来自对此文章的编辑。
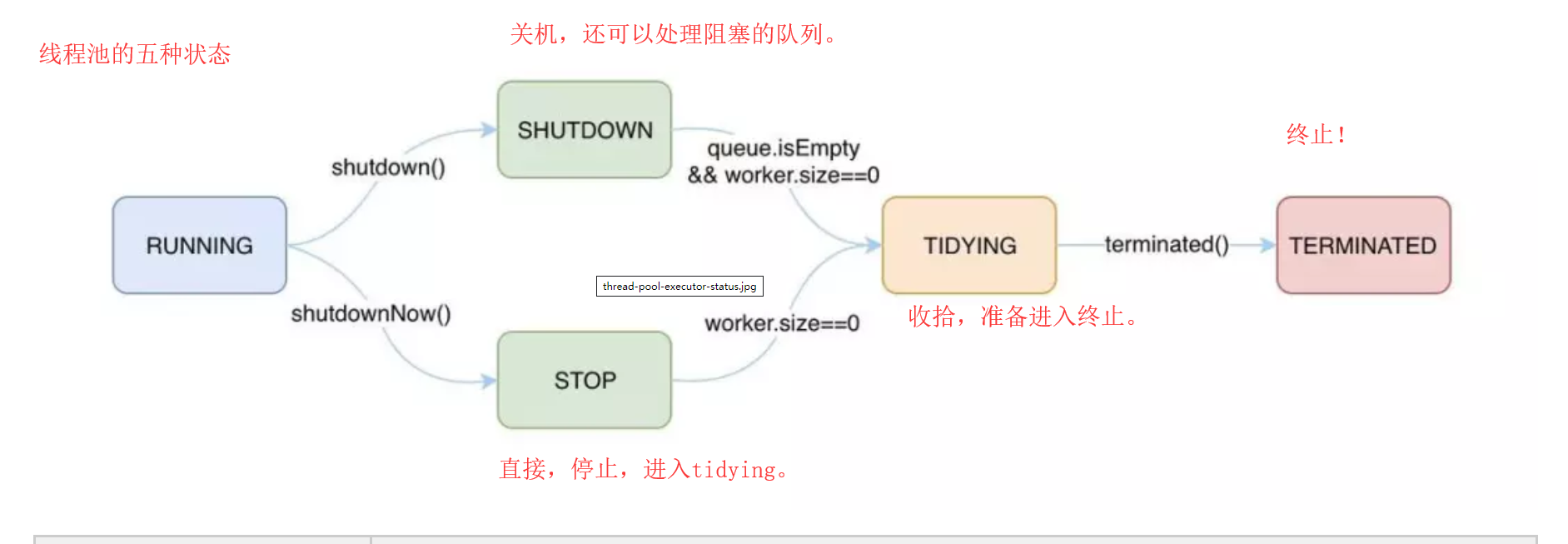
一、线程池的五种转态? 1.running /* 1.可以接受新的任务,亦可以处理阻塞队列中的任务。 2.执行 shutdown 可以进入shutdown状态。 3.执行 shutdownNow 方法可以进入 stop 转态 */ 2.shutdown 关机 /* 1.准备关机转态,不再接受新的任务,可以继续处理阻塞队列中的任务 2.当阻塞队列中的任务为空时,并且工作线程数为0,进入tidying状态 */ 3.stop /* 1.整理状态,不再接受新的任务,也不处理阻塞队列中的任务,并且会尝试结束执行中的任务。 2.当工作线程数为0时,进入tidying状态。 */ 4.TIDYING 收拾,整理。 /* 1.整理状态,此时的任务都已经执行完毕,并且也没有工作线程执行terminated方法后进入 terminated 转态。 */ 5.TERMINATED 终止的 /* 1.终止状态 此时线程池完全终止了,并且完成的所有资源的释放。 */
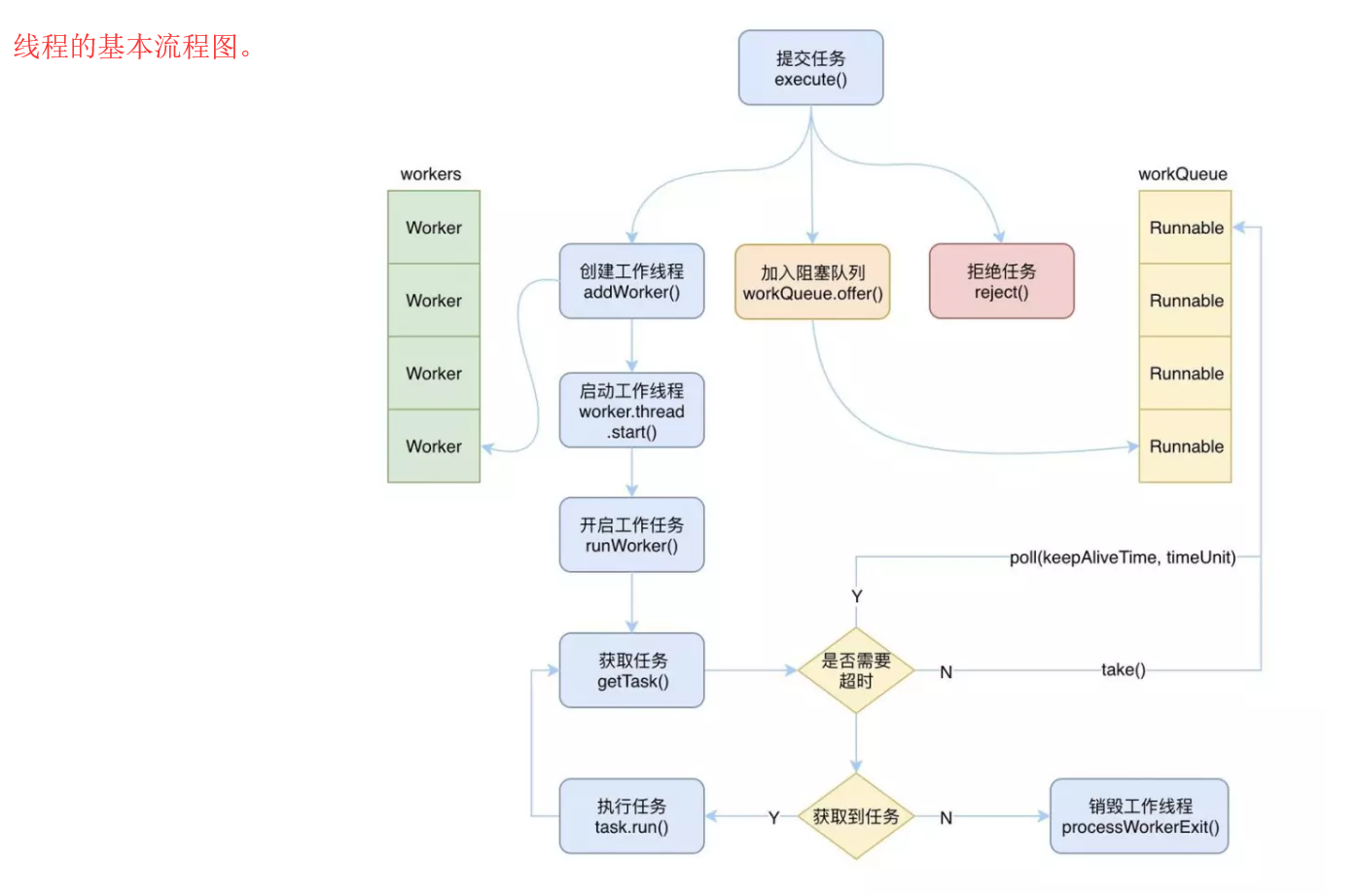
二、相关属性? // 一个线程池的核心参数有很多,每一个参数都有特殊的作用,将其聚合在一起,将完成整个线程池的完整工作。 1.线程状态和工作线程数量? /** 线程池需要执行具体的任务,在其内部封装了一个内部类,worker是工作线程, 每个worker 中都维持着一个thread。 ThreadPoolExecutor 中只用了一个 AtomicInteger 型的变量就保存了这两个属性的值,那就是 ctl。 ctl 的高3位用来表示线程池的状态(runState),低29位用来表示工作线程的个数(workerCnt), 至少需要3位才能表示得了5种状态。 */ 2.核心线程数和最大线程数? /** corePooLSize : 表示线程池中的核心线程的数量, 也可叫做闲置的线程数量 maxinmumPooLSize 真正工作的线程的数量,是随着任务的变化而变化的 */ 3.创建线程的工厂 这个任务就交给了线程工厂 ThreadFactory 来完成。 4.缓存任务的阻塞队列 /*** 当工作线程数达到 corePoolSize 了,这时又接收到新任务时,会将任务存放在一个阻塞队列中等待核心线程去执行。 为什么不直接创建更多的线程来执行新任务呢,原因是核心线程中很可能已经有线程执行完自己的任务了, 或者有其他线程马上就能处理完当前的任务,并且接下来就能投入到新的任务中去, 所以阻塞队列是一种缓冲的机制,给核心线程一个机会让他们充分发挥自己的能力。 另外一个值得考虑的原因是,创建线程毕竟是比较昂贵的,不可能一有任务要执行就去创建一个新的线程。 */ 5.非核心线程存活时间? /** 阻塞队列两种情况: 一种是有界的队列, 如果是有界队列,那么当阻塞队列中装满了等待执行的任务, 这时再有新任务提交时,线程池就需要创建新的“临时”线程来处理, 相当于增派人手来处理任务。 非核心线程的存活时间? 但是创建的“临时”线程是有存活时间的,不可能让他们一直都存活着, 当阻塞队列中的任务被执行完毕,并且又没有那么多新任务被提交时, “临时”线程就需要被回收销毁,在被回收销毁之前等待的这段时间, 就是非核心线程的存活时间,也就是 keepAliveTime 属性。 非核心线程? 其实核心线程跟创建的先后没有关系,而是跟工作线程的个数有关, 如果当前工作线程的个数大于核心线程数,那么所有的线程都可能是“非核心线程”, 都有被回收的可能。 闲置线程? 一个线程执行完了一个任务后,会去阻塞队列里面取新的任务, 在取到任务之前它就是一个闲置的线程。 一种是无界的队列。 核心线程忙不过来,所有新提交的任务都会被存放在该无界队列中,此时最大线程数 无意义,因为阻塞队列不会存在被装满的情况。 取任务的方法有两种? 一种是通过 take() 方法一直阻塞直到取出任务, 另一种是通过 poll(keepAliveTime,timeUnit) 方法在一定时间内取出任务或者超时,如果超时这个线程就会被回收,请注意核心线程一般不会被回收。 怎么保证核心线程不会被回收呢? 跟工作线程的个数有关,每一个线程在取任务的时候,线程池会比较当前的工作线程个数与核心线程数: 1.如果工作线程数小于当前的核心线程数, 则使用第一种方法取任务,也就是没有超时回收,这时所有的工作线程都是“核心线程”,他们不会被回收; 2.如果大于核心线程数,则使用第二种方法取任务, 一旦超时就回收,所以并没有绝对的核心线程,只要这个线程没有在存活时间内取到任务去执行就会被回收。 线程池需要处理的任务少时? 设置了允许核心线程超时被回收 就没有核心线程这种说法了 所有的线程都会通过 poll(keepAliveTime, timeUnit) 来获取任务, 一旦超时获取不到任务,就会被回收,一般很少会这样来使用,除非该线程池需要处理的任务非常少,并且频率也不高, 不需要将核心线程一直维持着。 拒绝策略? 如果是有界的阻塞队列,那就存在队列满的情况,也存在工作线程的数据已经达到最大线程数的时候。 如果这时候再有新的任务提交时,显然线程池已经心有余而力不足了,因为既没有空余的队列空间来存放该任务,也无法创建新的线程来执行该任务了,所以这时我们就需要有一种拒绝策略,即 handler。 直接丢弃该任务 使用调用者线程执行该任务 丢弃任务队列中的最老的一个任务,然后提交该任务 */ 线程的工作流程? //1.提交任务 //2.创建工作线程 创建工作线程需要做一系列的判断,需要确保当前线程池可以创建新的线程之后,才能创建。 首先,当线程池的状态是 SHUTDOWN 或者 STOP 时,则不能创建新的线程。 另外,当线程工厂创建线程失败时,也不能创建新的线程。 还有就是当前工作线程的数量与核心线程数、最大线程数进行比较,如果前者大于后者的话,也不允许创建。 除此之外,会尝试通过 CAS 来自增工作线程的个数,如果自增成功了,则会创建新的工作线程,即 Worker 对象。 然后加锁进行二次验证是否能够创建工作线程,最后如果创建成功,则会启动该工作线程。 //3.启动工作线程 Worker 对象中关联着一个 Thread,所以要启动工作线程的话,只要通过 worker.thread.start() 来启动该线程即可。 启动完了之后,就会执行 Worker 对象的 run 方法,因为 Worker 实现了 Runnable 接口,所以本质上 Worker 也是一个线程。 通过线程 start 开启之后就会调用到 Runnable 的 run 方法,在 worker 对象的 run 方法中, 调用了 runWorker(this) 方法,也就是把当前对象传递给了 runWorker 方法,让他来执行。 //4.获取任务并执行 在 runWorker 方法被调用之后,就是执行具体的任务了, 首先需要拿到一个可以执行的任务,而 Worker 对象中默认绑定了一个任务,如果该任务不为空的话,那么就是直接执行。 执行完了之后,就会去阻塞队列中获取任务来执行,而获取任务的过程,需要考虑当前工作线程的个数。 /* 如果工作线程数大于核心线程数,那么就需要通过 poll 来获取,因为这时需要对闲置的线程进行回收; 如果工作线程数小于等于核心线程数,那么就可以通过 take 来获取了,因此这时所有的线程都是核心线程,不需要进行回收, 前提是没有设置 allowCoreThreadTimeOut */