
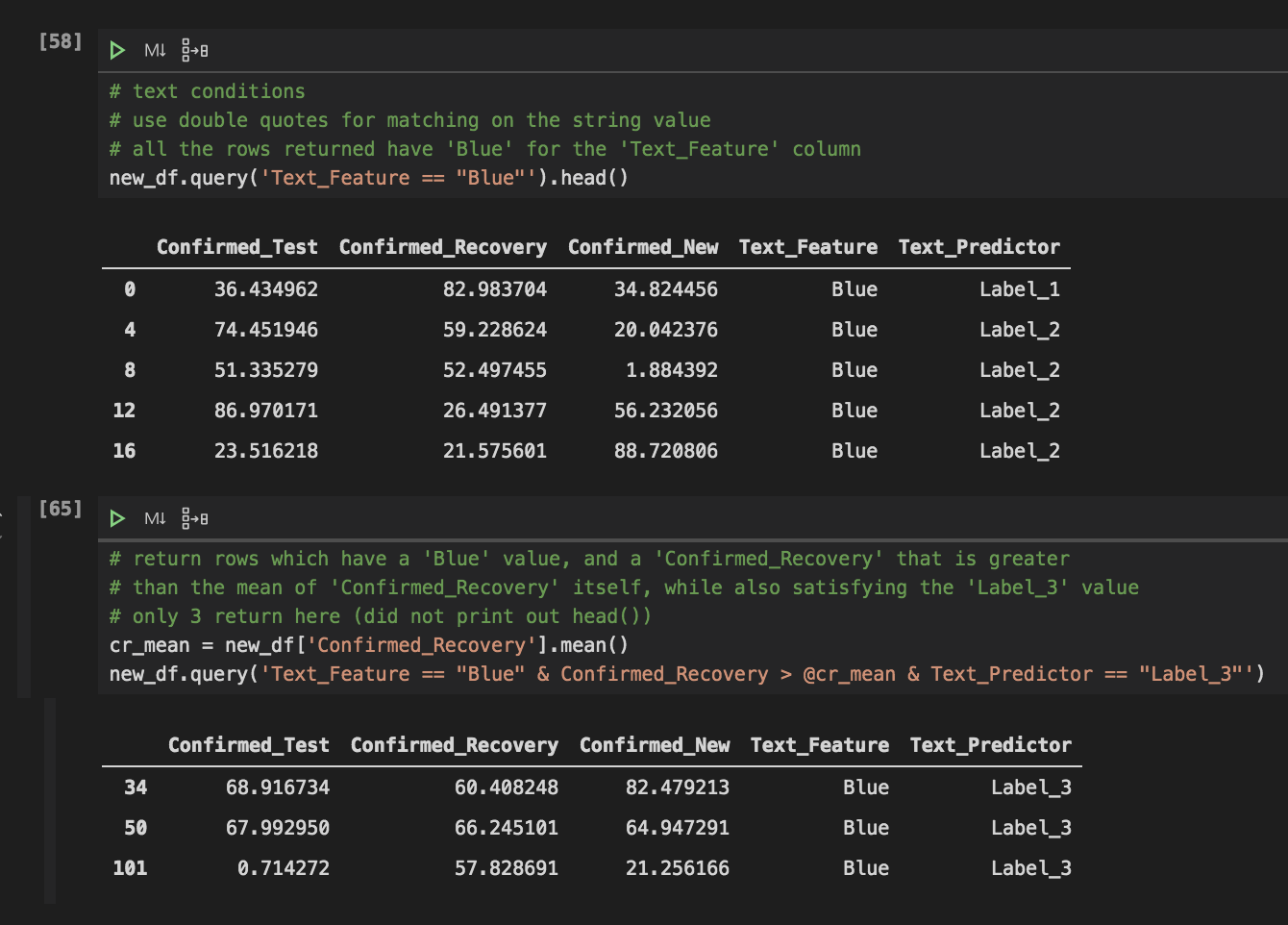
我已经编译了几个如何使用 pandas 查询函数的示例。下面的屏幕截图包含了带有查询的有用示例的摘要。下面,您可以看到如何同时满足文本和数字条件。查找特定列包含特定文本值的行,或使用“@”符号创建描述性统计数据。例如,'@mean_of_column'引用了您使用'.mean()'函数建立的值。在第65行,返回行了“蓝色”值和“Confirmed_Recovery”值比平均的更大的“Confirmed_Recovery”本身,同时还包括了“Label_3”值。

返回相等行以及其他几个条件的示例。作者 [3] 的截图。
灰色框中引用的教程代码是用于演示查询功能的所有代码。首先,我导入了熊猫并读取了我的数据框。然后,我添加我知道满足某些条件的新行,以显示如何使用查询函数。在“追加”功能是有用这里很好,因为它很快增加了新行数据帧,而无需显式调用了每一列,一旦在一系列格式。我返回了'df.tail()'以查看返回的行是否符合我的预期。
然后我返回行,其中一列的值等于另一列的值。您也可以使用相同的逻辑,但将其反转以查看您指定的列的哪些值彼此不相等。接下来,您可以比较一列的值是否大于另一列的值,反之亦然。
我相信,查询最有用的功能是“@”方法。就像 SQL 可以使用子查询来引用选择满足某些条件的行一样,这种方法也可以。在“@”方法保存要比较的值。对于下面的示例,我查看了要比较的一列的平均值。
最后,您可以使用查询函数通过输入类似于SQL中的“and”的“&”在一行代码中执行多个条件。
# All the python code below for use: # import library import pandas as pd # read in your dataframe df = pd.read_csv('/Users/example.csv') # write out new rows rows = [pd.Series([100, 100, 20,'Blue','Label_1'], index=df.columns), pd.Series([100, 80, 60,'Blue','Label_1'], index=df.columns), pd.Series([80, 60, 100,'Blue','Label_1'], index=df.columns)] # append the multiple rows 追加多行 new_df = df.append(rows , ignore_index=True) # check the newest 3 rows you made 检索创建的最新 3 行 new_df.tail(3) # return rows where values from one column equal that of another # they do not for this comparison new_df.query('Confirmed_Test == Confirmed_New') # return rows where values from one column equal that of another # they do for this comparison new_df.query('Confirmed_Test == Confirmed_Recovery') # return rows where values from one column do not equal that of another # they do for this comparison new_df.query('Confirmed_New != Confirmed_Recovery').head() # return rows where values from one column are bigger than that of another 返回一列值大于另一列值的行 new_df.query('Confirmed_New > Confirmed_Recovery').head() # see which rows where the 'Confirmed_New' values # are greater than the mean of the total column # use the '@' to reference 'cn_mean'
# 查看“Confirmed_New”值所在的行 # 大于总列的平均值 # 使用'@'来引用'cn_mean'
cn_mean = new_df['Confirmed_New'].mean() new_df.query('Confirmed_New > @cn_mean').head() # multiple conditions example cn_min = new_df['Confirmed_New'].min() cn_max = new_df['Confirmed_New'].max() new_df.query('Confirmed_New > @cn_min & Confirmed_New < @cn_max').head() # text conditions # use double quotes for matching on the string value # all the rows returned have 'Blue' for the 'Text_Feature' column new_df.query('Text_Feature == "Blue"').head() # return rows which have a 'Blue' value, and a 'Confirmed_Recovery' that is greater # than the mean of 'Confirmed_Recovery' itself, while also satisfying the 'Label_3' value # only 3 return here (did not print out head()) cr_mean = new_df['Confirmed_Recovery'].mean() new_df.query('Text_Feature == "Blue" & Confirmed_Recovery > @cr_mean & Text_Predictor == "Label_3"')