《网络攻防实践》综合实践
一、论文简介
1.1 论文信息
论文标题: Spectre Attacks: Exploiting Speculative Execution
论文出处: Proc. S&P, 2019
论文作者: Paul Kocher, Daniel Genkin, Daniel Gruss, Werner Haas, Mike Hamburg, Moritz Lipp, Stefan Mangard, Thomas Prescher, Michael Schwarz, Yuval Yarom.
1.2 摘要
现代处理器使用分支预测和推测执行来最大化性能。例如,如果分支的目标依赖于正在读取的内存值,CPU将尝试猜测目标并尝试提前执行。当内存值最终到达时,CPU要么丢弃要么提交推测性计算。推测逻辑在执行方式上是不可靠的,它可以访问受害者的内存和寄存器,并且可以执行具有可测量的副作用的操作。
Spectre攻击包括诱导受害者进行推测性的操作,而这些操作在正确的程序执行过程中是不会发生的,并且会通过一个旁路将受害者的机密信息泄露给敌方。本文描述了结合了侧通道攻击、故障攻击和可从受害者进程中读取任意内存的面向返回编程的方法的实际攻击。更广泛地说,本文表明,推测性执行实现违反了支撑众多软件安全机制的安全假设,包括操作系统进程分离、容器化、即时(JIT)编译以及缓存定时和侧通道攻击的对策。这些攻击是对实际系统的严重威胁,因为在数十亿设备中使用的Intel、AMD和ARM的微处理器中发现了易受攻击的推测性执行能力。
虽然临时处理器的对策可能在某些情况下,解决方案将需要修复处理器设计以及更新指令集架构(isa)给硬件架构师和软件开发人员一个共同的理解计算状态CPU实现什么和不允许泄漏。
1.3 概念与核心工作
推测式执行在如何执行方面是不可靠的,因为它可以访问受害者的内存和寄存器,并且可以执行具有可测量的副作用的操作。
幽灵攻击:诱导受害者在执行在正确的程序执行过程中不会发生的推测性操作,并通过一个侧信道将受害者的敏感数据泄露出去。
论文提出了一种实用的攻击方法,通过结合侧信道攻击,fault攻击和ROP攻击,可以从受害者进程中读取任意位置的数据
二、论文内容
由物理设备执行的计算通常会留下明显的副作用,超出计算的名义输出。旁道攻击的重点是利用这些副作用来获取无法获取的秘密信息。自90年代末出现以来,许多物理效应,如功耗、电磁辐射或声学噪声,都被用来提取密码学密钥和其他秘密。
物理侧信道攻击也可以用于从复杂的设备如pc和移动电话中提取秘密信息。然而,由于这些设备经常执行来自潜在未知来源的代码,它们面临着基于软件的攻击形式的额外威胁,这种攻击不需要外部测量设备。虽然有些攻击利用软件漏洞(如buffer overflows 或 double-free errors),但其他软件攻击利用硬件漏洞来泄漏敏感信息。后一种类型的攻击包括利用缓存定时、分支预测历史、分支目标缓冲区或打开DRAM行的微架构攻击。基于软件的技术也被用来安装改变物理内存或内部CPU值的错误攻击。
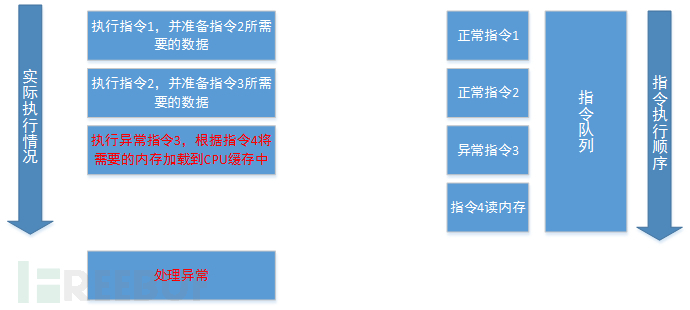
在过去的几十年里,一些微架构设计技术促进了处理器速度的提高。其中一个改进是推测性执行,它被广泛用于提高性能,包括让CPU猜测可能的未来执行方向,并在这些路径上过早地执行指令。更具体地说,考虑这样一个例子:程序的控制流依赖于位于外部物理内存中的未完成的值。由于此内存比CPU慢得多,所以通常需要几百个时钟周期才能知道该值。与通过空闲浪费这些周期不同,CPU尝试猜测控制流的方向,保存其寄存器状态的检查点,并在猜测的路径上推测地执行程序。当值最终从内存到达时,CPU检查其初始猜测的正确性。如果猜错了,CPU通过将寄存器状态恢复到存储的检查点来丢弃不正确的推测性执行,从而导致与空闲相当的性能。但是,如果猜测是正确的,那么将提交推测性执行结果,由于在延迟期间完成了有用的工作,从而获得显著的性能收益。
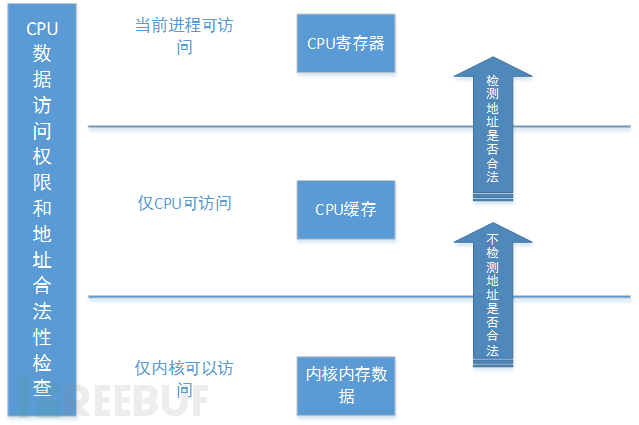
从安全的角度来看,投机性执行涉及到以可能不正确的方式执行程序。然而,由于cpu的设计是通过将不正确的推测性执行的结果恢复到它们之前的状态来维护功能正确性,所以这些错误在以前被认为是安全的。
2.1 实验思路
本文分析了这种不正确的推测执行的安全含义。提出了一类微架构攻击,称之为Spectre攻击。在较高的层次上,Spectre攻击诱使处理器推测性地执行在正确的程序执行下不应该执行的指令序列。当这些指令对名义CPU状态的影响最终被恢复时,本文称它们为暂态指令(transient instructions)。通过影响推测性地执行哪些暂态指令,我们能够从受害者的内存地址空间中泄漏信息。
通过利用暂态指令序列在非特权的本地代码和可移植的JavaScript代码中跨安全域泄漏信息,从经验上证明了Spectre攻击的可行性。
2.1.1 使用本机代码进行攻击
作为概念验证(POC),本文创建了一个简单的受害程序,该程序在其内存地址空间中包含秘密数据。接下来,本文作者搜索已编译的受害二进制文件和操作系统的共享库,以查找可用于从受害地址空间泄漏信息的指令序列。最后,作者编写了一个攻击程序,该程序利用CPU的推测性执行特点,将以前找到的序列作为暂态指令。使用这种技术,我们能够从受害者的地址空间读取内存,包括存储在其中的秘密。
2.1.2 使用JavaScript和eBPF进行攻击
除了使用本机代码破坏进程隔离边界之外,Spectre攻击还可以用来破坏沙箱,例如,通过可移植的JavaScript代码挂装沙箱。通过经验验证,作者展示了一个JavaScript程序,它成功地从运行它的浏览器进程的地址空间读取数据。此外,作者还演示了如何在Linux中利用eBPF解释器和JIT进行攻击。
2.2 相关工作
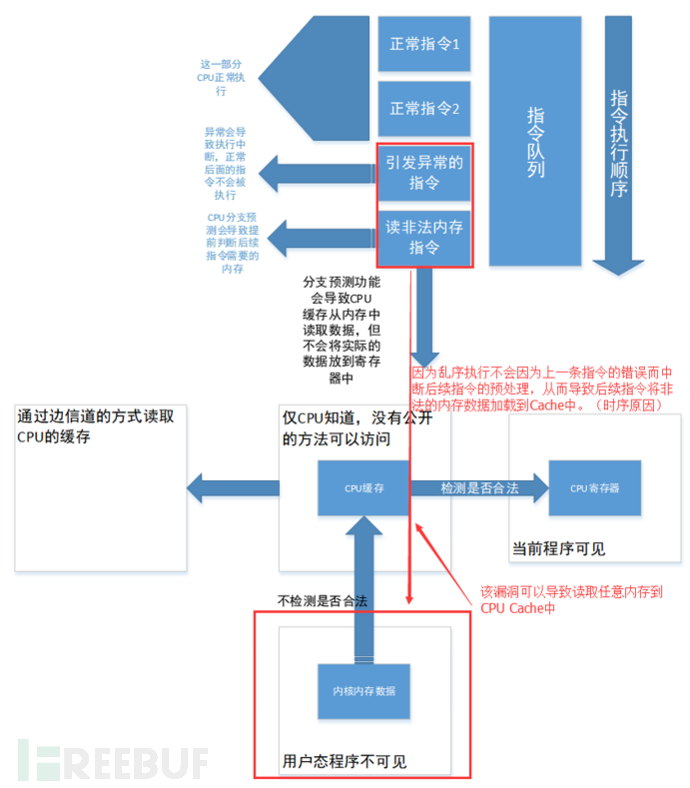
在较高的级别上,Spectre攻击通过将推测性执行与通过微架构隐蔽通道进行的数据过滤相结合,从而违反了内存隔离边界。更具体地说,要发起Spectre攻击,攻击者首先要在进程地址空间中定位或引入一系列指令,这些指令在执行时充当隐蔽的通道发射器,泄漏受害者的内存或寄存器内容。然后攻击者推测性地欺骗CPU并错误地执行这个指令序列,从而通过隐蔽通道泄漏受害者的信息。最后,攻击者通过隐蔽通道获取受害者的信息。虽然这种错误的推测性执行所导致的对名义CPU状态的更改最终会被恢复,但是之前泄漏的信息或对其他CPU微体系结构状态(例如缓存内容)的更改可以在名义状态恢复后继续存在。
上面关于Spectre攻击的描述是一般的,需要具体实例化,用一种方法来诱导错误的推测性执行,以及用一个微架构的隐蔽通道。虽然对于隐蔽通道组件有多种选择,但本工作中描述的实现使用基于cache的隐蔽通道,即, Flush+Reload, Evict+Reload。
接下来将描述本文的技术,即诱导和影响错误的投机执行。
2.2.1 变种1: Exploiting Conditional Branches
在Spectre攻击的这种变体中,攻击者诱使CPU的分支预测器错误地预测了分支的方向,导致CPU通过执行本来不会执行的代码,暂时违反了程序语义。正如作者所展示的,这种不正确的推测性执行允许攻击者读取存储在程序地址空间中的秘密信息。实际上,考虑以下代码示例:
if ( x < array1_size)
y = arrat2[array1[x] * 4096];
在上面的例子中,假设变量x包含攻击者控制的数据。为了确保对array1的内存访问的有效性,上面的代码包含一个if语句,其目的是验证x的值是否在一个合法的范围内。我们展示了攻击者如何绕过这个if语句,从而从进程的地址空间读取潜在的秘密数据。首先,在初始误译阶段,攻击者使用有效的输入调用上面的代码,从而训练分支预测器期望if为真。接下来,在攻击阶段,攻击者使用array1界限之外的x值调用代码。结果,而不是等待确定分支CPU猜测界限检查将是真实的,已经大胆执行指令,评估array2 [array1 [x] * 4096]使用恶意x。注意,从array2中读取的数据使用恶意的x将数据加载到依赖于array1[x]的地址的缓存中,并进行缩放,以便访问不同的缓存线路并避免硬件预取的影响。
当边界检查的结果最终被确定时,CPU发现它的错误,并恢复对其名义微体系结构状态所做的任何更改。但是,对缓存状态所做的更改不会被恢复,因此攻击者可以分析缓存内容,并在从受害者的内存中读取的越界读取中找到潜在的秘密字节的值。
2.2.2 变种2:利用间接分支
根据面向返回的编程(ROP),在这种变体中,攻击者从受害者的地址空间中选择一个gadget,并影响受害者推测性地执行这个gadget。与ROP不同,攻击者不依赖于受害者代码中的漏洞。相反,攻击者训练分支目标缓冲区(BTB)将分支从间接分支指令错误地预测到gadget的地址,从而导致gadget的投机性执行。与前面一样,虽然不正确的推测执行对CPU名义状态的影响最终会恢复,但它们对缓存的影响不会恢复,因此允许小部件通过缓存端通道泄漏敏感信息。我们通过经验证明了这一点,并展示了gadget选择是如何允许这种方法读取受害者的任意内存的。
为了误导BTB,攻击者在受害者的地址空间中找到gadget的虚拟地址,然后对该地址执行间接分支。这种训练是在攻击者的地址空间中完成的。不管攻击者的地址空间中的gadget地址是什么;所需要的只是攻击者在训练期间的虚拟地址与受害者的虚拟地址匹配(或别名)。事实上,只要攻击者处理异常,即使攻击者的地址空间中没有映射到小工具的虚拟地址的代码,攻击也可以工作。
2.2.3 其他变体
可以通过改变实现推测性执行的方法和泄漏信息的方法来设计进一步的攻击。示例包括mistraining return instructions、通过时间变化泄漏信息和算术单元争用。
2.3 目标硬件与当前状态
Hardware:本文已经通过经验验证了几个Intel处理器在Spectre攻击下的脆弱性,包括Ivy Bridge, Haswell, Broadwell, Skylake,和Kaby Lake处理器。作者还验证了该攻击对AMD Ryzen cpu的适用性。最后,作者还成功地组织了Spectre对流行手机上的几款基于arm的三星和高通处理器的攻击。
Current Status:使用负责任的披露实践,这篇论文的独立作者小组向部分重叠的CPU供应商和其他受影响的公司提供了结果的初步版本。在与工业界的协调下,作者还参与了对结果的封锁。Spectre族的攻击记录在CVE-2017-5753和CVE-2017-5715中。
2.4 Meltdown
