从JMeter 2.13开始,您可以通过提供实现AbstractBackendListenerClient的类,通过后端侦听器使用可能的任何后端(JDBC,JMS,Webservice,...)来获取发送到后端的实时结果 。 JMeter附带:
- GraphiteBackendListenerClient,允许您将指标发送到Graphite后端。
此功能提供:- 实时结果
- 指标的漂亮图表
- 能够比较2个或更多负载测试
- 只要JMeter产生相同的后端,就存储监控数据
- ...
- JMeter 3.2中引入的InfluxDBBackendListenerClient允许您使用UDP或HTTP协议将指标发送到InfluxDB后端此功能提供:
- 实时结果
- 指标的漂亮图表
- 能够比较2个或更多负载测试
- 能够向图表添加注释
- 只要JMeter产生相同的后端,就存储监控数据
- ...
在本文档中,我们将介绍配置设置,以便在不同的后端中绘制数据并对其进行历史记录:
- InfluxDBBackendListenerClient的InfluxDB设置
- InfluiteDB为GraphiteBackendListenerClient设置
- Grafana
- 石墨
15.1公开指标
15.1.1线程/虚拟用户度量标准
线程指标如下:
- <rootMetricsPrefix> test.minAT
- 最小活动线程
- <rootMetricsPrefix> test.maxAT
- 最大活动线程
- <rootMetricsPrefix> test.meanAT
- 平均活动线程
- <rootMetricsPrefix> test.startedT
- 开始线程
- <rootMetricsPrefix> test.endedT
- 完成的线程
15.1.2响应时间度量
响应相关指标如下:
- <rootMetricsPrefix> <samplerName> .ok.count
- 采样器名称的成功响应数
- <rootMetricsPrefix> <samplerName> .h.count
- 服务器每秒点击次数,此度量标准累积样本结果和子结果(如果使用事务控制器,则应取消选中“生成父样本”)
- <rootMetricsPrefix> <samplerName> .ok.min
- 成功响应采样器名称的最短响应时间
- <rootMetricsPrefix> <samplerName> .ok.max
- 采样器名称成功响应的最长响应时间
- <rootMetricsPrefix> <samplerName> .ok.avg
- 采样器名称成功响应的平均响应时间。
- <rootMetricsPrefix> <samplerName> .ok.pct <percentileValue>
- 针对采样器名称的成功响应计算百分位数。每个计算值将有一个度量标准。
- <rootMetricsPrefix> <samplerName> .ko.count
- 采样器名称的失败响应数
- <rootMetricsPrefix> <samplerName> .ko.min
- 采样器名称响应失败的响应时间最短
- <rootMetricsPrefix> <samplerName> .ko.max
- 采样器名称响应失败的最长响应时间
- <rootMetricsPrefix> <samplerName> .ko.avg
- 采样器名称响应失败的平均响应时间。
- <rootMetricsPrefix> <samplerName> .ko.pct <percentileValue>
- 针对采样器名称的失败响应计算百分位数。每个计算值将有一个度量标准。
- <rootMetricsPrefix> <samplerName> .a.count
- 采样器名称的响应数(ok.count和ko.count的总和)
- <rootMetricsPrefix> <samplerName> .sb.bytes
- 发送字节
- <rootMetricsPrefix> <samplerName> .rb.bytes
- 收到的字节
- <rootMetricsPrefix> <samplerName> .a.min
- 采样器名称响应的最小响应时间(ok.count和ko.count的最小值)
- <rootMetricsPrefix> <samplerName> .a.max
- 采样器名称响应的最大响应时间(最大值为ok.count和ko.count)
- <rootMetricsPrefix> <samplerName> .a.avg
- 采样器名称响应的平均响应时间(平均值为ok.count和ko.count)
- <rootMetricsPrefix> <samplerName> .a.pct <percentileValue>
- 针对采样器名称的响应计算百分位数。每个计算值将有一个度量标准。(根据OK和失败样本的总数计算)
后端侦听器 的默认百分位数设置为“90; 95; 99”,即3百分位数为90%,95%和99%。
该石墨命名层次 使用点(“”)分开的元素。这可能与小数百分位值混淆。JMeter转换任何此类值,用下划线(“ - ”)替换点(“。”)。例如,“ 99.9 ”变为“ 99_9 ”
默认情况下,JMeter发送在samplerName“ all ” 下累积的所有采样器的度量标准。如果配置了Backend Listener samplersList,那么JMeter还会发送匹配样本名称的度量,除非summaryOnly = true
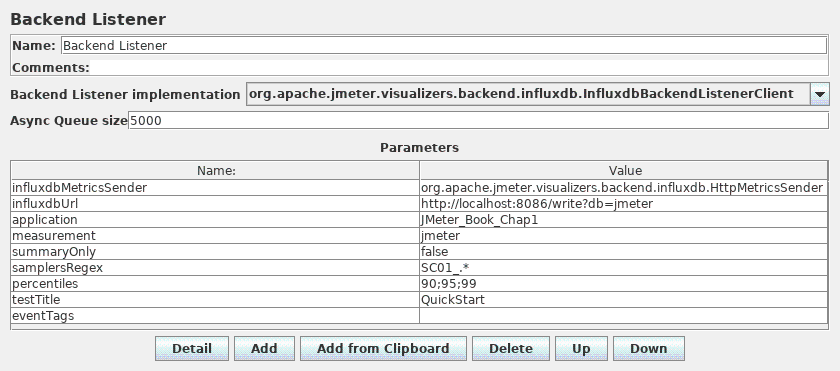
15.3 InfluxDB数据库配置
使用InfluxDB的命令行界面(CLI)连接到InfluxDB 。并创建JMeter数据库:
- jmeter:InfluxDB用于存储后端监听器发送的数据
15.3.1 InfluxDBBackendListenerClient的InfluxDB设置
InfluxDB是一个开源的,分布式的时间序列数据库,可以轻松存储指标。安装和配置非常简单,请阅读本文以获取有关InfluxDB文档的更多详细信息。
通过Grafana可以在浏览器中轻松查看InfluxDB数据。
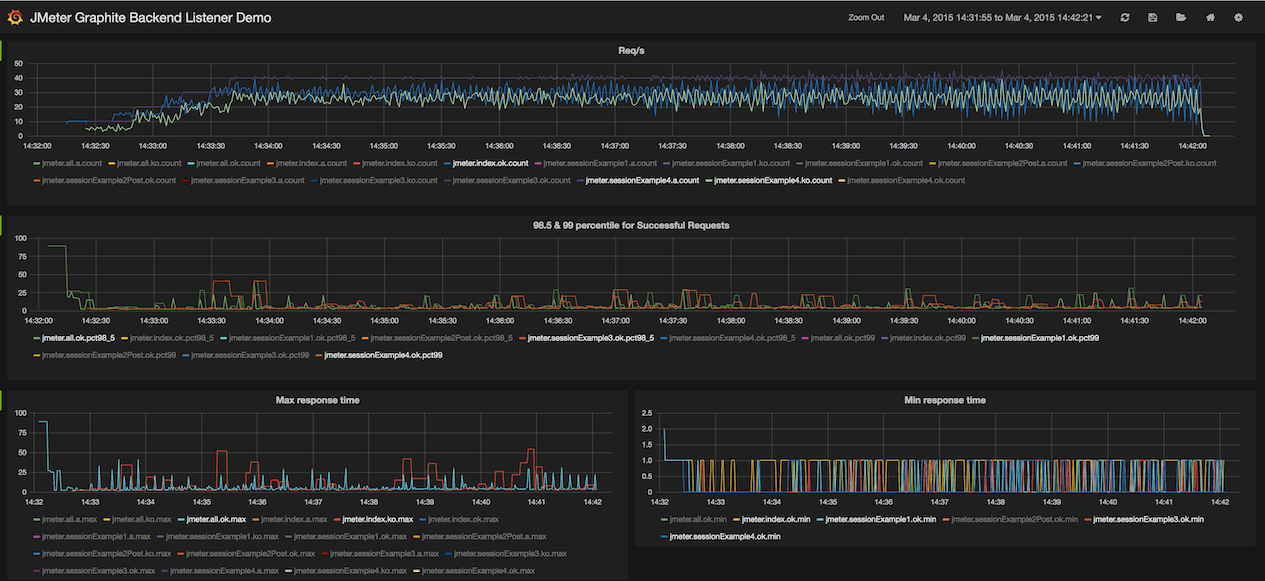
15.5石墨
欢迎使用本节,请参阅贡献文档