在这篇博客文章中,我将告诉你如何使用大熊猫选择的数据子集[ ],.loc,.iloc,.at,和.iat。我将使用UCI网站上托管的葡萄酒质量数据集。该数据记录了葡萄牙北部成千上万种红葡萄酒和白葡萄酒的11种化学特性(例如糖,柠檬酸,酒精,pH等的浓度)以及葡萄酒的质量,其等级从1开始到10。我们只会查看红酒的数据。
首先,我导入Pandas库,并将数据集读取到DataFrame中。

这是DataFrame的前5行:
wine_df.head()

我对列进行了重命名,以使其更容易调用列名称以用于将来的操作。
wine_df.columns = ['fixed_acidity', 'volatile_acidity', 'citric_acid', 'residual_sugar', 'chlorides', 'free_sulfur_dioxide', 'total_sulfur_dioxide','density','pH','sulphates', 'alcohol', 'quality' ]
选择列的不同方法
选择单列
要选择第一列“ fixed_acidity”,可以将列名称作为字符串传递给索引运算符。
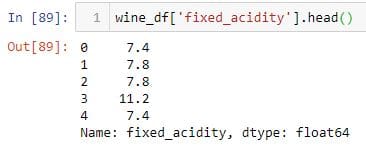
您可以使用点运算符执行相同的任务。

选择多列
要选择多个列,可以将列名称列表传递给索引运算符。
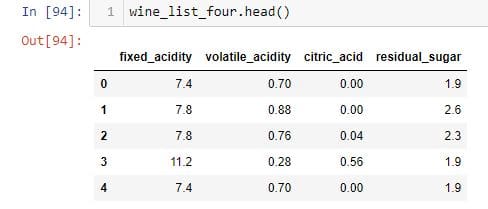
wine_four = wine_df[['fixed_acidity', 'volatile_acidity','citric_acid', 'residual_sugar']]
或者,您可以将所有列分配给一个列表变量,然后将该变量传递给索引运算符。
cols = ['fixed_acidity', 'volatile_acidity','citric_acid', 'residual_sugar']wine_list_four = wine_four[cols]
使用“ select_dtypes”和“ filter”方法选择列
要使用select_dtypes方法选择列 ,您应该首先找出每种数据类型的列数。
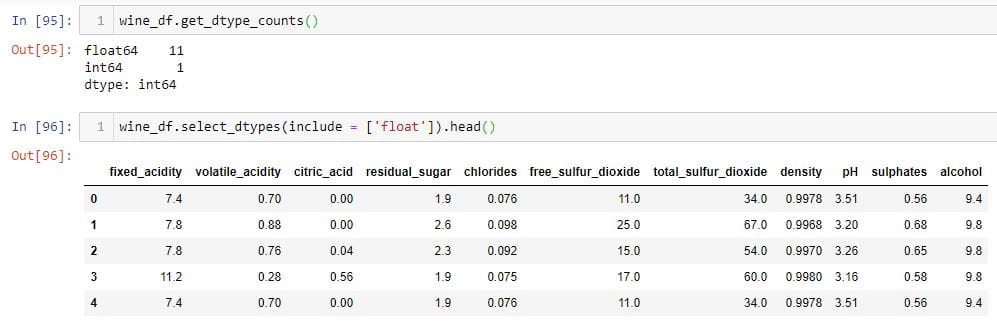
在此示例中,有11列是float列,而一列是整数。要仅选择浮点列,请使用 wine_df.select_dtypes(include = ['float'])。该select_dtypes方法在其include参数中接收数据类型列表。列表值可以是字符串或Python对象。
您还可以使用该filter方法根据列名或索引标签选择列。
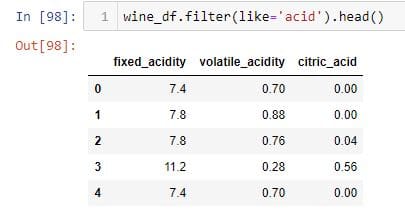
在上面的示例中,该filter方法返回包含确切字符串“ acid”的列。该like参数将字符串作为输入,并返回包含该字符串的列。
您可以regex在filter方法中使用带参数的正则表达式。
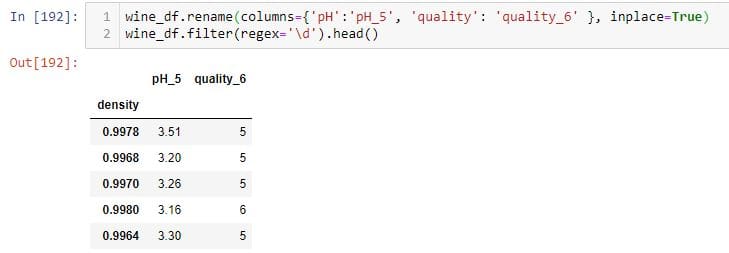
在这里,我首先重命名ph和quality列。然后,我将regex参数传递给该filter方法以查找所有具有数字的列。
更改列的顺序
我想更改列的顺序。

