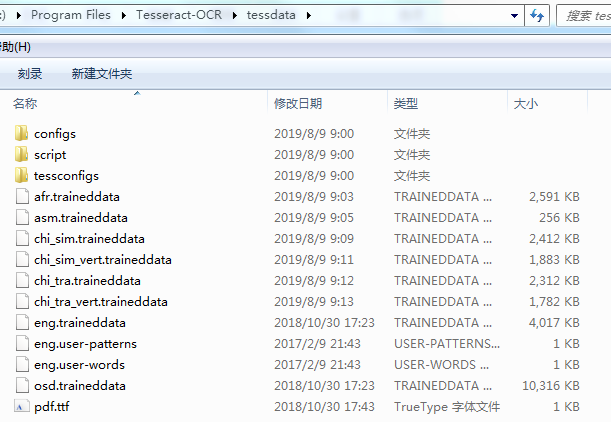
单独下载语言包链接 http://github.com/tesseract-ocr/tessdata
最后一步,添加至环境变量!
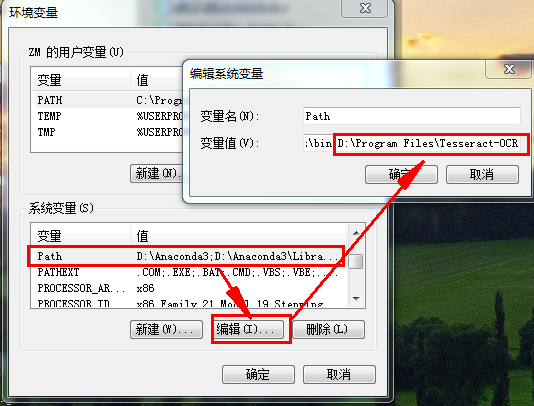
验证tesseract是否安装正确,在命令行中直接输入tesseract,出现以下结果表明ok!
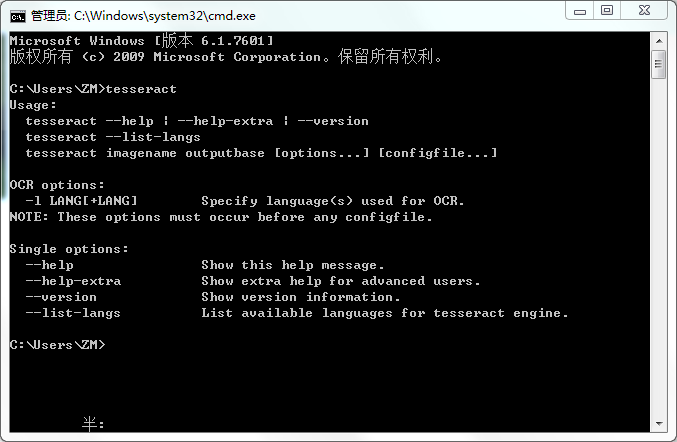
安装好tesseract之后,在python环境中安装tesserocr这个库
亲测发现使用conda install tesserocr、pip install tesserocr 都不好使……包括其他攻略上看到的这个命令conda install -c simonflueckiger tesserocr也是报错,并且PyCharm中也没有这个库
只好下载whl安装了……注意下载和tesseract版本版本匹配的
下载链接:https://github.com/simonflueckiger/tesserocr-windows_build/releases
我的百度网盘:
链接:https://pan.baidu.com/s/1OLaAuHY7w3d7bginYnLmDQ
提取码:zckj
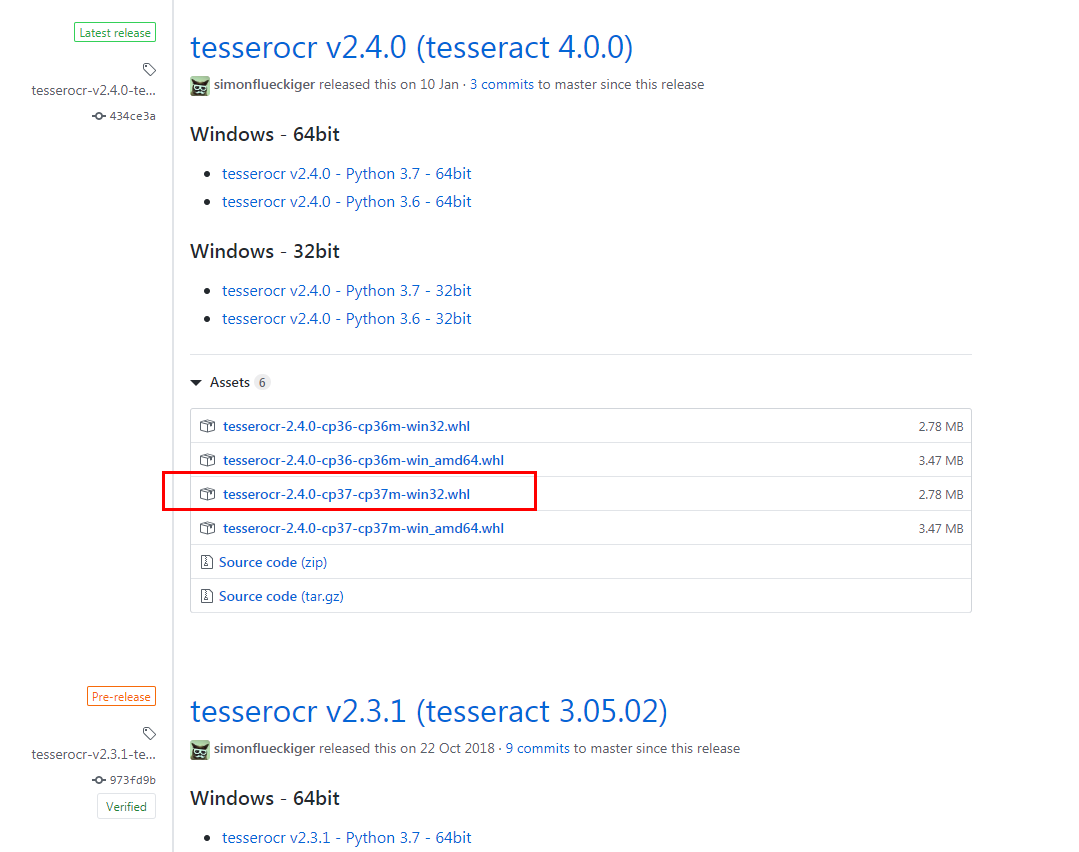
安装步骤就是在下载的这个文件夹下运行命令行(可通过shift+右键),pip install 这个whl文件的名称.whl
在python环境下import一下是否ok
至此,在python3环境下识别验证码的工作环境全部搞定!