一、list接口、concurrent下的CopyOnWriteList
1.ArrayList 基于数组实现,相当于一个动态数组,检索快,增删慢。
源码解析1:

1.可以看到ArrayList<E>是支持泛型的,所以ArrayList是可以构造成任何类型的动态数组。
2.继承了AbstractList<E>抽象类,抽象类实现了很多默认的方法,也有一些 抽象方法
3.实现类List、RandomAccess、Cloneable、Serializable四个接口;RandomAccess说明可以支持快速随机访问,Cloneable说明可以浅克隆,Serializable说 明支持序列化。
源码剖析2:
![]()
该数组是实际存放元素的数组,用了transient关键字,该关键字的功能是取消序列化。elementData为什么要用transient取消序列化呢?因为我们的elementData数组一般会有一些空的元素(数组里还没有填写数据的元素),如果这时候将elementData数组进行序列化,整个数组都会被序列化,连数组后面的空元素也会被序列化,这些是不应该被存储的,所以java的设计者就给ArrayList实现了一个writeObject方法,使用者可以显式的调用writeObject方法来将elementData数组序列化。
源码剖析3:
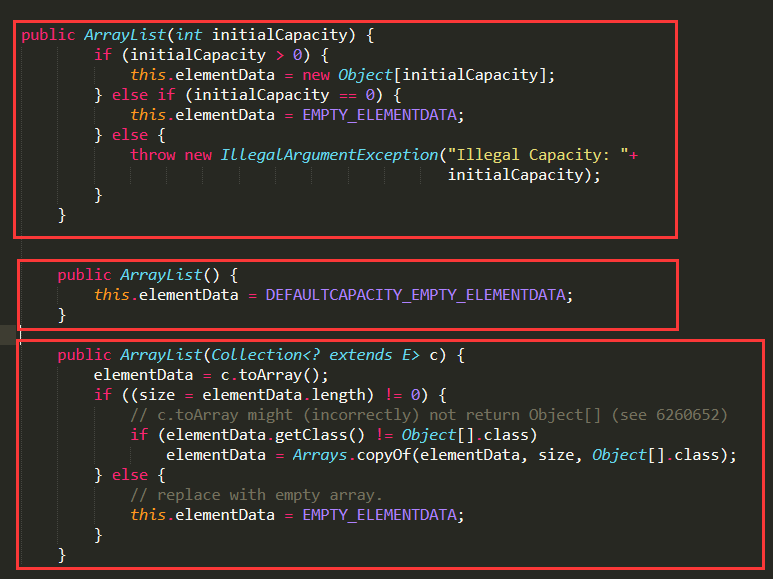
1.ArrayList实现了三个构造方法:第一个是由调用者传入指定list大小来创建elementData数组;第二个是创建一个默认大小为10的数组;第三个是传入一个集 合,将集合转成数组,再复制给elementData数组。
源码剖析4:

首先得到数组的旧容量,然后进行oldCapacity + (oldCapacity >> 1),将oldCapacity 右移一位,其效果相当于oldCapacity /2,我们知道位运算的速度远远快 于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量 当作数组的新容量,接着,再检查新容量是否超出了ArrayList所定义的最大容量,若超出了,则调用hugeCapacity()来比较minCapacity和MAX_ARRAY_SIZE,如 果minCapacity大于最大容量,则新容量则为ArrayList定义的最大容量,否则,新容量大小则为minCapacity。
1.grow是elementData的容量增长函数,oldCapacity>>1向右移一位,表示oldCapacity/2,因为位运算的速度远远大于整除运算,所以这里采用位运 算,oldCapacity+(oldCapacity>>1)则表示把容量扩增为原来的1.5倍,这是jdk1.7及更高版本的递增方式。jdk1.6及以下版本的递增方式是原来的1.5倍+1。 如下:

2.这里提以下ArrayList在JDK1.6和JDK1.7之间的区别:一是容量增长方式不同;而是JDK1.6没有对elementData做最大容量的限制,JDk1.8开始限制最大容 量为Integer.MAX_VALUE - 8。
2.LinkedList 基于双向链表的实现,检索慢,增删快
源码剖析1:

1.可见LinkedList没有实现RandomAccess接口,因为LinkedList是基于链表实现的,并不支持随机的快速检索。
源码剖析2:

1.LinkedList只提供两个构造函数,一个无参的构造函数,一个传入一个Collection集合的构造函数,并且LinkedList的头元素不存放数据。LinkedList允许元素 为空。
源码剖析3:关于LinkedList的get(int index)方法

————————————————————————

1.可见LinkedList的get(int index)方法调用了node方法进行查找,然而node方法不是一开始就从第一个元素进行遍历,而是进行了一个优化,先用index和size/2进行比较,如果index<size/2,则从第一个元素开始遍历到index;如果index>size/2,则从size-1开始往前遍历,一直遍历到index。
3.Vector vector也是基于数组实现的,不过vector是线程安全的
源码剖析1:

1.继承的父类和实现的接口和ArrayList一样,所以不再做过多解释。
源码剖析2:
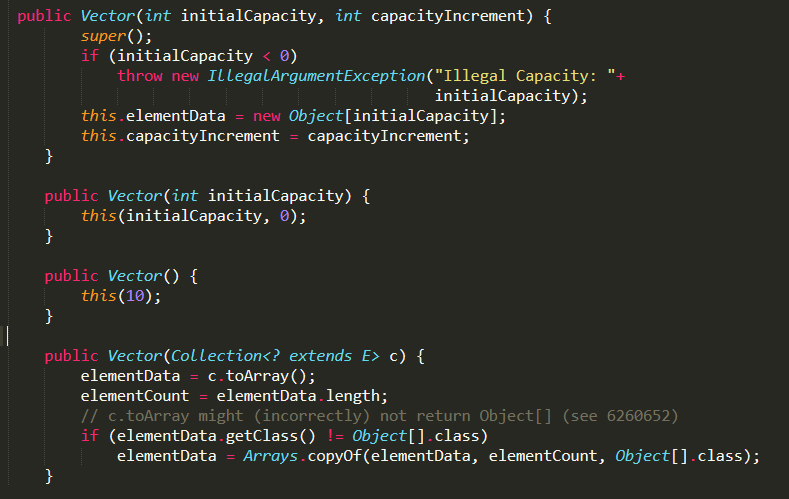
1.Vector实现了四个构造方法,比ArrayList多出的一个构造方法是传入初始容量大小initialCapacity,和增长容量大小capacityIncrement。
源码剖析3:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
1.由上面的grow()函数可以看出Vector的增长模式是:先判断增长容量capacityIncrement是否大于0,如果大于0则增长capacityIncrement大小,否则增长为原来的2倍。
4.CopyOnWriteList 在JDK1.5后出现的concurrent包下,支持多线程
CopyOnWriteList的实现原理:跟字面意思一样CopyOnWirte的意思就是在对列表进行写操作的时候,对列表进行复制。具体原理是:当需要向CopyOnWriteList添加元 素的时候,先对列表进行copy,得出一份副本,然后在副本上面进行添加元素,添加元素结束后再将原列表的引用指向副本列表。那么是否是当同时有多个线程再添加元素的时候是否会同时复制出多个副本呢?答案是:不会。因为,add()方法里是加了锁的,所以不可能出现同时复制出多个副本的情况;但是,CopyOnWriteList对读操作是没有添加锁的。下面是部分源码:


了解了CopyOnWriteList的锁机制后,便大致了解了CopyOnWriteList的性能了。CopyOnWriteList支持多线程,写效率较低,读效率较高。所以适用于读多写少的并发场景,例如黑名单、白名单、缓存这些写频率低,读频率高的并发场景。同时,可以轻易的知道CopyOnWriteList也存在两个问题,就是内存占用问题和数据一致性的问题。
内存占用问题:因为进行写操作时会复制多一个对象,内存里有两个对象占用内存。
数据一致性问题: 因为读操作的是否是对原列表进行读数据,而不是读取插入了新数据后的列表,所以读到的数据不存在一致性。
CopyOnWriteList & Collections.synchronizedList():
copyOnWriteList和Collections.synchronizedList()是实现支持多线程的列表的两种方式,这两种方式在读和写方面的性能有所差异。synchromizedList的同步方式是通过同步代码块来实现同步,所以在写操作方面synchronizedList的性能会好一点,因为copyOnWriteList虽然也是通过同步代码块,但是copyOnWriteList需要一个copy列表的过程;而在读操作上,copyOnWriteList的性能更高,因为copyOnWriteList在写操作上没有进行加锁。
补充:Vector和synchronizedList的区别:
1.Vector通过同步方法,synchronizedList通过同步代码块
2.synchronizedList可以指定锁定的对象
3.扩容方式不一样,Vector缺省值下扩大为原来2倍,synchronizedList和ArrayList的扩容方式一样
4.synchronizedList并没有对所有的代码块都进行了同步,例如listIterator需要手动加锁。
二、set接口(待续)
三、map接口(待续)
HashTable、HashMap、concurrentHashMap
1.HashTable和HashMap的增长区别:
HashTable增长模式:原来的两倍+1:

HashMap增长模式:原来的两倍
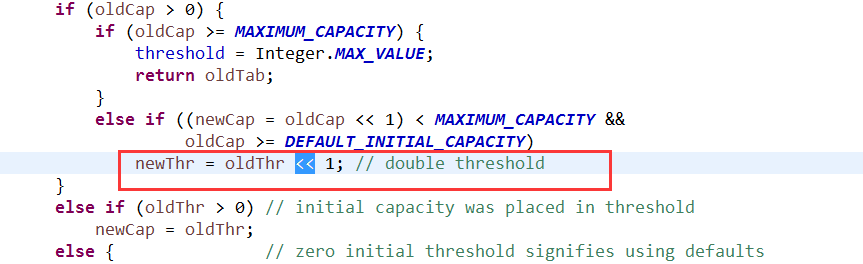
2.HashTable实现同步的方式:通过同步方法来实现同步,性能较低

3.HashMap在JDK1.7和JDK1.8之间的差别:
在JDK1.7中:HashMap通过Entry数组来存储数据,用key的hashCode来取模来决定key被放到数组的哪个位置,如果不同key的hashCode后取模的结果一样,则通过链表来解决冲突。
在JDK1.8中:HashMap通过Node数组来存储数据,用key的hashCode来取模来决定key被放到数组的哪个位置,如果不同key的hashCode后取模的结果一样,则不一定通过链表来解决冲突:如果同一个数组格子里的元素不超过8个,则采用链表的方式来解决冲突,如果超过8个,则利用treeifyBin()函数来把链表转成红黑树。
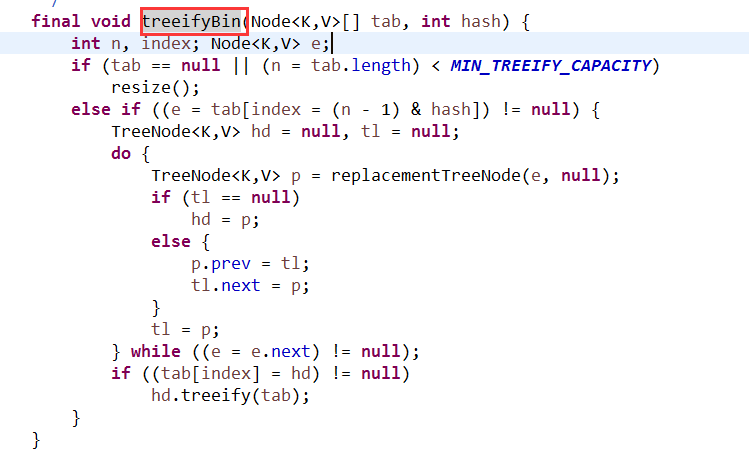
补充(摘抄):

HashTable不允许key和value为null,但是HashMap允许key和value为null(至多只能一个key为null)