爬虫的相关的库
urllib,requests,selenium,appium
数据解析
re,xpath,bs4,json
数据存储
pymysql,mongodb,...
任务
多线程,协程,异步
框架
scrapy,scrapy-redis
爬虫库urllib介绍
安装
pip install urllib
请求
from urllib.request import urlopen
# 发起网络请求
resp = urllopen('http://www.hao123.com')
assert resp.code == 200
print('请求成功')
# 保存请求的网页
# f 变量接收open()函数返回的对象的__enter__()返回结果
with open('a.html', 'wb') as f:
f.write(resp.read())
urlopen(url, data=None)可以直接发起url的请求, 如果data不为空时,则默认是POST请求,反之为GET请求。
resp是http.client.HTTPResponse类对象。
有请求头
from urllib.request import Request
def search_baidu():
# 网络资源的接口(URL)
url = 'https://www.baidu.com'
# 生成请求对象,封装请求的url和头header
request = Request(url,headers={'cookie':'放浏览器的cookie'}
response = urlopen(request) # 发起请求
assert response.code == 200
print('请求成功')
# 读取响应的数据
bytes_ = response.read()
# 将响应的数据写入文件中
with open('index.html', 'wb') as file:
file.write(bytes_)
5.2 urllib.parse模块
此模块有两个核心的函数:
- quote() 仅对中文字符串进行url编码;
- urlencode() 可以针对一个字典中所有的values进行编码,然后转成key=value&key=value的字符串。
"""
复杂的GET请求,多页面请求下载
"""
from urllib.request import Request, urlopen
from urllib.parse import urlencode
import ssl
import time
ssl._create_default_https_context = ssl._create_unverified_context
url = 'https://www.baidu.com/s?'
headers = {'User-Agent':'...'}
params = {
'wd': '',
'pn': 0 # 0, 10, 20, 30 ... = (n-1)*10
}
def pages_get(wd):
params['wd'] = wd
for page in range(1, 101):
params['pn'] = (page-1)*10
page_url = url+urlencode(params)
resp = urlopen(Request(page_url,
headers=headers))
assert resp.code == 200
file_name = 'baidu_pages/%s-%s.html' % (wd, page)
with open(file_name, 'wb') as f:
bytes_ = resp.read()
f.write(bytes_)
print(f'{file_name} 写入成功!')
time.sleep(0.5)
print('下载 %s 100页成功!' % wd)
if __name__ == '__main__':
pages_get('Python3.6')
5.3 HTTP处理器
urllib的请求处理器,主要用于urllib.request.build_opener()函数参数,表示构造一个由不同处理组成的伪浏览器。
5.3.1 HTTPHandler
处理Http协议的请求处理。
5.3.2 HTTPCookieProcessor
处理Cookie的处理器,创建类实例时,需要提供http.cookiejar.CookieJar类的实例对象。
requests库介绍
安装
pip install requests -i https://mirrors.aliyun.com/pypi/simple
requests核心函数
requests.request()
method:str制定请求方法,GET,POST,PUT,DELETE
url:str 请求资源接口
params:dict,请求GET请求查询参数
data:dict POST,PUT,DELETE请求表单参数
json:dict用于上传json数据参数,封装到body
files:dict
{'filename',file-like-object}
{'filename',file-like-object,content-type}
{'filename','file-like-object',content-type,custom-headers}
指定files上传文件,用post请求,请求头Content-Type
headers/cookies:dict 请求头
proxies:dict代理
auth:tuple 用于授权用户授权用户名口令
requests.get() 发起GET请求,查询数据,可以用的参数,url,params,json,headers/cookies/auth
