一、背景分析
线上故障主要会包括 CPU、内存、磁盘以及网络问题,而大多数故障可能会包含不止一个层面的问题,所以进行排查时候尽量四个方面依次排查一遍。基本上出问题就是 df、free、top,然后依次 使用jstack、jmap,具体问题具体分析。
二、CPU分析
一般来讲我们首先会排查 CPU 方面的问题。原因包括业务逻辑问题(死循环)、频繁 GC 以及上下文切换过多。而最常见的往往是业务逻辑(或者框架逻辑)导致的,可以使用 jstack 来分析对应的线程栈情况。
1. 使用 jstack 分析线程栈
先用 ps 命令找到对应进程的 pid,有好几个目标进程,可以先 top 找到cpu较高的进程。
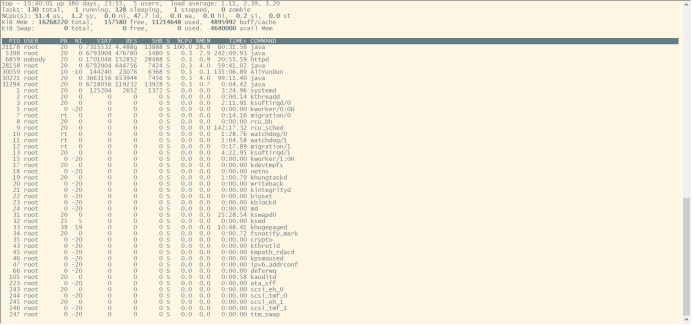
接着top -H -p <pid> 找到 CPU 使用率比较高的一些线程
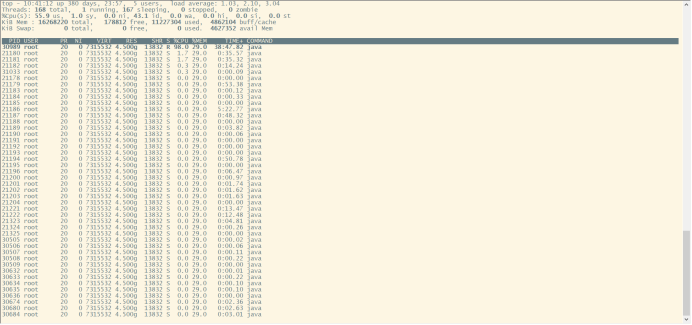
然后将占用最高的 pid 转换为 16 进制printf '%x ' <pid>得到 nid

接着直接在 jstack 中找到相应的堆栈信息
|
jstack <pid> |grep '<nid>' -C5 –color |
利用 jstack 生成虚拟机中所有线程的快照
|
jstack -l {pid} > {path} cat {path} |grep '790D' -C 5 |
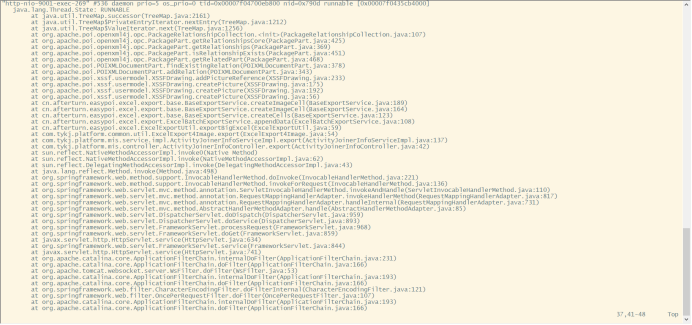
线程快照格式都是统一的,我们以一个线程快照简单说明下
|
"http-nio-9001-exec-269" #536 daemon prio=5 os_prio=0 tid=0x00007f04700eb800 nid=0x790d runnable [0x00007f0435cb4000] java.lang.Thread.State: RUNNABLE
"http-nio-9001-exec-269" 线程名称 #536 线程编号 daemon 守护线程 prio=5 线程的优先级 os_prio=0 系统级别的线程优先级 tid=0x00007f04700eb800 线程id nid=0x790d native线程的id runnable [0x00007f0435cb4000] 线程当前状态 |
对整个 jstack 文件进行分析,通常我们会比较关注 WAITING 和 TIMED_WAITING 的部分,如果 WAITING 之类的特别多,那么多半是有问题。
|
cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c |

2. 频繁 GC
先确定下 gc 是不是太频繁,使用jstat -gc pid 1000命令来对 gc 分代变化情况进行观察,1000 表示采样间隔(ms)
|
jstat -gc pid 1000 |
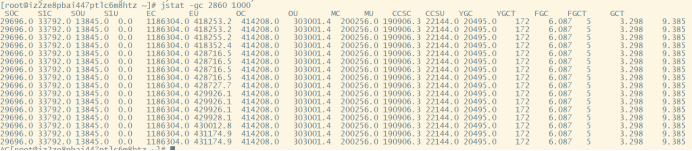
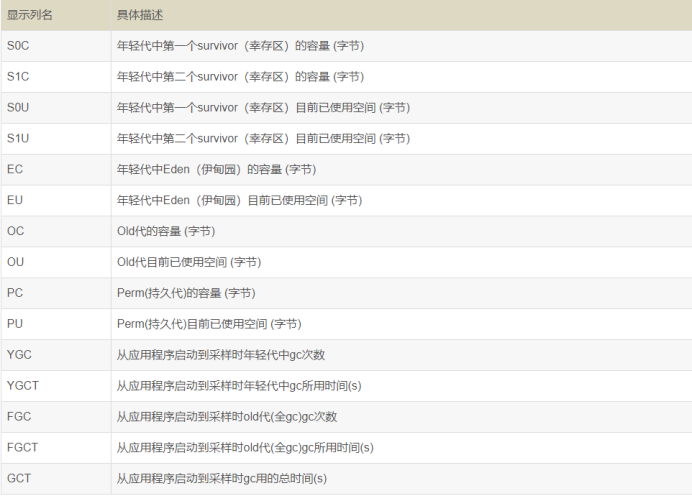
如果看到 gc 比较频繁,再针对 gc 方面做进一步分析。
3. 上下文切换
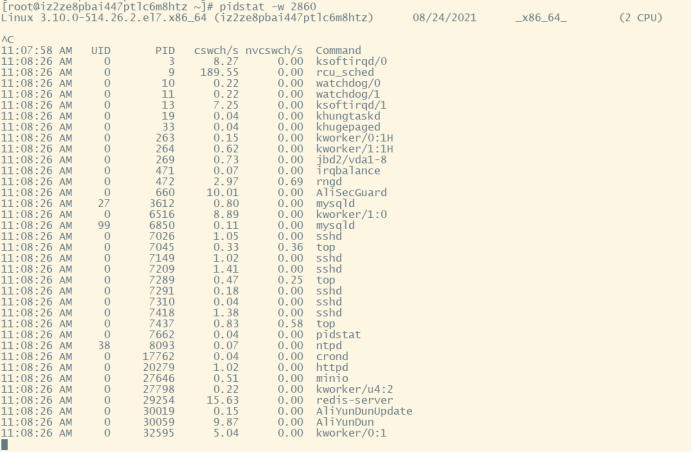
针对频繁上下文问题,我们可以使用vmstat命令来进行查看,cs(context switch)一列则代表了上下文切换的次数。