wine_df.columns显示所有列名称。我将列的名称组织为三个列表变量,然后将所有这些变量连接起来以获得最终的列顺序。
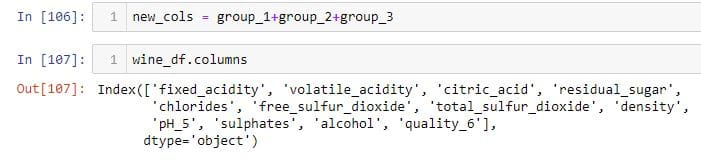
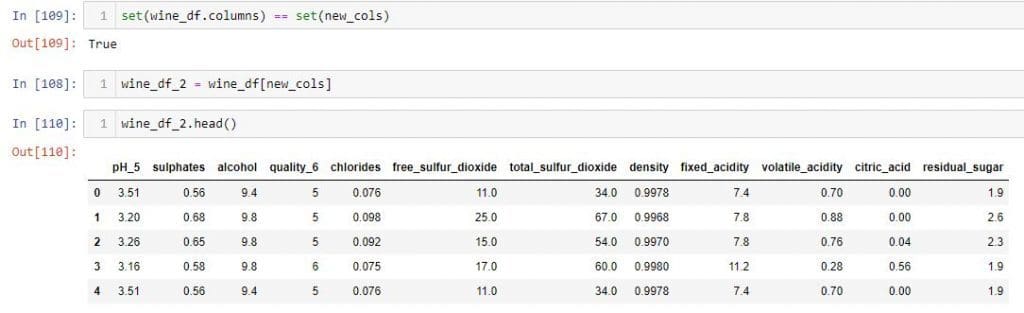
我使用Set模块来检查是否new_cols包含原始的所有列。
然后,将new_cols变量传递给索引运算符,并将结果DataFrame存储在变量中"wine_df_2" 。现在,wine_df_2 DataFrame具有我想要的顺序的列。
使用.iloc和loc选择行
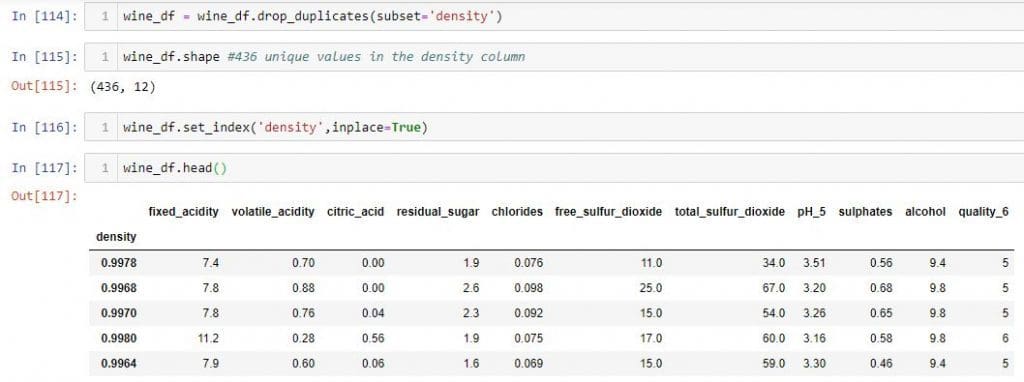
现在,让我们看看如何使用.iloc和loc从我们的DataFrame中选择行。为了更好地说明此概念,我从“密度”列中删除了所有重复的行,并将wine_df DataFrame的索引 更改为“密度”。
要选择wine_df DataFrame中的第三行,我将数字2传递给.iloc索引器。
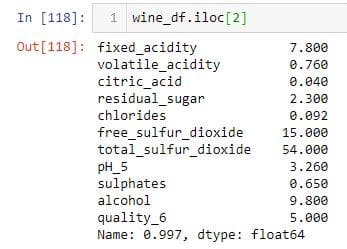
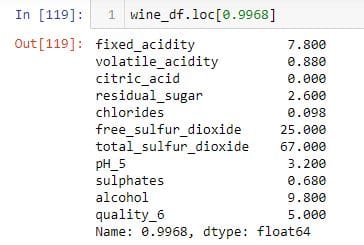
为了做同样的事情,我使用.loc索引器。
要选择具有不同索引位置的行,我将一个列表传递给.iloc索引器。

