今天让我们总结下SQLite数据库在android系统中的应用。首先来看一些数据库的介绍:
SQLite数据库是一种无类型的数据库,这就代表你可以保存任何类型的数据到任何表中的任何列哦,无论这个表在create的时候该列被声明成什么类型。因为SQLite在执行数据库建表语句的时候,会自动的将类型忽略的哦。
它是一种用C语言编写的嵌入式数据库,它是一个轻量级的数据库,在一些基础简单的语句处理上要比oracle/mysql快很多,而且其对内存的要求很低。
注意:这里一定要注意,SQLite数据库在一种情况下是要求类型匹配的,当我们建表是如create table table1(id integer primary key),sqlite对应一位integer primary key的列值允许你存储64位的整数。对于SQLite来说对字段不指定类型是完全有效的。Create Table ex1(a, b, c); -------------------------------------------------------------------------------
诚然SQLite允许忽略数据类型, 但是仍然建议在你的Create Table语句中指定数据类型. 因为数据类型对于你和其他的程序员交流,或者你准备换掉你的数据库引擎. SQLite支持常见的数据类型, 如:
CREATE TABLE ex2(
a VARCHAR(10),
b NVARCHAR(15),
c TEXT,
d INTEGER,
e FLOAT,
f BOOLEAN,
g CLOB,
h BLOB,
i TIMESTAMP,
j NUMERIC(10,5)
k VARYING CHARACTER (24),
l NATIONAL VARYING CHARACTER(16)
);
上面我们对sqlite数据库的基本信息进行了介绍,现在我们一起看看sqlite的数据库语法。
至于像增删改查的语法了,实在是没什么可说的,和我们平时用的sql基本上一摸一样。我这里主要提示下怎么通过sqlite进行分页,要进行分页,需要通过如下语句
select * from tb_name limit 10 offset 1
这里的limit 10代表要获取的数据的个数,offset 1表示从第几行数据开始获取。(第一行的offset为0)
---------------------------------------------------------------------
android与sqlite的结合:
android为我们提供了一系列的api对sqlite数据库进行访问。这些类或者接口一般都存储在android.database和android.database.sqlite两个包中。
如何创建和打开sqlite数据库
在android中我们通过SQLiteDatabase这个类来操作数据库,获取其对象的方法一般有以下几种:
1、在SQLiteDatabase中,我们可以看到这些方法
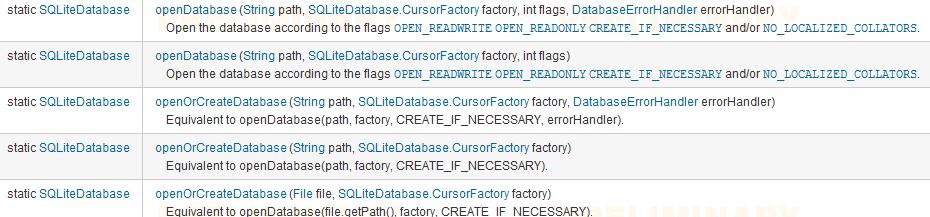
参数中的path代表着数据库的路径(如果是在默认路径/data/data/<package_name>/databases/下,则这里只需要提供数据库名称)、factory代表着在创建Cursor对象时,使用的工厂类,如果为null的话,则使用默认的工厂(这里我们可以实现自己的工厂进行某些数据处理哦)、flags代表的是创建表时的一些权限设置,多个权限之间用|分隔。
open_readonly 代表的是以只读方式打开数据库
open_readWrite代表以读写方式打开数据库
create_if_necessary当数据库不存在时创建数据库
no_localized_collators打开数据库时,不根据本地化语言对数据库进行排序
此外该类还有一个方法,为我们提供了一个内存表(即临时表,当跟数据库的连接被关闭的时候,会被删除)。当创建失败时,返回null
