一、IK分词器简介
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
2)采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
3)对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。 4)支持用户词典扩展定义。
5)针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
二、ElasticSearch集成IK分词器
1、IK分词器的安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases

2、解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8plugins下,并重命名文件夹为analysis-ik

3、重新启动ElasticSearch,即可加载IK分词器

4、IK分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word
其中 ik_smart 为最小切分,ik_max_word为最细粒度划分
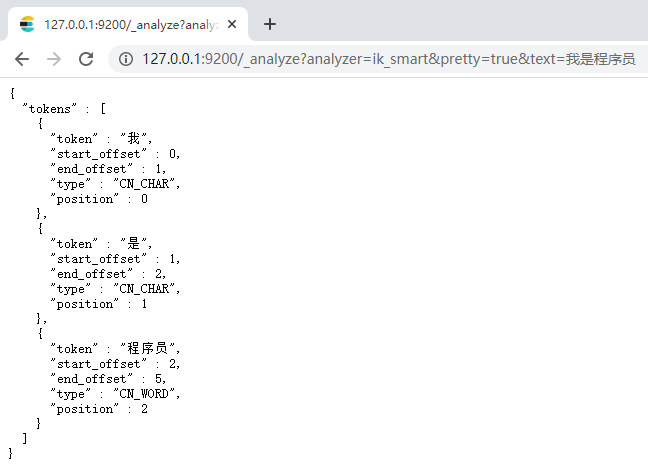
1)最小切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
输出的结果为:
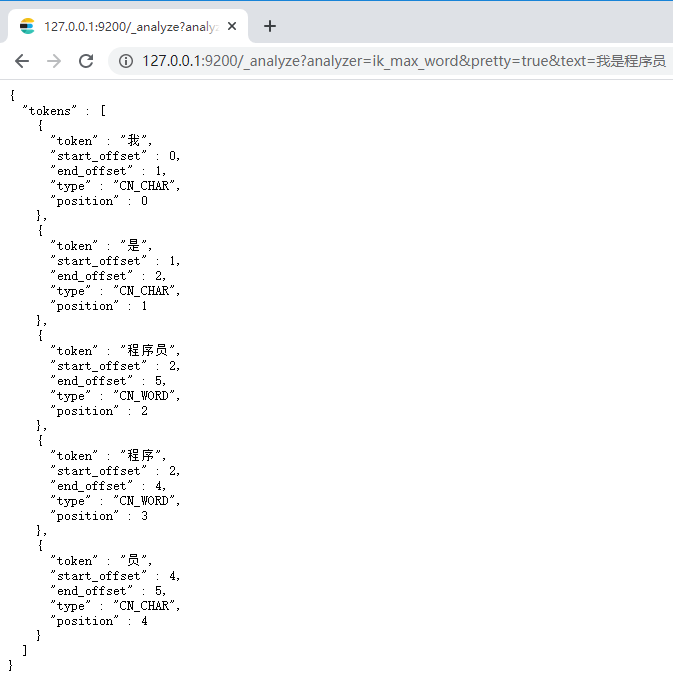
2)最细切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员
输出的结果为:
三、修改索引映射mapping
1、删除原有es_test01索引
请求:DELETE http://localhost:9200/es_test01 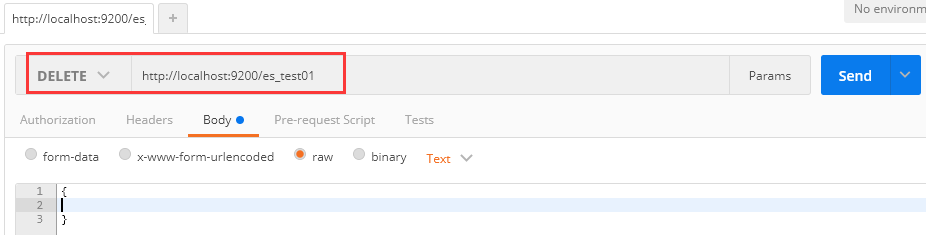
2、创建es_test01索引,此时分词器使用ik_max_word
请求:PUT http://localhost:9200/es_test01
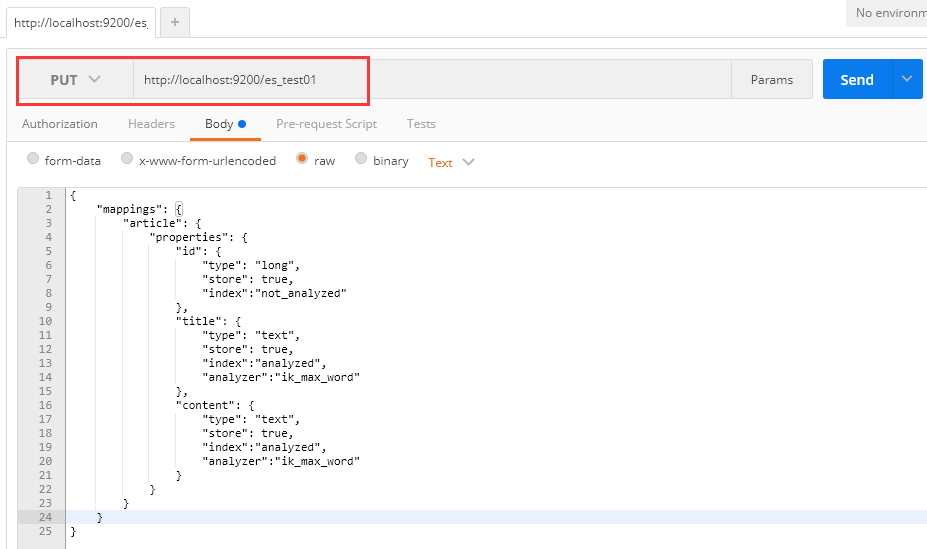
请求体:
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
}
}
}
}
}
3、创建文档
请求:PUT http://localhost:9200/es_test01/article/1

请求体:
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器", "content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfulweb接口。
Elasticsearch是用Java 开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时
搜索,稳定,可靠,快速,安装使用方便。"
}
4、再次测试queryString查询
请求:POST http://localhost:9200/es_test01/article/_search

请求体:
{
"query": {
"query_string": {
"default_field": "title",
"query": "搜索服务器"
}
}
}
返回结果:

5、将请求体搜索字符串修改为"钢索",再次查询

6、再次测试term测试
请求:POST http://localhost:9200/es_test01/article/_search

请求体:
{
"query": {
"term": {
"title": "搜索"
}
}
}
返回结果:
