断点续传得把下载到的位置给它记录下来。通过什么记?记在哪里?记在内存里行不行?用迅雷下了蓝光电影,动辄就好几个GB.下了一个GB突然间改早了没网了,这个时候你放在内存里面电脑一关所有的内容就都没有了,下一次还得重来。所以一定得保存到磁盘里,我得搞一个文件,通过这个文件来记录下载的位置。所以第一个就是得通过文件来记录下载的位置。问题2:下载的位置在哪里去记住?多线程下载的过程的这段代码是实际上真正的去往本地去写了。在本地去写究竟在什么位置来记录下载了多少?写一次记一次,写一次记一次。所以我得在这儿搞一个变量,int count。
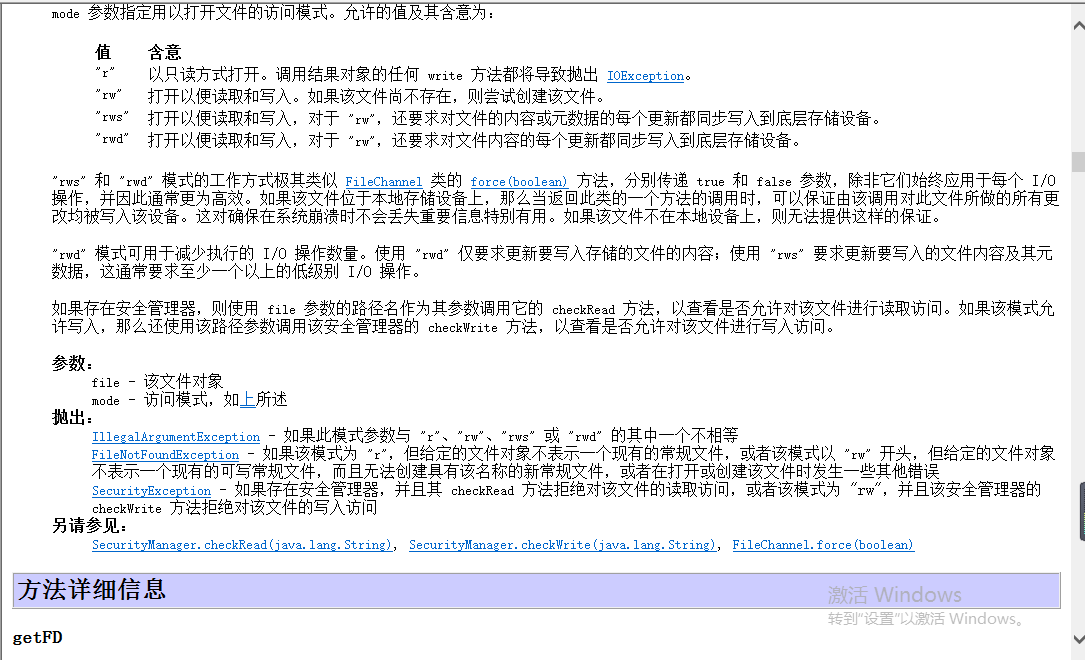
咱们存内容的存到本地,存到哪里?放到硬盘上。咱们买的硬盘不管是固态的还是机械的都有一个参数叫缓存。实际上你往磁盘里写的时候这个数据是先放到磁盘的缓存上的。放到缓存上什么时候这个缓存满了它才会把缓存的内容都同步到磁盘里。如果你用File去写咱们要写的这个数据的内容实际上很短,记录的就是下载到的位置。一看这个内容很短。很有可能你用file去存的话直接先放到缓存里,如果你突然间写上了断下来之后你在很短的时间内再去读有可能我这个内容还没同步到本地呢,你再去读有可能这个内容就读不到。因为咱们存的这个数据特别特别小,你就算再长的一串数,咱们这个东西顶多就十几位二十位了不起了,二十位的这个数存到本地连1KB都不到。用String去存20个,一个就是一个byte,20位就是20个byte再加一点元数据可能也就是20或者是30个byte,连1KB都不到。一般呢你的磁盘的缓存最起码有几十MB,这些东西往这里边一丢很有可能是先放到缓存里,它不会立即就放到磁盘当中。如果你是断开之后很快的又去读取这个内容,它就没来得及同步到本地。那这个时候你再去访问这个file实际上就访问不到了。为了避免这种情况要使用RandomAccessFile,保证你每一次更新都同步写入到底层存储设备。它不会去走磁盘缓存,比如说你存一次它一定会写到磁盘上,不会留到缓存里。所以这块咱们要使用RandomAccessFile。实际上元数据对于咱们来讲并不重要。最主要是文件存储的位置也就是文件的内容。
package com.itheima.multiThreadDownload; //import java.net.MalformedURLException; import java.io.InputStream; import java.io.RandomAccessFile; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL; //import java.net.URLConnection; import java.net.URLConnection; import java.util.RandomAccess; public class MultiThreadDownload { private static String path = "http://127.0.0.1:8080/FeiQ.exe"; private static int threadCount= 3;//不搞那么多就搞三个线程. public static void main(String[] args) { //①联网获取要下载的文件长度 try { URL url = new URL(path); //URLConnection openConnection = url.openConnection(); HttpURLConnection openConnection = (HttpURLConnection) url.openConnection(); openConnection.setRequestMethod("GET"); openConnection.setConnectTimeout(10000); int responseCode = openConnection.getResponseCode(); if(responseCode==200){ //获取要下载的文件长度 //int contentLength = openConnection.getContentLength(); //long contentLengthLong = openConnection.getContentLengthLong(); int contentLength = openConnection.getContentLength(); //在本地创建一个一样的文件 RandomAccessFile file = new RandomAccessFile(getFilename(path), "rw");//第一个叫file或者说是name(路径),第二个参数叫mode //名字可以通过路径去获取,截取这个路径最后一个斜杠.