1.熟练掌握Map端join的程序编写
2.准确理解Map端join的设计原理
3.了解Map端join的适用场景
4.学会编写Map端join的程序代码解决实际问题
实验原理
MapReduce提供了表连接操作其中包括Map端join、Reduce端join还有单表连接,现在我们要讨论的是Map端join,Map端join是指数据到达map处理函数之前进行合并的,效率要远远高于Reduce端join,因为Reduce端join是把所有的数据都经过Shuffle,非常消耗资源。
1.Map端join的使用场景:一张表数据十分小、一张表数据很大。
Map端join是针对以上场景进行的优化:将小表中的数据全部加载到内存,按关键字建立索引。大表中的数据作为map的输入,对map()函数每一对<key,value>输入,都能够方便地和已加载到内存的小数据进行连接。把连接结果按key输出,经过shuffle阶段,reduce端得到的就是已经按key分组并且连接好了的数据。
为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:
(1)用户使用静态方法DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的URI(如果是HDFS上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中9000是自己配置的NameNode端口号)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
(2)用户使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。
2.本实验Map端Join的执行流程
(1)首先在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeCache中取出该小表进行join连接的 <key ,value>键值对,将其解释分割放到内存中(可以放大Hash Map等等容器中)。
(2)要重写MyMapper类下面的setup()方法,因为这个方法是先于map方法执行的,将较小表先读入到一个HashMap中。
(3)重写map函数,一行行读入大表的内容,逐一的与HashMap中的内容进行比较,若Key相同,则对数据进行格式化处理,然后直接输出。
(4)map函数输出的<key,value >键值对首先经过一个suffle把key值相同的所有value放到一个迭代器中形成values,然后将<key,values>键值对传递给reduce函数,reduce函数输入的key直接复制给输出的key,输入的values通过增强版for循环遍历逐一输出,循环的次数决定了<key,value>输出的次数。
启动hadoop
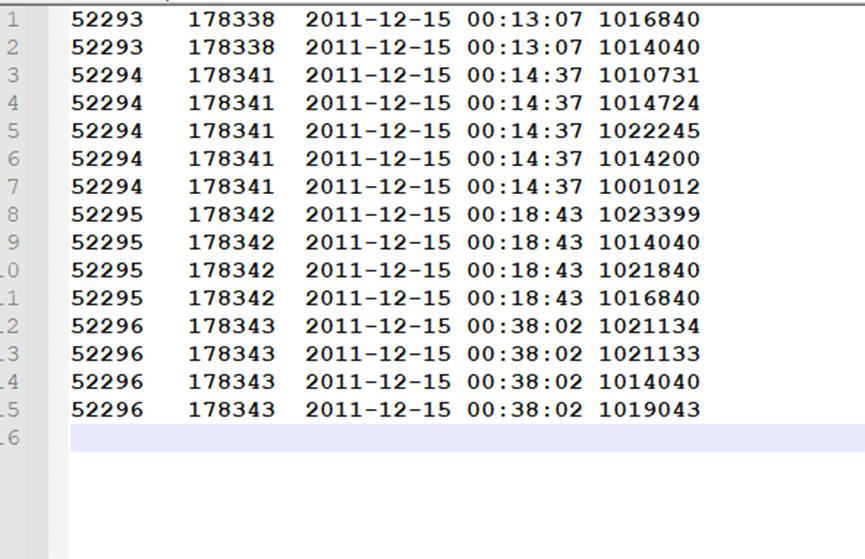
生成文件
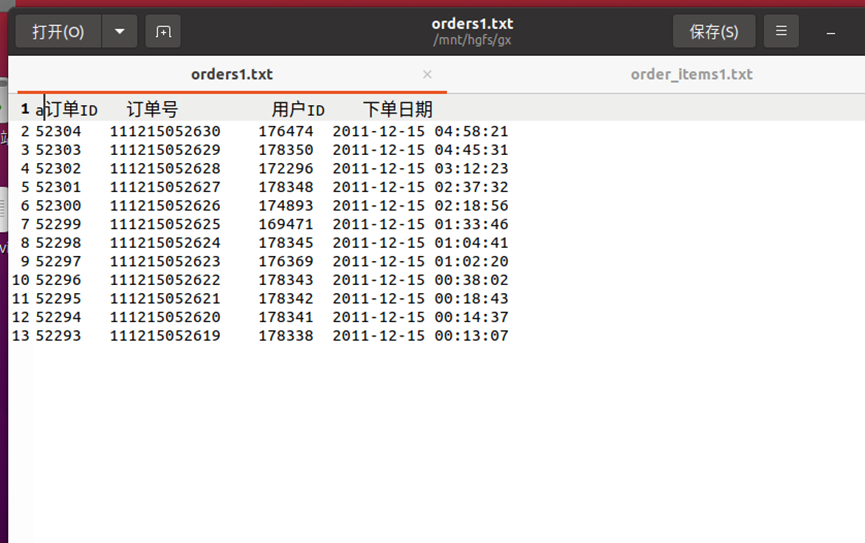
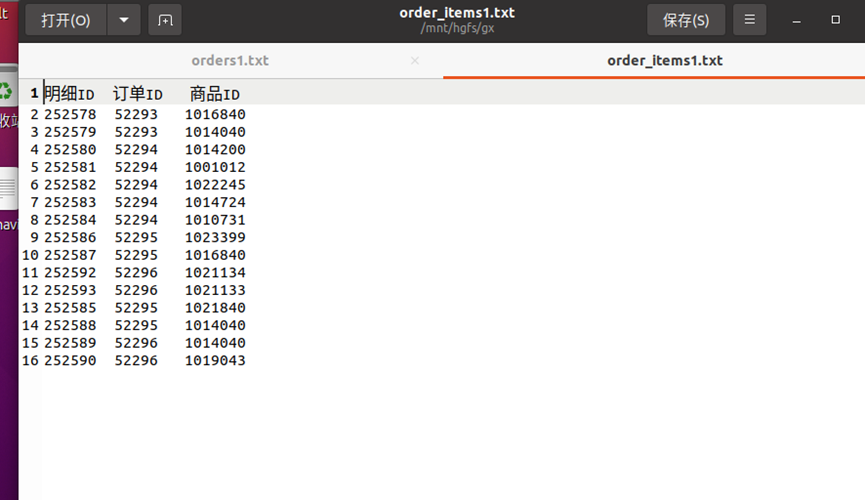
创建项目、写入代码
运行
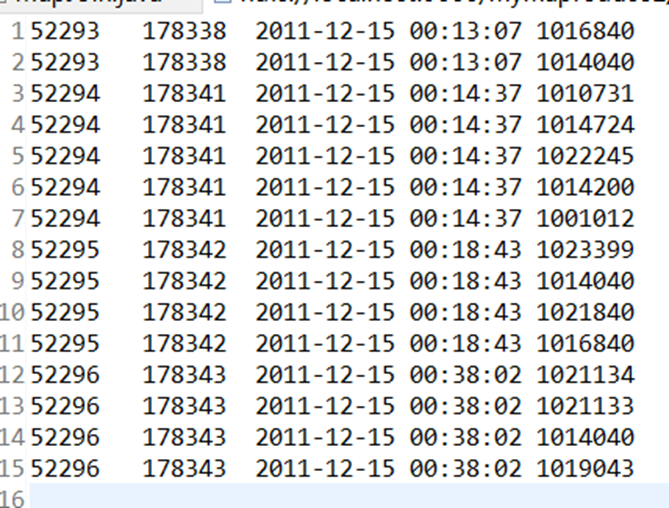
结果: