一、Hive是什么,作用是什么?
可以这么简单得理解,Hive是一个工具。它得作用是查询hdfs文件系统上得海量数据,方式是通过HQL语句查询(类似sql)。
或许你又有疑问了,明明可以在java程序里直接访问HDFS的数据了啊,为什么还出来一个Hive工具,不是多此一举吗?这种想法的确是对的,而为什么还需要hive呢,
其实hive这个工具就是为了方便那些熟悉sql语句,但是java技能水平有限的小伙伴们。
二、Hive架构:
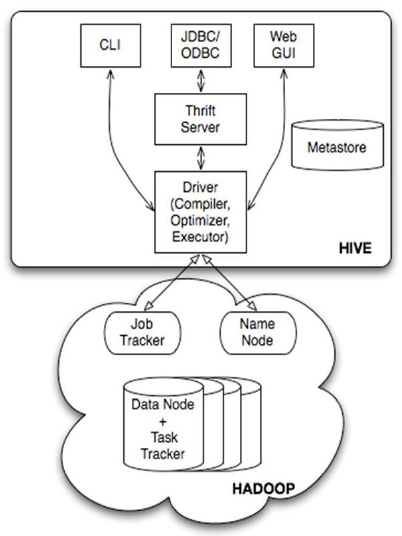
这里我们把Hive架构图从上往下分析:
1.最顶层——用户接口:
包括CLI(command line interface)命令行,Client 和 Web UI。CLI是开发过程中常用的接口。
2.Metadata:
hive 的元数据结构描述信息库,元数据默认是存储在数据库derby中,线上一般使用mysql。在hive的配置文件hive-site.xml中配置:
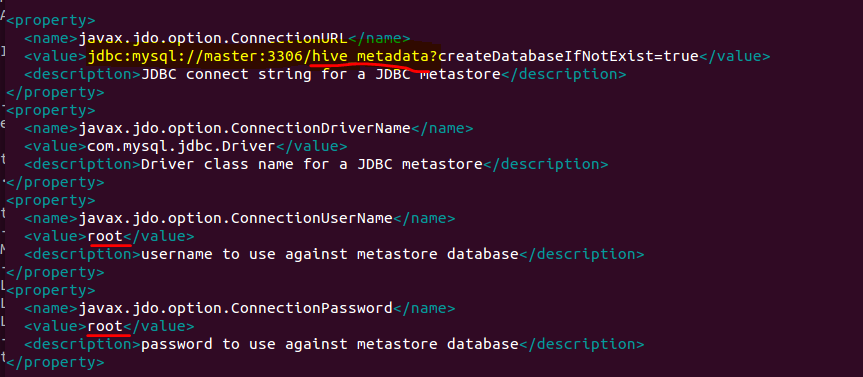
在配置文件中加入这一段时候,就会在途中路径中指定的mysql中新建hive_metadata这个数据库,hive_metahive就是拿来存储hive的元数据,并不会储存HDFS上的数据文件的内容,只会存储数据文件的相关信息。在查询中的主要功能就是结合元数据的信息,把HDFS映射成table提供给HQL来查询。
3.Driver: 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由 MapReduce调用执行。简单的来说:就是把HQL转成MapReduce的一个过程。
4.接下来就是HADOOP
把MapReduce任务放到HADOOP框架中执行,查询HADOOP中的HDFS文件系统中的海量数据。