mycat是什么?
1.mycat是一个彻底开源的,面向企业应用开发的大数据库集群,
2.支持事务、ACID、可以替代MySQL的加强版数据库,目前支持关系型数据库以及非关系型数据库
3.可以用来代替昂贵的oracle数据库
4.mycat是一个大数据(HDFS)的sql引擎
通过上面的介绍,我们知道,mycat其实就是一个数据库
为什么叫mycat?
mycat再初期的时候,是为了用来代替昂贵的oracle存在的,因此它支持的是免费的mysql数据库,也只支持mysql数据库,现在mycat已经可以支持多种数据库了,换句话说,mycat就是mysql的增强版。
再之前介绍架构,我们知道当数据库压力大的时候,使用独写分离和分库分表,但是mysql是不支持的,使用mycat来实现mysql独写分离和分库分表。
什么是HDFS?
HDFS:大数据的分布式文件存储系统
H:Hadoop(大数据),D:Distributed(分布式的),F:File(文件),S:System(系统)。
在大数据中,数据量是非常大的,如果有1PB的数据(1PB=1024TB),没有这么大的硬盘,那么数据应该如何存储呢?
将数据拆分为块,分别存储进不同的磁盘中,假设将这1P的数据,分为10份/20份,分别存储在10/20个磁盘上,当需要读取数据时,就从各个小的磁盘上来获取数据。
同样的,如果想要在1PB中查询一条数据,效率是非常低的,但是如果拆分为小块,查询数据时,直接到相应的块中查询,效率就会变高。
比如说:
1:在100条数据中查询第58条数据
2:将100条数拆分为10份,每份存十条,查询第58条数据,就到相应的块中查询数据,这就相当于在10条数据中查询一条数据
对比上面两种方式,可以看出第2种方式效率会比较高,当然这里假设的数据量比较少如果多的话呢?
HDFS就是通过第二种方式实现的,将大数据切分为块,分别存储到不同的服务器上,这个服务器称为数据节点DataNode(以下简称DN)。
那么现在的问题就是:如何确定要查询的数据存放在哪儿个数据节点上呢?
在之前写架构时,提到了,使用一个节点,这个节点就存放每个数据节点上存放的数据:
比如说,将1份很大的数据拆分为10份,然后将这十份数据标上号:1,2,3,...10。然后使用一个服务器节点,节点内容就是一号服务器放第一份和第三份数据,2号服务器放第2份和第四份数据.....这个节点就称为命名节点NameNode(以下简称NN)。
注意:在将数据拆分存储时,要保证每份数据在服务器集群中至少存在两个节点上。
NameNode是在内存中做计算的。(why?在内存中计算速度非常快,但是比较消耗内存资源)
下面使用一张图来帮助理解:

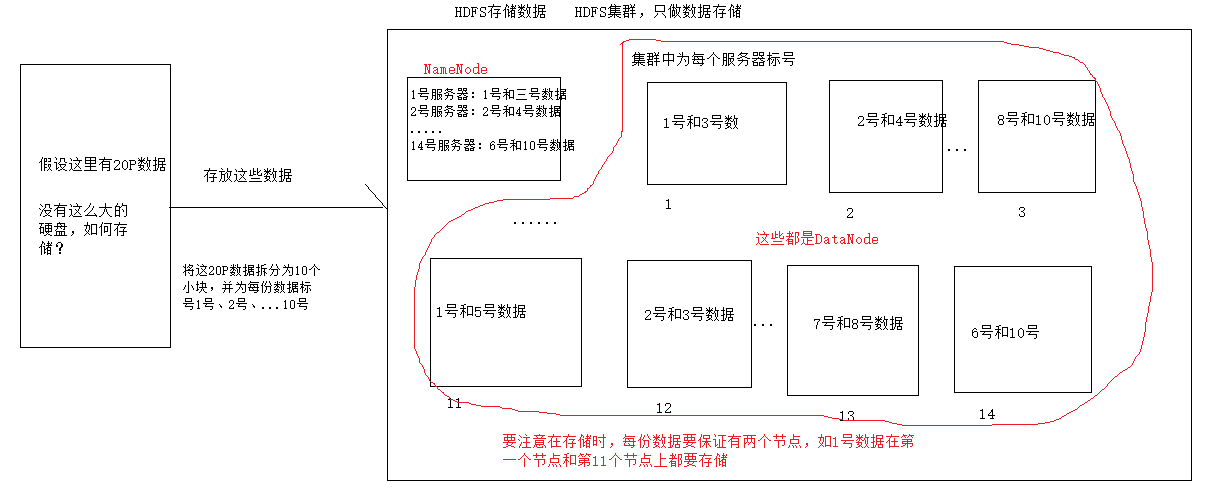
从这里可以看出,NN是非常重要的,获取数据都是通过NN来找数据的位置的,那么如果NN宕机,就获取不到一条数据了。
这里有一个问题,NN是在内存中做计算的,如果NN宕机,那么占用的内存资源就会被释放,NN中的数据就没有了,即使重启,也获取不到数据,如何解决?
