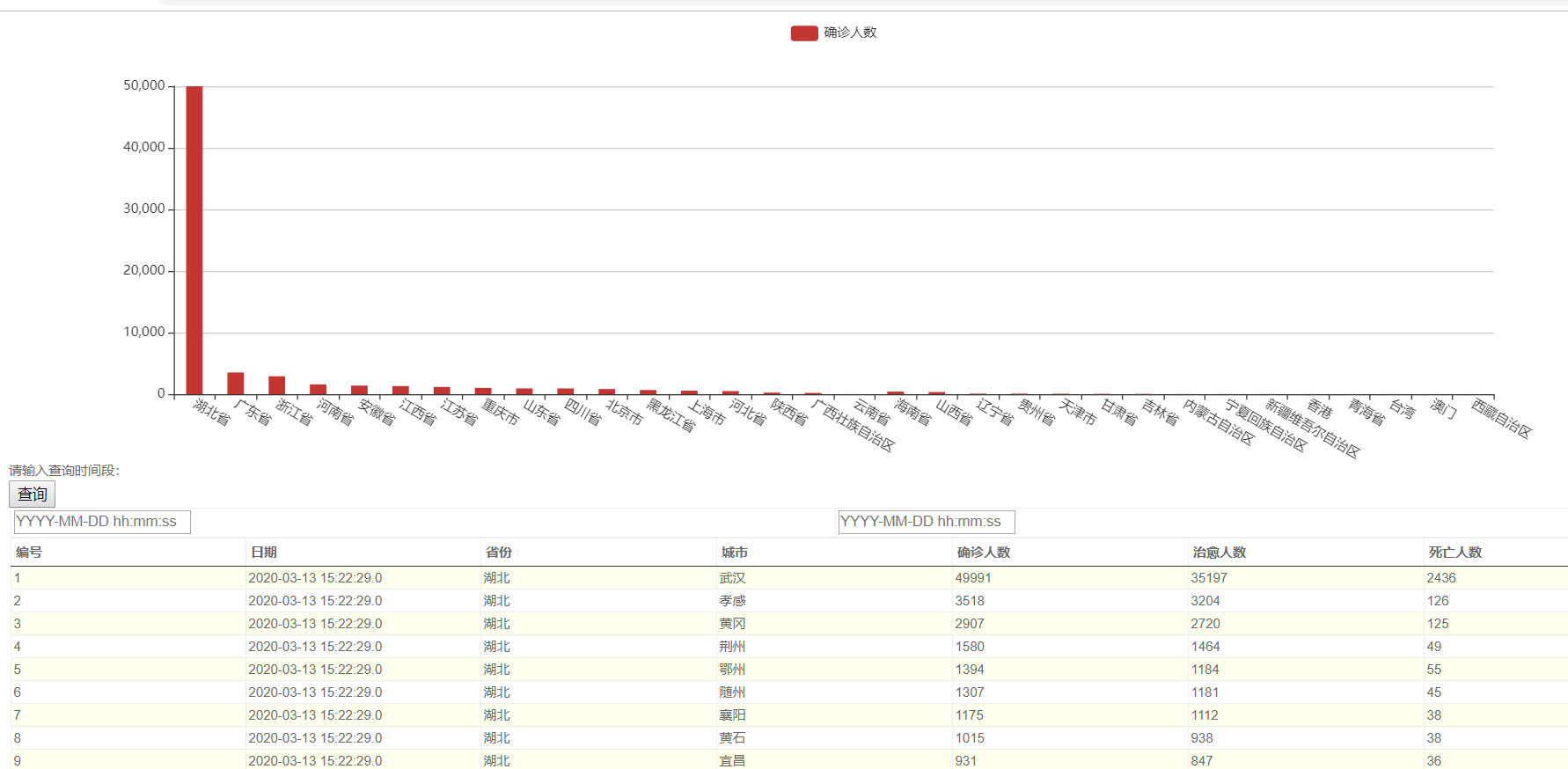
已部署到服务器:http://120.79.40.20/Payiqing/showservlet

项目计划总结表:
| 日期 | 编程 | 完善程序 | 测试程序 | 参考资料 | 日总结 |
| 3.10 | 16:00---17:30 | 1.5 | |||
| 3.11 | 9:00---11:30 | 14:00---17:30 | 19:00---21:00 | 1.5 | |
| 3.12 | 14:00---15:30 |
1.5 |
|||
| 3.13 | 9:00--9:30 |
时间记录总结:
| 日期 | 开始 | 结束 | 中断时间 | 净时间 | 活动 | 备注 |
| 3.10 | 16:00 | 17:00 | 无 | 1 | 编程 | |
| 3.11 | 9:00 | 11:30 | 无 | 2.5 | 修改与测试 | |
| 14:00 | 17:30 | 无 | 2.5 | 修改与测试 | ||
| 3.12 | 14:00 | 15:30 | 无 | 1.5 | 修改与测试 | |
| 3.13 | 8:30 | 9:35 | 无 | 1.05 | 修改与测试 |
缺陷记录表:
| 日期 | 编号 | 类型 | 引入 | 排除 | 修复 | 修复时间 |
| 3.10 | 1 | 程序 | 编程 | 编译 | python学习爬虫 | 1小时 |
| 3.11 | 2 | 程序 | 编程 | 编译 | url的测试 | 3小时 |
| 3.12 | 3 | 程序 | 编程 | 编译 | 获取数据不到 | 6小时 |
| 3.13 | 4 | 程序 | 编程 | 编译 | 获取数据过多 | 3小时 |
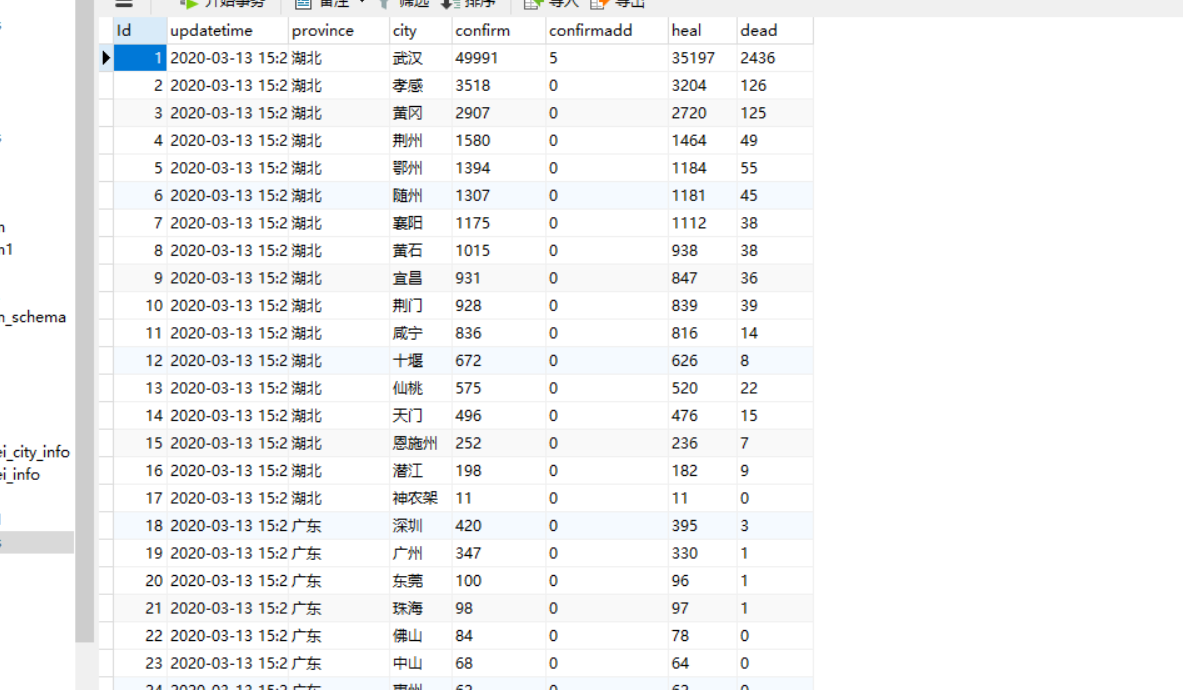
我使用的是python爬取的的疫情数据存到数据库中
import requests import json import pymysql url="https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5" headers ={ "user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Mobile Safari/537.36" } r=requests.get(url,headers) res=json.loads(r.text) #第一级转换 json 字符转换为字典 data_all =json.loads(res["data"]) details = [] update_time=data_all["lastUpdateTime"] data_country=data_all["areaTree"] #lsit集合 47 个国家 data_province =data_country[0]["children"] #中国各省 for pro_infos in data_province: province= pro_infos["name"] #省名 # print(province) for city_infos in pro_infos["children"]: city = city_infos["name"] confirm = city_infos["total"]["confirm"] confirm_add=city_infos["today"]["confirm"] heal= city_infos["total"]["heal"] dead=city_infos["total"]["dead"] details.append([update_time,province,city,confirm,confirm_add,heal,dead]) #建立连接 conn=pymysql.connect(host='127.0.0.1', user='root', password='101032', db='payiqing', ) cursor=conn.cursor() a=len(details) count =0 while count < a: #sql 语句与 eclipse 使用有所不同 sql="insert into info(Date,Province,City,Confirmed_num,confirmadd,Cured_num,Dead_num) values(%s,%s,%s,%s,%s,%s,%s)" try: cursor.executemany(sql,details) conn.commit() except: conn.rollback() count += 1 cursor.close() conn.close()