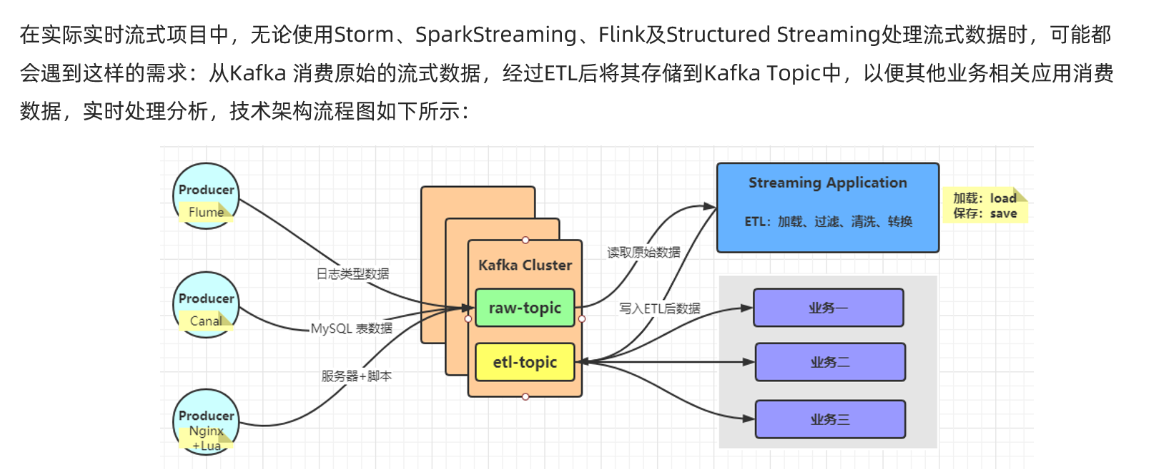
准备:
每台节点启动zookeeper集群
cd /usr/local/zookeeper/bin/
./zkServer.sh start
master上启动kafka:
cd /usr/local/kafka_2.12-2.7.0/bin kafka-server-start.sh ../config/server.properties
另开终端:
cd /usr/local/kafka_2.12-2.7.0/bin
kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181 --replication-factor 1 --partitions 4 --topic stationTopic
kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181 --replication-factor 1 --partitions 4 --topic etlTopic
kafka-console-consumer.sh --bootstrap-server master:9092 --topic stationTopic --from-beginning
再另开终端:
cd /usr/local/kafka_2.12-2.7.0/bin kafka-console-consumer.sh --bootstrap-server master:9092 --topic etlTopic --from-beginning
启动
MockStationLog
package cn.itcast.structured import java.util.Properties import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord} import org.apache.kafka.common.serialization.StringSerializer import scala.util.Random /** * 模拟产生基站日志数据,实时发送Kafka Topic中 * 数据字段信息: * 基站标识符ID, 主叫号码, 被叫号码, 通话状态, 通话时间,通话时长 */ object MockStationLog { def main(args: Array[String]): Unit = { // 发送Kafka Topic val props = new Properties() props.put("bootstrap.servers", "master:9092") props.put("acks", "1") props.put("retries", "3") props.put("key.serializer", classOf[StringSerializer].getName) props.put("value.serializer", classOf[StringSerializer].getName) val producer = new KafkaProducer[String, String](props) val random = new Random() val allStatus = Array( "fail", "busy", "barring", "success", "success", "success", "success", "success", "success", "success", "success", "success" ) while (true) { val callOut: String = "1860000%04d".format(random.nextInt(10000)) val callIn: String = "1890000%04d".format(random.nextInt(10000)) val callStatus: String = allStatus(random.nextInt(allStatus.length)) val callDuration = if ("success".equals(callStatus)) (1 + random.nextInt(10)) * 1000L else 0L // 随机产生一条基站日志数据 val stationLog: StationLog = StationLog( "station_" + random.nextInt(10), callOut, callIn, callStatus, System.currentTimeMillis(), callDuration ) println(stationLog.toString) Thread.sleep(100 + random.nextInt(100)) val record = new ProducerRecord[String, String]("stationTopic", stationLog.toString) producer.send(record) } producer.close() // 关闭连接 } /** * 基站通话日志数据 */ case class StationLog( stationId: String, //基站标识符ID callOut: String, //主叫号码 callIn: String, //被叫号码 callStatus: String, //通话状态 callTime: Long, //通话时间 duration: Long //通话时长 ) { override def toString: String = { s"$stationId,$callOut,$callIn,$callStatus,$callTime,$duration" } } }
再启动:
Demo09_Kafka_ETL
