计算机是进行数据处理、运算的机器
那么有两个基本的问题就包含在其中:
(1) 处理的数据在什么地方?
(2)要处理的数据有多长?
这两个问题,在机器指令中必须给以明确或隐含的说明,否则计算机就无法工作
bx、si、di和bp
(1) 在8086CPU中, 只有这4个寄存器可以用在“[...]”中来进行内存单元的寻址。
比如下面的指令都是正确的:
mov ax, [bx]
mov ax, [bx+si]
mov ax, [bx+di ]
mov ax, [bp]
mov ax, [bp+si]
mov ax, [bp+di]
而下面的指令是错误的:
mov ax, [cx]
mov ax, [ax]
mov ax, [dx]
mov ax, [ds]
(2)在[..]中, 这4个寄存器可以单个出现,或只能以4种组合出现: bx 和si、bx和di、bp和si、bp和di
比如下面的指令是正确的:
mov ax, [bx]
mov ax, [si]
mov ax, [di]
mov ax, [bp]
mov ax, [bx+si]
mov ax, [bx+di]
mov ax, [bp+si]
mov ax, [bp+di]
mov ax, [bx+si+idata]
mov ax, [bx+di+idata]
mov ax, [bp+si+idata]
mov ax, [bp+di+idata]
下面的指令是错误的:
mov ax, [bx+bp]
mov ax, [si+di]
(3)只要在[...]中使用寄存器bp,而指令中没有显性地给出段地址,段地址就默认在
ss中。比如下面的指令。
mov ax, [bp] 含义: (ax)=((ss) *16+ (bp) )
mov ax, [bp+ idata] 含义: (ax)=((ss) *16+ (bp) +idata)
mov ax, [bp+si] 含义: (ax)=((ss) *16+ (bp) + (si) )
mov ax, [bp+si+idata] 含义: (ax)=( (ss) *16+ (bp) + (si) +idata)
机器指令处理的数据在什么地方
绝大部分机器指令都是进行数据处理的指令,处理大致可分为3类:
读取、写入、运算
在机器指令这一层来讲,并不关心数据的值是多少
而关心指令执行前一刻,它将要处理的数据所在的位置
指令在执行前,所要处理的数据可以在3个地方: CPU内部、内存、端口(端口将在后面的课程中进行讨论),
比如下表中所列的指令

汇编语言中数据位置的表达
汇编语言中用3个概念来表达数据的位置
(1)立即数(idata)
对于直接包含在机器指令中的数据(执行前在CPU的指令缓冲器中),在汇编语言中称为:立即数(idata)
在汇编指令中直接给出
mov ax,1
add bx,2000h
or bx,00010000b
mov al,'a'
(2)寄存器
指令要处理的数据在寄存器中,在汇编指令中给出相应的寄存器名
mov ax,bx
mov ds,ax
push bx
mov ds:[0],bx
push ds
