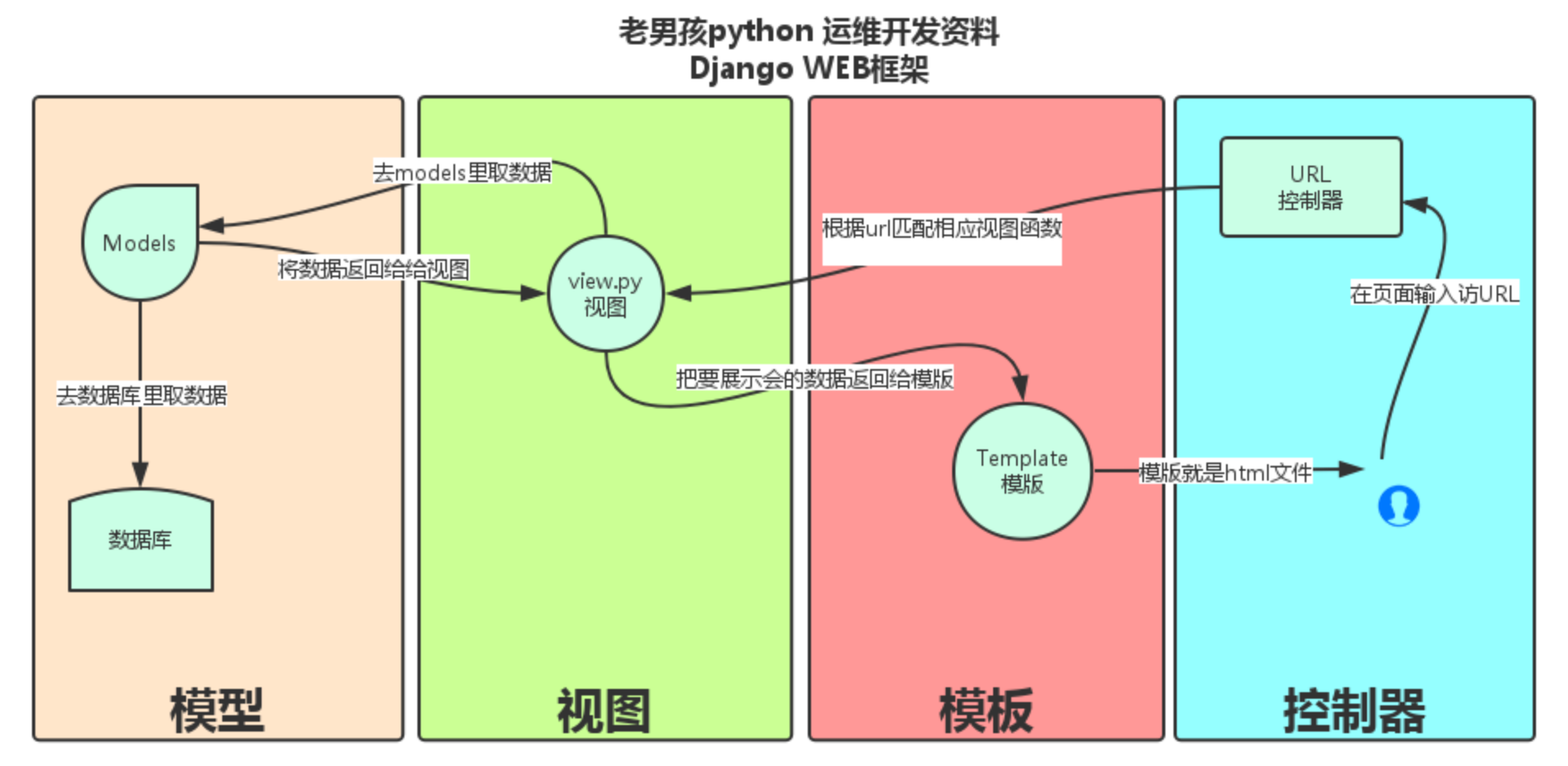
Django-MTV
MTV模型
Django的MTV分别代表:
Model(模型):负责业务对象与数据库的对象(ORM)
Template(模版):负责如何把页面展示给用户
View(视图):负责业务逻辑,并在适当的时候调用Model和Template
此外,Django还有一个urls分发器,它的作用是将一个个URL的页面请求分发给不同的view处理,view再调用相应的Model和Template
Django基本命令
1、下载Django:
pip3 install django
2、创建一个django project
django-admin.py startproject mysite
当前目录下会生成mysite的工程,目录结构如下:
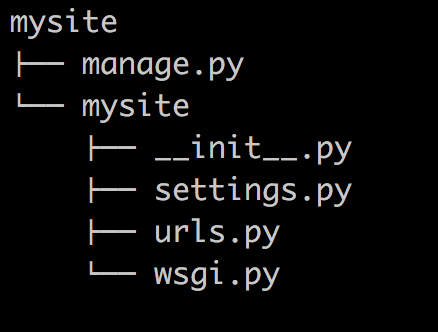
- manage.py ----- Django项目里面的工具,通过它可以调用django shell和数据库等。
- settings.py ---- 包含了项目的默认设置,包括数据库信息,调试标志以及其他一些工作的变量。
- urls.py ----- 负责把URL模式映射到应用程序。
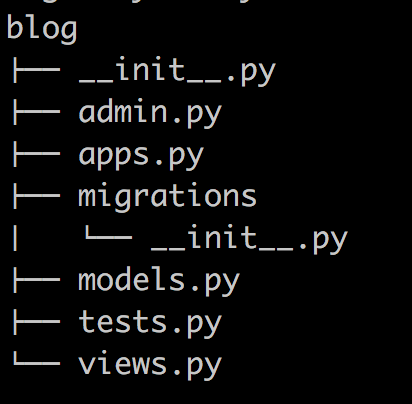
3、在mysite目录下创建应用
python manage.py startapp blog
4、启动django项目
python manage.py runserver 8080
这样我们的django就启动起来了!当我们访问:http://127.0.0.1:8080/时就可以看到:

5、同步更改数据库表或字段
''' python manage.py syncdb 注意:Django 1.7.1 及以上的版本需要用以下命令 python manage.py makemigrations python manage.py migrate '''
这种方法可以创建表,当你在models.py中新增了类时,运行它就可以自动在数据库中创建表了,不用手动创建。
6、清空数据库
python manage.py flush
此命令会询问是 yes 还是 no, 选择 yes 会把数据全部清空掉,只留下空表。
7、创建超级管理员
''' python manage.py createsuperuser # 按照提示输入用户名和对应的密码就好了邮箱可以留空,用户名和密码必填 # 修改 用户密码可以用: python manage.py changepassword username '''
8、Django 项目环境终端
python manage.py shell
这个命令和 直接运行 python 进入 shell 的区别是:你可以在这个 shell 里面调用当前项目的 models.py 中的 API,对于操作数据的测试非常方便。
9、Django 项目环境终端
ython manage.py dbshell
Django 会自动进入在settings.py中设置的数据库,如果是 MySQL 或 postgreSQL,会要求输入数据库用户密码。
在这个终端可以执行数据库的SQL语句。如果您对SQL比较熟悉,可能喜欢这种方式。
10、更多命令
python manage.py
查看所有的命令,忘记子名称的时候特别有用。
11 静态文件配置
概述: 静态文件交由Web服务器处理,Django本身不处理静态文件。简单的处理逻辑如下(以nginx为例): URI请求-----> 按照Web服务器里面的配置规则先处理,以nginx为例,主要求配置在nginx. conf里的location |---------->如果是静态文件,则由nginx直接处理 |---------->如果不是则交由Django处理,Django根据urls.py里面的规则进行匹配 以上是部署到Web服务器后的处理方式,为了便于开发,Django提供了在开发环境的对静态文件的处理机制,方法是这样:
static配置:
STATIC主要指的是如css,js,images这样文件:
STATIC_URL = '/static/' # 别名 STATICFILES_DIRS = ( os.path.join(BASE_DIR,"static"), #实际名 ,即实际文件夹的名字 ) ''' 注意点1: django对引用名和实际名进行映射,引用时,只能按照引用名来,不能按实际名去找 <script src="/statics/jquery-3.1.1.js"></script> ------error-----不能直接用,必须用STATIC_URL = '/static/': <script src="/static/jquery-3.1.1.js"></script> 注意点2: STATICFILES_DIRS = ( ("app01",os.path.join(BASE_DIR, "app01/statics")), ) <script src="/static/app01/jquery.js"></script> '''
have a try:
http://127.0.0.1:8000/static/jquery.js
media配置:
# in settings: MEDIA_URL="/media/" MEDIA_ROOT=os.path.join(BASE_DIR,"app01","media","upload") # in urls: from django.views.static import serve url(r'^media/(?P<path>.*)$', serve, {'document_root': settings.MEDIA_ROOT}),
have a try:
http://127.0.0.1:8000/media/1.png


''' 静态文件的处理又包括STATIC和MEDIA两类,这往往容易混淆,在Django里面是这样定义的: MEDIA:指用户上传的文件,比如在Model里面的FileFIeld,ImageField上传的文件。如果你定义 MEDIA_ROOT=c: empmedia,那么File=models.FileField(upload_to="abc/")#,上传的文件就会被保存到c: empmediaabc eg: class blog(models.Model): Title=models.charField(max_length=64) Photo=models.ImageField(upload_to="photo") 上传的图片就上传到c: empmediaphoto,而在模板中要显示该文件,则在这样写 在settings里面设置的MEDIA_ROOT必须是本地路径的绝对路径,一般是这样写: BASE_DIR= os.path.abspath(os.path.dirname(__file__)) MEDIA_ROOT=os.path.join(BASE_DIR,'media/').replace('\','/') MEDIA_URL是指从浏览器访问时的地址前缀,举个例子: MEDIA_ROOT=c: empmediaphoto MEDIA_URL="/data/" 在开发阶段,media的处理由django处理: 访问http://localhost/data/abc/a.png就是访问c: empmediaphotoabca.png 在模板里面这样写<img src="/media/abc/a.png"> 在部署阶段最大的不同在于你必须让web服务器来处理media文件,因此你必须在web服务器中配置, 以便能让web服务器能访问media文件 以nginx为例,可以在nginx.conf里面这样: location ~/media/{ root/temp/ break; } 具体可以参考如何在nginx部署django的资料。 '''
