运行dialogflow_api_client.py
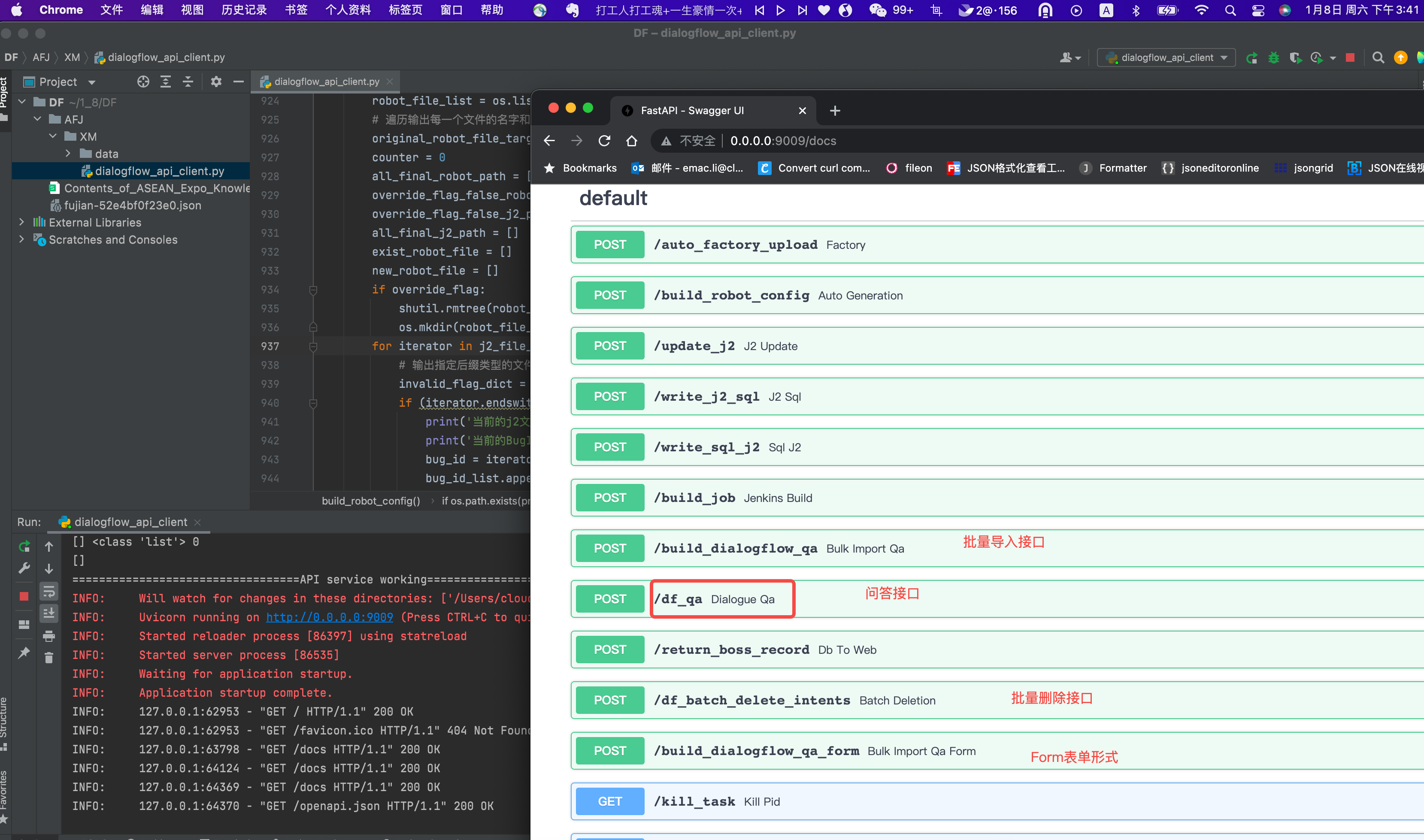
调用【问答】接口
http://0.0.0.0:9009/docs#/default/dialogue_qa_df_qa_post
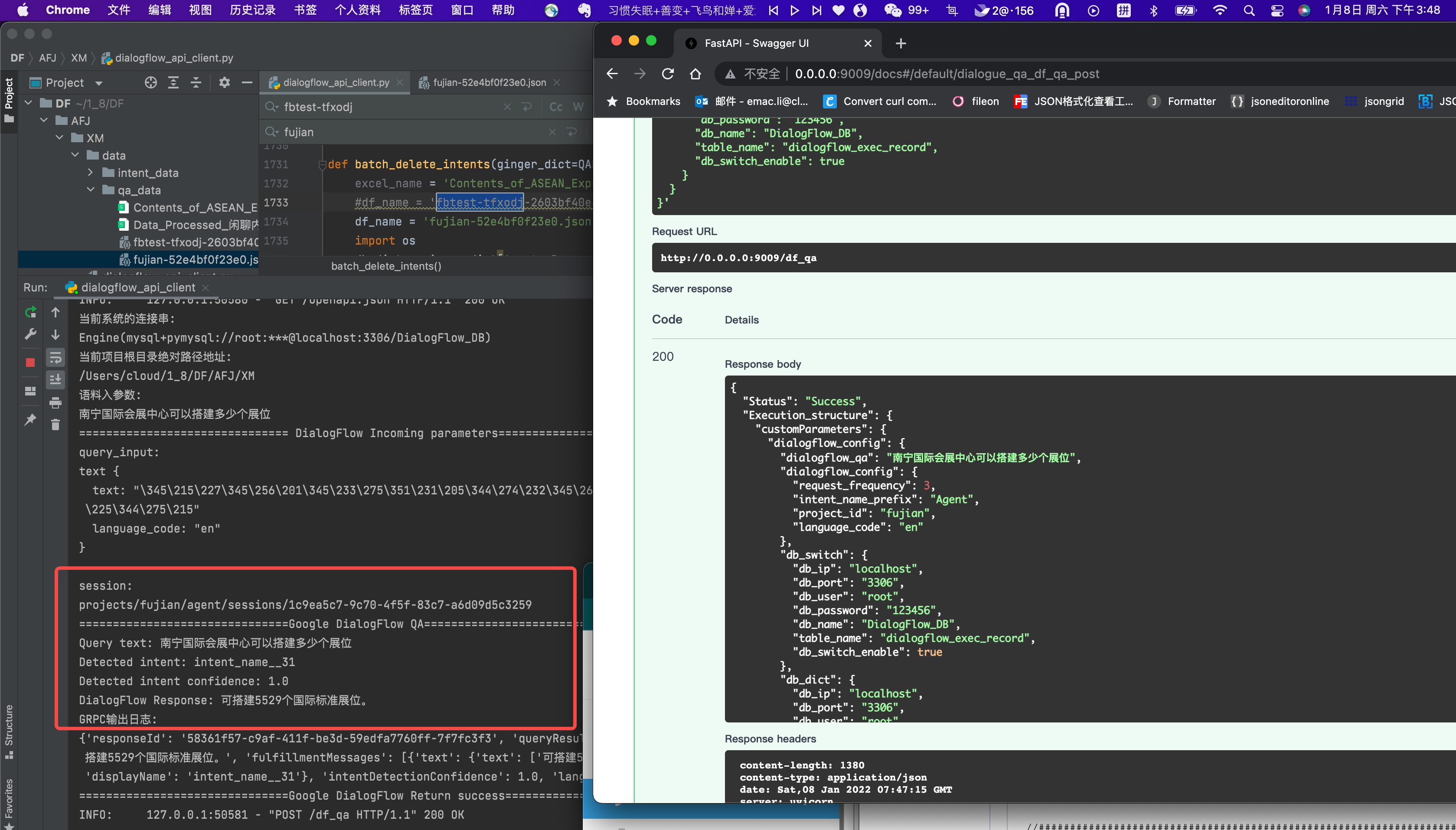
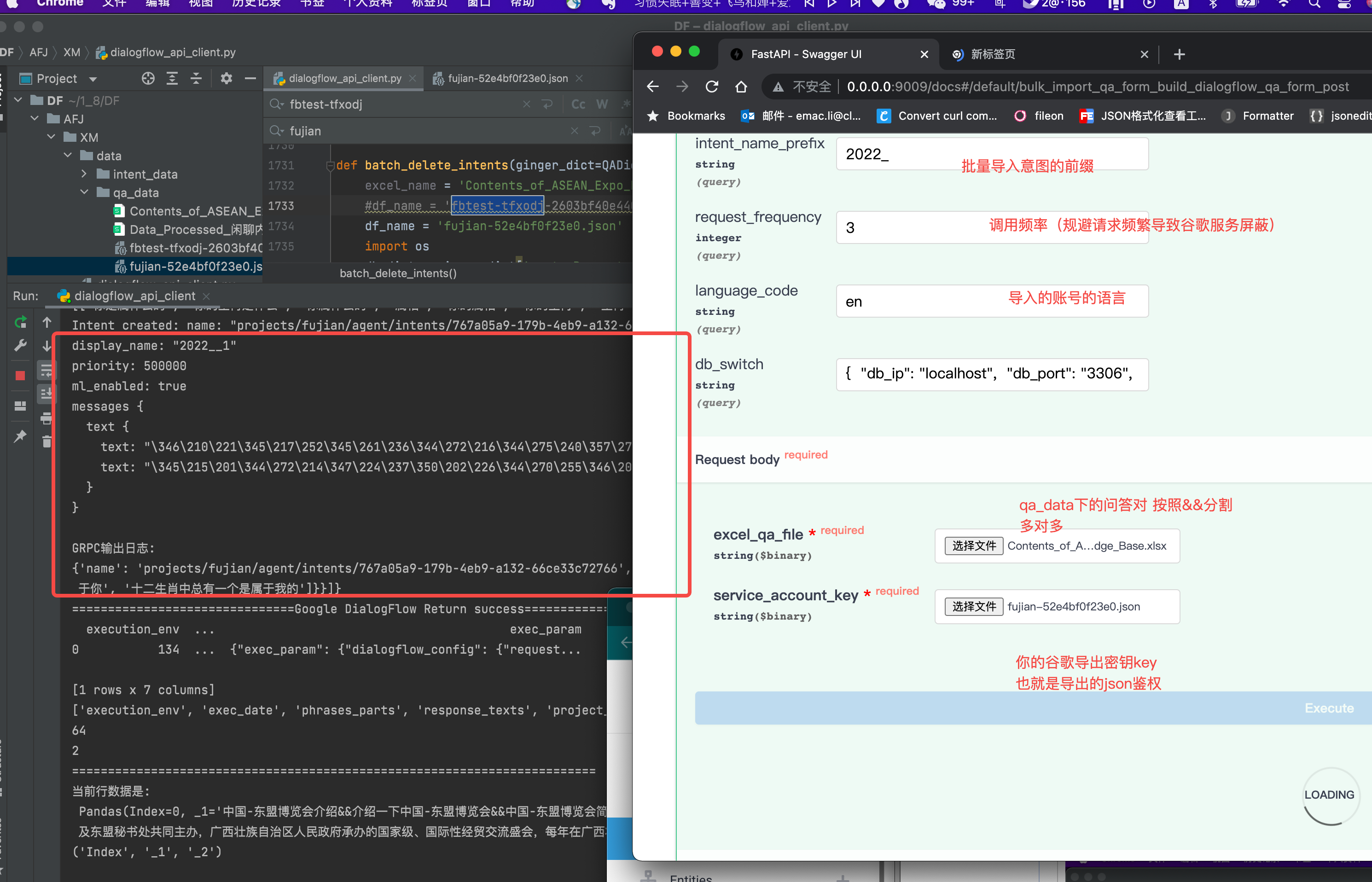
【批量问答对表格录入】
http://0.0.0.0:9009/docs#/default/bulk_import_qa_form_build_dialogflow_qa_form_post
//##################################################################################################################
//批量导入接口
//##################################################################################################################
【1】定义DialogFlow 批量导入接口入参
class DialogFlowDict(BaseModel): customParameters: dict = { "dialogflow_config": { "request_frequency": 3, "intent_name_prefix": "Agent", "project_id": "fbtest-tfxodj", "language_code": "en", } }
request_frequency 请求频率
intent_name_prefix 批量导入的问答前缀
project_id 谷歌json文件项目ID

language_code 导入谷歌项目的语言偏好设置
参考:
text_input = dialogflow.types.TextInput(text=dialogflow_qa, language_code=language_code)
query_input = dialogflow.types.QueryInput(text=text_input)
【2】批量导入接口
@app.post("/build_dialogflow_qa") async def bulk_import_qa(struct_iterator: DialogFlowDict): db_dict = { 'db_ip': 'localhost', 'db_port': '3306', 'db_user': 'root', 'db_password': '123456', 'db_name': 'DialogFlow_DB', 'table_name': 'dialogflow_exec_record', } struct_iterator.customParameters['db_dict'] = db_dict env_status = dialogflow_qa(ginger_dict=struct_iterator.dict()) if env_status and len(env_status) == 3: call_back = { "Status": env_status[0], "Execution_structure": env_status[1], "Message": env_status[2] } return call_back else: return env_status
【3】
定义批量导入问答接口实体函数
def dialogflow_qa(ginger_dict=DialogFlowDict): excel_name = 'Contents_of_ASEAN_Expo_Knowledge_Base.xlsx' #df_name = 'fbtest-tfxodj-2603bf40e440.json' df_name = 'fujian-52e4bf0f23e0.json' import os import datetime db_dict = ginger_dict['customParameters']['db_dict'] if 'db_dict' in ginger_dict['customParameters'] else None if isinstance(db_dict, dict) and db_dict.keys() > {'db_ip', 'db_port', 'db_user', 'db_password', 'db_name'}: engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(db_dict['db_user'], db_dict['db_password'], db_dict['db_ip'], db_dict['db_port'], db_dict['db_name'])) print('当前系统的连接串:\n{}'.format(engine, db_dict)) else: print('当前系统的连接串不满足参数要求') ginger_dict = ginger_dict['customParameters'] dialogflow_config = ginger_dict['dialogflow_config'] if 'dialogflow_config' in ginger_dict else None intent_name_prefix = dialogflow_config['intent_name_prefix'] if 'intent_name_prefix' in dialogflow_config else 'Default_' project_id = dialogflow_config['project_id'] if 'project_id' in dialogflow_config else None request_frequency = dialogflow_config['request_frequency'] if 'request_frequency' in dialogflow_config else 5 language_code = dialogflow_config['language_code'] if 'language_code' in dialogflow_config else 'en' project_path = os.path.abspath(os.path.join(os.getcwd())) print('当前项目根目录绝对路径地址:\n{}'.format(project_path)) excel_path = project_path + os.sep + 'data' + os.sep + 'qa_data' + os.sep + excel_name df_json_path = project_path + os.sep + 'data' + os.sep + 'qa_data' + os.sep + df_name conf_param_list = dict() if request_frequency and isinstance(intent_name_prefix, str) and isinstance(project_id, str) and excel_name and os.path.exists(excel_path) and os.path.exists(df_json_path): try: all_sheet_names_pd = pd.ExcelFile(excel_path) all_sheet_names = all_sheet_names_pd.sheet_names print('所有表格名称:\n{}'.format(all_sheet_names)) response_list = [] id = 0 for sn in all_sheet_names: handle_excel_path = project_path + os.sep + 'data' + os.sep + 'qa_data' + os.sep + 'Data_Processed_{}.xlsx'.format(sn) df_env = pd.read_excel(all_sheet_names_pd, sn, engine='openpyxl') # df_env = pd.read_excel(excel_path, sheet_name=0, engine='openpyxl') nrows = df_env.shape[0] ncols = df_env.columns.size print(nrows) print(ncols) print("=========================================================================") df_env = df_env.replace(np.nan, '') df_env = trim_columns(df_env) if isinstance(df_env, pd.DataFrame): # print(df_env.columns.tolist()) question_list = [] answer_list = [] for item in df_env.itertuples(): print('当前行数据是:\n', item) print(item._fields) print('\n获取行索引: ', item.Index) print('\n获取该行的x4值: ', item) phrases_parts = str(item[1]).replace('&&', ',').split(',') response_texts = str(item[2]).replace('&&', ',').split(',') phrases_parts = [x.encode('utf-8').decode('utf-8') for x in phrases_parts] response_texts = [y.encode('utf-8').decode('utf-8') for y in response_texts] question_list.append(phrases_parts) answer_list.append(response_texts) print('=====================================Single line==================================') print('问题:\n{}\n回复:\n{}'.format(question_list, answer_list)) print('=====================================All line==================================') print('问题:\n{}\n回复:\n{}'.format(question_list, answer_list)) # phrases_parts = ['你在哪边上班', '上班地点', '去哪上班'] # rsp = ['我在望京上班', '我在厦门上班', '我在福州上班', '我在房山上班'] # project_id = 'fbtest-tfxodj' print(question_list) print(answer_list) pd.DataFrame({'question_list': question_list, 'answer_list': answer_list}).to_excel(handle_excel_path) combine_list = pd.DataFrame({'question_list': question_list, 'answer_list': answer_list}).values.tolist() def create_intent(project_id, intent_name, phrases_parts, response_texts, language_code): intents_client = dialogflow_v2beta1.IntentsClient.from_service_account_json(df_json_path) parent = intents_client.project_agent_path(project_id) training_phrases = [] for training_phrases_part in phrases_parts: part = dialogflow_v2beta1.types.Intent.TrainingPhrase.Part(text=training_phrases_part) training_phrase = dialogflow_v2beta1.types.Intent.TrainingPhrase(parts=[part]) training_phrases.append(training_phrase) text = dialogflow_v2beta1.types.Intent.Message.Text(text=response_texts) message = dialogflow_v2beta1.types.Intent.Message(text=text) intent = dialogflow_v2beta1.types.Intent( display_name=intent_name, training_phrases=training_phrases, messages=[message]) response = intents_client.create_intent(parent, intent,language_code=language_code) print('Intent created: {}'.format(response)) if isinstance(request_frequency, int): time.sleep(request_frequency) else: time.sleep(5) rsp = MessageToDict(response) print('GRPC输出日志:\n{}'.format(rsp)) print('===============================Google DialogFlow Return success==================================') return rsp for idx in combine_list: id = id + 1 print(idx) response = create_intent(project_id, '{}_{}'.format(intent_name_prefix, id), idx[0], idx[1],language_code) project_url = str('https://dialogflow.cloud.google.com/#/' + response['name'].replace('agent/','').replace('projects','agent').replace('intents','editIntent') + '/') # hyper_link = '<a href="{}"></a>'.format(project_url) response_list.append(response) exec_param = dict() exec_param['exec_param'] = {'dialogflow_config': dialogflow_config, 'runtime_param': {'ID': id, 'phrases_parts': idx[0], 'response_texts': idx[1]}} df_exec_iterator = { "exec_date": str(datetime.datetime.now()), "phrases_parts": '&&'.join(idx[0]), "response_texts": '&&'.join(idx[1]), "exec_callback": json.dumps(response, ensure_ascii=False), "project_url": str(project_url), "execution_env": "134", "table_name": db_dict['table_name'], "exec_param": json.dumps(exec_param, ensure_ascii=False), } df_to_sql(engine, df_exec_iterator) else: env_status = ['Failure', conf_param_list, '执行失败,当前表格内容不合法'] return env_status conf_param_list['all_sheet_names'] = {'遍历表格名称': all_sheet_names} conf_param_list['DialogFlowResponse'] = {'dialogflow返回值': response_list} conf_param_list['customParameters'] = {'dialogflow_config': dialogflow_config} conf_param_list['QAParameters'] = {'问题': question_list, '回复': answer_list} env_status = ['Success', conf_param_list, '执行成功,回调信息\n{}'.format(json.dumps(dialogflow_config, ensure_ascii=False))] return env_status except Exception as e: env_status = ['Failure', conf_param_list, '执行失败,回调信息\n{}'.format(e)] return env_status else: return_msg = '入参条件不符合预期: excel_path\n{}\nintent_name_prefix:\n{}\nproject_id:\n{}\ndf_json_path:\n{}'.format(excel_path, intent_name_prefix,project_id, df_json_path) print(return_msg) return return_msg
//##################################################################################################################
//批量删除DialogFlow问答
//##################################################################################################################
【1】定义问答批量删除接口入参