mov ss,ax
mov sp,ax
段地址(SA)和偏移地址(EA)
指令要处理的数据在内存中
在汇编指令中可用[X]的格式给出EA, SA在某个段寄存器中
存放段地址的寄存器可以是默认的,比如:
mov ax, [0]
mov ax, [di]
mov ax, [bx+8]
mov ax, [bx+si]
mov ax, [bx+si+8]
段地址默认在ds中;
mov ax, [bp]
mov ax, [bp+8]
mov ax, [bp+si]
mov ax, [bp+si+8]
段地址默认在ss中。
存放段地址的寄存器也可以是显性给出的,比如以下的指令。
mov ax,ds:[bp] 含义: (ax)=((ds) *16+ (bp))
mov ax,es:[bx] 含义: (ax)=((es)*16+ (bx) )
mov ax,ss:[bx+si] 含义: (ax)=((ss) *16+ (bx) +(si) )
mov ax,cs:[bx+si+8] 含义: (ax)=((cs) *16+ (bx) +(si) +8)
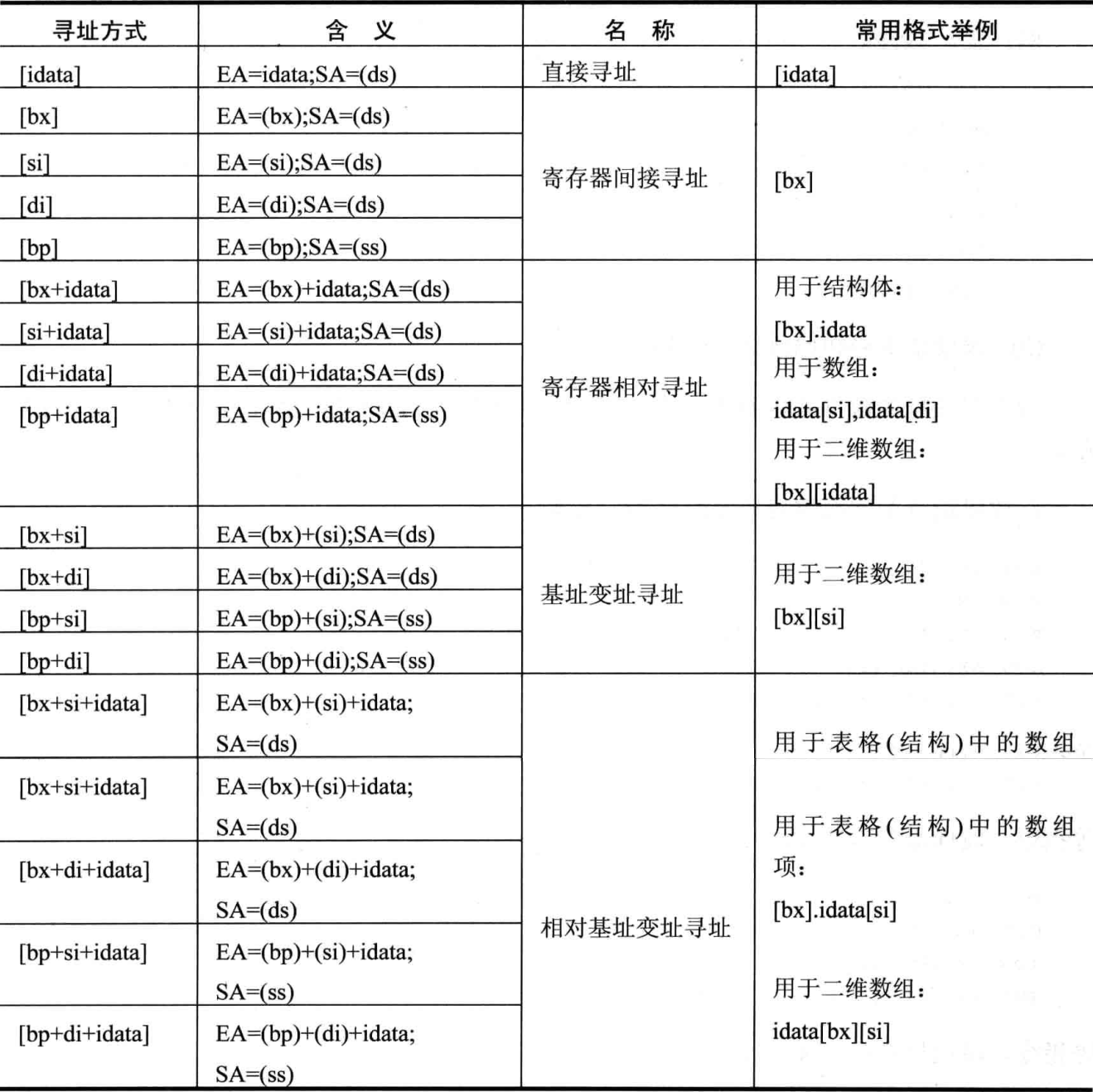
寻址方式
当数据存放在内存中的时候,我们可以用多种方式来给定这个内存单元的偏移地址,
这种定位内存单元的方法一般被称为 寻址方式
指令要处理的数据有多长
8086CPU的指令,可以处理两种尺寸的数据,byte 和word。
所以在机器指令中要指明,指令进行的是字操作还是字节操作
对于这个问题,汇编语言中用以下方法处理
(1)通过寄存器名指明要处理的数据的尺寸
例如,下面的指令中,寄存器指明了指令进行的是字操作。
mov ax, 1 mov bx,ds:[0] mov ds,ax mov ds:[0],ax inc ax add ax,1000
下面的指令中,寄存器指明了指令进行的是字节操作
mov al,1 mov al,bl mov al,ds:[0] mov ds:[0],al inc al add al,100
(2)在没有寄存器名存在的情况下
用操作符X ptr指明内存单元的长度
X在汇编指令中可以为word或byte
例如,下 面的指令中,用word ptr指明了指令访问的内存单元是一个字单元。
mov word ptr ds:[0],1 inc word ptr [bx] inc word ptr ds:[0] add word ptr [bx],2
下面的指令中,用byte ptr指明了指令访问的内存单元是一个字节单元。
mov byte ptr ds:[0],1 inc byte ptr [bx] inc byte ptr ds:[0] add byte ptr [bx],2
在没有寄存器参与的内存单元访问指令中
用word ptr 或byte ptr 显性地指明所要访问的内存单元的长度是很必要的
否则,CPU无法得知所要访问的单元是字单元,还是字节单元
假设我们用Debug查看内存的结果如下:
2000: 1000 FF FF FF FF FF F.......
