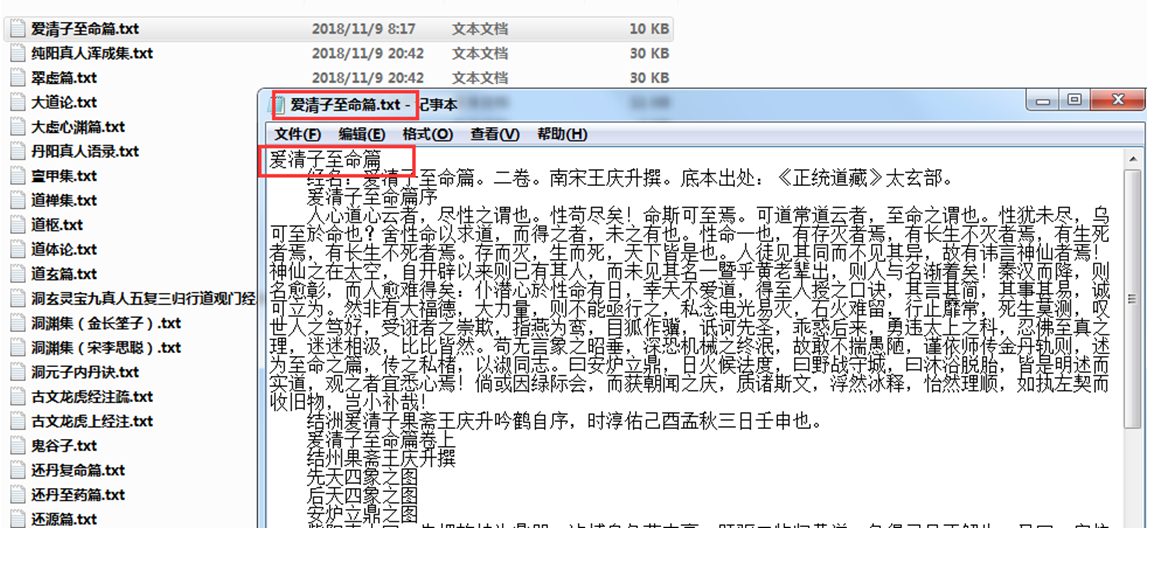
Jmeter实现了一个网站文章的爬虫,可以把所有文章分类保存到本地文件中,并以文章标题命名
它原理就是对网页提交一个请求,然后把返回的所有值提取出来,利用ForEach控制器去实现遍历。下面来介绍一下如何操作。
首先我们需要对网页提交一个请求。我们对一个站点发起一个请求,观察一下返回值可以发现中间有很多中文title,这些title都是href标签,他们作为超链接可以跳转到正文

我们用xpath提取器获取这些href的title,并且用-1提取全部

用foreach控制器遍历提取的title,并传参

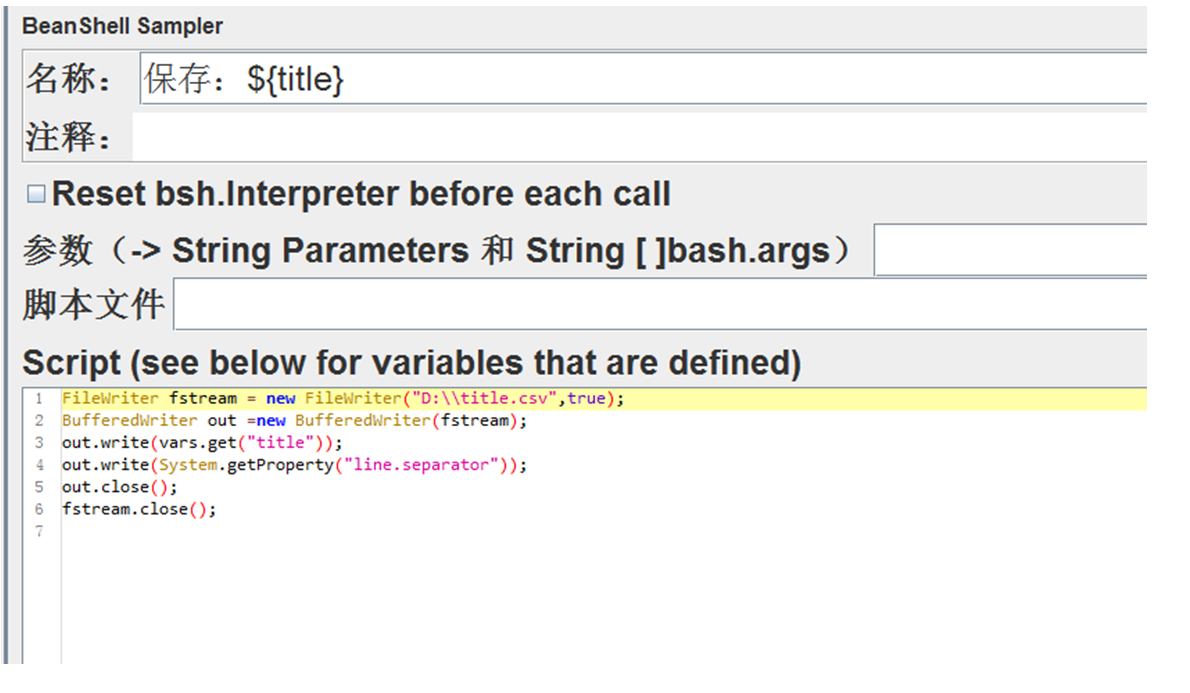
通过beanshell脚本将遍历提取的title保存到本地文件,文件保存为title.csv

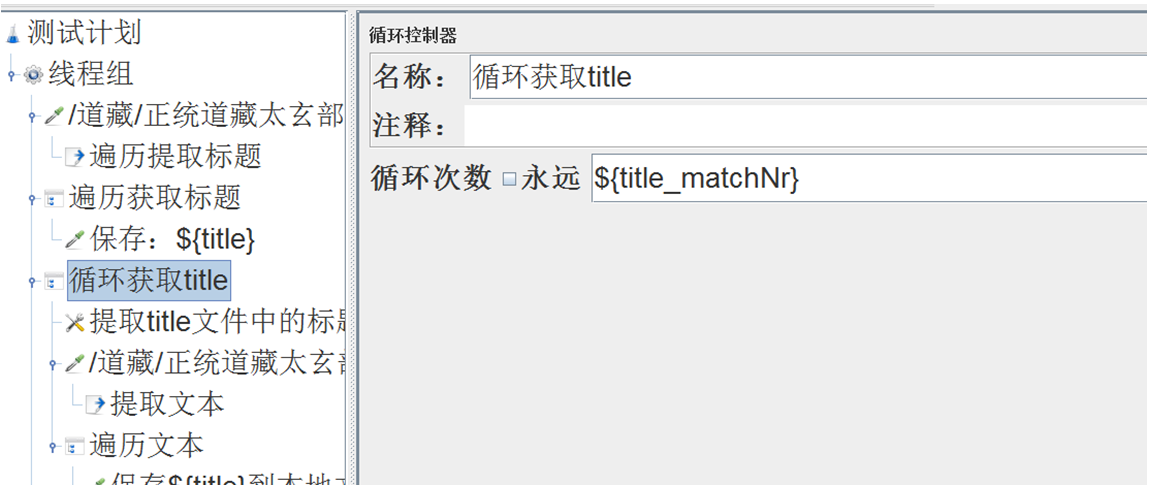
用matchNr函数获取返回的title总数,作为后续csv提取器的循环次数