Meltdown是一个相关的微体系结构攻击,它利用无序执行来泄漏内核内存。Meltdown和Spectre攻击有两个主要的区别。首先,与Spectre不同,Meltdown不使用分支预测。相反,它依赖于这样一种观察:当一条指令导致一个陷阱时,在终止之前乱序执行接下来的指令。其次,Meltdown利用了许多Intel和一些ARM处理器特有的漏洞,允许某些推测性执行的指令绕过内存保护。结合这些问题,Meltdown从用户空间访问内核内存。这种访问会导致一个陷阱,但是在陷阱发出之前,访问之后的指令会通过一个缓存隐蔽通道泄漏所访问的内存的内容。
相比之下,Spectre攻击的范围更广,包括大多数AMD和ARM处理器。此外,KAISER机制已经被广泛应用来缓解熔解攻击,但它并不能保护Spectre。
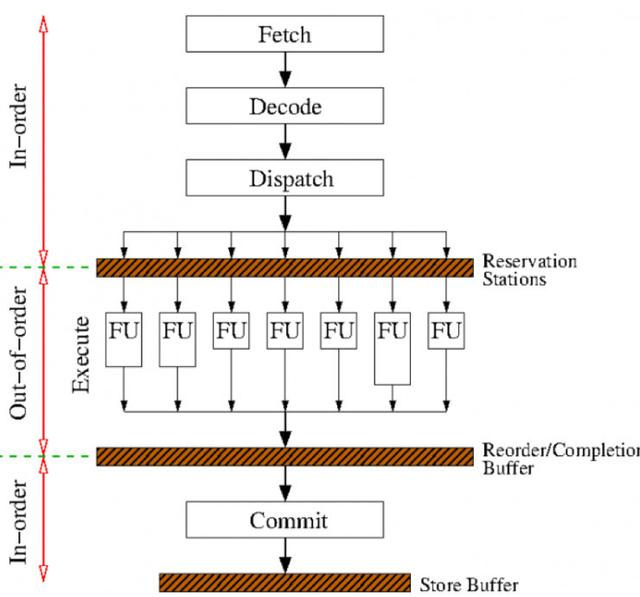
三、背景
在本节中,本文介绍了现代高速处理器的一些微体系结构组件,它们如何提高性能,以及它们如何泄漏运行程序中的信息。作者还描述了面向返回的编程(ROP)和gadget。
3.1 乱序执行
无序执行范例增加了处理器组件的利用率,因为它允许沿着程序的指令流向下的指令与指令并行执行,有时甚至在指令之前执行。
现代处理器在内部使用微操作系统,模拟体系结构的指令集,即,指令被解码成微操作。一旦与一条指令相对应的所有微操作以及之前的所有指令都完成了,这些指令就可以退役,将它们的更改提交到寄存器和其他体系结构状态,并释放重新排序缓冲区空间。因此,指令按照程序执行顺序退役。
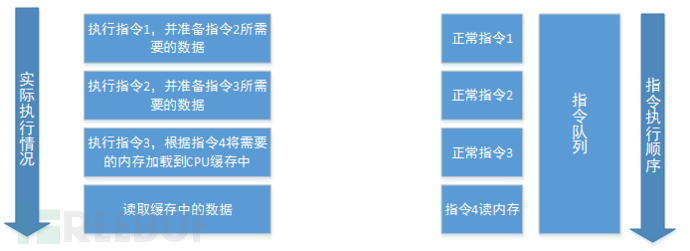
3.2 预测执行
处理器通常不知道程序的未来指令流。例如,当out-of-order执行到达一个条件分支指令时发生这种情况,该条件分支指令的方向依赖于尚未完成执行的前一个指令。在这种情况下,处理器可以保持当前的寄存器状态,对程序将遵循的路径做出预测,并推测地沿着该路径执行指令。如果预测结果是正确的,那么就会提交推测执行的结果(即(保存),从而获得与等待期间空闲相比的性能优势。否则,当处理器确定它走了错误的路径时,它会放弃推测性地执行的工作,通过恢复它的寄存器状态并沿着正确的路径恢复。
本文指的是执行错误的指令(错误预测的结果),但可能会留下微结构上的痕迹,如瞬态指令。虽然推测性的执行维护程序的体系结构状态,就好像执行遵循正确的路径一样,但是微体系结构元素可能处于与瞬时执行之前不同的(但有效的)状态。现代cpu上的推测执行可以运行数百条指令。该限制通常由CPU中重新排序缓冲区的大小决定。例如,在Haswell微体系结构上,重新排序缓冲区有足够的空间容纳192个微操作。由于微操作的数量和指令之间没有一一对应的关系,所以限制取决于所使用的指令。
3.3 分支预测
在猜测执行期间,处理器对分支指令的可能结果进行猜测。更好的预测通过增加可以成功提交的推测性执行操作的数量来提高性能。
现代Intel处理器的分支预测器,例如Haswell Xeon处理器,对于直接分支和间接分支有多种预测机制。间接分支指令可以跳转到运行时计算的任意目标地址。例如,x86指令可以跳转到寄存器、内存位置或堆栈上的地址,例如“jmp eax”、“jmp [eax]”和“ret”。间接分支也支持ARM(例如,“MOV pc, r14”)、MIPS(例如,“jr $ra”)、RISC-V(例如,“jalr x0,x1,0”)和其他处理器。为了补偿与直接分支相比的额外灵活性,使用至少两种不同的预测机制[35]对间接跳转和调用进行了优化。
英特尔中的处理器分支预测:
- “直接调用和跳跃(Direct Calls and Jumps)”:以静态或单调的方式
- “间接调用和跳跃(Indirect Calls and Jumps)”:以单调的方式,或以不同的方式,这取决于最近的程序行为,
- “条件分支(Conditional Branches)”:分支目标和是否采取分支。
因此,使用几个处理器组件来预测分支的结果。分支目标缓冲区(BTB)保持从最近执行的分支指令的地址到目标地址的映射。处理器可以使用BTB来预测未来的代码地址,甚至在对分支指令进行解码之前也是如此。Evtyushkin等人的分析了Intel Haswell处理器的BTB,并得出结论,只有分支地址的31个最低有效位被用来索引BTB。
对于条件分支,记录目标地址对于预测分支的结果是不必要的,因为当条件在运行时确定时,目标地址通常编码在指令中。为了改进预测,处理器维护分支结果的记录,包括最近的直接和间接分支。Bhattacharya等人分析了近年来Intel处理器中分支历史预测的结构。
虽然返回指令是间接分支的一种类型,但是在现代cpu中经常使用一种独立的机制来预测目标地址。返回堆栈缓冲区(RSB)维护调用堆栈中最近使用的部分的副本。如果RSB中没有可用的数据,则不同的处理器将停止执行或使用BTB作为备份。分支预测逻辑,例如BTB和RSB,通常不会在物理核心之间共享。因此,处理器只能从在同一核心上执行的以前的分支中学习。
3.4 内存层次结构
为了弥补速度更快的处理器和速度较慢的内存之间的速度差距,处理器使用连续的更小但更快的缓存层次结构。cache将内存分成大小固定的块,称为行,典型的行大小为64或128字节。当处理器需要来自内存的数据时,它首先检查位于层次结构顶部的L1 cache是否包含副本。在cache命中的情况下,即,数据在cache中找到,数据从L1 cache中检索并使用。否则,在cache丢失的情况下,将重复此过程,以尝试从下一个cache级别(最后是外部内存)检索数据。一旦读操作完成,数据通常会存储在cache中(以前cache的值会被清除以腾出空间),以备在不久的将来再次需要它。现代英特尔处理器通常有三个cache级别,每个核心有专用的L1和L2 cache,所有核心共享一个公共的L3 cache,也称为最后一级cache(LLC)。
处理器必须使用缓存一致性协议(通常基于MESI协议)确保每核L1和L2缓存是一致的。特别是使用MESI协议或它的一些变异意味着内存写操作在一个核心将导致相同的副本数据的L1和L2缓存其他核标记为无效的,也就是说,未来的访问这些数据在其他核将无法快速加载数据从L1和L2缓存。当这种情况在特定的内存位置重复发生时,这被非正式地称为cache-line bouncing.因为内存是按行粒度缓存的,所以即使两个内核访问了映射到同一高速缓存行的不同内存位置,也会发生这种情况。这种行为称为错误共享,众所周知,它是性能问题的根源。有时可以滥用缓存一致性协议的这些属性来替代使用clflush指令或清除模式的缓存清除。这一行为之前被认为是促进Rowhammer攻击的潜在机制 (memory cache 映射问题)。
3.5 微体系结构侧通道攻击
本文上面讨论的所有微体系结构组件都通过预测未来的程序行为来提高处理器性能。为了达到这个目的,它们保持依赖于过去程序行为的状态,并假设将来的行为与过去的行为相似或相关。当多个程序在同一硬件上执行时,无论是并发执行还是分时执行,由一个程序的行为引起的微体系结构状态的变化可能会影响到其他程序。这进而可能导致从一个程序到另一个的意外信息泄漏。最初的微体系结构侧通道攻击利用的时间变异性和L1数据缓存的泄漏来从密码原语中提取密钥。多年来,通道已经在多个微体系结构组件上进行了演示,包括指令缓存、lower level caches、BTB和分支历史。攻击的目标已经扩展到包括协同定位检测、破坏ASLR、按键监测、网站指纹识别和基因组处理。最近的结果包括跨内核和跨cpu攻击、基于云的攻击、对可信执行环境的攻击、来自移动代码的攻击和新的攻击技术。
在这项工作中,作者使用Flush+Reload技术,及其变体Evict+Reload,用于泄漏敏感信息。使用这些技术,攻击者首先从与受害者共享的缓存中清除缓存线。在受害者执行一段时间后,攻击者度量在与被驱逐的高速缓存线对应的地址上执行内存读取所需的时间。如果受害者访问了被监控的高速缓存线路,数据将在高速缓存中,访问将是快速的。否则,如果受害者没有访问该行,读取将会很慢。因此,通过测量访问时间,攻击者可以知道受害者是否在清除和探测步骤之间访问了被监视的高速缓存线路。
这两种技术之间的主要区别是用于从缓存中清除受监视的高速缓存线路的机制。在Flush+Reload技术中,攻击者使用专用的机器指令,例如x86的clflush,来删除行。使用Evict+Reload,通过强制对存储该行的缓存集进行争用来实现驱逐,例如,通过访问加载到缓存中的其他内存位置,并且(由于缓存的大小有限)导致处理器丢弃(驱逐)随后探测的行。
3.6 返回导向编程ROP
ROP (Return-Oriented Programming, ROP)是一种技术,它允许攻击者劫持控制流,通过将在脆弱的受害者代码中找到的机器代码片段(称为gadget)链接在一起,使受害者执行复杂的操作。更具体地说,攻击者首先在受害二进制文件中找到可用的gadget。每个gadget在执行返回指令之前执行一些计算。攻击者可以修改堆栈指针,例如,指向写入外部可写缓冲区的返回地址,或者覆盖堆栈内容,例如,使用缓冲区溢出,可以使堆栈指针指向一系列恶意选择的gadget地址的开头。执行时,每个返回指令从堆栈跳转到目标地址。因为攻击者控制着这一系列的地址,所以每次返回都会有效地跳转到链中的下一个gadget。(这个具体做法)
四、攻击概述
4.1 攻击的整体过程
Spectre攻击会诱导受害者进行推测性的操作,而这些操作在程序指令的严格串行顺序处理过程中是不会发生的,并且会通过隐蔽的渠道将受害者的机密信息泄露给对手。本文首先描述变异,利用条件错误(第四部分),然后变异,利用了目标的间接分支(V)节。在大多数情况下,攻击从一个设置阶段开始,在这个阶段中,对手执行的操作会使处理器失效,这样它以后就会利用错误的推测性预测。此外,设置阶段通常包括一些步骤,这些步骤有助于诱导推测性的执行,例如操作缓存状态以删除处理器确定实际控制流所需的数据。在设置阶段,对手也可以准备隐蔽通道,用于提取受害者的信息,例如,通过执行冲洗或驱逐部分的Flush+Reload or Evict+Reload attack。
在第二阶段,处理器推测性地执行指令,将机密信息从受害者上下文中传输到一个微结构的隐蔽通道。这可能是由攻击者请求受害者执行操作触发的,例如,通过系统调用、套接字或文件。在其他情况下,攻击者可能利用自己代码的推测(误)执行来从同一进程获取敏感信息。例如,被解释器、实时编译器或“安全”语言沙箱化的攻击代码可能希望读取它不应该访问的内存。虽然推测性执行可能通过广泛的隐蔽通道公开敏感数据,但是给出的示例导致推测性执行首先读取攻击者选择的地址上的内存值,然后执行修改缓存状态的内存操作(以公开该值的方式)。
