承接上篇博客, 本文探究MyBatis中的Executor, 如下图: 是Executor体系图
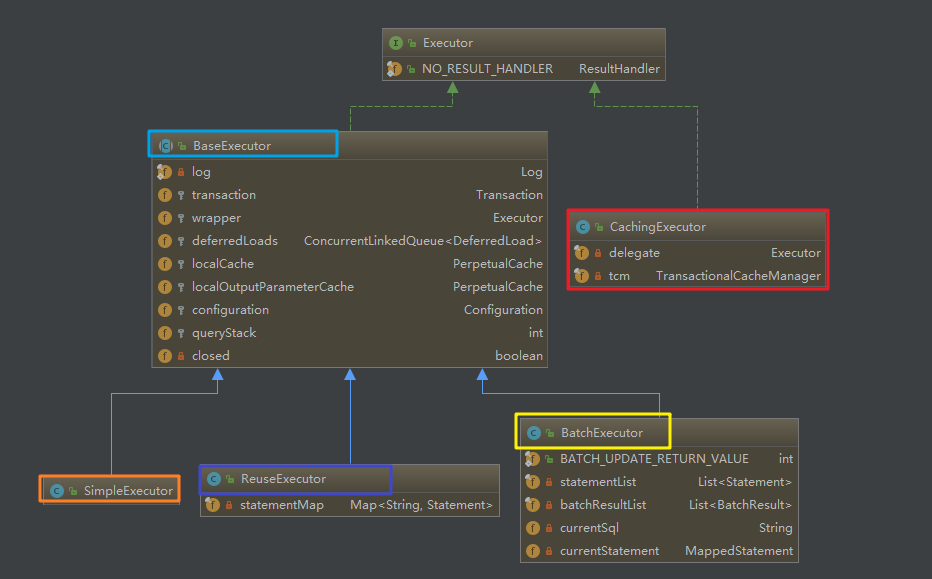
本片博客的目的就是探究如上图中从顶级接口Executor中拓展出来的各个子执行器的功能,以及进一步了解Mybatis的一级缓存和二级缓存
预览:
- BaseExecutor :实现了Executor的全部方法,包括对缓存,事务,连接提供了一系列的模板方法, 这些模板方法中留出来了四个抽象的方法等待子类去实现如下
protected abstract int doUpdate(MappedStatement ms, Object parameter)
throws SQLException;
protected abstract List<BatchResult> doFlushStatements(boolean isRollback)
throws SQLException;
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException;
protected abstract <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds, BoundSql boundSql)
throws SQLException;
- SimpleExecutor: 特点是每次执行完毕后都会将创建出来的statement关闭掉,他也是默认的执行器类型
- ReuseExecutor: 在它在本地维护了一个容器,用来存放针对每条sql创建出来的statement,下次执行相同的sql时,会先检查容器中是否存在相同的sql,如果存在就使用现成的,不再重复获取
- BatchExecutor: 特点是进行批量修改,她会将修改操作记录在本地,等待程序触发提交事务,或者是触发下一次查询时,批量执行修改
创建执行器
当我们通过SqlSessionFactory创建一个SqlSession时,执行openSessionFromDataBase()方法时,会通过newExecutor()创建执行器:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
通过这个函数,可以找到上面列举出来的所有的 执行器, MyBatis默认创建的执行器的类型的是SimpleExecutor,而且MyBatis默认开启着对mapper的缓存(这其实就是Mybatis的二级缓存,但是,不论是注解版,还是xml版,都需要添加额外的配置才能使添加这个额外配置的mapper享受二级缓存,二级缓存被这个CachingExecutor维护着)
BaseExecutor 的模板方法
在BaseExecutor的模本方法之前,其实省略了很多步骤,我们上一篇博文中有详细的叙述,感兴趣可以去看看,下面我就简述一下: 程序员使用获取到了mapper的代理对象,调用对象的findAll(), 另外获取到的sqlSession的实现也是默认的实现DefaultSqlSession,这个sqlSession通过Executor尝试去执行方法,哪个Executor呢? 就是我们当前要说的CachingExecutor,调用它的query(),这个方法是个模板方法,因为CachingExecutor只知道在什么时间改做什么,但是具体怎么做,谁取做取决于它的实现类
如下是BaseExecutor的query()方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
BaseExecutor维护的一级缓存
从上面的代码中,其实我们就跟传说中的Mybatis的一级缓存无限接近了,上面代码中的逻辑很清楚,就是先检查是否存在一级缓存,如果存在的话,就不再去创建statement查询数据库了
那问题来了,什么是这个一级缓存呢? **一级缓存就是上面代码中的localCache,如下图: **
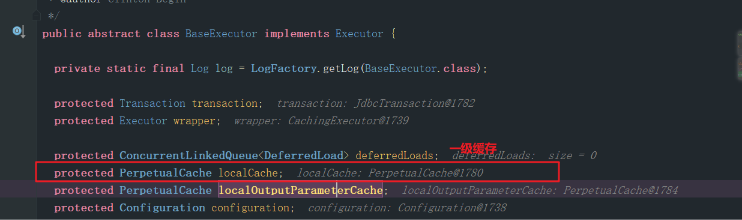
再详细一点就看下面这张图:

嗯! 原来传说中的一级缓存叫localCache,它的封装类叫PerpetualCache 里面维护了一个String 类型的id, 和一个hashMap 取名字也很讲究,perpetual意味永不间断,事实上确实如此,一级缓存默认存在,也关不了(至少我真的不知道),但是在与Spring整合时,Spring把这个缓存给关了,这并不奇怪,因为spring 直接干掉了这个sqlSession
一级缓存什么时候被填充的值呢?填充值的操作在一个叫做queryFromDataBase()的方法里面,我截图如下:
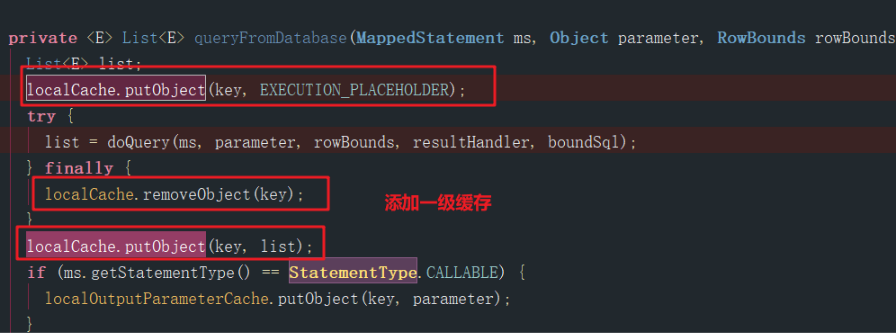
其中的key=1814536652:3224182340:com.changwu.dao.IUserDao.findAll:0:2147483647:select * from user:mysql
其实看到这里,平时听到的为什么大家会说一级缓存是属于SqlSession的啊,诸如此类的话就是从这个看源码的过程中的出来的结果,如果你觉的印象不深刻,我就接着补刀,每次和数据库打交道都的先创建sqlSession,创建sqlSession的方法会在创建出DefaultSqlSession之前,先为它创建一个Executor,而我们说的一级缓存就是这个Executor的属性
何时清空一级缓存
清空一级缓存的方法就是BaseExecutor的update()方法
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清空本地缓存
clearLocalCache();
// 调用子类执行器逻辑
