数据类型的补充
数据类型的转换
str ---> list
split
list ---> str
join
tuple ---> list
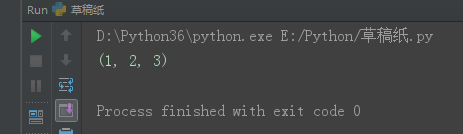
tu1 = (1, 2, 3) l1 = list(tu1) print(l1)

list ---> tuple
tu1 = (1, 2, 3) l1 = list(tu1) tu2 = tuple(l1) print(tu2)
dic ---> list
list(dic) 列表中只有key。
dic = {'k1': 'v1', 'k2': 'v2','k3': 'v3',}
l1 = list(dic)
print(l1)
print(list(dic.keys()))
print(list(dic.values()))
print(list(dic.items()))

0, '',[], {},() ---> bool都是False
print(bool(0))
print(bool(''))
print(bool(()))
print(bool([]))
print(bool({}))

print(bool([0, 0, 0]))

set 集合
set1 = {1, 2, 3, 'abc', (1, 2, 3), True, }
print(set1)

去重
集合去重
set2 = {11, 11, 11, 22}
print(set2)

列表的去重
l1 = [11, 11, 22, 22, 33, 33, 33, 44] l2 = list(set(l1)) l2.sort() print(l2)

添加
__.add('A') A为添加的内容,随机添加。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.add('太白')
print(set1)

__.update('A') A为添加的可迭代内容,将A拆分为最小单元然后迭代添加。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.update('abc')
print(set1)
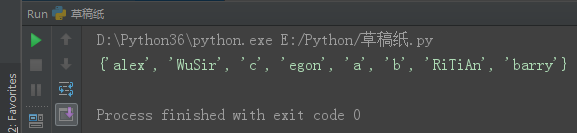
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.update([111, 2222, 333])
print(set1)

删
__.remove('A') 按元素删除。A为需要删除的内容。
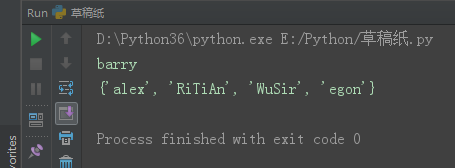
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.remove('RiTiAn')
print(set1)

__.pop() 随机删除,有返回值。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
print(set1.pop())
print(set1)
__.clear() 清空集合。 空集合为set()。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.clear()
print(set1)

del __ 删除集合。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
del set1
print(set1)
查
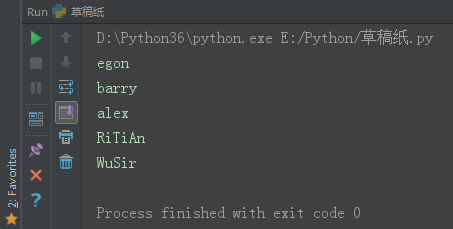
for循环。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
for i in set1:
print(i)
交集
交集:__ & __ 或者 __.intersection(__)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1 & set2
print(set3)

set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1.intersection(set2)
print(set3)

并集
并集:__ | __ 或者 __.union(__)
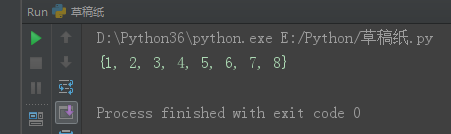
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1 | set2
print(set3)
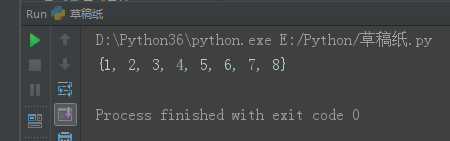
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1.union(set2)
print(set3)
差集
差集:__ - __ 或者 __.difference(__)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1 - set2
print(set3) # set1独有的
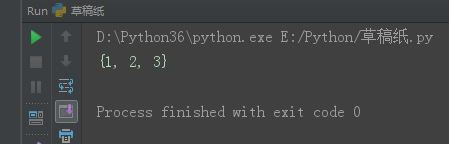
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1.difference(set2) # set1独有的
print(set3)

反交集
反交集:__ ^ __ 或者 __.symmetric_difference(__)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1 ^ set2
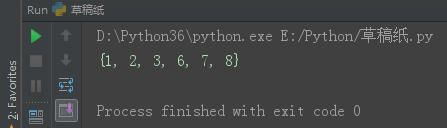
print(set3)
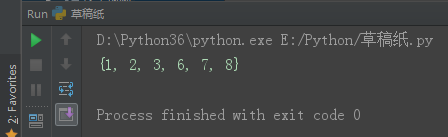
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1.symmetric_difference(set2)
print(set3)
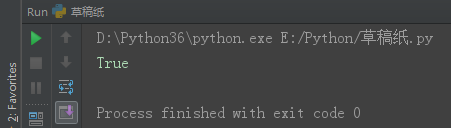
子集
子集:__ < __ 或者 __.issubset(__)
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set1 < set2) # True set1 是set2 的子集
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set1.issubset(set2)) # True set1是set2的子集

超集
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set2 > set1) # set2 是 set1 的超集
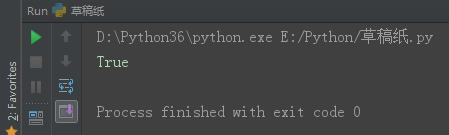
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set2.issuperset(set1)) # set2 是 set1 的超集
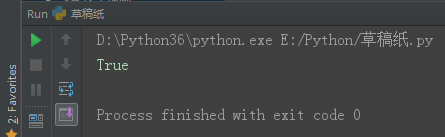
frozenset() frozenset是冻结的集合,它是不可变的,存在哈希值,好处是它可以作为字典的key,也可以作为其它集合的元素。缺点是一旦创建便不能更改,没有add,remove方法。
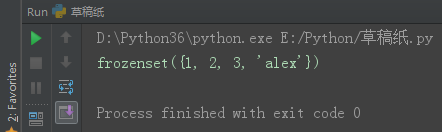
set1 = frozenset({1, 2, 3, 'alex'})
print(set1)
深浅copy
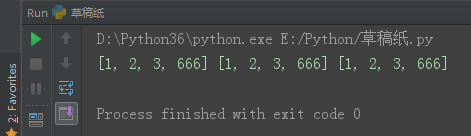
对于赋值运算来说,指向的都是同一个内存地址,一变都变。
l1 = [1, 2, 3] l2 = l1 l3 = l2 l3.append(666) print(l1, l2, l3)
浅copy
copy.() 浅copy
l1 = [11, 22, 33] l2 = l1.copy() l1.append(666) print(l1, id(l1)) print(l2, id(l2))
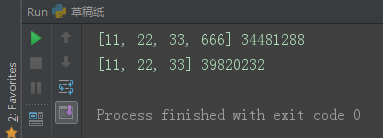
当列表内层列表增加元素时,浅copy跟随变化。内层的列表同样是同一个地址。
对于浅copy来说,第一层创建的是新的内存地址,从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
l1 = [11, 22, ['barry', [55, 66]], [11, 22]]
l2 = l1.copy()
l1[2].append('alex')
print(l1, id(l1))
print(l2, id(l2))
print(l1, id(l1[-1]))
print(l2, id(l2[-1]))

深copy
import copy
import copy l1 = [11, 22, 33] l2 = copy.deepcopy(l1) l1.append(666) print(l1, id(l1)) print(l2, id(l2))
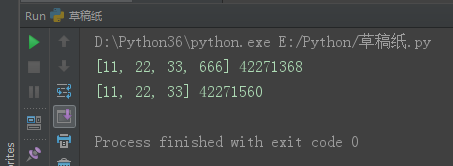
import copy
l1 = [11, 22, ['barry']]
l2 = copy.deepcopy(l1)
l1[2].append('alex')
print(l1, id(l1[-1]))
print(l2, id(l2[-1]))

深copy 完全独立。
l1 = [1, 2, 3] l2 = [1, 2, 3] l1.append(666) print(l1, id(l1)) print(l2, id(l2))
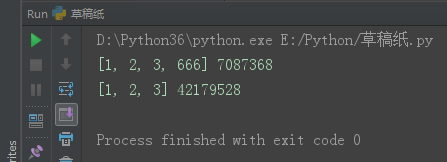
对于切片来说,这是浅copy。
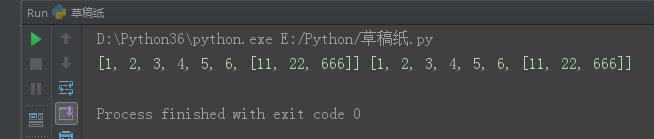
l1 = [1, 2, 3, 4, 5, 6, [11, 22]] l2 = l1[:] l1.append(666) print(l1, l2)
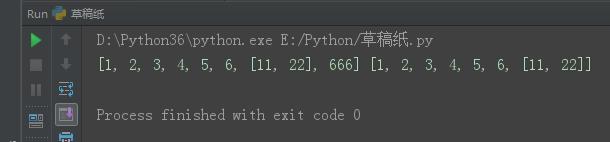
l1 = [1, 2, 3, 4, 5, 6, [11, 22]] l2 = l1[:] l1[-1].append(666) print(l1, l2)