如果对特定的 pid 进行监控可以使用 pidstat -w pid命令,cswch 和 nvcswch 表示自愿及非自愿切换。
|
pidstat -w <pid> |
4. 分析过程
(1) 找到CPU使用率最高的进程
(2) 找到该进程中CPU使用率最高的线程
(3) 利用jstack生成该进程下所有线程快照
(4) 在快照中找到对应的线程分析问题
三、磁盘
首先是磁盘空间方面,使用df -hl来查看文件系统状态
|
df -hl |

更多时候磁盘问题还是性能上的问题,可以通过 iostat -d -k -x来进行分析
|
iostat -d -k -x |

最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及wrqm/s分别表示读写速度,一般就能定位到具体哪块磁盘出现问题了。
四、内存
主要包括 OOM、GC 问题和堆外内存。一般来先用free命令先来检查内存的各种情况。
|
free 或者 free -h |

1. 堆内内存
内存问题大多还都是堆内内存问题。表象上主要分为 OOM 和 Stack Overflow。
(1) OOM
JMV 中的内存不足,OOM 大致可以分为以下几种:
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
没有足够的内存空间给线程分配 Java 栈,基本上还是线程池代码写的有问题,比如说忘记 shutdown,JVM 方面可以通过指定Xss来减少单个 thread stack 的大小。另外也可以在系统层面增大 os 对线程的限制。
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
堆的内存占用已经达到-Xmx 设置的最大值。解决思路仍然是先应该在代码中找,怀疑存在内存泄漏,通过 jstack 和 jmap 去定位问题。如果一切都正常需要通过调整Xmx的值来扩大内存。
Caused by: java.lang.OutOfMemoryError: Meta space
元数据区的内存占用已经达到XX:MaxMetaspaceSize设置的最大值,解决思路仍然是先应该在代码中找,怀疑存在内存泄漏,通过 jstack 和 jmap 去定位问题。参数方面可以通过XX:MaxPermSize来进行调整。
java.lang.StackOverflowError
栈溢出抛出java.lang.StackOverflowError错误,出现此种情况是因为方法运行的时候,请求新建栈帧时,栈所剩空间小于战帧所需空间(线程栈需要的内存大于 Xss 值)。常见于通过深度递归调用方法,不停的产生栈帧,一直把栈空间堆满,直到抛出异常。
Exception in thread "main" java.lang.StackOverflowError
(2) 使用 JMAP 定位代码内存泄漏
关于 OOM 和 Stack Overflo 的代码排查方面,我们一般使用 JMAP来导出 dump 文件。
|
jmap -dump:format=b,file=filename <pid> |
MAT(Eclipse Memory Analysis Tools)
mat独立版下载地址http://www.eclipse.org/mat/downloads.php
注:安装完成后,为了更有效率的使用 MAT,可以配置一些环境参数。因为通常而言,分析一个堆转储文件需要消耗很多的堆空间,为了保证分析的效率和性能,建议分配给 MAT 尽可能多的内存资源。可以采用如下两种方式来分配内存更多的内存资源给 MAT。