return doUpdate(ms, parameter);
}
SimpleExecutor
SimpleExecutor是MyBatis提供的默认的执行器,他里面封装了MyBatis对JDBC的操作,但是虽然他叫XXXExecutor,但是真正去CRUD的还真不是SimpleExecutor,先看一下它是如何重写BaseExecutor的doQuery()方法的
详细的过程在这篇博文中我就不往外贴代码了,因为我在上一篇博文中有这块源码的详细追踪
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
创建StatementHandler
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
虽然表面上看上面的代码,感觉它只会创建一个叫RoutingStatementHandler的handler,但是其实上这里面有个秘密,根据MappedStatement 的不同,实际上他会创建三种不同类型的处理器,如下:
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
// 早期的普通查询,极其容易被sql注入,不安全
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
// 处理预编译类型的sql语句
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
// 处理存储过程语句
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
创建PreParedStatement
点击进入上篇博文,查看如何创建PreparedStatement
执行查询
关闭连接
关于SimpleExecutor如何关闭statement,在上面一开始介绍SimpleExecutor时,我其实就贴出来了,下面再这个叫做closeStatement()的函数详情贴出来
protected void closeStatement(Statement statement) {
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
// ignore
}
}
}
ReuseExecutor
这个ReuseExecutor相对于SimpleExecutor来说,不同点就是它先来的对Statement的复用,换句话说,某条Sql对应的Statement创建出来后被放在容器中保存起来,再有使用这个statement的地方就是容器中拿就行了
他是怎么实现的呢? 看看下面的代码就知道了
public class ReuseExecutor extends BaseExecutor {
private final Map<String, Statement> statementMap = new HashMap();
public ReuseExecutor(Configuration configuration, Transaction transaction) {
super(configuration, transaction);
}
嗯! 所谓的容器,不过是一个叫statementMap的HashMap而已
下一个问题: 这个容器什么时候派上用场呢? 看看下面的代码也就知道了--this.hasStatementFor(sql)
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
Statement stmt;
if (this.hasStatementFor(sql)) {
stmt = this.getStatement(sql);
this.applyTransactionTimeout(stmt);
} else {
Connection connection = this.getConnection(statementLog);
stmt = handler.prepare(connection, this.transaction.getTimeout());
this.putStatement(sql, stmt);
}
handler.parameterize(stmt);
return stmt;
}
最后一点: 当MyBatis知道发生了事务的提交,回滚等操作时,ReuseExecutor会批量关闭容器中的Statement
BatchExecutor
这个执行器相对于SimpleExecutor的特点是,它的update()方法是批量执行的
执行器提交或回滚事务时会调用 doFlushStatements,从而批量执行提交的 sql 语句并最终批量关闭 statement 对象。
CachingExecutor与二级缓存
首先来说,这个CachingExecutor是什么? 那就得看一下的属性,如下:
public class CachingExecutor implements Executor {
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
让我们回想一下他的创建时机,没错就是在每次创建一个新的SqlSession时创建出来的,源码如下,这就出现了一个惊天的大问号!!!,一级缓存和二级缓存为啥就一个属于SqlSession级别,另一个却被所有的SqlSession共享了? 这不是开玩笑呢? 我当时确实也是真的蒙,为啥他俩都是随时用随时new,包括上面代码中的TransactionalCacheManager也是随时用随时new,凭什么它维护的二级缓存就这么牛? SqlSession挂掉后一级缓存也跟着挂掉,凭什么二级缓存还在呢?
