操作系统的存储部分.主要有实存的管理和虚存的管理.存储涉及到的知识点很多,有实存的管理,虚存的管理,cache,cache与主存之间它的命中率的一些计算其实也是存储相关的,存储的一个容量计算.
这些内容是如何分类的呢?在硬件部分(组成原理和体系结构当中),有存储一部分的知识.操作系统里面也有存储这一块的知识.它们的分类就是软件部分的处理放在操作系统部分来讲,而硬件相关的放在组成原理那一部分来讲.
比如说实存管理和虚存管理都是用软件的方法来管理存储器.这样子这一部分的内容就归为操作系统.
虚存的管理是最为重要的.也就是断页式的管理.

在程序执行之前,也就是说把程序调入内存,CPU要访问内存之前,才把地址转换出来.这里为什么要进行地址的转换呢?
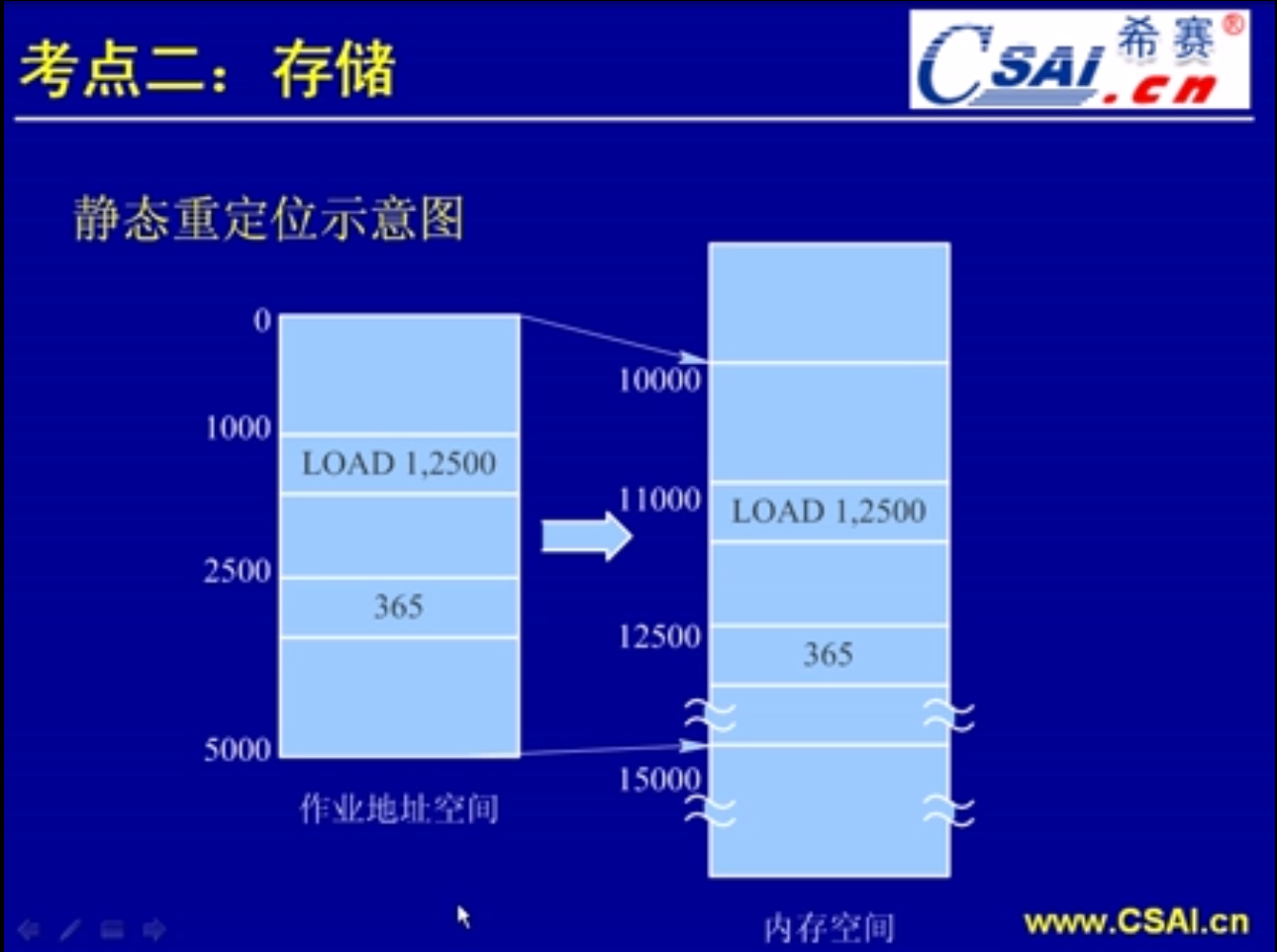
这是我们的程序所要使用到的存储空间.由于程序它是一个比较独立的一个概念,它要用到的空间它所指定的地址会是从0开始进行编址.这个地址称为一个逻辑的地址.但是当程序调入到内存去执行的时候往往无法用到这些地址,比如说从0开始到5000这个地址段它肯定是不会被这一个作业所执行的.因为内存空间前一部分地址一般是分配给操作系统来使用的.所以留给用户的内存空间可能就是从10000开始的或者是从15000开始的,或者说是用户空间分成了很多个区域,有从10000开始的有从20000开始的也有从25000开始的地址空间.然后像这么一个作业它要占用5000个内存单元,5000个字节的内存单元.那么我们就把它装入从10000开始到15000截止的一个内存单元.然后就把整个的程序段(能够执行的指令)等于是拷贝到了内存中.分析这种拷贝方式进去执行过程中会不会产生什么问题?比如说在这个程序当中它就出现了一条指令,就是在1000条指令的位置出现了一个LOAD 1,2500.这一句指令的含义就是从2500号内存单元(存储单元).2500是一个地址,是程序内部所使用的一个虚拟地址.从2500号单元取出数据365到寄存器1,这个程序的这个逻辑是没有问题的.