给出一个(n imes m)的网格图,第i行第j列上的格子有数字(a[i][j]),显然,你可以从中找到一个子矩阵,保证子矩阵中的数字互不相同,求子矩阵的最大面积,(n,mleq 400,a[i][j]leq 400^2)。
解
法一:确定上下边界+双指针
枚举子矩阵上边界和下边界,发现确定了左端点后,随着左端点的递增,右端点也在递增,于是可以双指针做到(O(n^4))。
参考代码:
你来写啊
法二:确定上边界,枚举下边界,维护一个左端点对应的右端点
先讲做法,再讲正确性,看仔细了,实在看不懂来找我吧,感觉很难讲清楚。
从小到大枚举上边界(u),再从小到大枚举下边界(d),维护(R_i)表示上边界,下边界,以及第i列围成的矩形向右最远可以延伸的位置,维护set c[i]表示数字i在网格图中出现的列位置。
现在从(d ightarrow d+1),先可以对于(d+1)行单独对于每个i求出其能最优延伸位置尝试对(R_i)更新,然后对于每个位置j,查询一个位置坐标p1小于等于j且与它相同的数字,查询一个位置p2大于等于j与之相同的数字,然后用(p1)更新(R_j),p2更新(R_{p1}),再把这一行的数字对应加入平衡树即可。
首先对于不同种类的数字,贡献是可以单独看的,这是一种很常见但我总是不记得的研究思路(如网格图中的行列独立,经典的错排问题),对于其中任意两个数字设其列位置为(x_1,x_2(x_1leq x_2)),显然它可以利用(x_2)更新的(R_i,i)的范围为([1,x_1]).
此时如果我们另(R_{x_1}=x_2),日后倒序枚举i,进行操作(R_i=min(R_i,R_{i+1})),等价于([1,x_1])中所有(R_i)都与(x_2)取min(区间修改转化为两点修改的思想,我又忘了)。
如果我们枚举对于一种数字每一对((x_1,x_2))进行上段的操作,肯定可以得到这个数字的贡献,更进一步,这对数字只要枚举最靠近的一对。
于是我们需要平衡树来维护位置关系,现在下边界从(d)到了(d+1),考虑答案的来源,显然是因为新来的一行的数字,显然答案只涉及该行的数字种类的影响,于是考虑该行上的每种数字,一个数字i对答案的贡献,显然是来自两个方向,第一个是(d)行及以上的离他最近的数字和(d+1)行离它最近的数字。
于是我们可以利用法一的双指针暴力求出一行中每个数字离他最近的相同的数字,然后其它的,直接在平衡树中查找即可,当然你也可以先全部加进平衡树,再一个一个找,按照前面提到的方法更新即可。
时间复杂度有点不稳,(O(n^3log(n))),如果你看懂了,证明我语文有进步了。
参考代码:
#include <iostream>
#include <cstdio>
#include <set>
#include <cstring>
#define il inline
#define ri register
#define Size 450
#define intmax 0x3f3f3f3f
using namespace std;
set<int>c[Size*Size];
set<int>::iterator i1,i2;
int a[Size][Size],bu[Size*Size],R[Size];
il void read(int&);
int main(){
int n,m,ans(-intmax);
read(n),read(m);
for(int i(1),j;i<=n;++i)
for(j=1;j<=m;++j)
read(a[i][j]);
for(int u(1),d;u<=n;++u){
memset(R,0,sizeof(R));
for(int i(1);i<=16000;++i)c[i].clear();
for(int i(1);i<=m;++i)R[i]=m;
for(d=u;d<=n;++d){
for(int i(1),j(0);i<=m;++i){
while(!bu[a[d][j+1]]&&j<m)
++j,++bu[a[d][j]];
R[i]=min(R[i],j),--bu[a[d][i]];
i2=c[a[d][i]].upper_bound(i);
i1=c[a[d][i]].lower_bound(i);
if(i2!=c[a[d][i]].begin())
--i2,R[*i2]=min(R[*i2],i-1);
if(i1!=c[a[d][i]].end())R[i]=min(R[i],*i1-1);
}for(int i(m-1);i;--i)R[i]=min(R[i],R[i+1]);
for(int i(1);i<=m;++i)
ans=max(ans,(R[i]-i+1)*(d-u+1)),
c[a[d][i]].insert(i);
}
}printf("%d",ans);
return 0;
}
il void read(int &x){
x^=x;ri char c;while(c=getchar(),c<'0'||c>'9');
while(c>='0'&&c<='9')x=(x<<1)+(x<<3)+(c^48),c=getchar();
}
法三:
法二的时间复杂度瓶颈在查询一个数字最靠近它的相同数字,然后出题人用了我最不记得的逆向思维,倒着枚举某个东西,看某个东西可以降时间复杂度。
我们倒序枚举(u),设(l[i][j])为第i行第j个位置上的数字从左边最靠近它的在第(i)行到第(u)行那个数字,(r[i][j])差不多意思,换了一个左右方向,显然当u减少的时候,(l[i][j],r[i][j])的答案来源于第(u-1)行的最靠近第j列的两个相同数字,显然两次扫描,这个就可以(O(n))维护(不晓得看代码)。