NN每隔一个小时,就会将数据持久化到硬盘中,当NN重启后会从硬盘中加载数据,这个过程大概20秒。
问题2:NN宕机重启后,可以从磁盘中获取数据,但是NN宕机时并不工作,如何获取数据,以及存储新的数据节点,重启后如何保证存储的数据正确?
其实除了NN之外,还有一个备用命名节点SecondaryNameNode(以下简称SN),DN中的数据会定期的向NN和SN中分别保存,SN负责监视NN,但是SN不是NN的从节点。
SN会不定时的检测NN的持久化硬盘中的数据,一旦发现自己有的数据,硬盘中没有,就会向硬盘中存入数据,也就是说,SN和NN组合在一起成为一个新的硬盘,替换掉原来的NN的硬盘,当NN重启后,会从新的硬盘中加载数据到内存。
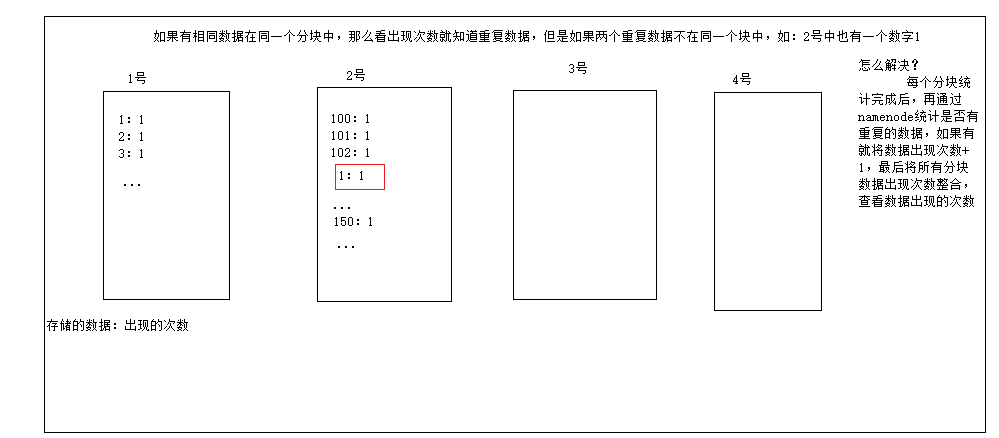
关于大数据时,总会问到的一个问题:如何在10G的数据中查询两条重复的数据?
看到这个问题,正常想到的可能会是for循环,但是当数据量非常大的时候,不能这样用,如果使用for循环,可能要查一个月,如何查找呢?
在HDFS中,查询两条相同数据,因为是分块查询,因此会每一块每一块的查询,并标记当前块中,每条数据出现的次数,如:
mycat就是使用的HDFS的方式实现的,不过这里将F该成了D,mycat是HDDS(High Distributed Data System),