视图层之路由配置系统(views)
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码。
'''
urlpatterns = [
url(正则表达式, views视图函数,参数,别名),
]
参数说明:
一个正则表达式字符串
一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
可选的要传递给视图函数的默认参数(字典形式)
一个可选的name参数
'''
2.1 URLconf的正则字符串参数
2.1.1 简单配置
from django.conf.urls import url from . import views urlpatterns = [ url(r'^articles/2003/$', views.special_case_2003), url(r'^articles/([0-9]{4})/$', views.year_archive), url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail), ]
''' NOTE: 1 一旦匹配成功则不再继续 2 若要从URL 中捕获一个值,只需要在它周围放置一对圆括号。 3 不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是^articles 而不是 ^/articles。 4 每个正则表达式前面的'r' 是可选的但是建议加上。 一些请求的例子: /articles/2005/3/ 不匹配任何URL 模式,因为列表中的第三个模式要求月份应该是两个数字。 /articles/2003/ 将匹配列表中的第一个模式不是第二个,因为模式按顺序匹配,第一个会首先测试是否匹配。 /articles/2005/03/ 请求将匹配列表中的第三个模式。Django 将调用函数 views.month_archive(request, '2005', '03')。 '''
#设置项是否开启URL访问地址后面不为/跳转至带有/的路径 APPEND_SLASH=True
2.1.2 有名分组(named group)
上面的示例使用简单的、没有命名的正则表达式组(通过圆括号)来捕获URL 中的值并以位置 参数传递给视图。在更高级的用法中,可以使用命名的正则表达式组来捕获URL 中的值并以关键字 参数传递给视图。
在Python 正则表达式中,命名正则表达式组的语法是(?P<name>pattern),其中name 是组的名称,pattern 是要匹配的模式。
下面是以上URLconf 使用命名组的重写:
from django.conf.urls import url from . import views urlpatterns = [ url(r'^articles/2003/$', views.special_case_2003), url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive), url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive), url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail), ]
这个实现与前面的示例完全相同,只有一个细微的差别:捕获的值作为关键字参数而不是位置参数传递给视图函数。例如:
/articles/2005/03/
请求将调用views.month_archive(request, year='2005', month='03')函数
/articles/2003/03/03/
请求将调用函数views.article_detail(request, year='2003', month='03', day='03')。
在实际应用中,这意味你的URLconf 会更加明晰且不容易产生参数顺序问题的错误 —— 你可以在你的视图函数定义中重新安排参数的顺序。当然,这些好处是以简洁为代价;有些开发人员认为命名组语法丑陋而繁琐。
2.1.3 URLconf 在什么上查找
URLconf 在请求的URL 上查找,将它当做一个普通的Python 字符串。不包括GET和POST参数以及域名。
例如,http://www.example.com/myapp/ 请求中,URLconf 将查找myapp/。
在http://www.example.com/myapp/?page=3 请求中,URLconf 仍将查找myapp/。
URLconf 不检查请求的方法。换句话讲,所有的请求方法 —— 同一个URL的POST、GET、HEAD等等 —— 都将路由到相同的函数。
2.1.4 捕获的参数永远是字符串
每个捕获的参数都作为一个普通的Python 字符串传递给视图,无论正则表达式使用的是什么匹配方式。例如,下面这行URLconf 中:
url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
views.year_archive() 的year 参数将是一个字符串
2.1.5 指定视图参数的默认值
有一个方便的小技巧是指定视图参数的默认值。 下面是一个URLconf 和视图的示例:
# URLconf from django.conf.urls import url from . import views urlpatterns = [ url(r'^blog/$', views.page), url(r'^blog/page(?P<num>[0-9]+)/$', views.page), ] # View (in blog/views.py) def page(request, num="1"): ...
在上面的例子中,两个URL模式指向同一个视图views.page —— 但是第一个模式不会从URL 中捕获任何值。如果第一个模式匹配,page() 函数将使用num参数的默认值"1"。如果第二个模式匹配,page() 将使用正则表达式捕获的num 值。
2.1.6 Including other URLconfs
#At any point, your urlpatterns can “include” other URLconf modules. This #essentially “roots” a set of URLs below other ones. #For example, here’s an excerpt of the URLconf for the Django website itself. #It includes a number of other URLconfs: from django.conf.urls import include, url urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^blog/', include('blog.urls')), ]
