搭建hadoop集群完整过程笔记
一、虚拟机和操作系统
环境:ubuntu14+hadoop2.6+jdk1.8
虚拟机:vmware12
二、安装步骤:
先在一台机器上配置好jdk和hadoop:
1.新建一个hadoop用户
用命令:adduser hadoop
2.为了让hadoop用户有sudo的权限:
用root用户打开sudors文件添加红色框里面的内容:
打开文件:
![]()
添加内容:
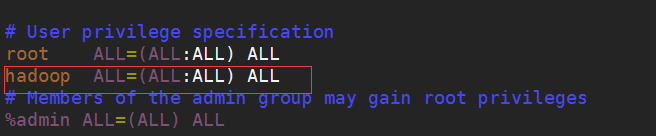
3.配置jdk,我把jdk的压缩包放在了hadoop的用户目录下,然后也解压在当前目录下

修改配置文件(配置环境变量):在下面这个位置添加红色框里面的内容,其中红色下划线上面的内容根据个人jdk的安装路径而修改
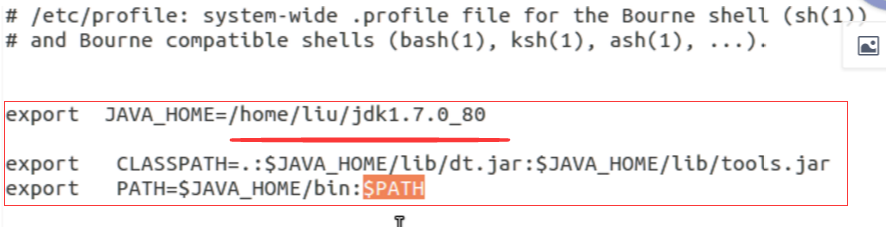
修改配置文件之后要让配置文件起效,输入以下命令:
![]()
输入命令:java -version,如果出现jdk的版本则表示安装成功,如下:

*****************到这里,成功配置了jdk,接下来是配置hadoop*********************
4.同样是把hadoop的压缩包放到hadoop的用户主目录下(/home/hadoop),然后解压在当前目录下:

5.修改配置文件(配置hadoop环境变量),在刚刚配置的jdk环境变量上添加内容:
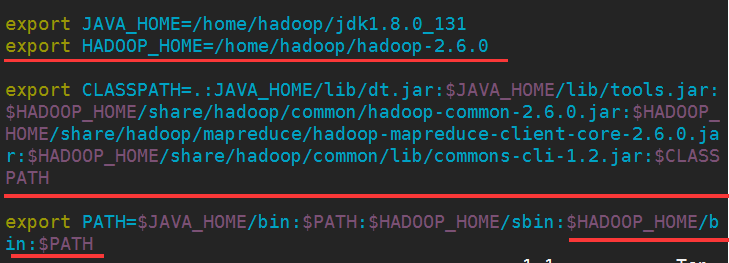
修改后,也要让配置文件重新起效
![]()
然后进入hadoop的安装目录的bin目录下

输入以下命令查看hadoop的版本,如果能看到hadoop的版本信息,则证明配置成功:

************************以上以及配置好了单机版本的hadoop环境***********************************
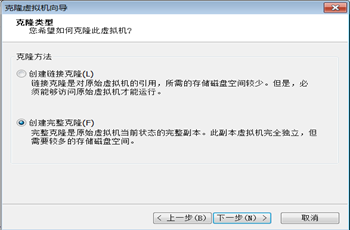
接下来克隆配置好的机器,克隆两台:打开vmvare: 虚拟机>管理>克隆。(建议新克隆出来的两台机器分别命令为slave1,slave2)
一直点击 下一步 完成克隆。其中克隆类型选择创建完整克隆。
1.分别修改各虚拟机的hostname,分别为master,slave1,slave2
![]()
2.修改三台虚拟机的hosts文件,这样接下来就不需要记住ip地址了,用主机名代替ip地址就可以了
(ip地址分别为三台机器的Ip地址,可以分别在三台机器上通过ifconfig命令查看)
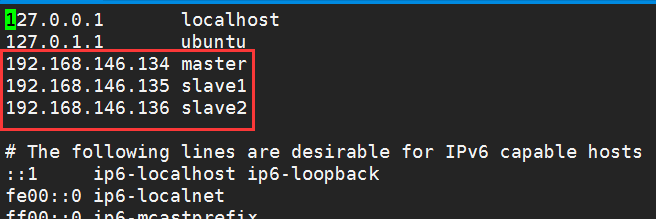
这一步完成后,最好重启一次系统,以便生效。然后可以用ping master(或slave1、slave2)试下,正常的话,应该能ping通。
注:hostname不要命名为“xxx.01,xxx.02”之类以“.数字”结尾,否则到最后hadoop的NameNode服务将启动失败。
3.设置静态ip
master主机设置静态ip,在slave上也要参考设置修改成具体的ip
执行命令
sudo gedit /etc/network/interfaces
打开文件修改成已下内容
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 192.168.140.128 //这里是本机器的Ip地址
netmask 255.255.255.0 //不用修改
network 192.168.140.0 //网段,根据Ip修改
boardcast 192.168.140.255 //根据Ip修改
gateway 192.168.140.2 //网关,把ip地址后面部门修改成2
4.配置ssh面密码登录
在ubuntu上在线安装
执行命令
sudo apt-get install ssh
**********************************************
配置ssh的实现思路:
在每台机子上都使用ssh-keygen生成public key,private key
所有机子的public key都拷到一台机子如master上
在master上生成一个授权key文件authorized_keys
最后把authorized_keys拷给所有集群中的机子,就能保证无密码登录
***************************************************
实现步骤:
1 .先在master上,在当前用户目录下生成公钥、私钥对
执行命令
$cd /home/hadoop
$ssh-keygen -t rsa -P ''
即:以rsa算法,生成公钥、私钥对,-P ''表示空密码。
该命令运行完后,会在个人主目录下生成.ssh目录,里面会有二个文件id_rsa(私钥) ,id_rsa.pub(公钥)
2 .导入公钥
执行命令
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
执行完以后,可以在本机上测试下,用ssh连接自己
执行命令
$ssh master
如果不幸还是提示要输入密码,说明还没起作用,还有一个关键的操作
查看权限,如果是属于其他用户的,需要修改该文件给其他用户权限
执行命令
chmod 644 .ssh/authorized_keys
修改文件权限,然后再测试下 ssh master,如果不需要输入密码,就连接成功,表示ok,一台机器已经搞定了。
如出现问题试解决
请先检查SSH服务是否启动,如果没启动,请启动!
如果没有.ssh目录则创建一个:
执行命令
$cd /home/hadoop
$mkdir .ssh
如无权限,使用命令修改要操作文件夹的owner为当前用户:
执行命令
sudo chown -R hadoop /home/hadoop
3 .在其它机器上生成公钥、密钥,并将公钥文件复制到master
以hadoop身份登录其它二台机器 slave1、slave2,执行 ssh-keygen -t rsa -P '' 生成公钥、密钥
然后用scp命令,把公钥文件发放给master(即:刚才已经搞定的那台机器)
执行命令
在slave1上:
scp .ssh/id_rsa.pub hadoop@master:/home/hadoop/id_rsa_1.pub
在slave2上:
scp .ssh/id_rsa.pub hadoop@master:/home/hadoop/id_rsa_2.pub
这二行执行完后,回到master中,查看下/home/hadoop目录,应该有二个新文件id_rsa_1.pub、id_rsa_2.pub,
然后在master上,导入这二个公钥
执行命令
$cat id_rsa_1.pub >> .ssh/authorized_keys
$cat id_rsa_2.pub >> .ssh/authorized_keys
这样,master这台机器上,就有所有3台机器的公钥了。
4 .将master上的“最全”公钥,复制到其它机器
继续保持在master上
执行命令
$scp .ssh/authorized_keys hadoop@slave1:/home/hadoop/.ssh/authorized_keys
$scp .ssh/authorized_keys hadoop@slave2:/home/hadoop/.ssh/authorized_keys
修改其它机器上authorized_keys文件的权限
slave1以及slave2机器上,均执行命令
chmod 600 .ssh/authorized_keys
5. 验证
在每个虚拟机上,均用命令 ssh+其它机器的hostname 来验证,如果能正常无密码连接成功,表示ok
如在slave1
执行命令
ssh slave1
ssh master
ssh slave2
分别执行以上命令要保证所有命令都能无密码登录成功。
5.修改hadoop配置文件
先配置hdfs,所以先修改4个配置文件:core-site.xml , hdfs-site.xml , hadoop-env.sh , slaves
到hadoop的该目录下:
![]()
1).修改core-site.xml
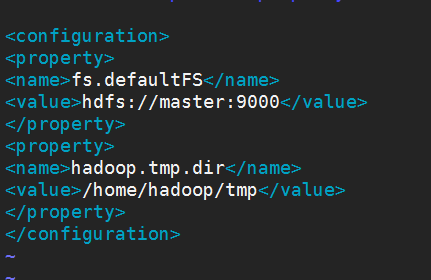
上面配置的路径/home/hadoop/tmp,如果不存在tmp文件夹,则需要自己新建tmp文件夹
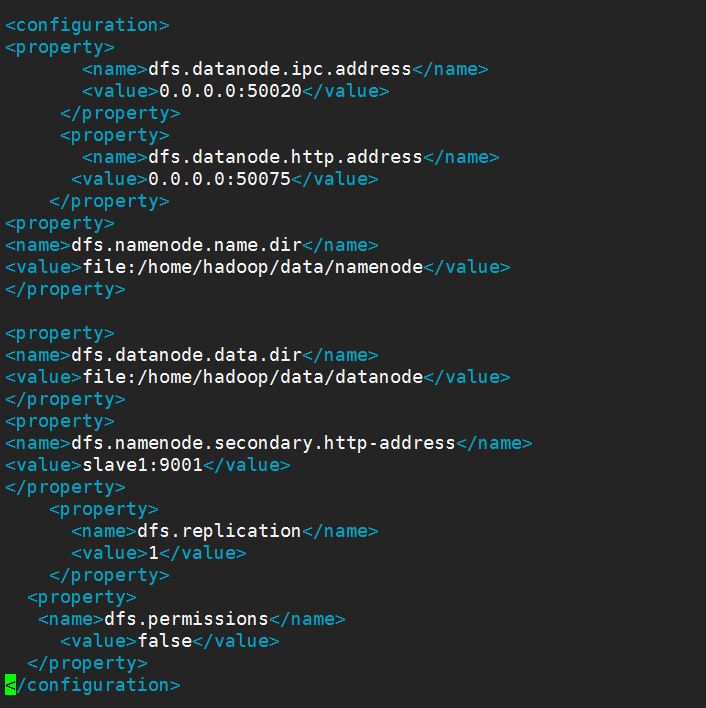
2.修改hdfs-site.xml
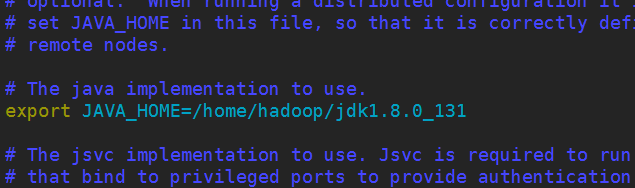
3.修改hadoop-env.sh,(有教程上面还需要配置HADOOP_HOME的环境变量,本人这里没有配置但是没问题,因为在前面已经配置过了)
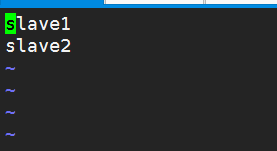
4.修改slaves,删掉原来的内容,添加其他两个节点的主机名
5.分发到集群的其它机器
把hadoop-2.6.0文件夹连同修改后的配置文件,通过scp拷贝到其它2台机器上。
执行命令
$scp -r hadoop-2.6.0/ hadoop@slave1: hadoop-2.6.0
修改这四个文件之后,hdfs服务就配置成功了。通过运行start-dfs.sh启动hdfs服务,检查是否配置成功。

启动完毕之后,输入jps,如果显示NameNode和Jps则表示配置成功。
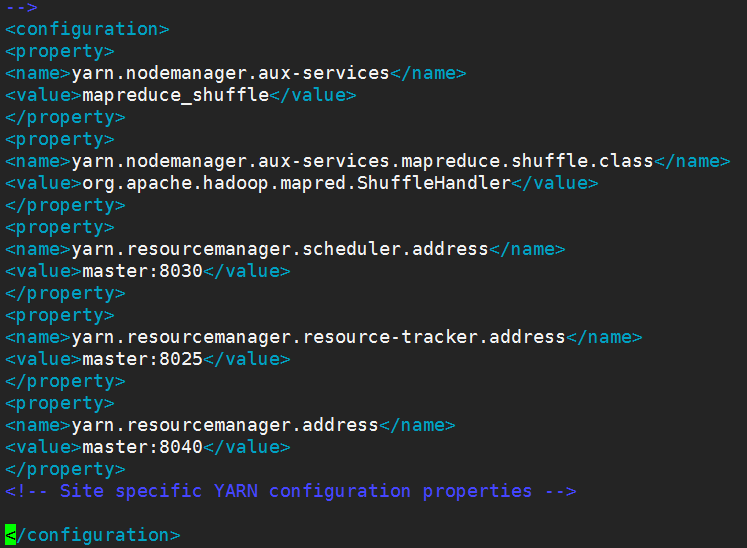
6.接下来配置mapreduce,要修改yarn-site.xml , mapred-site.xml文件
修改yarn-site.xml文件
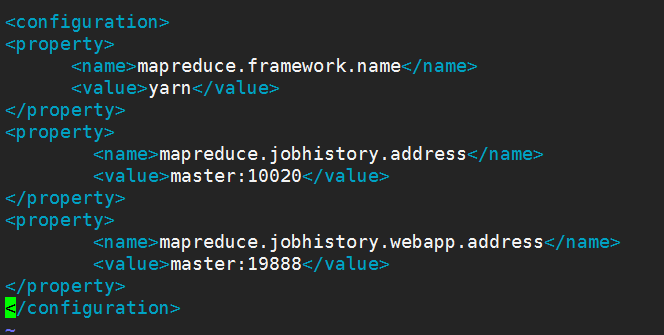
7.修改mapred-site.xml
8.分发到集群的其它机器
把hadoop-2.6.0文件夹连同修改后的配置文件,通过scp拷贝到其它2台机器上。
执行命令
$scp -r hadoop-2.6.0/ hadoop@slave1: hadoop-2.6.0
运行start-yarn.sh脚本,启动mapreduce服务。显示红色框里面的三个内容则表示配置成功。
