一、实验评估参数

实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实;又可以按照我们系统的输出是否属于某一个类(即selected和not selected),表示是否分到某一类别,这是实验输出。
以垃圾邮件为例:
tp:表示系统认为它是垃圾邮件,而确实它是垃圾邮件,所以为true positive
fn:表示系统不认为它是垃圾邮件,但它其实是垃圾邮件,所以为false negative
fp:表示系统认为是,其实不是,所以为false positive
tn:表示系统认为不是,确实也不是,所以是true negative
对于检测垃圾邮件,只用检测正确率,正确的部分则为tp和tn,所以正确率Acc=(tp+tn)/(tp+fp+fn+tn)
但是如果换一个语境:现在我们要在一篇文档中检测出现的鞋的牌子
那么假设文档中有100,000个词,其中10个是鞋的牌子,99,990个是其他词,如果我们的系统检测出来的鞋的牌子是0个,100,000个词是其他词,那么正确率反而是Acc=99,990/100,000=99.99%,但是显然是不准确的,系统根本没有做任何事,甚至我们用一行代码:for each word: return false。就可以实现,所以在这种情况下,正确率是无法合理评估的,我们更关注的是tp的部分,因此需要用准确率和召回率来评估。
Precision准确率(查准率):selected的部分中正确的比例,tp/(tp+fp)
Recall召回率(查全率):正确的部分中selected的比例,tp/(tp+fn)
两者是相斥的,相加为1,所以召回率越高,准确率反而越低,需要权衡两者,看是查准重要还是查全重要?
the F measure:综合考虑准确率和召回率,为加权调和平均数:

α值取决于作者本身对于应用的评估是查准重要还是查全重要。α=1/(β^2+1)
一般使用F1 measure, 即β=1(即,α=1/2),从而F=2PR/(P+R)
二、实验评估通用数据集
Reuters-21578 Data Set:


混淆矩阵:
横纵坐标为类别,对于每一对<c1,c2>, 其值表示属于c1的文档被错误分到c2的数目,如下:
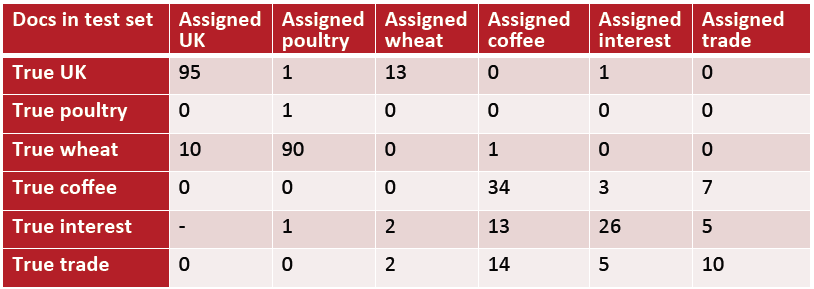
横坐标表头“True XX”表示真实的类别,纵坐标表头“Assigned XX”表示分类器分配的类别。
对角线表示正确分配类别的文档数目。
使用混淆矩阵可以计算各种评估参数:

如果有多个类别,如何结合多项实验参数得到一个参数用以评估:
方法1:Macroaveraging:为每一个类别计算一个值,然后取平均值
方法2:Microaveraging:收集每个类别中的决定,然后计算一个列联表,然后评估
实例:

数据集分为:
![]()
在开发测试集中计算各项评估参数:P/R/F1或Accuracy
然后按照评估参数修改模型,继续在训练集中训练模型。
而测试集要求数据跟前两个数据集完全不同,即unseen不可见,这是为了:
- 避免过度拟合
- 对性能的估计更保守
交叉验证:

从训练集中切割出部分开发测试集,然后我们将从每次分割中共享开发测试集的评估结果,然后计算总的开发集性能。从而避免开发测试集过小或者不具有代表性的问题。最后用不可见的测试集验证模型性能。
三、文本分类中的实际问题
1. 没有训练集怎么办?
使用手写规则:非常耗时耗力
2. 训练集很小怎么办?
- 使用Naive Bayes算法:即使训练数据很少,也不至于太过度拟合训练数据
- 获得更多的标签数据:一般也是手动
- 使用半监督训练方法:Bootstrapping, EM over unlabeled documents,...
3. 有足够的训练集
可以尝试任何分类器:SVM、逻辑回归、甚至决策树。
决策树是可以解释的,用户也是乐于去建立决策树的
4. 训练集非常庞大
那就可以达到很高的accuracy正确率,但是大部分分类器比如SVM、KNN都非常慢,逻辑回归会好一些,这种时候训练Naive Bayes反而会非常有效。
实验证明:当数据集非常庞大时,不同的分类器的正确率反而很相近
5. Naive Bayes中的一些关键问题
1)预防下溢:
因为多个小数相乘会导致接近于0。
通过转换成log、将乘法转换为加法可以解决这个问题
2)怎么调整性能:
- 按照领域挑选特定的特征和权重
- 对某些词增加它的计数,即出现一次的时候记成两次,比如:标题、每段的第一句、包含标题单词的句子中的单词