从这一节开始我们将进入到高速缓冲存储器的学习当中。这是本章的一个重中之重,所以大家一定要提高警惕。

我们来看一下,我们之前讲过,我们要提高访存的速率有两种方法,一种方法呢就是使用高性能的比如像双端口的RAM和多模块的存储器。那么第二种方法呢,就是采用我们的高速缓冲存储器,也就是我们的Cache。那这一节我们将要学习Cache的一些基本的概述。

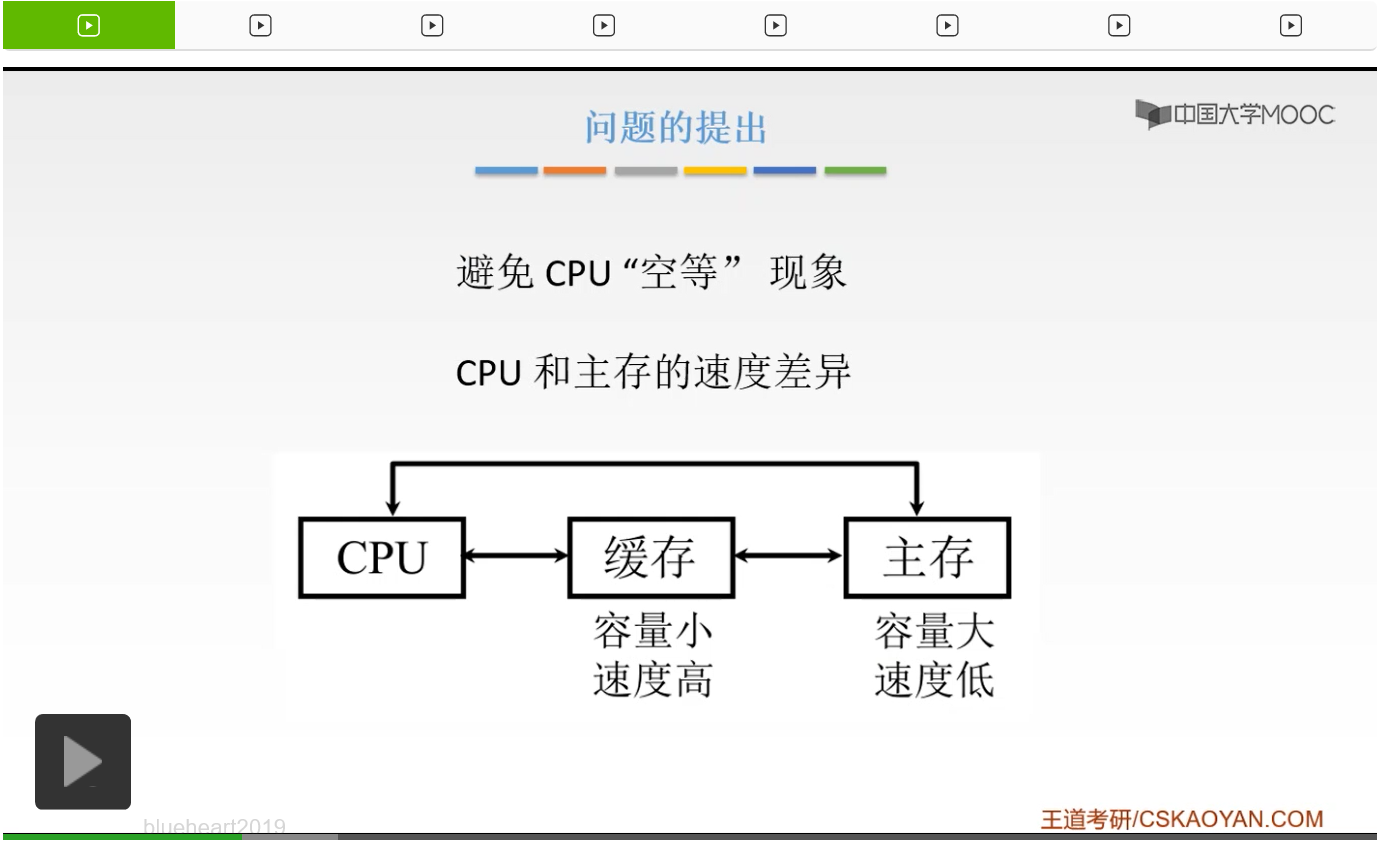
首先我们提出,为什么我们要使用Cache呢?这显然是为了提高我们的访存速度的。因为我们之前已经讲过好多次,我们CPU的增长速度,它的速度的增长速度是非常快的,是指数级别的增长。而我们的主存的增长速度,是一个线性的增长。所以它们的剪刀差会越来越大,而我们的指令、数据和结果都是要取自我们的存储器,或者说要保存到我们的存储器当中。如果我们的CPU跑的再快,你取不到指令,取不到数据那也是没有用的,那么也是无法完成我们的数据写入操作的,所以它只能空等。那么为了避免我们CPU的空等现象,我们就在主存和CPU之间加一级,加一级这样的缓存。它的容量虽然小,但是它的速度是非常高的,那么它就能够提高我们CPU的访存速率了。为了充分发挥我们Cache的作用,能够切实地提高我们CPU的访存速度,所以呢我们的CPU访问的数据和指令要求它能够大多数都能在我们的Cache中,能够取到。这样的话就都不需要到主存当中去取了,所以呢它就能够切实地提高我们CPU的访问速率。那么这就依靠我们的局部性的原理。
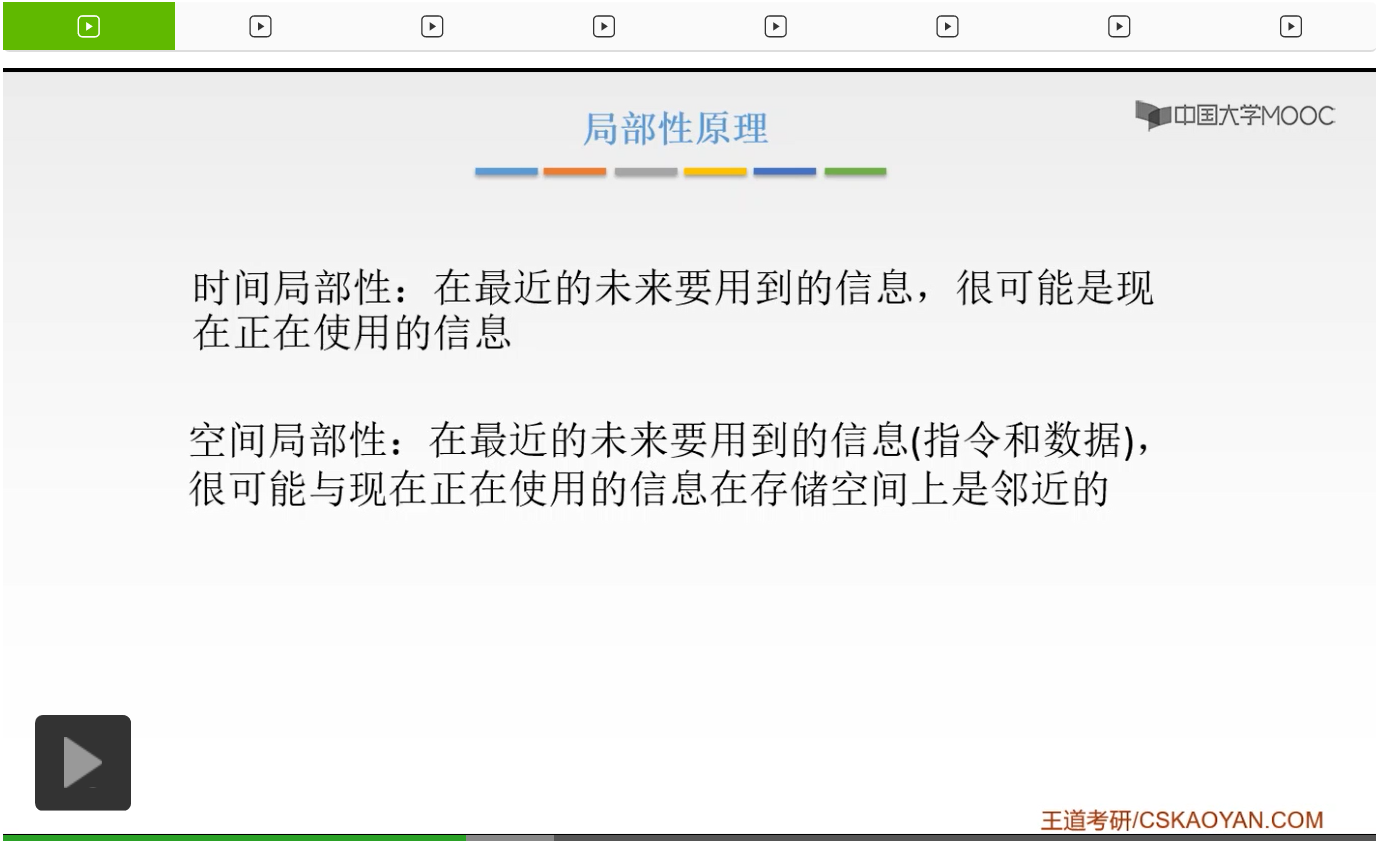
那么什么叫局部性的原理呢?局部性的原理分为空间局部性和时间局部性。那么时间局部性是说的什么呢,就是说我们最近的未来要使用到的信息呢很可能就是我们现在正在使用的信息。那么我们程序啊是存在一个循环的,所以我们最近要使用的一个信息呢就是我们现在要使用的一个信息。还有一个呢叫做空间局部性,空间局部性是说在最近的未来要用到的信息,很可能是现在正在使用的信息在存储空间上面邻近的一个信息。因为我们的这样的指令通常是顺序存放、顺序执行的,所以呢我们的数据也一般是以向量数组或者表这样的一个形式,顺序地存储在一起的。所以我们未来要使用的信息很可能和我们现在要使用的信息在存储空间上是邻近的。所以我们要把这样的信息放到Cache当中呢是把我们现在正在使用的信息放到Cache当中,并且呢把和它相邻的一些信息也放到Cache当中。那么这样就能够使得我们CPU要访问的数据和指令通常情况下都能在Cache当中能够得到。这样呢就能够完全地充分地发挥我们Cache的作用,然后切实地提高我们CPU的访存速度。那么我们Cache和主存进行数据交换的单位呢,就是以块儿为单位的。这个块儿我们把正在使用的信息,和相邻的这样的信息都放到这样的块儿当中,然后我们的Cache和主存交换信息的这样一个单位就是这样一个块儿。块的大小呢要通过实验的方式来测定。
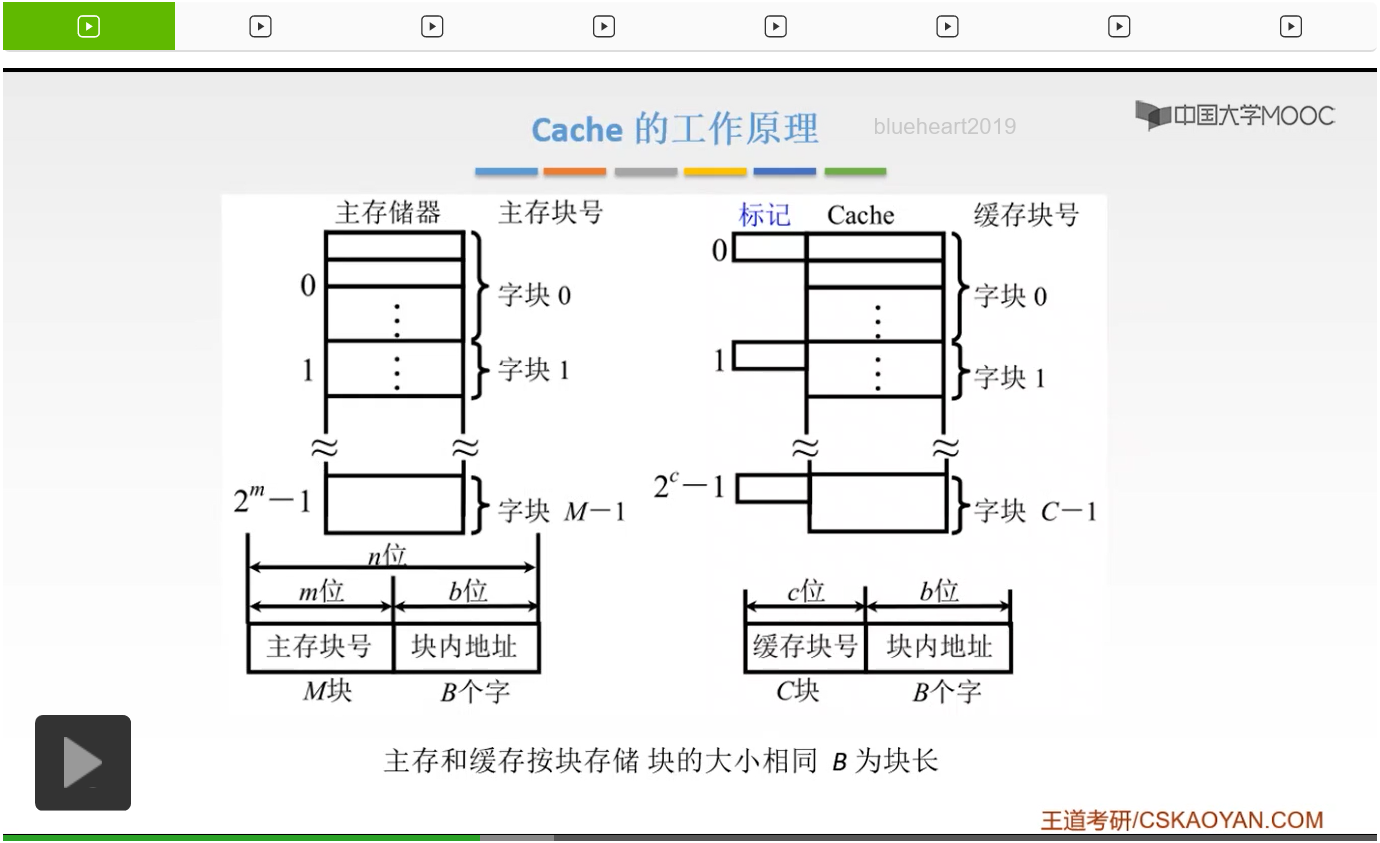
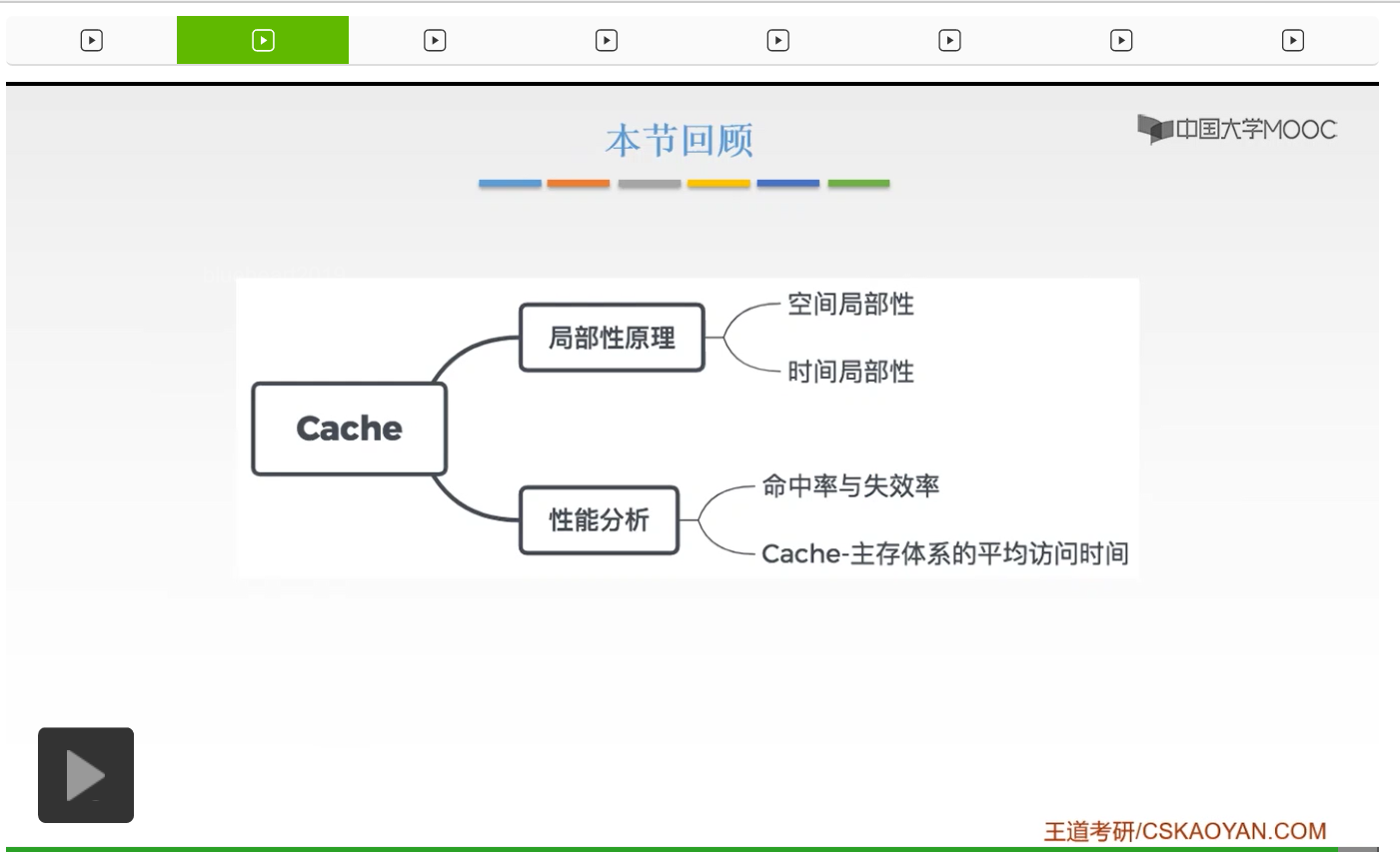
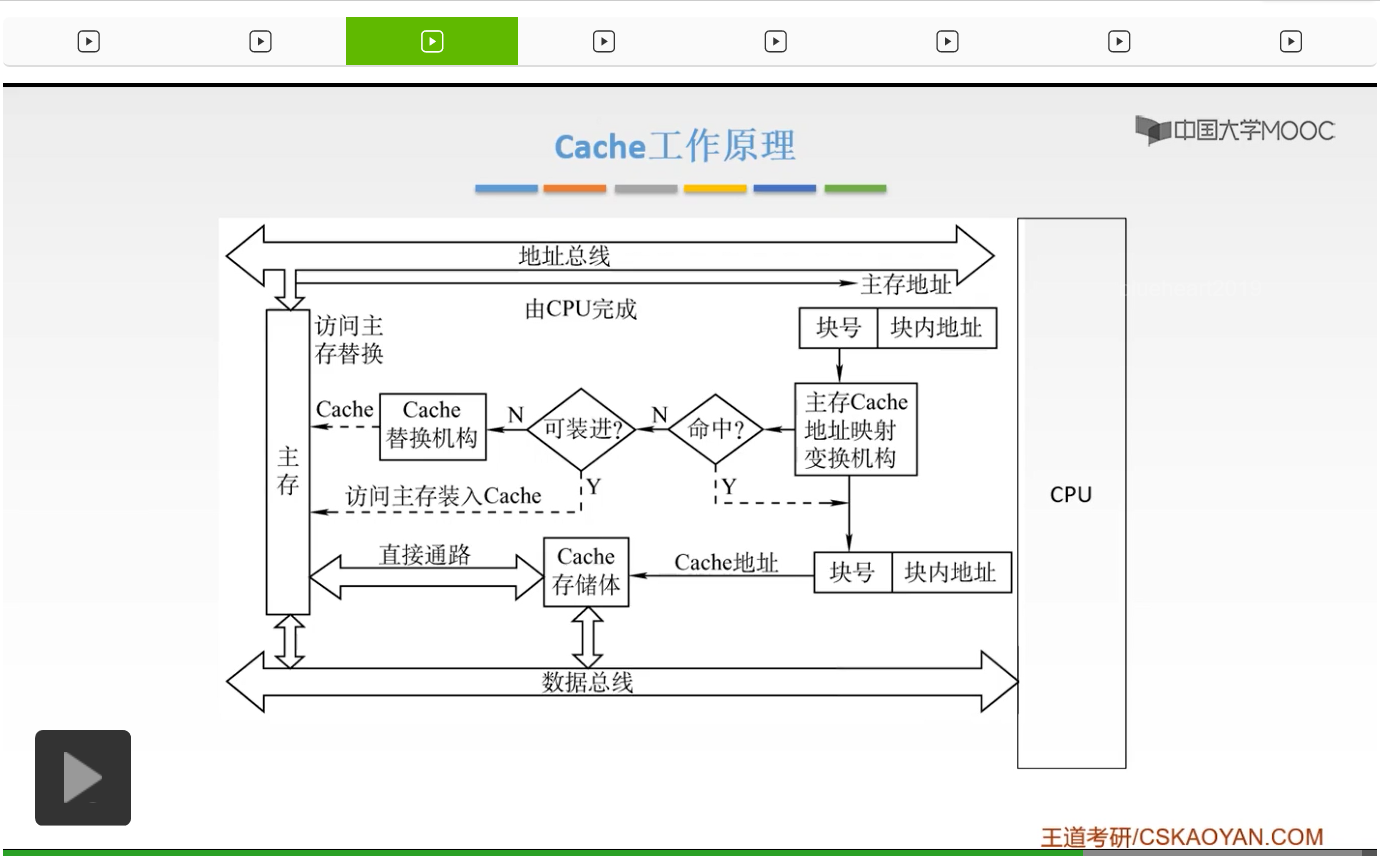
下面我们来看一下Cache的一个工作的原理。我们左边呢是我们的主存的这样的把它分为大小相等的这样的一个块,右边呢是我们的Cache也把它分成了大小相同的这样的一个块。那么主存呢一共有大M块,而Cache呢一共有大C块。要注意的是大M要远远大于大C,为什么呢?因为我们的主存的容量是要远远大于我们Cache的容量的。那么我们主存,它的这样一个地址呢可以分为块内地址和主存的块号,那么这个块内地址啊,它的位数就决定了我们块的大小。你比如说一个块,如果有16个字节的话,那么这个块内地址呢就有4位,啊这个我们之前已经讲过好多次了。然后还有一部分呢就是它的块号。同样的我们Cache也把它分为块内地址和缓存的这样一个块号,但是通常情况下我们Cache的这样一个地址呢它的意义呢并不大,所以呢也并不需要真正地形成我们Cache的这样一个地址。由于我们的主存和我们的缓存,它的这个块的大小是相同的,所以呢我们这个B它也是相同的,所以我们的位数是一样的。并且由于我们主存和我们的缓存进行信息交换的时候,它是以一个整体传送的方式进行交换的,所以它的块内地址的这样的字节的顺序也是不变的。所以,它的值也是相同的。所以我们的主存的块内地址,不仅它的位数是相同的,它的值也是和缓存相同的,所以它就是完全相同的。我们的主存和我们的缓存它的块内地址是完全相同的。标记是用来干嘛的呢?标记就是用来说明我们主存块和Cache块的它的对应关系的。如果我们的主存有一块写到了我们的缓存当中,那么这个主存的块号我们就把它写到这个标记当中,然后就用来记录我们Cache当中是否保存了我们的主存这样一块。那么如果CPU给出了一个主存的地址,我希望能够在我们的Cache当中能够访问到。我就要来看一下我们这个主存地址的这个主存它的这个东西是否已经送到了我们的缓存当中。所以呢我们就要用个主存的块号和我们的这个标记进行一个比较,如果它是相等的,并且它也是有效的话,所以我们就可以直接从Cache当中就得到了我们的信息想要的信息,那么就可以大大地提高我们的访存速率。那么值得要注意的是,我们的主存和我们的缓存都是按块儿进行存储的。块的大小是相同的,我们的B呢是这样的一个块长。那么这就是我们Cache的一个工作原理。
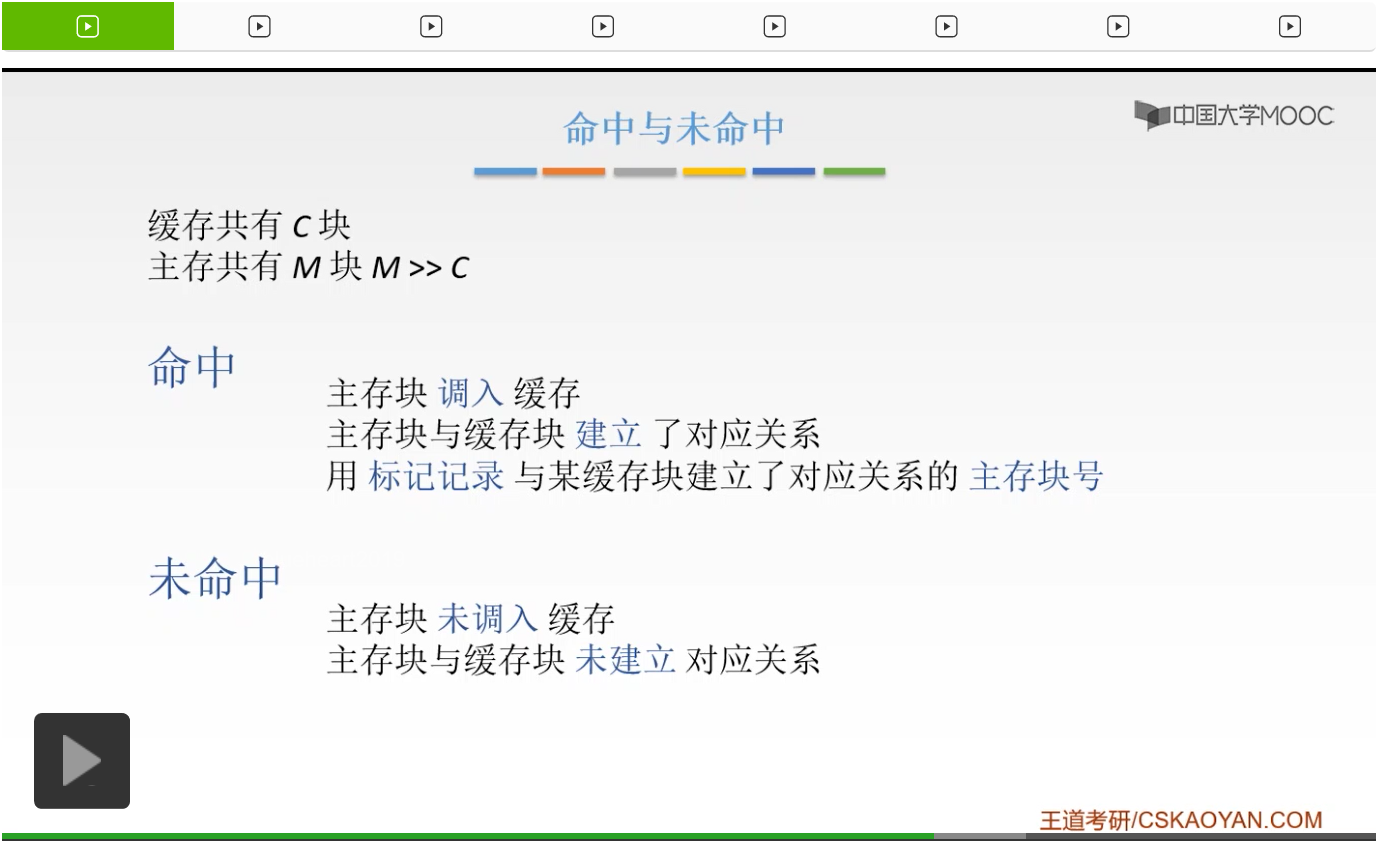
那么知道了这个之后我们就要来看一下有一个叫做命中和不命中的这样的一个概念。我们假设主存一共有大M块,而缓存呢一共有大C块,我们的大M是远远大于大C的,这个之前我们已经讲过。因为主存的容量是远远大于缓存的容量的。那么什么叫做命中和不命中呢?命中就是说我们的主存块它已经调入到了缓存当中,所以我们的主存块和我们的缓存块就可以建立一个对应关系。那么就可以用我们的标记来记录与某一个缓存对应的这样的一个主存的块号。而不命中呢,和它就是相反的,就是说我们的主存没有调入到我们的缓存。所以呢我们的主存块和我们的缓存块就没有办法建立一个对应关系,而这就是一个什么叫命中什么叫不命中。命中就是说我们的主存块已经调入到缓存当中,而不命中就是主存块没有调入到缓存当中。所以我们的主存块和缓存块就没有能够建立我们的对应关系。
那么有了命中和不命中就有我们的命中率。那么什么叫命中率呢?命中率就是说我们的CPU想要访存的信息,能够在Cache当中找到的这样的一个比率,那么这个呢就叫做命中率。命中率怎么来计算呢?很简单,你根据定义就可以得到它的公式。如果在一个程序执行期间,我们Cache的总的命中次数为Nc,而访问主存的总次数为Nm,那么也就是说我们有Nc个能够在Cache当中找到,而有Nm中没能在Cache当中找到,还要到主存当中去找。所以我们的命中率应该是Nc/(Nc+Nm)。Nc+Nm就是总共访问的次数。而Nc呢就是说它能够在Cache当中找到的这个次数,那命中率就是说在Cache当中的比率占整个的一个比率,所以这就叫做命中率。那么命中率和什么有关呢?我们来想一下。它肯定是和容量和块长有关的。为什么呢?如果我们的Cache的容量足够大,大到和我们的主存一样大。那么我们想要访问一个信息的话,除了第一次我们需要从主存当中把信息调到我们Cache当中以外,之后我们每一次信息都能在Cache当中找到。因为主存的容量是和Cache的容量是一样大的,所以它的命中率就接近100%。除了第一次你要从主存当中去把它调进来之外,其他每一次都能在Cache当中找到,所以它的命中率是非常高的。所以第一个,它和它的容量是关系的。那么还有一个呢,是和它的块长有关系的。如果我们的块长过小,我们一个块取到我们的Cache当中之后,我们没有执行几条指令之后,这个块内的信息呢就已经完全被用光了。我们还要再到主存当中去找,去读。所以,我们还要从主存当中去读下一条信息。所以就没有能够充分地运用我们的局部性原理。所以如果块长过小的话,没有能够充分利用我们的局部性原理的,所以我们的命中率我们的效率也就大大地降低了。而如果我们的块长过大的话,我们知道我们的容量有限的,我们块长过大的话,所以我们的块数就比较小。我们的块数比较小的话,我们一个块长它很大,它只有部分的信息它是有用的,只有一点点信息是有用的。我们要读其他的信息的时候同样去到主存当中去读,读一些块,所以如果块长过大或者过小的话,都会对这个命中率带来一定的影响。所以我们的命中率和Cache的容量、和Cache的块长都是有关系的。那么一般来说我们的每一个块呢是取4~8个字的,那么这个块长呢是取一个存储周期内从主存当中调出的信息长度,啊就是这个样子。也就是要为了能够完全利用我们的Cache,为了完全能够提高我们的访存速度,所以呢我们要提高我们的命中率,我们的容量、我们的块长都有一定的限制。啊,这就是我们整个Cache它的原理以及命中率和不命中率的一个概念还有我们的局部性原理,大家做一个简单的了解就可以了。

那么上一节我们已经讲到了命中率它的计算。那么呢我们就要根据我们的命中率来进行一个性能的分析,并且呢我们来看一道例题。
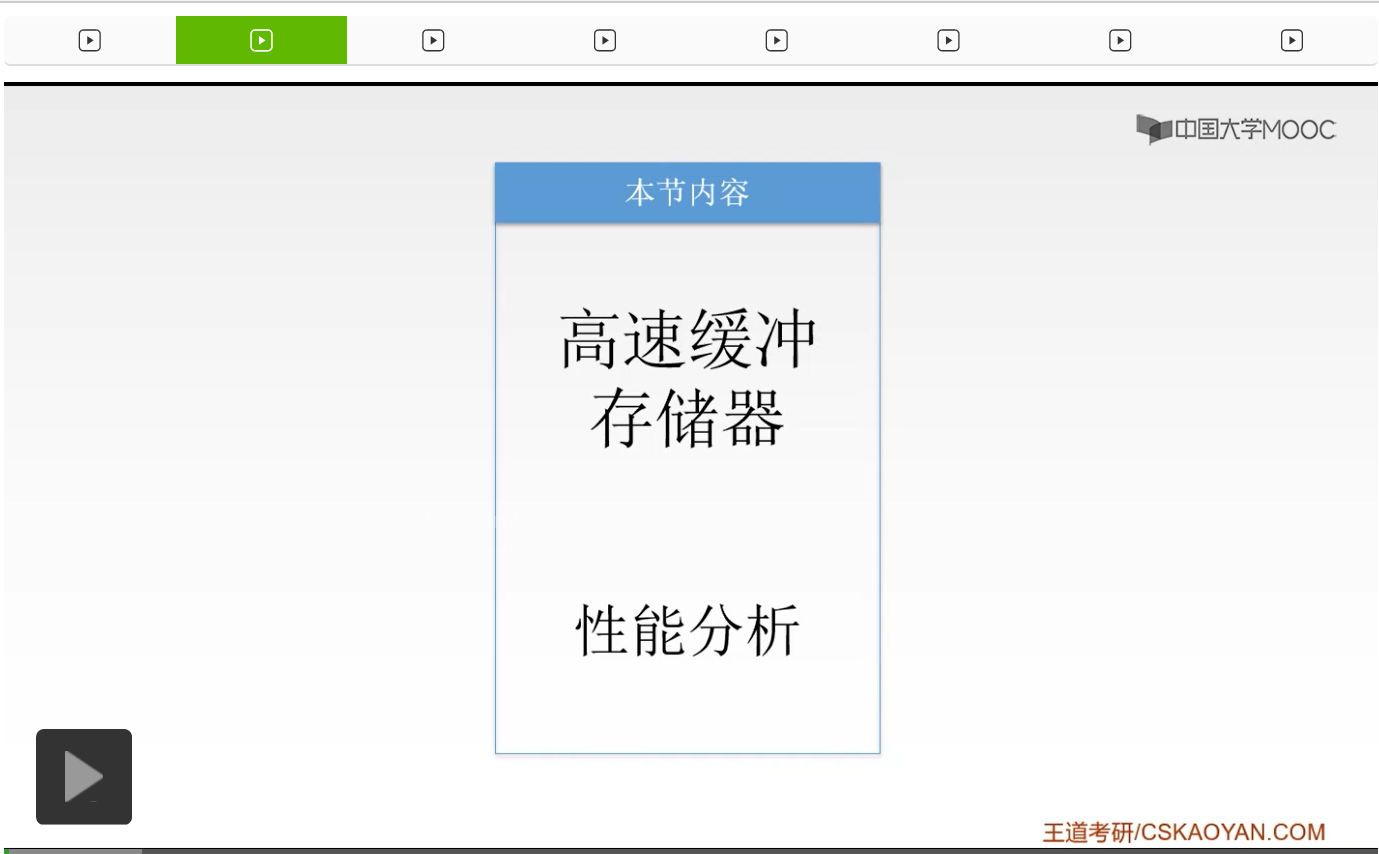
那么Cache和主存的这样的一个系统的效率我们用e来表示,效率呢,它显然是和命中率是有关的,它是如何来计算的呢?它的计算公式等于访问Cache的时间除以平均的一个访问时间。那么平均的访问时间是如何来计算的呢?这个大家一定要加以重视。这是考试当中很容易出到的一道题,那么呢我来给大家讲一下这个平均的访问时间是如何来计算的。我们之前已经讲过了Cache的命中率,我们把它设为h。那么如果我们访问Cache的时间它等于tc,而访问主存的时间呢是tm。那么我们的整个的平均的一个访问时间,就相当于是一个加权平均,是如何来计算的呢?是用一个命中率乘以访问Cache的时间,加上不命中率乘以访问主存的时间,那么也就是用h*tc+(1-h)*tm。前者是说我们访问Cache的时间,乘以我们访问Cache的一个相当于一个概率吧。命中率我们之前已经讲过了,它是说我们CPU想要访问的信息已经在Cache当中它的一个比率,所以它就相当于一个概率,所以要命中率乘以访问Cache的时间。那么1-h呢,1-h就相当于一个不命中率,就是我想访问的东西不在Cache当中我还要到主存当中去找,所以就用1-h乘以我们访问主存的时间tm,所以它的一个平均访问时间就等于h*tc+(1-h)*tm。那么我们的效率e就等于访问Cache的时间tc去除以我们的平均时间ta,我们就用ta来表示。所以ta就应该等于h*tc+(1-h)*tm。那么这就是一个效率。那么我们来思考一下,它的最小值是多少。最小值我们想一下,什么时候它才能最小?也就是说我们的命中率是0的时候它肯定是最小。也就是说我们要访问的东西在Cache当中都没有,我们都必须要到主存当中去访问,所以它的命中率是0。那么命中率是0的时候,效率呢就应该等于tc除以tm,也就是用访问Cache的时间去除以访问主存的时间,因为我们都要去访问主存嘛,命中率是0,它都要到主存当中去访问。所以它的最小值,应该是tc/tm。那么它的最大值是多少呢,最大值就是说我们的命中率是1的时候,也就是说我们想要访问的东西都在Cache当中,我们每要每访问一次它都是访问的Cache,所以如果命中率是1的时候,那么它的效率应该是最高的,所以它的最大值呢e也等于1,啊这就是它的最小值和最大值是如何计算的。但是要值得注意的是,我们这里的计算,是怎么来计算的呢?是一种并行的方式来计算的。也就是说我们在访问Cache的时候,同时去访问主存。大家思考一下,如果我们不是这样用并行的方式来访问的话,如果我们是先访问Cache,然后Cache不命中了,我们再去访问主存,那么这个公式该做出如何的变化呢?
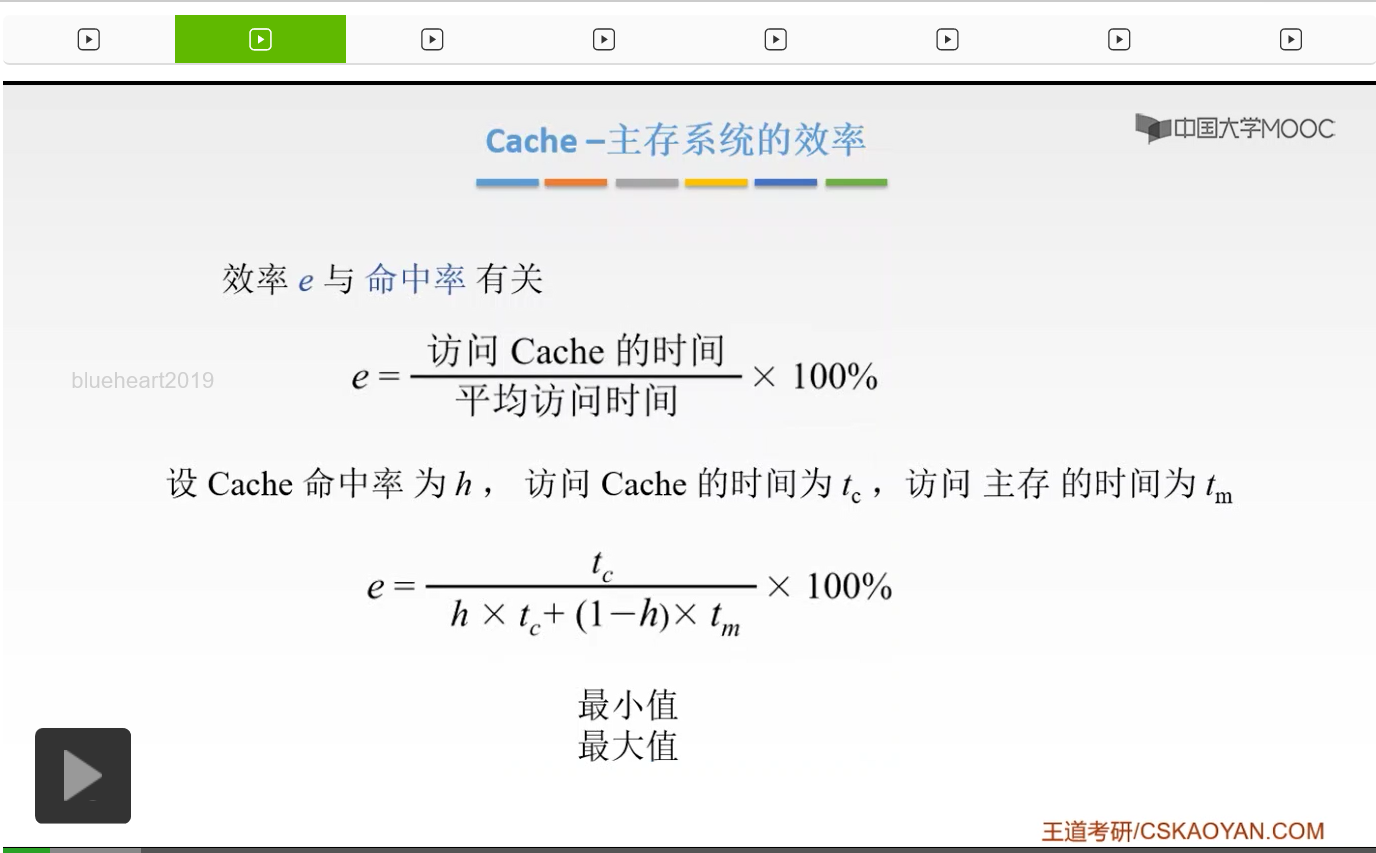
我们来看一道例题。假设我们Cache的速度是主存的5倍,并且我们的Cache的命中率是95%。如果采用Cache之后,我们存储器的性能能提高多少?那么我们就以第一种方式是,我们假设Cache和主存是同时被访问的,那么这个虽然你看的是它说我们的存储器的性能提高了多少,那么还是要求我们去计算它的一个访问时间,那么如何来计算呢?
我们假设我们Cache的存储周期是t,那么由于我们Cache的速度是主存的5倍,所以我们主存的存储周期应该是5t。这个大家要明白,速度和时间是成一个反比的。也就是说我们的速度是主存的5倍,所以我们主存的存储周期应该是Cache的5倍。所以如果假设我们Cache的存储周期是t的话,主存的存储周期呢应该是5t。接着我们来看一下我们的平均时间是多少?那么,如果我们的Cache和主存是同时被访问的,那么不命中的时间呢,访问时间就是访问我们主存的时间,就是5t,也就是我们之前这个公式当中的tm。所以我们的平均访问时间呢,应该是用h*tc+(1-h)*tm,也就是用0.95*t+0.05*5t=1.2t。啊这个平均访问时间的公式大家一定要记住。只有我们的命中率乘以访问Cache的时间加上不命中率乘以访问主存的时间,所以剩下的应该是1.2t。那么如果我们每个周期可以存取的数据量是S,那么我们的存储系统带宽呢应该用我们的数据量除以平均访问的时间,所以用S除以1.2t。那么如果我们不采用Cache的时候,也就是说我们去访问主存,那么它的这个带宽应该是S/5t。5t就是访问主存的时间嘛,所以如果不采用Cache的时候,带宽是S/5t。所以性能应该用S/1.2t/S/5t,这时候等于4.17,性能变为原来的4.17倍,所以我们提高了3.17倍。啊,这是我们同时访问的这样的一个时间,这样的一个性能。我们直接用主存的时间,用5t除以平均时间1.2t就可以得到。
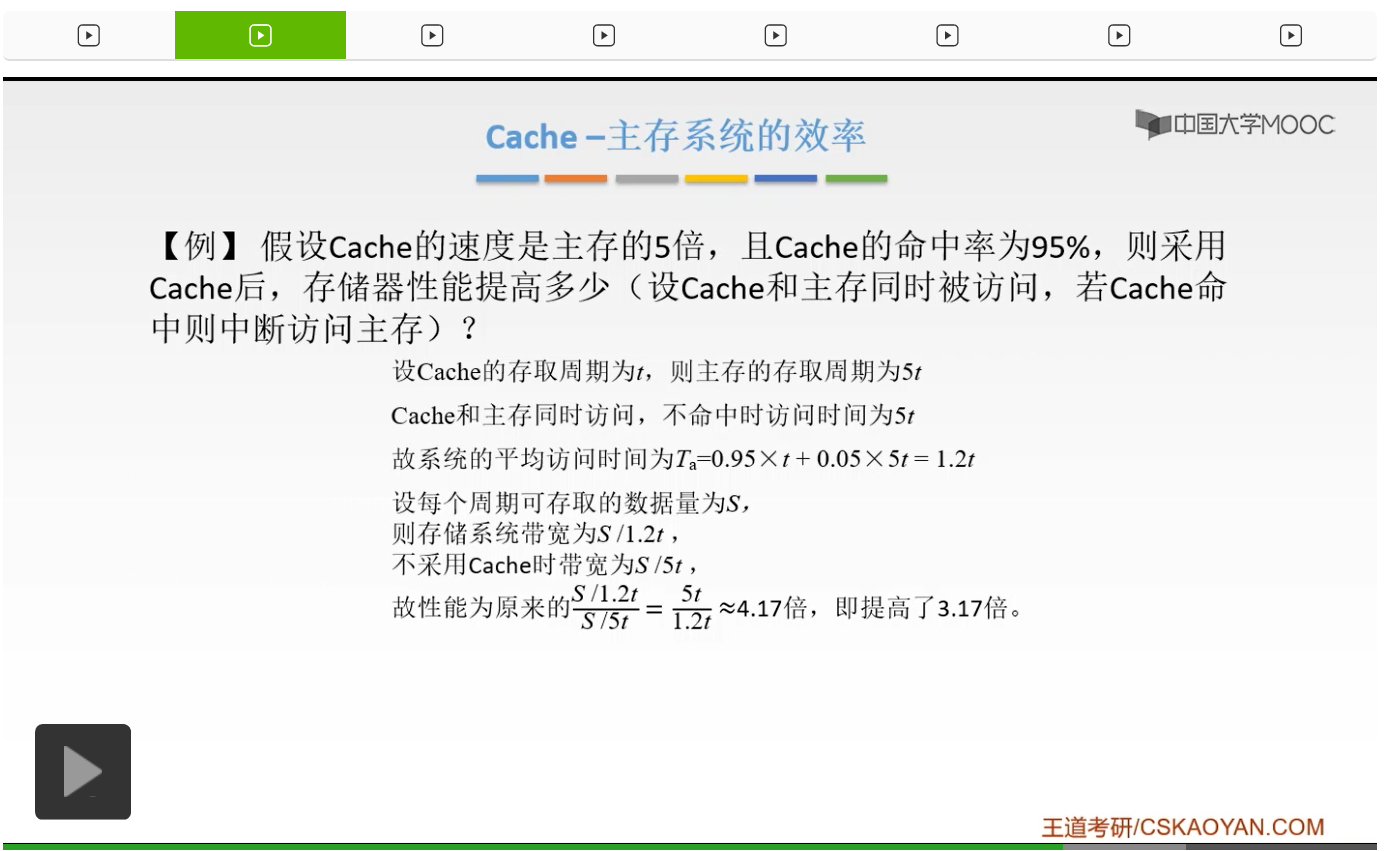
那么如果我们是这样的,先访问Cache,再访问主存,那么应该如何来计算呢?那么其实很简单,我们只要换一个角度思考一下就行了。如果先访问Cache,再访问主存,我们Cache它的存储时间是t,而我们的主存是5t。如果先访问Cache,然后再访问主存,这时候我们不命中的时候它的时间应该是多少呢。你先访问的Cache,再访问主存,所以应该用t+5t应该是6t。
所以这时候啊,不命中的时候,访问Cache的耗时是t。然后不命中的时候再去访问主存,它又耗时5t,所以整个的耗时呢就是6t。
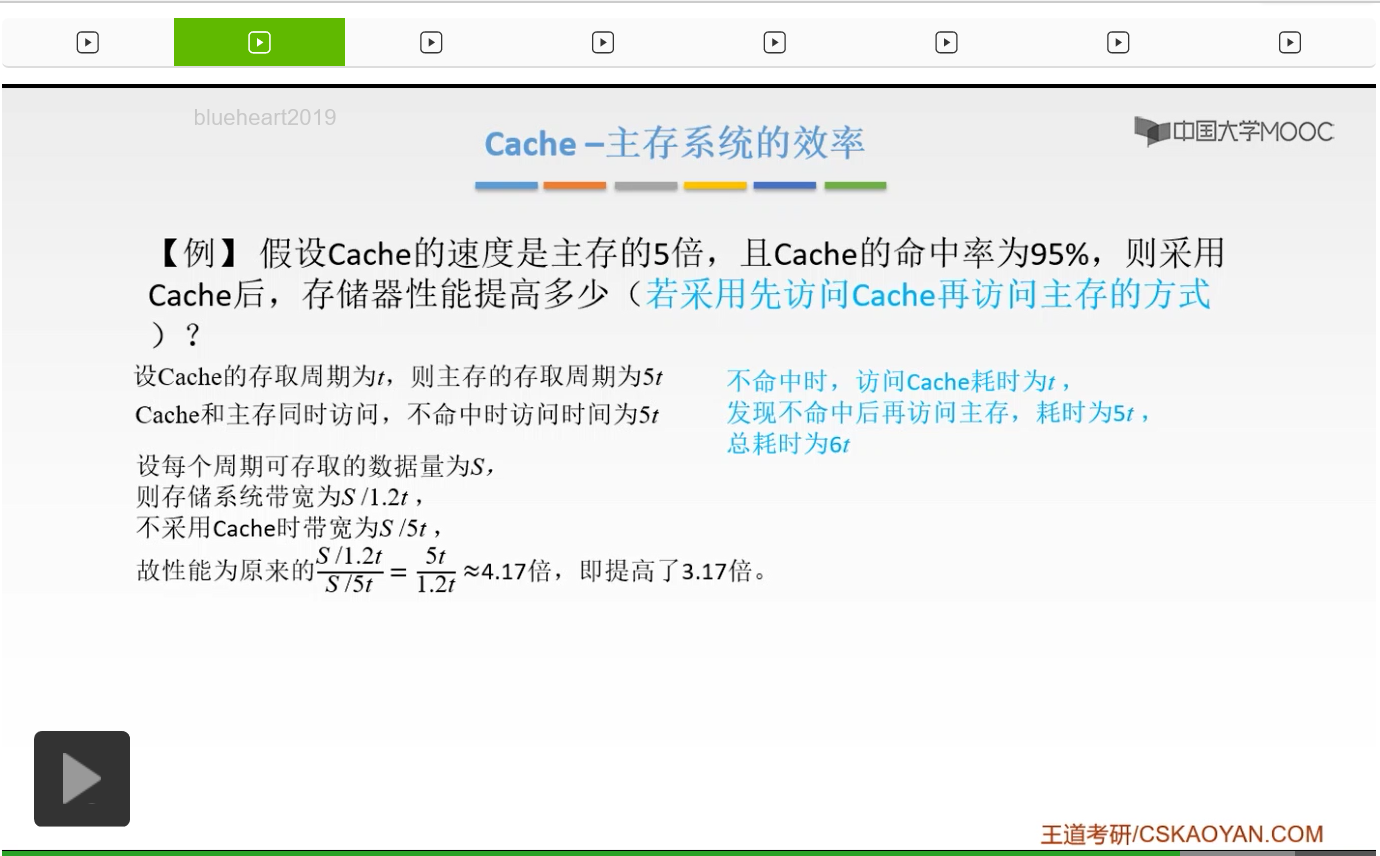
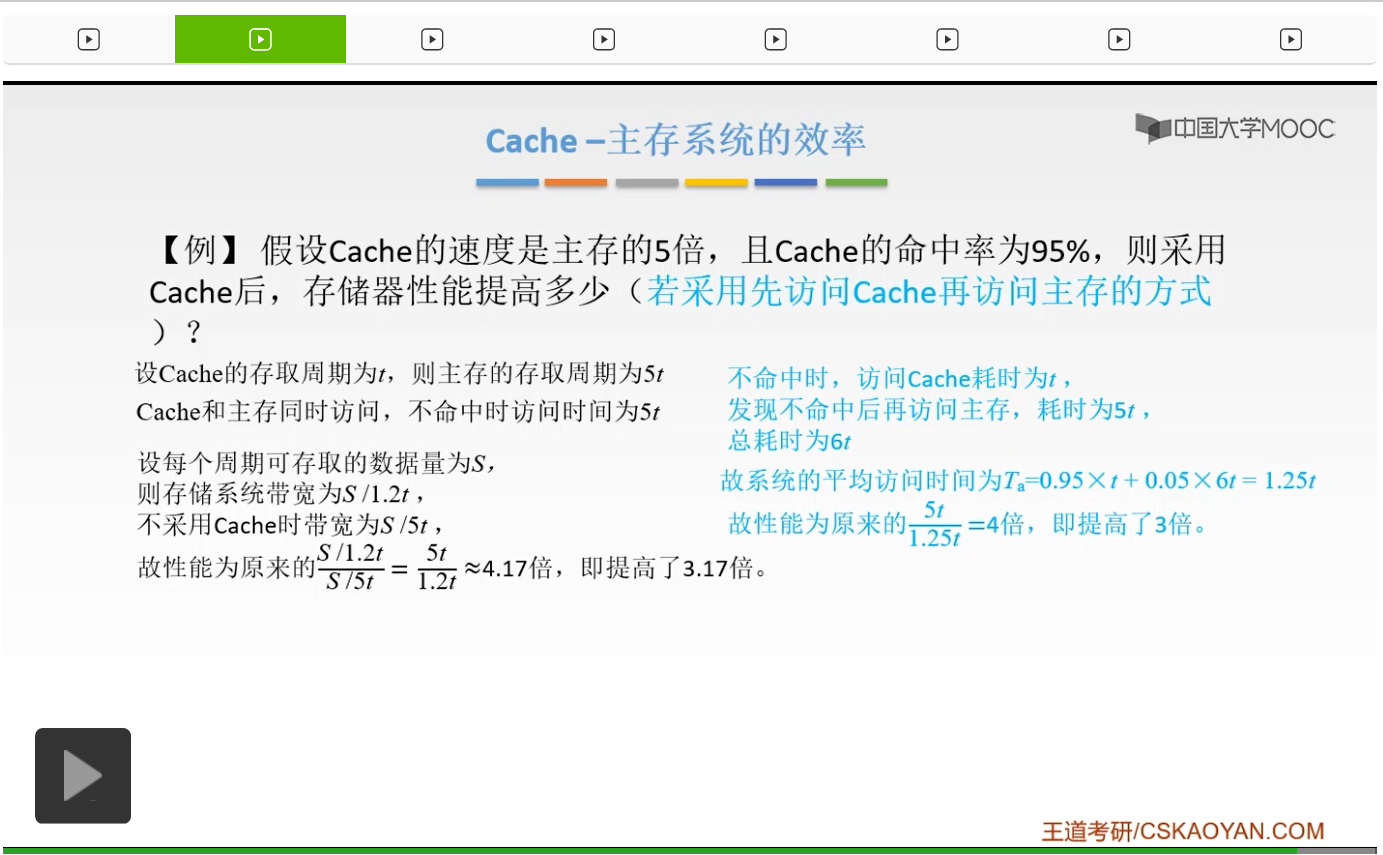
所以这时候就把后面一项改一下就可以了。所以这时候我们的平均访问时间呢,0.95*t+0.05*,后面这时候要把5t变成6t,这时候就是1.25t。这时候呢我们的性能变成了原来的4倍,所以就提高了3倍。啊这时候大家要注意一下,这个时候变的是什么呢?变的应该是我们后面那部分,也就是访问主存的时间变了。访问主存的时间要加上一个访问Cache的时间。因为你先去访问了Cache,再去访问了主存,所以这时候就要用1t+5t等于6t。所以这时候呢这个公式大家应该都记住了,大家应该也都会使用了。大家一定要把这个公式牢记。
好的,我们整个的这样的一个概述我们就已经讲完了。我们讲了局部性原理,空间局部性原理和时间局部性原理,然后还有一个性能的分析,也就是我们的命中率和我们的失效率,失效率就是不命中,就是1-h。然后我们的平均访问时间大家应该都会计算了。然后我们的这个一个效率e应该等于tc/ta。好的,这就是我们整个的一个概述的部分。
那么这一节我们来看一下Cache的基本工作原理。
我们的Cache啊它是位于存储器层次结构的一个顶层,通常呢是由一个静态的RAM来构成的。那么这就是这张图就给出了我们的Cache的基本结构,那么它呢和主存被分为若干大小相等的一个块,我们之前也已经讲过了,它交换数据的一个基本单位就是以块来进行交换的。它的每一块呢是由若干个字节来组成的。块的长度呢就被称为块长。我们的Cache的容量是要远远小于我们主存的容量的。所以我们的Cache的块数,就要远远小于主存的块数的。那么呢它仅保存我们主存当中最活跃的若干块的一个副本。所以呢我们的Cache要按照一些策略来预测我们CPU在未来一段时间想要访问的数据,然后把它装入到Cache当中。如果我们的CPU发出读请求的时候,如果命中了,命中的话,这时候我们就把这样的一个地址,转化为我们Cache的地址,直接对我们的Cache进行一个读操作,我们就不去访问主存了。那么如果Cache不命中的话,我们还要去访问主存。那么呢并且把我们想要访问的这个字所在的块,一次性地从主存当中调入到Cache当中。如果这时候Cache已经满了,那么就要根据一些替换算法用这个块去代替我们Cache当中原来的一些块。那么这个替换算法呢我们将要在后面的课程当中,来给大家详细地讲解。那么当CPU发出一个写请求的时候,如果我们的Cache命中,就有可能遇到我们Cache和主存当中的内容不一致。你比如说我们CPU写了Cache,那么我们Cache的一个单元就从,它的内容啊就从某一个值变成了某一个值。那么如果我们主存的这样的对应单元的内容,它还是原来的这样的值,没有改变的话,就会产生一个错误。所以呢如果我们的Cache命中的话,就需要按照一定的写策略进行处理。那么我们的写策略呢也要在我们后面当中进行讲解。常见的一些方法呢有写直达法和我们的写回法。啊,这就是我们Cache的一个工作的原理。
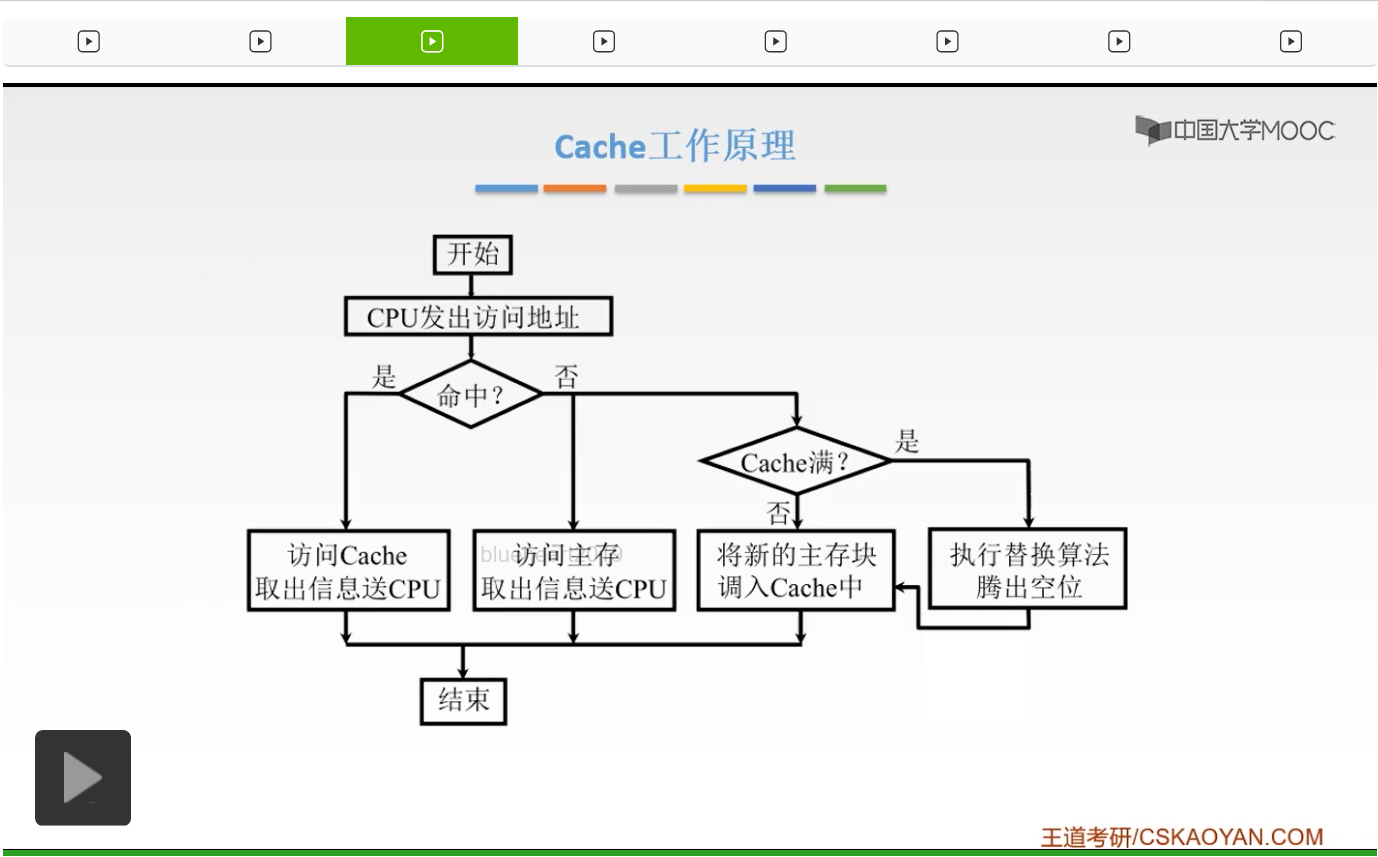
