线程池
线程池的优势
- 1:降低资源的消耗,通过重复利用已经创建的线程,降低线程的创建和销毁造成的资源的消耗
- 2:提高响应速度,当任务到达时,任务可以不需要去等待线程的创建就可以执行
- 3:提高线程的可管理,线程是稀缺资源,如果无限制的创建,会消耗系统的资源,降低系统的稳定性,但是使用线程池,可以进行统一的分配调优, 监控.
- 4:提供了定时执行,定期执行,单行程,并发数控制等功能...
new Thread的弊端
- 每次new Thread新建对象,性能差
- 线程缺乏统一管理,可能无限制的新建线程,相互竞争,有可能过多的占用系统的资源
- 缺少更多的功能,如更多执行,定期执行,线程中断
JDK提供了一套Executer框架,可以帮助开发人员,有效的进行线程控制,其中newFixedThreadPool(),newSingleThreadExecutor(),newCachedThreadPool均使用了 ThreadPoolExecutor,下面部分就是了解ThreadPoolExecutor
ThreadPoolExecutor的简单使用
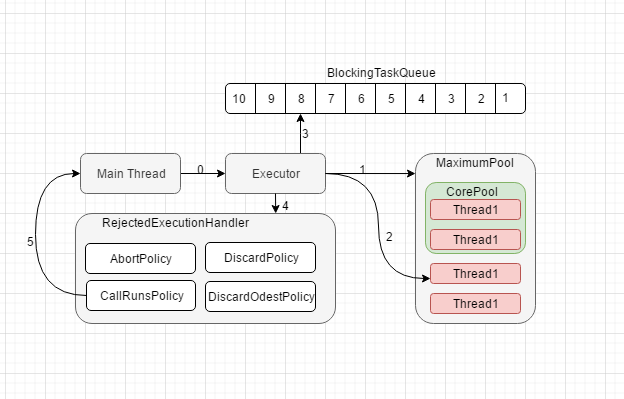
线程池的架构图
创建线程池并使用
public class newMyThreadPool {
public static void main (String[] args) {
AtomicInteger ai = new AtomicInteger(0);
//创建线程池
//饱和策略默认使用的 abortPolicy(流产策略) : 表示无法处理提交的新任务,抛出异常
/**
* corePoolSize: 正常的工作线程数
* maximumPoolSize: 线程池中最大的连接线程数
* keepAliveTime: 超过这个时间后, 会将超过corePoolSize数量的线程废弃
* unit: keepAliveTime的时间单位
* queue: 任务队列
* Factory: 创建线程使用的线程工厂
* handler: 拒绝策略
* abortPolicy: 超过了队列的长度后抛出异常 RejectedExecutionException
* CallerRunsPolicy: 即不丢弃, 也不爆出异常, 将这个任务丢给调用它的线程
* DisCardPolicy: 丢弃
* DisCardOdestPolicy: 丢弃等待时长最久的任务
*
*/
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 20, 10, TimeUnit.DAYS, new ArrayBlockingQueue<>(10),new ThreadPoolExecutor.DiscardOldestPolicy());
//提交100个线程任务
for (int i=0;i<100;i++){
//提交带返回值的线程任务
Future<String> future = threadPoolExecutor.submit(new Callable<String>() {
@Override
public String call(){
ai.getAndIncrement();
return Thread.currentThread().getName();
}
});
try {
System.out.println("线程名字:"+future.get()+"执行结果"+future.isDone());
System.out.println("线程数为"+ai);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
/* // 提交不带返回值的线程任务
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});*/
}
threadPoolExecutor.shutdown();
}
}
构造方法参数:
| 参数名 | 解释 |
|---|---|
| corePoolSize | 线程池的基本大小,运行时,当任务提交过来了,如果线程池中的线程数小于corePoolSize,即便当前的线程数够用了,也会继续创建新线程,当作辅助线程 |
| maximumPoolSize | 线程中最大的线程数量 |
| keepAliveTime | 超出这个时间后就会将大于corePoolSize数量的线程干掉 |
| unit | keepAliveTime的时间单位 |
| workQueue | 任务队列,保存被提交的尚未执行的任务,(仅仅保存由execute方法提交的 Runable 任务) |
| threadFactory | 执行程序创建新线程时使用的工厂。一般使用默认的即可 |
| handler | 拒绝策略,当任务太多,来不及处理时,如何拒绝的策略 |
1.2 详解workQueue和handler
workQueue