requests.post() 参数,url,data/files/json/headers/cookies/auth
requests.put() 发起put请求,修改更新数据
requests.patch()
requests.delete() 删除数据
Response
status_code 响应状态码 一般是200,url,headers,cookies,text,content,encoding,
json(), 响应数据类型,application/json,将响应数据进行反序列化,JSON.stringify(obj)序列化,JSON.parse(text),反序列化
xpath解析数据介绍
绝对路径,从根标签,依次向下查找
相对路径
//相对于整个文档
/依次查找
.//相对于当前节点向下找所有节点
./相对于当前节点
//title/text() 查找文本
//img/@href 提取属性
//meta[1]/@content第一个
//meta[lats()]/@content 最后一个
//meta[position()-2]/@content倒数第2个
//meta[position()<3]//@content 前两个
//img[@class="circle-img"] 根据属性条件查找标签
//title/text()|//img@src 同时提取两个
//div[contains(@class,'page')] 查找class包含page的所有的div标签
//div[end-with(@class,"clearfix")]最后一个class属性值为clearfix的div标签
扩展封装的ES-SDK
"""
基于requests库封装操作ElasticSearch搜索引擎的函数 (SDK)
"""
from urllib.parse import quote
import requests
INDEX_HOST = '119.3.170.97'
INDEX_PORT = 80
class ESIndex():
"""ES的索引库的类"""
def __init__(self, index_name, doc_type):
self.index_name = index_name
self.doc_type = doc_type
def create(self): # 创建索引库
url = f'http://{INDEX_HOST}:{INDEX_PORT}/{self.index_name}'
json_data = {
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
resp = requests.put(url, json=json_data)
if resp.status_code == 200:
print('创建索引成功')
print(resp.json())
def delete(self): # 删除索引库
resp = requests.delete(f'http://{INDEX_HOST}:{INDEX_PORT}/{self.index_name}')
if resp.status_code == 200:
print('delete index ok')
def add_doc(self, item: dict):
# 向库中增加文档
doc_id = item.pop('id', None)
url = f'http://{INDEX_HOST}:{INDEX_PORT}/{self.index_name}/{self.doc_type}/'
if doc_id:
url += str(doc_id)
resp = requests.post(url, json=item)
if resp.status_code == 200:
print(f'{url} 文档增加成功!')
def remove_doc(self, doc_id):
# 删除文档
url = f'http://{INDEX_HOST}:{INDEX_PORT}/{self.index_name}/{self.doc_type}/{doc_id}'
resp = requests.delete(url)
if resp.status_code == 200:
print(f'delete {url} ok')
def update_doc(self, item: dict):
# 更新文档
doc_id = item.pop('id')
url = f'http://{INDEX_HOST}:{INDEX_PORT}/{self.index_name}/{self.doc_type}/{doc_id}'
resp = requests.put(url, json=item)
assert resp.status_code == 200
print(f'{url} update ok')
def query(self, wd=None):
# 查询
q = quote(wd) if wd else ''
url = f'http://{INDEX_HOST}:{INDEX_PORT}/{self.index_name}/_search?size=100'
if q:
url += f'&q={q}'
resp = requests.get(url)
datas = []
if resp.status_code == 200:
ret = resp.json()
hits = ret['hits']['hits']
if hits:
for item in hits:
data = item['_source']
data['id'] = item['_id']
datas.append(data)
return datas
if __name__ == '__main__':
index = ESIndex('gushiwen', 'tuijian')
# index.create()
# index.add_doc({
# 'id': 1,
# 'name': 'disen',
# 'price': 19.5
# })
#
# index.add_doc({
# 'id': 2,
# 'name': 'jack',
# 'price': 10.5
# })
print(index.query())
扩展linuk文件权限
解析站长之家
"""
基于正则re模块解析数据
"""
import re
import os
import requests
from utils.header import get_ua
base_url = 'http://sc.chinaz.com/tupian/'
url = f'{base_url}shuaigetupian.html'
headers = {
'User-Agent': get_ua()
}
if os.path.exists('mn.html'):
with open('mn.html', encoding='utf-8') as f:
html = f.read()
else:
resp = requests.get(url, headers=headers)
print(resp.encoding) # IOS-8859-1
resp.encoding = 'utf-8' # 可以修改响应的状态码
assert resp.status_code == 200
html = resp.text
with open('mn.html', 'w', encoding=resp.encoding) as f:
f.write(html)
# print(html)
# [u4e00-u9fa5]
compile = re.compile(r'<img src2="(.*?)" alt="(.*?)">')
compile2 = re.compile(r'<img alt="(.*?)" src="(.*?)">')
imgs = compile.findall(html) # 返回list
if len(imgs) == 0:
imgs = compile2.findall(html)
print(len(imgs), imgs, sep='
')
# 下一页
next_url = re.findall(r'<b>20</b></a><a href="(.*?)" class="nextpage"',html, re.S)
print(base_url+next_url[0])
re正则
字符表示
. 表示任意一个字符
[a-z],[A-Z],[0-9] 小写,大写,数字
[|sS]匹配空白字符 换行S非空白,不包括换行
w数字字母下划线
f
特殊字符
^ 开始
$ 结尾
*匹配零次或多次
?非贪婪字符
{n} 匹配确定的n次
{n,} 至少匹配n次
{n,m}最少n最多m次
贪婪 <.*>
非贪婪 <.*?>
分组表示
()普通分组 多个正则分组 search().groups 返回是元祖
`(?P<name> 字符+数量)`带有名称的分组, 多个正则分组时,search().groupdict()返回是字典, 字典的key即是分组名。
import re
text = '123abc90ccc'
re.search(r'(?P<n1>d+?)[a-z]+?(?P<n2>d+)', text).groupdict()
python 中正则模块
re.compile() 一次生成正则对象,可以匹配查询
re.match(),re.search(),re.findall(),re.sub()
re.sub('d+','120',text)
re.split()
进程线程
multiprocessing模块
Process进程类
Queue进程间通信的队列
put(item,timeout)
item=get(timeout)
threading模块(线程)
Thread线程类
线程间通信(访问对象)
queue.Queue线程队列
回调函数(主线程声明,子线程调用函数)
bs4数据解析
安装
pip install bs4
from bs4 import BeautifulSoup
root = BeautifuleSoup(html,'lxml')
查找节点(bs4.element,Tag)
root.find('标签名',class="",id="") 返回Tag对象
root.find_all('标签名',id="",limit=3) 返回limit指定数量的Tag对象
root.select('样式选择器')
#id,.class,标签名,'属性',div ul 间接子节点 div>ul 直接子节点
节点属性,获取文本数据div.text/div.string/div.get_text()
获取属性 div.get('属性名')
div['属性名']
div.attrs['属性名']
div.attrs.get('属性名')
contents 获取所有文本子节点
descendants 获取所有子节点的对象
协程爬虫
协程是线程的替代,线程是cpu调度,协程是用户调度的
协程的方式
基于生成器generator(过渡)
yield,send()
- Python3 之后引入了 asyncio模块
- @asyncio.coroutine 协程装饰器, 可以在函数上使用此装饰器,使得函数变成协程对象
- 在协程函数中,可以使用yield from 阻塞当前的协程,将执行的权限移交给 yield from 之后的协程对 象。
- asyncio.get_event_loop() 获取事件循环模型对象, 等待所有的协程对象完成之后结束。
