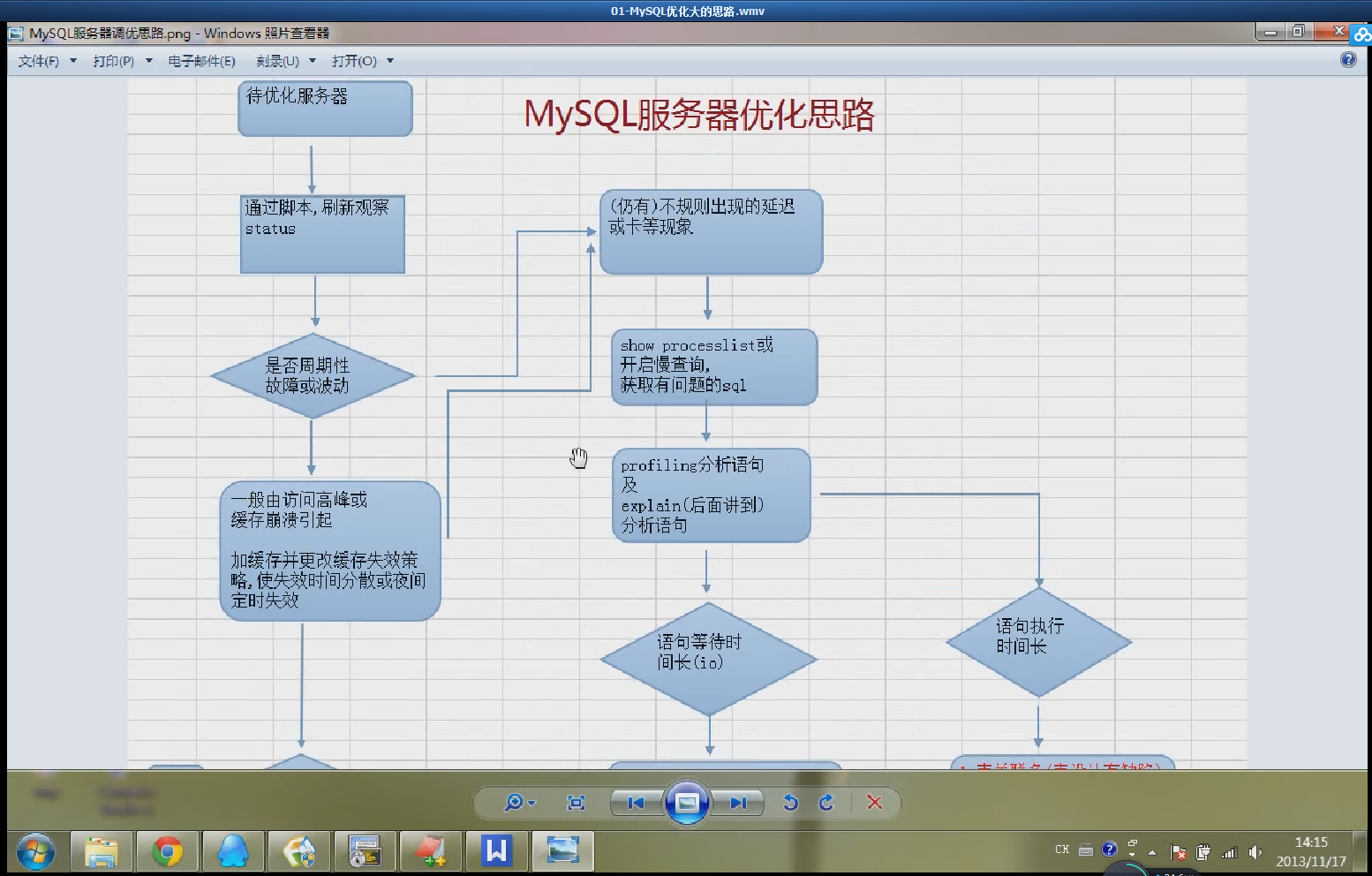
首先不是看它的表结构等等。从整体上去观察,不断去看它的状态。这个状态往往不是一两个小时可以看出来的,得写一个脚本,观察它的24小时的周期性变化,不断刷新它的脚本,观察它的Status。主要是看它有没有周期性的故障或者波动。一个访问高峰/缓存崩溃引起的。
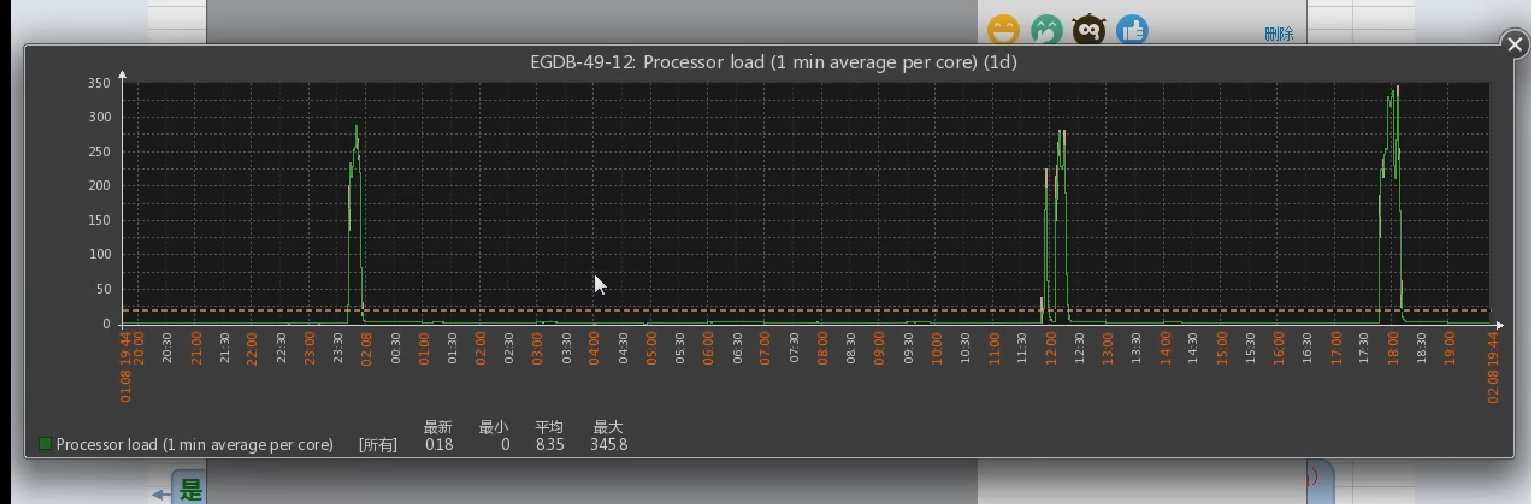
缓存一失效,服务器百分之百挂。

一条sql语句A失效了,失效了之后三个sql语句同时去select它,并且建立这条缓存,这就造成了浪费。所以如果某个语句失效了,有一个拿着锁的人、拿着钥匙的人、上了锁的这个进程去负责select的查询并且更新缓存。

凌晨两三点钟失效,人特少,访问量少,就算它失效了负载也不大,等到早上七八点钟的时候这个缓存又建立的差不多了。所以得看它是不是由于周期性的波动或者是高峰期引起的。所以首先是从缓存这方面解决,而不是说服务器哪儿整的不对。