那么指令:
mov ax,2000H mov ds,ax mov byte ptr [1000H],1
将使内存中的内容变为:
2000: 1000 01 FF FF FF FF FF ....
而指令:
mov ax, 2000H mov ds, ax mov word ptr [1000H], 1
将使内存中的内容变为:
2000: 1000 01 00 FF FF FF FF
这是因为mov byte ptr [1000H],1
访问的是地址为ds:1000H的字节单元
修改的是ds:1000H单元的内容
而mov word ptr [1000H],1
访问的是地址为ds:1000H的字单元
修改的是ds:1000H和ds:1001H两个单元的内容
(因为一个字单元 等于 两个字节,一个内存单元为1个字节)
(3)其他方法
有些指令默认了访问的是字单元还是字节单元
比如,push [1000H]就不用指明访问的是字单元还是字节单元
因为push指令只进行字操作
寻址方式的综合应用
下面我们通过一个问题来进一步讨论一下各种寻址方式的作用。
关于DEC公司的一条记录(1982年)如下
公司名称: DEC 总裁姓名: Ken Olsen 排名: 137 收入: 40(40亿美元) 著名产品: PDP(小型机)

可以看到,这些数据被存放在seg段中从偏移地址60H起始的位置
从seg:60起始 以ASCII字符的形式存储了3个字节的公司名称
从seg:60+3起始 以ASCII字符的形式存储了9个字节的总裁姓名
从seg:60+0C起始 存放了一个字型数据,总裁在富翁榜上的排名
从seg:60+0E起始 存放了一个字型数据,公司的收入
从seg:60+10起始 以ASCII字符的形式存储了3个字节的产品名称
以上是该公司1982年的情况,到了1988年DEC公司的信息有了如下变化。
(1) Ken Olsen 在富翁榜上的排名已升至38位;
(2) DEC 的收入增加了70 亿美元;
(3) 该公司的著名产品已变为VAX系列计算机。
需要编程修改内存中的过时数据
要修改内容是:
(1) (DEC 公司记录)的(排名字段)
(2) (DEC 公司记录)的(收入字段)
(3) (DEC 公司记录)的(产品字段)的(第一个字符)、(第二个字符)、(第三个字符)
从要修改的内容,我们就可以逐步地确定修改的方法
(1)要访问的数据是DEC公司的记录,所以,首先要确定DEC公司记录的位置:R=seg: 60
确定了公司记录的位置后,下面就进一步确定要访问的内容在记录中的位置
(2)确定排名 字段在记录中的位置: 0CH。
(3) 修改R+0CH处的数据。
(4)确定收入字 段在记录中的位置: 0EH
(5) 修改R+0EH处的数据。
(6)确定产品字段在记录中的位置: 10H。
要修改的产品字段是一个字符串(或-一个数组),需要访问字符串中的每一一个字符。所
以要进一步确定每-一个字符在字符串中的位置。
(7)确定第- 一个字符在产品字段中的位置: P=0。
(8) 修改R+10H+P处的数据; P=P+1。
(9)修改R+10H+P处的数据; P=P+1。
(10)修改R+10H+P处的数据
根据上面的分析,程序如下。
mov ax, seg mov ds, ax mov bx, 60h ;确定记录地址,ds :bx mov word ptr [bx+0ch],38 ;排名字段改为38 add word ptr [bx+0eh],70 ;收入字段增加70 mov si,0 ;用si来定位产品字符串中的字符 mov byte ptr [bx+10h+si],'V' inc si mov byte ptr [bx+10h+si],'A' inc si mov byte ptr [bx+10h+si],'X'
如果你熟悉C语言的话,我们可以用C语言来描述这个程序,大致应该是这样的:
struct company { /*定义一个公司记录的结构体*/ char cn[3]; /*公司名称* / char hn[9]; /*总裁姓名*/ int pm; /*排名*/ int sr; /*收入*/ char cp[3]; /*著名产品*/ }; 」, struct company dec={"DEC","Ken Olsen",137,40,"PDP"} ; /*定义一个公司记录的变量,内存中将存有一条公司的记录*/ main () { int i; dec.pm=38; dec.sr = dec.sr+70; i=0; dec.cp[i]='V'; i++; dec.cp[i]='A'; i++; dec.cp[i]='X'; return 0; }
我们再按照C语言的风格,用汇编语言写一下这个程序,注意和C语言相关语句的
比对:
mov ax,seg mov ds,ax mov bx,60h ;记录首址送BX mov word ptr [bx].0ch,38 ; 排名字段改为38 ; C: dec. pm=38; add word ptr [bx].0eh,70 ; 收入字段增加70 ; C:dec.sr=dec.sr+ 70; ; 产品字段改为字符串'VAX' mov si,0 ; C:i=0; mov byte ptr [bx].10h[si],'V' ; dec.cp[i]='V'; inc si ; i++; mov byte ptr [bx].10h[si],'A' ; dec.cp[i]='A'; inc si ; i++; mov byte ptr [bx].10h[si],'X' ; dec.cp[i]='X';
我们可以看到,8086CPU提供的如[bx+si+idata]的寻址方式为结构化数据的处理提供了方便
使得我们可以在编程的时候,从结构化的角度去看待所要处理的数据
从上面可以看到,一个结构化的数据包含了多个数据项
而数据项的类型又不相同,有的是字型数据,有的是字节型数据,有的是数组(字符串)
一般来说:
用[bx+idata+si]的方式来访问结构体中的数据
用bx定位整个结构体
用idata 定位结构体中的某一个数据项
用si 定位数组项中的每个元素
为此,汇编语言提供了更为贴切的书写方式,如:
[bx].idata、[bx].idata[si]。
在C语言程序中我们看到,如: dec.cp[i]
dec是一个变量名,指明了结构体变量的地址,cp 是一个名称,指明了数据项cp的地址,而i用来定位cp中的每一个字符
汇编语言中的做法是: bx.10h[si]
看一下,是不是很相似?
div指令
除法指令,使用div时应注意以下问题
1、除数:有8位和16位两种,在一个寄存器或内存单元中
2、被除数:默认放在AX或DX和AX中
如果除数为8位,被除数则为16位,默认在AX中存放;
如果除数为16位,被除数则为32位,在DX和AX中存放
DX存放高16位,AX存放低16位
3、结果:
如果除数为8位,则AL存储除法操作的商,AH存储除法操作的余数
如果除数为16位,则AX存储除法操作的商,DX存储除法操作的余数
格式如下:
div 寄存器
div内存单元
现在,我们可以用多种方法来表示一个内存单元了,比如下面的例子:
div byte ptr ds:[0] 含义: (al)表示al中的数据111w (al) = (ax) / ( (ds) * 16 + 0 ) 的商 (ah) = (ax) / ( (ds) * 16 + 0 ) 的余数 div word ptr es:[0] 含义: (ax) = [ (dx) * 10000H + (ax) ] / ( (es) * 16 + 0 )的商 (dx)=[ (dx) * 10000H + (ax) ] / ( (es) * 16 + 0 )的余数 div byte ptr [bx+si+8] 含义: (al) = (ax) / ( (ds) * 16 + (bx) + (si) + 8)的商 (ah) = (ax) / ( (ds) * 16 + (bx) + (si) + 8 )的余数 div word ptr [bx+si+8] 含义: (ax) = [ (dx) * 10000H + (ax) ] / ( (ds) * 16 + (bx) + (si) + 8)的商 (dx) = [ (dx) * 10000H + (ax) ] / ( (ds) * 16+ (bx) + (si) + 8)的余数
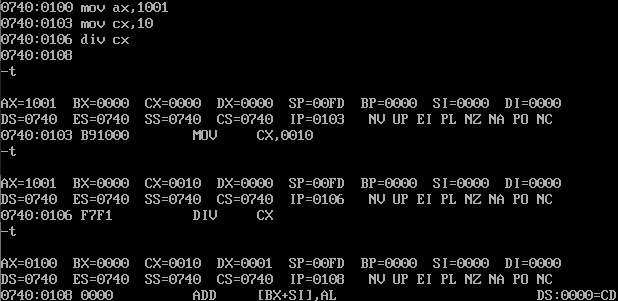
编程,利用除法指令计算100001/100
首先分析一下,被除数100001 大于65535, 不能用ax寄存器存放,所以只能用dx
和ax两个寄存器联合存放100001,也就是说要进行16位的除法。除数100小于255,可
以在一个8位寄存器中存放,但是,因为被除数是32位的,除数应为16位,所以要用一
个16位寄存器来存放除数100。
因为要分别为dx和ax赋100001的高16位值和低16位值,所以应先将100001表示
为16 进制形式: 186A1H。 程序如下:
mov dx, 1 mov ax, 86A1H ;(dx) * 10000H + (ax) =100001 mov bx, 100 div bx
程序执行后,(ax)=03E8H(即1000), (dx)=1(余数为 1)
编程,利用除法指令计算1001/100
伪指令dd
前面我们用db和dw定义字节型数据和字型数据
dd是用来定义dword(doubleword,双字)型数据的
比如:
data segment db 1 dw 1 dd 1 data ends
在data段中定义了3个数据:
第一个数据为01H,在data:0处,占1个字节;
第二个数据为0001H,在data:1处,占1个字;
第三个数据为00000001H,在data:3处,占2个字。
用div计算dara段中第一个数据除以第二个数据后的结果
商存放在第三个数据二点存储单元
datasg segment dd 100001 dw 100 dw 0 datasg ends
答案
assume cs:codesg,ds:datasg datasg segment dd 100001 dw 100 dw 0 datasg ends codesg segment start: mov ax,datasg mov ds,ax mov ax,ds:[0] ;ds:0字单元中的低16位存储在ax中 mov dx,ds:[2] ;ds:2字单元中的高16位存储在dx中 mov ax,100 div word ptr ds:[4] ;用dx:ax中的32位数据除以ds:4字单元中的数据 mov ds:[6],ax ;将商存储在ds:6字单元中 mov ax,4c00h int 21h codesg ends end start
dup
dup是一个操作符
在汇编语言中同db,dw,dd等一样
用来进行数据的重复
比如:
db 3 dup (0)
定义3个都为0的字节 相当于 db,0,0,0
db 3 dup (0,1,2)
定义9个字节
相当于 db 0,1,2,0,1,2,0,1,2
db 3 dup ('abc', 'ABC')
定义了18个字节,它们是'abcABCabcABCabcABC, 相当于db'abcABCabcABCabcABC。
可见,dup 的使用格式如下
db重复的次数 dup (重复的字节型数据)
dw重复的次数 dup (重复的字型数据)
dd重复的次数 dup (重复的双字型数据)
实验(几乎综合了前面的知识,必做)

下面是已定义的数据