package cn.itcast.structured import org.apache.spark.SparkContext import org.apache.spark.sql.streaming.Trigger import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} /** * Author itcast * Desc 演示StructuredStreaming整合Kafka, * 从stationTopic消费数据 -->使用StructuredStreaming进行ETL-->将ETL的结果写入到etlTopic */ object Demo09_Kafka_ETL { def main(args: Array[String]): Unit = { //TODO 0.创建环境 //因为StructuredStreaming基于SparkSQL的且编程API/数据抽象是DataFrame/DataSet,所以这里创建SparkSession即可 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4") //本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ //TODO 1.加载数据-kafka-stationTopic val kafkaDF: DataFrame = spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "master:9092") .option("subscribe", "stationTopic") .load() val valueDS: Dataset[String] = kafkaDF.selectExpr("CAST(value AS STRING)").as[String] //TODO 2.处理数据-ETL-过滤出success的数据 val etlResult: Dataset[String] = valueDS.filter(_.contains("success")) //TODO 3.输出结果-kafka-etlTopic etlResult.writeStream .format("kafka") .option("kafka.bootstrap.servers", "master:9092") .option("topic", "etlTopic") .option("checkpointLocation", "./ckp") //TODO 4.启动并等待结束 .start() .awaitTermination() //TODO 5.关闭资源 spark.stop() } } //0.kafka准备好 //1.启动数据模拟程序 //2.启动控制台消费者方便观察 //3.启动Demo09_Kafka_ETL
可以看到主题stationTopic不断的接收模拟日志,而etlTopic接收过滤了success的数据

案例:
kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181 --replication-factor 1 --partitions 4 --topic iotTopic
启动消费:
kafka-console-consumer.sh --bootstrap-server master:9092 --topic iotTopic --from-beginning
启动数据模拟程序
package cn.itcast.structured import java.util.Properties import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord} import org.apache.kafka.common.serialization.StringSerializer import org.json4s.jackson.Json import scala.util.Random object MockIotDatas { def main(args: Array[String]): Unit = { // 发送Kafka Topic val props = new Properties() props.put("bootstrap.servers", "master:9092") props.put("acks", "1") props.put("retries", "3") props.put("key.serializer", classOf[StringSerializer].getName) props.put("value.serializer", classOf[StringSerializer].getName) val producer = new KafkaProducer[String, String](props) val deviceTypes = Array( "db", "bigdata", "kafka", "route", "bigdata", "db", "bigdata", "bigdata", "bigdata" ) val random: Random = new Random() while (true) { val index: Int = random.nextInt(deviceTypes.length) val deviceId: String = s"device_${(index + 1) * 10 + random.nextInt(index + 1)}" val deviceType: String = deviceTypes(index) val deviceSignal: Int = 10 + random.nextInt(90) // 模拟构造设备数据 val deviceData = DeviceData(deviceId, deviceType, deviceSignal, System.currentTimeMillis()) // 转换为JSON字符串 val deviceJson: String = new Json(org.json4s.DefaultFormats).write(deviceData) println(deviceJson) Thread.sleep(100 + random.nextInt(500)) val record = new ProducerRecord[String, String]("iotTopic", deviceJson) producer.send(record) } // 关闭连接 producer.close() } /** * 物联网设备发送状态数据 */ case class DeviceData( device: String, //设备标识符ID deviceType: String, //设备类型,如服务器mysql, redis, kafka或路由器route signal: Double, //设备信号 time: Long //发送数据时间 ) }