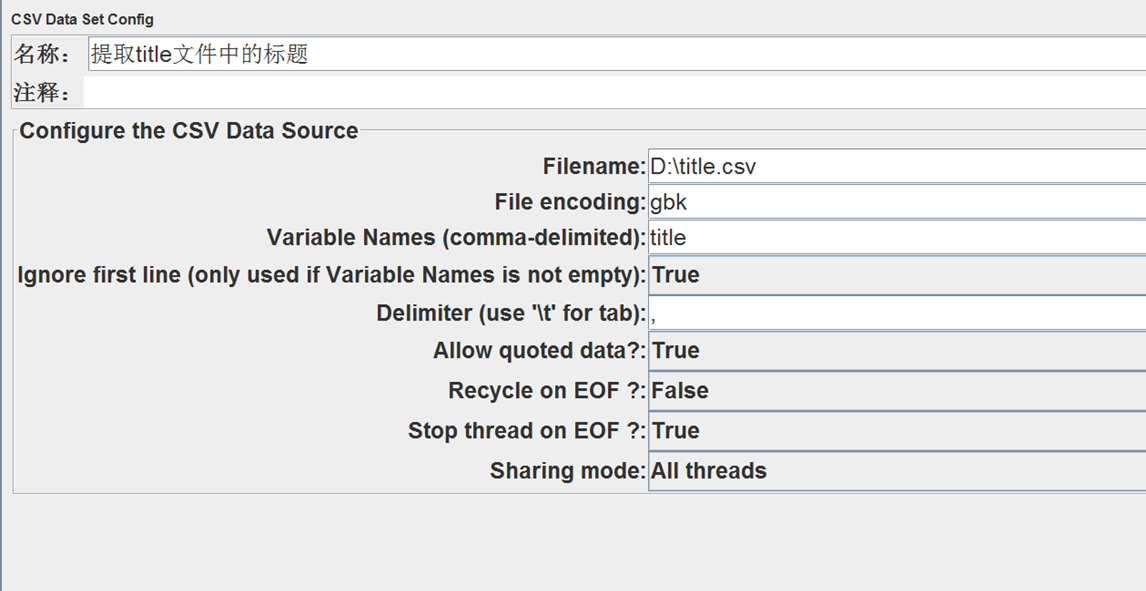
在循环控制器下,用csv提取器从之前保存到本地的title.csv中循环读取title,并作为参数传递到后续接口的url中
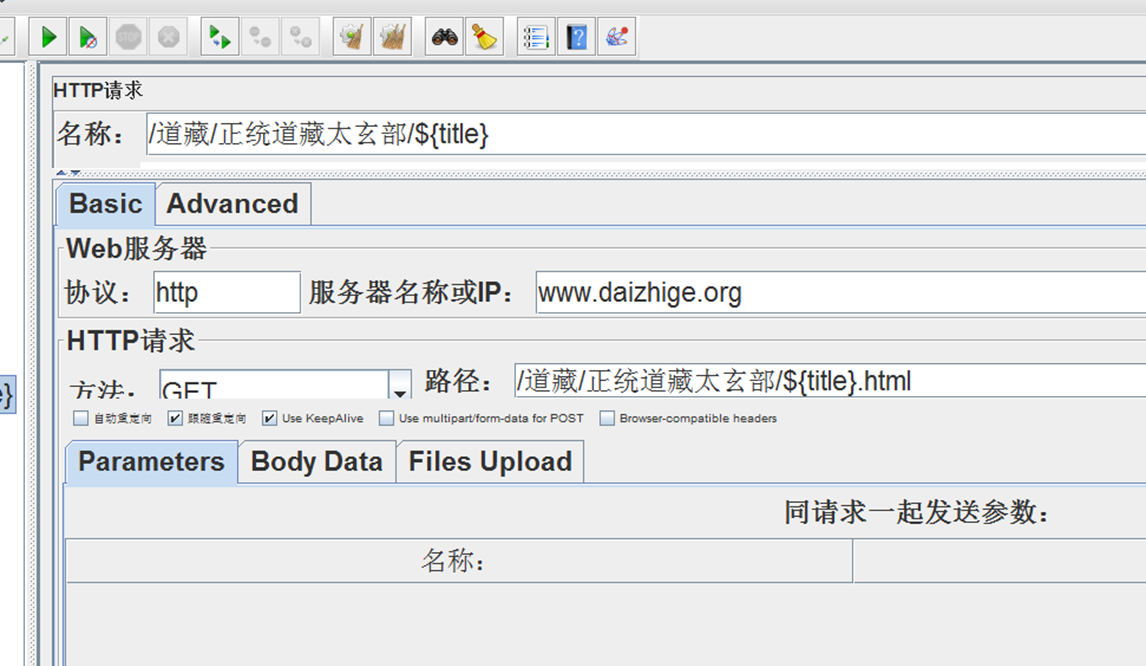
循环控制器下,通过csv传参,循环触发url
循环触发url之后,用xpath表达式从url中提取出文本,传递变量为text