2.2 传递额外的选项给视图函数(了解)
URLconfs 具有一个钩子,让你传递一个Python 字典作为额外的参数传递给视图函数。
django.conf.urls.url() 函数可以接收一个可选的第三个参数,它是一个字典,表示想要传递给视图函数的额外关键字参数。
例如:
from django.conf.urls import url from . import views urlpatterns = [ url(r'^blog/(?P<year>[0-9]{4})/$', views.year_archive, {'foo': 'bar'}), ]
在这个例子中,对于/blog/2005/请求,Django 将调用views.year_archive(request, year='2005', foo='bar')。
这个技术在Syndication 框架中使用,来传递元数据和选项给视图。
2.3 URL 的反向解析
在使用Django 项目时,一个常见的需求是获得URL 的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。
人们强烈希望不要硬编码这些URL(费力、不可扩展且容易产生错误)或者设计一种与URLconf 毫不相关的专门的URL 生成机制,因为这样容易导致一定程度上产生过期的URL。
换句话讲,需要的是一个DRY 机制。除了其它有点,它还允许设计的URL 可以自动更新而不用遍历项目的源代码来搜索并替换过期的URL。
获取一个URL 最开始想到的信息是处理它视图的标识(例如名字),查找正确的URL 的其它必要的信息有视图参数的类型(位置参数、关键字参数)和值。
Django 提供一个办法是让URL 映射是URL 设计唯一的地方。你填充你的URLconf,然后可以双向使用它:
- 根据用户/浏览器发起的URL 请求,它调用正确的Django 视图,并从URL 中提取它的参数需要的值。
- 根据Django 视图的标识和将要传递给它的参数的值,获取与之关联的URL。
第一种方式是我们在前面的章节中一直讨论的用法。第二种方式叫做反向解析URL、反向URL 匹配、反向URL 查询或者简单的URL 反查。
在需要URL 的地方,对于不同层级,Django 提供不同的工具用于URL 反查:
- 在模板中:使用url 模板标签。
- 在Python 代码中:使用
django.core.urlresolvers.reverse()函数。 - 在更高层的与处理Django 模型实例相关的代码中:使用
get_absolute_url()方法。
例子:
考虑下面的URLconf:
from django.conf.urls import url from . import views urlpatterns = [ #... url(r'^articles/([0-9]{4})/$', views.year_archive, name='news-year-archive'), #... ]
根据这里的设计,某一年nnnn对应的归档的URL是/articles/nnnn/。
你可以在模板的代码中使用下面的方法获得它们:
<a href="{% url 'news-year-archive' 2012 %}">2012 Archive</a> <ul> {% for yearvar in year_list %} <li><a href="{% url 'news-year-archive' yearvar %}">{{ yearvar }} Archive</a></li> {% endfor %} </ul>
在Python 代码中,这样使用:
from django.core.urlresolvers import reverse from django.http import HttpResponseRedirect def redirect_to_year(request): # ... year = 2006 # ... return HttpResponseRedirect(reverse('news-year-archive', args=(year,)))
如果出于某种原因决定按年归档文章发布的URL应该调整一下,那么你将只需要修改URLconf 中的内容。
在某些场景中,一个视图是通用的,所以在URL 和视图之间存在多对一的关系。对于这些情况,当反查URL 时,只有视图的名字还不够。
2.4 名称空间(Namespace)
命名空间(英语:Namespace)是表示标识符的可见范围。一个标识符可在多个命名空间中定义,它在不同命名空间中的含义是互不相干的。这样,在一个新的命名空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,因为已有的定义都处于其它命名空间中。
urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^app01/', include("app01.urls",namespace="app01")), url(r'^app02/', include("app02.urls",namespace="app02")), ]
app01.urls:
urlpatterns = [ url(r'^index/', index,name="index"), ]
app02.urls:
urlpatterns = [ url(r'^index/', index,name="index"), ]
app01.views
from django.core.urlresolvers import reverse def index(request): return HttpResponse(reverse("app01:index"))
app02.views
from django.core.urlresolvers import reverse def index(request): return HttpResponse(reverse("app02:index"))
2.5 CBV
url(r'^login.html$', views.Login.as_view()),
============================
from django.views import View
class Login(View):
def dispatch(self, request, *args, **kwargs):
print('before')
obj = super(Login,self).dispatch(request, *args, **kwargs)
print('after')
return obj
def get(self,request):
return render(request,'login.html')
def post(self,request):
print(request.POST.get('user'))
return HttpResponse('Login.post')
视图层之视图函数(views)