- Python3.5之后,引入两个关键字
- async 替代 @asyncio.coroutine
- await 替代 yield from
协程的知识点
- @asyncio.coroutine 将函数升级为协程对象(闭包函数)
- yield from 将执行的权限移交给其它协程对象
- loop = asyncio.get_event_loop() 获取事件模型
- loop.run_until_complete(协程对象) 事件模型启动协程,直到协程执行完成后,释放事件模型对象。
- 如果是多个协程对象时, 需要使用asyncio.wait() 将多个协程对象以元组方式传入到wait()方法中。
- Python 3.5+增加两个关键字
- async 替代@asyncio.coroutine
- await 替代 yield from
注意: async 和 await 必须同时使用
seleinum 库
安装
pip install seleinum
下载驱动
Chrome驱动
seleinum.webdriver.common.by.By 导入By
By.CLASS_NAME
By.CSS_SELECTOR
By.ID
By.NAME
By.XPATH
By.LINK_TEXT
seleinum.webdriver.Chrome
chrome.get(url)
chrome.find_element(by,value) 在element 加s 查找多个节点
chrome.window_handlers:list 获取窗口标签页
chrome.excute_script(js) 当前窗口执行js脚本
chrome.swich_to.window/frame() 切换窗口
chrome.close()
chrome.page_source 渲染之后的html 页面代码
WebElement 查找元素对象类型
click() 点击
send_keys()输入内容
等待WebElement元素出现
selenium.webdriver.support模块
ui WebDriverWait(driver,timeout)
until(expected_conditions,err_msg)
expected_conditions
visibility_of_all_element_located((By,value))
docker 教程
docker 容器,将远程docker拉到本地
基本操作
- 镜像操作
- 基本信息
- 名称
- 版本
- ID
- 描述
- docker images 查看所有镜像
- docker rmi 名称:版本号 / ID 删除镜像
- docker run 名称:版本号 / ID 启动镜像
- -dit 后台启动镜像,启动后可进入容器并打开新的terminal(终端)
- -p 宿主机端口: 容器端口
- 容器操作
- docker ps 查看正运行的容器
- -a 查看所有的容器
- -l 查看最后一个启动的容器
- docker logs 容器名或ID 查看容器运行的日志
- docker exec 容器名或ID Linux命令 在容器中执行Linux命令
- docker exec -it 容器名或ID bash 进入容器
- docker stop 容器名或ID
- docker start 容器名或ID
- docker restart 容器名或ID
- docker rm -f 容器名或ID 删除容器, -f强制删除正运行的容器
日志模块
python中的logging
级别
DEBUG 最轻
INFO
WARNING
ERROR
CRITICAL 最重
输出到控制台
使用 logging 在控制台打印日志,这里我们用 Pycharm 编辑器来观察:
保存为.txt文件
依旧是强大的 basicConfig
logging.basicConfig(level=logging.DEBUG, filename='coder.log', filemode='a') # 配置中填写 filename (指定文件名) 和 filemode (文件写入方式)
import os
import logging
import uuid
from logging import Handler, FileHandler, StreamHandler
class PathFileHandler(FileHandler):
def __init__(self, path, filename, mode='a', encoding=None, delay=False):
filename = os.fspath(filename)
if not os.path.exists(path):
os.mkdir(path)
self.baseFilename = os.path.join(path, filename)
self.mode = mode
self.encoding = encoding
self.delay = delay
if delay:
Handler.__init__(self)
self.stream = None
else:
StreamHandler.__init__(self, self._open())
class Loggers(object):
# 日志级别关系映射
level_relations = {
'debug': logging.DEBUG, 'info': logging.INFO, 'warning': logging.WARNING,
'error': logging.ERROR, 'critical': logging.CRITICAL
}