在最后阶段,恢复敏感数据。对于使用Flush+Reload或Evict+Reload的Spectre攻击,恢复过程包括定时访问被监视的高速缓存线路中的内存地址。Spectre攻击只假设推测执行的指令可以从内存中读取,而受害进程可以正常访问,例如,不会触发页面错误或异常。因此,Spectre与Meltdown是正交的,它利用一些cpu允许用户指令无序执行的场景来读取内核内存。因此,即使处理器阻止用户进程中指令的投机性执行来访问内核内存,Spectre攻击仍然可以工作。
4.2 利用条件分支预测失误
在本节中,作者演示攻击者如何利用条件转移错误预测从另一个上下文(例如另一个进程)读取任意内存。考虑这样一种情况,Listing1中的代码是一个函数(例如,一个系统调用或一个库)的一部分,该函数从一个不可信的源接收一个无符号整数x。运行该代码的进程可以访问大小为array1_size的无符号字节数组array1和大小为1mb的第二个字节数组array2。
if ( x < array1_size)
y = arrat2[array1[x] * 4096];
代码片段以对x的边界检查开始,这对安全性至关重要。特别是,这种检查防止处理器读取array1之外的敏感内存。否则,超出边界的输入x可能触发异常,或者通过提供x =(要读取的秘密字节的地址)- (array1的基本地址),导致处理器访问敏感内存。
公式演示了结合推测性执行的边界检查的四种情况。在知道边界检查的结果之前,CPU通过预测比较的最可能结果来推测性地执行符合条件的代码。有很多原因可以解释为什么边界检查的结果不能立即知道,例如,在边界检查之前或期间的缓存丢失,边界检查所需执行单元的拥塞,复杂的算术依赖关系,或嵌套的推测性执行。然而,正如所示,在这些情况下,对条件的正确预测将导致更快的整体执行。
不幸的是,在投机执行期间,边界检查的条件分支可能遵循错误的路径。在这个例子中,假设一个对手使得代码运行如下:
- x的值是恶意选择的(越界),比如array1[x]解析为受害者内存中的某个秘密字节k;
- array1_size和array2未被缓存,但k被缓存;
- 以前的操作接收到的x值是有效的,这导致分支预测器假设if可能为真。
实验在多种x86处理器架构上进行,包括Intel Ivy Bridge(i7-3630QM),Intel Haswell(i7-4650U),Intel Skylake(Google Cloud上未指定的Xeon)和AMD Ryzen。在所有这些CPU上都发现了Spectre漏洞。在32位和64位模式以及Linux和Windows上都观察到了相似的结果。一些ARM处理器还支持推测执行,并且初步测试已确认ARM处理器也受到影响。推测执行可以远远领先于主处理器。例如,在用于大多数测试的i7 Surface Pro 3(i7-4650U)上,附录A中的代码可在源代码中的“ if”语句和行访问数组1/数组2之间插入多达188条简单指令。
4.3 利用间接分支实现幽灵攻击
间接分支跳转的优势:可以跳转到更多的地方,条件分支指令只能跳转到两个地方。
如果由于cache miss而延迟了间接分支的目标地址确定,并且间接分支预测器被使用恶意的目标地址错误训练,则就可能会在攻击者选择的地址进行推测执行。此时即使没有可利用的条件分支错误预测的情况下,也会暴露受害者内存。
攻击前提:当间接分支跳转发生时,攻击者可以控制两个寄存器的值(R1,R2)。攻击前提的一种实际情况:处理外部接收到的数据的函数内部进行函数调用,传入的数据(可以控制)在寄存器(R1,R2)中,寄存器(R1,R2)在调用函数时会被压入堆栈中,在结束时恢复。
攻击者首先在受害者的可执行内存(二进制代码或者库函数中)中寻找一个gadget。一个gadget的示例:包含两条指令(不一定相邻),一条根据R1寄存器寻址内存,然后将结果加到R2中,另一条是根据R2的数据作为地址,访问内存。(对于某些gadget,攻击者控制单个寄存器、堆栈上的值或内存值就足够了)。
这种攻击方式很类似于ROP,但是它不需要gadget正确的返回,因为推测错误最终会终止它的执行。
BTB mistraining实际测试:在intel x86处理器的一个超线程上执行代码能够错误训练分支预测器,使得另一个在同一个CPU的超线程也受到影响。在Skylake处理器上测试的结果表明,在相同的vCPU上的进程之间也可以相互影响分支预测器。
一些攻击实现的硬件选择和OS选择:
- gadgets需要在受害者的可执行的内存范围内,否则无法进行推测执行。
- 多个windows程序共享一个dll时,通常会加载一个副本并且映射到所有进程的相同虚拟地址上。几乎所有的windows程序包含的DLL,都包括足够搜索gadget的可执行代码。
- 分支预测器只关注分支目标的虚拟地址,其它的类似于指令源地址,物理地址,时间和进程ID似乎无关紧要(意味着其它进程可以mistraining BTB)。
- 分支预测器只需要使用虚拟地址的低若干位进行索引,因此攻击者并不需要一定使用固定的一样的分支地址进行训练。同时低0-15位并不会被ASLR影响。
- 在攻击者中训练分支预测器,尽管由于跳转到非法目的地址会引发异常,但是可以简单的捕获异常,并不会终止程序等。
- 对于分支预测器的错误训练影响无法传递到其它的CPU,即分支预测器在每个CPU上是独立的。
