一、场景描述:
接口1返回html内容,其中包含有供下一个接口上送的验签值,该验签值每次都不一样,接口2拿到接口1html中的验签后,将该验签作为参数之一一起请求。
二、实现过程:
1、整体目录

过程:‘获取HTML加载的上送token’接口通过get方式,返回带有验签的value值的HTML内容。通过 Xpath Extractor这个插件,将返回的value值取出来,并赋值给变量Token, ‘新增应用’接口引用变量Token的值。最终实现成功发送请求的过程。
2、接口1与接口2的关系说明:
第二个接口的请求参数如图:
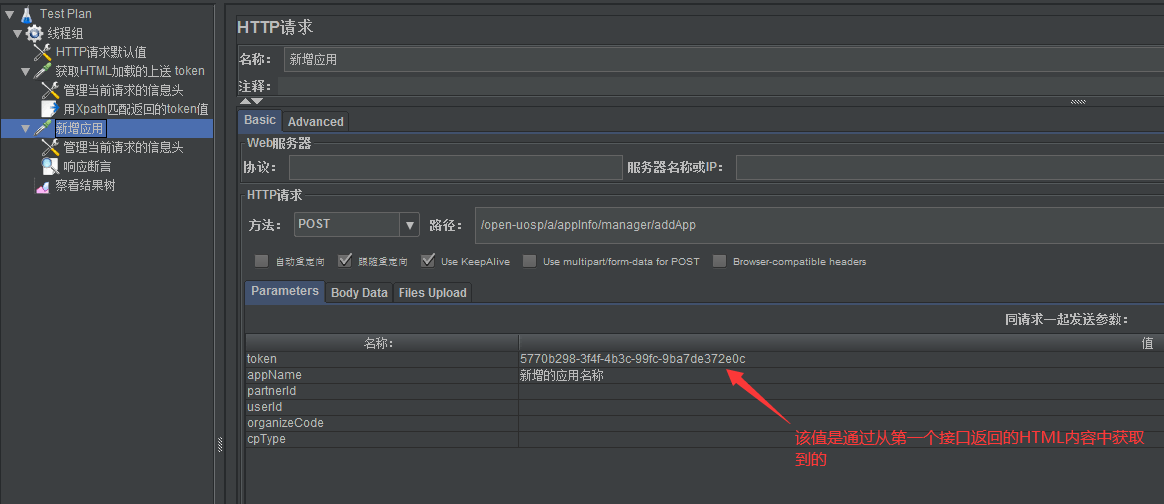