一个视图函数,简称视图,是一个简单的Python 函数,它接受Web请求并且返回Web响应。响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片. . . 是任何东西都可以。无论视图本身包含什么逻辑,都要返回响应。代码写在哪里也无所谓,只要它在你的Python目录下面。除此之外没有更多的要求了——可以说“没有什么神奇的地方”。为了将代码放在某处,约定是将视图放置在项目或应用程序目录中的名为views.py的文件中。
一个简单的视图
下面是一个返回当前日期和时间作为HTML文档的视图:
from django.http import HttpResponse import datetime def current_datetime(request): now = datetime.datetime.now() html = "<html><body>It is now %s.</body></html>" % now return HttpResponse(html)
让我们逐行阅读上面的代码:
-
首先,我们从 django.http模块导入了HttpResponse类,以及Python的datetime库。
-
接着,我们定义了current_datetime函数。它就是视图函数。每个视图函数都使用HttpRequest对象作为第一个参数,并且通常称之为request。
注意,视图函数的名称并不重要;不需要用一个统一的命名方式来命名,以便让Django识别它。我们将其命名为current_datetime,是因为这个名称能够精确地反映出它的功能。
-
这个视图会返回一个HttpResponse对象,其中包含生成的响应。每个视图函数都负责返回一个HttpResponse对象。

HttpRequest对象的属性
属性: django将请求报文中的请求行、首部信息、内容主体封装成 HttpRequest 类中的属性。 除了特殊说明的之外,其他均为只读的。 ''' 1.HttpRequest.body 一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,例如:二进制图片、XML,Json等。 但是,如果要处理表单数据的时候,推荐还是使用 HttpRequest.POST 。 另外,我们还可以用 python 的类文件方法去操作它,详情参考 HttpRequest.read() 。 2.HttpRequest.path 一个字符串,表示请求的路径组件(不含域名)。 例如:"/music/bands/the_beatles/" 3.HttpRequest.method 一个字符串,表示请求使用的HTTP 方法。必须使用大写。 例如:"GET"、"POST" 4.HttpRequest.encoding 一个字符串,表示提交的数据的编码方式(如果为 None 则表示使用 DEFAULT_CHARSET 的设置,默认为 'utf-8')。 这个属性是可写的,你可以修改它来修改访问表单数据使用的编码。 接下来对属性的任何访问(例如从 GET 或 POST 中读取数据)将使用新的 encoding 值。 如果你知道表单数据的编码不是 DEFAULT_CHARSET ,则使用它。 5.HttpRequest.GET 一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。 6.HttpRequest.POST 一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。 POST 请求可以带有空的 POST 字典 —— 如果通过 HTTP POST 方法发送一个表单,但是表单中没有任何的数据,QueryDict 对象依然会被创建。 因此,不应该使用 if request.POST 来检查使用的是否是POST 方法;应该使用 if request.method == "POST" 另外:如果使用 POST 上传文件的话,文件信息将包含在 FILES 属性中。 7.HttpRequest.REQUEST 一个类似于字典的对象,它首先搜索POST,然后搜索GET,主要是为了方便。灵感来自于PHP 的 $_REQUEST。 例如,如果 GET = {"name": "john"} 而 POST = {"age": '34'} , REQUEST["name"] 将等于"john", REQUEST["age"] 将等于"34"。 强烈建议使用 GET 和 POST 而不要用REQUEST,因为它们更加明确。 8.HttpRequest.COOKIES 一个标准的Python 字典,包含所有的cookie。键和值都为字符串。 9.HttpRequest.FILES 一个类似于字典的对象,包含所有的上传文件信息。 FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。 注意,FILES 只有在请求的方法为POST 且提交的<form> 带有enctype="multipart/form-data" 的情况下才会 包含数据。否则,FILES 将为一个空的类似于字典的对象。 10.HttpRequest.META 一个标准的Python 字典,包含所有的HTTP 首部。具体的头部信息取决于客户端和服务器,下面是一些示例: CONTENT_LENGTH —— 请求的正文的长度(是一个字符串)。 CONTENT_TYPE —— 请求的正文的MIME 类型。 HTTP_ACCEPT —— 响应可接收的Content-Type。 HTTP_ACCEPT_ENCODING —— 响应可接收的编码。 HTTP_ACCEPT_LANGUAGE —— 响应可接收的语言。 HTTP_HOST —— 客服端发送的HTTP Host 头部。 HTTP_REFERER —— Referring 页面。 HTTP_USER_AGENT —— 客户端的user-agent 字符串。 QUERY_STRING —— 单个字符串形式的查询字符串(未解析过的形式)。 REMOTE_ADDR —— 客户端的IP 地址。 REMOTE_HOST —— 客户端的主机名。 REMOTE_USER —— 服务器认证后的用户。 REQUEST_METHOD —— 一个字符串,例如"GET" 或"POST"。 SERVER_NAME —— 服务器的主机名。 SERVER_PORT —— 服务器的端口(是一个字符串)。 从上面可以看到,除 CONTENT_LENGTH 和 CONTENT_TYPE 之外,请求中的任何 HTTP 首部转换为 META 的键时, 都会将所有字母大写并将连接符替换为下划线最后加上 HTTP_ 前缀。 所以,一个叫做 X-Bender 的头部将转换成 META 中的 HTTP_X_BENDER 键。 11.HttpRequest.user 一个 AUTH_USER_MODEL 类型的对象,表示当前登录的用户。 如果用户当前没有登录,user 将设置为 django.contrib.auth.models.AnonymousUser 的一个实例。你可以通过 is_authenticated() 区分它们。 例如: if request.user.is_authenticated(): # Do something for logged-in users. else: # Do something for anonymous users. user 只有当Django 启用 AuthenticationMiddleware 中间件时才可用。 ------------------------------------------------------------------------------------- 匿名用户 class models.AnonymousUser django.contrib.auth.models.AnonymousUser 类实现了django.contrib.auth.models.User 接口,但具有下面几个不同点: id 永远为None。 username 永远为空字符串。 get_username() 永远返回空字符串。 is_staff 和 is_superuser 永远为False。 is_active 永远为 False。 groups 和 user_permissions 永远为空。 is_anonymous() 返回True 而不是False。 is_authenticated() 返回False 而不是True。 set_password()、check_password()、save() 和delete() 引发 NotImplementedError。 New in Django 1.8: 新增 AnonymousUser.get_username() 以更好地模拟 django.contrib.auth.models.User。 12.HttpRequest.session 一个既可读又可写的类似于字典的对象,表示当前的会话。只有当Django 启用会话的支持时才可用。 完整的细节参见会话的文档。 13.HttpRequest.resolver_match 一个 ResolverMatch 的实例,表示解析后的URL。这个属性只有在 URL 解析方法之后才设置,这意味着它在所有的视图中可以访问, 但是在 URL 解析发生之前执行的中间件方法中不可以访问(比如process_request,但你可以使用 process_view 代替)。 '''
HttpRequest对象的方法
''' 1.HttpRequest.get_host() 根据从HTTP_X_FORWARDED_HOST(如果打开 USE_X_FORWARDED_HOST,默认为False)和 HTTP_HOST 头部信息返回请求的原始主机。
如果这两个头部没有提供相应的值,则使用SERVER_NAME 和SERVER_PORT,在PEP 3333 中有详细描述。 USE_X_FORWARDED_HOST:一个布尔值,用于指定是否优先使用 X-Forwarded-Host 首部,仅在代理设置了该首部的情况下,才可以被使用。 例如:"127.0.0.1:8000" 注意:当主机位于多个代理后面时,get_host() 方法将会失败。除非使用中间件重写代理的首部。 2.HttpRequest.get_full_path() 返回 path,如果可以将加上查询字符串。 例如:"/music/bands/the_beatles/?print=true" 3.HttpRequest.build_absolute_uri(location) 返回location 的绝对URI。如果location 没有提供,则使用request.get_full_path()的返回值。 如果URI 已经是一个绝对的URI,将不会修改。否则,使用请求中的服务器相关的变量构建绝对URI。 例如:"http://example.com/music/bands/the_beatles/?print=true" 4.HttpRequest.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age=None) 返回签名过的Cookie 对应的值,如果签名不再合法则返回django.core.signing.BadSignature。 如果提供 default 参数,将不会引发异常并返回 default 的值。 可选参数salt 可以用来对安全密钥强力攻击提供额外的保护。max_age 参数用于检查Cookie 对应的时间戳以确保Cookie 的时间不会超过max_age 秒。 复制代码 >>> request.get_signed_cookie('name') 'Tony' >>> request.get_signed_cookie('name', salt='name-salt') 'Tony' # 假设在设置cookie的时候使用的是相同的salt >>> request.get_signed_cookie('non-existing-cookie') ... KeyError: 'non-existing-cookie' # 没有相应的键时触发异常 >>> request.get_signed_cookie('non-existing-cookie', False) False >>> request.get_signed_cookie('cookie-that-was-tampered-with') ... BadSignature: ... >>> request.get_signed_cookie('name', max_age=60) ... SignatureExpired: Signature age 1677.3839159 > 60 seconds >>> request.get_signed_cookie('name', False, max_age=60) False 复制代码 5.HttpRequest.is_secure() 如果请求时是安全的,则返回True;即请求通是过 HTTPS 发起的。 6.HttpRequest.is_ajax() 如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH 相应的首部是否是字符串'XMLHttpRequest'。 大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),你必须手工设置这个值来让 is_ajax() 可以工作。 如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形式的缓存例如Django 的 cache middleware,
你应该使用 vary_on_headers('HTTP_X_REQUESTED_WITH') 装饰你的视图以让响应能够正确地缓存。 7.HttpRequest.read(size=None) 像文件一样读取请求报文的内容主体,同样的,还有以下方法可用。 HttpRequest.readline() HttpRequest.readlines() HttpRequest.xreadlines() 其行为和文件操作中的一样。 HttpRequest.__iter__():说明可以使用 for 的方式迭代文件的每一行。'''
注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用:
request.POST.getlist("hobby")
render 函数
render(request, template_name[, context])
结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
参数:
request: 用于生成响应的请求对象。
template_name:要使用的模板的完整名称,可选的参数
context:添加到模板上下文的一个字典。默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
content_type:生成的文档要使用的MIME类型。默认为DEFAULT_CONTENT_TYPE 设置的值。
status:响应的状态码。默认为200。
redirect 函数
参数可以是:
- 一个模型:将调用模型的get_absolute_url() 函数
- 一个视图,可以带有参数:将使用urlresolvers.reverse 来反向解析名称
- 一个绝对的或相对的URL,将原封不动的作为重定向的位置。
默认返回一个临时的重定向;传递permanent=True 可以返回一个永久的重定向。
你可以用多种方式使用redirect() 函数。
传递一个对象
将调用get_absolute_url() 方法来获取重定向的URL:
from django.shortcuts import redirect
def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object)
传递一个视图的名称
可以带有位置参数和关键字参数;将使用reverse() 方法反向解析URL:
def my_view(request):
...
return redirect('some-view-name', foo='bar')
传递要重定向的一个硬编码的URL
def my_view(request):
...
return redirect('/some/url/')
也可以是一个完整的URL:
def my_view(request):
...
return redirect('http://example.com/')
默认情况下,redirect() 返回一个临时重定向。以上所有的形式都接收一个permanent 参数;如果设置为True,将返回一个永久的重定向:
def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object, permanent=True)
跳转(重定向)应用
-----------------------------------url.py url(r"login", views.login), url(r"yuan_back", views.yuan_back), -----------------------------------views.py def login(req): if req.method=="POST": if 1: # return redirect("/yuan_back/") name="yuanhao" return render(req,"my backend.html",locals()) return render(req,"login.html",locals()) def yuan_back(req): name="苑昊" return render(req,"my backend.html",locals()) -----------------------------------login.html <form action="/login/" method="post"> <p>姓名<input type="text" name="username"></p> <p>性别<input type="text" name="sex"></p> <p>邮箱<input type="text" name="email"></p> <p><input type="submit" value="submit"></p> </form> -----------------------------------my backend.html <h1>用户{{ name }}你好</h1>
redirect关键点:两次请求过程,掌握流程。
注意:render和redirect的区别:
1、 if 页面需要模板语言渲染,需要的将数据库的数据加载到html,那么render方法则不会显示这一部分。
2、 the most important: url没有跳转到/yuan_back/,而是还在/login/,所以当刷新后又得重新登录。
模板层(template)
你可能已经注意到我们在例子视图中返回文本的方式有点特别。 也就是说,HTML被直接硬编码在 Python代码之中。
def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
尽管这种技术便于解释视图是如何工作的,但直接将HTML硬编码到你的视图里却并不是一个好主意。 让我们来看一下为什么:
-
对页面设计进行的任何改变都必须对 Python 代码进行相应的修改。 站点设计的修改往往比底层 Python 代码的修改要频繁得多,因此如果可以在不进行 Python 代码修改的情况下变更设计,那将会方便得多。
-
Python 代码编写和 HTML 设计是两项不同的工作,大多数专业的网站开发环境都将他们分配给不同的人员(甚至不同部门)来完成。 设计者和HTML/CSS的编码人员不应该被要求去编辑Python的代码来完成他们的工作。
-
程序员编写 Python代码和设计人员制作模板两项工作同时进行的效率是最高的,远胜于让一个人等待另一个人完成对某个既包含 Python又包含 HTML 的文件的编辑工作。
基于这些原因,将页面的设计和Python的代码分离开会更干净简洁更容易维护。 我们可以使用 Django的 模板系统 (Template System)来实现这种模式,这就是本章要具体讨论的问题。
python的模板:HTML代码+模板语法
模版包括在使用时会被值替换掉的 变量,和控制模版逻辑的 标签。
def current_time(req): # ================================原始的视图函数 # import datetime # now=datetime.datetime.now() # html="<html><body>现在时刻:<h1>%s.</h1></body></html>" %now # ================================django模板修改的视图函数 # from django.template import Template,Context # now=datetime.datetime.now() # t=Template('<html><body>现在时刻是:<h1>{{current_date}}</h1></body></html>') # #t=get_template('current_datetime.html') # c=Context({'current_date':str(now)}) # html=t.render(c) # # return HttpResponse(html) #另一种写法(推荐) import datetime now=datetime.datetime.now() return render(req, 'current_datetime.html', {'current_date':str(now)[:19]})
模板语法之变量
在 Django 模板中遍历复杂数据结构的关键是句点字符 .
语法:
{{var_name}}
views:
def index(request):
import datetime
s="hello"
l=[111,222,333] # 列表
dic={"name":"yuan","age":18} # 字典
date = datetime.date(1993, 5, 2) # 日期对象
class Person(object):
def __init__(self,name):
self.name=name
person_yuan=Person("yuan") # 自定义类对象
person_egon=Person("egon")
person_alex=Person("alex")
person_list=[person_yuan,person_egon,person_alex]
return render(request,"index.html",{"l":l,"dic":dic,"date":date,"person_list":person_list})
template:
<h4>{{s}}</h4>
<h4>列表:{{ l.0 }}</h4>
<h4>列表:{{ l.2 }}</h4>
<h4>字典:{{ dic.name }}</h4>
<h4>日期:{{ date.year }}</h4>
<h4>类对象列表:{{ person_list.0.name }}</h4>
注意:句点符也可以用来引用对象的方法(无参数方法)。
<h4>字典:{{ dic.name.upper }}</h4>
模板之过滤器
语法:
{{obj|filter__name:param}}
default
如果一个变量是false或者为空,使用给定的默认值。否则,使用变量的值。例如:
{{ value|default:"nothing" }}
length
返回值的长度。它对字符串和列表都起作用。例如:
{{ value|length }}
如果 value 是 ['a', 'b', 'c', 'd'],那么输出是 4。
filesizeformat
将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等)。例如:
{{ value|filesizeformat }}
如果 value 是 123456789,输出将会是 117.7 MB。
date
如果 value=datetime.datetime.now()
{{ value|date:"Y-m-d" }}
slice
如果 value="hello world"
{{ value|slice:"2:-1" }}
truncatechars
如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾。
参数:要截断的字符数
例如:
{{ value|truncatechars:9 }}
如果value是“Joel 是 a >,输出将为“Joel i ...”。
safe
Django的模板中会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全。但是有的时候我们可能不希望这些HTML元素被转义,比如我们做一个内容管理系统,后台添加的文章中是经过修饰的,这些修饰可能是通过一个类似于FCKeditor编辑加注了HTML修饰符的文本,如果自动转义的话显示的就是保护HTML标签的源文件。为了在Django中关闭HTML的自动转义有两种方式,如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。比如:
value="<a href="">点击</a>"
{{ value|safe}}
这里简单介绍一些常用的模板的过滤器,更多详见
模板之标签
标签看起来像是这样的: {% tag %}。标签比变量更加复杂:一些在输出中创建文本,一些通过循环或逻辑来控制流程,一些加载其后的变量将使用到的额外信息到模版中。
一些标签需要开始和结束标签 (例如{% tag %} ...标签 内容 ... {% endtag %})。
for标签
遍历每一个元素:
{% for person in person_list %} <p>{{ person.name }}</p> {% endfor %}
可以利用{% for obj in list reversed %}反向完成循环。
遍历一个字典:
{% for key,val in dic.items %} <p>{{ key }}:{{ val }}</p> {% endfor %}
注:循环序号可以通过{{forloop}}显示
forloop.counter The current iteration of the loop (1-indexed) forloop.counter0 The current iteration of the loop (0-indexed) forloop.revcounter The number of iterations from the end of the loop (1-indexed) forloop.revcounter0 The number of iterations from the end of the loop (0-indexed) forloop.first True if this is the first time through the loop forloop.last True if this is the last time through the loop
for ... empty
for 标签带有一个可选的{% empty %} 从句,以便在给出的组是空的或者没有被找到时,可以有所操作。
{% for person in person_list %} <p>{{ person.name }}</p> {% empty %} <p>sorry,no person here</p> {% endfor %}
if 标签
{% if %}会对一个变量求值,如果它的值是“True”(存在、不为空、且不是boolean类型的false值),对应的内容块会输出。
{% if num > 100 or num < 0 %}
<p>无效</p>
{% elif num > 80 and num < 100 %}
<p>优秀</p>
{% else %}
<p>凑活吧</p>
{% endif %}
with
使用一个简单地名字缓存一个复杂的变量,当你需要使用一个“昂贵的”方法(比如访问数据库)很多次的时候是非常有用的
例如:
{% with total=business.employees.count %}
{{ total }} employee{{ total|pluralize }}
{% endwith %}
csrf_token
这个标签用于跨站请求伪造保护
自定义标签和过滤器
1、在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag.
2、在app中创建templatetags模块(模块名只能是templatetags)
3、创建任意 .py 文件,如:my_tags.py
from django import template
from django.utils.safestring import mark_safe
register = template.Library() #register的名字是固定的,不可改变
@register.filter
def filter_multi(v1,v2):
return v1 * v2
@register.simple_tag
def simple_tag_multi(v1,v2):
return v1 * v2
@register.simple_tag
def my_input(id,arg):
result = "<input type='text' id='%s' class='%s' />" %(id,arg,)
return mark_safe(result)
4、在使用自定义simple_tag和filter的html文件中导入之前创建的 my_tags.py
{% load my_tags %}
5、使用simple_tag和filter(如何调用)
-------------------------------.html
{% load xxx %}
# num=12
{{ num|filter_multi:2 }} #24
{{ num|filter_multi:"[22,333,4444]" }}
{% simple_tag_multi 2 5 %} 参数不限,但不能放在if for语句中
{% simple_tag_multi num 5 %}
注意:filter可以用在if等语句后,simple_tag不可以
{% if num|filter_multi:30 > 100 %}
{{ num|filter_multi:30 }}
{% endif %}
模板继承 (extend)
Django模版引擎中最强大也是最复杂的部分就是模版继承了。模版继承可以让您创建一个基本的“骨架”模版,它包含您站点中的全部元素,并且可以定义能够被子模版覆盖的 blocks 。
通过从下面这个例子开始,可以容易的理解模版继承:
<!DOCTYPE html> <html lang="en"> <head> <link rel="stylesheet" href="style.css" /> <title>{% block title %}My amazing site{%/span> endblock %}</title> </head> <body> <div id="sidebar"> {% block sidebar %} <ul> <li><a href="/">Home</a></li> <li><a href="/blog/">Blog</a></li> </ul> {% endblock %} </div> <div id="content"> {% block content %}{% endblock %} </div> </body> </html>
这个模版,我们把它叫作 base.html, 它定义了一个可以用于两列排版页面的简单HTML骨架。“子模版”的工作是用它们的内容填充空的blocks。
在这个例子中, block 标签定义了三个可以被子模版内容填充的block。 block 告诉模版引擎: 子模版可能会覆盖掉模版中的这些位置。
子模版可能看起来是这样的:
{% extends "base.html" %}
{% block title %}My amazing blog{% endblock %}
{% block content %}
{% for entry in blog_entries %}
<h2>{{ entry.title }}</h2>
<p>{{ entry.body }}</p>
{% endfor %}
{% endblock %}
extends 标签是这里的关键。它告诉模版引擎,这个模版“继承”了另一个模版。当模版系统处理这个模版时,首先,它将定位父模版——在此例中,就是“base.html”。
那时,模版引擎将注意到 base.html 中的三个 block 标签,并用子模版中的内容来替换这些block。根据 blog_entries 的值,输出可能看起来是这样的:
<!DOCTYPE html>
<html lang="en">
<head>
<link rel="stylesheet" href="style.css" />
<title>My amazing blog</title>
</head>
<body>
<div id="sidebar">
<ul>
<li><a href="/">Home</a></li>
<li><a href="/blog/">Blog</a></li>
</ul>
</div>
<div id="content">
<h2>Entry one</h2>
<p>This is my first entry.</p>
<h2>Entry two</h2>
<p>This is my second entry.</p>
</div>
</body>
</html>
请注意,子模版并没有定义 sidebar block,所以系统使用了父模版中的值。父模版的 {% block %} 标签中的内容总是被用作备选内容(fallback)。
这种方式使代码得到最大程度的复用,并且使得添加内容到共享的内容区域更加简单,例如,部分范围内的导航。
这里是使用继承的一些提示:
-
如果你在模版中使用
{% extends %}标签,它必须是模版中的第一个标签。其他的任何情况下,模版继承都将无法工作。 -
在base模版中设置越多的
{% block %}标签越好。请记住,子模版不必定义全部父模版中的blocks,所以,你可以在大多数blocks中填充合理的默认内容,然后,只定义你需要的那一个。多一点钩子总比少一点好。 -
如果你发现你自己在大量的模版中复制内容,那可能意味着你应该把内容移动到父模版中的一个
{% block %}中。 -
If you need to get the content of the block from the parent template, the
{{ block.super }}variable will do the trick. This is useful if you want to add to the contents of a parent block instead of completely overriding it. Data inserted using{{ block.super }}will not be automatically escaped (see the next section), since it was already escaped, if necessary, in the parent template. -
为了更好的可读性,你也可以给你的
{% endblock %}标签一个 名字 。例如:{% block content %} ... {% endblock content %}在大型模版中,这个方法帮你清楚的看到哪一个
{% block %}标签被关闭了。
最后,请注意您并不能在一个模版中定义多个相同名字的 block 标签。这个限制的存在是因为block标签的作用是“双向”的。这个意思是,block标签不仅提供了一个坑去填,它还在 _父模版_中定义了填坑的内容。如果在一个模版中有两个名字一样的 block 标签,模版的父模版将不知道使用哪个block的内容。
模型层基础(model)
模型层进阶(model)
C语言I作业12—学期总结
C语言I博客作业11
C语言I博客作业10
非数值数据的编码方式
定点数
C语言||作业01
C语言寒假大作战04
C语言寒假大作战03
C语言寒假大作战02