- ArrayBlockingQueue:一个基于数组结构的有界数组队列,按照FIFO的原则,对任务进行排序
- LinkedBlockingQueue:基于链表结构的阻塞队列,同样按照FIFO排序元素,吞吐量通常高于ArrayBlockingQueue,但是他有个坑, 虽然有界, 但是它的容量大小是
Integer.MAX_VALUE, 换句话说如果我们使用原生的这个线程池创建出来的没有大小限制的工作队列,在高并发的情况下很容易出现OOM异常- Excutor的静态工厂方法,Executors.newFixedThreadPool()使用了这个队列
- SynchronizedQueue: 一个不存储元素的阻塞队列,每个插入操作,必须等待另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常高于LinkedBlockingQueue高---它将任务直接提交给线程而不保持它们
- 静态工厂方法 Executors.newCachedThreadPool使用了这个队列
- PriorityBlockingQueue: 一个具有优先级的无限阻塞队列
handler
RejectedExecutionHandler饱和策略,当线程池和队列都满了,这个时候,又来了新的任务,那么久必须采用一种策略处理新的任务,这个策略默认使用的是abortPolicy,(流产策略,表示无法处理新任务而抛出异常)
- DiscardOdestPolicy: 丢弃等待事件最长的任务
- CallerRunsPolicy: 比如是main线程任务队列中发放任务, 如果丢列慢了, 就由main线程去执行这个任务
- DiscardPolicy: 不处理,丢弃掉
- AbortPolicy: 默认的策略,直接抛出异常,RejectedExecutionExeception
1.3 线程任务的提交
execute() & submit()
- execute()方法用于提交不需要返回值的任务,意味着,无法得知任务是否正常执行
// 提交不带返回值的线程任务
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});*/
- submit()用于提交一个任务,并带有返回值,submit()将返回一个Future类型的对象,然后我们可以通过这个对象判断任务是否执行成功并且可以同futrue.get()的方法获取返回值并使用,get()会阻塞当前线程,直到任务完成
//提交带返回值的线程任务
Future<String> future = threadPoolExecutor.submit(new Callable<String>() {
@Override
public String call(){
ai.getAndIncrement();
return Thread.currentThread().getName();
}
});
try {
System.out.println("线程名字:"+future.get()+"执行结果"+future.isDone());
System.out.println("线程数为"+ai);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
1.4 shutdown()与shutdownNow()方法
区别
- 执行shutdown()方法后,会等待已经添加进来的任务全部执行完后,在关闭线程池
- 将线程的状态设置成SHUTDOWN,然后去中断没有执行任务的线程
- shutdownNow(),不管任务是否在执行,中断任务,关闭线程池
- 将线程的状态修改为STOP,然后尝试停止所有正在执行的线程任务,并返回等待执行任务的列表
相同点
都是遍历线程池中的工作线程,挨个调用它们的interrupt()方法
2 合理配置线程池
根据任务的特性,合理配置线程池
- 任务性质:
- CPU密集型任务(绝大部分时间花费在计算上)
- 应该配置尽可能少的线程,如N+1 N是CPU数 Runtime.getRuntime().availableProcessors()
- IO密集型任务(大部分时间花费在等待IO上)
- 应配置尽可能多的线程,如2*N
- 混合型任务
- 拆分成一个任务密集型和一个io密集型
- CPU密集型任务(绝大部分时间花费在计算上)
- 任务的优先级: 高,底,中
- 任务执行时间: 长,中,短
- 任务的依赖性: 是否依赖其他系统资源,如数据库连接
3ThreadPoolExecutor同样提供了很多线程池监控的方法
| 方法名 | 描述 |
|---|---|
| beforeExecute(Thread t, Runnable r) | 在Runable执行任务之前调用 |
| afterExecute(Runnable r, Throwable t) | Runnable任务执行完后调用 |
| getActiveCount() | 主动执行任务的近似线程数 |
等等..
Executor多线程框架
如果ThreadPoolExecutor是一个线程池,那么Executors就是一个线程池工厂
java.util.concurrent
类 Executors
java.lang.Object
继承 java.util.concurrent.Executors
Executor是一个很灵活的基于接口的任务执行工具,使用它可以极为简单的创建出一个很棒的任务工作队列,却只需要一行代码
ExecutorService executor = Executors.newCachedThreadPool();
提交一个Runable方法
executor.execute(Runable);
// submit(Runable)
// submit(Callable,T)
// submit(Runable,T)
优雅的终止
executor.shutdown();
public class Executorsextends Object此包中所定义的 Executor、ExecutorService、ScheduledExecutorService、ThreadFactory 和 Callable 类的工厂和实用方法。此类支持以下各种方法:
创建并返回设置有常用配置字符串的 ExecutorService 的方法。
创建并返回设置有常用配置字符串的 ScheduledExecutorService 的方法。
创建并返回“包装的”ExecutorService 方法,它通过使特定于实现的方法不可访问来禁用重新配置。
创建并返回 ThreadFactory 的方法,它可将新创建的线程设置为已知的状态。
创建并返回非闭包形式的 Callable 的方法,这样可将其用于需要 Callable 的执行方法中。
使用Executors的工厂方法,可以简单粗暴的获取我们想要的线程池
简单使用
- 方法返回一个固定大小的线程池,线程数目始终不变,当有新任务被提交过来,如果有空闲的线程,立即执行任务,没有空闲的线程,任务会被暂存在一个任务队列中.等待有空闲的线程来执行
public static ExecutorService newFixedThreadPool(10);
查看他的实现,可以看到,其实他就是使用ThreadPoolService实现的
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- 返回一个根据实际情况进行调整,没有固定大小的线程池,如果有空闲的线程,优先调用空闲的线程,没有空闲的线程,创建新的线程执行任务,他在执行的过程中通常会创建和所需线程数量相等的线程数,因此它是合理的Executor首选
public static ExecutorService newCachedThreadPool();
- 返回一个只有一个线程的线程池,任务被提交后,如果线程空闲,那么由此线程执行任务,多余的任务被保存进任务队列,按照先进先出的顺序,排队等待执行
为什么单个线程还整一个线程池? 因为 new 出来的线程在执行任务时如果挂掉了,那么任务就不会被继续执行下去,而使用线程池,虽然只有一个线程,但是线程挂掉后,依然会创建出新的线程执行任务...(用于更新本地或远程日志,或者时间分发线程)
public static ExecutorService newSingleThreadExecutor();
- 返回一个ScheduledExecutorService对象,线程池的大小是corePoolSize, ScheduledExecutorService 继承了ExecutorService接口,并且对他进行了升级,添加了 在给定的延迟后执行某些任务的,或者周期性执行某些任务的方法
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
简单使用
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(3);
/*
while (true) {
scheduledExecutorService.schedule(new Runnable() {
@Override
public void run() {
System.out.println("-->" + Thread.currentThread().getName());
}
}, 5, TimeUnit.SECONDS);
}
*/
ScheduledFuture<String> schedule = scheduledExecutorService.schedule(new Callable<String>() {
@Override
public String call() throws Exception {
System.out.println(Thread.currentThread().getName());
return Thread.currentThread().getName();
}
}, 3, TimeUnit.SECONDS);
try {
System.out.println(schedule.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
- 5 返回一个只有一个线程的线程池
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
JDK8新添加:
public static ExecutorService newWorkStrealingPool
使用:
public static void main(String[] args) {
ExecutorService pool = Executors.newWorkStealingPool(Runtime.getRuntime().availableProcessors());
for (int i=0;i<50;i++){
pool.submit(new Runnable() {
@Override
public void run() {
Date date = new Date();
System.out.println("线程"+Thread.currentThread().getName()+"完成任务,时间为:"+date.getTime());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
while (true){}//主线程自旋,不然看不见效果
}
- 任务窃取线程池,什么是任务窃取?就是让闲置的线程去执行本不属于他们的任务, 带并行级别,并行级别就是同一时刻,最多有多少条线程同时执行,达到减少竞争的效果,,和CPU数相关,如果不设置参数,默认就是CPU的个数.
在工作中如何抉择
这一点在阿里巴巴开发手册中有明文要求: 不推荐使用Executors去获取线程池, 因为这种机制获取的线程池使用的任务队列的容量是Integer.MAXVALUE , 在高并发的情况下有机率出现OOM异常的情况
参考书籍<<java编程思想>>Bruce Eckel著 <