Spatiotemporal Transformer for Video-based Person Re-identification
Abstract
- Key issue: How to extract discriminative information from a tracklet.
- Problem: Vanilla Transformer overfits here.
- Solution: A pipeline: pretrained on synthesized video data + transferred to downstream domain with STT(perception-constrained Spatiotemporal Transformer) module and GT(global Transformer) module.
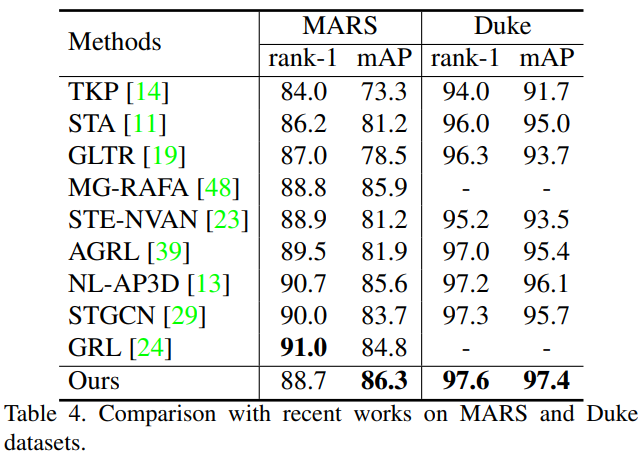
STT & GT
- Propose a constrained attention learning scheme to prevent the Transformer from over-focusing on local regions.
- Two-stage design separates S & T information to avoid the over-fitting. But patches in an image cannot communicate with those from another image -- to associate patches across frames, a global attention learning branch was added here.
即兴笑话一则: 有一群影魔在那里排队solo, 他们魔很多一个个挨个上, 那么请问第几个sf最厉害呢? -- 第p个, 因为p-th的影魔最厉害.
Constrained Attention Learning
Give constraints on ST and TT to relieve the over-fitting.
Feature: feature map -> H x W -> 1-dim tokens. And there is an extra one as classification token (totally H x W + 1).
Loss spatial constraint (L_{SpaC} = L_{spa\_part\_xent} + L_{spa\_xent}):
- (L_{spa\_xent}) -- cross entropy loss for learning discriminative representation.
- Due to dataset is small for the Transformer, to avoid that ST focus on limited regions but ignore detailed cues, a spatial part cross entropy loss (L_{spa\_part\_xent}) is proposed -- Divide tokens into P groups horizontally as some re-id tasks did. An average pooling operation is conducted with each group. (L_{spa\_part\_xent = frac{1}{P}sumlimits_{spa\_part\_xent}^{(p)}}). where p presents the pth group.
Loss temporal constraint (L_{TemC} = L_{tem\_trip} + L_{tem\_attn}):
- (L_{tem\_xent}) -- supervises the final output.
- (L_{tem\_trip}) -- shrink the distances of positive pairs (in the same tracklet).
- (L_{tem\_attn} = sumlimits_{i=1}^{N}[exp(sumlimits_{k=1}^{L}alpha_{i,k} log(alpha_{i, k})) - alpha]_{+}) -- increase the information entropy of the attention weights in each tracklet and leaves much space for Transformer to decide which frame is more critical with the parameter (alpha).
Global Attention Learning
The aim is to establish the relationships between patches of different frames, which are ignored in the former design.
Components: a Global Transformer module -- take H x W patches of all L frames in a tracklet as its input. As a result, there will be H x W x L + 1 (classification token) fed into the Global Transformer (GT) with an extra classification token.
Then, a cross entropy loss (L_{global\_xent}) is adopted to supervise the learning of GT.
The final representation is generated by the concatenation of outputs of STT and GT.
Synthesized Video Pre-training
- Adopt UnrealPerson toolkit, 4 environments X 34 cameras.
- Set disturbance that persons may not appear in the middle.
- Set disturbance that severely occluded frames are also kept.
Implementation
- Architecture
- CNN baseline -- first 4 residual blocks of ResNet-50.
- CNN + Transformer -- 4-th residual block is replaced by Transformer blocks.
- ST and TT share the same architecture design, with 1 layer and 6 heads.
- The Global Transformer has 2 layers and 6 heads.
- Workflow:
- The output feature maps of the CNN backbone go through a conv layer and are flattened to patch tokens.
- The embedding dimension of all Transformers is set to 768.
- Positional embeddings are only used in ST.
Idea: 换人物背景后, triplet loss拉近会不会效果更好? 其实unrealPerson那种很适合直接换, 不然就要出掩码之类的.
Ablation Study
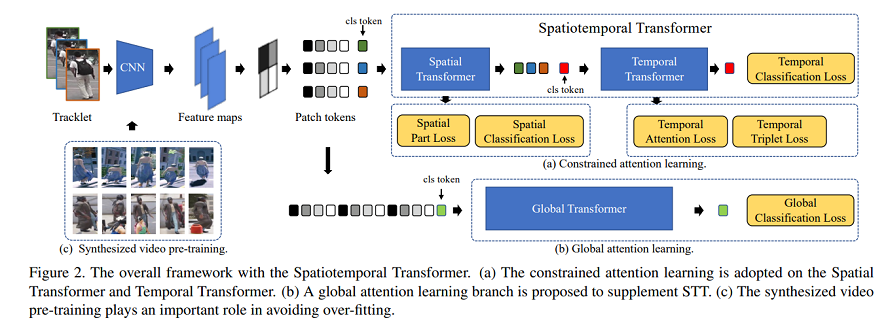
- Spatial Attention
- Temporal Attention

Both of them give regularization to the attention region to avoid overfitting.
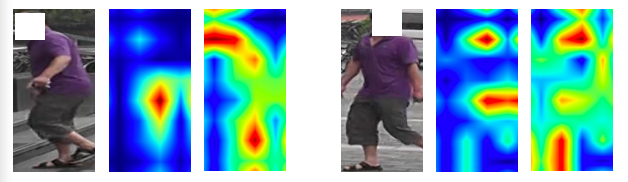
- Variable Controlling
- Results