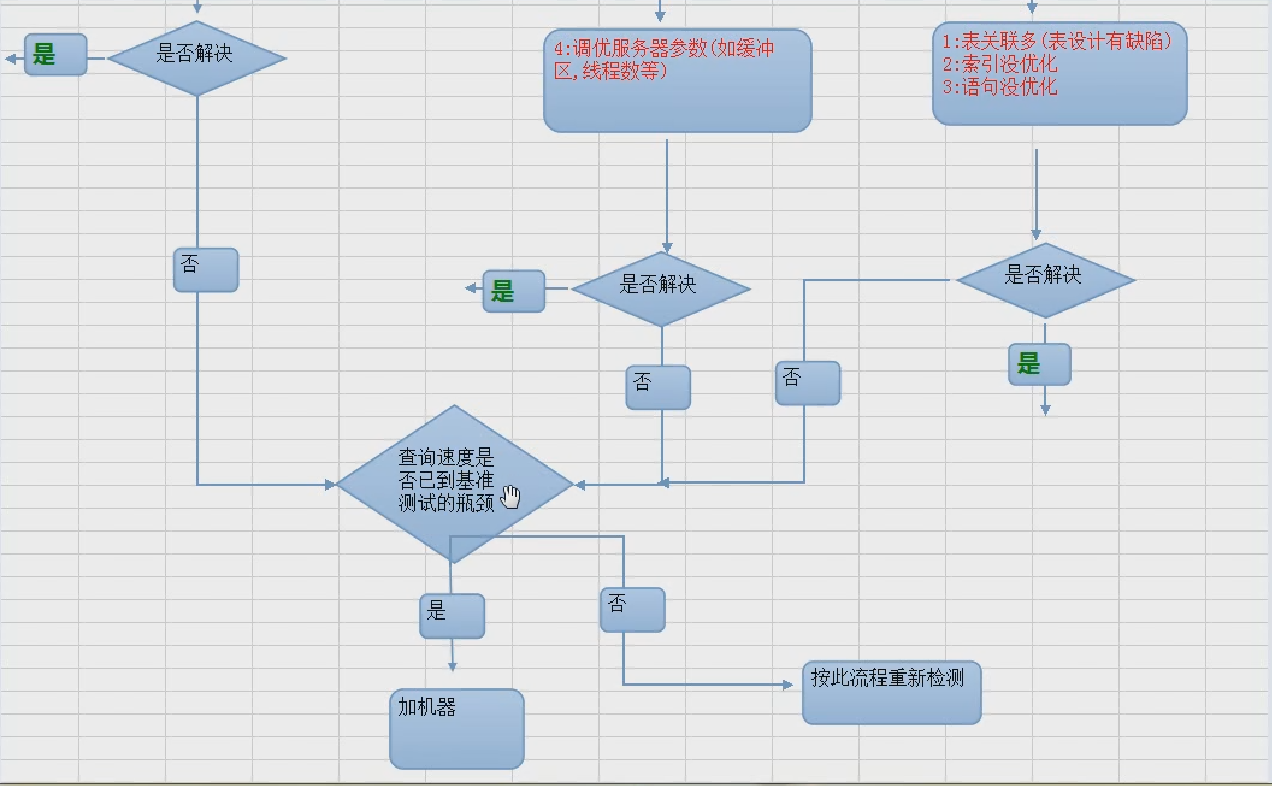
然后看查询速度是不是已到基准测试的瓶颈。如果查询速度换算成I/O都已经60或者70M了,测试的时候我们的机器一秒钟最多读个一百兆。MySQL就已经达到60、70MI/O这已经相当夸张了。
如果说不是一个周期性的波动,这是某条sql语句写的不好引起。只要这条语句出现,服务器它就卡一下,它占的内存资源特别大,或者说它占的I/O资源也特别大。这个时候就要把害群之马找出来。找出来之后用profiling分析它的语句然后用explain分析它的扫描效果。
一上来是先观察,找到问题所在。观察之前首先是做了一个服务器的基准测试,知道服务器的潜力到底有多大。接着观察服务器的当前状态,是否有周期性波动。
首先我们应该学习的是观察服务器状态。