def __init__(self, filename='{uid}.log'.format(uid=uuid.uuid4()), level='info', log_dir='log',
fmt='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s'):
self.logger = logging.getLogger(filename)
abspath = os.path.dirname(os.path.abspath(__file__))
self.directory = os.path.join(abspath, log_dir)
format_str = logging.Formatter(fmt) # 设置日志格式
self.logger.setLevel(self.level_relations.get(level)) # 设置日志级别
stream_handler = logging.StreamHandler() # 往屏幕上输出
stream_handler.setFormatter(format_str)
file_handler = PathFileHandler(path=self.directory, filename=filename, mode='a')
file_handler.setFormatter(format_str)
self.logger.addHandler(stream_handler)
self.logger.addHandler(file_handler)
if __name__ == "__main__":
txt = "谢谢关注"
log = Loggers(level='debug')
log.logger.info(4)
log.logger.info(5)
log.logger.info(txt)
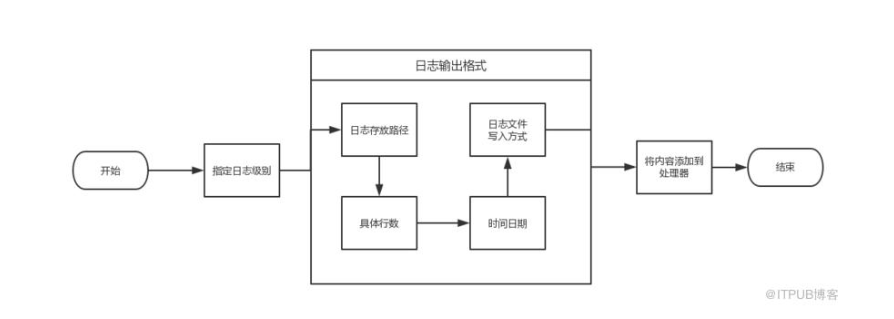
日志格式
日志的核心
日志记录器Logger
日志处理器Handler
日志过滤器Filter
日志的格式化 Formatter
日志核心方法函数
logging.getLogger(name) 默认没有name 返回root
logging.baseConfig()配置root 记录器格式,处理器
logging.info()/debug()/warning()/error()/由root记录器记录日志信息
logger记录器核心方法
setLevel(logging.DEBUG|INFO|WARNING|ERROR|CRITICAL)
addHander(hander)
debug()info()
handler处理器核心方法
Formatter初始化参数
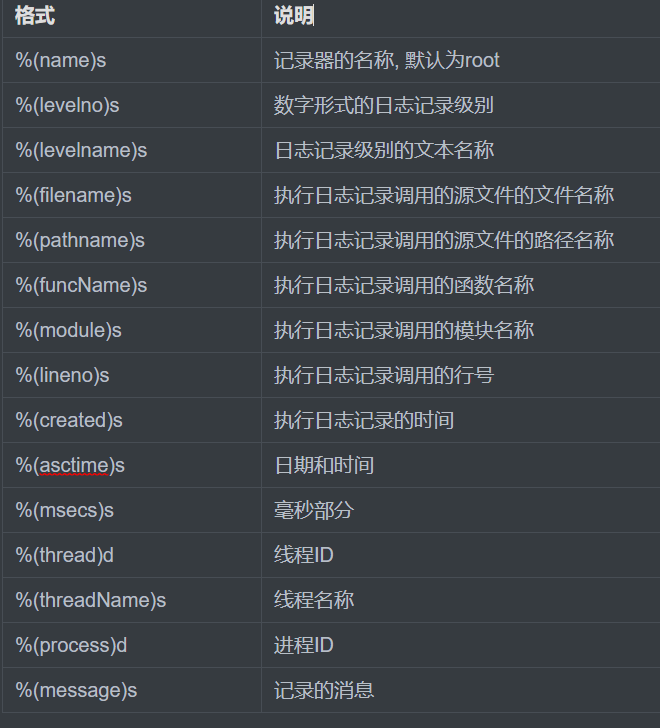
format 格式化字符串,使用`%(日志变量)s` 相关日志变量占位符组成的字符串
'hi, %(name)s, age is %(age)s' % {'age': 20, 'name': 'jack'}
'hi, %s, age is %s' % ('disen', 30)
datefmt 指定 `%(asctime)s` 日志时间的格式, 通常使用 `%Y-%m-%d %H:%M:%S` 即`年月日 时分秒`格式。
scrapy 框架
核心
engine 引擎 协调其他四个组件之间的联系,通信
spider 爬虫类 爬虫发起请求经过engine 转入scheduler
scheduler 调度器 调度所有的请求(优先级高先执行)当执行某一个请求时,engine 转入到downloader
downloader 下载器,实现任务执行,从网络上请求数据,请求到数据封装成响应对象,响应对象返回给engine,engine将数据响应数据对象,回传给它的爬虫类对象解析
itempipline 数据管道 ,当spider 解析完,将engine转入到此(数据管道),再根据数据类型,进数据处理
爬虫中间件 介于spider 和engine 之间可以拦截spider 发起的请求和数据
下载中间件 介于engine 和downloader 之间可以拦截下载和响应可以设置代理,请求头,cookie 可以基于splash和selenium实现特定操作
scrapy指令
创建项目指令:scrapy startproject 项目名
创建爬虫命令 sccrapy genspider 爬虫名域名
启动爬虫命令 scrapy crawl 爬虫名
调试爬虫命令 scrapy shell url scrapy shell fetch
Response
属性相关
body 响应字节数据
text 响应编码后的文本数据
encoding 响应数据编码字符集
status 响应状态码
url 请求url
request 请求对象
meta 元数据 在request 和callback 回调函数之间传值
解析
selector()
css()样式选择器 返回selector选择器可迭代对象
scrapy.selector.SelectorList选择器列表
x()/xpath()
scrapy.selector.Selector 选择器
样式选择器提取属性或文本
::text提取文本
::attr('属性名')提取属性
xpath()
选择器常用用法,css()xpath
extract() 提取所有内容返回是list
extract_first/get() 提取每个选择器中内容,返回文本
Request类
scrapy.http.Request
请求对象有 url callback解析数据回调函数对象 headers priority优先级
dont_filter 是否过滤重复的url,True不过滤,False过滤
scrapy 数据管道
scrapy crawl 爬虫名 -o xxx.json|csv