第一修改启动参数 MemoryAnalyzer.exe-vmargs -Xmx4g
第二编辑文件 MemoryAnalyzer.ini,在里面添加类似信息 -vmargs– Xmx4g。
1. MemoryAnalyzer.ini中的参数一般默认为-vmargs– Xmx1024m,这就够用了。假如机器的内存不大,改大该参数的值,会导致MemoryAnalyzer启动时,报错:Failed to create the Java Virtual Machine。
2.当导出的dump文件的大小大于配置的1024m(说明1中,提到的配置:-vmargs– Xmx1024m),MAT输出分析报告的时候,会报错:An internal error occurred during: "Parsing heap dump from XXX”。适当调大说明1中的参数即可。
mat(Eclipse Memory Analysis Tools)导入 dump 文件进行分析。
内存泄漏问题一般直接选 Leak Suspects 即可,mat 给出了内存泄漏的建议。线程相关的问题可以选择 thread overview 进行分析。
IBM 内存分析工具 ha457.jar
IBM HeapAnalyzer 下载地址https://www.ibm.com/support/pages/ibm-heapanalyzer
生产环境自动dump出oom信息的phrof文件
使用启动参数 -XX:+HeapDumpOnOutOfMemoryError
导出地址:-XX:+HeapDumpPath={path}
2. GC 问题和线程
GC 问题除了影响 CPU 也会影响内存,排查思路也是一致的。一般先使用 jstat 来查看分代变化情况,比如 youngGC 或者 fullGC 次数是不是太多;EU、OU 等指标增长是不是异常等。
线程的话太多而且不被及时 gc 也会引发 oom,大部分是unable to create new native thread。
3. 堆外内存
堆外内存溢出表现就是物理常驻内存增长快,报错的话视使用方式都不确定,如果由于使用 Netty 导致的,那错误日志里可能会出现OutOfDirectMemoryError错误,如果直接是 DirectByteBuffer,那会报OutOfMemoryError: Direct buffer memory。
堆外内存溢出往往是和 NIO 的使用相关,一般我们先通过 pmap 来查看下进程占用的内存情况pmap -x pid | sort -rn -k3 | head -30,意思是查看对应 pid 倒序前 30 大的内存段。这边可以再一段时间后再跑一次命令看看内存增长情况,或者和正常机器比较可疑的内存段在哪里。
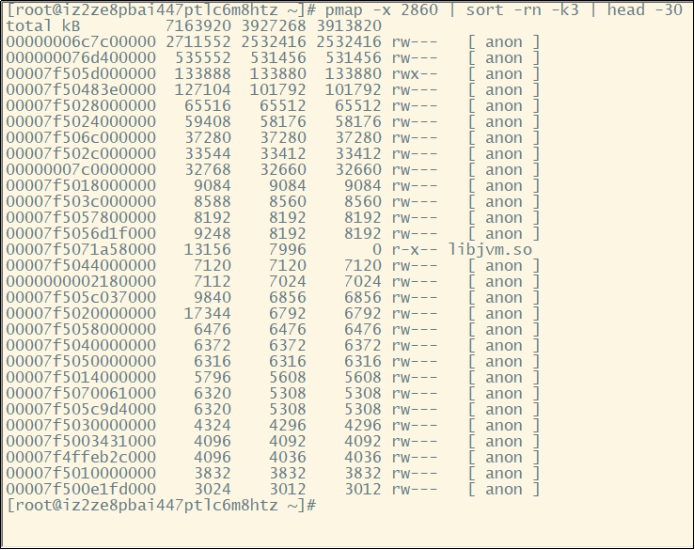
关键还是要看错误日志栈,找到可疑的对象,搞清楚回收机制,然后去分析对应的对象。比如 DirectByteBuffer 分配内存的话,是需要 full GC 或者手动 system.gc 来进行回收的。那么其实我们可以跟踪一下 DirectByteBuffer 对象的内存情况,通过jmap -histo:live pid手动触发 fullGC 来看看堆外内存有没有被回收。如果被回收了,那么大概率是堆外内存本身分配的太小了,通过-XX:MaxDirectMemorySize进行调整。如果没有什么变化,那就要使用 jmap 去分析那些不能被 gc 的对象,以及和 DirectByteBuffer 之间的引用关系了。
