lasticsearch中,内置了很多分词器(analyzers),例如standard (标准分词器)、english(英文分词)和chinese (中文分词)。其中standard 就是无脑的一个一个词(汉字)切分,所以适用范围广,但是精准度低;english 对英文更加智能,可以识别单数负数,大小写,过滤stopwords(例如“the”这个词)等;chinese 效果很差,后面会演示。这次主要玩这几个内容:安装中文分词ik,对比不同分词器的效果,得出一个较佳的配置。关于Elasticsearch,之前还写过两篇文章:Elasticsearch的安装,运行和基本配置 和 备份和恢复,需要的可以看下。
安装中文分词ik
Elasticsearch的中文分词很烂,所以我们需要安装ik。首先从github上下载项目,解压:
- cd /tmp
- wget https://github.com/medcl/elasticsearch-analysis-ik/archive/master.zip
- unzip master.zip
- cd elasticsearch-analysis-ik/
然后使用mvn package 命令,编译出jar包 elasticsearch-analysis-ik-1.4.0.jar。
- mvn package
将jar包复制到Elasticsearch的plugins/analysis-ik 目录下,再把解压出的ik目录(配置和词典等),复制到Elasticsearch的config 目录下。然后编辑配置文件elasticsearch.yml ,在后面加一行:
- index.analysis.analyzer.ik.type : "ik"
重启service elasticsearch restart 。搞定。
如果上面的mvn搞不定的话,你可以直接从 elasticsearch-rtf 项目中找到编译好的jar包和配置文件(我就是怎么干的)。
【2014-12-14晚更新,今天是星期天,我在vps上安装ik分词,同样的步骤,总是提示MapperParsingException[Analyzer [ik] not found for field [cn]],然后晚上跑到公司,发现我公司虚拟机上Elasticsearch的版本是1.3.2,vps上是1.3.4,猜是版本问题,直接把vps重新安装成最新的1.4.1,再安装ik,居然ok了……】
准备工作:创建索引,录入测试数据
先为后面的分词器效果对比做好准备,我的Elasticsearch部署在虚拟机 192.168.159.159:9200 上的,使用chrome的postman插件直接发http请求。第一步,创建index1 索引:
- PUT http://192.168.159.159:9200/index1
- {
- "settings": {
- "refresh_interval": "5s",
- "number_of_shards" : 1, // 一个主节点
- "number_of_replicas" : 0 // 0个副本,后面可以加
- },
- "mappings": {
- "_default_":{
- "_all": { "enabled": false } // 关闭_all字段,因为我们只搜索title字段
- },
- "resource": {
- "dynamic": false, // 关闭“动态修改索引”
- "properties": {
- "title": {
- "type": "string",
- "index": "analyzed",
- "fields": {
- "cn": {
- "type": "string",
- "analyzer": "ik"
- },
- "en": {
- "type": "string",
- "analyzer": "english"
- }
- }
- }
- }
- }
- }
- }
为了方便,这里的index1 索引,只有一个shards,没有副本。索引里只有一个叫resource 的type,只有一个字段title ,这就足够我们用了。title 本身使用标准分词器,title.cn 使用ik分词器,title.en 自带的英文分词器。然后是用bulk api批量添加数据进去:
- POST http://192.168.159.159:9200/_bulk
- { "create": { "_index": "index1", "_type": "resource", "_id": 1 } }
- { "title": "周星驰最新电影" }
- { "create": { "_index": "index1", "_type": "resource", "_id": 2 } }
- { "title": "周星驰最好看的新电影" }
- { "create": { "_index": "index1", "_type": "resource", "_id": 3 } }
- { "title": "周星驰最新电影,最好,新电影" }
- { "create": { "_index": "index1", "_type": "resource", "_id": 4 } }
- { "title": "最最最最好的新新新新电影" }
- { "create": { "_index": "index1", "_type": "resource", "_id": 5 } }
- { "title": "I'm not happy about the foxes" }
注意bulk api要“回车”换行,不然会报错。
各种比较
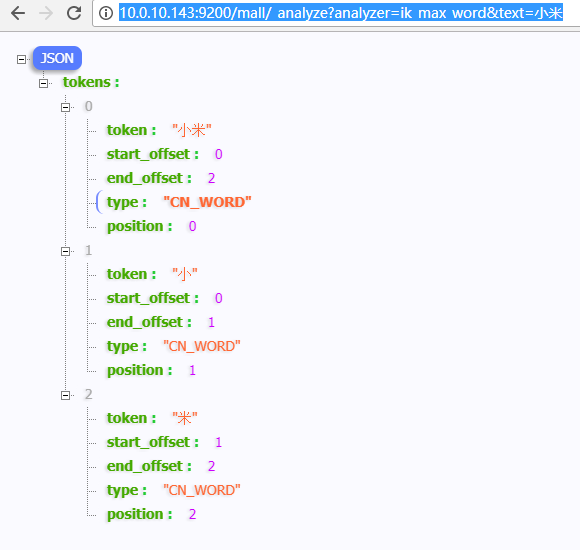
1、对比ik分词,chinese分词和standard分词
- POST http://192.168.159.159:9200/index1/_analyze?analyzer=ik
- 联想召回笔记本电源线
ik测试结果:
- {
- "tokens": [
- {
- "token": "联想",
- "start_offset": 0,
- "end_offset": 2,
- "type": "CN_WORD",
- "position": 1
- },
- {
- "token": "召回",
- "start_offset": 2,
- "end_offset": 4,
- "type": "CN_WORD",
- "position": 2
- },
- {
- "token": "笔记本",
- "start_offset": 4,
- "end_offset": 7,
- "type": "CN_WORD",
- "position": 3
- },
- {
- "token": "电源线",
- "start_offset": 7,
- "end_offset": 10,
- "type": "CN_WORD",
- "position": 4