- DLL的代码和常量数据区域可以被任何使用DLL的进程读取和刷新,意味着可以使用这些区域作为flush+probe攻击的探测表(类似于array2)。
- DLL使用了copy-on-write机制,即本来共享的DLL,如果某个进程需要写DLL,则会将其复制一份,然后再写,并且该进程只可见复制之后的副本,其它进程仍旧看到未修改之前的DLL。
4.4 在Windows上实现利用BTB的幽灵攻击
一个简单的受害者程序:生成一个随机键值,然后死循环调用{Sleep(0), load文件的前几个字节(文件头),调用windows的cryto函数(加密使用)计算SHA-1哈希值,最后打印hash值,如果文件头发生变化,则打印出hash值}。在优化编译此程序的时候,会使用寄存器ebx,edi中的文件数据(load的数据)调用Sleep函数。
寻找一些共享DLL的memory,用于之后的flush-and-probe检测使用。寻找gadget,可以推测执行使用ebx和edi,这两个值可以被攻击者控制。寻找到的结果(ntdll.dll中):
adc edi,dword ptr [ebx+edx+13BE13BDh]
adc dl,byte ptr [edi]
当攻击者设定ebx=m - 0x13BE13BD - edx (edx=3),第一条指令会从m处读取32位值,将加到edi上(不考虑进位,提前被清除了)。攻击者控制edi的值,第二条指令会利用计算的地址将数据加载到cache中。因为edi已知,因此最终判断cache中是否有该地址范围的数据即可。
错误训练sleep函数的第一条指令:jmp dword ptr ds:[76AE0078h] ,使其可以跳转到gadget的位置。同时需要保证指令中原本的目的地址没有被放到cache中。
将带有跳转指令的内存页设置为可写的状态(copy-on-write),然后将跳转的目的地址修改为gadget的地址。然后将包含gadget的内存页也设置为可写状态,然后在gadget指令序列结尾增加ret指令,以返回跳转指令的地方。使用一个单独的线程,返回清除受害者包含跳转指令的目的地址的内存地址在mistraining的线程中,会有一个循环,不断将映射地址(gadget的地址)压入堆栈,然后初始化时设置的返回指令将会根据堆栈的内容跳转到gadget,然后从gadget的返回指令再跳转回来。训练使用的返回指令被初始化在一个1MB的可执行区域中(20位,可能是为了ASLR带来的影响)。通过这样的训练,BTB则会被错误训练指向gadget的地址。
4.5 幽灵的其它变种
4.5.1 使用Evict+time带来flush+reload
if (false but mispredicts as true)
read array1[R1]
read [R2]
测量操作执行的时间,并且这种操作依赖于cache的状态。
在上述的代码中,R1是敏感数据,如果array1[R1]在cache中,则读取R2地址的操作将会很快完成,如果不在cache中,则读取R2的操作将会更慢。因此可以通过测量这些操作的时间,来判断R1是哪一个(即cache中只包括一个)。
这种方式,如果推测执行无法修改cache的状态,也仍旧可以泄露数据。
4.5.2 指令执行的时间(instruction timing)
某些指令的执行时间依赖于操作数,这些指令就可以用于泄露数据。在代码中,推测执行中使用了乘法器计算R1*R2,通过测量之后乘法器多久后可用的时间,来揭示R1和R2的信息
if (false but mispredicts as true)
multiply R1, R2
multiply R3, R4
4.5.3 寄存器堆的争用
使用CPU中用于保存检查点的寄存器的变化来泄露数据。在下面的代码中,如果第二条if为真,则需要在多增加一个检查点,如果为假,则不需要。攻击者通过检查检查点存储的变化来判断R1的值。
if (false but mispredicts as true)
if (condition on R1)
if (condition)
4.6 防御措施
串行化指令,但是不是针对所有处理器或者系统配置的有效对策。可以在编译的时候使用静态分析,增加FENCE指令,但是问题在于可能无法全面的阻止(如果全部插入,性能会下降很多),同时代码也需要重新编译。
为了降低间接分支带来的问题,在上下文切换期间,禁用超线程和刷新分支预测器状态(似乎没有体系结构定义这种方法)。但是无法解决所有问题。
限制cache的对策并不是很充分,因为在推测执行的过程中也可能会泄露信息。此时需要考虑来自内存总线的竞争,DRAM行地址选择状态,虚拟寄存器的可用性(例如保存检查点的寄存器),ALU的可用性,以及分支预测器本身的状态所带来的时间影响。除此之外,还包括power等传统侧信道的影响因素。
五、复现结果
5.1 代码分析
具体见word文档
5.2 实验环境
- win10 家庭中文版1809 64位
- CPU:i5-9400
- 内存:16G

5.3 幽灵缺陷判断
1.https://gallery.technet.microsoft.com/scriptcenter/Speculation-Control-e36f0050下载SpeculationControl.zip
2.将下载文件解压放在某个文件夹下 。
3.用管理员权限打开 PowerShell.