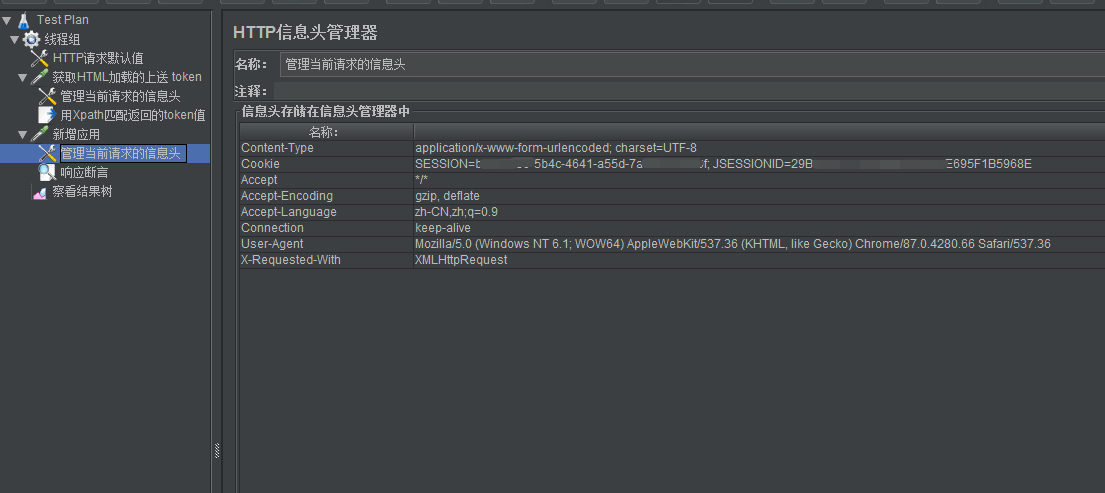
第二个接口的信息头内容:
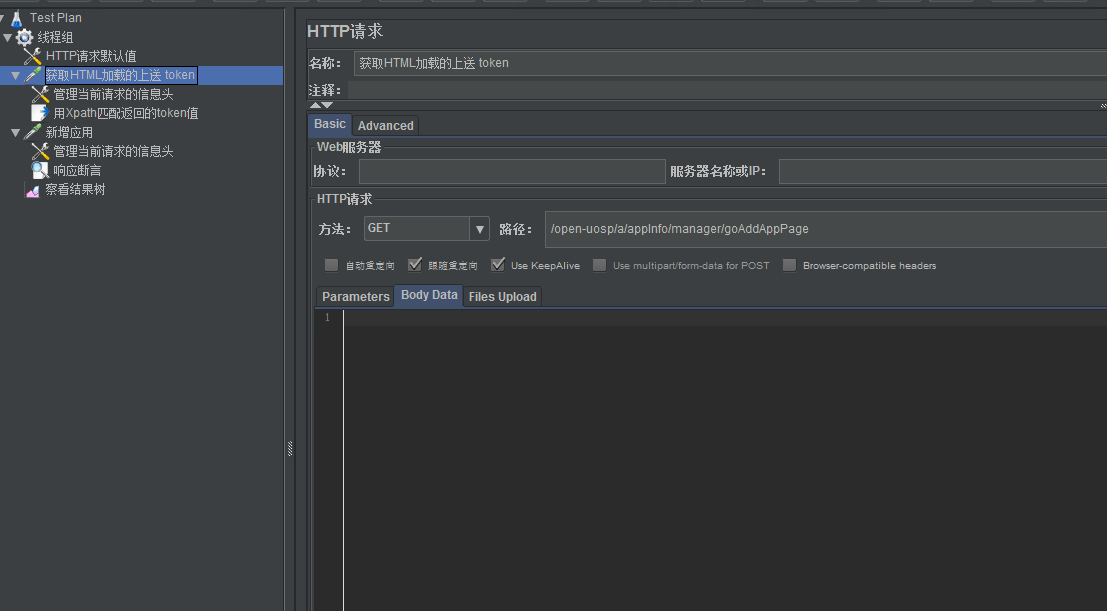
第一个接口请求内容,该接口是为get请求:
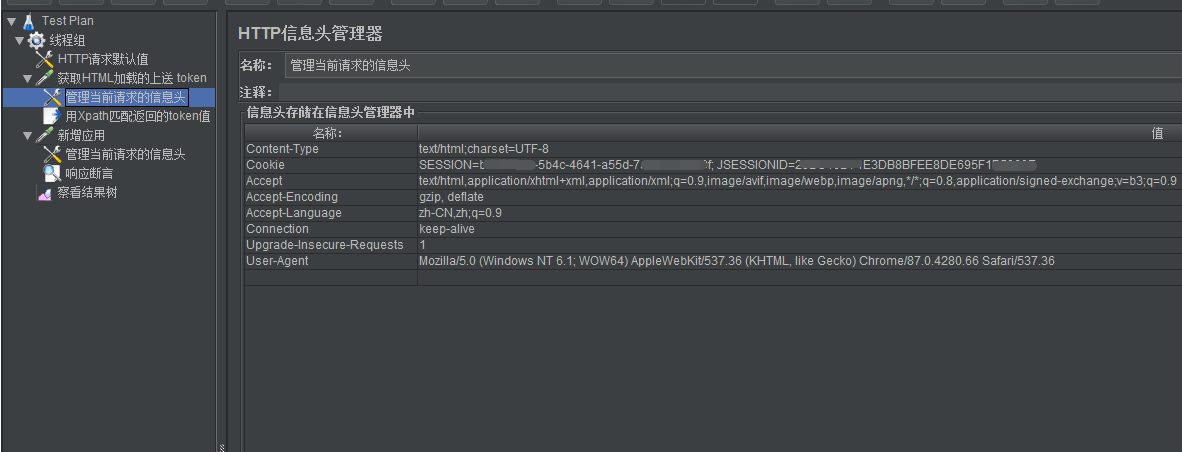
第一个接口的信息头内容:
第一个接口返回内容,为标准的html页面:
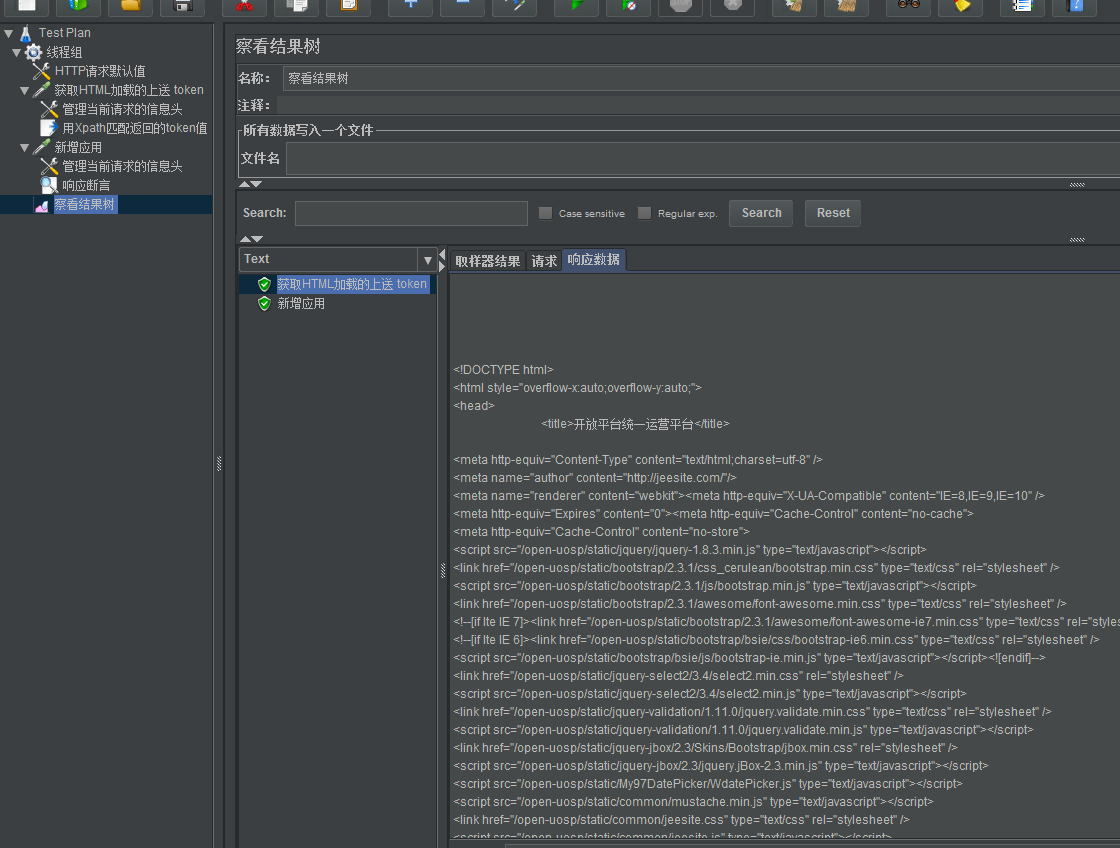
第一个接口中需要取出的目标值:

3、Xpath Extractor的取值过程:

Xpath表达式说明:
//*[@id='token']/@value
释意:在所有标签下找到id为token的标签 ,并取出该标签下的value值。
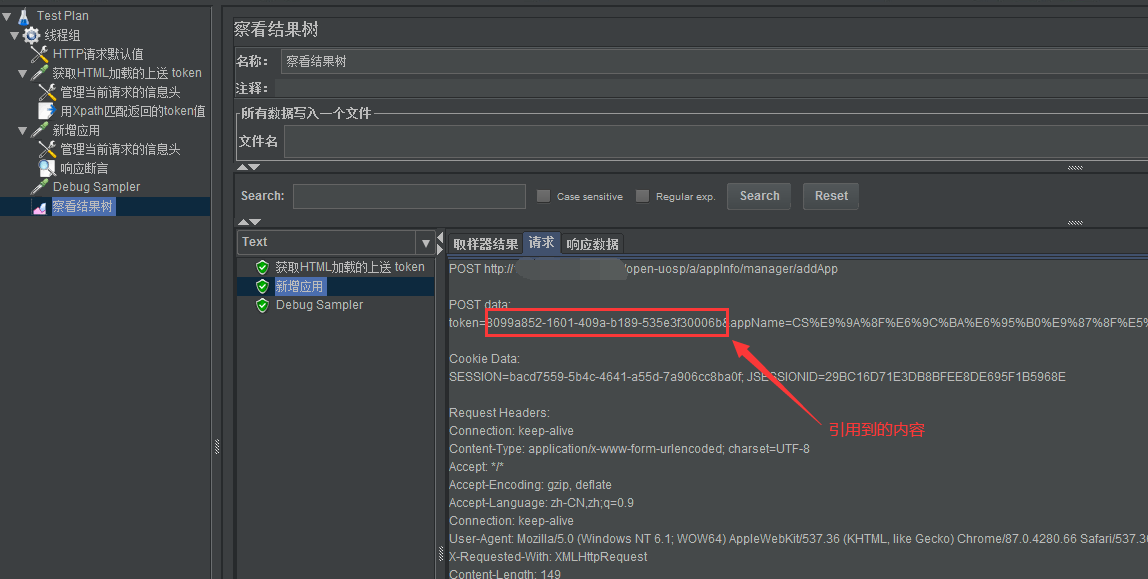
4、接口2的引用过程:

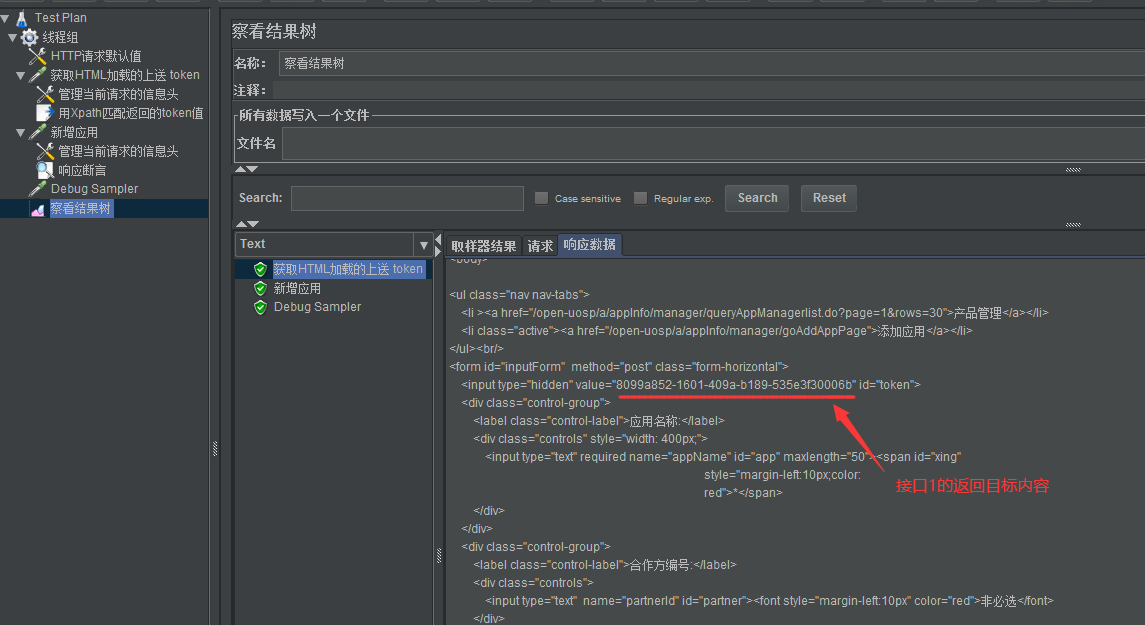
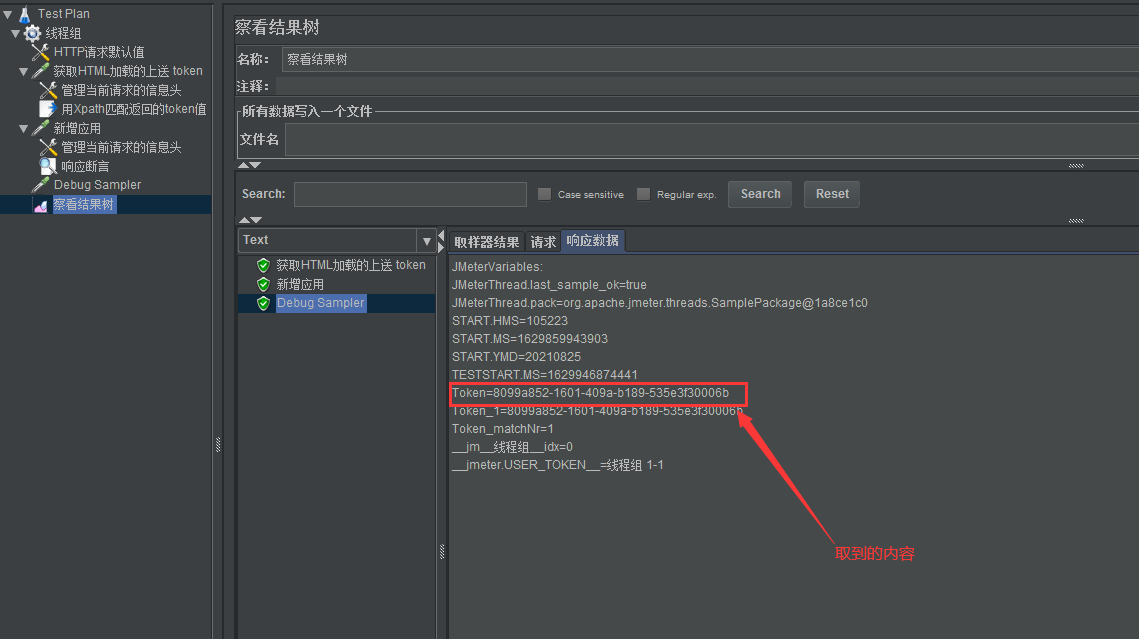
5、结果验证:
三、补充说明:
1、关于Xpath详细了解的可以去:
2、关于Xpath Extractor面板的各项指标说明:
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples::作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
XML Parsing Options:要解析的XML参数
UseTidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
Quiet:表示只显示需要的HTML页面,
Report errors:表示显示响应报错,
Show warnings:表示显示警告;
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析;
Ignore Whitespace:忽略空白内容;
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容;
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
Reference Name:引用名称,存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。
匹配数字:取第几个匹配结果,0随机,-1全部,1代表第一个,2代表第二个,....以此类推
Default Value:参数的默认值。