我将密度值列表传递给.iloc索引器,以重现上述DataFrame。

您可以使用切片来选择多行。这类似于在Python中切片列表。

上面的操作选择第2、3和4行。
您可以使用来执行相同的操作loc。
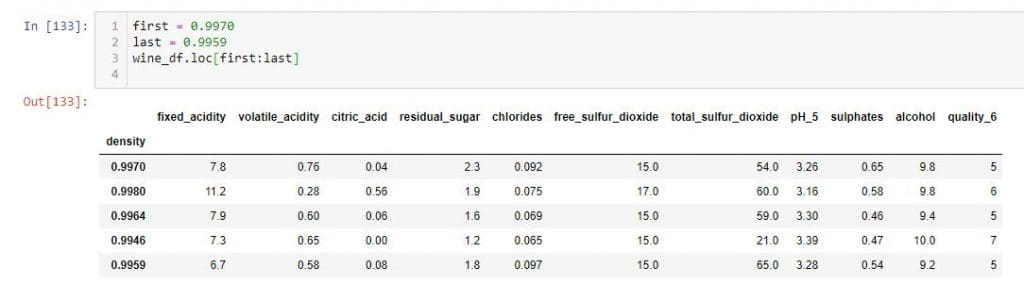
在这里,我正在选择索引0.9970 和0.9959之间的行。
同时选择行和列
您必须在.iloc和loc索引器中传递行和列的参数,才能同时选择行和列。行和列的值可以是标量值,列表,切片对象或布尔值。
选择所有行以及第4、5和7列:
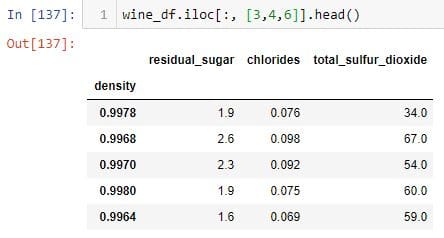
要复制上面的DataFrame,请将列名作为列表传递给.loc索引器:
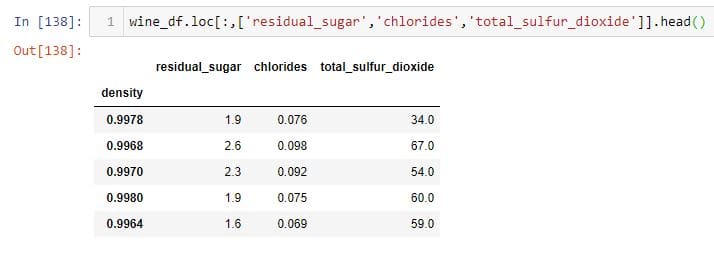
选择脱节的行和列
要选择特定数量的行和列,可以使用进行以下操作.iloc。

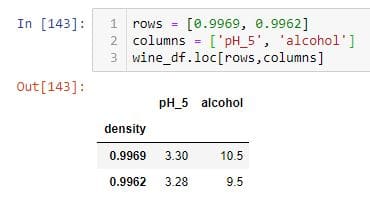
要选择特定数量的行和列,可以使用进行以下操作.loc。
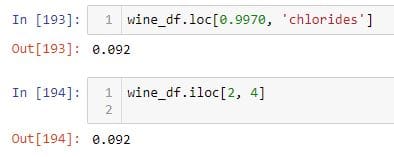
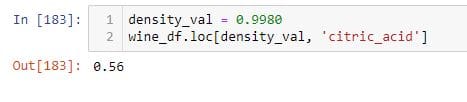
要从DataFrame中选择一个值,您可以执行以下操作。
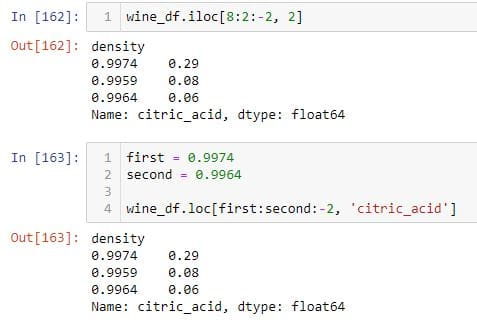
您可以使用切片来选择特定的列。
要同时选择行和列,您需要了解方括号中逗号的用法。逗号左侧的参数始终根据行索引选择行,而逗号右侧的参数始终根据列索引选择列。
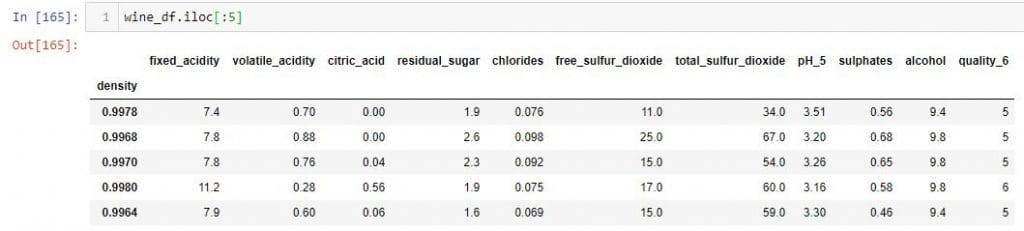
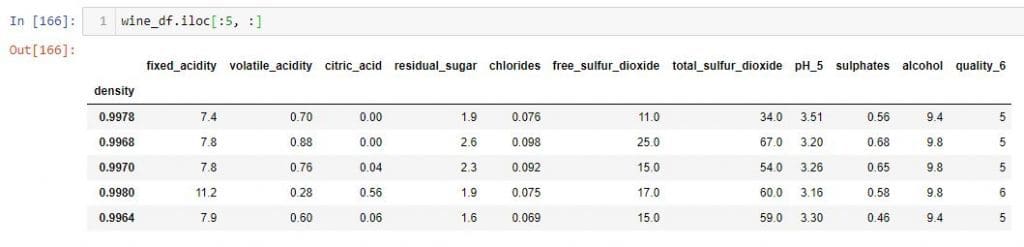
如果要选择一组行和所有列,则无需在逗号后使用冒号。
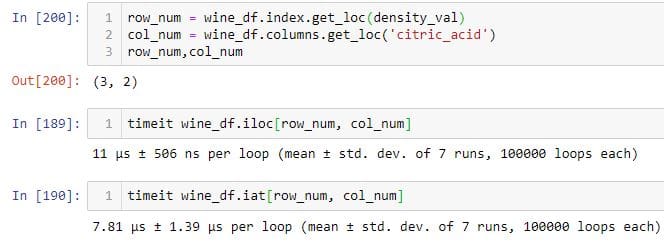
使用“ get_loc”和“ index”方法选择行和列
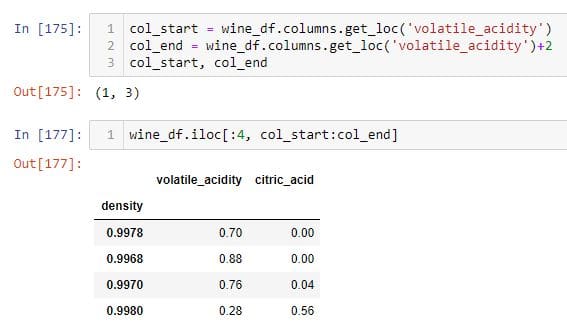
在上面的示例中,我使用该 get_loc 方法查找“ volatile_acidity”列的整数位置并将其分配给变量col_start。同样,我使用该 get_loc 方法查找比'volatile_acidity'列多2个整数值的列的整数位置,并将其分配给名为col_end.I的变量,然后使用该iloc 方法选择前4行col_start和col_end列。如果将索引标签传递给该 get_loc 方法,则它将返回其整数位置。
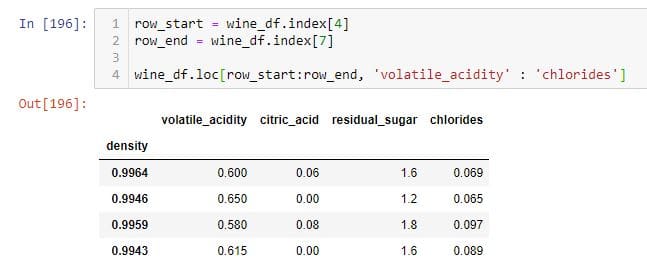
您可以使用进行非常类似的操作。loc。下面显示了如何从3到7的行以及“ volatile_acidity”到“ chlorides”的列进行选择。
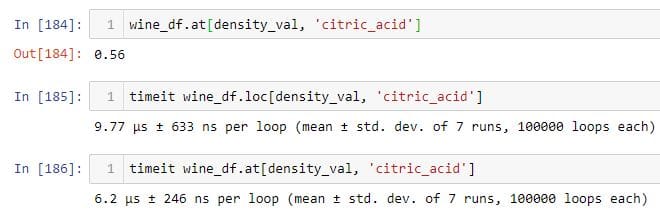
使用.iat和at进行子选择
从DataFrame中选择单个元素时,索引器(.iat和).at比.iloc和.loc快得多。
我将编写更多有关使用Pandas处理数据的