因为2500号逻辑地址确实对应的是365这一个数据.而当我们把这一个地址空间映射到了内存当中的时候,情况就发生了改变.我们知道程序的起始地址由0变为了10000,这一条指令LOAD 1,2500由1000的地址空间变为了11000的地址空间.但是程序内部它用到的这个地址还没有发生变化.还是LOAD 2500到1号寄存器.这时的2500就不再是365了,是一个什么数据我们不清楚,可能读到的是操作系统用到的一个数据,也可能读到的是一个用户其他程序的一个数据.因为现在的365它的内存空间地址已经变为了12500,所以这样的一个程序它的逻辑地址在程序编制的时候它是没有错误的,但是当它读到内存当中进行运行的时候就发现了地址的错误.错误的主要原因就是因为逻辑地址和物理地址它不对应.不对应的话我们就要想办法让它对应起来,对应起来就有一个地址的转换过程.这个地址的转换过程我们就称它为重定位.
那么这一个程序装入它的正确过程应该是怎样的呢?就是把这一段指令拷贝过去的同时把所有指令当中牵涉到的逻辑地址全部进行转换.比如说这个2500我们就要进行转换,转换成2500+内存的起始地址=12500.所以说11000号这一条指令也就是逻辑地址为1000的这一条指令它要改为LOAD 1,12500.这样的一个地址它就正确了.因为它实际上在内存中的地址应该是12500.12500就对应了这个365.可以正确地把这个365取出来.然后我们就称这种在程序的装入过程中把所有的地址(虚地址)变为实地址的过程称为静态的重定位.因为它这个过程当中它会一次性地把所有的地址全部改为绝对地址.而这个绝对地址是不会发生改变的.你在程序的运行过程中也无法对它再进行一个更改/修改的过程.所以称为一个静态重定位,它是一次性的一个过程.


动态重定位是把程序/一个作业调入内存之后,然后它这个地址空间不发生变化.也就是它还是LOAD 1,2500.刚才不是说了,不把地址转换出来它可能就会产生错误.我们要如何来解决这个问题呢?
