查天气(1)
http://wthrcdn.etouch.cn/weather_mini?citykey=101280804
http://wthrcdn.etouch.cn/WeatherApi?citykey=101280804
http://bbs.crossincode.com/forum.php?mod=viewthread&tid=8&extra=page%3D4
http://bbs.crossincode.com/forum.php?mod=viewthread&tid=9&extra=page%3D4
查天气(2)
# -*- coding: utf-8 -*- import urllib2 web = urllib2.urlopen('http://www.baidu.com') content = web.read() print content
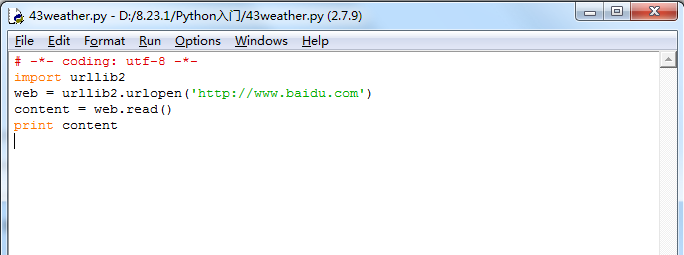
# -*- coding: UTF-8 -*- import urllib2 import json from city import city cityname = raw_input('你想查哪个城市的天气? ') citycode = city.get(cityname) if citycode: url = ('http://www.weather.com.cn/data/cityinfo/%s.html' % citycode) content = urllib2.urlopen(url).read() print content
http://www.weather.com.cn/data/cityinfo/101280800.html