4.进入 上述文件夹,运行下列三条指令
Set-ExecutionPolicy RemoteSigned -Scope Currentuser
Import-Module .SpeculationControl.psd1
Get-SpeculationControlSettings
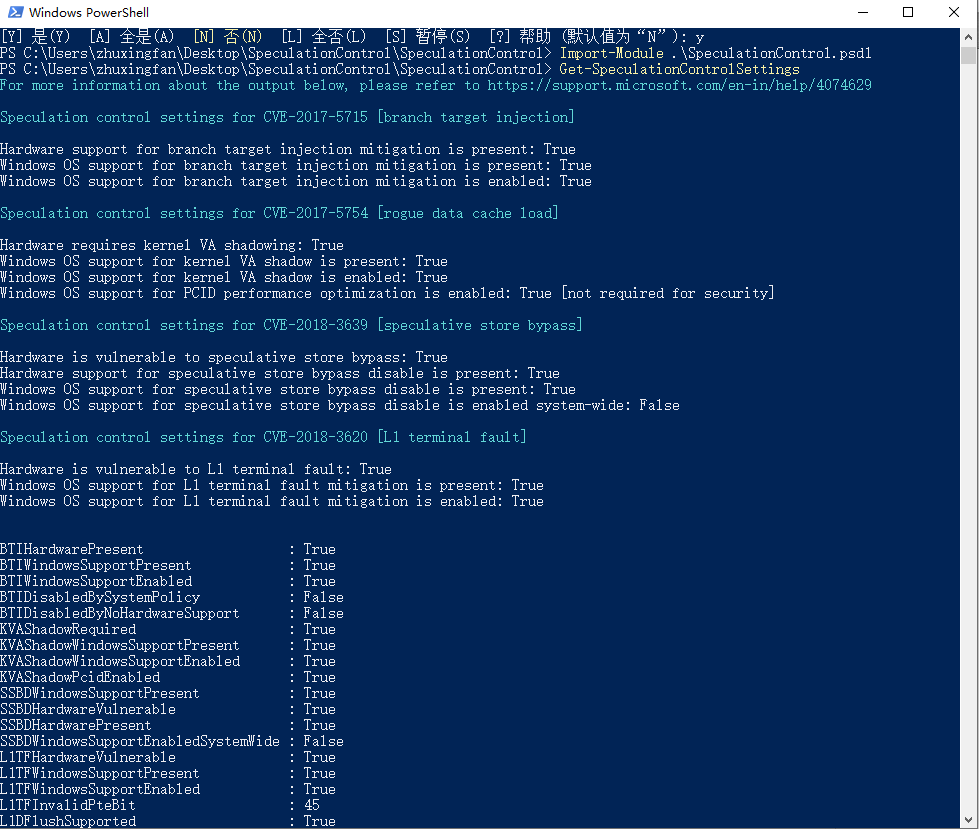
从上面可以看出,我的处理器i5-9400不存在 CVE-2017-5754 [rouge cache load] 漏洞,也就是没有熔断缺陷。如果提示信息是 “Hardware requires kernel VA shadowing: True”(硬件是否需要操作系统核心虚拟地址阴影化:是),那么你的处理器有“熔断”缺陷。
至于幽灵缺陷,网络上的很多说法危言耸听,说是这一缺陷虽然难以被利用,但永远无法消除。事实并非如此,很多处理器具有暂时关闭间接分叉预测的功能。这一功能甚至连某些著名专家都不知道 -- David Kanter 就在网络讨论中表现出对这一功能的陌生。以 AMD 的处理器为例,它们有两个设置,IBPB 与 IBRS,分别可以控制间接分叉预测缓存的清空与间接分叉预测限制。如果将 IBPB设为2,则 AMD处理器在进入核心高级模式前会将间接分叉预测记录清空,幽灵攻击就无法施展了。
对于INTEL处理器来说,必须将 IBRS设为1,也就是在核心模式下完全关闭间接分叉预测。这当然会产生一定的性能影响,但是影响应该不大 -- 一般系统调用都已经高度优化,关键部分甚至是手写的汇编代码。INTEL最大的问题是其独有的“熔断”缺陷。
5.4 攻击实验
1.根据《Spectre Attacks: Exploiting Speculative Execution》论文所给出的PoC代码,编译后生成可执行文件。
2.Windows安全中心会立刻报毒,说明该攻击已被纳入微软的安全计划中。

3.将幽灵攻击的exe文件添加信任,再次运行。
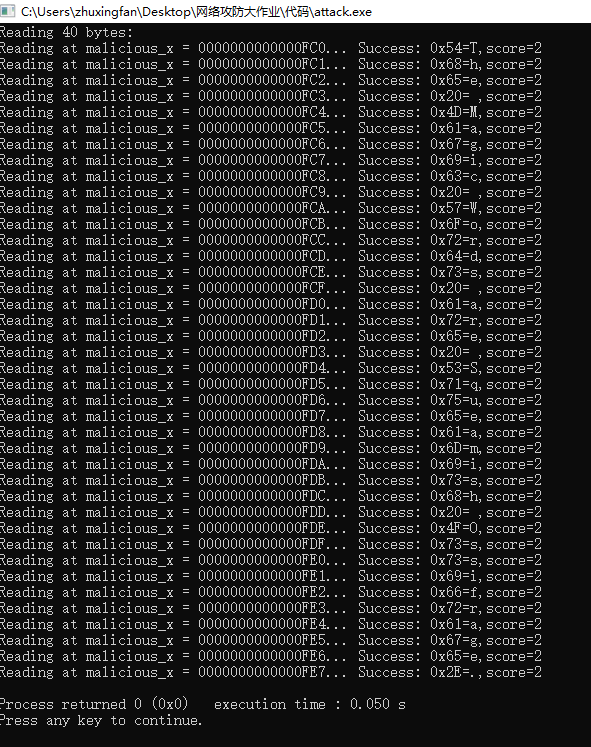
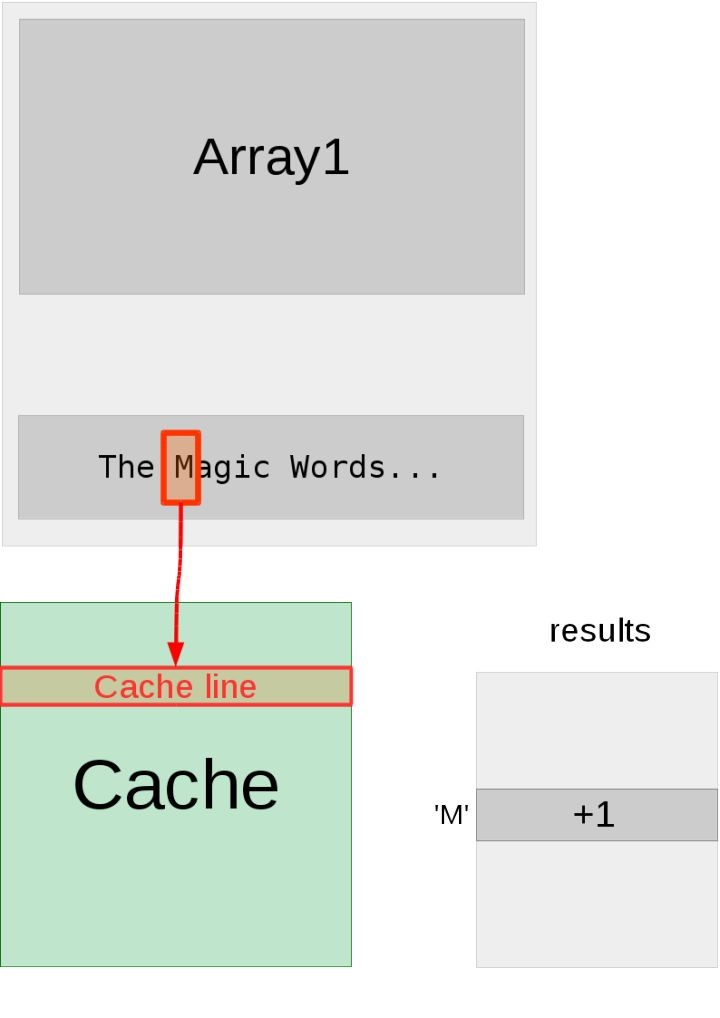
4.复现论文提到的攻击实验结果如图所示,可见攻击成功,显示出了受害者想保密的内容:“The Magic Words are Squeamish Ossifrage”。
5.5 解决方案
- 完全禁止乱序执行: 这不太可行,这对性能是毁灭性的打击。
- 序列化的权限检测:就是每次取内存的时候都检查一下权限,但是这样性能消耗也非常大,也不太可行。
- 通过物理内存隔离来实现:这可以通过现代内核使用CPU控制寄存器(例如CR4)中的新的硬分离位来启用。如果hardsplit位被设置,内核必须驻留在地址空间的上半部分,用户空间必须驻留在地址空间的下半部分。通过这种硬分割,内存提取可以立即识别目标的这种提取是否会违反安全边界。 现在的物理内核中用户态和内核态并非隔离的,而是杂乱的排在一起。 弃用硬隔离后两者的物理地址空间直接隔离,那么检测是否有违反安全边界就很简单了。
新的内核采用第三种方案,也就是KAISER,在Linux正式版本中叫做KPTI。 可能是将用户态进程的内核栈从内核的线性映射改为非线性映射,类似于用户态。 但是用户态和内核态的栈必须隔离,安全起见。 所以还需要一些工作就是防止CR4切换带来的cache失效。
六、分析感悟
6.1 遇到的问题及分析
6.1.1 array2大小为何是256*512?
根据论文中提到的存储器层次结构和一些资料,这可能是因为系统中存在多重缓存,把内存中某处的数值读到最高速的缓存中时,其相邻的值很可能也会被读到比它次一级的高速缓存,在次一级的高速缓存中的数值被读取的速度同样非常快,可能会影响程序中用读取时间判断是否命中。
6.1.2 幽灵漏洞的防护问题?有解决方案吗?