它还是有方法可以解决的,就是CPU要执行这一条指令的时候,我们就要对这个地址进行重新的核算.重新核算看从虚地址转为实地址,重新的核算的过程是怎样的呢?就是把这个相对的这个虚地址给取出来,取出来然后与重定位寄存器中的一个值进行相加,相加之后就得到了实地址.然后从这个实地址去取这一个数据出来.而重定位寄存器中存的是什么呢?存的是我们装入主存的时候它的一个主存起始地址:10000.这样的一个过程就是动态的重定位.
实存部分:
其实实存部分考的知识点是比较少的.主要是为了讲虚存,所以也要把实存拿出来讲一讲.这样子可以让大家更深刻地理解虚存和实存的区别.概念上的区别.实存的管理是对实实在在存在的这个主存的一个管理,虚存的管理待会会讲到.虚存和实存在概念上的区别:
实存的管理管理到的全部都是实实在在的内存/主存,虚存是一种折中的方案,由于内存数量少外存数量多,为了解决内存数量少的问题我们就用一定的外存来当做内存使用.
引入了虚存的概念那么我们就有可能执行大的程序,比如我的内存现在是640KB,然而我现在要运行的程序它需要耗费的内存为1MB,如果仅仅有实存的管理而没有引入虚存的概念那么这一个系统它是无法执行这一个1MB的程序的.因为内存无法装入这个程序而虚存它就不一样了,虚存它可以把这一个程序进行分段、分页,把它拆分为几个部分依次装入主存.其实这种处理方法是非常科学的.虚存处理大的程序的过程是一个非常科学的过程.
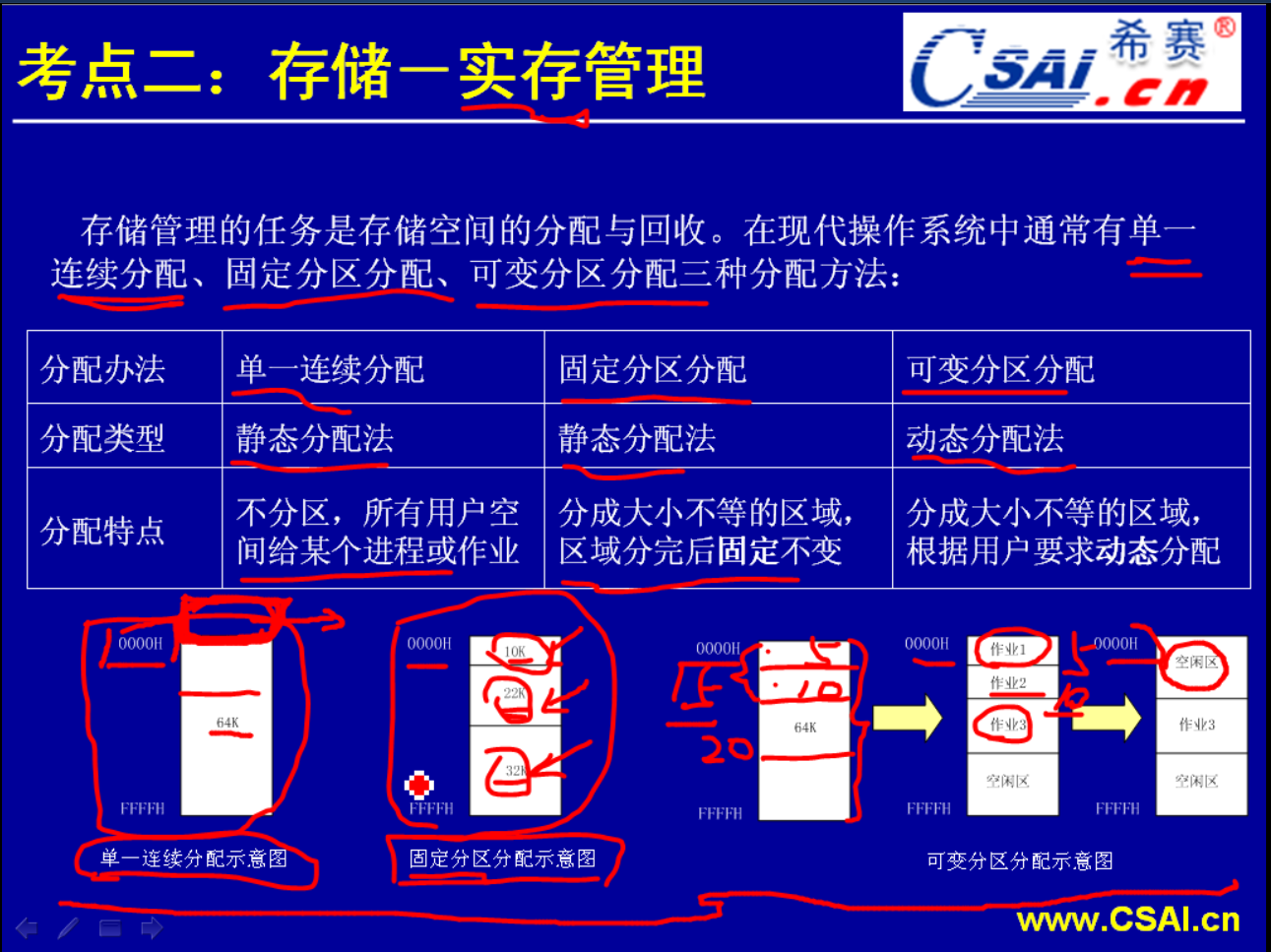
在实存的管理部分通常会把主存进行分配,分配的话有几种分配方案.第一种分配方案就是单一的连续分配,第二种是固定分区分配,第三种是可变分区的分配.三种分配方式各有特色.
单一分配和固定分配都是属于静态的分配法.静态的含义是分配完之后它就不再做调动/调整了.静态重定位就是一旦重定位完成以后它就不再做修改,这里就是进行单一连续分配和固定分区分配的时候一旦分配完成就不再做处理了.而可变分区的分配它是在分配完之后它是可以灵活地调动的.
系统给用户的存储空间是64KB.单一连续分配它就是把整个的用户内存区划为一个块,这样做的缺点是它同一时间只能够在内存当中装入一个程序,无法装入多个程序.所以这种分配方式最多只能够用于单用户的操作系统,而且是单用户单任务,它无法同时执行多个任务,而只能够执行一个任务.因为它把内存已经划为了一个区,一个块.
固定分区分配方案.单一连续分配它是把整个内存区划为一个区,而固定分区分配它就存在着一个分区的过程了.它就把内存分成了几块.64KB内存分成了10KB,22KB,32KB这三个块.这三个块就使一种现象成为可能,我要运行三个程序,一个程序占用空间是5KB,另外一个是10KB,第三个是20KB.这三个程序可以同时被装入内存,分别装到这三个区当中来.这种分区分配方案把分区给定死了,就是一旦分区完成就只有10KB,22KB和32KB这三个区,无法再做变更.比如说我现在要执行一个35KB的程序,那么这一个内存系统它就不能够执行这样的程序.因为它每一个区都不够35KB的大小.但是即使它们三个区都空闲都无法把它们进行合并来执行一个大的程序,所以内存虽然有64KB,但是无法执行一个35KB的一个程序.这也是固定分区的它的一个弊病所在.