启动Demo10_Kafka_IOT
package cn.itcast.structured import org.apache.commons.lang3.StringUtils import org.apache.spark.SparkContext import org.apache.spark.sql.streaming.Trigger import org.apache.spark.sql.types.DoubleType import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * Author itcast * Desc 演示StructuredStreaming整合Kafka, * 从iotTopic消费数据 -->使用StructuredStreaming进行实时分析-->将结果写到控制台 */ object Demo10_Kafka_IOT { def main(args: Array[String]): Unit = { //TODO 0.创建环境 //因为StructuredStreaming基于SparkSQL的且编程API/数据抽象是DataFrame/DataSet,所以这里创建SparkSession即可 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4") //本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ import org.apache.spark.sql.functions._ //TODO 1.加载数据-kafka-iotTopic val kafkaDF: DataFrame = spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "master:9092") .option("subscribe", "iotTopic") .load() val valueDS: Dataset[String] = kafkaDF.selectExpr("CAST(value AS STRING)").as[String] //{"device":"device_30","deviceType":"kafka","signal":77.0,"time":1610158709534} //TODO 2.处理数据 //需求:统计信号强度>30的各种设备类型对应的数量和平均信号强度 //解析json(也就是增加schema:字段名和类型) //方式1:fastJson/Gson等工具包,后续案例中使用 //方式2:使用SparkSQL的内置函数,当前案例使用 val schemaDF: DataFrame = valueDS.filter(StringUtils.isNotBlank(_)) .select( get_json_object($"value", "$.device").as("device_id"), get_json_object($"value", "$.deviceType").as("deviceType"), get_json_object($"value", "$.signal").cast(DoubleType).as("signal") ) //需求:统计信号强度>30的各种设备类型对应的数量和平均信号强度 //TODO ====SQL schemaDF.createOrReplaceTempView("t_iot") val sql: String = """ |select deviceType,count(*) as counts,avg(signal) as avgsignal |from t_iot |where signal > 30 |group by deviceType |""".stripMargin val result1: DataFrame = spark.sql(sql) //TODO ====DSL val result2: DataFrame = schemaDF.filter('signal > 30) .groupBy('deviceType) .agg( count('device_id) as "counts", avg('signal) as "avgsignal" ) //TODO 3.输出结果-控制台 result1.writeStream .format("console") .outputMode("complete") //.option("truncate", false) .start() //.awaitTermination() //TODO 4.启动并等待结束 result2.writeStream .format("console") .outputMode("complete") //.trigger(Trigger.ProcessingTime(0)) //.option("truncate", false) .start() .awaitTermination() //TODO 5.关闭资源 spark.stop() } } //0.kafka准备好 //1.启动数据模拟程序 //2.启动Demo10_Kafka_IOT
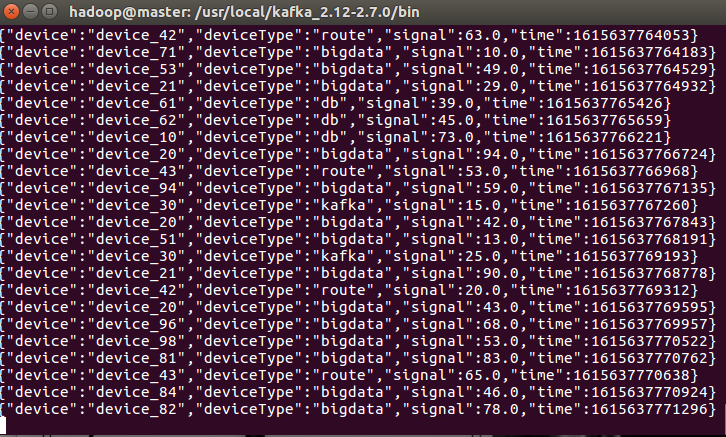

直接把结果输出到控制台。