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
先说一下,我是看到哪行代码后意识到二级缓存是这么特殊的,如下:大家也看到了,下面代码中的tcm.getObject(cache, key);,是我们上面新创建出来的TransactionalCacheManager,然后通过这个空白的对象的getObject()竟然就将缓存中的对象给获取出来了,(我当时忽略了入参位置的cache,当然现在看,满眼都是这个cache)
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
我当时出现这个问题完全是我忽略了一部分前面解析配置文件部分的源码,下面我带大家看看这部分源码是怎么执行的
一开始MyBatis会创建一个XMLConfigBuilder用这个builder去解析配置文件(因为我们环境是单一的MyBatis,并没有和其他框架整,这个builder就是用来解析配置文件的)
我们关注什么呢? 我们关注的是这个builder解析<mapper>标签的,源码入下:
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
propertiesElement(root.evalNode("properties"));
...
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
关注这个方法中的configuration.addMapper(mapperInterface);方法,如下: 这里面存在一个对象叫做,MapperRegistry,这个对象叫做mapper的注册器,其实我觉得这是个需要记住的对象,因为它出现的频率还是挺多的,它干什么工作呢? 顾名思义,解析mapper呗 我的当前是基于注解搭建的环境,于是它这个MapperRegistry为我的mapper生成的对象就叫MapperAnnotationBuilder见名知意,这是个基于注解的构建器
public <T> void addMapper(Class<T> type) {
mapperRegistry.addMapper(type);
}
所以说我们就得去看看这个解析注解版本mapper的builder,到底是如何解析我提供的mapper的,源码如下:
public void parse() {
String resource = type.toString();
if (!configuration.isResourceLoaded(resource)) {
loadXmlResource();
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
parseCache();
parseCacheRef();
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
parseStatement(method);
}
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
方法千千万,但是我关注的是它的 parseCache();方法,为什么我知道来这里呢? (我靠!,我找了老半天...)
接下来就进入了一个高潮,相信你看到下面的代码也会激动, 为什么激动呢? 因为我们发现了Mybatis处理@CacheNamespace注解的细节信息
private void parseCache() {
CacheNamespace cacheDomain = type.getAnnotation(CacheNamespace.class);
if (cacheDomain != null) {
Integer size = cacheDomain.size() == 0 ? null : cacheDomain.size();