第三种是可变分区,可变分区采用的是动态的分配方法.可变分区最初的一种状态和单一连续分配是一样的.就是还没有执行任何的用户程序的时候它是一个空白的大区.当有程序装入的时候它就开始进行分区了.比如说作业1需要5KB的内存,那么操作系统就给作业1划分5KB的内存,作业2需要10KB的内存所以当作业1在运行的时候空闲区就只剩下59KB了,第二个作业进来的时候它需要10KB的资源,那么操作系统就从这个剩余的59KB的资源当中给它划了一块10KB的,作业3进来的时候它需要20KB的资源,那么操作系统就从这个剩余的空间里面又划了一个20KB的空间给作业3,当作业1执行完毕的时候它这一块空间它就空余出来了,就空余出来一块5KB的资源.同时如果作业2它的10KB的这个程序执行完了,作业2也会释放它的资源.这里就有一个10KB的块了.但与这种固定分区有不同的就是说它虽然这里分了5KB这里分了10KB,但是当它两个都是空闲的时候,那么这两个分区可以进行合并.它合并成为一个15KB的单元.也就是说如果说作业3在执行完毕的时候它释放了20KB的资源,现在系统的64KB的资源又合成了一个整体的块了.所以可变分区分配方案它的适用范围和灵活度大一些,就是我们刚才说的作业1和作业2执行完了空闲区就会进行合并,合并成一个大的空闲区.所以可变分区分配方案就比较灵活了.当然灵活意味着需要花更多的资源去对它进行管理,所以说我们待会就要讲一讲可变分区分配方案的几种管理方式,对空闲区的一种管理方式.
