在多种应用比如word中都有拼写检查和校正功能,具体步骤分为:
- 拼写错误检测
- 拼写错误校正:
- 自动校正:hte -> the
- 建议一个校正
- 建议多个校正
拼写错误类型:
- Non-word Errors非词错误:即写了一个不是单词的词,比如graffe并不存在,应校正为giraffe
- 检测方法:认为任一不在字典中的词都是一个非词错误,因此字典本身越大越好
- 校正方法:为错误词产生一个候选,其是跟错误词相似的真词,然后选择加权编辑距离最短或者信道噪声概率最高的那个词。
- Real-word Errors真词错误:
- 印刷错误:three->there
- 认知错误(同音异形字):piece -> peace; too -> two
- 检测方法:由于每个真词可能都是一个错误词,因此我们为每个词都产生一个候选集,包括该词本身、跟该词发音或拼写相似的词(编辑距离为1的英文单词)、同音异形词。
- 校正方法:按照信道噪声或者分类器选择最好的候选词。
一、非词错误校正
基本方法:使用The Noisy Channel Model of Spelling信道噪声模型
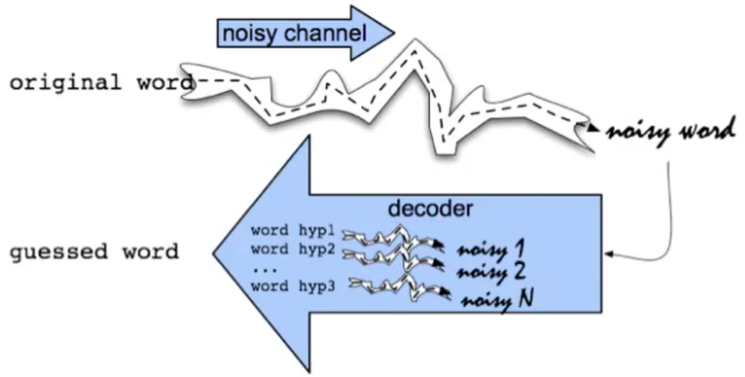
假设初始词经过一个噪声信道输出一个噪声词,即为可能的错误词,我们旨在对该噪声信道建模,从而使得在解码阶段能够根据噪声词得到一个猜测词,其跟初始词一致,即找到错误词正确的拼写。
而信道噪声我们视之为一个概率模型,如下:
输入:一个错误词x
旨在:找到一正确的词w
要求:
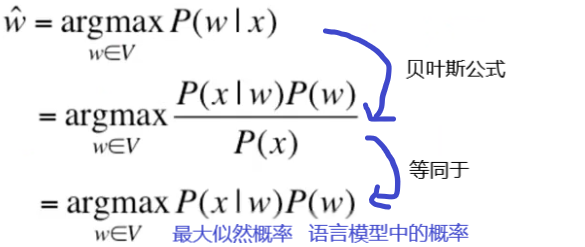
P(w)称为语言模型表示单词w为一个单词的概率,P(x|w)称为信道概率(或错误概率)表示如果是w,x是w拼错的词的概率。
例子:
设:有一个错误词“acress”
1. 产生候选词:
- 相似拼写词:跟错误词之间小的编辑距离
- 采用Damerau-Levenshtein edit distance,计算的操作包括:插入、删除、置换和两个相邻字母之间的换位transposition,
- 以下是与“acress”编辑距离=1的列表:
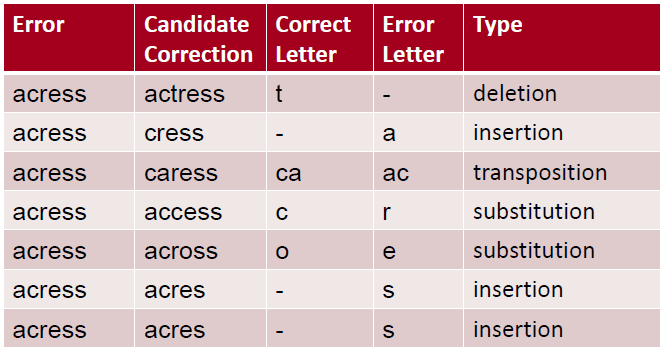
- 80%错误词与正确词之间的编辑距离为1,大部分的编辑距离都小于等于2
- 允许插入空格或者连字符-:thisidea -> this idea; inlaw -> in-law
- 相似发音词:跟错误词的发音之间小的编辑距离
2. 选择最优候选词:套用公式
a) 计算语言模型P(w):可以采用之前说过的任一语言模型,比如unigram、bigram、trigram,大规模拼写校正也可以采用stupid backoff。
b) 计算信道概率P(x|w):首先获得多个单词拼错的列表,然后计算混淆矩阵,然后按照混淆矩阵计算信道概率。
设:
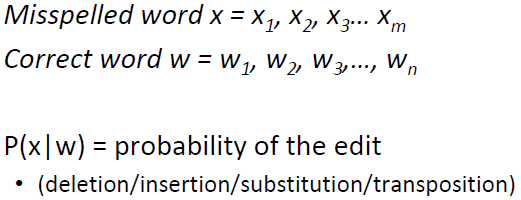
有:

x和y为任一字母a-z,计数count表示后面那张情况发生的次数,其中插入和删除的情况都依赖于前一个字符,sub[x,y]的混淆矩阵结果如下:

然后按照上述混淆矩阵计算信道概率:
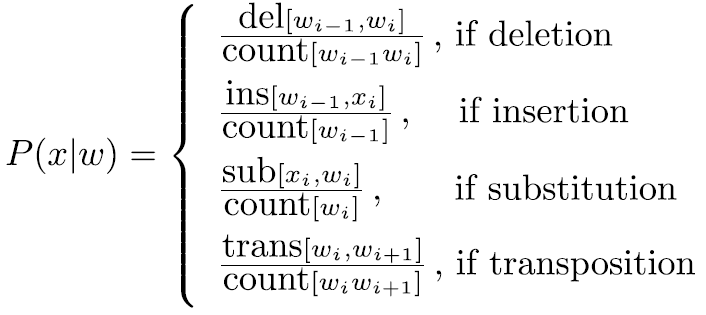
c) 整体概率计算实例如下:

也可以选用语言模型计算整体概率,比如:使用bigram或trigram语言模型

3. 结果评估方法:
使用拼写错误测试集:

二、真词校正
25-40%的拼写错误都是真词错误。
具体步骤:

实例:
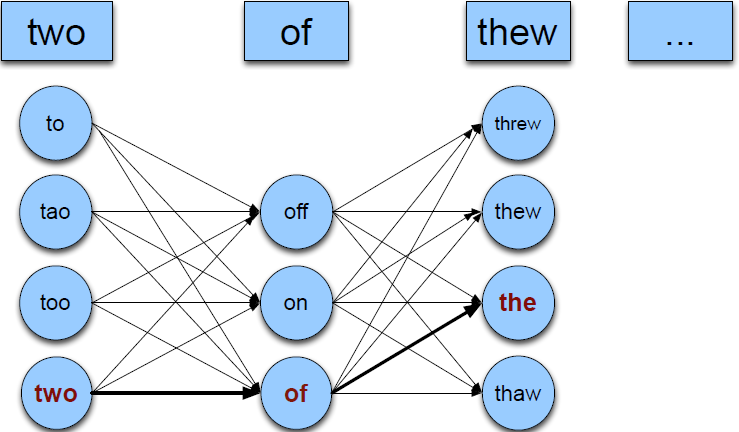
为了方便起见,我们假定每个句子中只有一个拼写错误,所以有:

要求从中找到一个组合序列使得序列的概率最高。
计算P(W):
方法1:语言模型,比如unigram、bigram等
方法2:信道模型:跟“一”中的方法一样,但还需要额外计算没有错误的概率P(w|w),因为候选集中还包括自身词。
计算P(w|w):其完全依赖于应用本身,表示一个词可能被拼错的概率,不同的应用概率不同:

三、经典系统state of art
1. HCI issues in spelling
- 如果对校正结果非常自信:自动校正
- 一般自信:给定一个最好的校正方案
- 一点点自信:给定一个校正方案的列表
- 没有自信:给错误词做出标记,不校正
2. 经典噪声信道
实际应用中,信道概率和语言模型概率的权重并非一致,而是采用如下的计算公式:
![]()
然后在开发测试数据集中训练学习lambdas的值。
3. 语音错误模型
针对有相似发音的错误拼写的纠正
a) Metaphone, used in GNU aspell
- 将错误拼写转换为变音发音,规则如下:

- 然后找到跟错误拼写的发音的编辑距离为1-2的词
- 给结果列表打分,按照:
- 候选词跟错误词之间的加权编辑距离
- 候选词的发音与错误词发音的编辑距离
4. 信道模型的升级版
a) 允许更多的操作(Brill and Moore 200)

b) 在信道中结合发音(Toutanova and Moore 2003)
c)在计算信道概率P(x|w)时考虑更多的影响因素

5. 基于分类器的真词拼写校正方法
- 考虑更多的特征
- 针对特定词对建立分类器