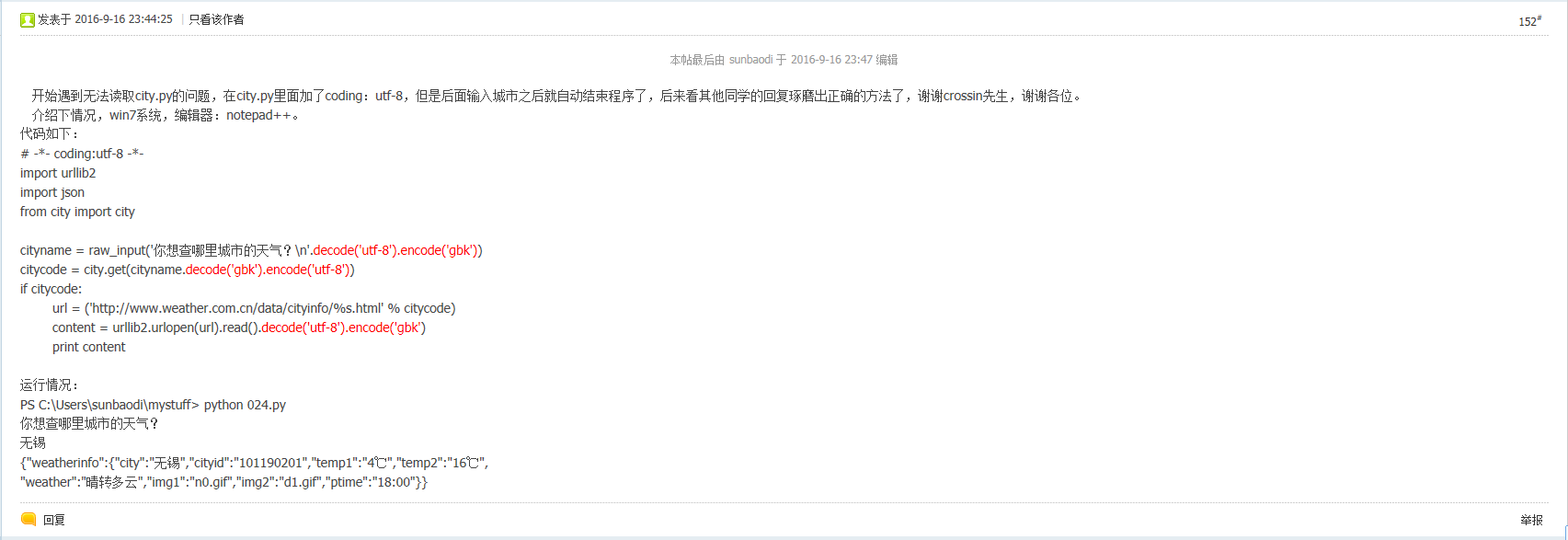
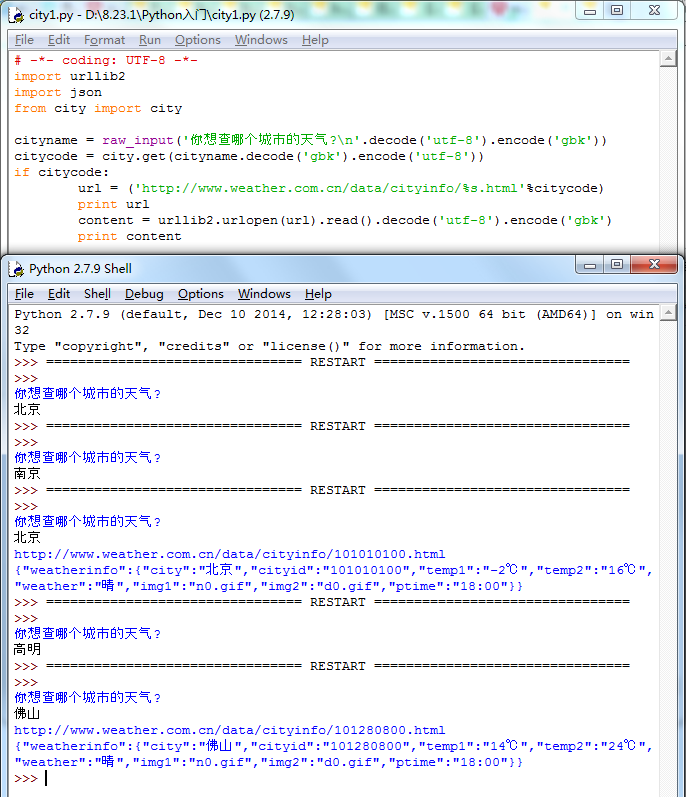
# -*- coding: UTF-8 -*- import urllib2 import json from city import city cityname = raw_input('你想查哪个城市的天气? '.decode('utf-8').encode('gbk')) citycode = city.get(cityname.decode('gbk').encode('utf-8')) if citycode: url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode) print url content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk') print content
查天气(3)
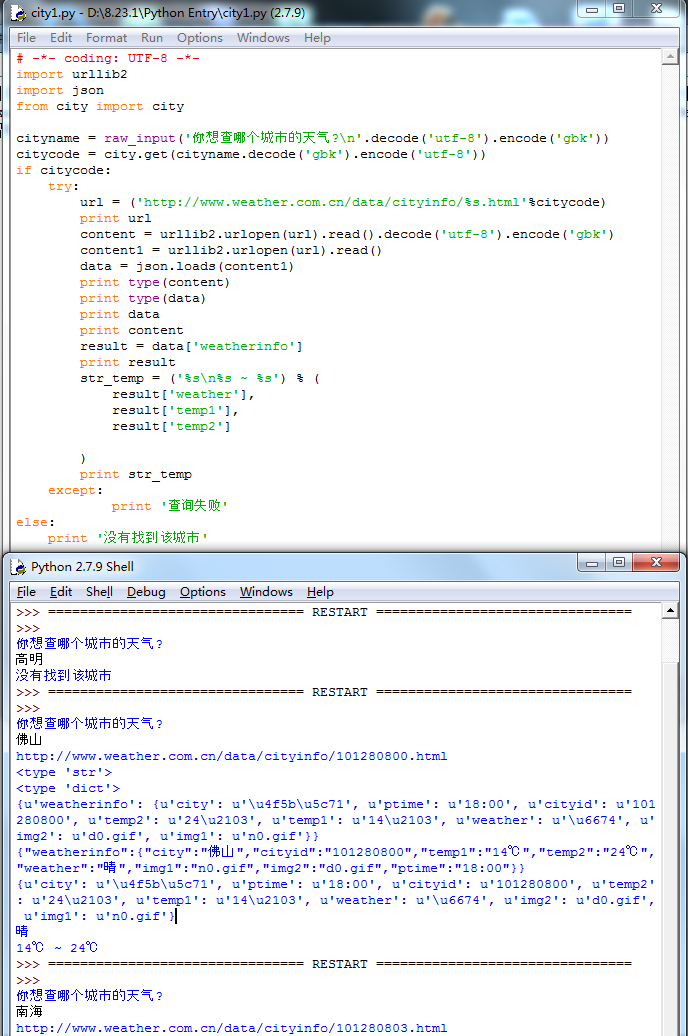
看一下我们已经拿到的json格式的天气数据:
{"weatherinfo":{"city":"佛山","cityid":"101280800","temp1":"14℃","temp2":"24℃","weather":"晴","img1":"n0.gif","img2":"d0.gif","ptime":"18:00"}}
{ "weatherinfo":{ "city":"佛山", "cityid":"101280800", "temp1":"14℃", "temp2":"24℃", "weather":"晴", "img1":"n0.gif", "img2":"d0.gif", "ptime":"18:00"} }