然后从(u)开始顺序枚举(d),然后我们是否就可以像法二一样求出每个(usim d)的(R_i)?接着我们的时间复杂度就降为了(O(n^3))。
参考代码:
#include <iostream>
#include <cstdio>
#include <cstring>
#define il inline
#define ri register
#define Size 450
using namespace std;
int a[Size][Size],l[Size][Size],
r[Size][Size],R[Size],p[Size*Size];
il void read(int&);
int main(){
int n,m,ans(0);read(n),read(m);
for(int i(1),j;i<=n;++i)
for(j=1;j<=m;++j)
read(a[i][j]);
for(int u(n),d;u;--u){
memset(p,0,sizeof(p));
for(int i(1);i<=m;++i){
l[u][i]=p[a[u][i]],p[a[u][i]]=i;
for(d=u+1;d<=n;++d)
l[d][i]=max(l[d][i],p[a[d][i]]);
}for(int i(1);i<=160000;++i)p[i]=m+1;
for(int i(m);i;--i){
r[u][i]=p[a[u][i]],p[a[u][i]]=i,R[i]=m+1;
for(d=u+1;d<=n;++d)
r[d][i]=min(r[d][i],p[a[d][i]]);
}for(d=u;d<=n;++d){
for(int i(1);i<=m;++i){
R[i]=min(R[i],r[d][i]);
R[l[d][i]]=min(R[l[d][i]],i);
}for(int i(m-1);i;--i)
R[i]=min(R[i],R[i+1]);
for(int i(1);i<=m;++i)
ans=max(ans,(d-u+1)*(R[i]-i));
}
}printf("%d",ans);
return 0;
}
il void read(int &x){
x^=x;ri char c;while(c=getchar(),c<'0'||c>'9');
while(c>='0'&&c<='9')x=(x<<1)+(x<<3)+(c^48),c=getchar();
}
法四:
子矩阵问题可以区间dp,算是长眼界了,设(f[i][l][r])表示下边界为第i行,从第l列到第r列,最小的上边界,设(b[i][j][k]),表示第i行第j列往上出现数字k的最行坐标,然后就有
(f[i][l][r]=min(f[i-1][l][r],f[i][l+1][r],f[i][l][r-1],b[i][l][a[i][r]],b[i][r][a[i][l]]))
这个方程需要解释,
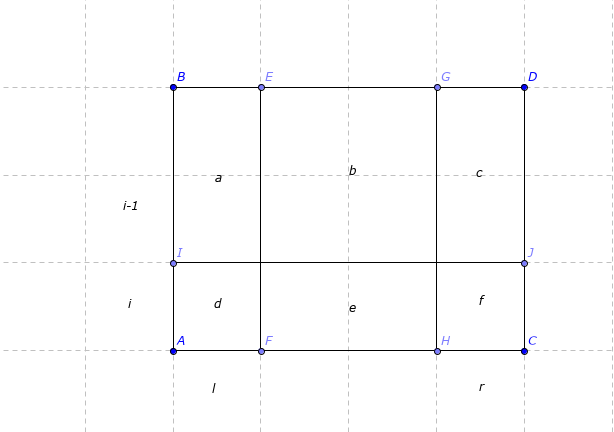
注意到(min(f[i][l+1][r],f[i][l][r-1]))保证了答案区域(a,d eq b,e eq c,f),但不能保证区域(a,d eq c,f),再与(f[i-1][l][r])取min,对于d来说,已经满足了(a,b,e eq d),那么只要看(c,f)和(d)考虑在一起的上界了,因为对称,(f)也只要考虑(a,d)。
最后,显然如果你开这么多维度,肯定会(MLE),但实际上,f的第一维可以压掉,包括b的第一维,最后时间复杂度是(O(n^3)),虽然常数大了一点,空间有点大,但不失为一种奇妙的思路。
参考代码:
#include <iostream>
#include <cstdio>
#define il inline
#define ri register
#define Size 402
using namespace std;
int a[Size][Size],dp[Size][Size],
b[Size][Size*Size];
il void read(int&);
int main(){
int n,m,ans(0);read(n),read(m);
for(int i(1),j;i<=n;++i)
for(j=1;j<=m;++j)read(a[i][j]);
for(int i(1),j,k;i<=n;++i){
for(j=1;j<=m;++j)dp[j][j]=max(dp[j][j],b[j][a[i][j]]),b[j][a[i][j]]=i;
for(j=1;j<=m;++j)
for(k=j-1;k;--k)
dp[k][j]=max(dp[k][j],max(max(dp[k+1][j],dp[k][j-1]),max(b[j][a[i][k]],b[k][a[i][j]])));
for(k=1;k<=m;++k)
for(j=k;j<=m;++j)
ans=max(ans,(i-dp[k][j])*(j-k+1));
}printf("%d",ans);
return 0;
}
il void read(int &x){
x^=x;ri char c;while(c=getchar(),c<'0'||c>'9');
while(c>='0'&&c<='9')x=(x<<1)+(x<<3)+(c^48),c=getchar();
}