这里举的例子是一种比较理想的状态.就是为了让大家不混淆概念,所以我是取了64KB从0000H开始到FFFFH.而通常情况下想要达到这种效果是不可能的,因为内存区它要分一块给操作系统用,操作系统它的内存空间是占了前面的一部分,基本上都是占前面的一部分所以一般在用户区前面它会有一块内存是用于操作系统专用的.所以往往用户的内存不是从0开始.但是这个不要紧,我们理解这一个概念就可以了.
可变分区分配方案的几种分配算法.
当程序运行到一定的程度,系统运行了一段时间以后,它的内存区肯定不是一个连续的区域,因为它执行了一些进程又释放掉了一些资源这样反反复复可能现在的内存空间就是非常零散的一些资源,第一段一个5KB的空闲区,第二段是一个作业在运行,第三部分它可能又是一个空闲区,第四部分它又是一个作业在运行.这样它内存的空闲区可能就分成了很多个小块,这样当内存中要调入新的作业的时候我们就要考虑把这个作业放在哪一块空闲区比较合理.这样子就形成了分配算法,就是我们以什么样的一个规则来把作业调入空闲区这样的一个过程,所以我们提出来这四种算法.
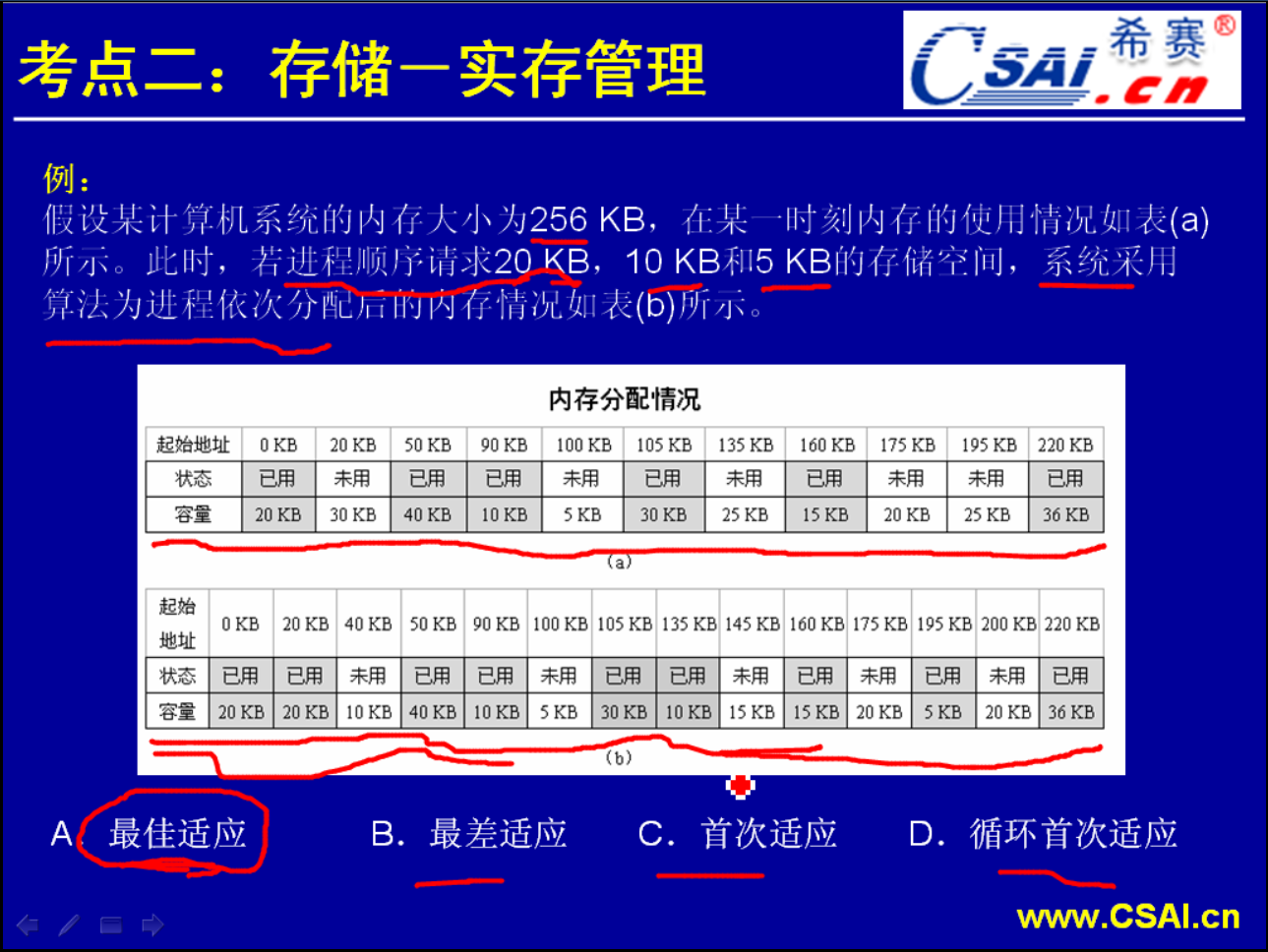
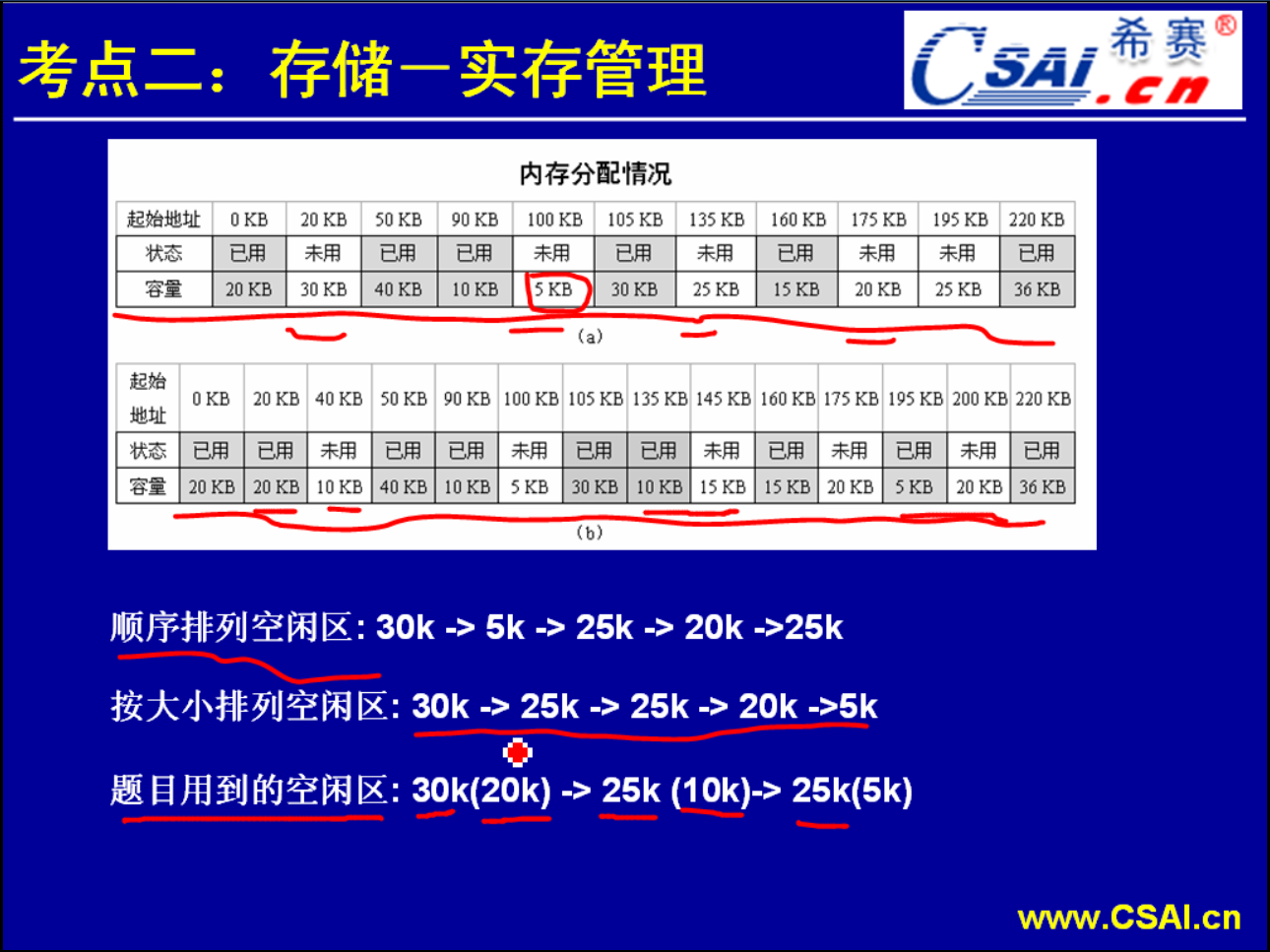
最佳适应算法:把程序/作业放到和它大小刚好合适或者是大小接近的一个内存区当中.