五、GC 问题
堆内内存泄漏总是和 GC 异常相伴。不过 GC 问题不只是和内存问题相关,还有可能引起 CPU 负载、网络问题等,只是相对来说和内存联系紧密些。
在启动参数中加上-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps来开启 GC 日志。GC 日志能大致推断出 youngGC 与 fullGC 是否过于频繁或者耗时过长。
1. youngGC 过频繁
youngGC 频繁一般是短周期小对象较多,先考虑是不是新生代设置的太小了,看能否通过调整-Xmn、-XX:SurvivorRatio 等参数设置来解决问题。如果参数正常,但是 young gc 频率还是太高,就需要使用 Jmap 和 MAT 对 dump 文件进行进一步排查了。
|
-Xmn2G 设置年轻代大小为2G -XX:SurvivorRatio=8 定义了新生代中Eden区域和Survivor区域的比例,默认为8,也就是说Eden占新生代的8/10,From幸存区和To幸存区各占新生代的1/10 |
2. youngGC 耗时过长
耗时过长问题就要看 GC 日志里耗时耗在哪一块了。
3. 触发 fullGC
(1)直接调用 System.gc() 时(调用后并不会立即发生 fullGC,后面会在某个时间点发生)
(2)老年代的可用空间不足时
(3)方法区空间不足时,或 Metaspace Space 使用达到 MetaspaceSize 但未达到 MaxMetaspaceSize 阈值;大多情况下扩容都会触发
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存时。由 Eden 区、From Survior 区向 To Survior 区复制时,对象大小大于 To Survior 区可用内存,则把该对象转存到老年代
(5)执行 jmap -histo:live 或者 jmap -dump:live;
分析过程
(1)找到内存使用率最高的进程
(2)利用jmap生成该进程的堆转储快照
(3)利用转储快照分析工具分析问题
六、总结
1. JVM 常用命令
jps:列出正在运行的虚拟机进程
jstat:监视虚拟机各种运行状态信息,可以显示虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据
jinfo:实时查看和调整虚拟机各项参数
jmap:生成堆转储快照,也可以查询 finalize 执行队列、Java 堆和永久代的详细信息
jstack:生成虚拟机当前时刻的线程快照
jhat:虚拟机堆转储快照分析工具
与 jmap 搭配使用,分析 jmap 生成的堆转储快照,与 MAT 的作用类似
2. 排查步骤
1、先找到对应的进程: PID
2、生成线程快照 stack (或堆转储快照: hprof )
3、分析快照(或堆转储快照),定位问题
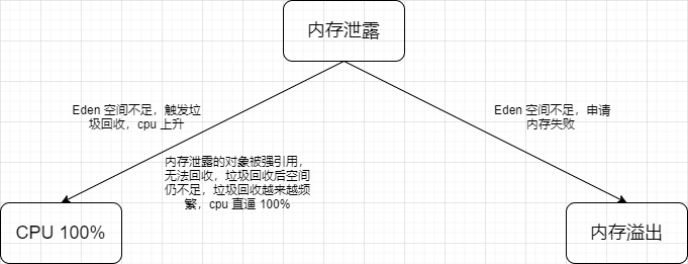
3. 内存泄露、内存溢出和 CPU 100% 关系
4. 常用 JVM 性能检测工具
Eclipse Memory Analyer、JProfile、JProbe Profiler、JVisualVM、JConsole、Plumbr