



说明:

[ { "name": "jack", "tel": "1388888888", }, { "name": "jack", "tel": 13888888888, "age":18 }, { "name": "jack", "tel": "1388888888", "age": "18" } ]
-
非结构数据--需要处理之后变为结构化/半结构化才支持
如视频/图片/音频...
SparkCore的数据抽象:RDD
SparkStreaming的数据抽象:DStream,底层是RDD
SparkSQL的数据抽象:DataFrame和DataSet,底层是RDD

DataFrame = RDD - 泛型 + Schema约束(指定了字段名和类型) + SQL操作 + 优化
DataFrame 就是在RDD的基础之上做了进一步的封装,支持SQL操作!
DataFrame 就是一个分布式表!
DataSet = DataFrame + 泛型
DataSet = RDD + Schema约束(指定了字段名和类型) + SQL操作 + 优化
DataSet 就是在RDD的基础之上做了进一步的封装,支持SQL操作!
DataSet 就是一个分布式表!
package cn.itcast.sql import org.apache.spark.SparkContext import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * Author itcast * Desc 演示SparkSQL初体验 */ object Demo01 { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") //TODO 1.加载数据 val df1: DataFrame = spark.read.text("data/input/text") val df2: DataFrame = spark.read.json("data/input/json") val df3: DataFrame = spark.read.csv("data/input/csv") //TODO 2.处理数据 //TODO 3.输出结果 df1.printSchema() df2.printSchema() df3.printSchema() df1.show() df2.show() df3.show() //TODO 4.关闭资源 spark.stop() } }

package cn.itcast.sql import org.apache.spark import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} /** * Author itcast * Desc 演示SparkSQL-RDD2DataFrame */ object Demo02_RDD2DataFrame1 { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") //TODO 1.加载数据 val lines: RDD[String] = sc.textFile("data/input/person.txt") //TODO 2.处理数据 val personRDD: RDD[Person] = lines.map(line => { val arr: Array[String] = line.split(" ") Person(arr(0).toInt, arr(1), arr(2).toInt) }) //RDD-->DF import spark.implicits._ val personDF: DataFrame = personRDD.toDF() //TODO 3.输出结果 personDF.printSchema() personDF.show() //TODO 4.关闭资源 spark.stop() } case class Person(id:Int,name:String,age:Int) }
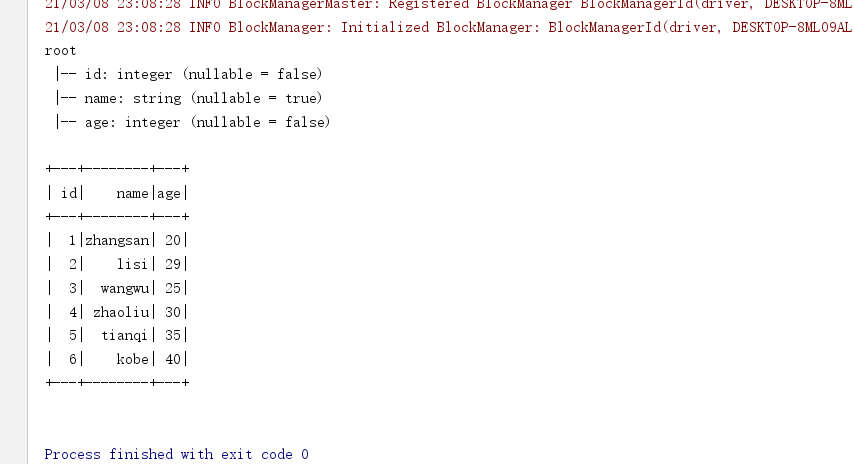
package cn.itcast.sql import cn.itcast.sql.Demo02_RDD2DataFrame1.Person import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} /** * Author itcast * Desc 演示SparkSQL-RDD2DataFrame-指定类型和列名(当数据少的时候使用) */ object Demo02_RDD2DataFrame2 { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") //TODO 1.加载数据 val lines: RDD[String] = sc.textFile("data/input/person.txt") //TODO 2.处理数据 val tupleRDD: RDD[(Int, String, Int)] = lines.map(line => { val arr: Array[String] = line.split(" ") (arr(0).toInt, arr(1), arr(2).toInt) }) //RDD-->DF import spark.implicits._ val personDF: DataFrame = tupleRDD.toDF("id","name","age") //TODO 3.输出结果 personDF.printSchema() personDF.show() //TODO 4.关闭资源 spark.stop() } }
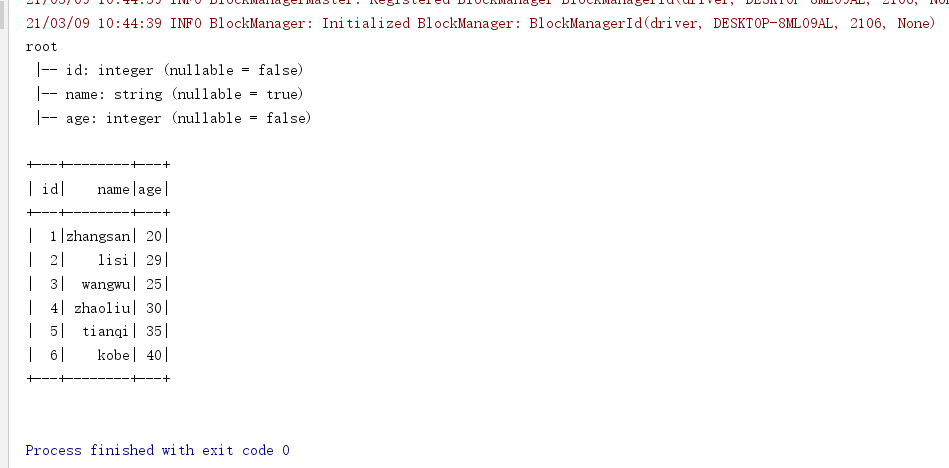
package cn.itcast.sql import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Row, SparkSession} /** * Author itcast * Desc 演示SparkSQL-RDD2DataFrame-自定义Schema */ object Demo02_RDD2DataFrame3 { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") //TODO 1.加载数据 val lines: RDD[String] = sc.textFile("data/input/person.txt") //TODO 2.处理数据 val rowRDD: RDD[Row] = lines.map(line => { val arr: Array[String] = line.split(" ") Row(arr(0).toInt, arr(1), arr(2).toInt) }) //RDD-->DF import spark.implicits._ /*val schema: StructType = StructType( StructField("id", IntegerType, false) :: StructField("name", StringType, false) :: StructField("age", IntegerType, false) :: Nil)*/ //相当于List集合 //自己指定列名和类型,用的较少 val schema: StructType = StructType(List( StructField("id", IntegerType, false), StructField("name", StringType, false), StructField("age", IntegerType, false) )) val personDF: DataFrame = spark.createDataFrame(rowRDD, schema) //TODO 3.输出结果 personDF.printSchema() personDF.show() //TODO 4.关闭资源 spark.stop() } }

多数据源:
读:spark.read.格式(路径) //底层 spark.read.format("格式").load(路径)
写:df.writer..格式(路径) //底层 df.writer.format("格式").save(路径)
package cn.itcast.sql import java.util.Properties import org.apache.spark.SparkContext import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession} /** * Author itcast * Desc 演示SparkSQL-支持的外部数据源 * 支持的文件格式:text/json/csv/parquet/orc.... * 支持文件系统/数据库 */ object Demo06_DataSource { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ //TODO 1.加载数据 val df: DataFrame = spark.read.json("data/input/json")//底层format("json").load(paths : _*) //val df: DataFrame = spark.read.csv("data/input/csv")//底层format("csv").load(paths : _*) df.printSchema() df.show() //TODO 2.处理数据 //TODO 3.输出结果 df.coalesce(1).write.mode(SaveMode.Overwrite).json("data/output/json")//底层 format("json").save(path) df.coalesce(1).write.mode(SaveMode.Overwrite).csv("data/output/csv") df.coalesce(1).write.mode(SaveMode.Overwrite).parquet("data/output/parquet") df.coalesce(1).write.mode(SaveMode.Overwrite).orc("data/output/orc") val prop = new Properties() prop.setProperty("user","root") prop.setProperty("password","123456") df.coalesce(1).write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","person",prop)//表会自动创建 //TODO 4.关闭资源 spark.stop() } }


需求: 加载文件中的数据并使用SparkSQL-UDF将数据转为大写
package cn.itcast.sql import org.apache.spark.SparkContext import org.apache.spark.sql.expressions.UserDefinedFunction import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * Author itcast * Desc 演示SparkSQL-使用SparkSQL-UDF将数据转为大写 */ object Demo08_UDF { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ //TODO 1.加载数据 val ds: Dataset[String] = spark.read.textFile("data/input/udf.txt") ds.printSchema() ds.show() /* +-----+ |value| +-----+ |hello| | haha| | hehe| | xixi| +-----` */ //TODO 2.处理数据 //需求:使用SparkSQL-UDF将数据转为大写 //TODO ======SQL //TODO 自定义UDF函数 spark.udf.register("small2big",(value:String)=>{ value.toUpperCase() }) ds.createOrReplaceTempView("t_word") val sql:String = """ |select value,small2big(value) as bigValue |from t_word |""".stripMargin spark.sql(sql).show() /* +-----+--------+ |value|bigValue| +-----+--------+ |hello| HELLO| | haha| HAHA| | hehe| HEHE| | xixi| XIXI| +-----+--------+ */ //TODO ======DSL //TODO 自定义UDF函数 import org.apache.spark.sql.functions._ val small2big2: UserDefinedFunction = udf((value:String)=>{ value.toUpperCase() }) ds.select('value,small2big2('value).as("bigValue")).show() /* +-----+--------+ |value|bigValue| +-----+--------+ |hello| HELLO| | haha| HAHA| | hehe| HEHE| | xixi| XIXI| +-----+--------+ */ //TODO 3.输出结果 //TODO 4.关闭资源 spark.stop() } }