- }
- ]
- }
自带chinese和standard分词器的结果:
- {
- "tokens": [
- {
- "token": "联",
- "start_offset": 0,
- "end_offset": 1,
- "type": "<IDEOGRAPHIC>",
- "position": 1
- },
- {
- "token": "想",
- "start_offset": 1,
- "end_offset": 2,
- "type": "<IDEOGRAPHIC>",
- "position": 2
- },
- {
- "token": "召",
- "start_offset": 2,
- "end_offset": 3,
- "type": "<IDEOGRAPHIC>",
- "position": 3
- },
- {
- "token": "回",
- "start_offset": 3,
- "end_offset": 4,
- "type": "<IDEOGRAPHIC>",
- "position": 4
- },
- {
- "token": "笔",
- "start_offset": 4,
- "end_offset": 5,
- "type": "<IDEOGRAPHIC>",
- "position": 5
- },
- {
- "token": "记",
- "start_offset": 5,
- "end_offset": 6,
- "type": "<IDEOGRAPHIC>",
- "position": 6
- },
- {
- "token": "本",
- "start_offset": 6,
- "end_offset": 7,
- "type": "<IDEOGRAPHIC>",
- "position": 7
- },
- {
- "token": "电",
- "start_offset": 7,
- "end_offset": 8,
- "type": "<IDEOGRAPHIC>",
- "position": 8
- },
- {
- "token": "源",
- "start_offset": 8,
- "end_offset": 9,
- "type": "<IDEOGRAPHIC>",
- "position": 9
- },
- {
- "token": "线",
- "start_offset": 9,
- "end_offset": 10,
- "type": "<IDEOGRAPHIC>",
- "position": 10
- }
- ]
- }
结论不必多说,对于中文,官方的分词器十分弱。
2、搜索关键词“最新”和“fox”
测试方法:
- POST http://192.168.159.159:9200/index1/resource/_search
- {
- "query": {
- "multi_match": {
- "type": "most_fields",
- "query": "最新",
- "fields": [ "title", "title.cn", "title.en" ]
- }
- }
- }
我们修改query 和fields 字段来对比。
1)搜索“最新”,字段限制在title.cn 的结果(只展示hit部分):
- "hits": [
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "1",
- "_score": 1.0537746,
- "_source": {
- "title": "周星驰最新电影"
- }
- },
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "3",
- "_score": 0.9057159,
- "_source": {
- "title": "周星驰最新电影,最好,新电影"
- }
- },
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "4",
- "_score": 0.5319481,
- "_source": {
- "title": "最最最最好的新新新新电影"
- }
- },
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "2",
- "_score": 0.33246756,
- "_source": {
- "title": "周星驰最好看的新电影"
- }
- }
- ]
再次搜索“最新”,字段限制在title ,title.en 的结果(只展示hit部分):
- "hits": [
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "4",
- "_score": 1,
- "_source": {
- "title": "最最最最好的新新新新电影"
- }
- },
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "1",
- "_score": 0.75,
- "_source": {
- "title": "周星驰最新电影"
- }
- },
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "3",
- "_score": 0.70710677,
- "_source": {
- "title": "周星驰最新电影,最好,新电影"
- }
- },
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "2",
- "_score": 0.625,
- "_source": {
- "title": "周星驰最好看的新电影"
- }
- }
- ]
结论:如果没有使用ik中文分词,会把“最新”当成两个独立的“字”,搜索准确性低。
2)搜索“fox”,字段限制在title 和title.cn ,结果为空,对于它们两个分词器,fox和foxes不同。再次搜索“fox”,字段限制在title.en ,结果如下:
- "hits": [
- {
- "_index": "index1",
- "_type": "resource",
- "_id": "5",
- "_score": 0.9581454,
- "_source": {
- "title": "I'm not happy about the foxes"
- }
- }
- ]
结论:中文和标准分词器,不对英文单词做任何处理(单复数等),查全率低。
我的最佳配置
其实最开始创建的索引已经是最佳配置了,在title 下增加cn 和en 两个fields,这样对中文,英文和其他什么乱七八糟文的效果都好点。就像前面说的,title 使用标准分词器,title.cn 使用ik分词器,title.en 使用自带的英文分词器,每次搜索同时覆盖