class DFDict(BaseModel): customParameters: dict = { "df_action": {"batch_deletion": True, "Single_deletion": False}, "dialogflow_config": { "request_frequency": 3, "intent_name_prefix": "意图前缀", "project_id": "fujian", "language_code": "en", }, "db_switch": { "db_ip": "localhost", "db_port": "3306", "db_user": "root", "db_password": "123456", "db_name": "DialogFlow_DB", "table_name": "batch_exec_record", "db_switch_enable": True } }
【2】定义问答批量删除接口
@app.post("/df_batch_delete_intents") async def batch_deletion(struct_iterator: DFDict): db_switch = struct_iterator.customParameters['db_switch'] if isinstance(db_switch, dict) and isinstance(db_switch['db_switch_enable'], bool) and not db_switch['db_switch_enable']: print('db_switch参数:\n{}'.format(db_switch)) db_dict = { 'db_ip': 'localhost', 'db_port': '3306', 'db_user': 'root', 'db_password': '123456', 'db_name': 'DialogFlow_DB', 'table_name': 'qa_exec_record', } db_switch = db_dict else: db_dict = db_switch struct_iterator.customParameters['db_dict'] = db_dict env_status = batch_delete_intents(ginger_dict=struct_iterator.dict()) if env_status and len(env_status) == 3: call_back = { "Status": env_status[0], "Execution_structure": env_status[1], "Message": env_status[2] } return call_back else: return env_status
【3】
问答批量删除接口实体函数
def batch_delete_intents(ginger_dict=QADict):
excel_name = 'Contents_of_ASEAN_Expo_Knowledge_Base.xlsx'
#df_name = 'fbtest-tfxodj-2603bf40e440.json'
df_name = 'fujian-52e4bf0f23e0.json'
import os
db_dict = ginger_dict['customParameters']['db_dict'] if 'db_dict' in ginger_dict['customParameters'] else None
if isinstance(db_dict, dict) and db_dict.keys() >= {'db_ip', 'db_port', 'db_user', 'db_password', 'db_name'}:
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(db_dict['db_user'], db_dict['db_password'], db_dict['db_ip'], db_dict['db_port'], db_dict['db_name']))
print('当前系统的连接串:\n{}'.format(engine, db_dict))
else:
print('当前系统的连接串不满足参数要求')
ginger_dict = ginger_dict['customParameters']
dialogflow_config = ginger_dict['dialogflow_config'] if 'dialogflow_config' in ginger_dict else None
project_id = dialogflow_config['project_id'] if 'project_id' in dialogflow_config else None
dialogflow_qa = ginger_dict['dialogflow_qa'] if 'dialogflow_qa' in ginger_dict else None
project_path = os.path.abspath(os.path.join(os.getcwd()))
print('当前项目根目录绝对路径地址:\n{}'.format(project_path))
df_json_path = project_path + os.sep + 'data' + os.sep + 'qa_data' + os.sep + df_name
conf_param_list = dict()
if isinstance(project_id, str) and os.path.exists(df_json_path):
try:
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = (df_json_path)
intents_client = dialogflow_v2beta1.IntentsClient.from_service_account_json(df_json_path)
parent = intents_client.project_agent_path(project_id)
intents_to_delete = []
display_name_list = []
question_list = []
rsp_list = []
df_qa_url_list = []
intents = intents_client.list_intents(parent)
for intent in intents:
intent = intents_client.get_intent(intent.name, intent_view=dialogflow.enums.IntentView.INTENT_VIEW_FULL)
question = MessageToDict(intents_client.get_intent(intent.name, intent_view=dialogflow.enums.IntentView.INTENT_VIEW_FULL))['trainingPhrases']
answer = MessageToDict(intent)['messages'][0]['text']
print(intent.name)
print(intent.display_name)
question_list.append(question[0]['parts'][0]['text'])
rsp_list.append(answer['text'][0])
df_qa_url_list.append(str('https://dialogflow.cloud.google.com/#/' + MessageToDict(intent)['name'].replace('agent/','').replace('projects','agent').replace('intents','editIntent') + '/'))
display_name_list.append(intent.display_name)
if intent.display_name:
intents_to_delete.append(intent)
if intents_to_delete !=[]:
rsp = MessageToDict(intents_client.batch_delete_intents(parent, intents_to_delete).operation)
print(rsp)
else:
rsp = []
# qa_to_sql(engine, qa_exec_iterator)
conf_param_list['customParameters'] = {'dialogflow_config': dialogflow_config}
conf_param_list['QAParameters'] = {'问题': question_list, '回复': rsp_list}
exec_param = dict()
exec_param['exec_param'] = {
'dialogflow_config': dialogflow_config,
'runtime_param': {'phrases_parts': '', 'response_texts': ''}
}
qa_exec_iterator = {
"exec_date": str(datetime.datetime.now()),
"direct_url_qa": str('&&'.join(df_qa_url_list)),
"phrases_parts": str('&&'.join(question_list)),
"response_texts": str('&&'.join(rsp_list)),
"exec_callback": json.dumps(rsp,ensure_ascii=False),
"execution_env": "134",
"table_name": db_dict['table_name'],
"exec_param": json.dumps(exec_param, ensure_ascii=False),
}
qa_to_sql(engine, qa_exec_iterator)
env_status = ['Success', conf_param_list, '执行成功,回调信息\n{}'.format(json.dumps(ginger_dict, ensure_ascii=False))]
return env_status
except Exception as e:
env_status = ['Failure', conf_param_list, '执行失败,回调信息\n{}'.format(e)]
return env_status
else:
return_msg = '入参条件不符合预期:\nproject_id:\n{}\ndf_json_path:\n{}'.format(project_id, df_json_path)
print(return_msg)
return return_msg
//##################################################################################################################
//问答接口
//##################################################################################################################
【1】定义问答接口入参
class QADict(BaseModel): customParameters: dict = { "dialogflow_qa": '南宁国际会展中心可以搭建多少个展位', "dialogflow_config": { "request_frequency": 3, "intent_name_prefix": "Agent", "project_id": "fbtest-tfxodj", "language_code": "en", }, "db_switch": { "db_ip": "localhost", "db_port": "3306", "db_user": "root", "db_password": "123456", "db_name": "DialogFlow_DB", "table_name": "dialogflow_exec_record", "db_switch_enable": True } }
【2】定义问答接口
@app.post("/df_qa") async def dialogue_qa(struct_iterator: QADict): db_switch = struct_iterator.customParameters['db_switch'] if isinstance(db_switch, dict) and isinstance(db_switch['db_switch_enable'], bool) and not db_switch['db_switch_enable']: print('db_switch参数:\n{}'.format(db_switch)) db_dict = { 'db_ip': 'localhost', 'db_port': '3306', 'db_user': 'root', 'db_password': '123456', 'db_name': 'DialogFlow_DB', 'table_name': 'qa_exec_record', } db_switch = db_dict else: db_dict = db_switch struct_iterator.customParameters['db_dict'] = db_dict env_status = df_qa(ginger_dict=struct_iterator.dict()) if env_status and len(env_status) == 3: call_back = { "Status": env_status[0], "Execution_structure": env_status[1], "Message": env_status[2] } return call_back else: return env_status
【3】
定义问答接口实体函数
def df_qa(ginger_dict=QADict): excel_name = 'Contents_of_ASEAN_Expo_Knowledge_Base.xlsx' # df_name = 'fbtest-tfxodj-2603bf40e440.json' df_name = 'fujian-52e4bf0f23e0.json' import os db_dict = ginger_dict['customParameters']['db_dict'] if 'db_dict' in ginger_dict['customParameters'] else None if isinstance(db_dict, dict) and db_dict.keys() >= {'db_ip', 'db_port', 'db_user', 'db_password', 'db_name'}: engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}'.format(db_dict['db_user'], db_dict['db_password'], db_dict['db_ip'], db_dict['db_port'], db_dict['db_name'])) print('当前系统的连接串:\n{}'.format(engine, db_dict)) else: print('当前系统的连接串不满足参数要求') ginger_dict = ginger_dict['customParameters'] dialogflow_config = ginger_dict['dialogflow_config'] if 'dialogflow_config' in ginger_dict else None project_id = dialogflow_config['project_id'] if 'project_id' in dialogflow_config else None dialogflow_qa = ginger_dict['dialogflow_qa'] if 'dialogflow_qa' in ginger_dict else None request_frequency = dialogflow_config['request_frequency'] if 'request_frequency' in dialogflow_config else 5 language_code = dialogflow_config['language_code'] if 'language_code' in dialogflow_config else 'en' project_path = os.path.abspath(os.path.join(os.getcwd())) print('当前项目根目录绝对路径地址:\n{}'.format(project_path)) df_json_path = project_path + os.sep + 'data' + os.sep + 'qa_data' + os.sep + df_name conf_param_list = dict() if request_frequency and isinstance(project_id, str) and excel_name and os.path.exists(df_json_path): try: os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = (df_json_path) # DIALOGFLOW_PROJECT_ID = 'fbtest-tfxodj' # DIALOGFLOW_LANGUAGE_CODE = 'en' SESSION_ID = str(uuid.uuid4()) # text_to_be_analyzed = "南宁国际会展中心可以搭建多少个展位" print('语料入参数:\n{}'.format(dialogflow_qa)) session_client = dialogflow.SessionsClient() session = session_client.session_path(project_id, SESSION_ID) text_input = dialogflow.types.TextInput(text=dialogflow_qa, language_code=language_code) query_input = dialogflow.types.QueryInput(text=text_input) try: print('=============================== DialogFlow Incoming parameters==================================') print('query_input:\n{}'.format(query_input)) print('session:\n{}'.format(session)) print('===============================Google DialogFlow QA==================================') response = session_client.detect_intent(session=session, query_input=query_input) except InvalidArgument: raise print("Query text:", response.query_result.query_text) print("Detected intent:", response.query_result.intent.display_name) print("Detected intent confidence:", response.query_result.intent_detection_confidence) print("DialogFlow Response:", response.query_result.fulfillment_text) rsp = MessageToDict(response) print('GRPC输出日志:\n{}'.format(rsp)) print('===============================Google DialogFlow Return success==================================') conf_param_list['customParameters'] = {'dialogflow_config': ginger_dict} conf_param_list['QAParameters'] = {'问题': dialogflow_qa, '回复': rsp} exec_param = dict() exec_param['exec_param'] = { 'dialogflow_config': dialogflow_config, 'runtime_param': {'phrases_parts': dialogflow_qa, 'response_texts': rsp} } import datetime qa_exec_iterator = { "exec_date": str(datetime.datetime.now()), "direct_url_qa": str('https://dialogflow.cloud.google.com/#/' + rsp['queryResult']['intent']['name'].replace('agent/','').replace('projects','agent').replace('intents','editIntent') + '/'), "phrases_parts": str(dialogflow_qa), "response_texts": str(response.query_result.fulfillment_text), "exec_callback": json.dumps(rsp, ensure_ascii=False), "execution_env": "134", "table_name": db_dict['table_name'], "exec_param": json.dumps(exec_param, ensure_ascii=False), } qa_to_sql(engine, qa_exec_iterator) env_status = ['Success', conf_param_list, '执行成功,回调信息\n{}'.format(json.dumps(dialogflow_config, ensure_ascii=False))] return env_status except Exception as e: env_status = ['Failure', conf_param_list, '执行失败,回调信息\n{}'.format(e)] return env_status else: return_msg = '入参条件不符合预期:\nproject_id:\n{}\ndf_json_path:\n{}'.format(project_id, df_json_path) print(return_msg) return return_msg
【定义问答消息到mySQL】
def df_to_sql(engine, df_exec_iterator): try: conf_param_list = dict() conf_param_list['dialogflow_collection'] = df_exec_iterator if isinstance(df_exec_iterator, dict) and df_exec_iterator.keys() >= {'execution_env', 'exec_date', 'phrases_parts', 'response_texts', 'project_url', 'exec_callback', 'exec_param', 'table_name'}: df_sql = pd.DataFrame.from_dict(df_exec_iterator, orient='index').T dtypedict = { 'id': BigInteger(), 'execution_env': NVARCHAR(length=255), 'exec_date': NVARCHAR(length=255), 'phrases_parts': NVARCHAR(length=255), 'response_texts': NVARCHAR(length=255), 'project_url': NVARCHAR(length=255), 'exec_callback': NVARCHAR(length=255), 'exec_date': NVARCHAR(length=255), 'exec_param': NVARCHAR(length=255) } def trim_columns(df): trim = lambda x: x.strip() if isinstance(x, str) else x return df.applymap(trim) obj_columns = list(df_sql.select_dtypes(include=['object']).columns.values) df_sql[obj_columns] = df_sql[obj_columns].replace([None], '') df_sql[obj_columns] = df_sql[obj_columns].replace([{}], '') df_sql = trim_columns(df_sql) sort_columns = ['execution_env', 'exec_date', 'phrases_parts', 'response_texts', 'project_url', 'exec_callback', 'exec_param'] df_sql = df_sql[sort_columns] table_name = df_exec_iterator['table_name'] df_sql.to_sql(table_name, con=engine, if_exists='append', index=False) # with self.engine.connect() as con: # con.execute('ALTER TABLE {} ADD PRIMARY KEY (`{}`);'.format(table_name, 'Index')) print(df_sql) print(sort_columns) return_list = df_sql.to_json(orient="records", force_ascii=False) if isinstance(return_list, str): return_list = json.loads(return_list) return return_list, 'Success', 'DialogFlow日志执行[入库成功]' else: env_status = ['Failure', conf_param_list, '执行失败,当前表格内容不合法'] return env_status except Exception as e: email_status = ['Failure', 'DialogFlow日志入库失败,回调信息{}'.format(e)] return email_status
【定义QA到数据库】
def qa_to_sql(engine, qa_exec_iterator): try: conf_param_list = dict() conf_param_list['dialogflow_collection'] = qa_exec_iterator if isinstance(qa_exec_iterator, dict) and qa_exec_iterator.keys() >= {'execution_env', 'exec_date','direct_url_qa', 'phrases_parts', 'response_texts', 'exec_callback', 'exec_param', 'table_name'}: df_sql = pd.DataFrame.from_dict(qa_exec_iterator, orient='index').T def trim_columns(df): trim = lambda x: x.strip() if isinstance(x, str) else x return df.applymap(trim) obj_columns = list(df_sql.select_dtypes(include=['object']).columns.values) df_sql[obj_columns] = df_sql[obj_columns].replace([None], '') df_sql[obj_columns] = df_sql[obj_columns].replace([{}], '') df_sql = trim_columns(df_sql) sort_columns = ['execution_env', 'exec_date', 'direct_url_qa', 'phrases_parts', 'response_texts', 'exec_callback', 'exec_param'] df_sql = df_sql[sort_columns] table_name = qa_exec_iterator['table_name'] df_sql.to_sql(table_name, con=engine, if_exists='append', index=False) print(df_sql) print(sort_columns) return_list = df_sql.to_json(orient="records", force_ascii=False) if isinstance(return_list, str): return_list = json.loads(return_list) return return_list, 'Success', 'DialogFlow日志执行[入库成功]' else: env_status = ['Failure', conf_param_list, '执行失败,当前dialogflow返回内容不合法,提交数据库失败\n{}'.format(json.dumps(qa_exec_iterator, ensure_ascii=False))] return env_status except Exception as e: email_status = ['Failure', 'DialogFlow日志入库失败,回调信息{}'.format(e)] return email_status
谷歌配置文件操作步骤:
https://console.cloud.google.com/projectselector2/iam-admin/serviceaccounts?supportedpurview=project
创建后生成
权限设置
选配
进入密钥创建详情页
github地址源码:
https://github.com/Kitty2014/DialogFlowQA.git