public static SQLiteDatabase create(CursorFactory factory)
2、和创建、打开文件相似的是,这里context中也为我们提供了一些更加方便快捷的获取数据库对象SQLiteDatabase的方法。
* @mode #MODE_PRIVATE * @mode #MODE_WORLD_READABLE * @mode #MODE_WORLD_WRITEABLE * @mode #deleteDatabase *创建或打开一个指定名称的数据库 */ public SQLiteDatabase openOrCreateDatabase(String name, int mode, CursorFactory factory);
此外,还提供了
public abstract boolean deleteDatabase(String name);
该方法可以删除私有数据库当前目录下的名称为name的数据库。
public String[] databaseList()则返回与当前activity相关联的所有的私有数据库的名称。
3、第三种办法就是通过实现自己的SQLiteOpenHelper。
SQLiteOpenHelper是系统提供的一个管理数据库表创建和更新的抽象类,我们必须通过继承SQLiteOpenHelper来实现自己的帮助类。
一般我们要重写三个方法,构造器、onCreate方法、onupgrade方法。
SQLiteOpenHelper创建数据库实际上是使用的context里面的方法创建、打开私有目录下的数据库文件。该类给我们提供了两个方法来获取SQLiteDatabase对象。

这里要特别注意,getReadableDatabase()和getWritableDatabase()方法并非和我们想象中的那样,一个返回只读,一个返回可读写的database。
getWritableDatabase方法,返回一个可读写的database(如果数据库不存在则创建一个),一旦创建成功了,那么这个database数据库就会被缓存,下次再调用该方法时,会直接把缓存中的数据库对象返回给你。当由于磁盘以及写满或者权限问题导致无法获得可写的对象时,会抛出异常!如果过了一段时间,问题已经被修复了,当你再次调用该方法的时候,依旧可以获得一个可读写的database。
getReadableDatabase方法,正常情况下,返回的结果和getWritableDatabase方法的一模一样。当遇见磁盘写满这种事故是,它不会跑出异常,而是返回一个只读的数据库对象。当我们再以后再调用改方法的时候,如果事故已经被解决掉,那么它会继续返回和getWritableDatabase一样的数据库对象。
------------------------------------------------------------------------------------
利用数据库对象SQLiteDatabase对数据库进行增删改查操作。
这里要强调一点,无论我们怎么获得的数据库连接,我们可以看到,我们最后都是为了获得一个SQLiteDatabase对象,而我们的所以增删改查方法便都是通过这个对象来实现的。
增加数据:

参数介绍:
table 要插入数据的表的名称
values:一个ContentValues对象,类似一个map.通过键值对的形式存储值。
conflictAlgon:冲突解决方案。例如当数据表主键的唯一性检测出错的时候,就会按照该值设定的值进行处理。
nullColumnHack:当values参数为空或者里面没有内容的时候,我们insert是会失败的(底层数据库不允许插入一个空行),为了防止这种情况,我们要在这里指定一个列名,到时候如果发现将要插入的行为空行时,就会将你指定的这个列名的值设为null,然后再向数据库中插入。
(这里很多人会迷惑,nullColumnHack到底干什么用的,为什么会出现呢。当我们不设定一列的时候,不都是数据库给设为默认值吗?很多字段设置默认值也是null,这里显示的设置也是null,有什么区别吗,怎么会显示设置了之后就允许插入了呢?笔者为了找到原因,我去查看了源代码)