直接在命令行中看到的应该是没有换行和空格的一长串字符,这里我把格式整理了一下。可以看出,它像是一个字典的结构,但是有两层。最外层只有一个key--“weatherinfo”,它的value是另一个字典,里面包含了好几项天气信息,现在我们最关心的就是其中的temp1,temp2和weather。
虽然看上去像字典,但它对于程序来说,仍然是一个字符串,只不过是一个满足json格式的字符串。我们用python中提供的另一个模块json提供的loads方法,把它转成一个真正的字典。
import json data = json.loads(content)
这时候的data已经是一个字典,尽管在控制台中输出它,看上去和content没什么区别,只是编码上有些不同:
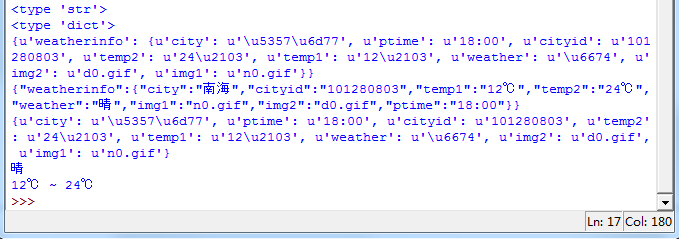
{u'weatherinfo': {u'city': u'u4f5bu5c71', u'ptime': u'18:00', u'cityid': u'101280800', u'temp2': u'24u2103', u'temp1': u'14u2103', u'weather': u'u6674', u'img2': u'd0.gif', u'img1': u'n0.gif'}}
但如果你用type方法看一下它们的类型:
print type(content) print type(data)
就知道区别在哪里了。
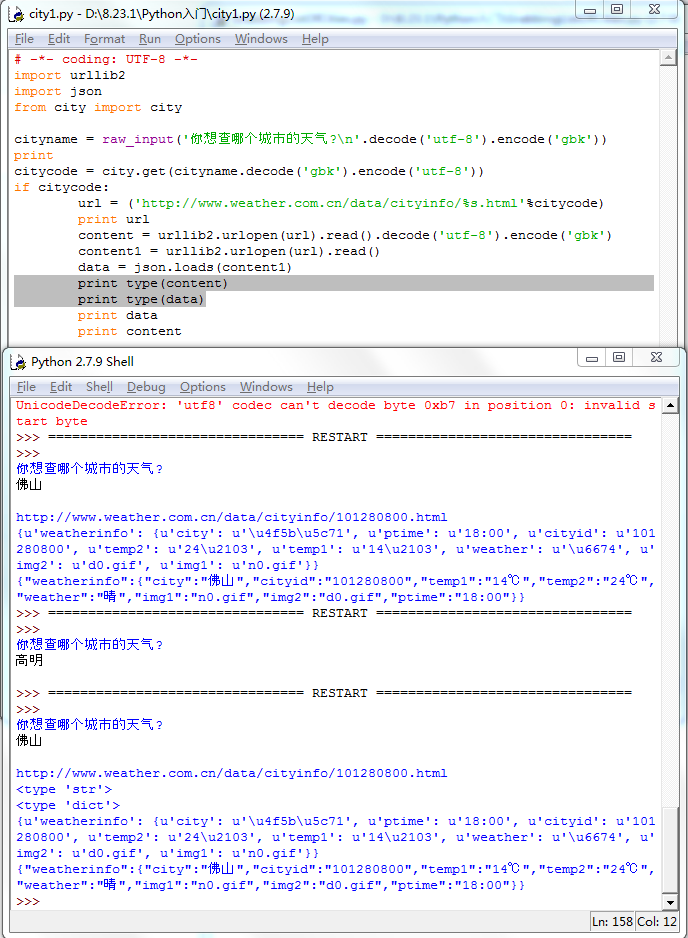
# -*- coding: UTF-8 -*- import urllib2 import json from city import city cityname = raw_input('你想查哪个城市的天气? '.decode('utf-8').encode('gbk')) print citycode = city.get(cityname.decode('gbk').encode('utf-8')) if citycode: url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode) print url content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk') content1 = urllib2.urlopen(url).read() data = json.loads(content1) print type(content) print type(data) print data print content
之后的事情就比较容易了。
result = data['weatherinfo'] str_temp = ('%s %s ~ %s') % ( result['weather'], result['temp1'], result['temp2'] ) print str_temp
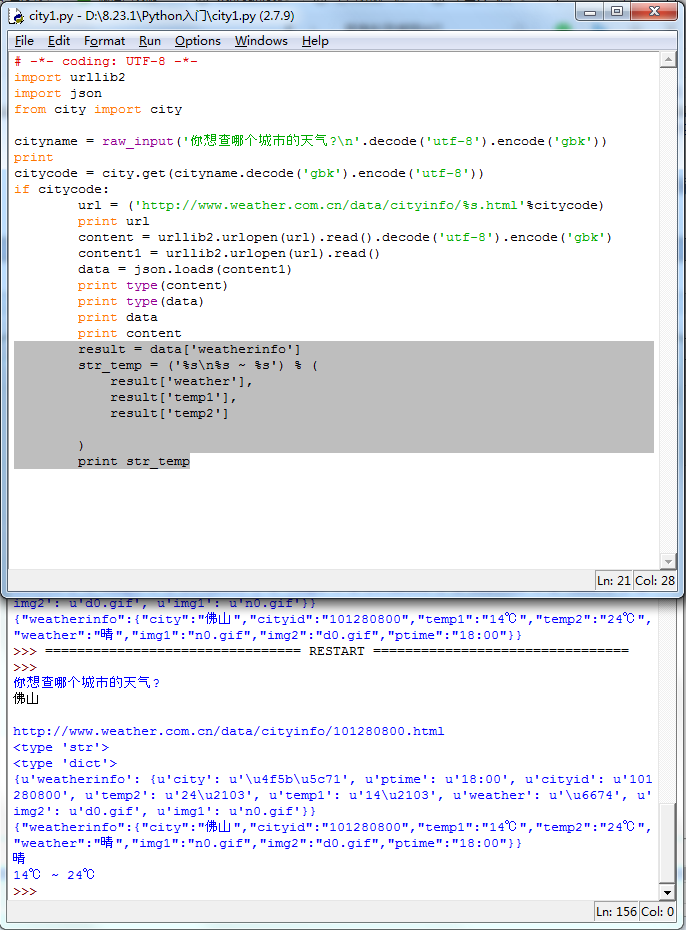
# -*- coding: UTF-8 -*- import urllib2 import json from city import city cityname = raw_input('你想查哪个城市的天气? '.decode('utf-8').encode('gbk')) print citycode = city.get(cityname.decode('gbk').encode('utf-8')) if citycode: url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode) print url content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk') content1 = urllib2.urlopen(url).read() data = json.loads(content1) print type(content) print type(data) print data print content result = data['weatherinfo'] str_temp = ('%s %s ~ %s') % ( result['weather'], result['temp1'], result['temp2'] ) print str_temp
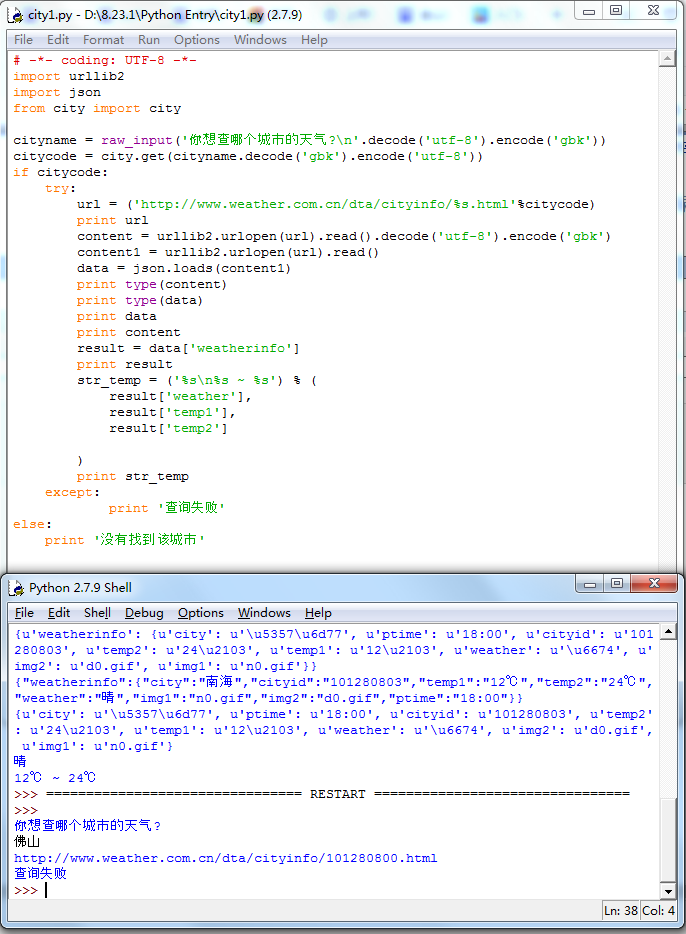
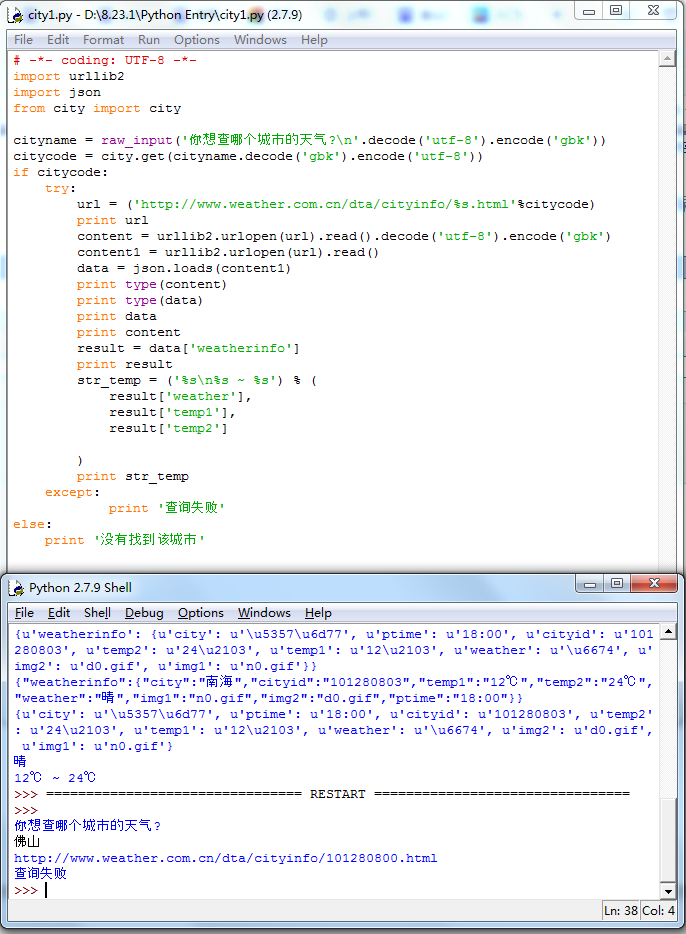
为了防止在请求过程中出错,我加上了一个异常处理。
try: ### ### except: print '查询失败'
以及没有找到城市时的处理:
if citycode: ### ### else: print '没有找到该城市'
# -*- coding: UTF-8 -*- import urllib2 import json from city import city cityname = raw_input('你想查哪个城市的天气? '.decode('utf-8').encode('gbk')) citycode = city.get(cityname.decode('gbk').encode('utf-8')) if citycode: try: url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode) print url content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk') content1 = urllib2.urlopen(url).read() data = json.loads(content1) print type(content) print type(data) print data print content result = data['weatherinfo'] print result str_temp = ('%s %s ~ %s') % ( result['weather'], result['temp1'], result['temp2'] ) print str_temp except: print '查询失败' else: print '没有找到该城市'
查天气(4)
这一课算是“查天气”程序的附加内容。没有这一课,你也查到天气了。但了解一下城市代码的抓取过程,会对网页抓取有更深的理解。
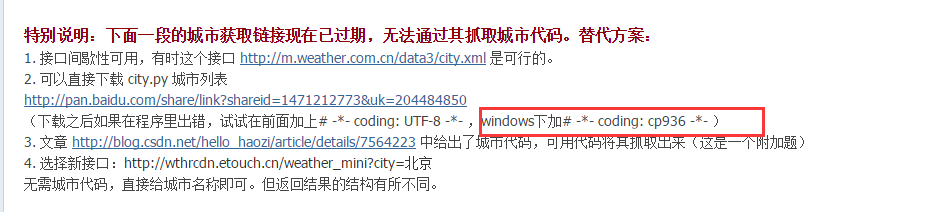
天气网的城市代码信息结构比较复杂,所有代码按层级放在了很多xml为后缀的文件中。而这些所谓的“xml”文件又不符合xml的格式规范,导致在浏览器中无法显示,给我们的抓取又多加了一点难度。
首先,抓取省份的列表:
# -*- coding: UTF-8 -*- import urllib2 url1 = 'http://m.weather.com.cn/data3/city.xml' content1 = urllib2.urlopen(url1).read() provinces = content1.split(',') print content1
输出content1可以查看全部省份代码:
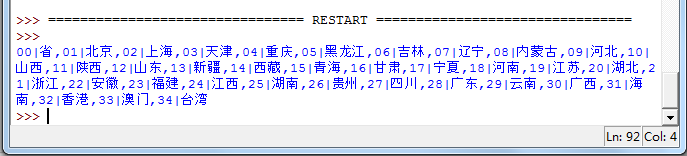
对于每个省,抓取城市列表:
url = 'http://m.weather.com.cn/data3/city%s.xml' for p in provinces: p_code = p.split('|')[0] url2 = url % p_code content2 = urllib2.urlopen(url2).read() cities = content2.split(',') print content2.decode('utf-8')
输出content2可以查看此省份下所有城市代码:
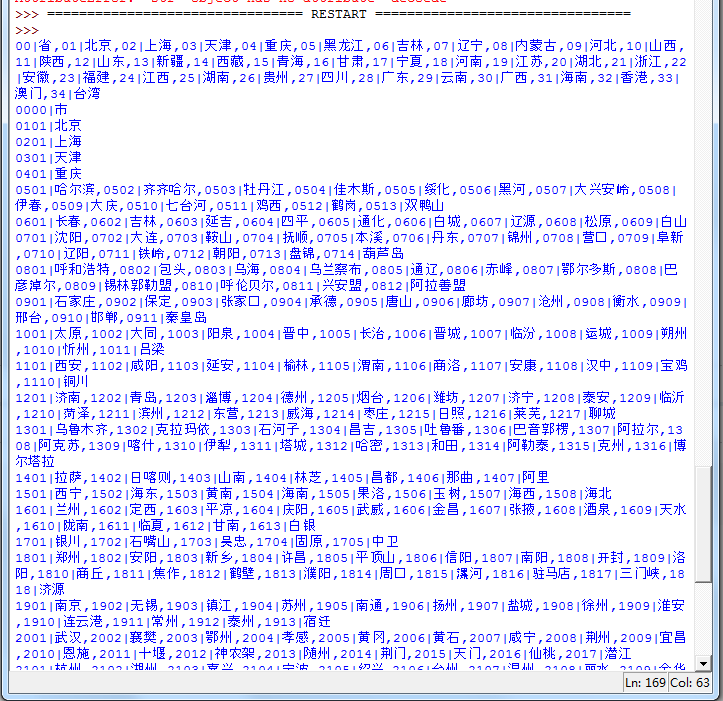
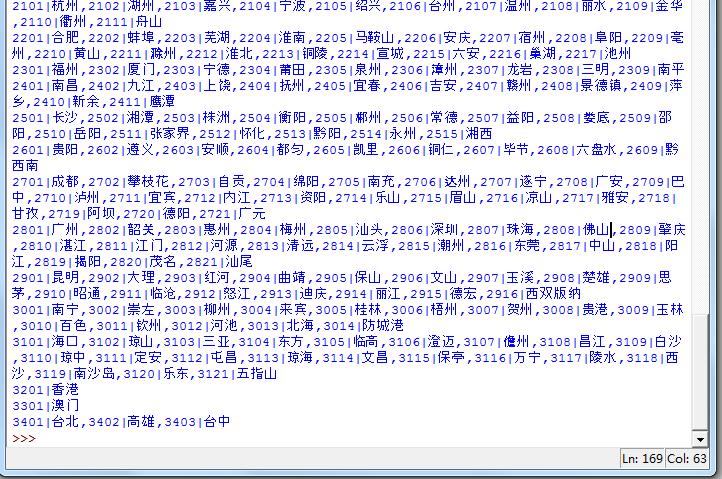
再对于每个城市,抓取地区列表:
for c in cities[:3]: c_code = c.split('|')[0] url3 = url % c_code content3 = urllib2.urlopen(url3).read() districts = content3.split(',') print content3.decode('utf-8')
content3是此城市下所有地区代码:
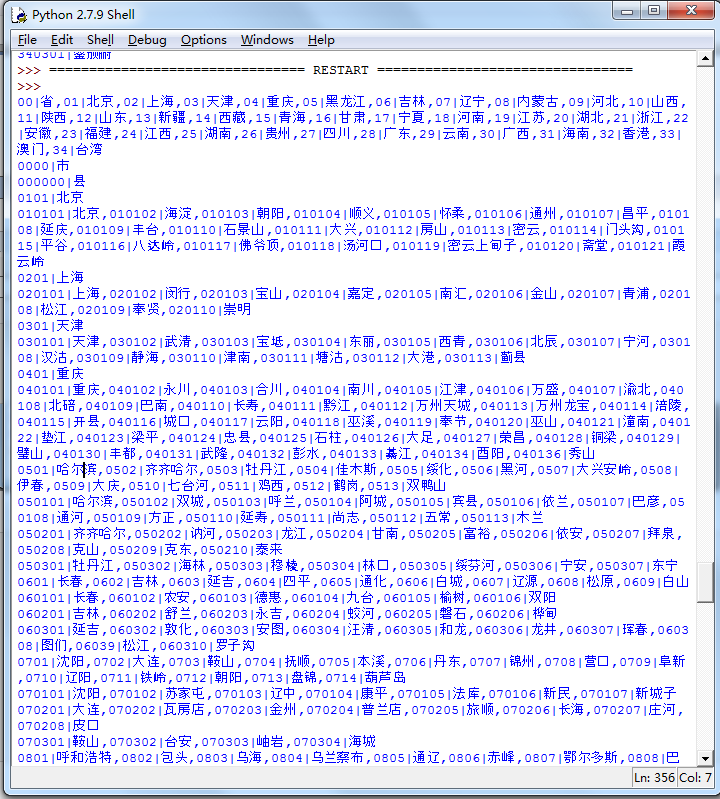

最后,对于每个地区,我们把它的名字记录下来,然后再发送一次请求,得到它的最终代码: