这节课我们来学习一下IP数据报的格式。那之所以把路由算法这一小节跳过呢,就是因为我们之后会要讲到路由的选择协议。那在路由选择协议这一块讲路由算法,我觉得是比较合适的。那我们先来看一下这节课要讲的知识。
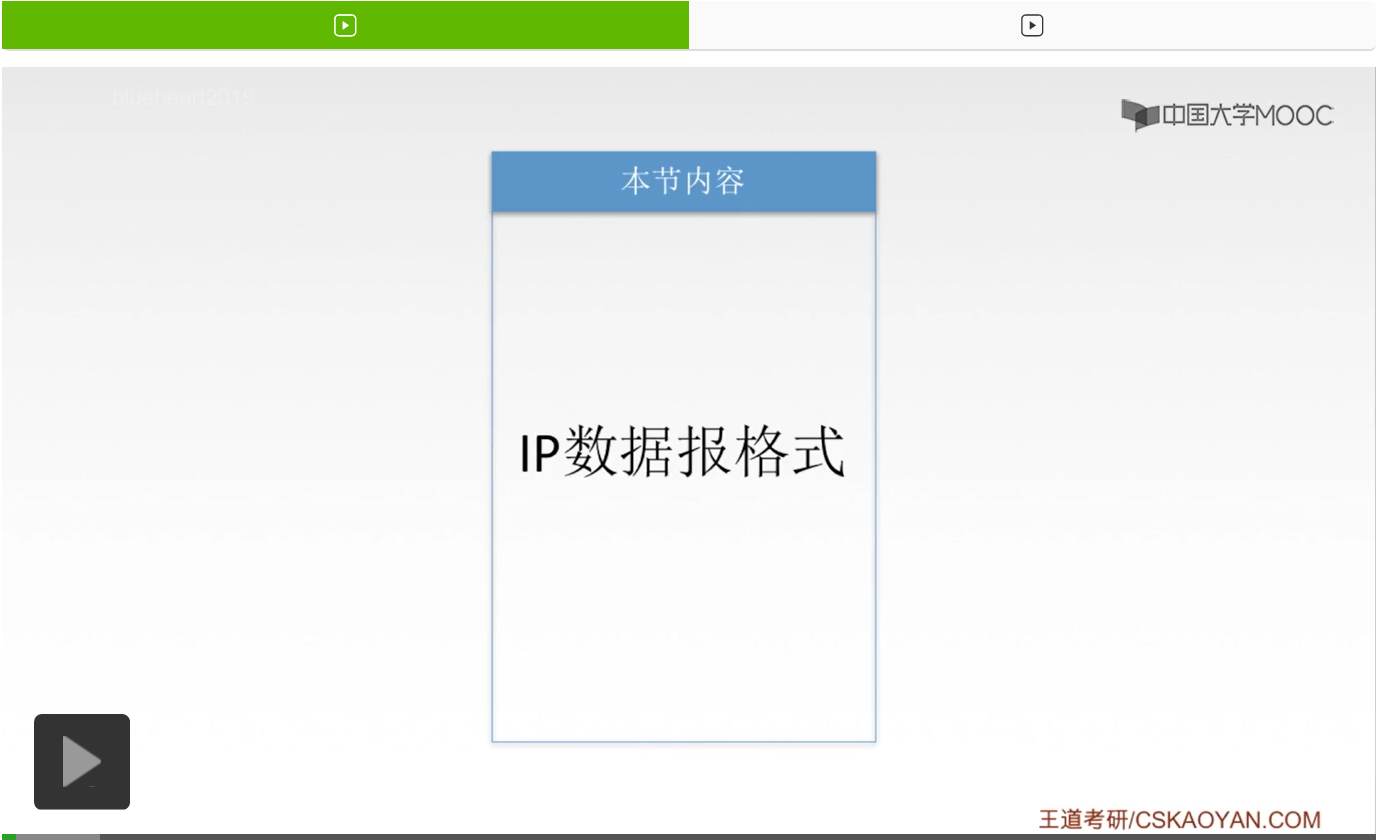
首先呢我们来看一个IPTCP/IP协议栈的一个构造。那这个协议栈呢就是自顶向下分别是因应用层、传输层、网络层、链路层和物理层。那有关于网络层的协议呢,主要是这四个,ARP协议、IP协议、ICMP协议以及IGMP协议。那我们在考试当中啊,除了要清楚每一个协议它们的功能是什么,还要知道这些协议它们之间还有一定的关系。那ARP协议如果它在最下面,它自然就要为这个IP协议服务。而这个IP协议呢也要为上面这两个协议——ICMP协议和IGMP协议来进行一个服务。那可以看到,在这个协议栈当中啊,IP协议它是占了大半江山,那就说明IP协议非常的重要。而这节课要讲的IP数据报的格式,正可以说明这个IP协议都具有哪些功能。
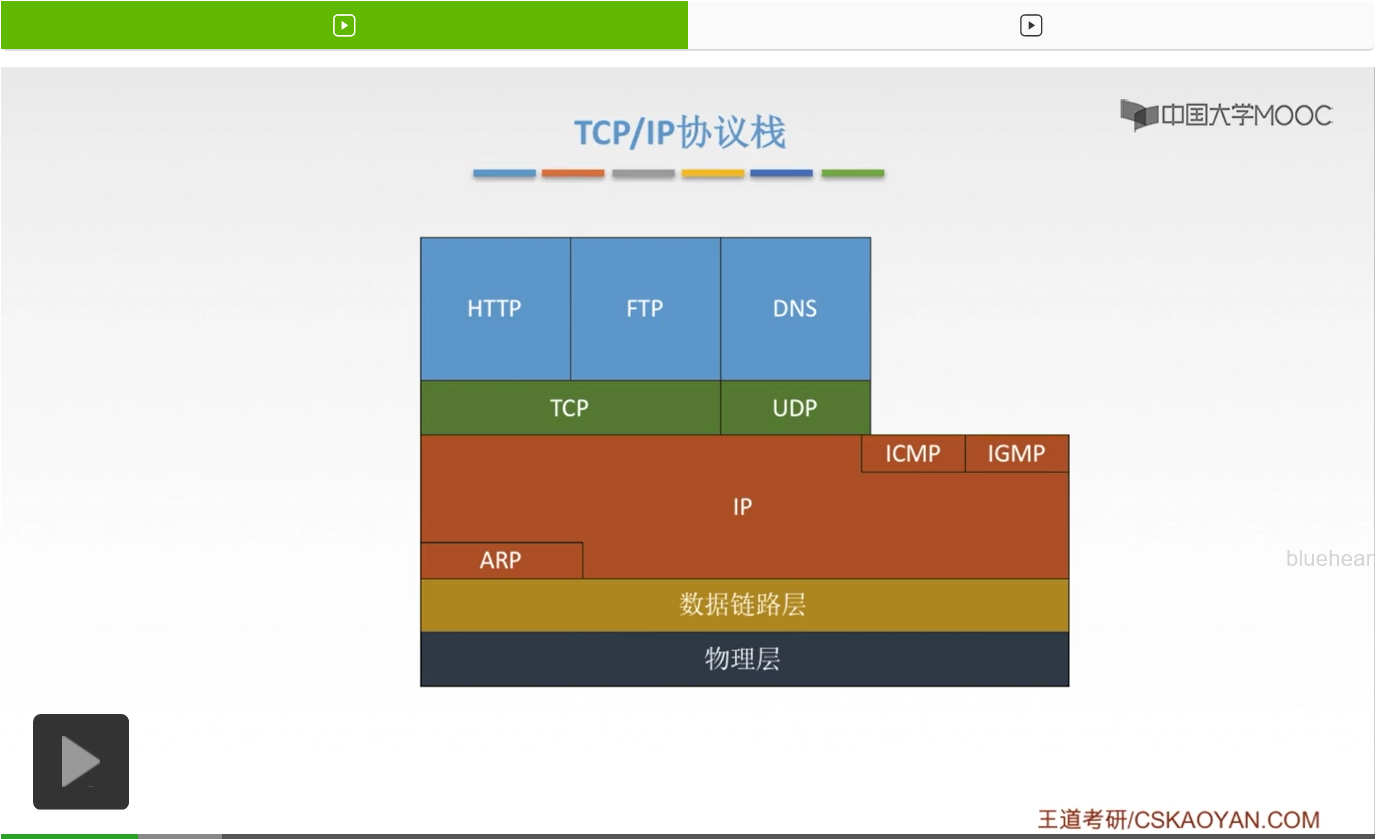
那我们就来看一下这节课要讲的IP数据报格式。首先呢我们对于一个IP数据报,分成了两部分。一个是首部和数据部分。那这个数据部分呢,也就是运输层的传送传送单元,有TCP段,也有UDP段。那这个首部呢也可以称之为IP数据报的头部。那要注意的一点是在这一章,在网络层这一章IP数据报和分组我们是不用做太细的区分的,可以暂时就把这两个当成一样的东西。但是我们要清楚的是,它们还是有一定的区别。就是对于一个IP数据报,如果过大,我们就会给它进行一个分片。那分片下来的一个小单位呢,也就是网络层的传输单元及分组。
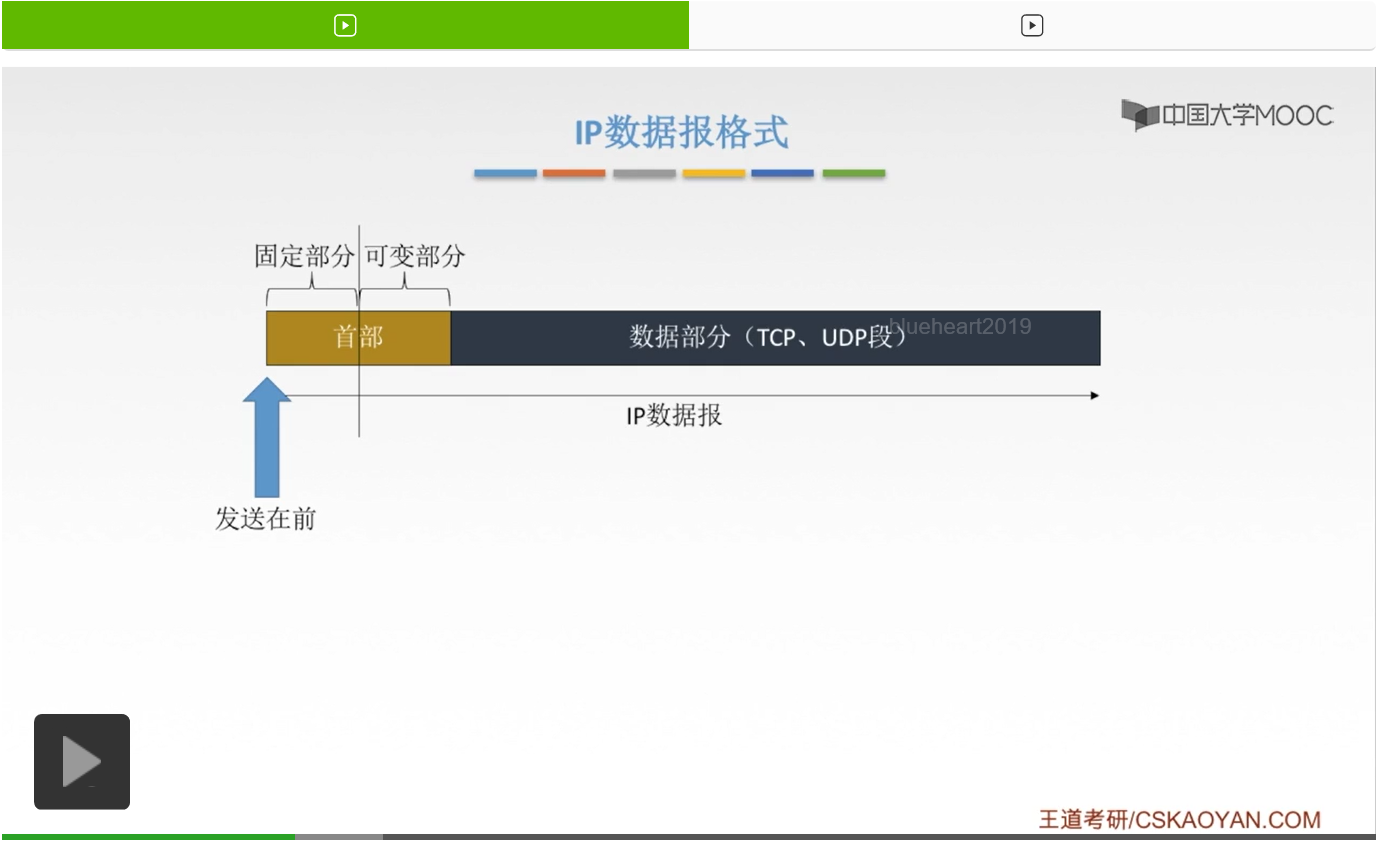
那自然这个地方叫首部,那我们发送数据的时候肯定就是要从首部开始。所以首部这个位置的数据是发送在先,然后逐个比特再去发送。

那对于这个首部呢我们还给它细分成了两部分。那第一部分呢就叫做固定部分,第二部分呢叫做可变部分。那这个固定部分顾名思义,就是固定不变的。对于任何一个IP数据报,它的固定部分大小都相同,都是20字节,而且是一定要有的。但是这个可变部分呢,就是可有可无。但是大多数的情况下,都是没有这个可变部分的。
那接下来我们就来看一下具体的这个首部它有哪些字段。那对于这个数据部分呢我们就不做过多的讲解了,因为它不是网络层的重点。数据部分呢它是传输层的报文段,所以我们这里就放在传输层上面去讲。
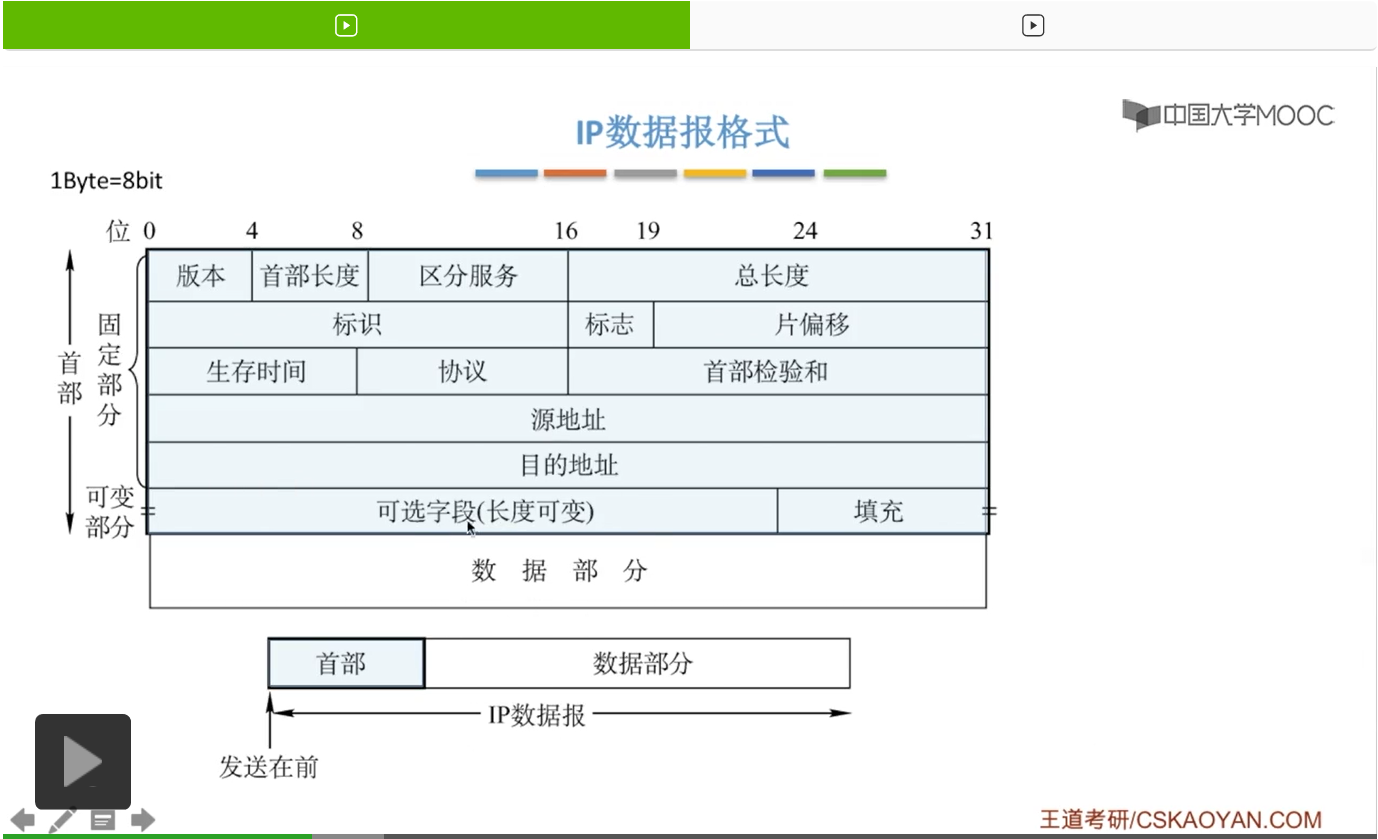
那我们就来看一下它的首部,首部呢前面是这个固定部分,那这个固定部分呢长度自然也是固定的,是这个20字节。那要注意这个字节和比特的一个换算,1字节(Byte)=8比特(bit)。所以这里面要区分,这个是位啊。这个位就是比特,所以可以看到这个是以位为单位来对这个首部进行一个划分。首先我们来看第一个字段,也就是版本字段。

版本字段呢是0到4,也就是说这个版本字段它是有4位的。那这个版本指的就是使用的是IPv4还是IPv6,也就是我们使用的IP协议的版本。那这个版本对应的英文单词就是version,也就是这里面的v。目前呢我们广泛通用的是这个IPv4的版本。但是在未来呢,随着这个我们对于IP地址的数目要求变多,那一定会使用到这个IPv6的协议。
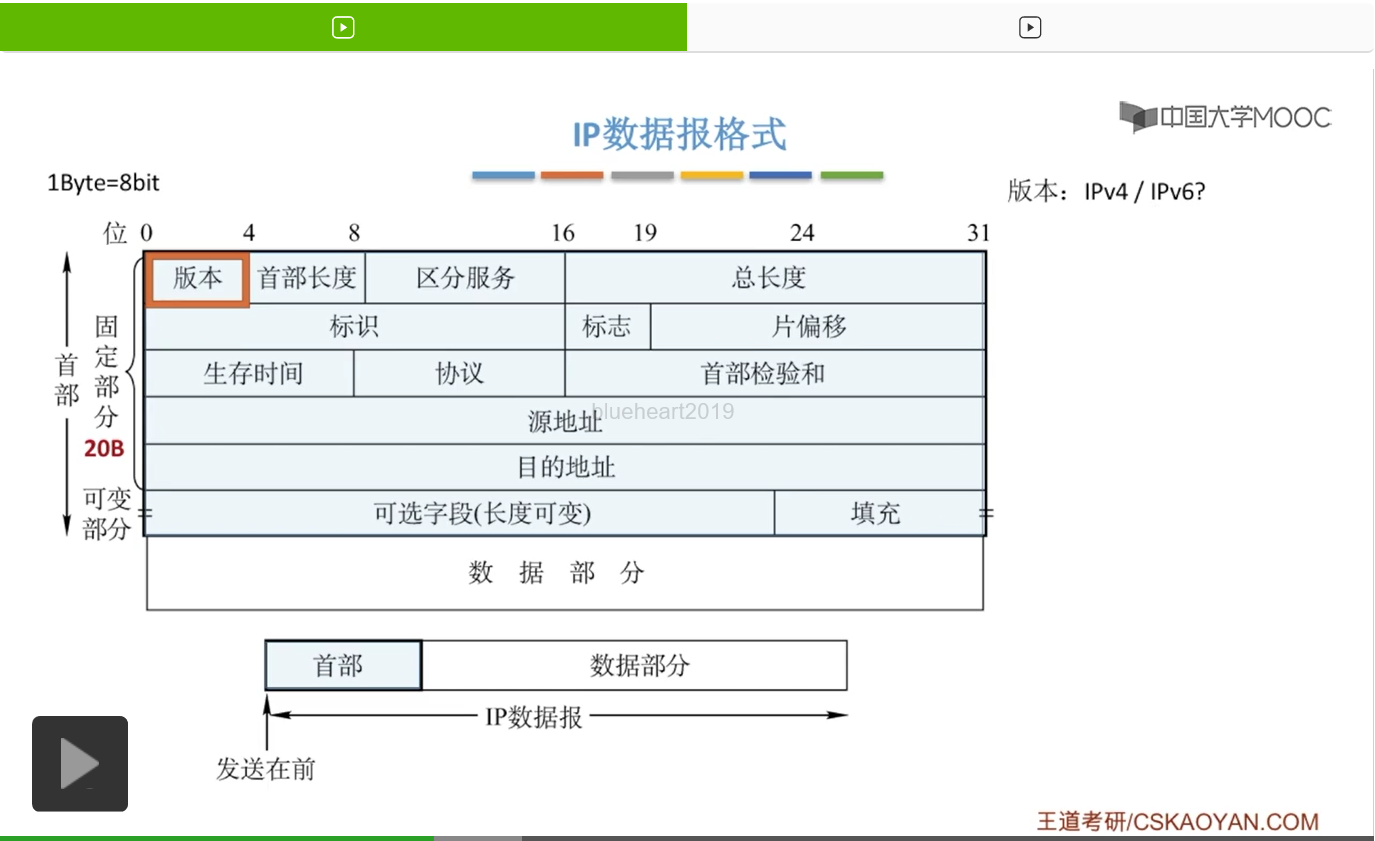
那我们接下来再看第二个字段,首部长度。那这个首部长度呢,也是4位,也就是4比特。那这个首部长度的单位是4字节,如何理解呢?
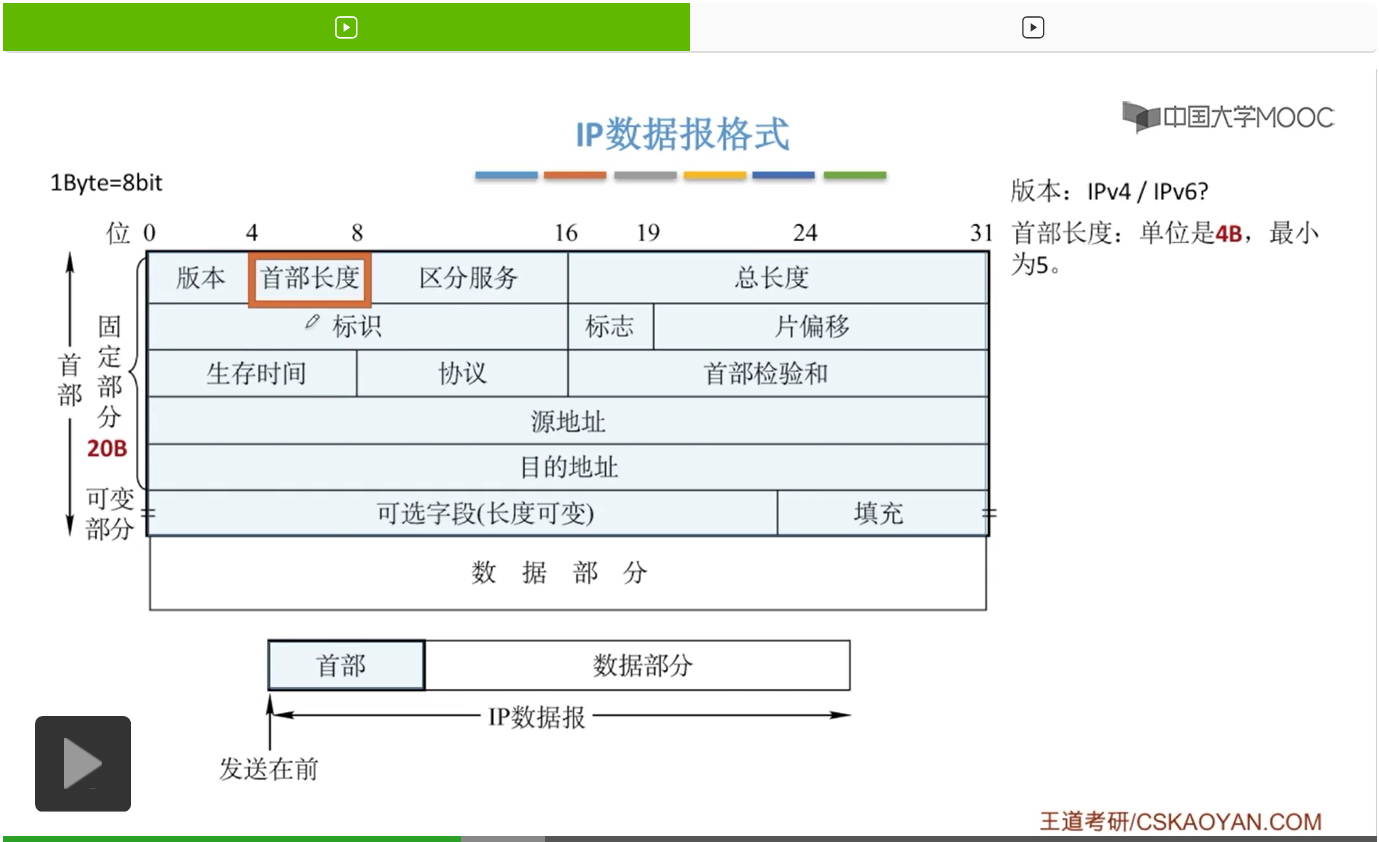
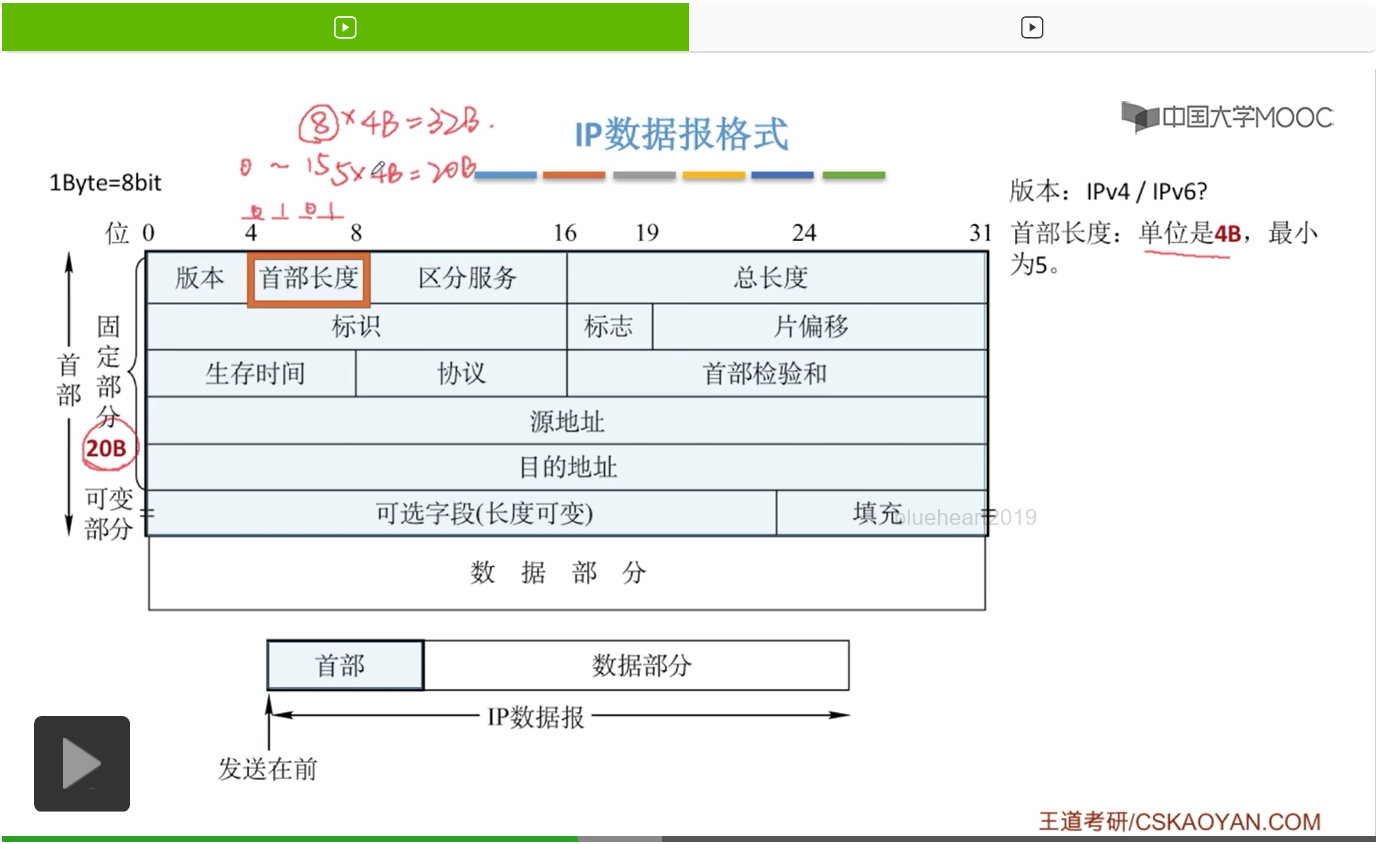
首先,这个首部长度它是4位,那我们就画上这4位。那对应一个4位的二进制数,我们知道它可以表示的十进制数总共有16个。也就是从0一直到15,这都是这4位二进制数可以表示的一个范围。那单位是4B(字节)如何理解。那就是说,对于首部长度,如果确定下来是一个数,比如说我们确定现在的首部长度是8,那这个实际上的首部长度大小就是我们8*4B也就是32B。那如果对应的这个首部长度现在是5,那首部长度的大小就是5*4B也就是20B,刚好就是我们固定部分的这样一个长度。所以说为了保证一个IP数据报一定满足这个20字节的固定部分,它的首部长度要从5开始,也就是要从0101这样一个二进制的表示形式。
那接下来我们再来看第三个字段,区分服务。那区分服务呢,它的长度是16位。它指示的是期望获得哪种类型的服务。比如说我这个数据报,我想优先发送,也就是要强调这个数据报的优先级,那就是在区分服务这儿进行一个规定。当然这个区分服务呢我们在实际应用当中是很少用的,而且是只有在使用区分服务的时候这个字段才起作用。其他的情况这个字段就没有什么存在感。
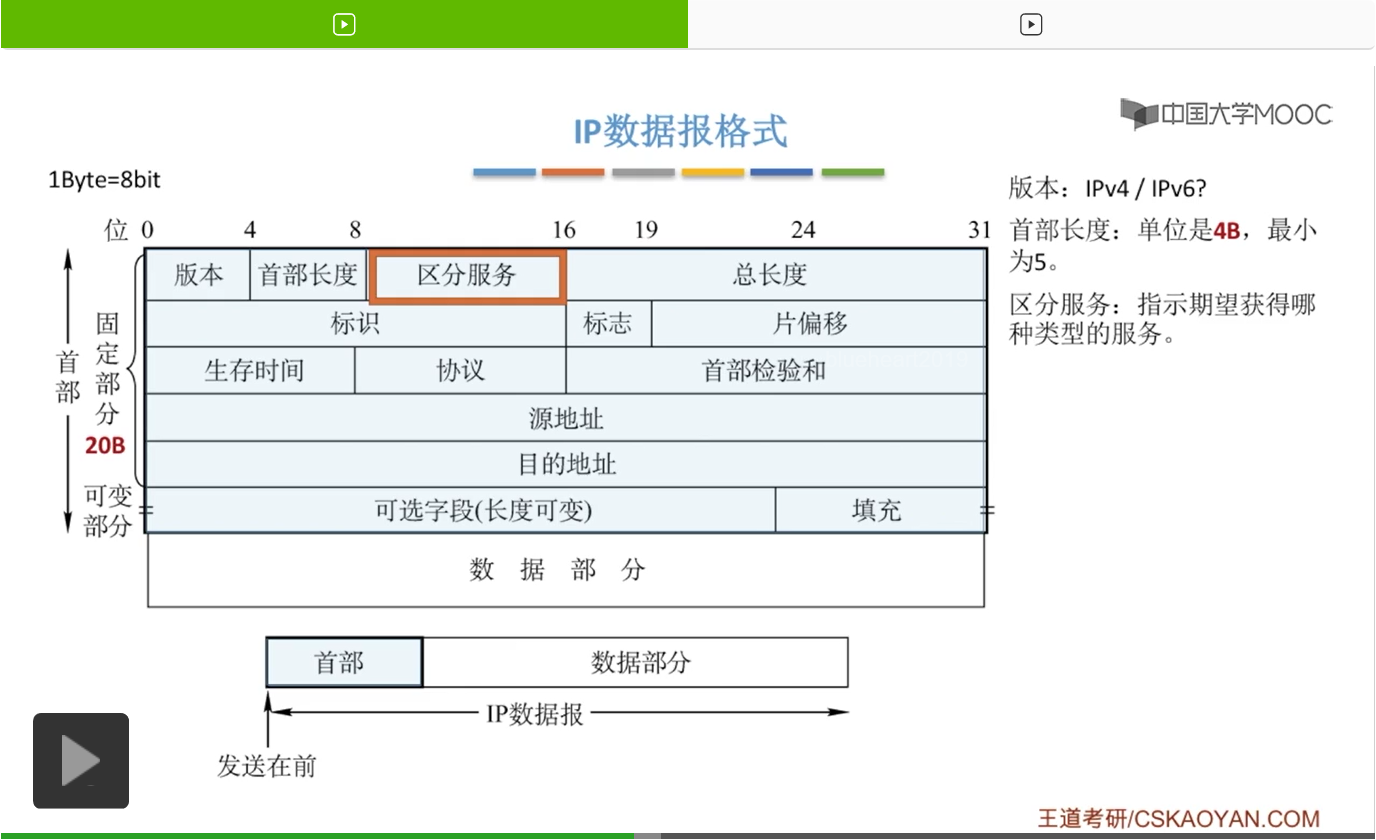
那我们再来看第四个字段,也就是总长度。总长度呢它指的是首部的长度。
这节课我们来讲一下IP数据报分片的一个过程以及在IP数据报首部它的几个相关字段。
首先呢我们来看这样一个概念,最大传送单元MTU。这个其实是我们在链路层所讲的一个概念了,在链路层上面,每一个数据帧它都有一个可封装数据的上限,而这个上限呢就叫做最大传送单元MTU。
那对于这种特殊的以太网来说,以太网的MTU是1500字节。

这是一个IP的分组,也可以称之为是一个IP数据报,它们分为首部和数据部分。
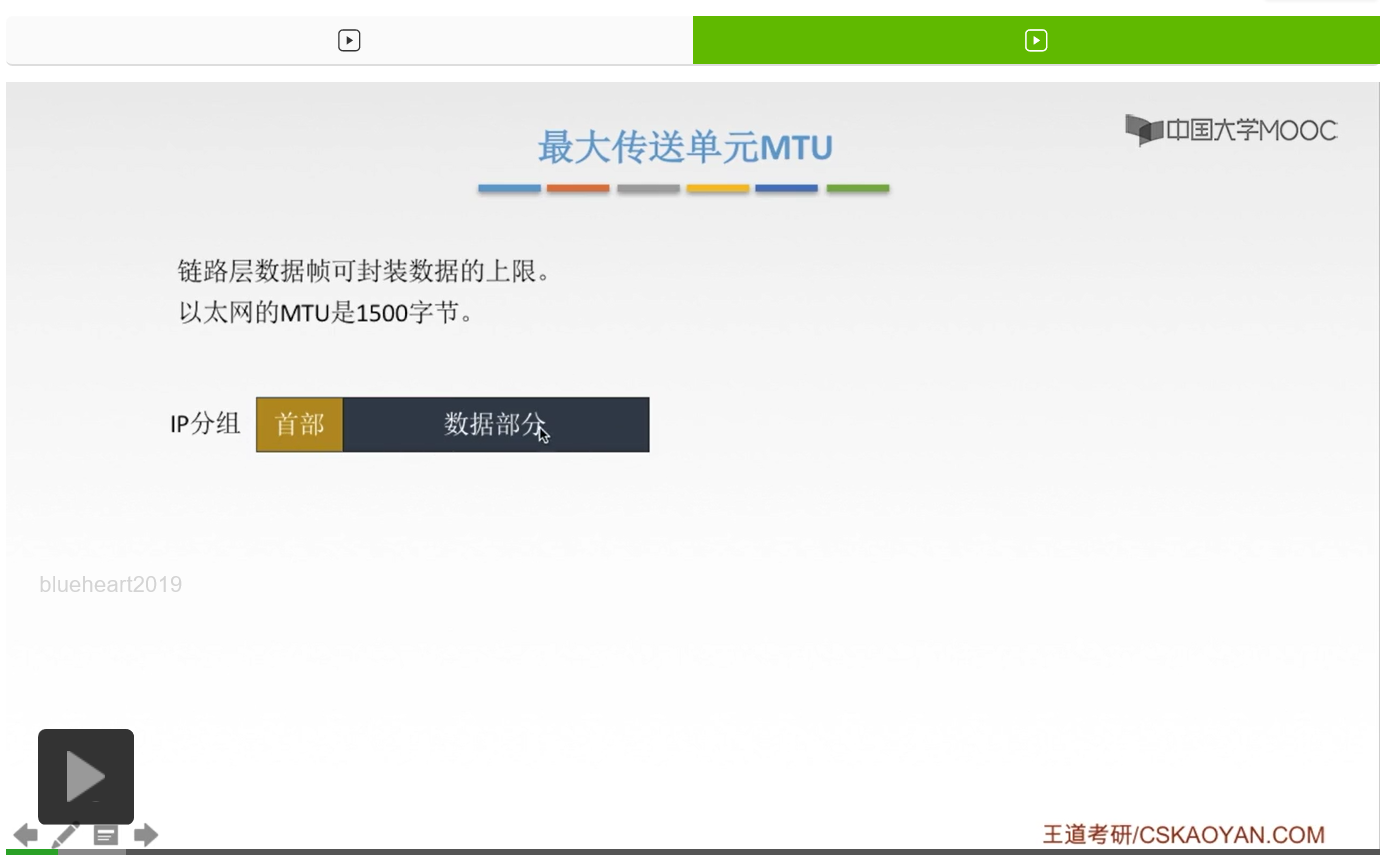
那这样一个IP分组就要经过封装,然后形成这个链路层的数据帧。那么封装的过程呢就是在这个分组前面加头,在分组后面加尾,加头加尾,然后中间的部分呢也就是IP分组,它形成了数据帧的数据部分。那这个数据部分就是有一个最大要求,这个最大的要求就是MTU,不能超过这个上限值。那以太网当中,这个数据帧的数据部分,最大就是1500字节。
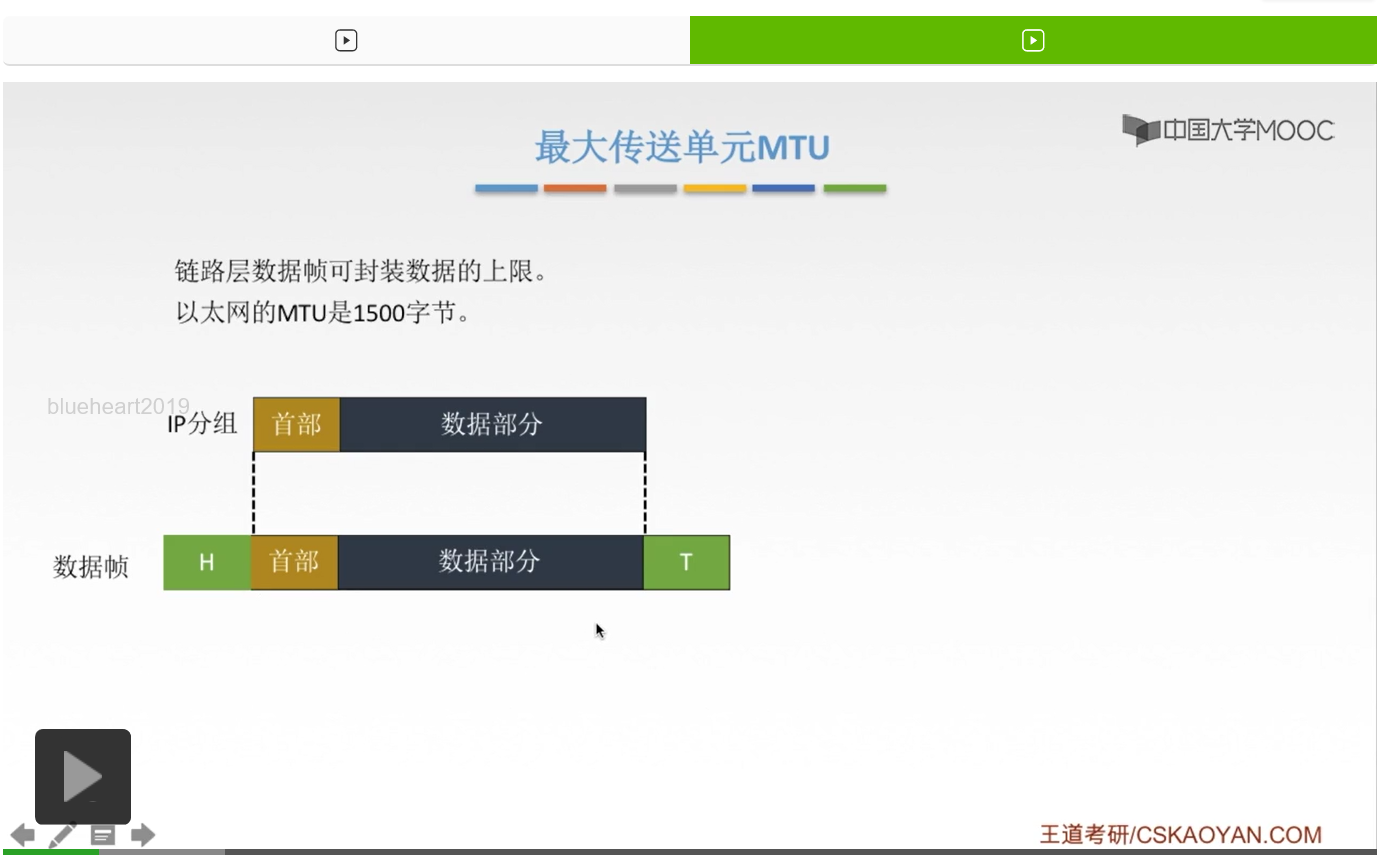
那我们现在想这样一个问题,如果我们要传送的数据报长度超过了这个链路的MTU怎么办?还是要给它塞进来吗?硬要给它封装上吗?啊当然是不可以的,那我们解决办法呢就是分片。当然啊,这种分片的解决办法呢,前提是要这个IP分组它自己同意,把自己的数据报进行一个分片,那有的IP分组它比较傲娇比较任性,它不想分片,宁死也不去。啊如果不分片,那这个IP分组呢就没有办法再往下传递了,因此呢就会返回一个ICMP的差错报文。那这个ICMP呢,我们之后再来讲。
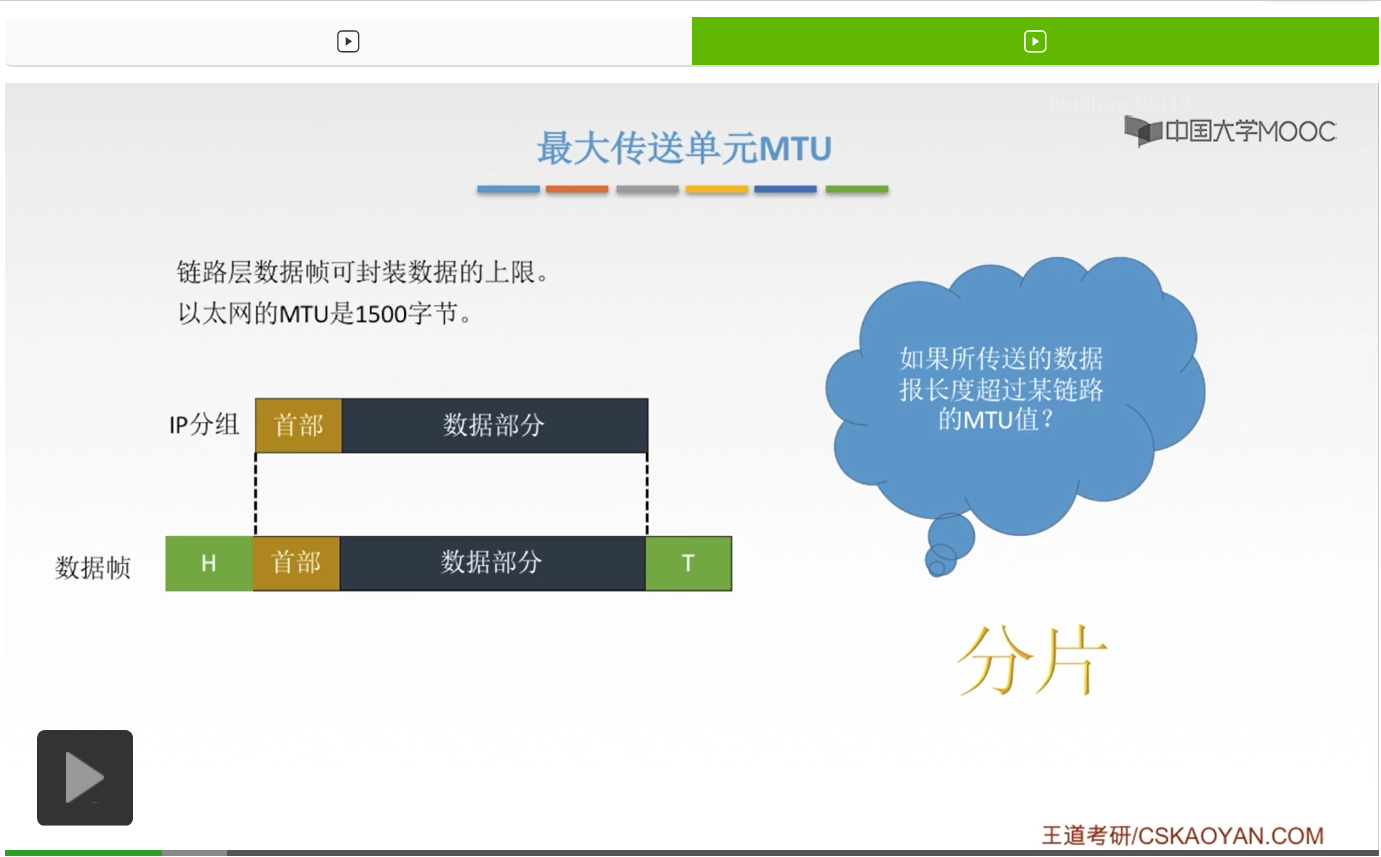
那我们接下来看一下这种普遍使用的分片方法。那分片方法呢就要结合这个IP数据报格式首部当中的标识、标志以及片偏移三个字段来理解。

首先我们来看什么叫标识。标识指的是同一数据报的分片,啊只要是同一数据报的分片,它都会使用相同的标识,也就是说一个原始的、原来的数据报,啊如果它现在长度超过了链路层的MTU,它就要进行分片,那每分得的一个小片它都和原来的数据报享用或者说使用同样的一个标识。那假如说原来数据报的标识是666,那现在每一个分片它的首部的这个标识字段都是666。也就是说,这个标识的作用呢就是使这些分片,让它们知道自己是哪家的,啊到最后到接收端的时候呢,才可以把这些同一家的、同一个标识的分片再给组合起来,形成原来的完整的数据报。

那再来看这个标志字段。标志字段呢,它是有3位。
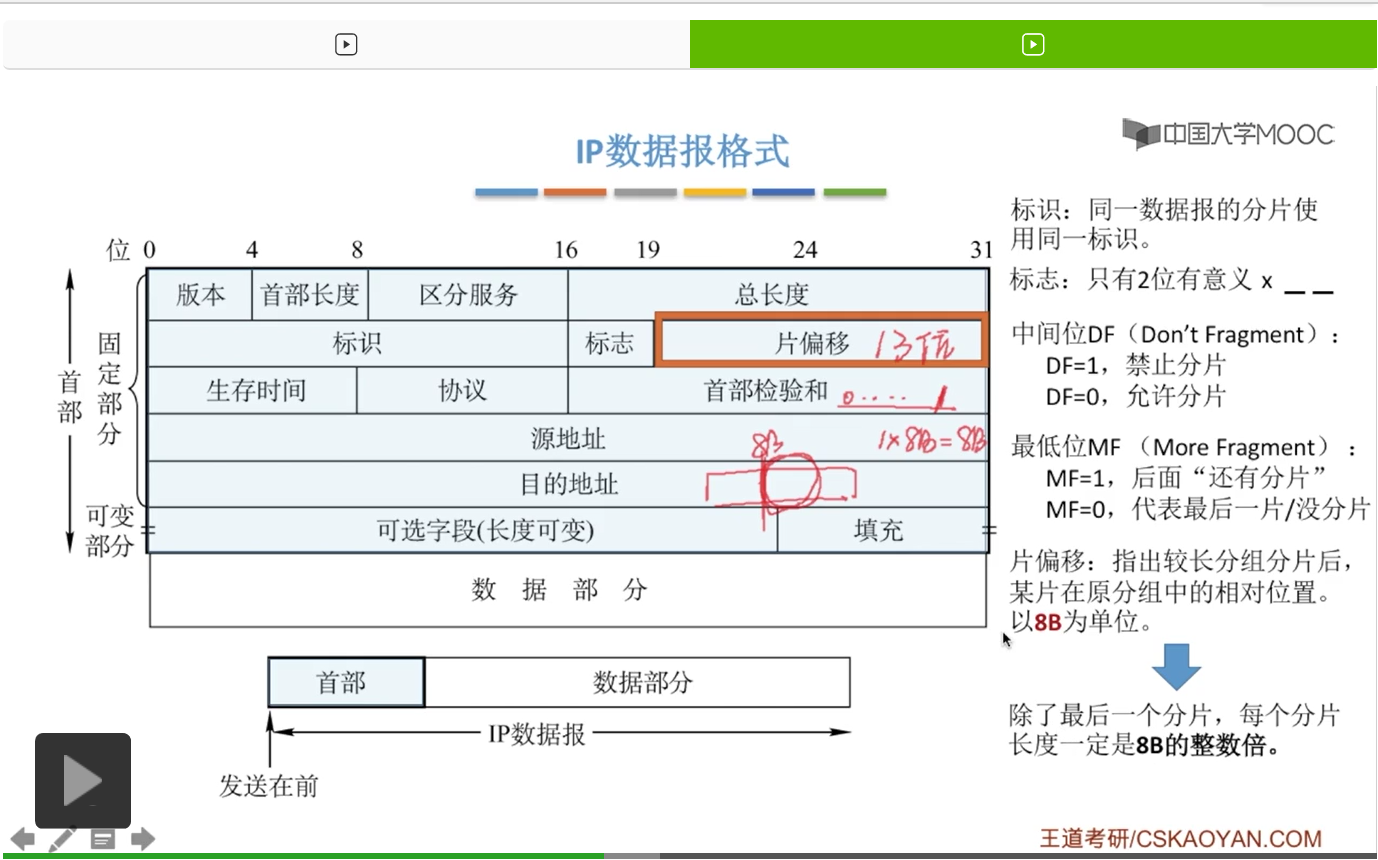
标志字段的3位,但是只有两位是有意义的。那这个最高位呢是保留,我们就不用。那我们就看一下,这个最低位和中间两位分别是代表什么。 首先我们来看中间位,那中间这一位呢叫做DF,那DF用英文来说就是Don't Fragment,不许分片,啊不许分片。如果满足不许分片呢,那就是DF=1,也就是禁止分片。那如果不满足,不满足这个DF,也就是不满足禁止分片,那就是允许分片。也就是DF=0的时候,是允许分片的。因为我们知道在这个1和0啊,啊这两种情况,通常都是表示是或者否。啊1就是是,0就是否。那1就是满足,0就是不满足。那对于DF如果=1,就是满足DF,也就是满足不许分片。满足不许分片就是禁止分片。如果不满足禁止分片呢,就是允许分片了。

那再来看第二位,也就是最低位的MF。MF呢指的就是More Fragment,啊More Fragment就是更多的分片。那如果满足这个更多的分片,就说明后面还有分片。但是如果这个不满足,也就是MF=0,不满足更多分片,那说明这个分片就是所有分片的最后一个,就是老末。那还有一种情况呢,就是说明没有分片。就说这个数据报它的长度呢是不大的,它可以满足这个不超过MTU,所以呢它就不需要分片。那它所对应的标识位的MF这个字段,就是MF=0。那我们可以看到,这个DF和MF其实是有一种关系的。啊只有DF等于0之后,我们这个MF才有意义。啊如果这个DF=1,禁止分片,那这个MF就没有存在的意义了。所以如果我们在讨论MF是等于1还是等于0的时候,它的前提都是DF=0,就是允许分片,在这种分片模式下我们才能讨论这个有没有分片,是不是最后一个分片。

那我们再来看第三个,片偏移字段。片偏移呢指出较长分组分片之后,某片在原分组中的相对位置。因为我们可以看到,对于这种MF=0以及MF=1的情况,我们只能知道这个分片是不是最后一个。但是如果它不是最后一个,它在中间是第几个呢?或者说它是原来数据报当中哪个位置呢?我们最后如何根据这个位置来还原数据报呢?就是要靠片偏移这个字段。有了这个字段呢,我们就知道现在的这样一个分片对应于原来分组当中或者说原来数据报当中具体在哪一个位置上。而这个片偏移呢是以8字节为一单位的,那这个片偏移字段它的长度呢就是16减去3位的标志位,也就是13位,13比特。那现在假如说这个对应于一个分组,对应于一个IP数据报,它的片偏移这个字段是00000......直到1,也就是这个如果用十进制表示,就是1。那它的意思呢就是指,这样一个分片或者说这样一个分组,它在原来分组或者是原来数据报当中的相对位置,是1*8B字节,也就是8B字节。就是在原来这样一个数据报当中,啊第8个字节开始的,这样一个对应的位置,从8B字节开始的这样一个位置,那它这个分片的位置也自然就确定出来了。

那正因为片偏移它有这样一个特点,以8字节为单位,我们就可以推出来除了最后一个分片,每一个分片的长度一定都是8字节的整数倍。当然啊有的时候这个最后一个分片,也有可能是8字节的整数倍。
那我们结合一个例子再来看一下这个分片的过程以及这几个字段是如何应用的。首先呢,对应于这样一个比较长的IP数据报,首部是20字节,可以看到它没有使用可变部分也没有使用填充字段。数据部分呢是3800字节,所以说加一块整个数据报的总长度,就是3820字节。那对应于这个数据报所要传输的链路来说呢,啊最大的MTU是1420字节。也就是说现在要把数据部分进行分片了,就按照MTU来进行分片。那这里面的MTU是1420字节,那这一个1420字节的数据报片或者说是分片,其中的20字节是一定要作为首部的,那剩下的1400字节,才可以作为这个数据报或者说这个分片的数据部分。那因此呢,我们就把这个数据部分进行一个切割。
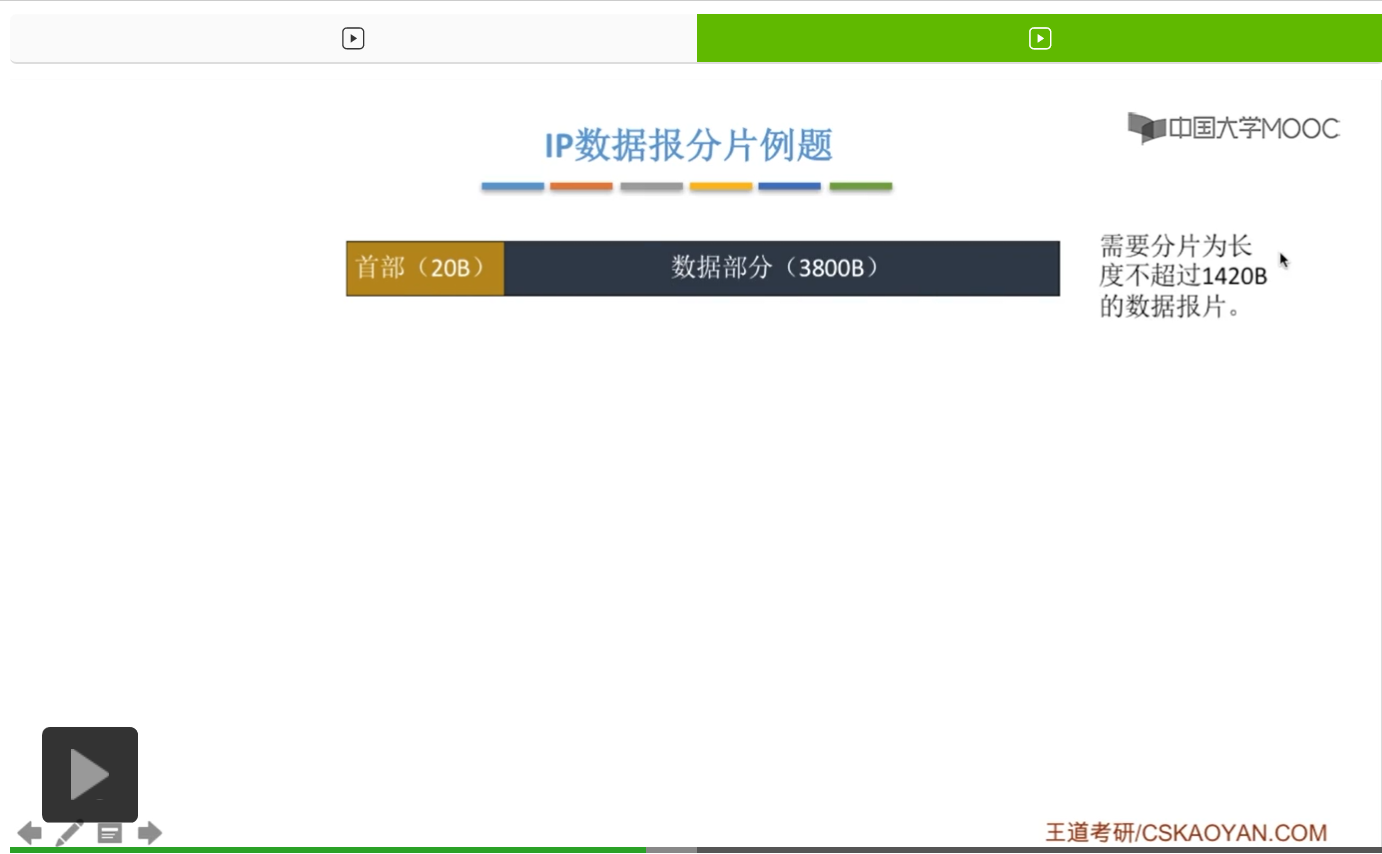
怎么切割?就是尽可能地使分割完的数据部分越大越好。最大自然就是这个1420字节,减20,就是1400字节。所以,这儿可以分出来一个1400字节的数据报,然后呢这儿又可以分出来一个1400字节的数据报或者分片,还剩下1000字节的分片。那我们知道,分完的每一个分片呢,啊分下来之后就要再加上一个首部,才形成一个完整的分片。那这个首部呢,就随长辈,随爸妈,还是加上这样一个20字节。
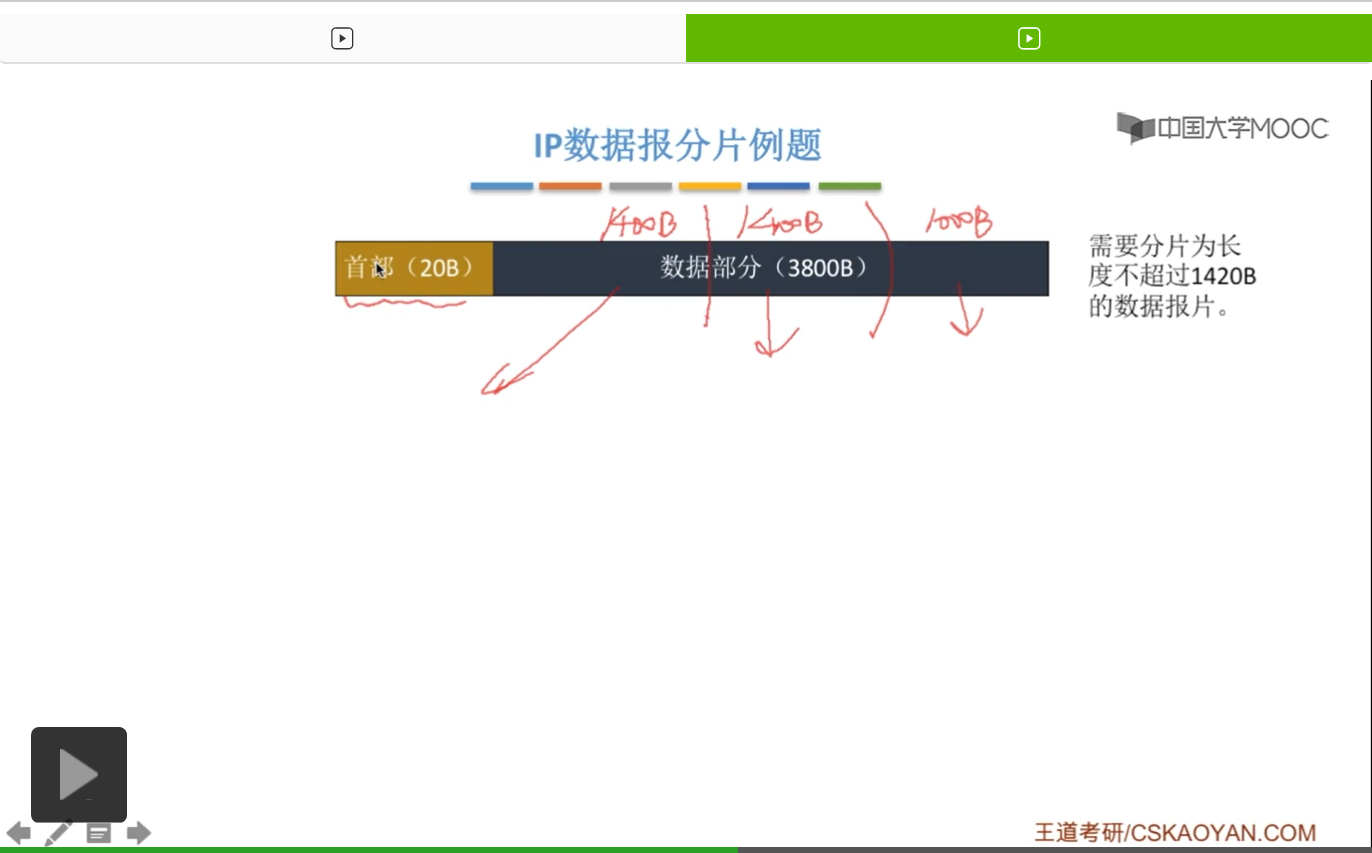
因此呢,我们可以看到,分片之后,就形成了这样三个数据报片,或者说三个分片,它们分别都有20字节的首部以及一定长度的数据部分。那对应于前两个,是1400字节的数据部分,第三个,就是剩下的1000字节。
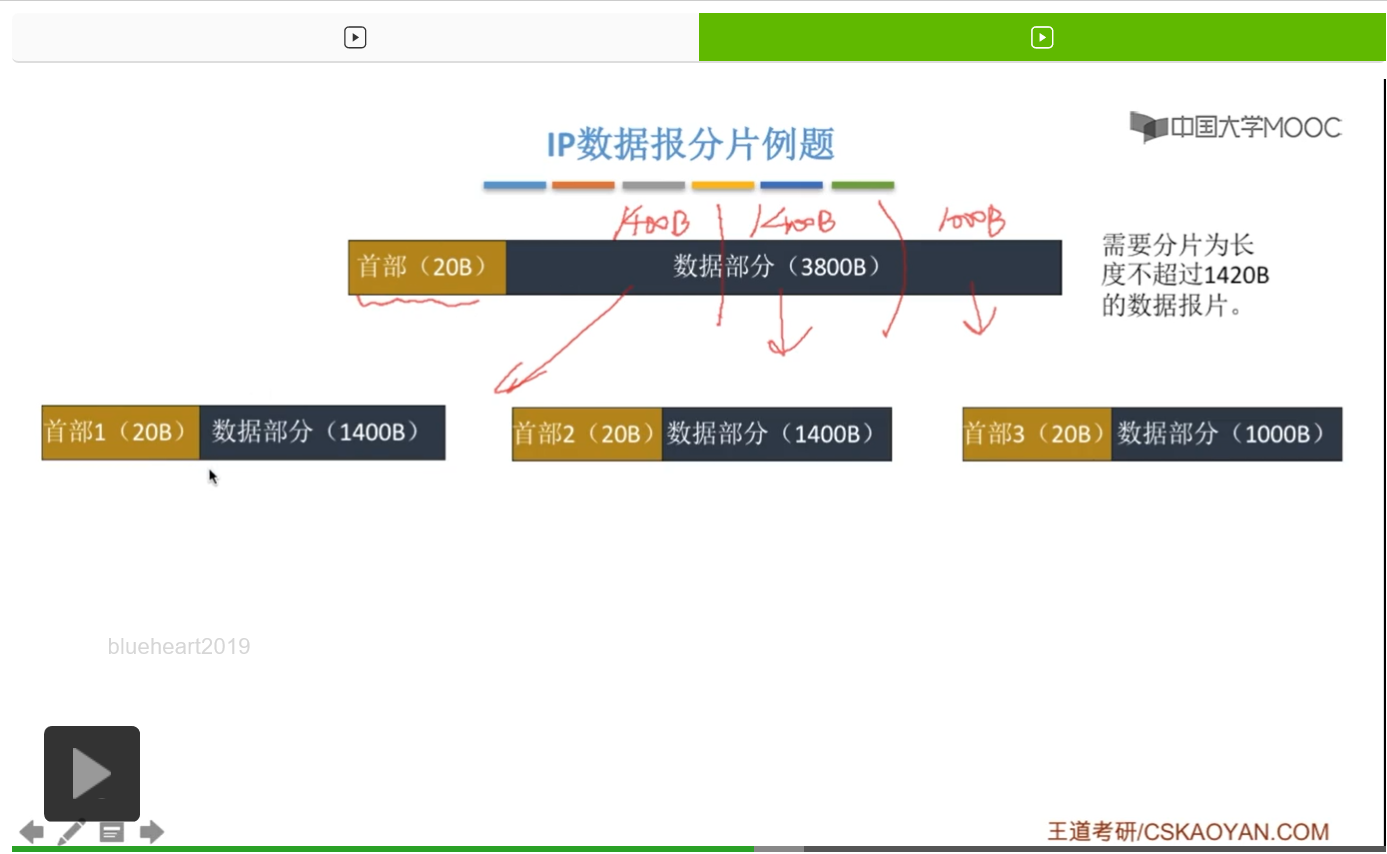
那么我们现在来具体分析一下对于每一个数据报片它的片偏移量应该是多少。首先呢,我们要对于这个源数据报的数据部分啊进行一个规定。它的第一个字节我们称之为0字节,也就是这一小条是0字节。那接下来下一个呢就是1字节,2字节,等等等等。那我们可以看到,第一个数据报片,它拿出了1400字节也就是从0字节一直到1399字节。它把这些字节拿出来了。那这样一个数据报片在原来的数据报当中,偏移量是多少呢?或者说,啊距原来的这个数据报的数据部分,最开始的位置有多远呢?当然,片偏移量就是0。因为这个数据部分啊它是从第一个字节,也就是从这个0号字节开始取的,所以我们把这个第一个分片划回去,啊其实就是在这儿。因此呢,它相对于这个源数据报的数据部分,开头来说是没有距离的。因此,它片偏移量就是0。
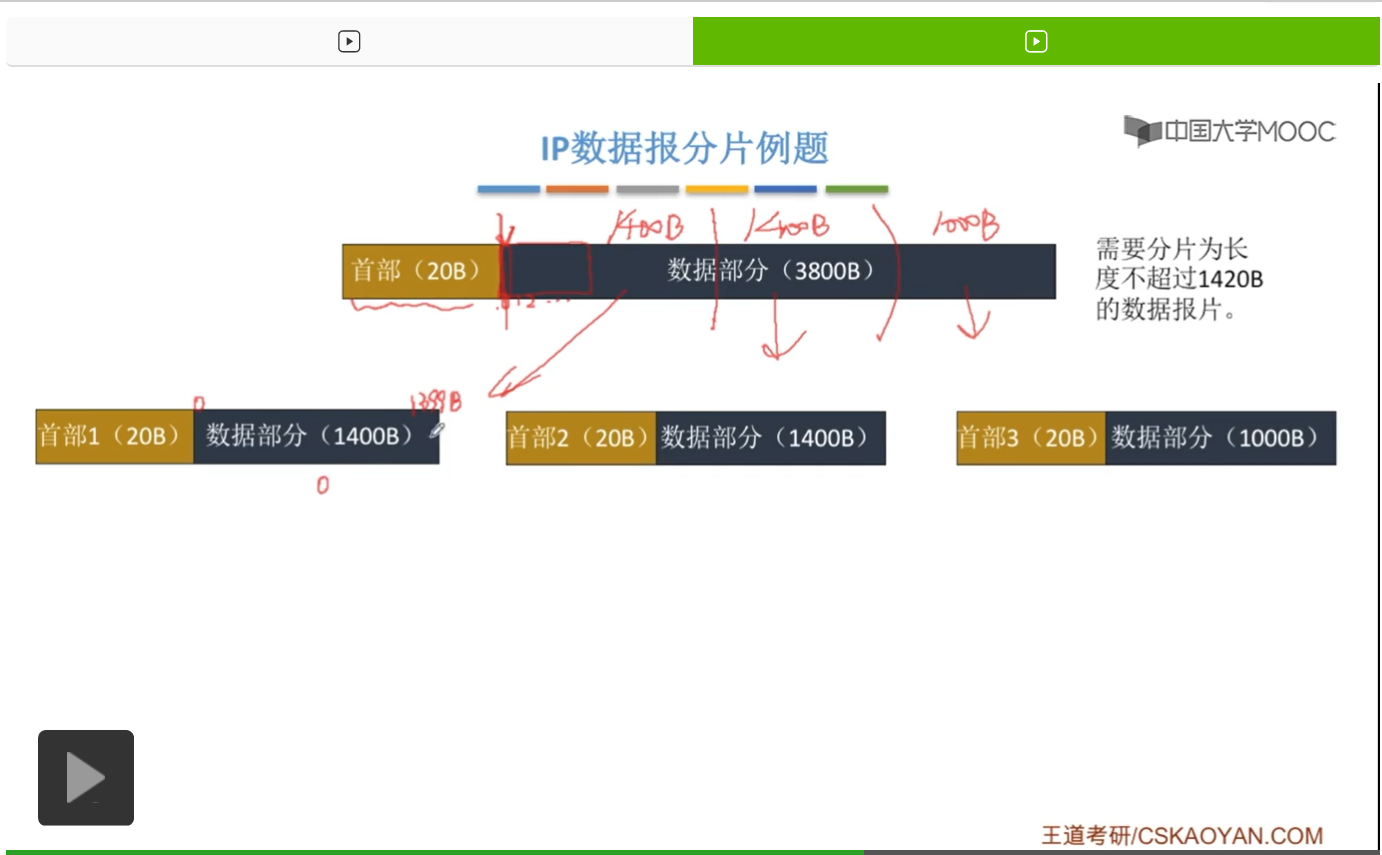
那么再来看第二个分片,第二个分片它的数据部分是1400字节。那它从哪个字节开始的呢?刚才第一个字节是从1399字节结束。这就是1399字节。那这个第二个分片就要从1400,1400字节开始,所以它这个第一字节对应的就是1400字节。那1400字节呢在之后再查一个1400字节,也就到了2799字节。就是说这个第二个分片,它的最后一个字节,是原来数据部分的2799个字节的位置。那我们再来看这个第二个分片它的偏移量是多少。我们还是可以把它还原回去。我们还原在这儿,从1400字节开始,也就是求这样一段长度是多少。那自然就是用1400字节,也就是它刚开头的那个位置,然后呢再除以8,也就等于175。因此,得到的这个片偏移量,啊这个片偏移量就是175,就应该添到这个二号分片它首部的片偏移量字段当中。
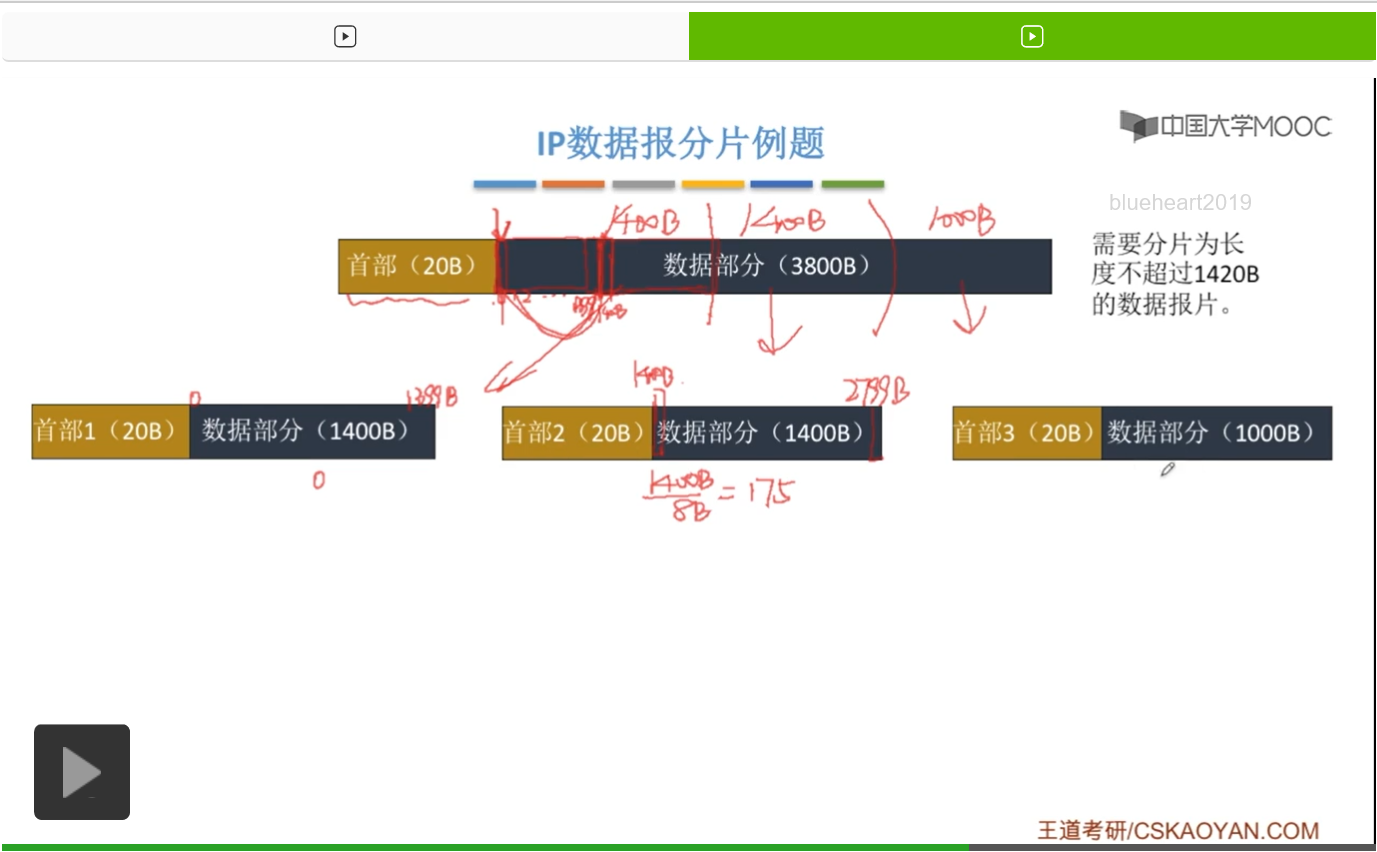
那再来看第三个分片,第三个分片呢它的数据部分