其实在底层,各种insert方法最后都回去调用insertWithOnConflict方法,这里我们粘贴出该方法的部分实现
/** * General method for inserting a row into the database. * * @param table the table to insert the row into * @param nullColumnHack SQL doesn't allow inserting a completely empty row, * so if initialValues is empty this column will explicitly be * assigned a NULL value * @param initialValues this map contains the initial column values for the * row. The keys should be the column names and the values the * column values * @param conflictAlgorithm for insert conflict resolver * @return the row ID of the newly inserted row * OR the primary key of the existing row if the input param 'conflictAlgorithm' = * {@link #CONFLICT_IGNORE} * OR -1 if any error */ public long insertWithOnConflict(String table, String nullColumnHack, ContentValues initialValues, int conflictAlgorithm) { if (!isOpen()) { throw new IllegalStateException("database not open"); } // Measurements show most sql lengths <= 152 StringBuilder sql = new StringBuilder(152); sql.append("INSERT"); sql.append(CONFLICT_VALUES[conflictAlgorithm]); sql.append(" INTO "); sql.append(table); // Measurements show most values lengths < 40 StringBuilder values = new StringBuilder(40); Set<Map.Entry<String, Object>> entrySet = null; if (initialValues != null && initialValues.size() > 0) { entrySet = initialValues.valueSet(); Iterator<Map.Entry<String, Object>> entriesIter = entrySet.iterator(); sql.append('('); boolean needSeparator = false; while (entriesIter.hasNext()) { if (needSeparator) { sql.append(", "); values.append(", "); } needSeparator = true; Map.Entry<String, Object> entry = entriesIter.next(); sql.append(entry.getKey()); values.append('?'); } sql.append(')'); } else { sql.append("(" + nullColumnHack + ") "); values.append("NULL"); }