data segment db '1975', '1976', '1977', '1978', '1979', '1980', '1981', '1982', '1983' db '1984', '1985', '1986', '1987', '1988', '1989', '1990', '1991', '1992' db '1993', '1994', '1995' ;以上表示21年的21个字符串 dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514 dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000 ;以上是表示21年公司总收入的21个dword型数据 dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226 dw 11542,14430,15257,17800 ;以上是表示21你公司雇员人数的21个word型数据 data ends table segment db 21 dup ('year summ ne ?? ') table ends
编程,将data 段中的数据按如下格式写入到table段中,并计算21年中的人均收入(取整)
结果也按照下面的格式保存在table段中
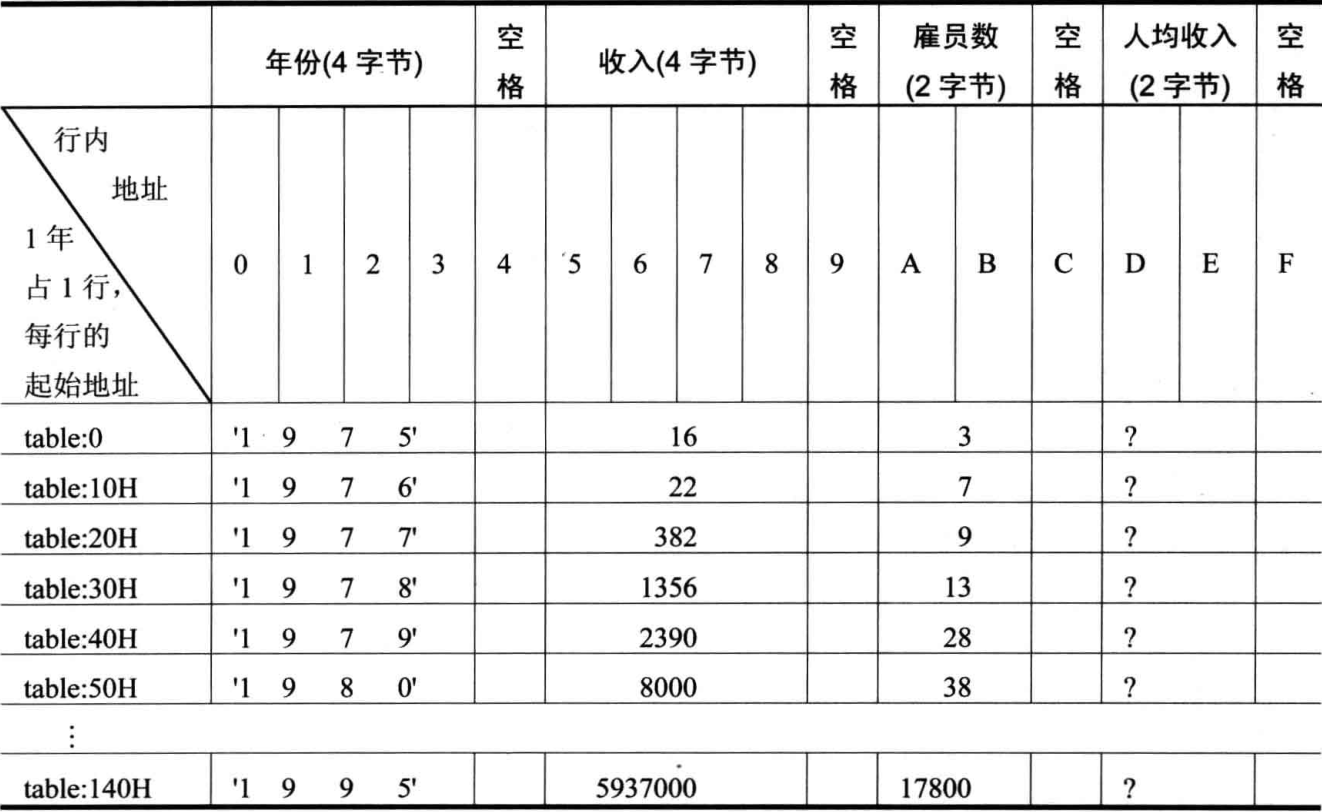
提示,可将data段中的数据看成是多个数组,而将table中的数据看成是一个结构型数据的数组
每个结构型数据中包含多个数据项
可用bx定位每个结构型数据,用idata定位数据项,用si 定位数组项中的每个元素
对于table中的数据的访问可采用[bx].idata和[bx].idata[si]的寻址方式
答案
assume cs:codesg,ds:data,es:table,ss:stack data segment db '1975', '1976', '1977', '1978', '1979', '1980', '1981', '1982', '1983' db '1984', '1985', '1986', '1987', '1988', '1989', '1990', '1991', '1992' db '1993', '1994', '1995' dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514 dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000 dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226 dw 11542,14430,15257,17800 data ends table segment db 21 dup ('year summ ne ?? ') table ends stack segment dw 0,0,0,0,0,0,0,0 stack ends codesg segment start: mov ax,data mov ds,ax mov si,0 mov ax,table mov es,ax mov di,0 mov cx,21 s: mov ax,ds:[si] ;年份转送 mov es:[di],ax mov ax,ds:[si+2] mov es:[di+2],ax mov ax,ds:[si+84] ;收入转送 mov es:[di+5],ax mov dx,ds:[si+84+2] mov es:[di+7],dx push cx ;将外层循环的cx值压栈 mov cx, ds: [84+84+bx] ;雇员数转送 mov es:[di+0ah], cx div cx ;计算人均收入 pop cx mov es:[di+0dh],ax ;人均收入转送 add si,4 add bx,2 add di,16 loop s mov ax,4c00h int 21h codesg ends end start
参考: 王爽 - 汇编语言 和 小甲鱼零基础汇编