-
-
支持一个基本上与平台无关的进程派生模型,并为相关目标如IPC提供工具,如锁,管道,队列等
-
因为使用进程而非线程来并行地运行代码,有效的避开了线程GIL带来的限制
-
multiprocess模块允许程序员既能发挥多处理器的威力来完成并行任务,又能保留线程模型带来的大部分的简易性和可移植性-
与原始的进程分支相比,跨平台可移植性及强大的IPC工具
-
与线程相比,从本质上将,付出了一些潜在的,依赖于系统平台的任务启动额外耗时,但是获得了在多核或多CPU机器上真正地并行运行任务的能力
-
-
线程没有限制及由某些功能加强造成的不便
-
因为对象的复制跨越进程界限,线程中的共享可变状态不再正常工作
-
一个进程中的改变一般不会为其他进程所注意
-
自由地共享状态可能是线程的最大卖点
-
在模块中,这一点缺失对其在某些使用线程的情景中的应用可能有所限制
-
-
模块要求在Windows平台下进程以及某些IPC工具能够进行
Pickle操作,某些编码范式可能实现起来较为复杂,或者不能跨平台移植,尤其当它们使用了绑定对象方法或者向派生的进程中传入套接字等不能Pickle的对象-
lambda编码模式可在threading模块中使用,但是Windows平台下的这个模块中,不能作为进程的目标可调用对象,因为不能进程Pickle操作 -
pickle操作在接受进程中产生一个对象副本,而并非对原始对象的引用-
对于由pickle后传给新进程的方法复制了一个可变消息缓存,更新其状态对其原始对象没有效果
-
-
Unix下分支本质上也是复制整个进程 -
在Windows下,进程的参数的可Pickle特性要求可以在其他情境下限制
multiprocessing的使用
-
-
-
mulitprocessing模块基于单独的进程,可能最适用于相互独立,不能自由共享可变对象状态,并且能够利用这个模块提供的消息传递和共享内存工具的任务 -
这个模块的大部分接口被设计成了类似
threading和queue模块,如Process类似Thread,允许启动一个与调用者脚本并行的函数调用,在Windows平台上启动新的解释器,Unix启动分支新进程 -
向
Process对象传入一个带有参数的target -
也可以创建其子类来重新定义
run行为方法-
start方法在一个新进程中调用其run方法 -
默认的
run方法仅仅调用传入的目标函数
-
-
join等待子进程的退出,提供了为多种进程同步化工具lock


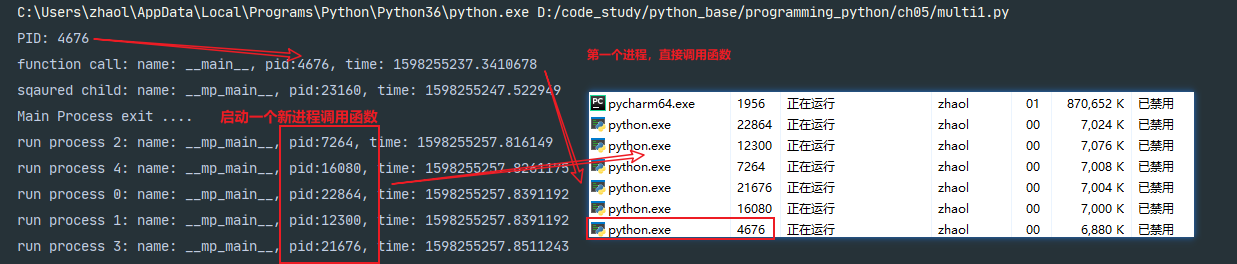
""" multiprocessing模块基本操作 Process类似threading.Thread 不过在并行进程而非线程中允许函数调用 可以用锁进程同步化,如打印操作 在Windows平台上启动新的解释器,Unix启动分支新进程 """ import os import time from multiprocessing import Process, Lock def whoaim(label, lock): msg = '%s: name: %s, pid:%s, time: %s' with lock: print(msg % (label, __name__, os.getpid(), time.time())) if __name__ == '__main__': lock = Lock() print("PID:", os.getpid()) whoaim('function call', lock) p = Process(target=whoaim, args=('sqaured child', lock)) p.start() p.join() for i in range(5): Process(target=whoaim, args=(('run process %s' % i), lock)).start() with lock: print("Main Process exit ....")
-
脚本运行时首先在进程中直接调用函数,在同一个进程中,PID一致
-
在一个新的进程中启动该函数并等待其退出
-
最后在一个循环中派生五个并行的函数调用

-
-
在Unix下,虽然子进程可以使用父进程中创建的共享全局对象
-
更好的方法:将对象作为参数传入子进程的构造器
-
既可以具有向
Windows的移植性 -
如果这种对象是父进程收集的垃圾的化,还能避免一些潜在的问题
-
-
-
Windows下,通过
Windows下特有的进程创建工具来派生一个新的解释器,通过管道向新进程传入pickle后的Process对象,并在新的进程中运行python -c命令行,后者运行这个包里的一个特殊的Python编码的函数来读取和unpickle这个Process对象并调用其run方法 -
在
Windows下,主进程的业务逻辑通常嵌套在if __name__ == '__main__'的测试中,这样就可以由一个新的解释器自由地载入而没有副作用 -
在
Windows下当子进程访问全局对象时,后者的值可能与其在父进程中的起始时间不同,因为它们的模块将被载入一个新的进程 -
在
Windows下,Process接受的所有参数必须能够进行pickle操作-
包含
target,目标应该是可以pickle的简单函数而不能是绑定或者非绑定对象的方法,也不能是lambda语句创建的函数 -
基本所有的对象都可以进行
pickle,只是函数和类这些可调用对象必须是可以载入的 -
它们仅仅通过名称进行pickle,之后还需要载入以重新创建字节码
-
在
Windows下,带有系统状态的对象,如套接字,一般来讲是不能做为目标参数,因为不能Pickle
-
-
定制的
Process子类在Windows
-
模块的
pipe对象-
和
Process对象类似 -
提供了一个可连接俩个进程的匿名管道
-
调用后,返回两个
Connection对象, 表示管道的两端, 管道默认是双向的,可以发送和接受任何可pickle的Python对象 -
在Unix下,在内部由一对连接上的
套接字或os.pipe调用得以实现 -
在Windows下,由平台特异的
具名管道是实现
-
-
Value/Array对象
-
实现了共享的进程/线程安全的内存以用于进行进程间通信
-
返回基于
ctype模块并在共享内存中创建的标量和数组对象 -
默认带有访问同步化设置
-
-
Queue模块
-
可以作为Python对象的一个先进先出的列表
-
允许多个生产者和消费者
-
队列是一个管道加上用来协调随机访问的锁机制,并继承了Pipe加上pickle的限制
-
这些工具可以在数个进程间安全适用,经常以他们为通信的同步点并因此取代了锁之类的更贴近底层的工具
-
限制:管道(间接包含队列)pickle它们传递的对象,使得在接收端进程里重新,不支持不能pickle的对象,传输的对象能被pickle,实际上它在接收端进程类被复制了,对可变对象状态的原位更改不会为发送者中的副本感知, 状态都不能线程模型中那样自由的共享
""" 使用多进程匿名管道进行通信 返回两个Connection对象分别表示管道的来两端 对象从一端发送,在另一端接受,管道默认是双向的 """ import os import time from multiprocessing import Pipe, Process def sender(pipe): print(os.getpid(), "发送数据") time.sleep(10) """在匿名管道上向父进程发送对象""" pipe.send(['sapm'] + [42, 'eggs']) pipe.close() def talker(pipe): """通过管道发送和接受对象""" pipe.send(dict(name="Bob", spam=42)) reply = pipe.recv() print("talker got:", reply, os.getpid()) if __name__ == '__main__': print(os.getpid()) (parentEnd, childEnd) = Pipe() # 派生带管道的子进程 Process(target=sender, args=(childEnd,)).start() # 从子进程中接受 print("patent got: ", parentEnd.recv()) # 关闭端口 parentEnd.close() time.sleep(60) (parentEnd, childEnd) = Pipe() # 从子进程接受 child = Process(target=talker, args=(childEnd,)) child.start() print("parent got:", parentEnd.recv()) # 向子进程发送 parentEnd.send({x * 2 for x in "spam"}) # 等待子进程退出 child.join() print('Parent exit ...')
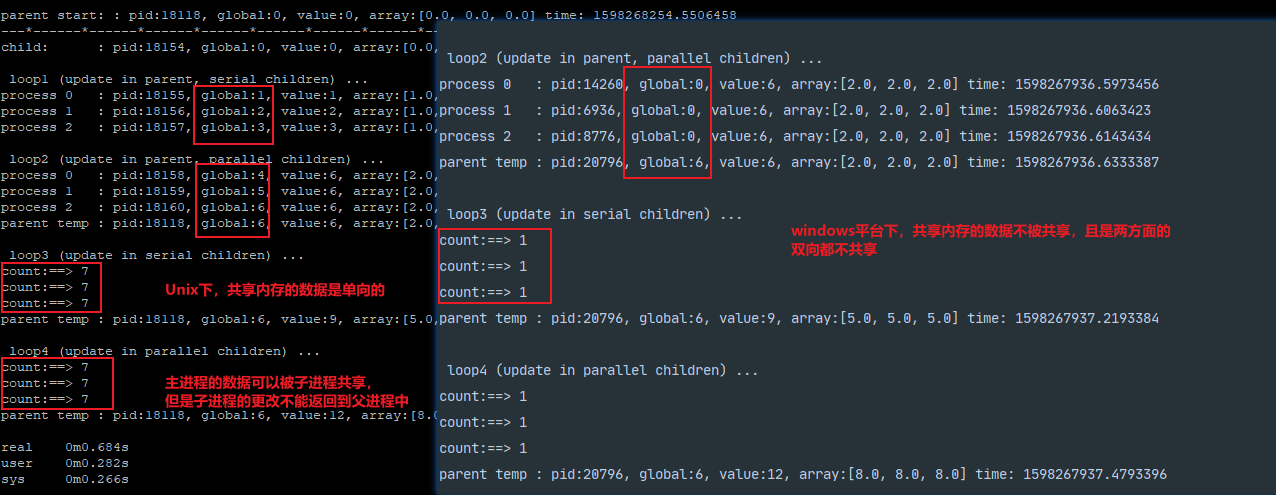
""" 使用多进程共享内存对象进程通信 传输的对象是共享的,但在windows下不共享全局对象 """ import os from multiprocessing import Process, Value, Array import time # 每个进程各自的全局对象,并非共享 procs = 3 count = 0 def showdata(label, val, arr): """在这个进程中打印数据值""" msg = "%-12s: pid:%4s, global:%s, value:%s, array:%s time: %s" print(msg % (label, os.getpid(), count, val.value, list(arr), time.time())) def updater(val, arr): """通过共享内存进程通信""" global count # 全局计数器,非共享 count += 1 print("count:==>", count) # 传入的对象是共享的 val.value += 1 for i in range(3): arr[i] += 1 if __name__ == '__main__': # 共享内存是线程/进程安全的 # ctype中的而类型代码 scalar = Value('i', 0) vector = Array('d', procs) # 在父进程中显示初始值 showdata('parent start: ', scalar, vector) print("---*---" * 20) # 派生子进程,传入共享内存 p = Process(target=showdata, args=('child: ', scalar, vector)) p.start() p.join() # 传入父进程中更新过的共享内存,等待每次传入结束 # 每个子进程看到的父进程中到现在为止对args的更新(全局变量的看不到) print(" loop1 (update in parent, serial children) ...") for i in range(procs): count += 1 scalar.value += 1 vector[i] += 1 p = Process(target=showdata, args=(('process %s' % i), scalar, vector)) p.start() p.join() # 同上,不过允许子进程并行运行 # 所有进程都看到了最近一次迭代的结果,因为共享这个对象 print(" loop2 (update in parent, parallel children) ...") ps = [] for i in range(procs): count += 1 scalar.value += 1 vector[i] += 1 p = Process(target=showdata, args=(('process %s' % i), scalar, vector)) p.start() ps.append(p) for p in ps: p.join() showdata('parent temp', scalar, vector) # 共享内存在派生子进程中更新,等待每个更新结束 print(" loop3 (update in serial children) ...") ps = [] for i in range(procs): p = Process(target=updater, args=(scalar, vector)) p.start() p.join() showdata('parent temp', scalar, vector) # 同上,但是允许子进程并行更新 print(" loop4 (update in parallel children) ...") ps = [] for i in range(procs): p = Process(target=updater, args=(scalar, vector)) p.start() ps.append(p) for p in ps: p.join() showdata('parent temp', scalar, vector) parent start: : pid:20796, global:0, value:0, array:[0.0, 0.0, 0.0] time: 1598267935.7003455 ---*------*------*------*------*------*------*------*------*------*------*------*------*------*------*------*------*------*------*------*--- child: : pid:14172, global:0, value:0, array:[0.0, 0.0, 0.0] time: 1598267935.8503418 loop1 (update in parent, serial children) ... process 0 : pid:23836, global:0, value:1, array:[1.0, 0.0, 0.0] time: 1598267936.032341 process 1 : pid:3356, global:0, value:2, array:[1.0, 1.0, 0.0] time: 1598267936.1933422 process 2 : pid:13252, global:0, value:3, array:[1.0, 1.0, 1.0] time: 1598267936.3533394 loop2 (update in parent, parallel children) ... process 0 : pid:14260, global:0, value:6, array:[2.0, 2.0, 2.0] time: 1598267936.5973456 process 1 : pid:6936, global:0, value:6, array:[2.0, 2.0, 2.0] time: 1598267936.6063423 process 2 : pid:8776, global:0, value:6, array:[2.0, 2.0, 2.0] time: 1598267936.6143434 parent temp : pid:20796, global:6, value:6, array:[2.0, 2.0, 2.0] time: 1598267936.6333387 loop3 (update in serial children) ... count:==> 1 count:==> 1 count:==> 1 parent temp : pid:20796, global:6, value:9, array:[5.0, 5.0, 5.0] time: 1598267937.2193384 loop4 (update in parallel children) ... count:==> 1 count:==> 1 count:==> 1 parent temp : pid:20796, global:6, value:12, array:[8.0, 8.0, 8.0] time: 1598267937.4793396 Process finished with exit code 0
-
注意:全局变量值的变化在
Windows下的派生进程中不被共享,而Value和Array则被共享 -
和线程不同,全局变量在
windows下的每个进行都有一个副本的数据 -
在Unix下,父进程中的共享对象可以被子进程共享,但是只是单向的,子进程对数据的更改不能返回到父进程
队列和子类
multiprocessing有以下特性
-
允许模块的
Process创建子类,并提供架构和状态保留(类似Thread) -
提供进程安全的
Queue对象,可以在任意数量的进程间共享,满足更广泛的通信需求(类似queue.Queue)
队列支持更灵活的多重服务器/客户端模型
""" 创建Process类的子类,类似threading.Thread Queue类似queue.Queue,不过不是线程间的工具,而是进程间的工具 """ import os, time, queue from multiprocessing import Process,Queue # 进程安全的共享队列,是 管道+锁/信号机制 class Counter(Process): label = "@" # 为运行中的用处保留状态 def __init__(self, start, queue): self.state = start self.post = queue Process.__init__(self) def run(self): """新进程中调用start()开始运行""" for i in range(3): time.sleep(1) self.state += 1 print(self.label, self.pid, self.state) # stdout文件为所有进程共享 self.post.put([self.pid, self.state]) print(self.label, self.pid, '-') if __name__ == '__main__': print('start ...', os.getpid()) expected = 9 post = Queue() # 开始共享队列的3个进程,是生产者 p = Counter(0, post) q = Counter(100, post) r = Counter(1000, post) p.start(); q.start();r.start() while expected: # 父进程消耗队列中数据 time.sleep(0.5) try: data = post.get(block=False) except queue.Empty: print("no data ...") else: print('Posted:', data) expected -= 1 p.join() q.join() r.join() print('finish ...', os.getpid(), r.exitcode)
独立程序一般用系统全局工具,如套接字和FIFO文件,来进行通信
multiprocessing派生的进行也可以使用这些工具,但是它们之间较紧密的关系,使得它们可以使用这个模块提供的额外的IPC通信手段
multiprocessing的设计目的是为并行运行函数调用而服务的,而不是直接启动完全不同的程序
如果某个程序的启动可能阻塞其调用者,派生程序可以使用os.system,os.popen和subprocess等工具
但是在其他情况下,开始一个进程来启动某个程序并没有什么意义
启动独立程序的方法
-
Unix下,
os.fork和exec组合 -
os.system,os.popen,subprocess可跨平台移植的shell命令行启动器 -
multiprocessing模块选项 -
os.spawn家族函数os.spawn家族函数os.spawnv和os.spawnve调用的出现是为了在windows下启动程序,和Unix下的os.fork和exec组合调用类似,但是也可以在Unix平台下使用,且添加了一些功能,接近os.exec的作用OS.spawn函数家族在新进程中执行命令行指定的程序,基本操作方面,类似os.fork和exec组合调用并且可以代替我们之前学到的system和open调用不去真的复制调用它们的进程,共享描述符不起作用,可以用来启动一个完全独立于调用者而运行的程序
-
目前的
subprocess和multiprocessing模块都提供了命令行派生程序的具有可移植的替代方案 -
除非
os.spawn调用提供不可获取的独特行为,一般使用更具有可移植性的multiprocessing模块代替
""" 启动10个并行运行的程序 在windows下用spawn启动程序 使用P_OVERLAY进程替换,使用P_DETACH子进程stdout不指向任何地方 """ import os import sys for i in range(10): if sys.platform[:3] == "win": pypath = sys.executable os.spawnv(os.P_NOWAIT, pypath, ('python', 'child.py', str(i))) else: pid = os.fork() if pid != 0: print("Process %d spawned " % pid) else: os.execlp('python', 'python', 'child.py', str(i)) print("Main process exit ...")
-
os.system调用可用来启动一个DOS的start命令(基于一个文件的Windows文件名关联),独立地打开这个文件,就像单击打开一样,在Python中os.startfile将这个操作变得更加简单,而且可以避免阻塞调用者 -
DOS的
start命令:就类似在运行对话框中输入命令一样-
如果是一个文件名,就打开文件,类似在资源管理器中单机一样
-
-
os.startfile不提供等待应用关闭的选项,