目前很多处理器具有暂时关闭间接分叉预测的功能。以 AMD 的处理器为例,它们有两个设置,IBPB 与 IBRS,分别可以控制间接分叉预测缓存的清空与间接分叉预测限制。如果将 IBPB设为2,则 AMD处理器在进入核心高级模式前会将间接分叉预测记录清空,幽灵攻击就无法施展了。
6.1.3 幽灵漏洞对个体用户的影响大吗?
对于普通用户而言,漏洞可造成的主要危害在于用浏览器访问了一个带有漏洞利用代码的网页,导致敏感信息(账号密码等)泄露。只要养成良好的上网习惯,不轻易点击陌生人发来的链接,基本不会受到漏洞影响;同时,浏览器针对漏洞发布的补丁和缓解措施简单有效,而且不会造成性能下降或兼容性问题,用户可以选择将浏览器升级到最新版本,从而避免受到漏洞攻击。
6.2 个人感悟
CPU性能的提升带来了计算机速度的飞速提升,但是提升性能的代价是一些非显性的安全问题,熔断和幽灵都是如此,想要完全避免这中漏洞攻击,可以通过打补丁修改机制,不过会降低性能,也可以更换硬件,从根本上解决问题,但是谁也说不好新的方案会不会有什么问题。幽灵攻击来无影去无踪,踏雪无痕,但是如同这篇文章做的工作一样,发现了问题,总有完美解决的一天,人类的科技进步也遵循这样发现问题-解决问题的规律。
虽然漏洞影响范围广泛,并引起全球关注,但受影响最大的主要是云服务厂商,对于普通用户来说,大可不必过于恐慌。首先,虽然漏洞细节以及PoC已经公开,但是并不能直接运用于攻击。漏洞运用于真实攻击还有许多细节问题需要解决,目前也没有一个稳定通用,同时可以造成明显严重后果(窃取账号密码等)的漏洞利用代码;
该文介绍的幽灵漏洞未来一段时间内仍然是各界关注的重点,需要安全团队对漏洞动态保持持续关注,同时对漏洞做更加深入的分析和研究,从而为广大用户提供更加准确的参考信息,以及更加可靠的解决方案。
七、学习总结和建议意见
7.1 学习总结
这学期很有幸选了王老师的课。以前对密码和安全的看法只觉得网络攻防对日常用户的影响不大,经过一学期的学习发现,网络攻防涉及到我们的日常生活、学习等各个方面。《网络安全攻防》这门课程让我接触到更多的新技术,极大地开拓了我的视野,让我接触到更多的技术和研究方向。从攻防的角度出发,接触新的技术,让我看到了多种技术的结合使用,学科交叉与融合,在这之前很少能够想到可以把两个东西进行结合。对一篇论文的复现把课程由广度引向深度,让我在获得更多视角的同时,能够深入理解。很幸运选择了这门课,为我今后研二的科研工作打下了一个良好的开端、锻炼了我查找论文的能力、扩展了我们的视野。
7.2 建议意见
- 部门内容还是有点太难了,对基础薄弱的同学做起来很耗时间,尤其是还有其他课业的情况下。
- 对于理论性强的知识最好从实例出发或者与生活相关、密切的例子,这样更能吸引学生的注意力和兴趣。
- 复现论文的时候,重点可以放在每个人专攻的方向上,这样和之后的科研研究也契合,说不定会有新思路的产生
八、参考文献
参考文献
[1] Spectre Attacks: Exploiting Speculative Execution. https://arxiv.org/pdf/1801.01203.pdf.
[2] 幽灵攻击原理. https://www.cnblogs.com/kvm-qemu/articles/8283884.html.
[3] 解读CPU漏洞:熔断和幽灵. https://baijiahao.baidu.com/s?id=1589007257364714181&wfr=spider&for=pc.
[4] CPU 推测执行漏洞. https://www.jianshu.com/p/90a8d561ca26.
[5] 熔断漏洞原理. https://www.cnblogs.com/kvm-qemu/articles/8284508.html.
2020 年 7月 3日