Long flushInterval = cacheDomain.flushInterval() == 0 ? null : cacheDomain.flushInterval();
Properties props = convertToProperties(cacheDomain.properties());
assistant.useNewCache(cacheDomain.implementation(), cacheDomain.eviction(), flushInterval, size, cacheDomain.readWrite(), cacheDomain.blocking(), props);
}
}
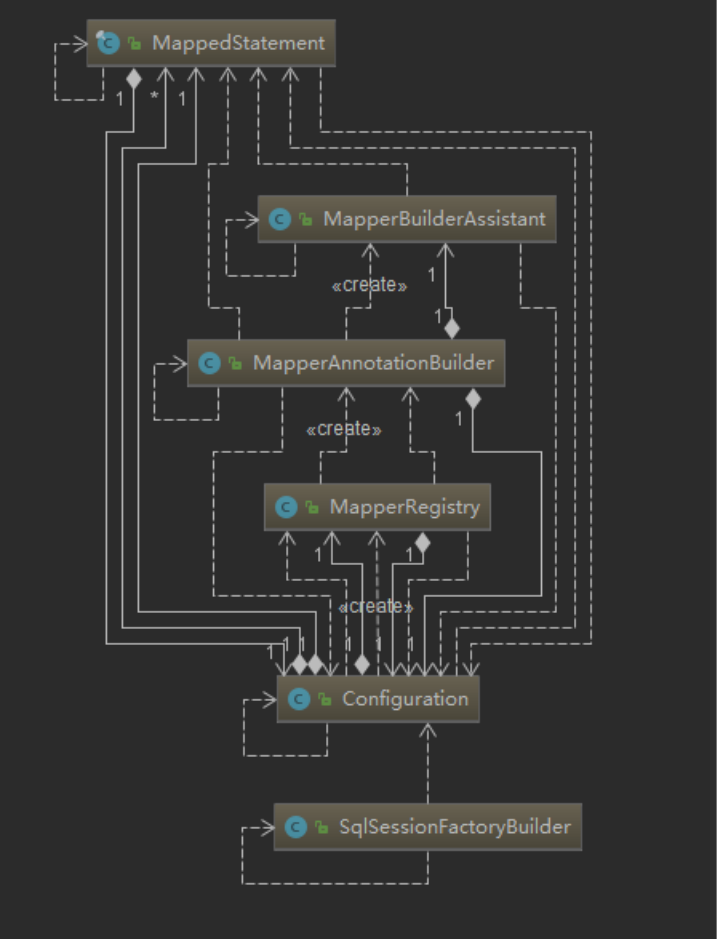
再往下跟进这个 assistant.useNewCache()方法,就会发现,MyBatis将创建出来的一个Cache对象,这个Cache的实现类叫BlockingCache
创建出来的对象给谁了?
- Configuration对象自己留了一份 (放在了 caches = new StrictMap<>("Caches collection");中)
- 当前类
MapperBuilderAssistant也保留一了一份 - 最主要的是
MappedStatement对象中也保留了一份mappedStatement.cache
说了这么多了,附上一张图,用来纪念创建这个Cache的成员
小结
其实上面创建这个Cache对象才是二级缓存者, 前面说的那个CachingExecutor中的TransactionalCacheManager不过是拥有从这个Cache中获取数据的能力而已
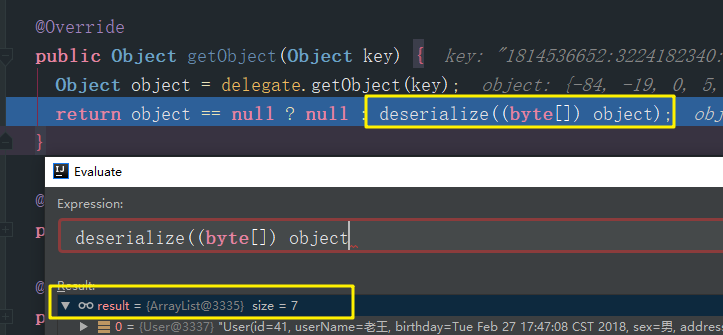
我有调试他是如何从Cache中获取出缓存,事实证明,二级缓存中存放的不是对象,而是被序列化后存储的数据,需要反序列化出来
下图是Mybatis反序列化数据到新创建的对象中的截图
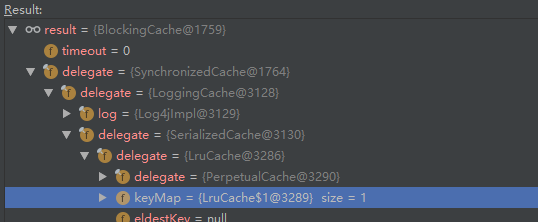
下图是TransactionalCacheManager是如何从Cache中获取数据的调用栈的截图
二级缓存与一级缓存的互斥性
第一点: 通过以上代码的调用顺序也能看出,二级缓存在一级缓存之前优先被执行, 也就是说二级缓存不存在,则查询一级缓存,一级缓存再不存在,就查询DB
第二点: 就是说,对于二级缓存来说,无论我们有没有开启事务的自动提交功能,都必须手动commit()二级缓存才能生效,否则二级缓存是没有任何效果的
第三点: CachingExecutor 提交事务时的源码如下:
@Override
public void commit(boolean required) throws SQLException {
// 代理执行器提交
delegate.commit(required);
// 事务缓存管理器提交
tcm.commit();
}
这就意味着,TransactionalCacheManager和BaseExecutor的实现类的事务都会被提交
为什么说二级缓存和以及缓存互斥呢?可以看看BaseExecutor的源码中commit()如下: 怎么样? 够互斥吧,一个不commit()就不生效,commit()完事把一级缓存干掉了
@Override
public void commit(boolean required) throws SQLException {
if (closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
}
clearLocalCache();
flushStatements();
if (required) {
transaction.commit();
}
}
到这里本文又行将结束了,总体的节奏还是挺欢快挺带劲的,我是bloger-赐我白日梦,如果有错误欢迎指出,也欢迎您点赞支持...