这里我们可以看到,当我们的ContentValues类型的数据initialValues为null,或者size<=0时,就会再sql语句中添加nullColumnHack的设置。我们可以想象一下,如果我们不添加nullColumnHack的话,那么我们的sql语句最终的结果将会类似insert into tableName()values();这显然是不允许的。而如果我们添加上nullColumnHack呢,sql将会变成这样,insert into tableName (nullColumnHack)values(null);这样很显然就是可以的。
删除相关:

table:要删除的数据所在的表的名称
whereClause:条件语句,注意这里的条件语句并不包括where这个单词。例如 name="chenzheng_java" and age=23
whereArgs:我们再where子句中,为了防止sql注入,我们通常会通过?的方式进行代替,然后再为?赋值。
当删除正常执行时,返回的是删除的数据的个数;否则的话,返回0.如果我们想全部删除的话,whereClause设置为“1”即可。
查询相关:
主要方法有
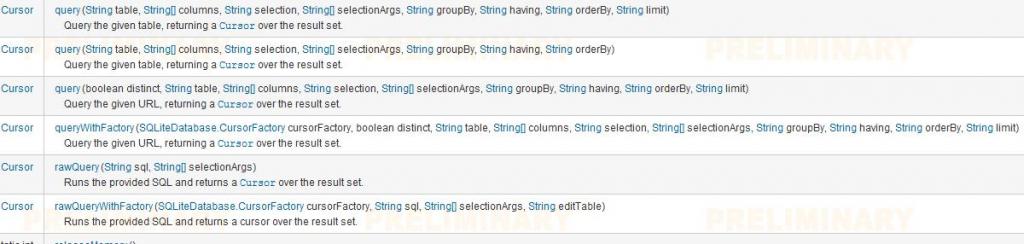
参数介绍:
table 表名称
columns 要查询的列名,以数组的形式提供。
selection:条件语句
selectionArgs:条件语句中?的内容参数、
limit:所取的记录个数限制
eidtTable :第一个可编辑的表名称
其中rawQuery是通过sql语句进行查询的哦。
修改操作:

----------------------------------------------------------------------------
事务相关:
和事务相关的方法
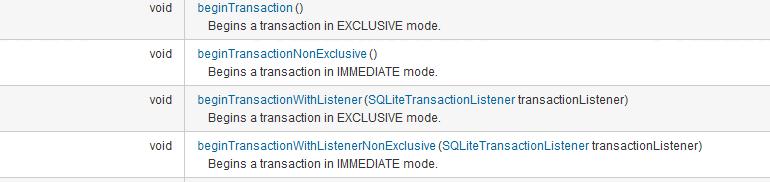
transactionListener:当事务执行了begin/commit/rollback方法时触发
关于Exclusive和immediate模式的说明:
Exclusive代表排他的、独立的,当我们用这种模式获取事务时,在我们的事务没有结束之前,其他的线程和进程是既不能读取该数据库,也不能对数据库进行任何写操作;
immediate代表即时的,当我们用这种模式获取事务的时候,其他进程和线程无法写入该数据库,但是却可以正常的读取。
设置事务提交的方法
setTransactionSuccessful() ,记得一定要调用此方法,要不事务不会提交,而是会自动回滚的。
结束事务:endTransaction();一般在调用了setTransactionSuccessful()方法之后接着调用endTransaction()方法、
--------------------------------------------------------------------------------------
记得,在程序的最后,一定要调用SQLiteDatabase的close()方法关闭数据库。
---------------------------------------------------------------------------------------
结果集的遍历:
android.database.Cursor接口
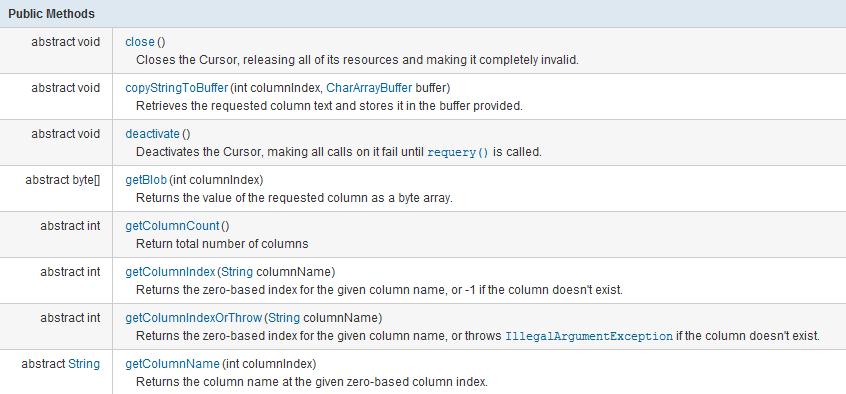
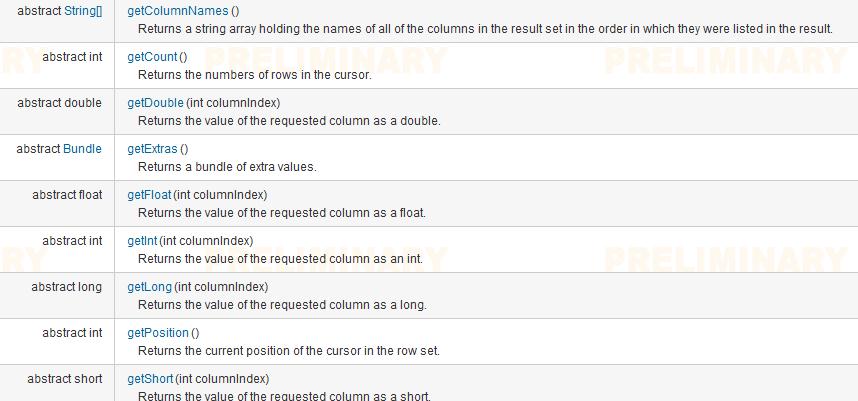
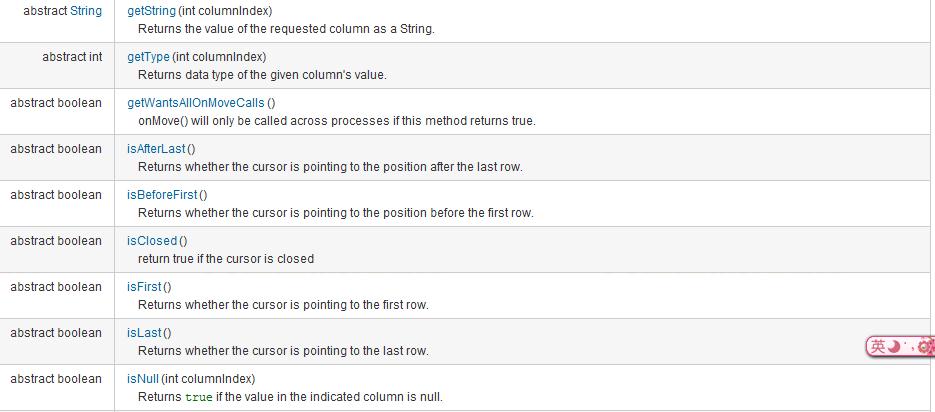


如果你用过JDBC中的游标,那你对这里面的所有方法应该都不陌生。这里就不多详细介绍用法了。