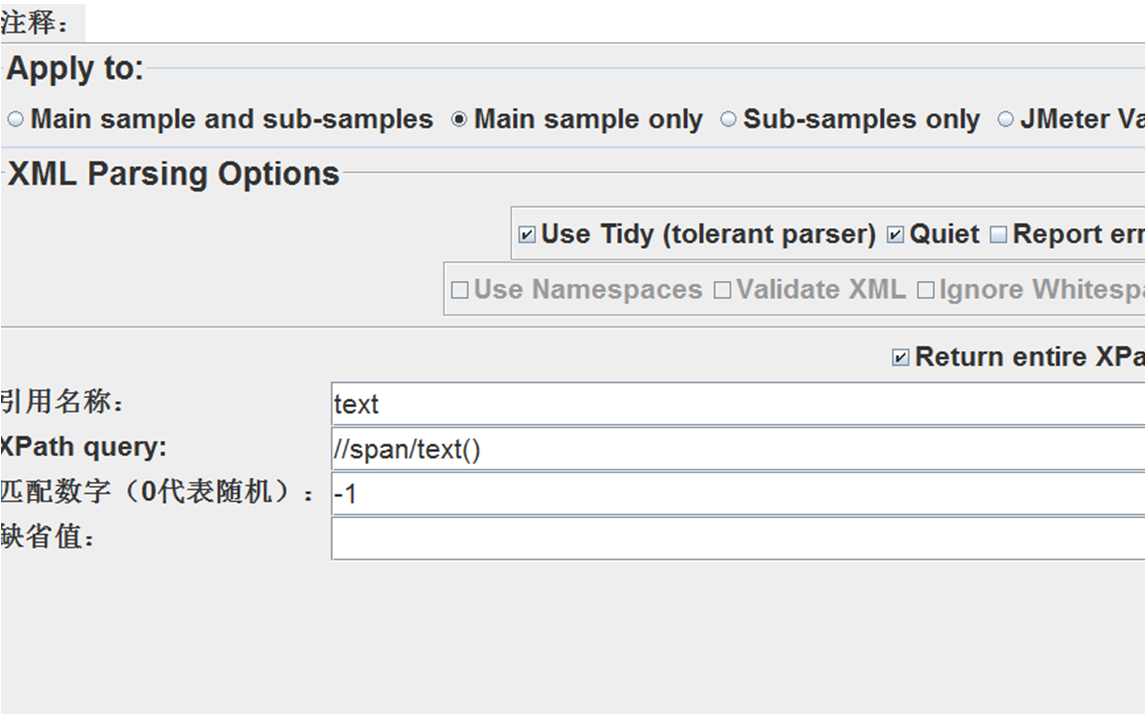
循环控制器下,通过foreach控制器遍历之前的提取的text,保存到本地文件。文件名用遍历获取的title依次命名创建
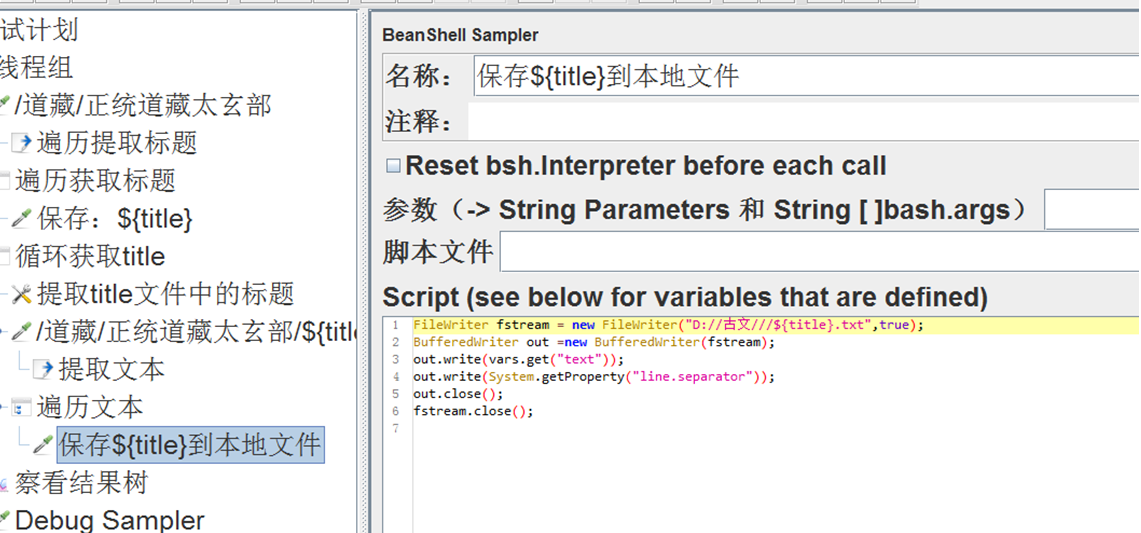
注:难点在于,需要按照超链接的标题创建本地文件,并把超链接之后的文本正确保存到文件之中

你还在为找不到可练习的接口而烦恼吗?现在加入龙渊阁,我们手把手教你搭建属于自己的接口测试环境!