剩下的这个就是我要下载的文件名 //file.setLength(contentLengthLong);//文件创建出来之后去设置文件的长度 file.setLength(contentLength);//文件创建出来之后去设置文件的长度 //计算每一个线程要下载多少数据 //int blockSize = contentLengthLong/threadCount; int blockSize = contentLength/threadCount; //计算每一个线程要下载的数据范围 for (int i = 0; i < threadCount; i++) { //用i和blockSize来确定startIndex和endIndex int startIndex = i*blockSize; int endIndex = (i+1)*blockSize-1; if(i==threadCount-1){ //说明是最后一个线程 endIndex = contentLength-1; } new DownLoadThread(startIndex, endIndex, i).run();//main是静态的方法,要求DownLoadThread也是静态的. } } } //catch (MalformedURLException e) { catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } private static class DownLoadThread extends Thread{ private int startIndex; private int endIndex; private int threadID;//线程的编号 public DownLoadThread(int startIndex, int endIndex, int threadID) { super(); this.startIndex = startIndex; this.endIndex = endIndex; this.threadID = threadID; } @Override public void run() { // TODO Auto-generated method stub //super.run(); //run方法还是要联网,拿着url向服务端请求数据.多个线程联网下载数据 try { URL url = new URL(path); //URLConnection openConnection = url.openConnection(); HttpURLConnection openConnection = (HttpURLConnection) url.openConnection(); openConnection.setRequestMethod("GET"); openConnection.setConnectTimeout(10000); //设置Range头,用计算好的开始索引和结束索引到服务端请求数据 openConnection.setRequestProperty("Range", "bytes="+startIndex+"-"+endIndex);//计算出来的开始索引和结束的位置 if(openConnection.getResponseCode()==206){ System.out.println("线程"+threadID+"开始下载"+startIndex); InputStream inputStream = openConnection.getInputStream(); //通过RandomAccessFile来写对应的内容了 int len = -1; byte[] buffer = new byte[1024];//循环是一次读取固定的内容,避免一次读取数据过大,内存溢出。你这里的size最好写成1024 RandomAccessFile file = new RandomAccessFile(getFilename(path), "rw");//文件存在的话它其实是做打开的操作,文件不存在的话是做创建 //这个文件咱们已经创建好了,现在咱们是要给它打开. //打开之后需要注意这一步一定不要忘记 要 要 seek到startIndex位置 写入数据 //如果你这个seek忘了 实际上你每一个线程都是从头开始写的 三个线程都是从最开始写到了三分之一的位置 //把这三件数据写到了同一个位置 你的文件大小 因为咱们之前创建了一个相同大小的文件 你看起来这个大小是没问题的 但是只有前三分之一有数据 file.seek(startIndex);//挪到每个线程指定的位置开始去写 int count = 0; while((len=inputStream.read(buffer))!=-1){//写对应的内容了. file.write(buffer,0,len); count+=len; int position = count+startIndex; RandomAccessFile temp = new RandomAccessFile(getFilename(path)+threadID+".log","rwd" );//这样就确保咱们这个文件一定是存到本地的. temp.write(String.valueOf(position).getBytes()); }//整个while循环结束了这个文件就写完了 file.close(); System.out.println("线程"+threadID+"下载结束"); } //} catch (MalformedURLException e) { } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } } private static String getFilename(String path) { String[] split = path.split("/");//拿斜杠去切 return split[split.length-1]; } }




现在位置咱们都记下来了。文件都存下来了,但是下一次再开始的时候得把这个内容给它读出来。读出来之后我拿着这个内容我要更新startIndex.首先到服务端请求就没有必要从头再请求数据了,当前下载到哪儿我就从这个位置去请求,然后接着下载后面的内容。断点续传的原理就是更新startIndex.