随着Web2.0的发展,如今已经进入了一个数据爆炸的时代。人们想要找到自己需要的信息也越来越难。
–因此有了Search,在用户对自己需求相对明确的时候,用Search能很快的找到自己需要的数据
–但很多情况下,用户其实并不明确自己的需要,或者他们需要更加符合他们个人口味和喜好的结果,因此出现了Recommendation
–这是个从数据的搜索到发现的转变
推荐方法分类–基于数据
•推荐系统可以简化建模为以下模型
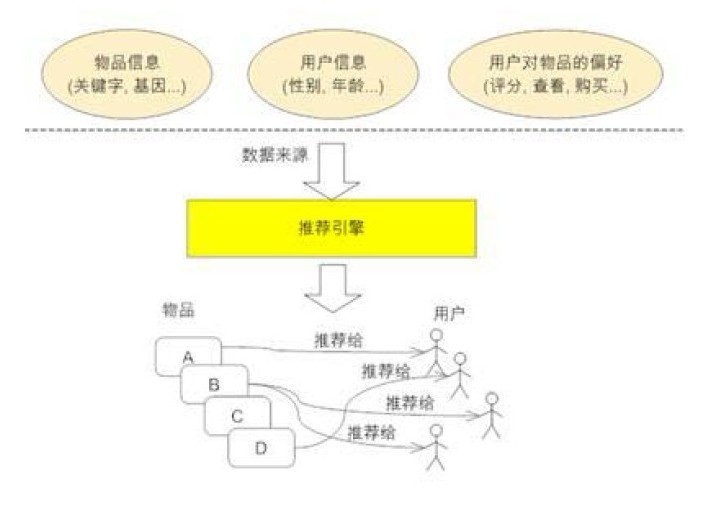
根据数据的不同,可以把推荐方法分为以下3类:
–根据用户特征(人口统计学):年龄,性别,职业,收入,地理位置
–根据物品的特征:关键词,基因…
–根据用户对物品的行为:评分,购买,评论…
协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)
基于用户的协同过滤
基本原理
–根据所有用户对物品或者信息的偏好,计算用户间的相似度
–基于相似度找到与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K-邻居”的算法
–基于这K 个邻居的历史偏好信息,为当前用户进行推荐

用户相似度的计算
–每个用户是一个向量,向量空间为物品集合,用向量的距离表示用户的相似度,cosine相似度 
优化方法:
•很多user之间其实没有共同的item,导致分子为0.
•所以先建立物品到用户的倒排表,这样就很容易找到有共同打分的user,对每两个对物品有评价的用户,在User-User的相似度表中先标出他们的分子,最后在统一计算他们的相似度
基于物品的协同过滤
基本原理也是类似的:
–它使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户
Item-based CF算法
•需要注意:
–CF算法都对流行物品进行了一些特殊的处理,以减轻他在权重中的影响。
–对ItemCF,有一个扩展算法,就是考虑用户活跃度对物品相似度的影响,认为越活跃的用户对物品的贡献度越小,类似UserCF的扩展。其实都是类似TFIDF的计算,其实对于过于活跃的用户,有的系统会忽略它的兴趣列表,这样可以提高推荐的覆盖率。
•ItemCF的相似度矩阵应该进行归一化处理,这样可以避免不同类型物品相似度绝对值范围不同的问题,以提高推荐的准确率。
两种协同过滤方法的比较
•差别
–UserCF更侧重反映和用户兴趣相似的小群体的热点,所以UserCF其实更加社会化,而ItemCF侧重于维系用户的历史兴趣,是推荐更加个性化。
–UserCF更加适合时效性强,用户个性化兴趣不明显的领域,比如个性化新闻,而ItemCF适合长尾物品丰富,用户个性化需求强烈的领域,比如图书,电影。
–通常购物网站会采用基于物品的协同过滤方法,因为物品相对用户数目更少,更容易计算。
•应用
–基于用户:Digg, 新闻网站(比如雅虎新闻)
–基于物品:Amazon, Netflix, YouTube