一、产生句子
方法:Shannon Visualization Method
过程:根据概率,每次随机选择一个bigram,从而来产生一个句子
比如:
- 从句子开始标志的bigram开始,我们先有一个(<s>, w),w是随机一个单词,比较有可能的是I这个单词,那么我们就有(<s>, I)
- 随机选择下一个单词,得到(w,x),这里w是I,x概率最大的是want
- 重复以上步骤,直到得到</s>

问题1:过度拟合。N-grams在预测句子上只有当测试语料库和训练语料库非常相似的时候才会比较准确。比如不能把在《莎士比亚全集》上训练的模型在《华尔街日报》上测试。
问题2:在训练集中没有出现但是测试集中有出现。比如:

在训练集中"denied the offer"出现的概率为0,但是其在测试集中有出现,但是我们的模型依然只会记住其概率为0,那么就识别不了这个词组,如果是机器翻译,那么就无法翻译这个词组。
那么如何应对测试集中概率为0的数据呢?
二、如何应对bigram中概率为0的数据?
方法:add-one smoothing (Laplace smoothing)
主要思想:假装每个单词我们都看了一遍,然后都加到总数里
从而将原来使用最大似然估计的概率转变为Add-1 估计的概率:
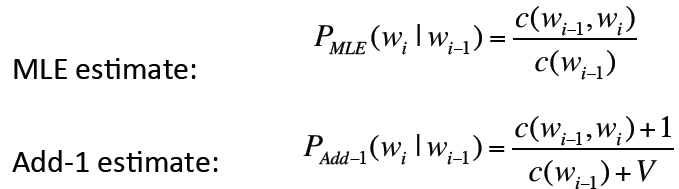
因为我们把每个单词的计数都加了1,那么一共有V的单词的话,计数总数就加了V
· 最大似然估计:
假设单词“bagel”在一个由1000000个词组成的语料库中出现了400次,那么在其他语料库中随机出现一个单词是“bagel”的概率是多少?
最大似然估计出来的概率为400/1000000=.004
这个可能会非常不准确,但是这最有可能的估计了。
· Add-1 估计:
将所有的计数都加1,则有:

bigram概率则为:
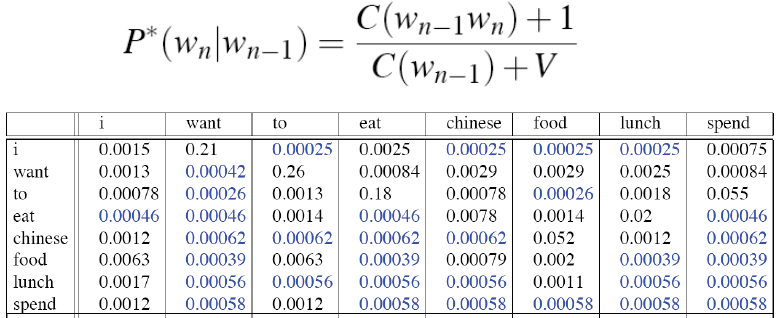
重新计算计数得:
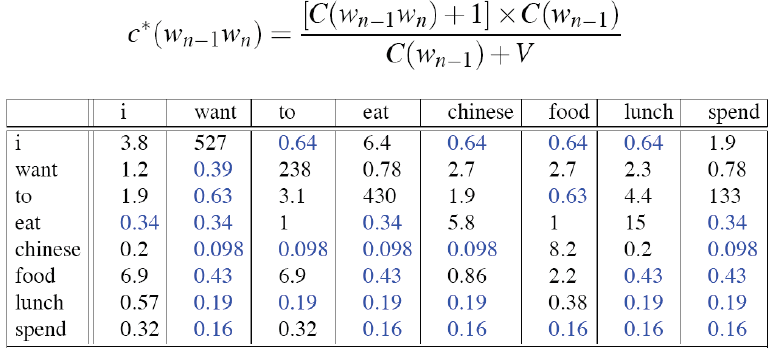
可以发现跟实际的计数非常不一样,差别可能会很大,add-1估计太过粗糙,所以实际应用中我们并不在N-gram中使用这种方法,但是在其他模型中会使用这种方法,比如文本分类这种概率为0的数目并不会很多的情况。
三、backoff回退和interpolation插值
backoff指:由于N-gram模型中当使用的N值较大时,很多项的概率会是0,所以换用较小的N值。
interpolation指:混合多种模型,比如trigram、bigram和unigram,其是按照权重分配多种模型的概率的。
实际应用表明interpolation的效果更好。
1. 线性插值
简单插值:
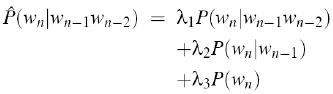 ,
, ![]()
第一项是trigram得出的概率,第二项是bigram,第三项是unigram。
上式中使用的权值lambdas值为常数,下式我们基于内容使用前两个词作为权值的参数,更科学灵活:
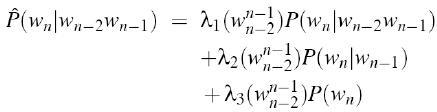
· 怎么设置lambdas参数
方法:使用held-out留存语料库
首先将数据分为训练数据集、留存数据集和测试数据集:

其中训练数据集用以训练n-gram模型、然后在留存数据集里检验模型计算出的概率,再反过来修正训练数据集中的lambdas值,用以找到能使留存数据集中的概率最大的lambdas值,即:
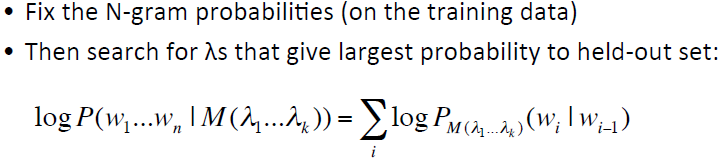
2. 如何应对未知的词汇
如果我们能提前知道所有的词汇,那词汇表就固定下来了,只能进行封闭的词汇任务。
而在大多数应用中,并不能提前知道所有的词汇,我们称词汇表外的词为Out Of Vocabulary(OOV words),从而能进行开放的词汇任务。
我们使用token<UNK>来标记这种未知的词汇。
在具体的训练过程中,首先有一个固定的词汇表L,大小为V,在文本标准化时,将所有不在词汇表中的训练词汇替换为<UNK>,然后在此基础上,将其作为正常的单词进行数据的训练。
在测试阶段,如果在输入文本中出现一个未知的单词(没有在训练阶段出现过的),就将其替换为<UNK>,然后做正常的测试。
3. n-gram如何应对非常巨大的语料库
诸如Google N-gram corpus,其语料库非常巨大,n-gram难以应对。
方法之一是剪枝:
a) 只存储N-gram计数超过界限值的项,移除只出现一次的高阶n-grams。
b)使用基于熵的剪枝方法。
还有其他的方法:
a) 使用有效的数据结构,比如字典树Trie
b) Bloom filters布隆过滤器:一种近似语言模型
c) 不将词简单地存为字符串,而存储为索引:使用哈弗曼编码
d) 使用Quantize probabilities,不将概率存储为8位的float,而存储为长度为4-8的位
· 如何对巨量的N-grams做平滑
通用方法是“Stupid backoff” (Brants et al. 2007),非常简单但是有效,具体如下:

即,当某项计数为0时,再往前一个词,即从k-gram变成k+1-gram,并设有一个权重0.4。
四、总结:N-gram平滑方法
1. Add-1 smoothing:对文本类别有效,但是对语言模型效果不好
2. 最通用的方法:插值方法
3. 对大型语料库:Stupid backoff
五、高级语言模型
1. 判别模型:选择多个N-gram的权重来提高效果,而不是在多个N-gram中选择一个
2. 基于解析的模型
3. 缓存模型:将最近使用的单词放入缓存,然后在缓存的基础上计算新词的条件概率
![]()
但是这种方法对于语音识别效果非常差。