那么我们再来看一下,这是当Cache要读的时候,我们CPU先发出一个访存的地址,看它有没有命中,如果命中的话,我们呢直接就从Cache当中取出信息给CPU。如果没有命中的话,我们将要去访问主存,然后呢从主存当中取出信息放送到CPU当中。并且呢,还要把主存当中的信息呢,写到我们Cache当中。如果Cache满了的话,我们将用一些替换算法去腾出一个空位来进行替换。如果没有满,直接把我们的主存的块调入我们Cache当中就可以了。啊这就是我们Cache整个的一个工作原理。
好的,那么我们来看一下高速缓冲存储器的地址映射方式,这是本节当中最重要的一部分,大家一定要加以重视。
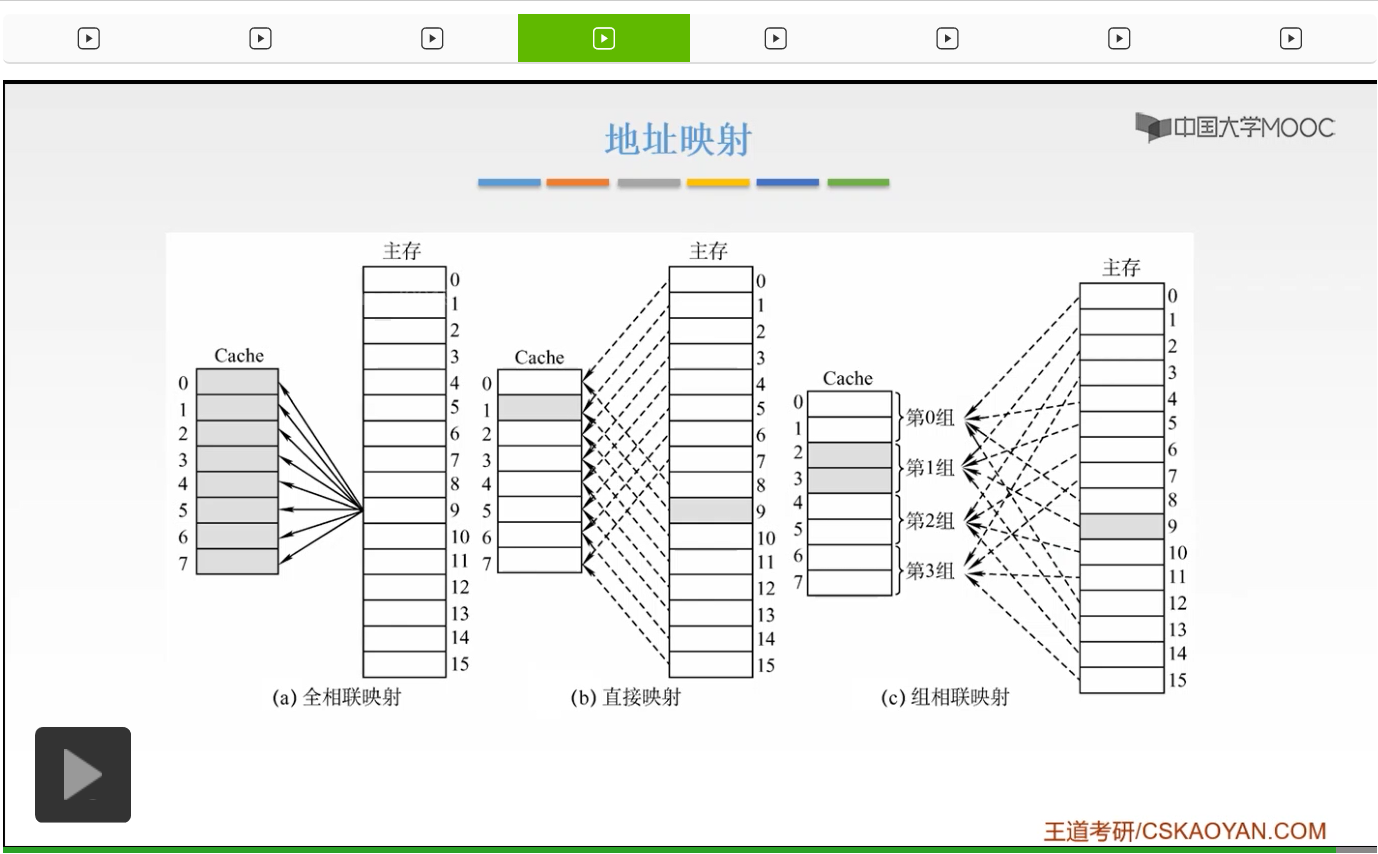
那我们上一节课已经讲过了,Cache的基本工作原理,那么主要有三点,第一点就是说我们的主存中的块应该放到Cache当中的哪一个位置。那我们就提出了三种方法,像第一种方法呢就叫做空位随意法,你只要有空位我就把你放进去。我们的主存的数据块可以放到Cache当中的任何一个位置,那么呢这就叫做全相联映射。那么第二种呢就是说我必须对号入座,我的主存的数据块只能放到Cache当中的唯一的一个位置。那么这个叫做直接映射。第三种方法呢就是按号分组,组内我可以随便放。那么这个叫做组相联映射。那么这就是我们地址映射的三种方式。
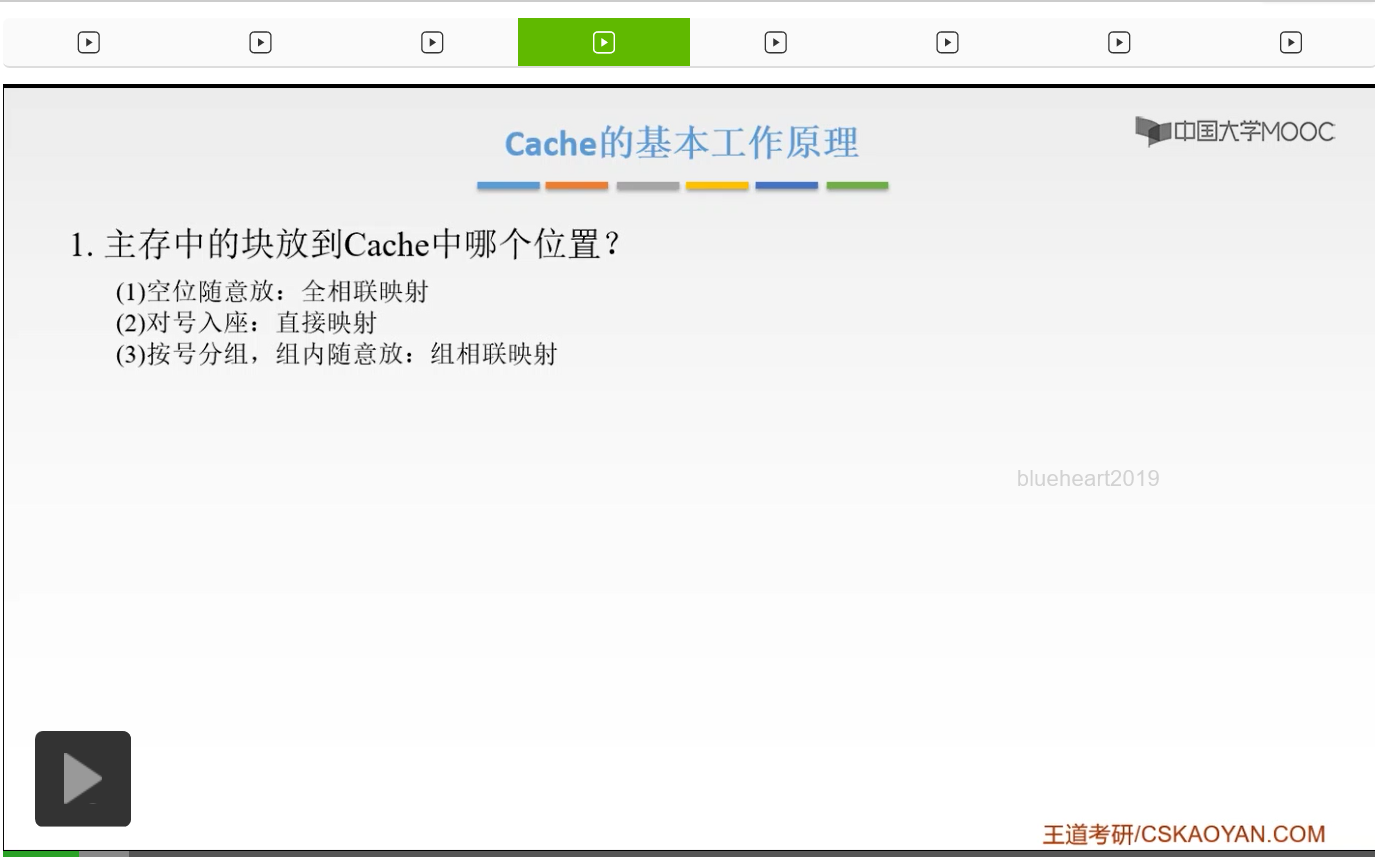
那么第二个问题就是说,我们的Cache块如果满了,应该如何处理?或者说我们的对应位置如果被占用了,我们应该如何处理。那我们就提出了,几种替换算法。那么有随机的,还有叫做先进先出,或者叫做最近最少使用,还有一个叫做最不经常使用的这些算法。
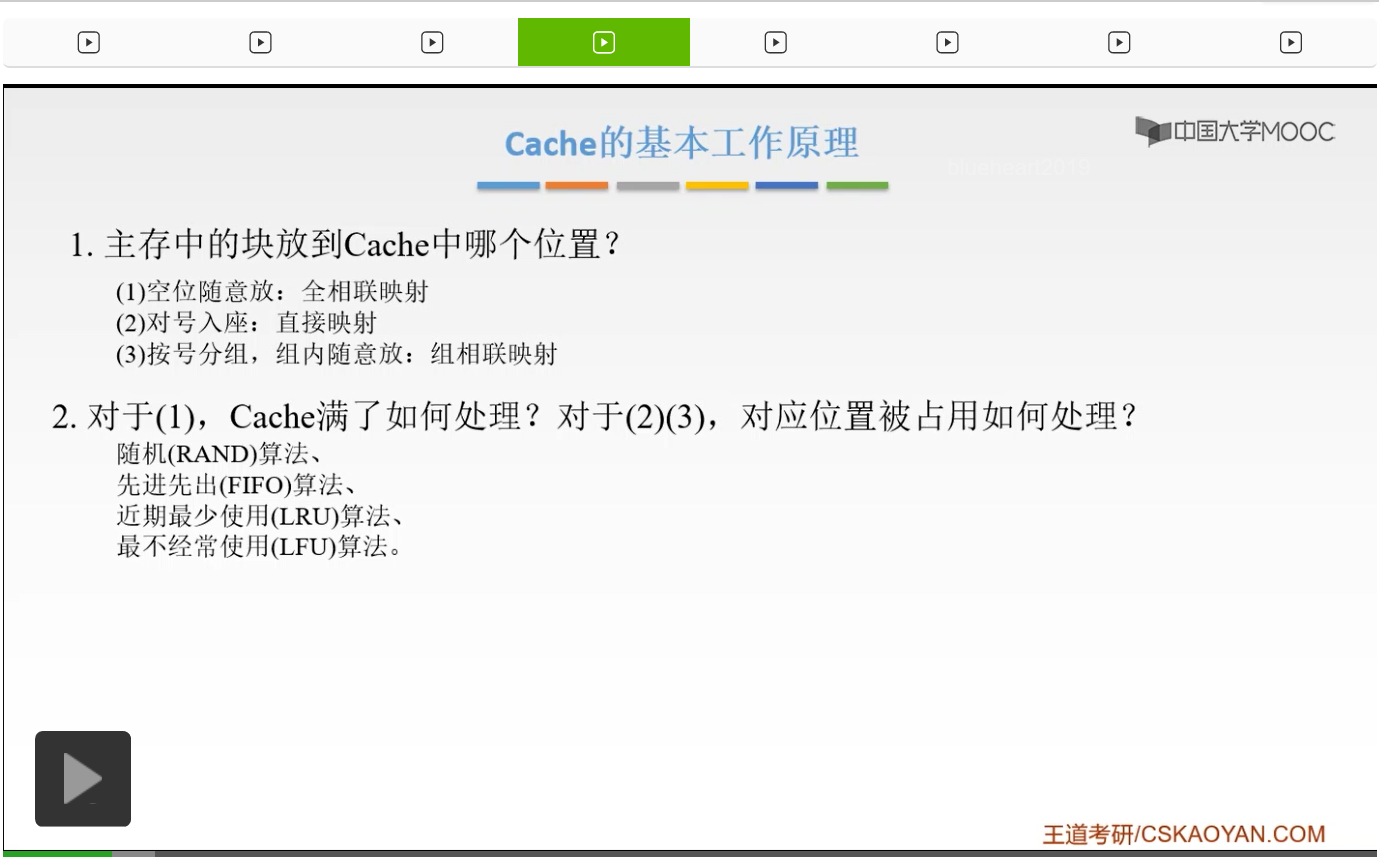
那么第三个就是说,如果我修改了Cache当中的内容之后,我如何保持和主存当中相应内容的一致性。那么如果命中了,我们有全写法和写回法。如果有不命中的话,我们有写分配法和非写分配法。那么这就是我们接下来的课程将要学习的内容。好的,我们这一节课将要讲解的呢就是我们的地址空间映射。那么什么叫做地址映射呢?地址映射就是说我们把主存的地址空间,映射到Cache当中的地址空间。或者就是说,我们把存放在主存当中的这个程序,我要按照某一种规则我要装入到Cache当中,如何进行装入?也就是说如果我们要把主存当中的任意一块,加载到我们Cache当中的话,我应该加载到Cache当中的哪一块当中。

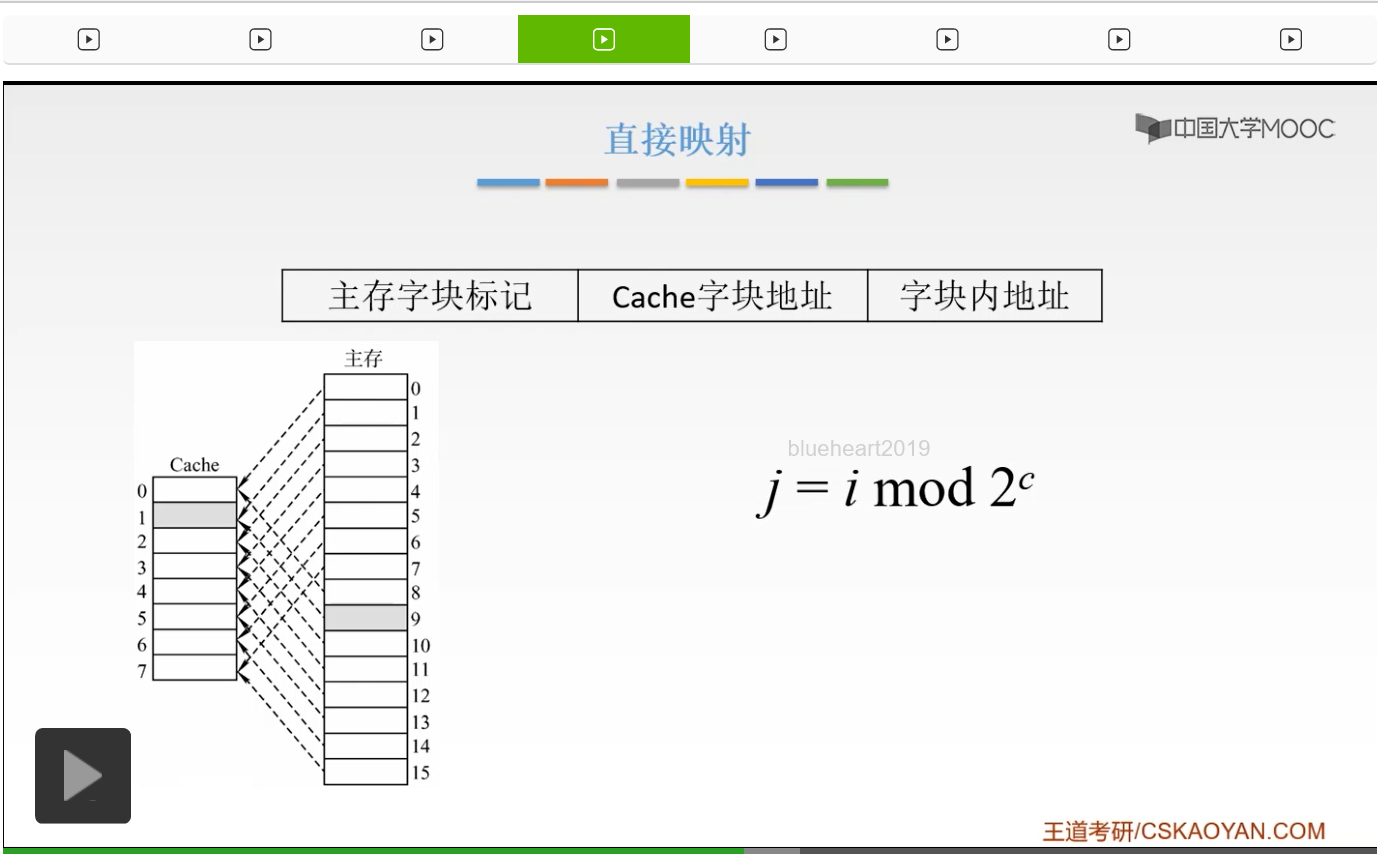
啊这就是我们这节课将要解决的问题。那么第一种方式呢叫做直接映射。直接映射就是说我们的主存当中的数据块,只能够装入到Cache当中的唯一一个位置。也就是说某一个指定位置的Cache块当中,主存当中,我只能装入到Cache当中的唯一一个区,某一个指定的一个区。那如何来装入呢?我们来看一下。也就是说我们以Cache它的存储体作为一个尺子,我去度量主存这样的一个主存储体,也就是说我们把主存储体划分为若干个和Cache存储体相等的一个区,就是我们把主存体划分为若干个区,每一个区它的大小和Cache是相等的。然后,我们每一个区当中,它的字块数,也是相等的,是0到2^c-1,占2^c个块。我们的每一个区当中的某一号单元,只能映射到我们Cache当中的某一个指定的位置。比如说我们第一个区当中的零号单元,只能放到我们的Cache的字块0这个位置。我们的第二个区当中的零号单元,也只能放到我们Cache当中的零号单元这个位置,啊就相当于这个当中。那么这就非常好容易理解了,就相当于我们把主存划分为若干个和Cache大小相等的这样的一个区。我们每一个区的某一块单元,只能放到我们Cache当中指定的那一块当中,就像图中所给的这样,我们把主存划分为n个这样的和Cache相等的区域。第一个区的字块0只能映射到我们Cache的字块0当中。我们第二个区的字块0,就是2^c这个,也只能映射到我们的Cache当中的字块0当中。同样我们的2的c+1次方,也只能映射到我们字块0当中。啊就是唯一的一个区域,唯一的一个位置。那么我们主存地址的高m位,就被划分为两个部分,我们的第c位是指Cache的字块地址。我们的高t位,这个t呢就等于m-c,它是指主存的字块标记。它是用来干什么的呢?它被记录在建立了对应关系的缓存位的标记位当中。我们当缓存接到我们CPU接来的一个主存地址之后,我们只需要根据中间的c位,找到我们Cache字块,然后根据我们的这个字块的标记,是否与主存的高t位相符,我们进行一个判断。如果相符,并且有效位是有效的,那么就表示这个Cache块已经和我们的主存的某一块地址建立了一个对应关系。那我们就可以根据我们的b位地址从Cache当中取得信息。那么如果不符合的话,或者说我们的有效位它是不命中的,那么就要从主存当中读入我们新的字块来代替旧的字快,并且把这个信息送到CPU当中。所以我们的这个主存地址的t位和c位大家应该都知道是干什么的了。我们如果一接到我们CPU送到的主存地址之后,我们根据我们中间的这个c位啊来找到我们的Cache字块,然后呢再根据我们的这个标记啊,就我们找到这个Cache字块之后,我们再根据它这个标记和我们的主存的这个地址的前t位的这个标记是否相等,我们来判断是不是我们要的这个区域的字块。啊,就是这个样子。所以这就是直接映射,它的特点就是说我们的每一个缓存块i可以和我们的若干个主存块相对应。但是呢我们的每一个主存块,只能和一个缓存块相对应。啊,就是图中所给的这个样子。我们的蓝色区域,就是这样的。就是说我们的一个缓存块,我们可以跟若干个主存块相对应,但是呢我们一个主存块只能放到指定的一个Cache当中。
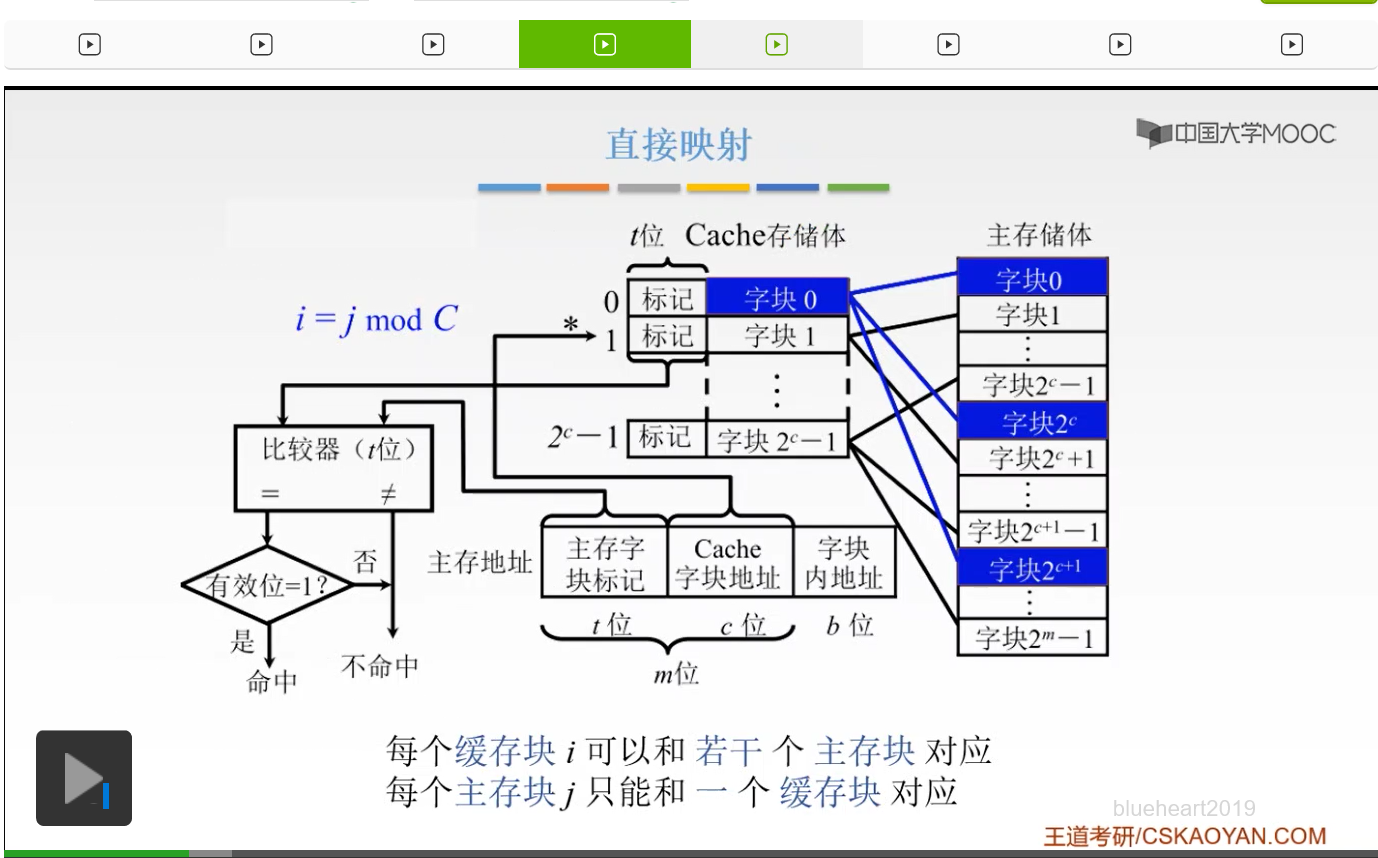
好的,所以呢,这就是直接映射。主存地址呢就被划分为三个部分,主存字块标记,Cache字块地址和我们的字块内地址。那么这就是一个示意图。那么它的这个直接的映射关系呢就可以直接定义为j=i mod 2^c。那么这个j是什么呢?j呢就是我们的Cache的块号,而i呢,是我们的主存的块号。2^c是什么东西呢?就是我们刚才Cache当中的总的块数。那么我们的主存的第0块,第2的c次方块,第2的c+1次方块只能映射到我们Cache的第0块。
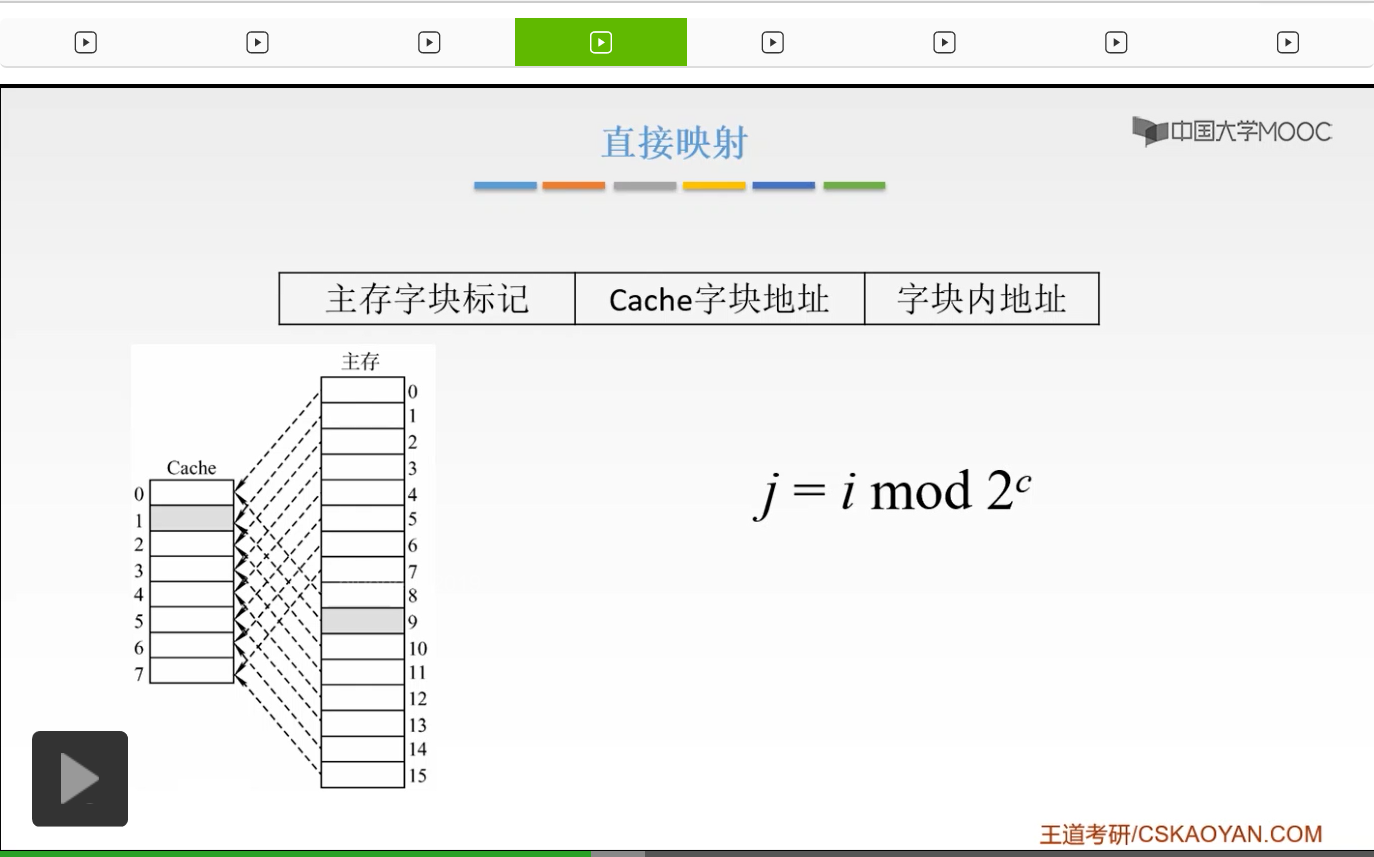
啊,刚才在这个图当中,我们已经看到了。我们的0,我们的2^c,我们的2^(c+1),都只能放到我们的Cache当中的第0块。
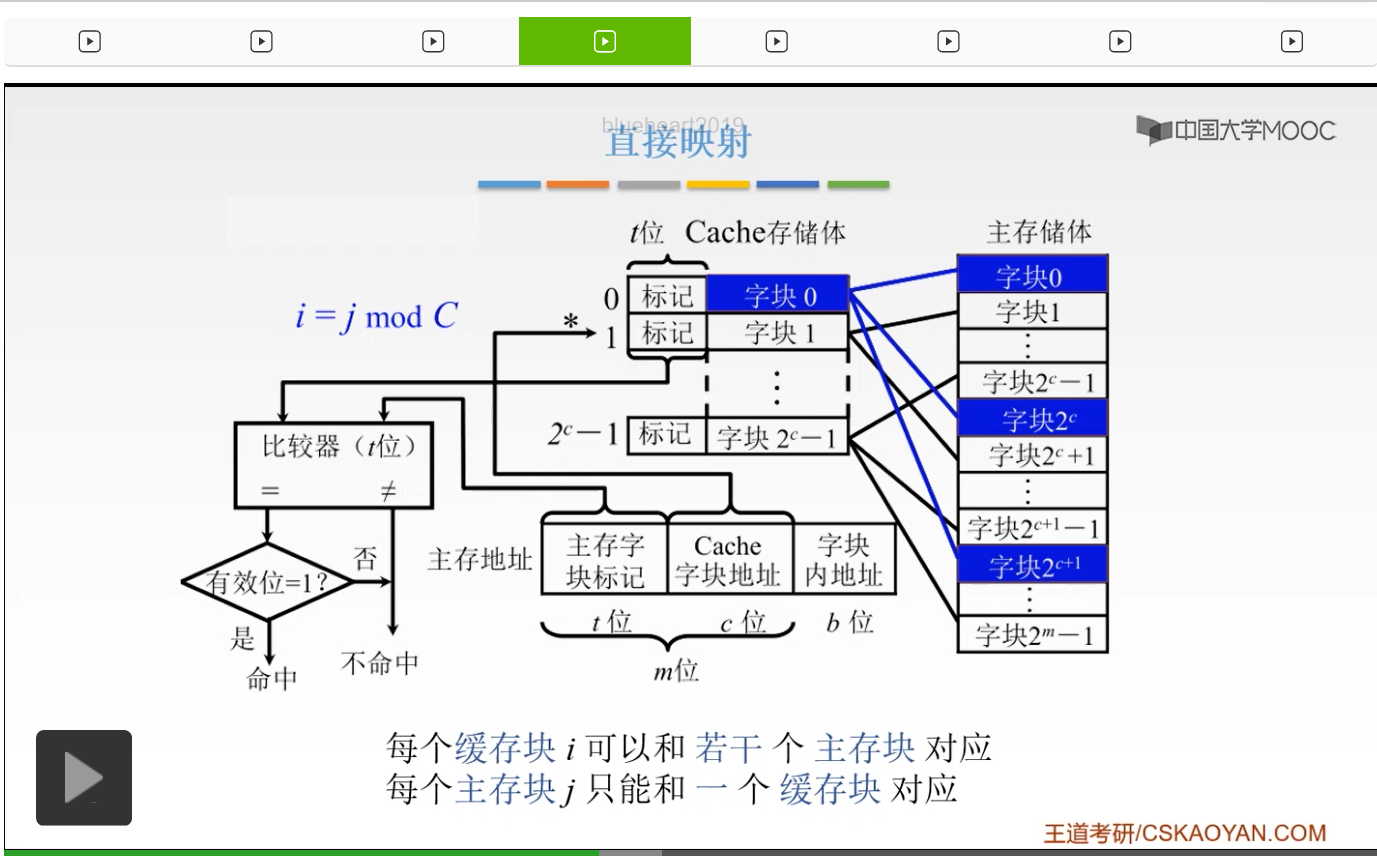
所以呢这就是我们的这个公式。好的,这就是我们的直接映射,它有什么特点呢?它的特点就是说,非常的简单,结构也简单,速度也很快。但是就是说,它不够灵活。发生冲突的概率也是最高的。为什么呢?就比如说我们现在要用到我们的主存的第0块,就是这个主存的0,它也只能映射到我们Cache当中的第0个对吧。我们假设现在Cache后面的这些都空了,只有这个第0个是跟主存的第0个是相映射的。现在我要用到我们的第2^c个这样的一个东西。我们现在Cache其他部分都空了,但是我们现在想要2^c的时候,因为它和主存的第0个它都只能映射到同一个位置,也就是Cache的第0号。这时候我就必须把这个主存的第0个替换掉,所以这时候就会发生冲突的概率,也就是说即使我们Cache有很多的空位,但是我也不能占用它,我必须还是只能用它。我们的每一个主存块只能固定地对应了我们某个缓存块。也就是说即使我们现在缓存块内还空着很多位置我现在也不能占用,所以呢我的缓存的存储空间就不能得到一个充分的利用。同时,我们如果现在我们的程序恰好又重复访问对应的同一缓存位置的不同的存储块,我们要重复访问这样的一个Cache的同一个位置。这样的同一个位置呢,它因为呢是对应着主存的不同的块,我现在就不停地要进行一个替换,所以呢就降低了我们的命中率,啊这就是我们直接映射的它的特点。
那么第二种方式,全相联映射,它走了另一个极端。我们刚才的直接映射是指,我们的主存的数据块只能装入到我们Cache当中的唯一一个位置。但是全相联映射跟它正好相反,就是说我们的主存的一个数据块我可以装入到Cache当中的任意一个位置当中。所以呢它就大大地提高了我们的利用率,空间利用率。也就是说你只要有空位置,我们的主存就可以放入到你这个空位当中,所以它的利用率是非常高的。但是就是说它的速度是非常慢的,为什么呢?因为我们的主存当中的一个数据块可以放到你任何一个位置,所以我现在有了一个主存地址。我的主存字块标记就要跟你那个标记,每一个标记进行一个比较。所以呢,这样的方式呢,所需要的逻辑电路就比较多,所以呢我们的电路比较复杂,因为我要和你的所有的块都进行一个比较。但是它是比较灵活的,命中率呢也就更高了,这和我们的直接相联是正好相反的。因为它可以放到你Cache当中的任意一块位置。所以呢和直接映射相比,它的主存的字块标记从t位变成了t+c位,所以呢我的标记位就增多了,并且呢你访问Cache的时候我的主存字块标记是要和我的Cache的全部的标记进行一个比较,你才能判断出我们的访问的主存地址的内容是否已经在这个Cache当中。所以这就是全相联映射的一个特点,大家把这个图记住就可以了。就是说我们的主存当中的任意一块都可以映射到我们缓存当中的任意一块,它是任意的。

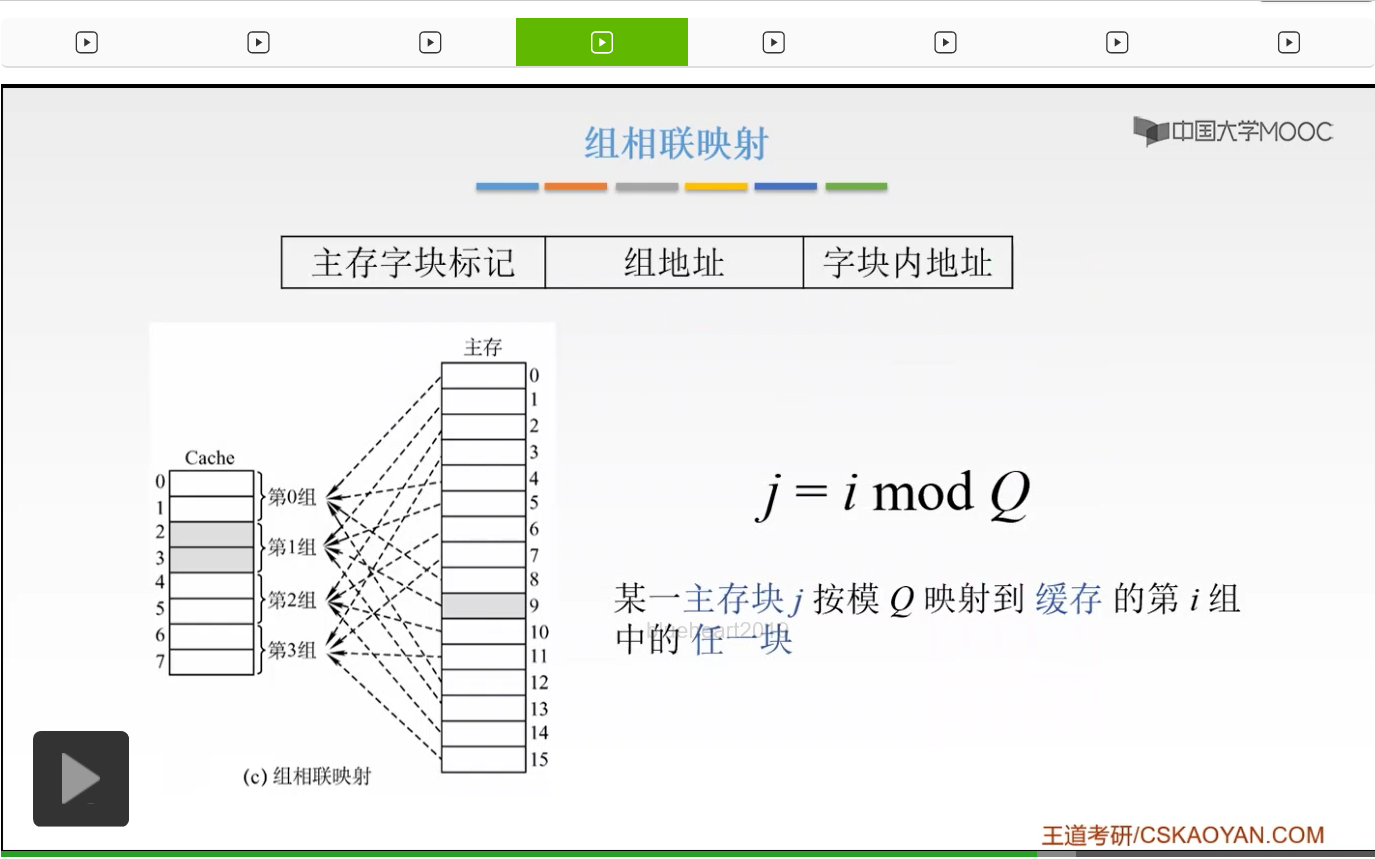
那么我们有没有一种折衷的方案呢?我们就提出了组相联的这样的一个映射。它呢是直接映射和全相联映射的一个折衷。它是怎么说呢?它是说先把我们的主存储器先划分为块,然后呢再把每一个块划分为组。也就是说,我们先把这个Cache地址啊分为大小相同的一些组,我们的每一个主存的一个数据块呢可以装入到一个组内的任何一个位置,那么这就是一个直接映射和全相联映射的一个折衷,也就是说我们的组间呢是采用一个直接映射,但是我们的组内是采用的全相联映射。也就是说我们先把这样的主存储器分区,然后区的大小呢和我们的组数,我们Cache的组数是相同的。我们有多少个组,我们就把主存储器呢划分为多少个区。然后我们的每一个区当中,我们的字块0它是放到我们的第0组。但是它可以放到我们第0组的任何一个位置,啊就是这样的。或者呢我们的字块的2^(c-r),它也可以放到第0组。但是呢这个第0组当中,它可以放到任意一个位置,那么它就是一个直接映射和我们的全相联的一个折衷。它必须放到固定的一个组当中,但是它的组当中呢是可以放到任何一个位置的,啊是这个样子。所以呢我们的主存地址就可以划分为三个部分,一个呢是叫做主存字块标记,然后呢是一个组地址,然后就是我们的字块内地址。
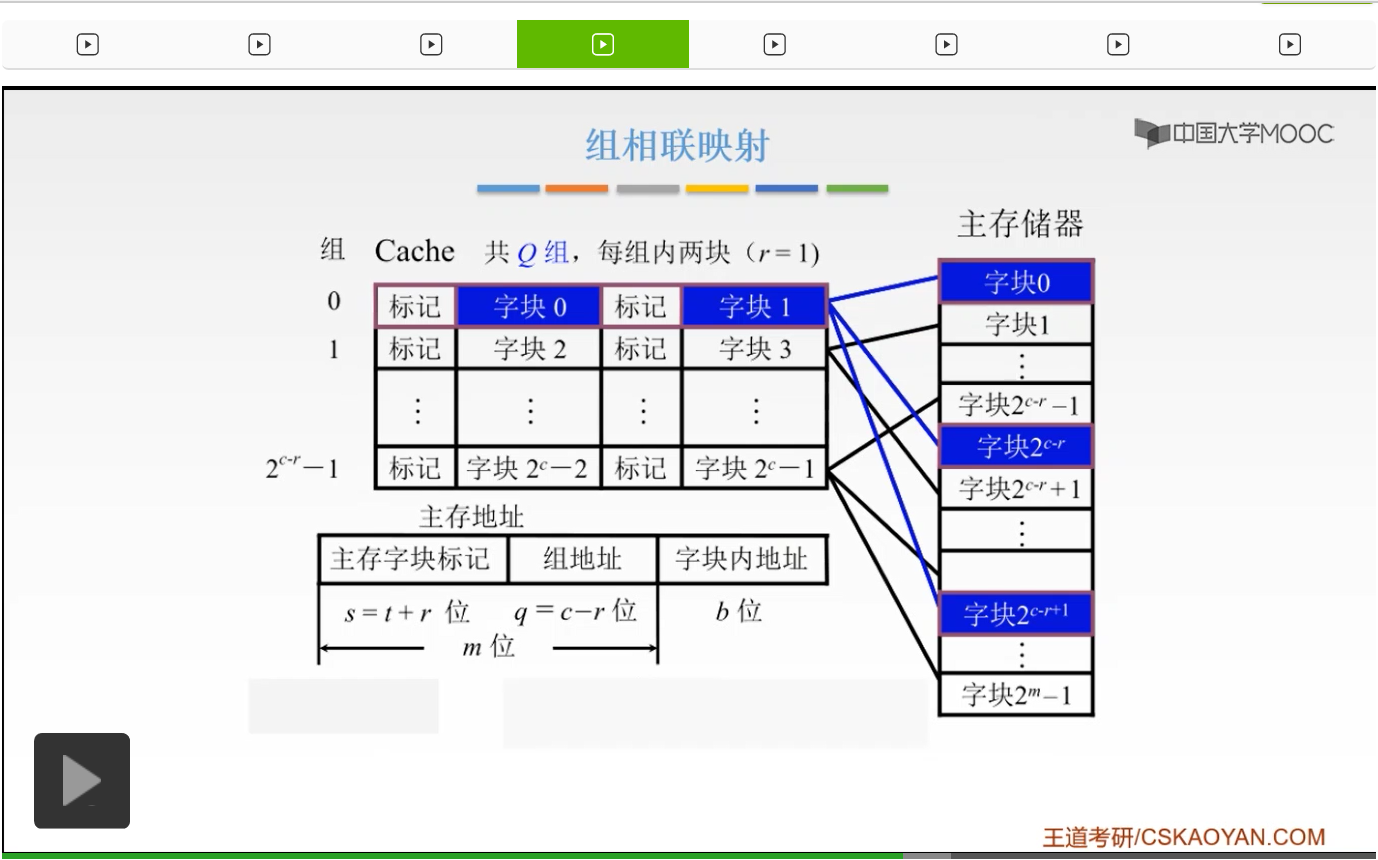
啊,就是这个样子。
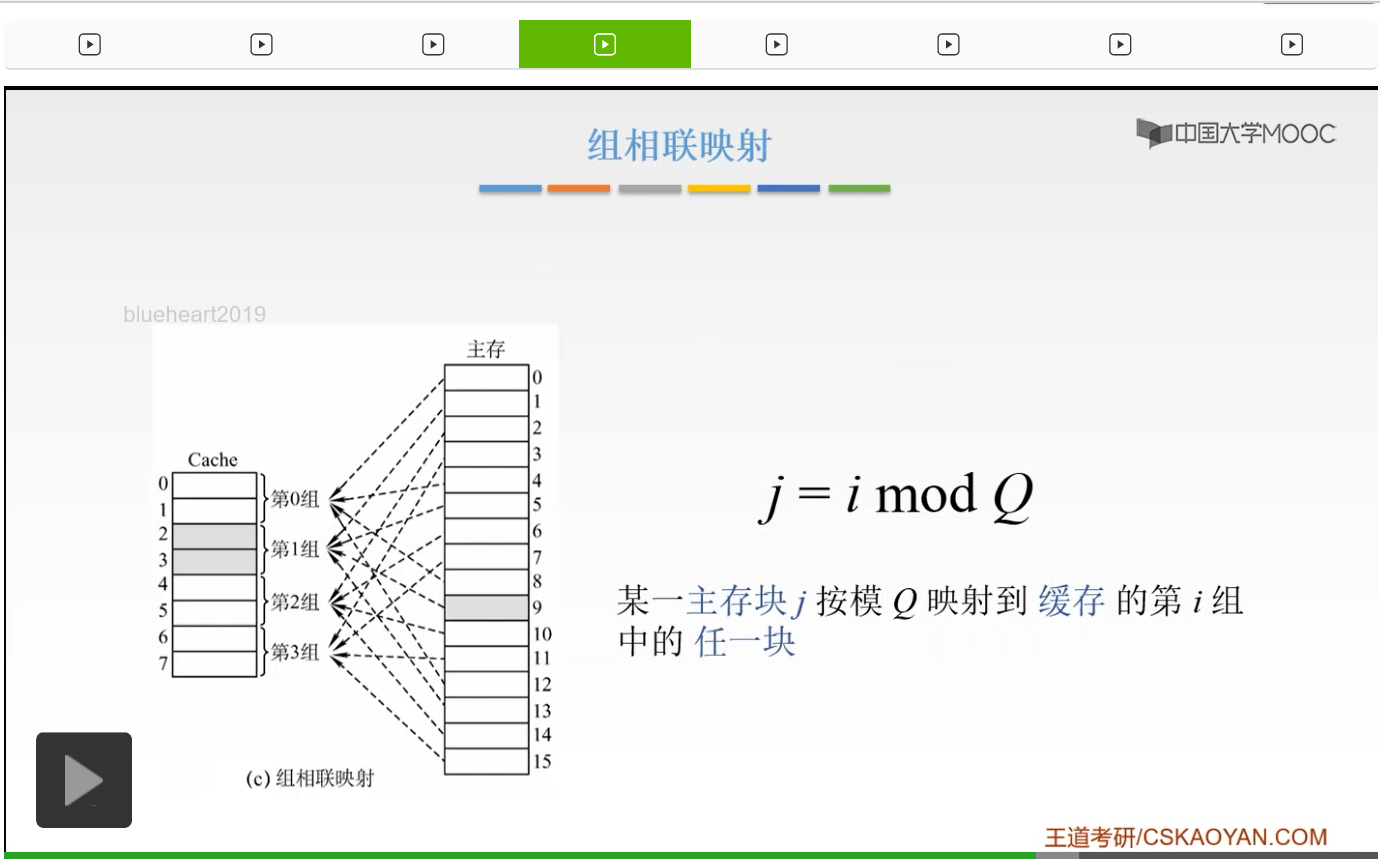
那么呢,我们的某一个主存块j我们可以按照模Q映射到我们缓存的第i组的任何一块。我们的这个Q是什么呢?Q就是我们的Cache的组数,啊组数。如果我们现在Q=1的话,也就只有一组,只有一组就变成了什么呀?就变成了全相联对吧,我们只有一组嘛,你可以放到一组当中的任何一个位置,不就是全相联嘛。那如果我们一组当中只有,每一组当中只有一块的话,那这就相当于一个直接映射了。因为只能我们每一组只有一块,所以我们的主存只能映射到唯一的这一块,所以这就是一个直接映射。所以呢组相联呢就是我们的直接映射和全相联的一个折衷。那么这个j就是我们的缓存的组号,而我们的i呢就是我们主存的块号。这时候进行比较的时候,我们只需要找到第i组,我们只要找到我们的第几组,然后在这几组当中进行一个比较,而不需要跟我们的所有的Cache当中的每一块进行比较,这就大大简化了我们的电路。那么如果我们的组内,每组有两块,就是我们图中给出的这个样子,那么这样的一个组相联映射呢我们把它称为二路组相联映射,二路组相联。那么我们来举一个简单的小例子吧,如果我们的主存的某一个字块按照模16进行映射,也就是说现在我们的Q=16,也就是说现在我们有16组,然后我们的主存的第0,第16,第32这样的字块呢,就可以映射到我们的第0组的两个字块当中的任意一个。而我们的主存的第15、31、47这些字块可以映射到我们第15组的任何一个字块,啊就是这样。所以我们的一堆块就会映射到我们的Cache当中的第i组之内,然后每一个组当中你可以选任何一个。那么这就是组相联映射,也是非常容易理解的。那么这呢就是把我们的直接映射和全相联进行了一个折衷,它呢电路实现起来呢比全相联映射要简单的多。因为我们的全相联要和我们的所有的Cache当中的所有的进行比较,而我们的组相联只需要跟每一组当中的所有的进行一个比较,这就大大简化了我们电路的设计,并且呢它的速度也是比较快的,所以呢我们一般来说组相联映射用的还是比较多的。那么如果在我们的多级的Cache当,多级的Cache的这样的一个体系当中,多级嘛,我们越靠近CPU,我们要求速度越快。所以这时候我们一般采用的呢就是直接映射,因为它速度比较快嘛。然后越往后呢,我们的速度要求不那么高的时候,我们就要可以用我们的组相联。它呢虽然没有直接映射它的速度快,但是它呢是比较容易接受的,比全相联电路要简单的多。所以呢如果越往后的这样的Cache多级存储,多级Cache的这样,如果到最后这样一级你就可以用全相联映射,因为它呢命中率比较高,虽然速度不快但是命中率比较高。而组相联呢就结合了它们两个的长处。
那么我们这一节呢就把我们的地址映射全部讲完了,全相联映射、直接映射和组相联映射,大家一定要搞清楚它们的这样的映射的算法,它的方式,并且呢它的特点,大家一定要掌握。然后我们的全相联就是说我们的任意一块,你也可以放到任意一块当中。所以呢它的命中率非常高,但是它的速度是很慢的。而我们的直接映射我们的主存当中的一块只能放到我们Cache当中的一块,也就是唯一的一块地址。也就是说我们主存当中的某一块地址,某一块数据,只能放到我们Cache当中的唯一一块当中。而组相联呢就是说我们主存当中的某一块你可以放到唯一的一组当中,但是这一组当中你可以放到任意一个位置。啊,这就是我们三个映射方式的它的特点。
那么上一讲呢我们已经把地址映射方式的这样的原理都给大家讲清楚了,我们总共有三种方式,直接映射、全相联映射和组相联映射。那么这节课呢我们来举一个例子让大家再加深一下我们的理解。
那么我们主存块,放到Cache当中的哪一个位置。如果是随意放的,那就是全相联映射。如果是对号入座的,那就是直接映射。如果是按号分组,然后组内随意放的,那这就是组相联映射。
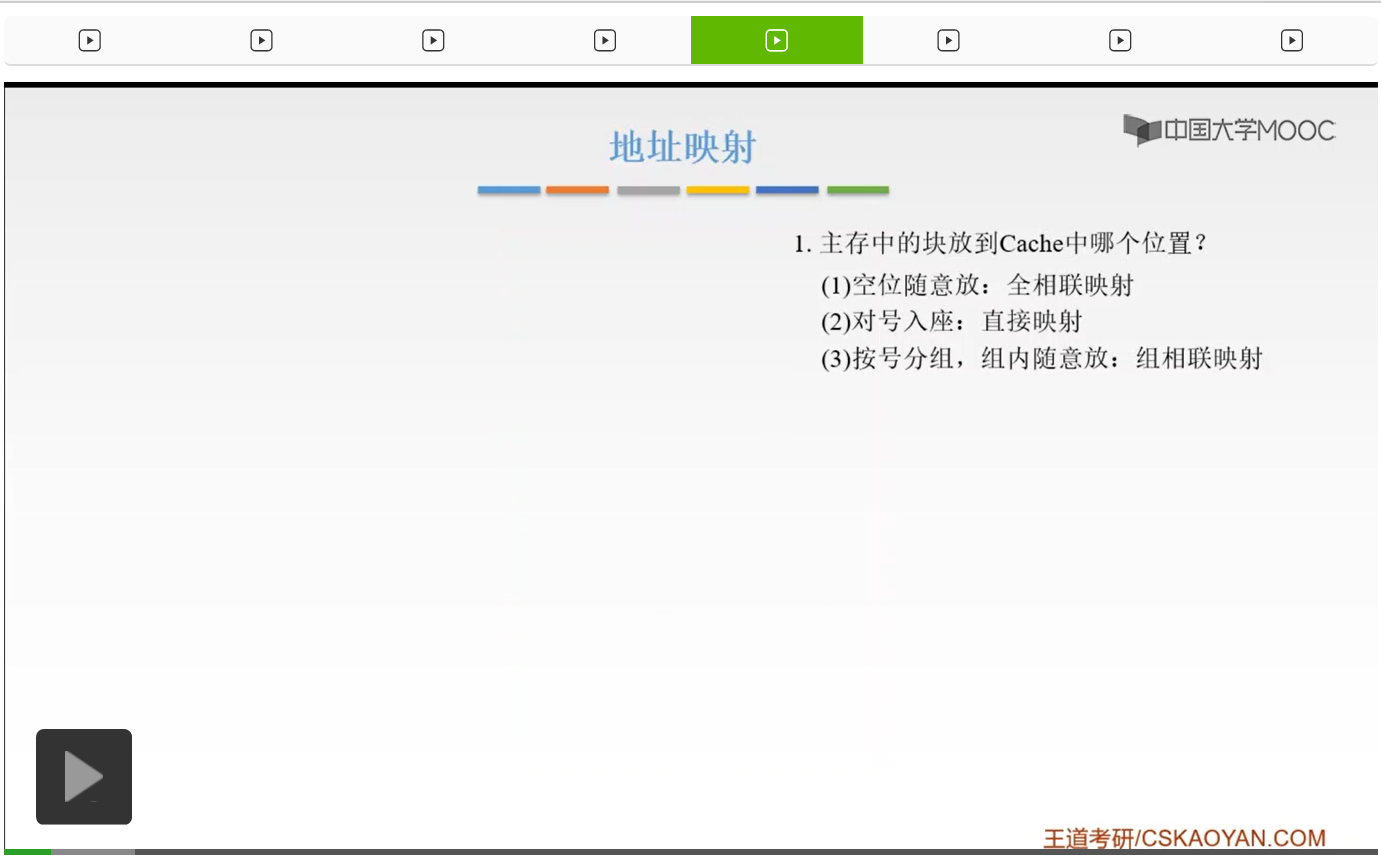
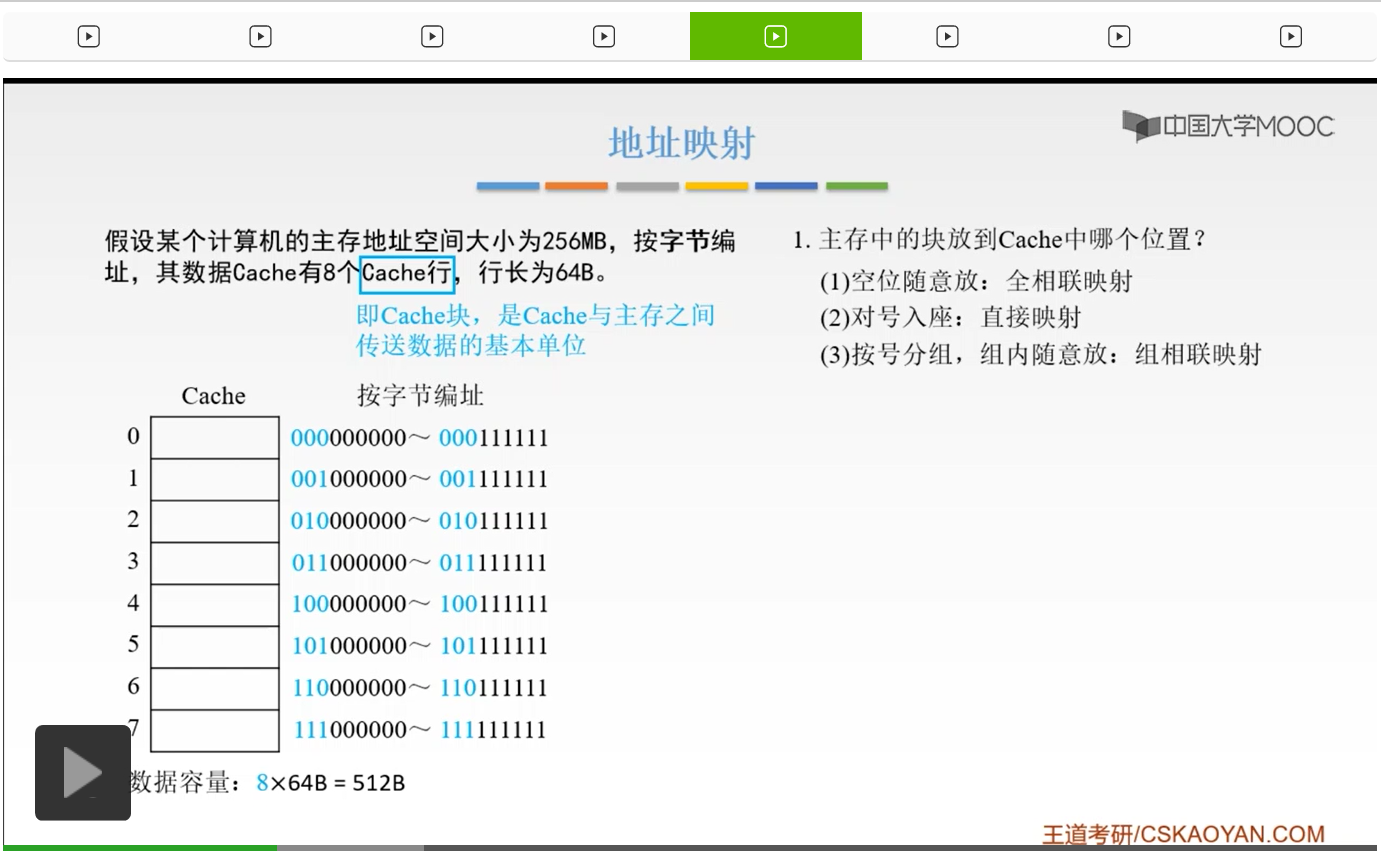
我们来看这样的一个例子,这是书上的一个例题。我们假设某个计算机的主存地址空间大小为256兆B,然后按照字节进行编址。那么它的数据Cache呢,有8个Cache行,那么什么是Cache行呢?就是我们之前一直举的这个例子当中的Cache块,啊就是我们之前也讲过了,就是Cache和主存之间传送数据的一个基本单位,它是以块进行一个传输的。那么我们的行长,行长就是我们的块的长度啊,它是64个字节。那么来画一下这个图。它总共有8个块嘛,我们就把它画8个格子来显像地来看一下。然后呢这就是我们的Cache,然后我们为了方便说明我们给它编号0-7,就8个块嘛。然后它的数据容量就是8*64字节也就是512B。因为它的行长是64B嘛,然后所以它就是8*64B。
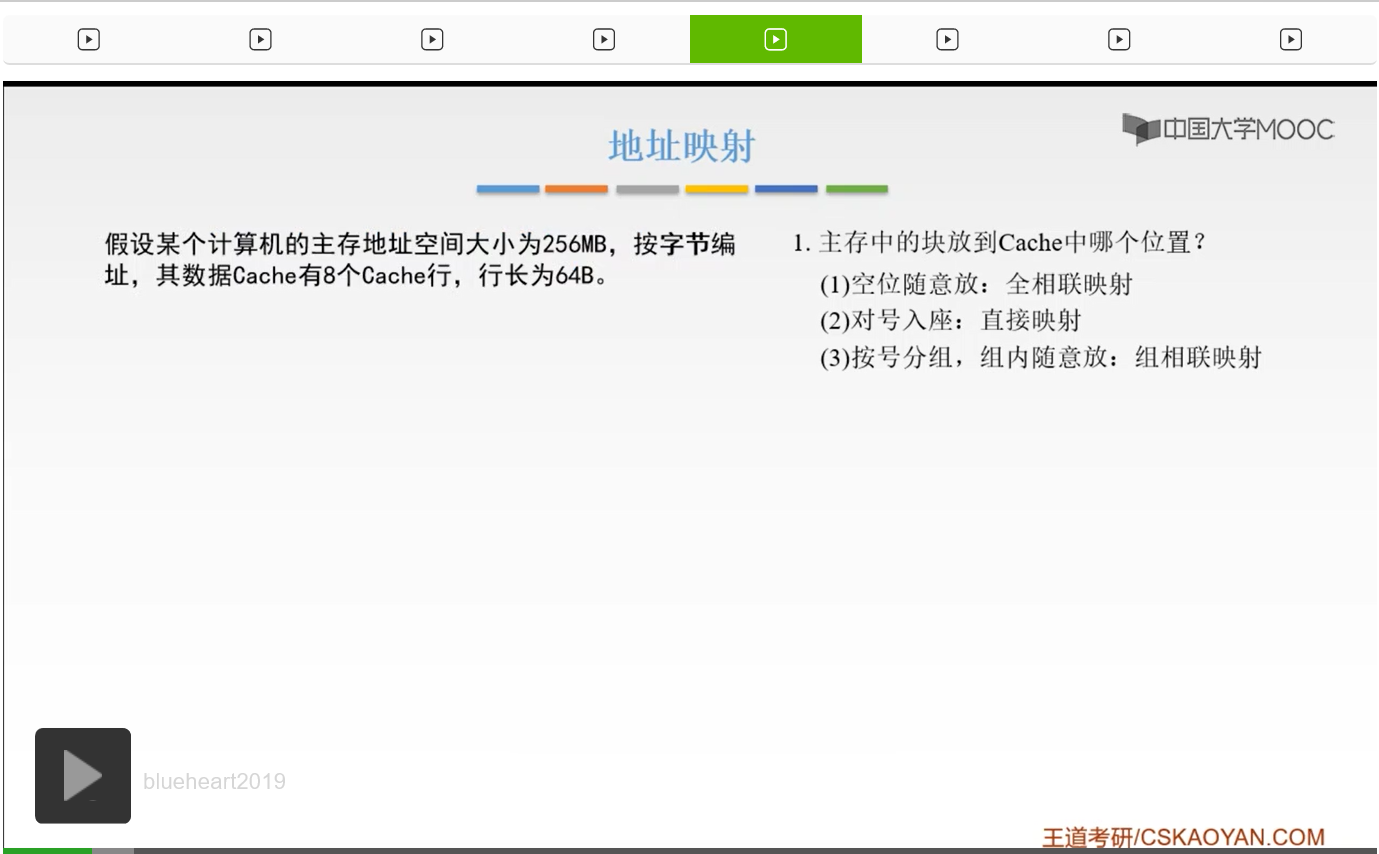
我们给它编址的话,我们按照字节进行编址的话,就是一个8位的地址,8位的地址就是这个样子。我们可以看到,前三位和这个Cache的标号是一一对应的,然后后面的都是6位,因为6位就是2^6,64字节。后面呢就是它的每一行、每一块它里面的这个地址,高层位是它的号码。
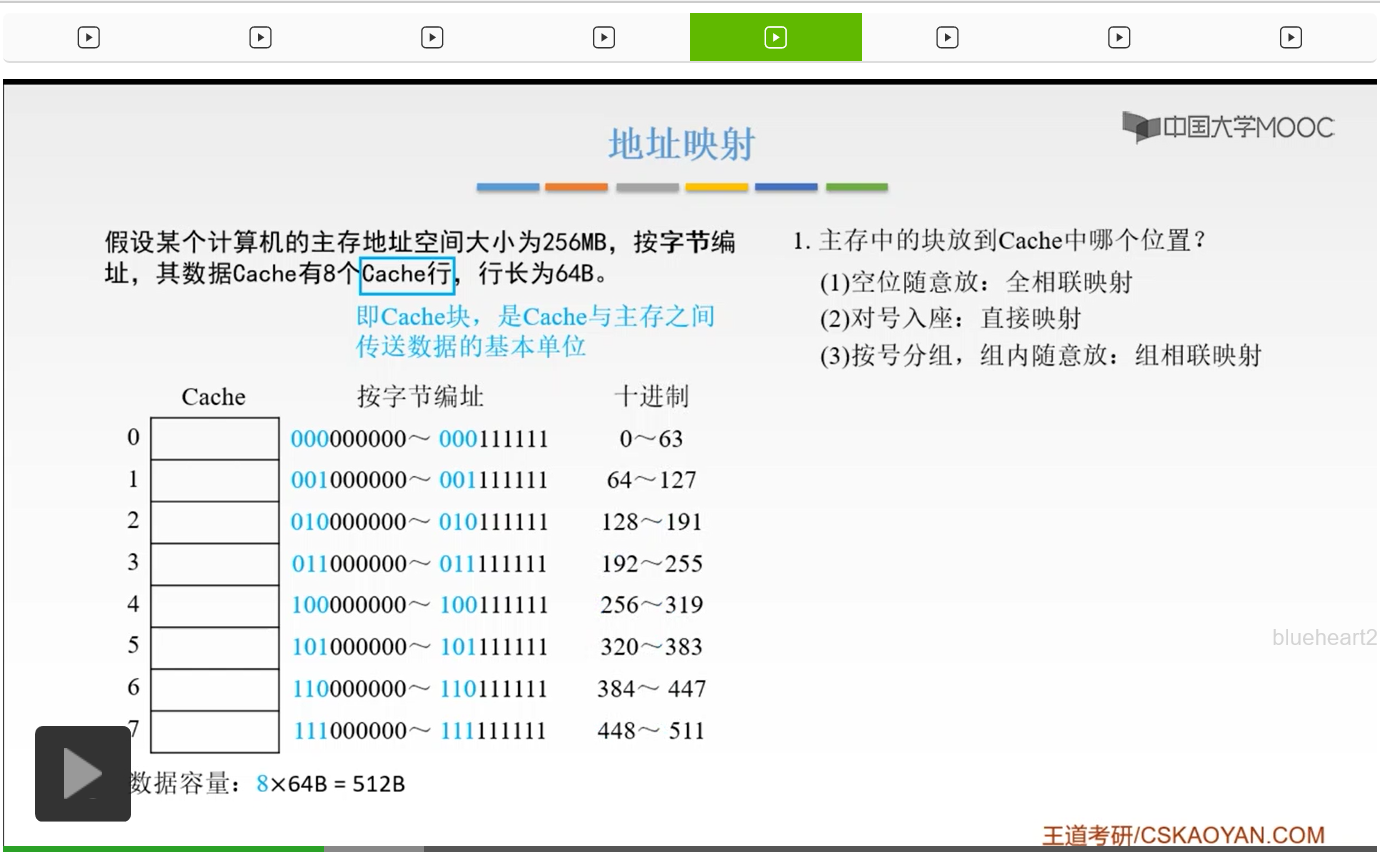
如果大家对这种编号方式不太适应的话,我们把它化成十进制的话呢大家就非常容易理解了。化成十进制的话,第一行,
那么这一节我们来看一下替换策略。也就是说,按我们新的主存块需要调入到Cache当中,并且它的可用位置又被占满的时候,我们现在就要替换掉我们Cache的数据。这时候我们就要来看一下我们要替换掉哪一个,所以这就产生了我们的替换策略或者叫做替换算法。
我们的替换算法呢总共有四个。书上给出了的呢是4。第一种方法呢叫做随机算法,也就是说我们随机地去确定需要替换的Cache。啊这个呢大家了解一下就行了,考试不可能考你这个,因为它的实现是比较简单的,并且呢没有按照一个局部性原理,所以它的命中率很低。那么第二种方法呢,是比较容易考到的,它叫做先进先出的算法。那么它呢是选择我们最早调入的进行一个替换,把我们最早调入到我们Cache当中的替换掉。它呢是比较容易实现的,我们用一个栈就可以来实现了。因为先进先出和我们数据结构当中的栈是完全一样的,但是它也没有按照我们的局部性原理,只是你先把它调入到Cache当中,我就把它替换掉。所以呢它就可能会把一些需要经常使用的一些存储块作为一个最早调入到Cache的块中来替换掉,而比较的不科学。那么第三种方法呢,叫做近期最少使用。比如说我们根据一个局部性的原理,把我们在最近一段时间当中长久没有访问的这样一个数据块把它替换掉,所以呢它的平均命中率要比我们的先进先出要高一点。它是怎么来实现的呢?因为我们要有一个最近最少使用,我们就可以对每一块设置一个计数器,如果它命中一次我们就把它清零,而其他的呢再加1。最后如果我要替换的时候,我把最大的把它替换掉。最大的说明它很久没有使用