首次适应法:从主存低地址开始,把所有的自由区可以说是连成一个串,第一个空闲区第二个空闲区第三个空闲区,你要装入一个作业的时候就要从第一个空闲区开始判断,判断这个空闲区的大小是不是比你作业的大小要大,如果说比你作业的大小要大的话那么我们就从空闲区划一块空间给这个作业使用.也就是说只要第一次发现了这种比作业大的空闲块,我们就把这个作业放进去执行.这样子它就是一种首次/第一次适应算法.第一次适应那么我们就给它进行分配.这种算法可以快速地进行内存的分配,
最差适应算法:最佳适应算法虽然每一次的运行、每一次的分配它都会把与作业大小基本上相符的内存块分配出去,看上去它是一种最佳的方案.但是实际上是存在着问题的.比如一个6KB的块装入了5KB的程序,那么就形成了一个1KB的空闲区.这个1KB的空闲区是一个很小的空闲区,它往往无法被任何的一个程序/一个作业所使用.因为很少会有1KB这么大的作业.所以说多次进行这种适应分配的话,它就产生了一个问题:系统中间的内存的这种碎片越来越多,这种碎片又无法得到使用.所以说到后期执行了很多次这种分配之后可能系统就存在很多很多这种碎片,所以这种最佳适应算法它也是有弊端的.
循环首次适应算法:和首次适应算法非常类似.唯一不同的是首次适应算法它是每次从主存的低地址出发寻找可用的内存区.而循环首次适应算法,

例题:
计算机系统中给用户使用的内存大小是128KB.
最佳适应算法把内存空闲区进行一个排列,从小到大的一个排列.10KB<25KB<28KB.
最差适应算法是最佳适应算法的逆过程.
循环首次适应算法是从上一次执行完的地方开始算起.

软考的真题: