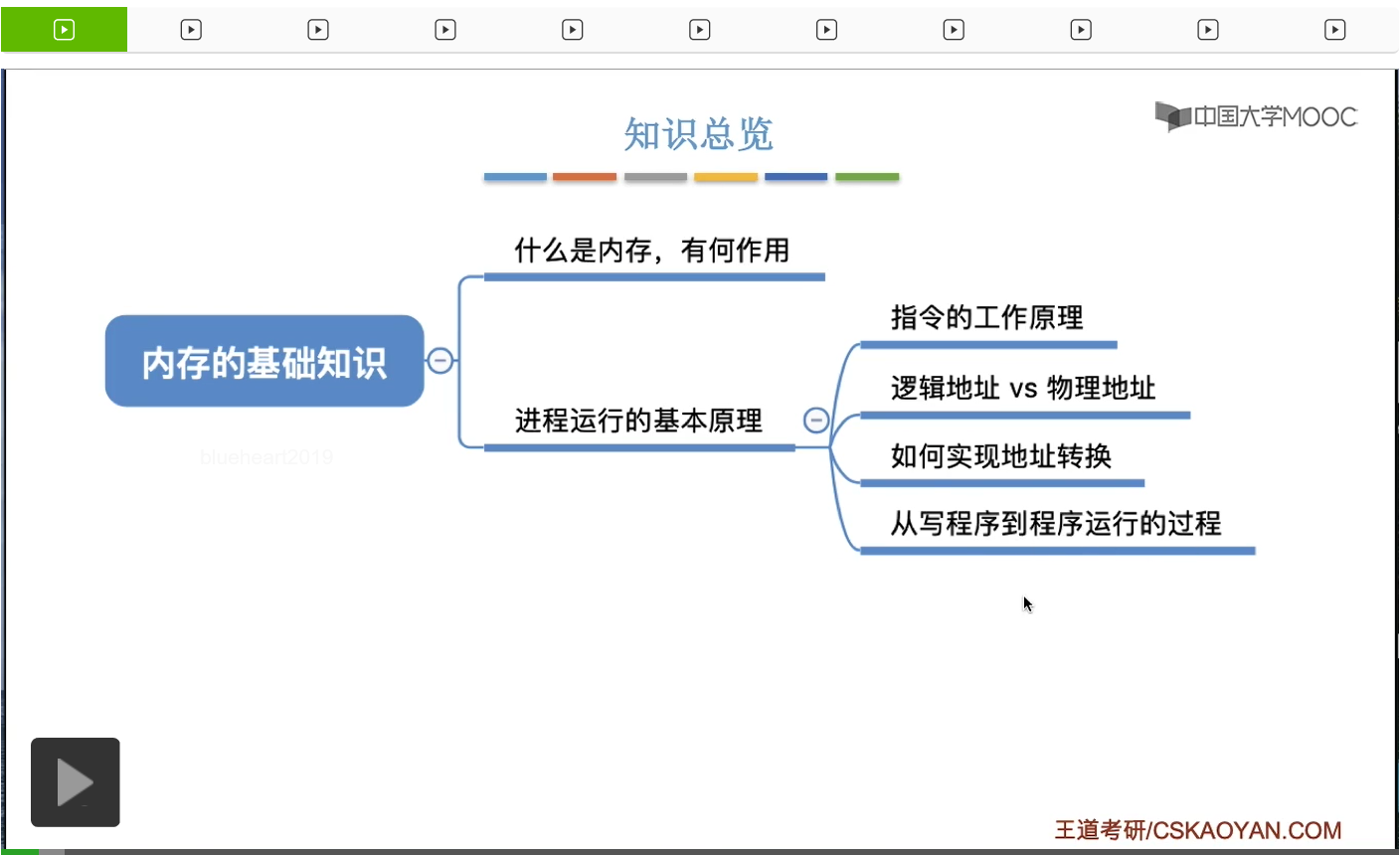
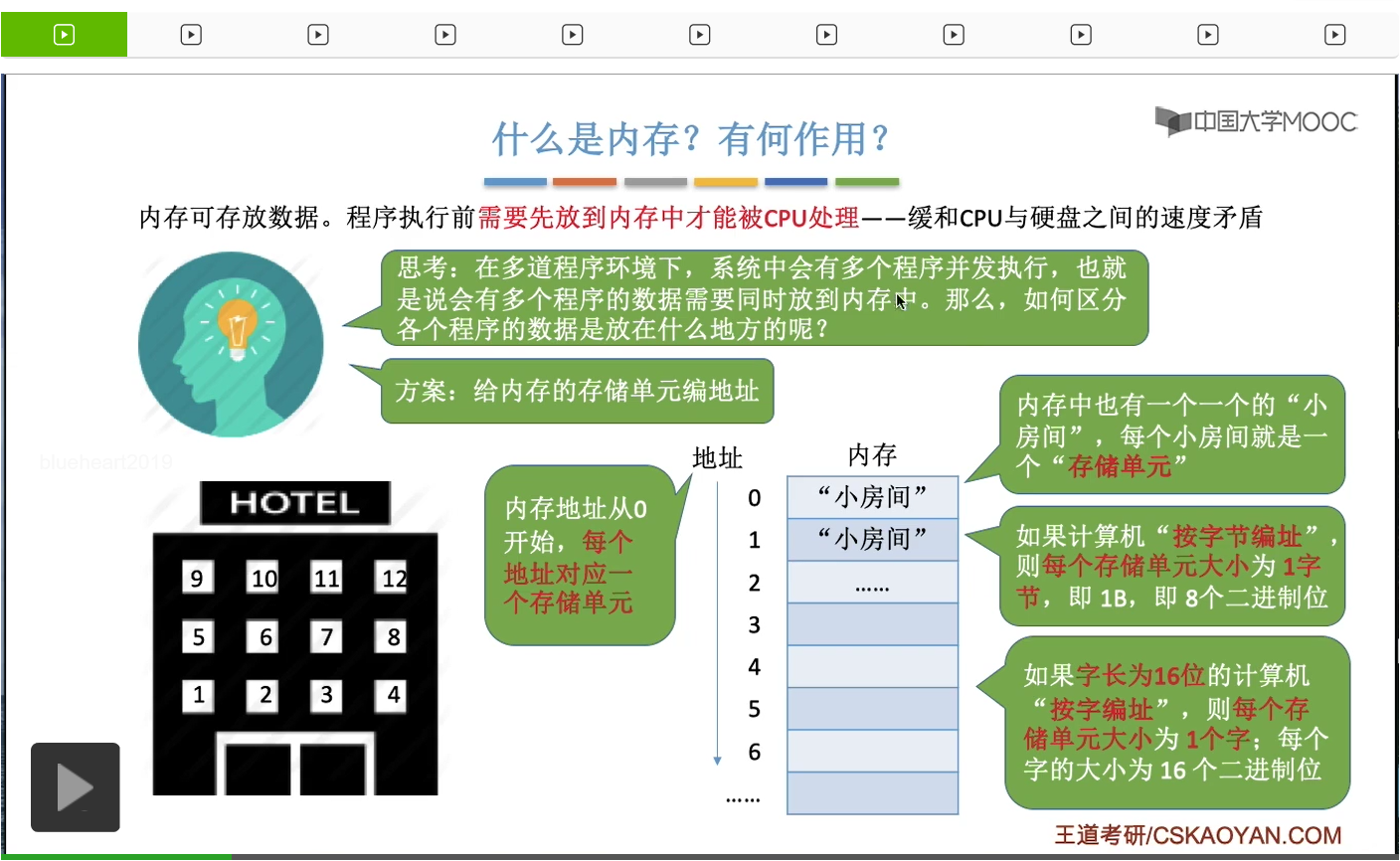
其實内存它的作用就是用來存放數據。我們的程序本來是放在外存、放在磁盤當中的,但是磁盤的讀寫速度很慢,而CPU的處理速度又很快,所以如果CPU要執行這個程序,程序相關的數據都是從外存讀入的,那麽很顯然CPU的這個速度會被外存的速度給拖累。所以爲了緩和這個CPU和硬盤、外存之間的速度矛盾,所以我們必須先把我們要執行的、CPU要處理的這些程序數據把它放入内存裏。既然我們的内存是存放數據的,那麽我們的内存當中可能會存放很多很多數據,那操作系統是怎麽區分各個程序的數據是放在什麽地方的呢?那爲了區分這些數據存放的位置,就需要給内存進行一個地址的編號。就有點類似於說我們去住酒店的時候,怎么區分我們每個人住在哪個房間?其實很簡單,酒店的做法就是給每個房間編號,那我們的内存其實和這個酒店是一樣的,只不過酒店的這些房間裏你可以存的是人,而内存當中,它的這些“小房間”裏,它存的是一個一個的數據。那内存會被劃分成這樣一個一個的“小房間”,每個小房間就是一個存儲單元。那接下來在劃分的這些存儲單元之後,就需要給這些存儲單元進行一個編號。那内存的這個地址編號一般來説是從零開始的,然後依次遞增。并且每個地址會對應一個數據的存儲單元,也就是會對應一個“小房間”。那麽,這樣的一個存儲單元可以存放多少數據呢?這個具體得看計算機的編址方式。我們在操作系統這門課當中大部分遇到的情況是會告訴你說計算機按字節編址,按字節編址的意思就是一個地址它對應的是一個字節的數據,也就是說這樣的一個存儲單元,它可以存放一個字節,而一個字節它又由8個二進制位組成,也就是8個0101這樣組成。那在有的題目當中也有可能會告訴我們這個計算機是按字編址的,如果它告訴我們是按字編址的話,那麽就意味著一個地址它所對應的存儲單元可以存放一個字,而一個字的長度是多少個比特位?這個具體得看題目當中給出的條件。有的計算機當中字長是16位,那麽它一個字的大小就是16個比特。也有的計算機可能字長是32位,字長是64位等等。總之,我們需要根據題目給的條件來判斷一個字它占有多少個比特位。好的,那麽在這個部分我們為大家介紹了内存的一些最基本的知識。什麽叫做存儲單元,就是用於存放數據的最小單元。另外,每一個地址可以對應這樣的一個存儲單元。而一個存儲單元可以存儲多少數據,那具體要看這個計算機它是怎麽設計的。對於我們考研來説,我們就要看它題目給的條件到底是什麽。
那在内存管理這個章節當中,可能會有很多題目會涉及到這個數據的一些基本單位。而對於不考計組的同學來説可能對這些單位的描述是比較陌生的,所以我們在這個地方還需要再介紹一下一些常見的單位。比如說我們平時所説的一個手機,或者說一台電腦它有4GB内存,那除了GB之外,我們還經常看到什麽MB,KB這樣的單位。那所謂的1KB,其實就是2的10次方這麽多。而1MB,其實是2的20次方這麽多。而這裏的1GB,其實是2的30次方那麽多。所以這個地方4G其實它是一個數量,而B是一個數據的單位,這個大BByte指的是字節,小b小寫的b它指的是bit,是一個比特位,一個二進制位。一個Byte也就是一個大B等於8個小b,所以如果一個手機有4GB内存的話那麽就意味著這個手機的内存當中它可以存放4*2^30這麽多個字節的數據。所以如果這個手機或者這個電腦它是按字節編址的,那麽這個内存的地址空間就應該是4*2^30這麽多個存儲單元。每一個存儲單元可以存放一個字節。那我們知道,在計算機的世界當中,所有的這些數字其實都是用二進制0101這樣來表示的。包括我們的内存地址,其實也需要用二進制來表示。所以有的題目當中可能會告訴我們,内存的大小是多少。比如說内存大小是4GB,并且告訴我們這個内存是按字節編址的,題目可能會問我們到底需要多少個二進制位才能表示這麽多個存儲單元也就是2^32次方個存儲單元。那對於跨考的同學來說,一定要去了解一下二進制編碼還有二進制數和這個十進制數的一個轉換關係。對二進制比較熟悉的就可以很快速地反應出來這麽多個存儲單元肯定就需要32個二進制位來表示。所以如果手機的内存是4GB,并且它是按字節編址的,那麽對於這個手機來説它的地址至少需要用32個二進制位來表示。好的那麽再次提醒,對於跨考的同學來說,如果二進制和十進制的這個轉換不是很熟練的話,一定要下去練習。

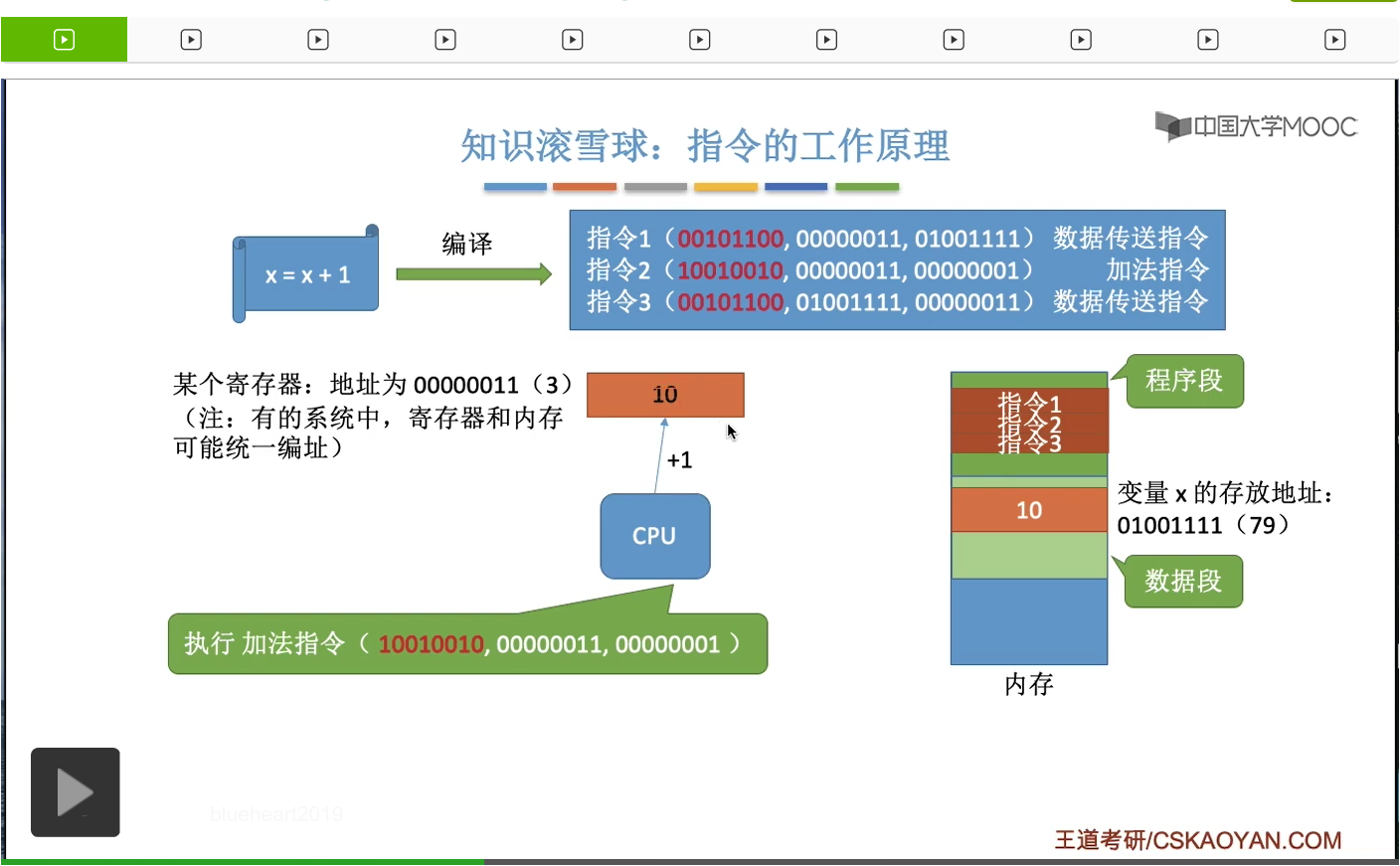
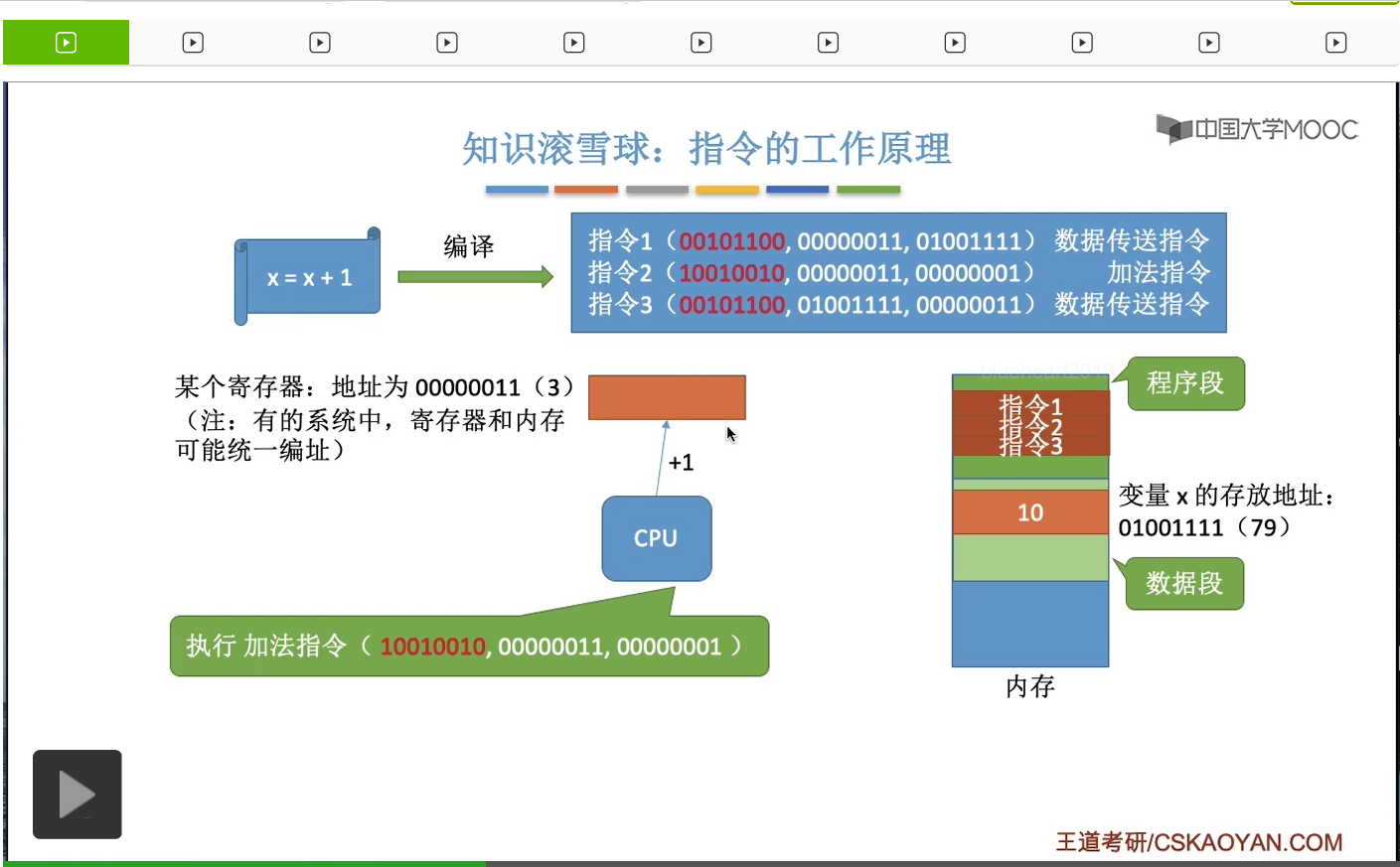
在瞭解了内存的作用、内存的存儲單元、内存的地址這些概念之後,我們再結合之前我們提到過的一些基礎再給大家更進一步深入地講解一下指令工作的具體原理。這個知識點有助於大家對後面的那些内容的更深入的理解。那我們之前的學習當中提到過,其實我們用高級語言編程的代碼經過編譯之後,會形成與它對應的等價的一系列的機器語言指令。每一條指令就是讓CPU幹一件具體的事情。比如說我們用C語言寫的x=x+1;這樣一個很簡單的操作,經過編譯之後可能會形成這樣的三條與它對等的機器指令。那當這個程序運行的時候,系統會爲它建立相應的進程,而我們之前學到過一個進程在内存當中會有一片區域叫做程序段就是用於存放這個進程相關的那些代碼指令的。另外還有一個部分叫做數據段,數據段就是用來存放這個程序所處理的一些變量啊之類的數據。比如說我們這兒的x變量,它就是存放在所謂的數據段裏。那我們來看一下這三條指令分別代表著什麽呢?CPU在執行這几條指令的時候首先它取出了指令1,然後指令1它發現由這樣的幾個部分組成。第一個部分紅色的這個部分叫做操作碼,就是指明了這條指令是要幹一件什麽事情。那這個地方的二進制碼我只是胡亂寫的,大家只需要理解它的原理就可以了。那我們假設這個什麽101100它代表的是讓CPU做一個數據傳送的事情。那後面這兩段數據又是指明了這個操作相關的一些必要的參數。比如說我們的指令1就是讓CPU從内存地址01001111把這個地方存放的數據把它取到對應十進制就是編號為3的這個寄存器當中。所以CPU在執行這個指令的時候,它就知道我現在要做的事情是要做數據的傳送。那怎麽傳送呢?我需要從地址為79的這個内存單元當中,把它裏面的數據取出來,然後把它放到編號為3的這個寄存器當中。所以指令1的執行就會導致編號為3的這個寄存器當中有了10這個數。把x的值放到了這個寄存器中。那在執行了指令1之後,CPU就會開始執行指令2。
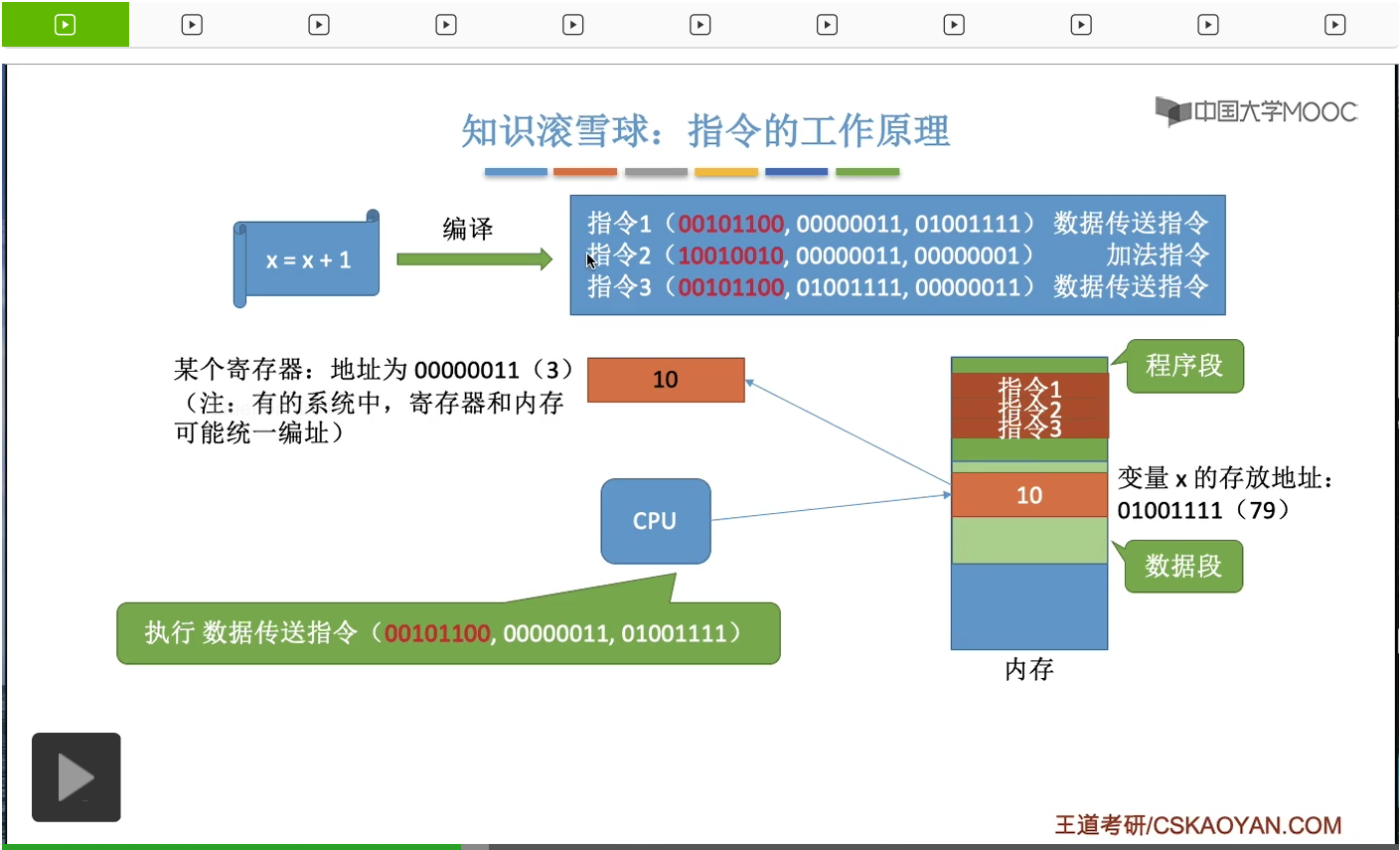
同樣的,它會解析這個指令2到底是要幹一件什麽事情。根據它前面的這個部分,也就是所謂的操作碼,它可以判斷出這個指令是要做一個加法操作,加法運算。而怎麽加呢?CPU需要把編號為00000011也就是換成十進制的話也就是編號為3的這個寄存器當中的内容加上1,所以根據這條指令CPU會把這個寄存器當中的值從10加1,也就是變成11。

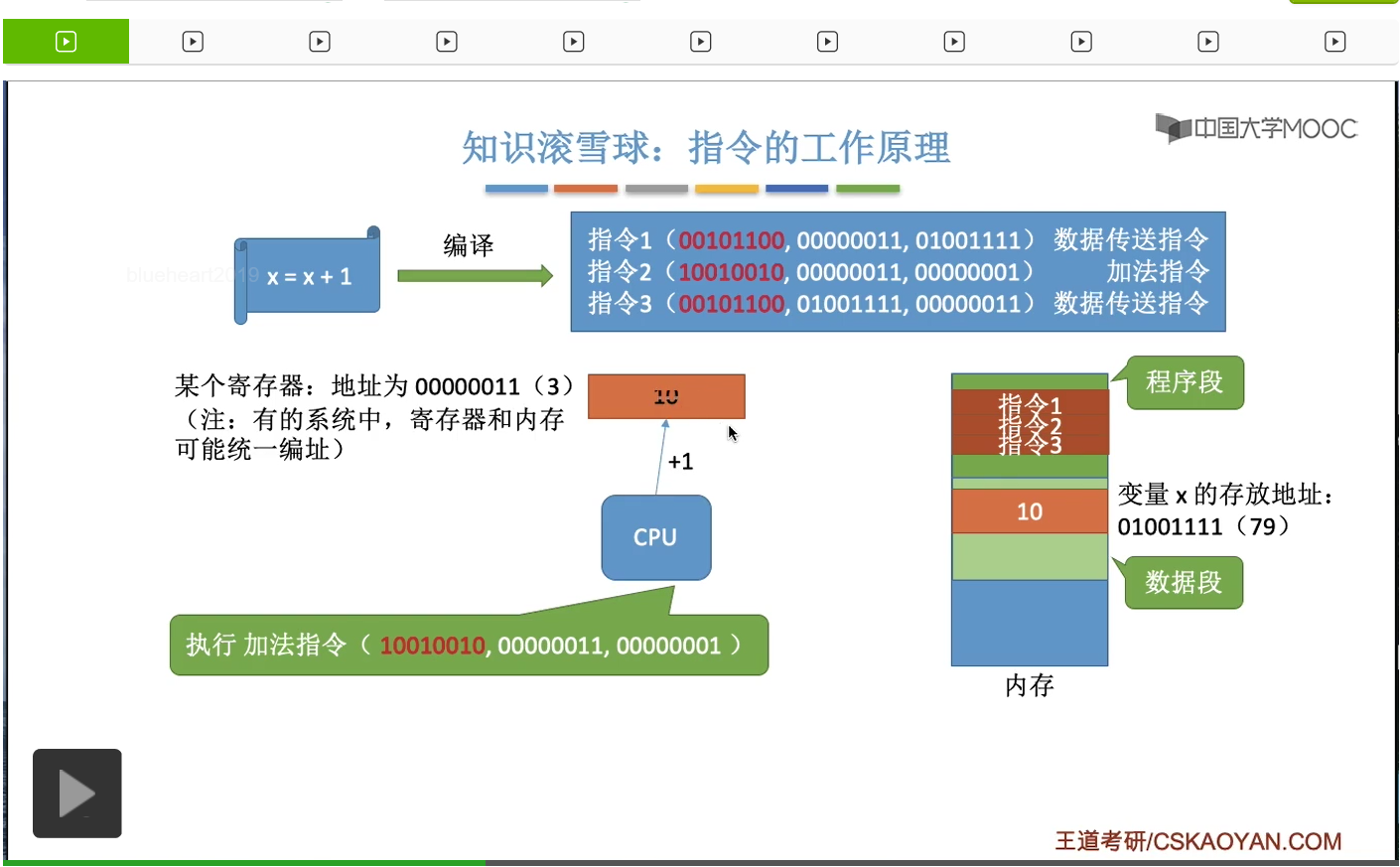
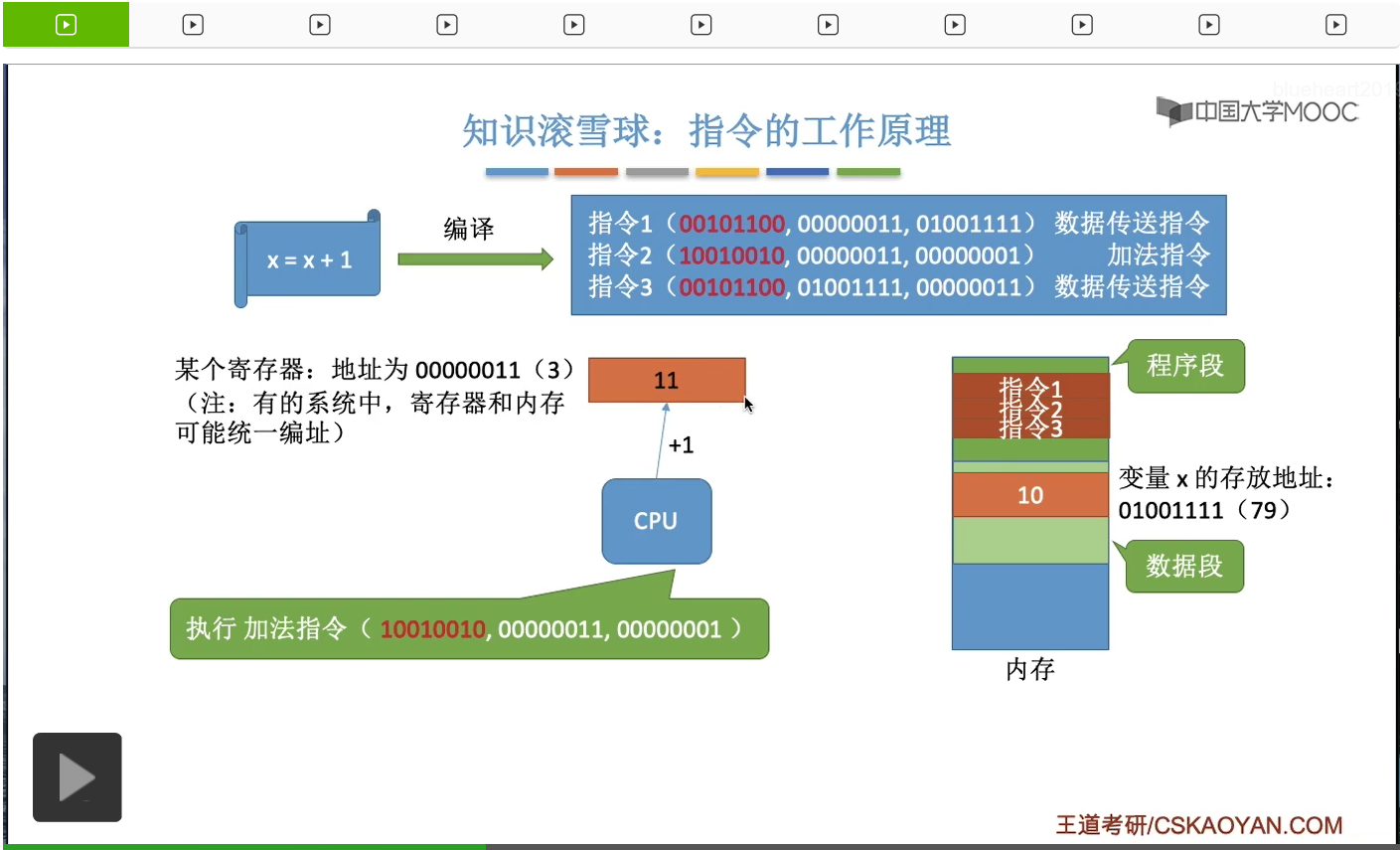
那再接下來它又執行的是第三條指令。這個指令同樣是一個數據傳送的指令。可以看到它的這個操作碼和第一個指令的操作碼是一樣的,就説明這兩條指令它們要幹的是同一個事情,是同一種指令。只不過它們的參數是不一樣的,大家可以對比著來看一下。那這個指令3是讓CPU幹這樣的一個事情。它需要把編號為3的這個寄存器當中的内容,把它寫回編號為01001111這個内存單元當中,所以CPU在執行第三條指令的時候,就會把這個寄存器當中的内容把它寫回x這個變量在内存當中存放的那個地址。因此這就完成了x=x+1;這樣的一個操作。當然剛才我們講的這三條指令只是我自己胡亂寫的,其實并不嚴謹。如果大家想要了解這些指令真正的什麽操作碼啊參數啊到底是什麽樣一種規範,那還需要學習計算機組成原理。但是對於不考那門課的同學來説,只要理解到這一步就差不多了。其實CPU在執行這些一條一條指令的過程當中,它就是在處理這些内存啊或者寄存器當中的數據,而怎麽處理這些數據,怎麽找到這些數據呢?它就是基於地址這個很重要的概念來進行的。我們的内存會有它自己的一些地址編址,同樣的我們的寄存器也會有一些它自己的地址編址。總之我們的程序經過編譯之後,會形成一系列等價的機器指令。在這個機器指令當中它會有一些相應的參數,告訴CPU你應該去哪些地址去讀數據,或者往哪些地址寫數據。那在剛才我們講的這個例子當中,我們默認了我們所提到的這個進程它是從0這個地址開始連續存放的。所以在它的這個指令當中,是直接指明了各個變量的存放位置。比如說x的存放地址,它就直接把它寫死在了這個指令裏。它是存放在79這個地址所對應的存儲單元裏的。那接下來我們要思考的一個問題是這樣的,如果我們的這個地址它不是從零開始存放的,而是從別的地址開始存放的,會不會導致我們的這個進程的運行出現一些問題呢?我們來具體看一下。
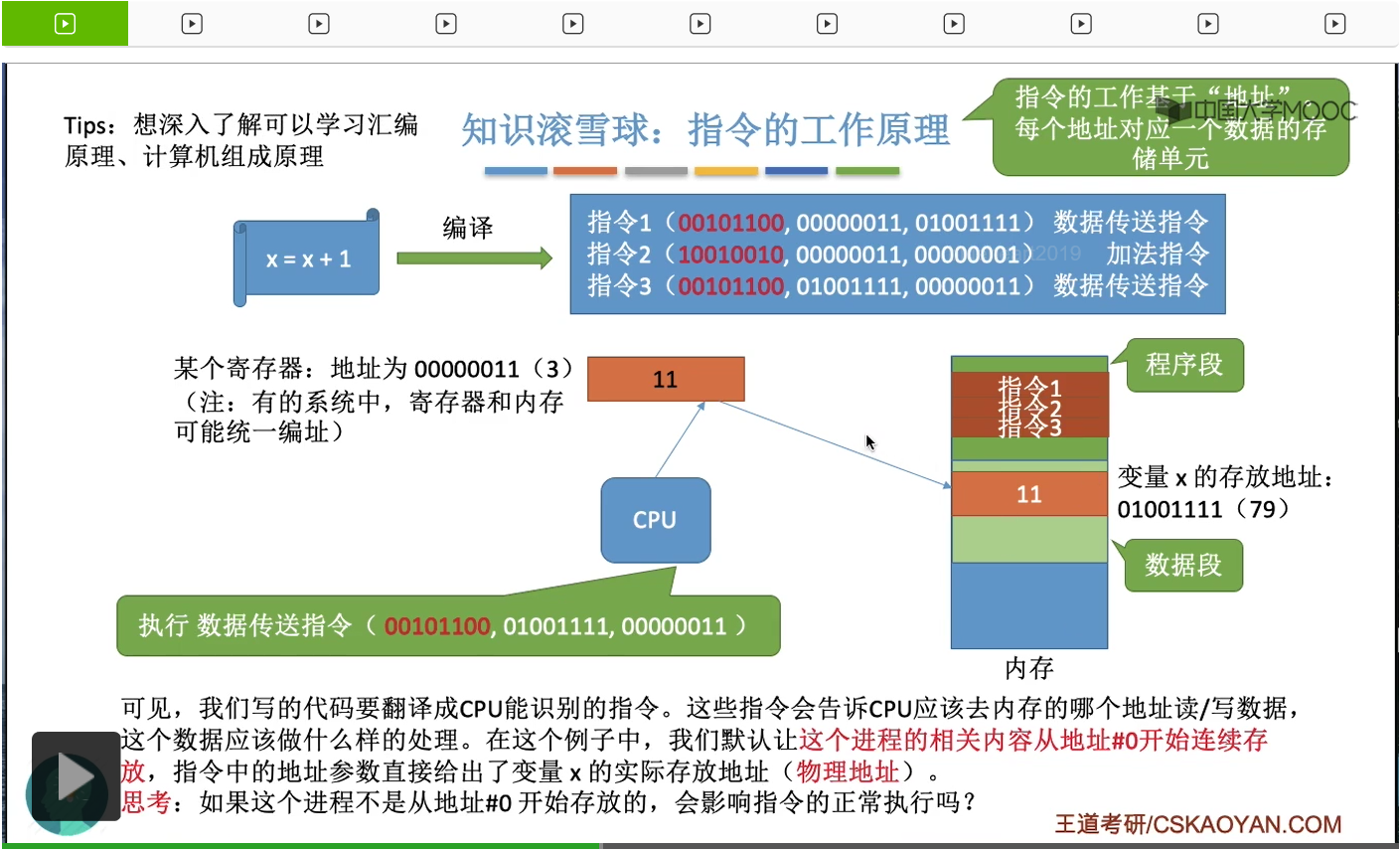
這個可執行文件在Windows系統當中就是.exe,這個可執行文件又可以稱作為裝入模塊。這個概念我們之後還會具體細聊。總之我們形成了這個裝入模塊,形成了這個可執行文件之後,就可以把這個可執行文件放入内存裏然後就開始執行這個程序了。不過需要注意的是,我們所形成的這個可執行文件,它的這些指令當中所指明的這些地址參數,其實指的是一個邏輯地址,一個相對地址。所謂的相對地址就是指,這個地址指的是它相對於這個進程的起始地址而言的地址。有點繞,不過其實並不難理解,在之前的那個例子當中,我們是默認了這個進程它相關的這些數據是從内存地址為零這個地方開始存放的。所以這條指令它是要進行x這個變量的初始化,并且它指明了x這個變量它存放的地址是79,它的初始值為10,所以CPU在執行這條指令的時候,它會往79這個地址所對應的内存單元裏寫入x的初始值10,那這是我們剛才提到的情況。我們的這個程序裝入模塊,它是從内存地址為零這個地方開始往後依次存放的,所以我們的指令當中指明的這些地址并不會出現什麽問題。
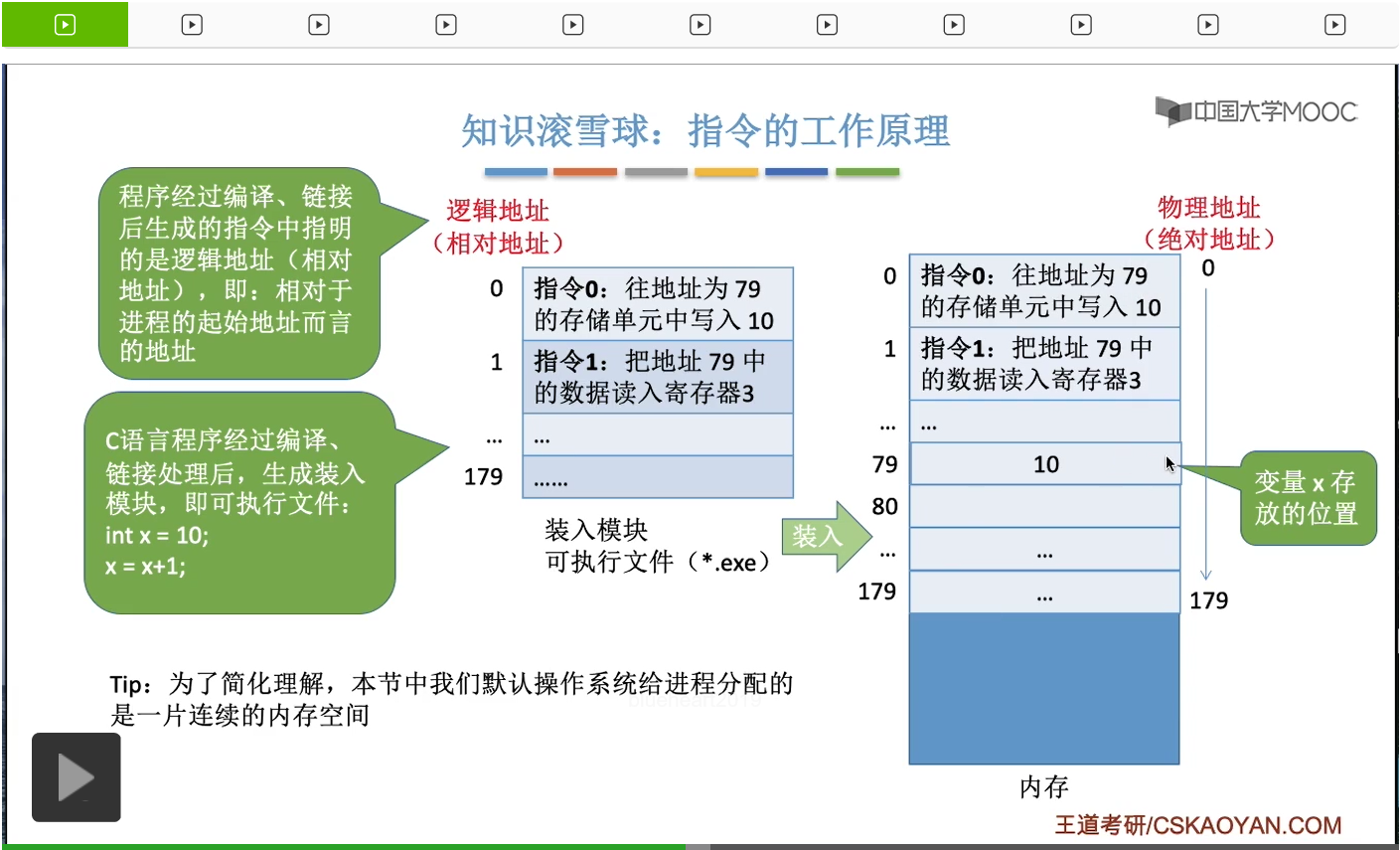
那接下來再來看另一種情況。假設我們的這個程序的裝入模塊,它裝入内存的時候,并不是從地址為零的地方開始的,而是從地址為100的這個地方開始的。那麽這就意味著操作系統給這個進程、給這個程序分配的地址空間其實是一百到279這麽多,所以如果是這種情況的話,這個程序的這些邏輯地址和它最終存放的物理地址就會出現對應不上的情況。比如説我們的指令零是要給x這個變量進行初始化,但是這個指令指明了x這個變量的值它是要寫到地址為79的那個内存單元當中的,所以如果CPU執行這條指令的話,
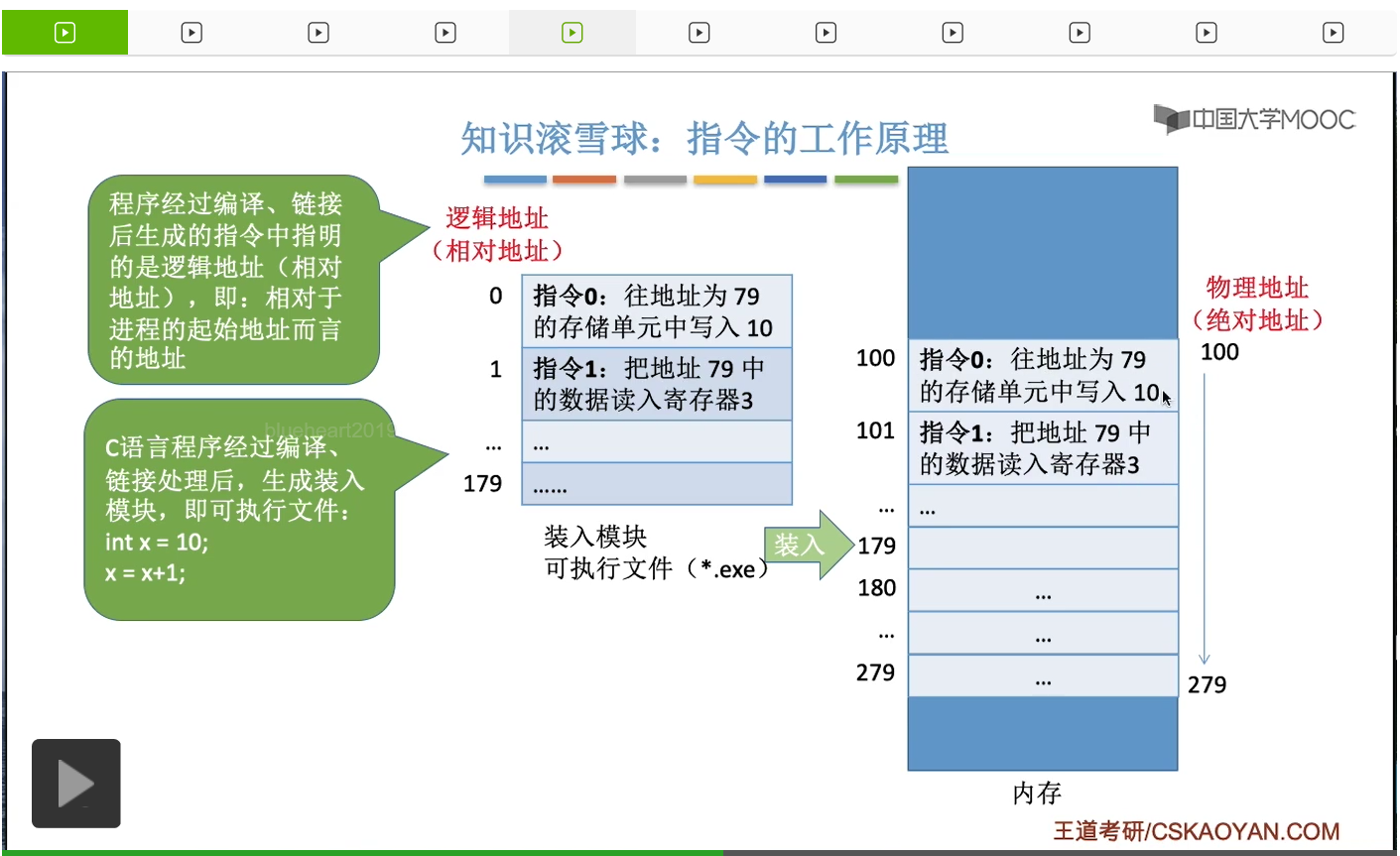
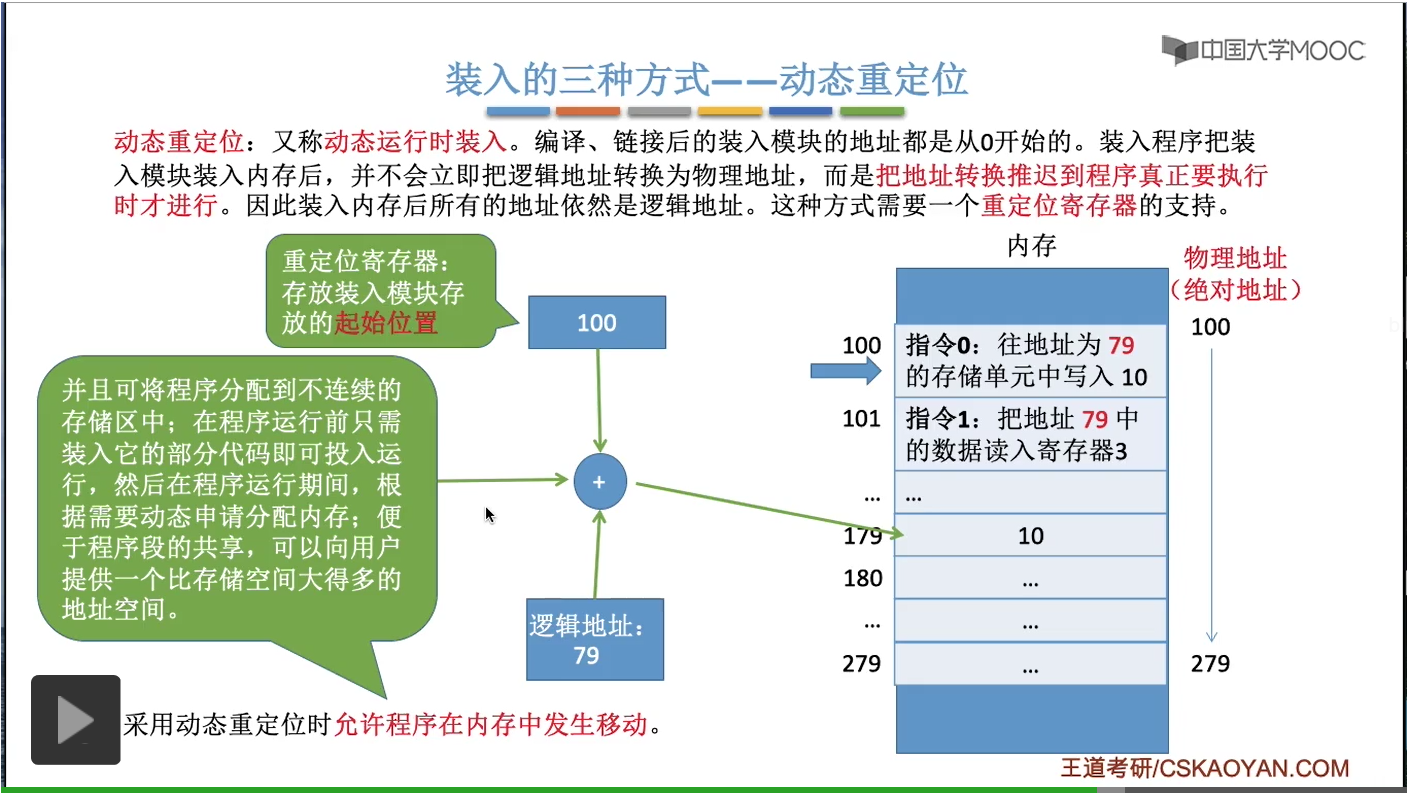
它就會把x的值10把它寫在上面的這個地方,79這個地址所對應的内存單元裏。而這上面的這一片内存空間,極有可能是分配給其他進程的,所以也就意味著本來是這個進程它自己的數據然而它强行往其他進程的那個地址空間裏去寫入了自己的數據。那這顯然是一個危險的并且應該被阻止的一種行爲。而事實上在這個例子當中,我們期待的x這個變量的正確的存放位置,應該是從它的這個起始位置開始往後79個單位這樣的一個内存單元裏,也就是179這個地址所對應的内存單元當中。如果x的值寫在這兒,那就是沒問題的。相信大家對邏輯地址和物理地址應該有一個比較直觀的體會了。總之我們的程序它編譯鏈接等等之後,所形成的這些指令當中一般來説使用的是邏輯地址,也就是相對地址。而這個程序最終被裝到内存的什麽位置,這個其實是我們沒辦法確定的,所以在内存管理這個章節當中有一個很重要的我們需要解決的問題就是如何把這些指令當中所指明的這些邏輯地址把它轉換為最終的物理地址、正確的物理地址。那這個小節當中我們會介紹三種策略來解決這個地址轉換的問題。這三種策略分別是絕對裝入、可重定位裝入(靜態重定位)和動態運行時裝入(動態重定位)。那我們會依次來看一下這三種策略是怎麽解決這個問題的。
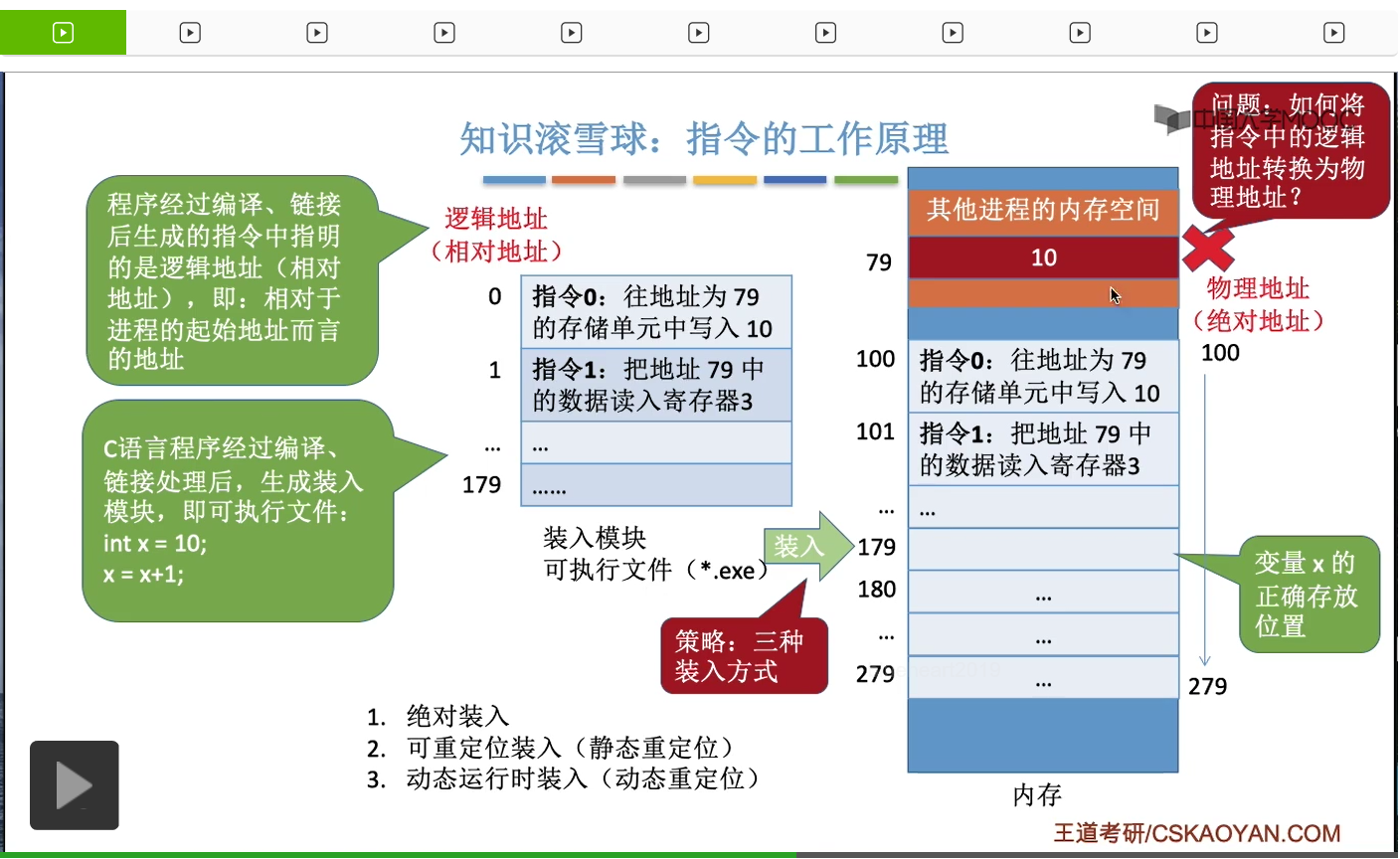
首先來看第一種策略,絕對裝入。所謂的“絕對裝入”就是指,如果我們能夠在程序放入内存之前就知道這個程序會從哪個位置開始存放,那在這種情況下我們其實就可以讓編譯程序把各個變量存放的那些地址直接把它修改成一個正確的一個絕對地址。那還是以剛才的那個例子為例。比如說我們先前就已經知道了我們的那個裝入模塊它是要從地址為100的地方開始存放的,那麽按照之前我們的介紹來説,這個裝入模塊它裏面所使用到的這些地址都是相對地址,但是如果我們知道它是從100這個地址開始裝入的,

那其實在編譯的時候就可以由編譯器把它改爲正確的地址。比如按照之前的分析我們知道,x那個變量它正確的存放地址應該是179。所以接下來我們把這個裝入模塊從起始地址為100的這個地方開始裝入,那麽當這個程序運行的時候就可以把它的這些變量存放到一個正確的位置了,所以這是第一種方式。在編譯的那個時候,就把邏輯地址轉換成最終的物理地址。但是有一個前提就是我們需要知道我們的裝入模塊它會裝到内存的哪個位置,從什麽地方開始裝。所以這種方式的靈活性其實很差,它只適用於單道程序的環境,也就是早期的還沒有操作系統的那個階段,使用的就是這樣的一種方式。大家可以想一下,如果采用絕對裝入這種方式的話,那麽假設我的這個可執行文件此時要運行在另外一臺電腦當中,而另一臺電腦當中又不能讓它從100這個位置開始存放,那是不是就意味著這個程序換一臺電腦它就不能執行了,所以這種方式它的靈活性是特別低的。

第二種裝入方式叫做可重定位裝入,又叫靜態重定位方式。如果采用這種方式的話,那麽編譯、鏈接最終形成的這個裝入模塊這些指令當中使用的地址依然是從0開始的邏輯地址,也就是相對地址。而把這個地址重定位這個過程是留在了裝入模塊裝入内存的時候進行。比如說這個裝入模塊裝到内存裏之後,它的起始物理地址是100,那麽如果我們采用的是靜態重定位這種方式的話,就意味著在這個程序裝入内存的時候,我們同時還需要把這個程序當中所涉及的所有的這些和地址相關的參數都把它進行加100的操作。比如說指令0我們就需要把它加100,然後指令1也對79這個内存單元進行了操作,所以這個地址我們也需要把它加100。所以靜態重定位這種方式就是在我們的程序裝入内存的時候再進行這個地址的轉換。那這種方式的特點是我們給這個作業分配的這些地址空間必須是連續的,并且這個作業必須一次全部裝入内存。也就是說在它執行之前就必須給它分配它所需要的全部的内存空間。難道還可以只分配它所需要的部分空間嗎?那這個問題大家在學習了之後的虛擬存儲技術之後就會有更深入的了解。并且這個地方其實也不是特別重要。那靜態重定位這種方式它還有一個特點就是,在這個程序運行期間它是不可以移動的。這個很好理解,因爲我們的這些指令當中已經寫死了我們具體要操作那個物理地址到底是多少。如果這個程序這個進程相關的這一系列的數據發生了移動的話,那麽這個地址的指向又會發生錯誤。所以這是靜態重定位這種方式的一個局限性。

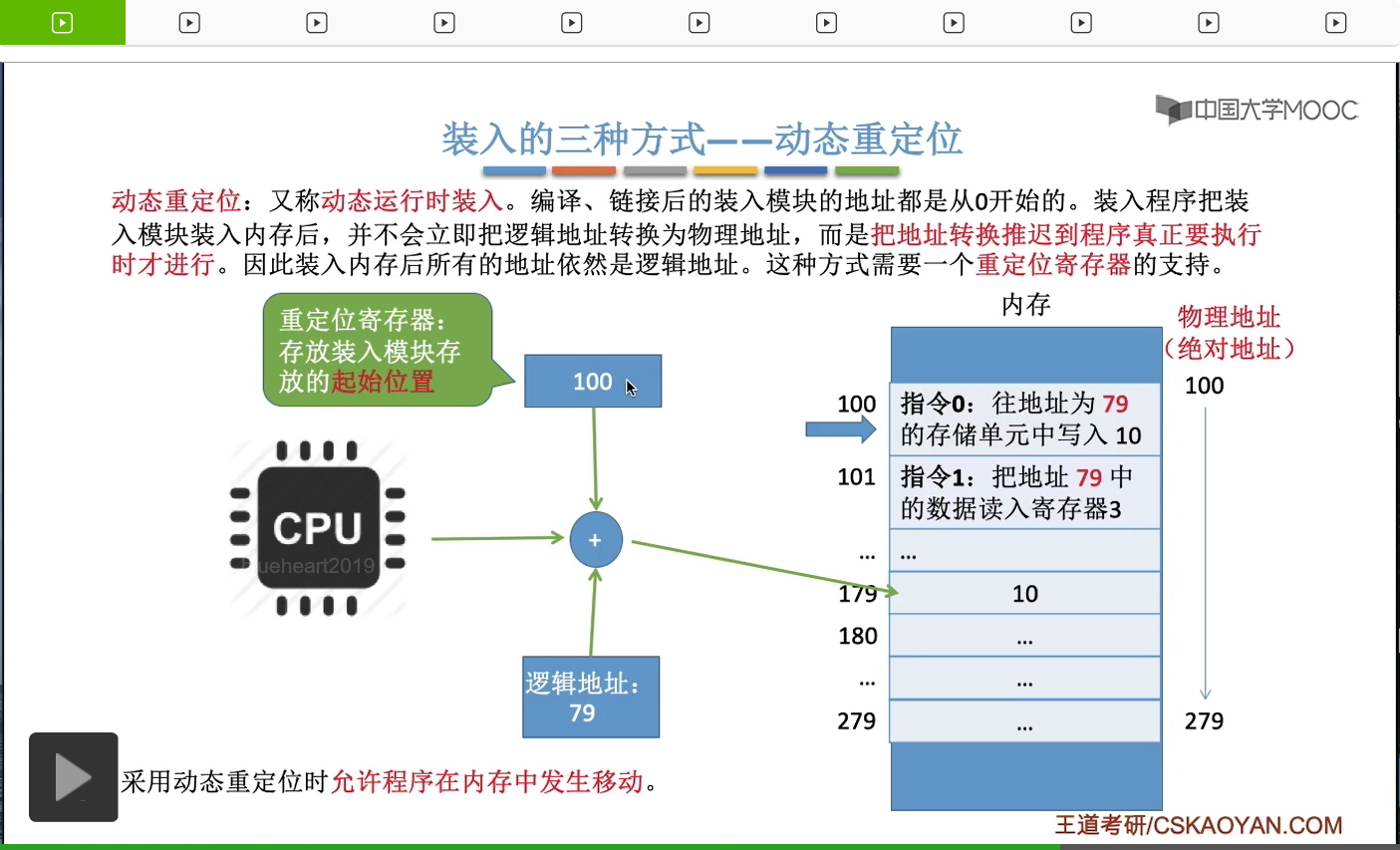
那最後我們來看一下現代的系統使用的這種地址轉換的機制,叫做動態重定位,又叫動態運行時裝入。那如果采用的是這種方式的話,程序經過編譯鏈接最後形成的裝入模塊當中,它這些指令所使用的其實也是邏輯地址也就是相對地址。并且這個可執行文件這個程序在裝入内存的時候,它們的這個指令當中所使用的同樣還是邏輯地址。如果一個系統支持這種動態重定位方式的話,那這個系統當中還需要設置一個專門的一個寄存器叫做重定位寄存器。重定位寄存器當中存放了這個進程,或者說這個作業它在内存當中的起始地址是多少,比如說我們的這個程序這個進程它是從起始地址為100的這個地方開始存放的,所以重定位寄存器當中我們就存放它的起始地址100。而當CPU在執行相應的這些指令的時候,比如說它在執行指令0的時候,這個指令0是讓他往地址為79的存儲單元當中寫入x這個變量的初始值10。CPU在對一個内存地址進行訪問的時候,它會做這樣的事情。它把邏輯地址和重定位寄存器當中存放的這個起始地址進行一個相加的操作,然後加出來的這個地址才是最終它可以訪問的地址。所以經過這樣的一步處理它就知道,指令0是讓它往地址為179的這個地方寫入數據10。那很顯然如果采用這種方式的話,我們想讓進程的數據在運行的過程當中發生移動是很方便的。比如說我們把這個進程的數據把它移到從200開始的話,那很簡單。我們只需要把重定位寄存器的值再修改成200就可以了,所以動態重定位方式有很多很多的優點。
它可以把程序分配到不連續的存儲區。那不連續的分配這個現在先不展開,經過后续的學習大家會有更深入的理解,這兒先簡單提一下。那這些内容現在还可能都看不懂,我们在学习了之后的虚拟存储管理之后就可以对这个特性有更深入的理解了。那这个地方我们也暂时不展开,把这个点的理解往后挪一挪。
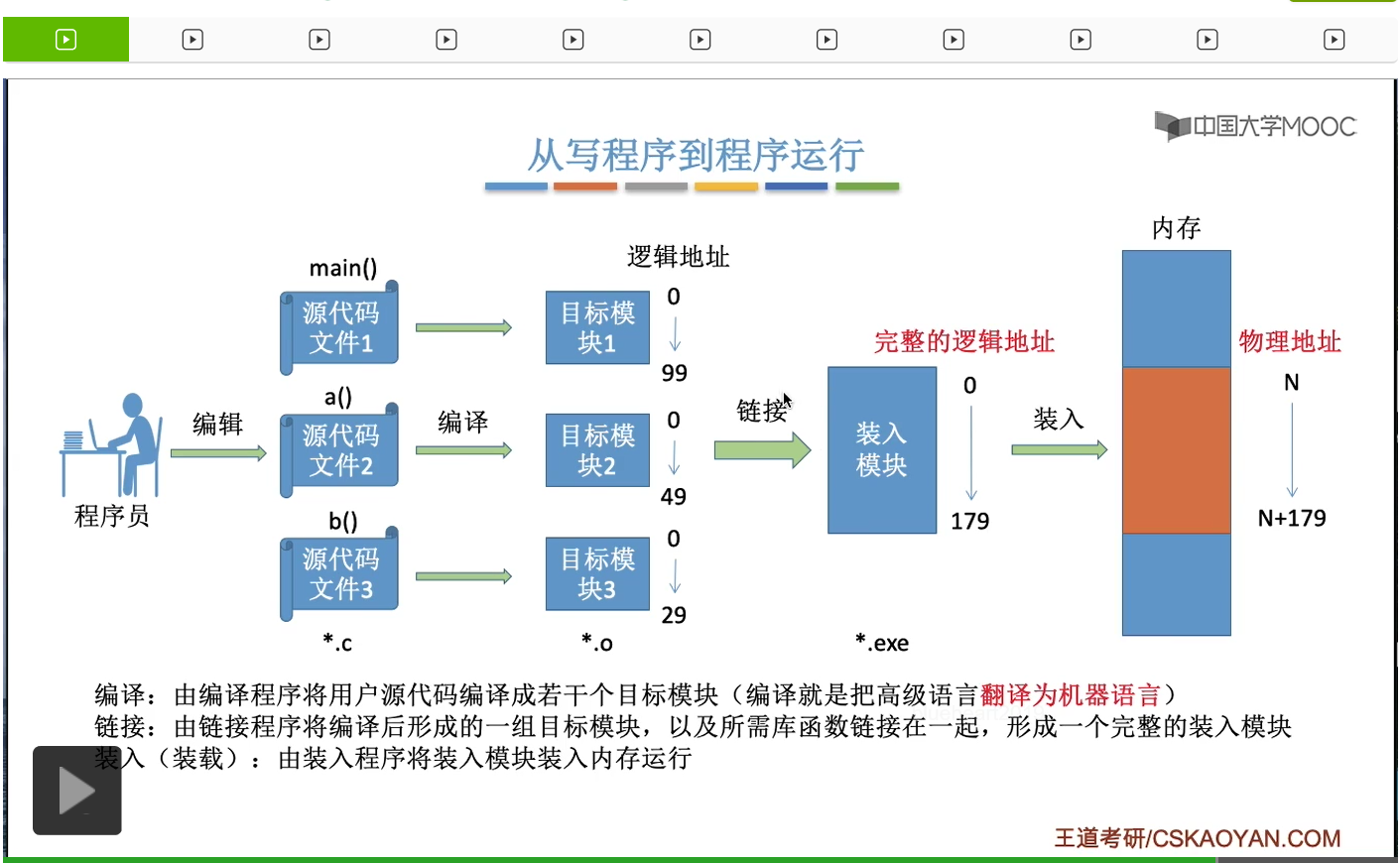
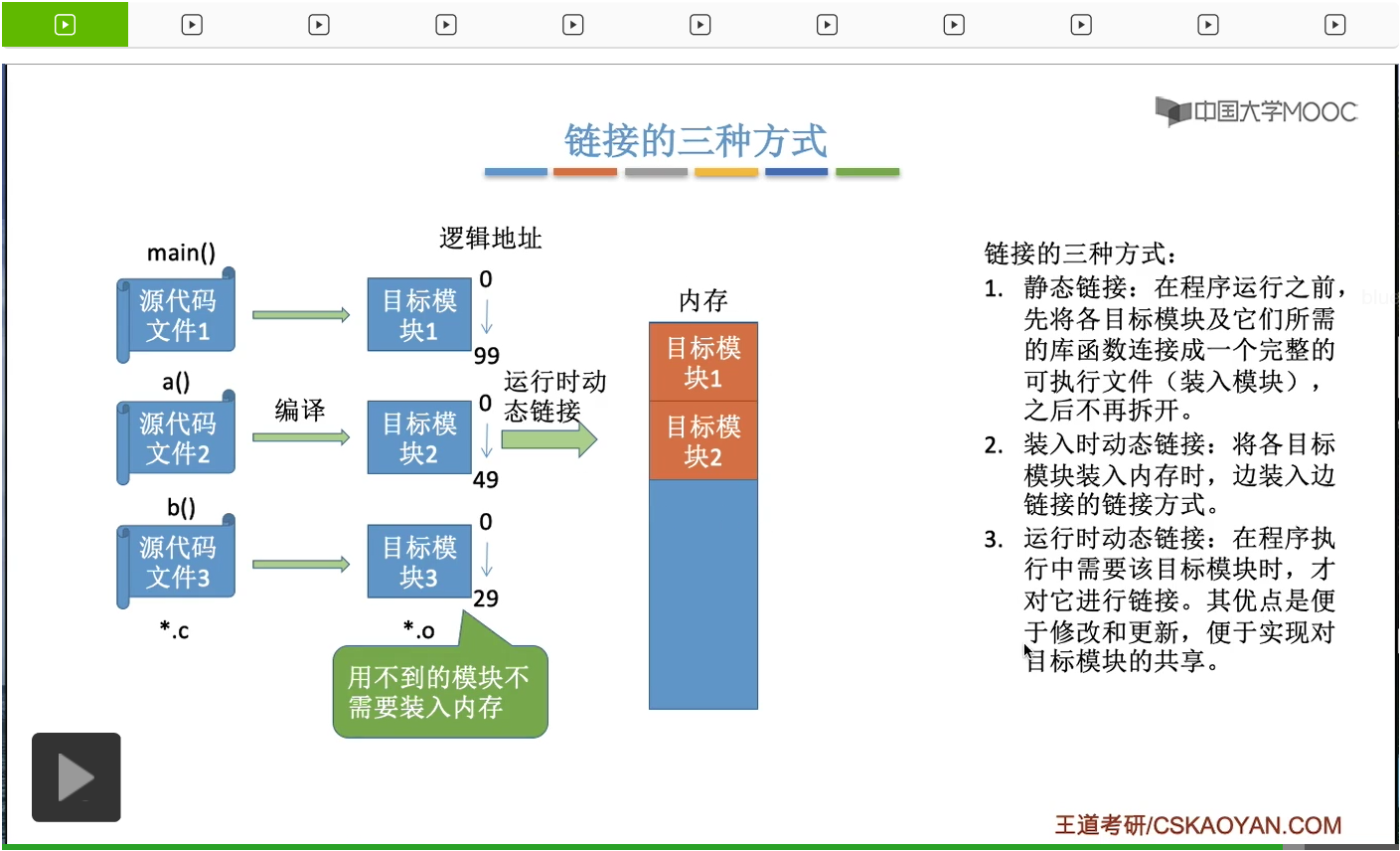
好的那么刚才我们介绍了内存的基本知识,介绍了内存的地址,介绍了什么叫逻辑地址什么叫物理地址,并且也介绍了三种装入方式来解决了逻辑地址到物理地址的转换这样的一个过程。那接下来我们再从一个更宏观更全局的这样的一个角度再来看一下我们从写程序到程序运行它所经历的步骤。目标模块文件在C语言里就是.o文件。并且这些目标模块当中其实已经包含了这些代码所对应的那些指令了,而这些指令的编址,都是一个逻辑地址也就是相对地址。每一个模块的编址都是从逻辑地址0开始的。所以经过了编译之后我们就把高级语言翻译成了与它们等价的机器语言。只不过每一个模块的逻辑地址的编址都是相互独立的,都是从0开始的。那接下来的一步叫做链接。这一步做的事情就是把这些目标模块都给组装起来,形成一个完整的装入模块。而在Windows电脑当中,所谓的装入模块就是我们很熟悉的.exe文件,也就是可执行文件。把这些目标模块链接起来之后,所形成的装入模块,就有一个完整的逻辑地址。当然在链接这一步,除了我们自己编写的这些目标模块需要链接以外,还需要把它们所调用到的一些库函数比如说printf啊之类的这些函数,也给链接起来,把它形成一个完整的装入模块。那有了装入模块或者说有了这个可执行文件之后,我们就可以让这个程序开始运行了。那程序要运行首先要做的事情就是我们刚才一直强调的那个过程,就是需要把这个装入模块装入内存当中,并且当它装入内存之后就确定了这个进程它所对应的实际的物理地址到底是多少。所以这就是我们从写程序到程序运行的一个完整的流程。那之前我们一直强调的是,装入这个步骤怎么完成,三种装入的策略可以实现逻辑地址到物理地址的转换。那接下来我们要介绍的是三种链接的方式,也就是这一步也有三种方法。
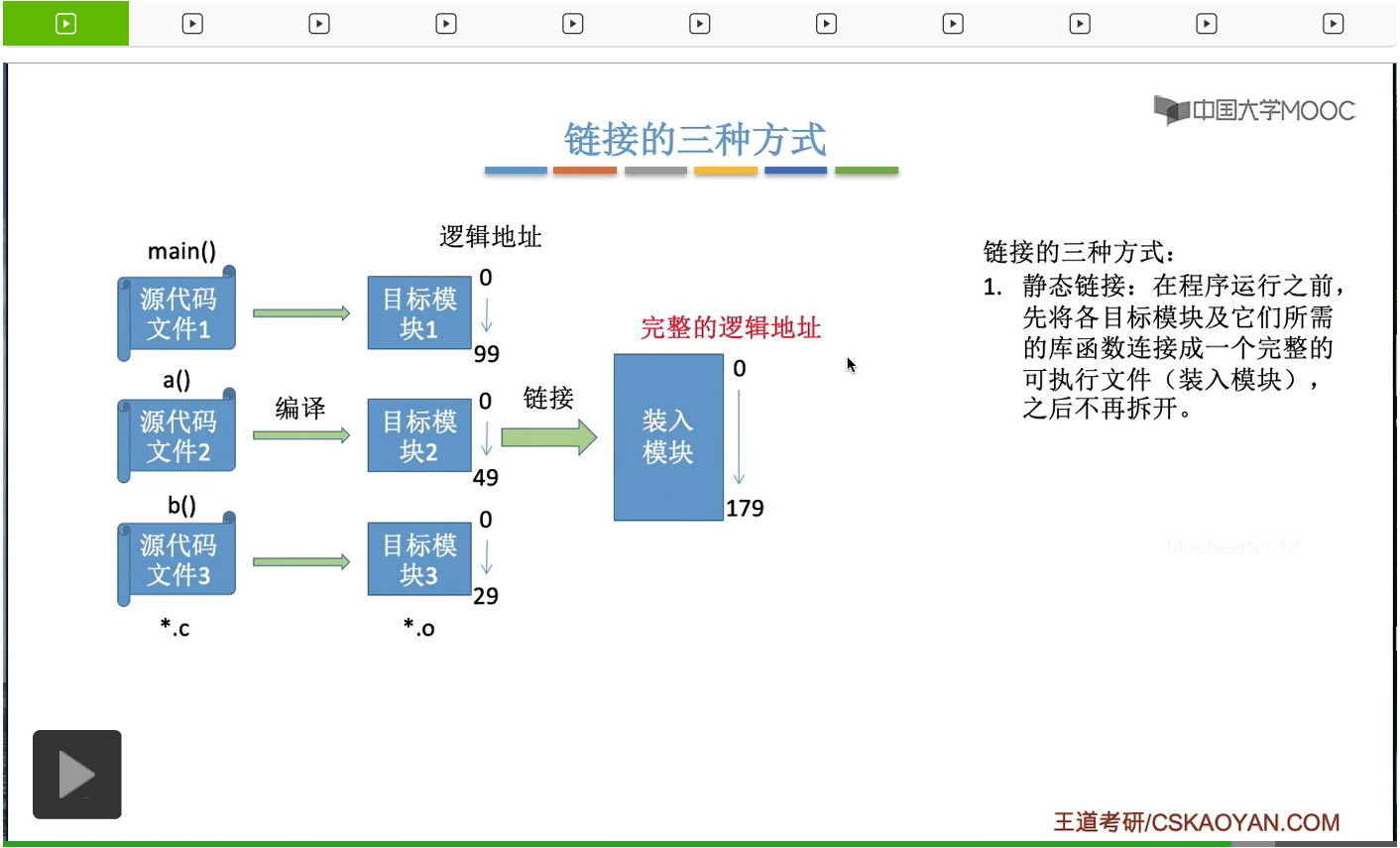
第一种链接方式叫做静态链接,就是指在程序运行之前就把这些一个一个的目标模块把它们链接成一个完整的可执行文件,也就是装入模块,之后便不再拆开,就是刚才我们所提到的这种方式。也就是说在形成了这个装入模块之后,就确定了这个装入模块的完整的逻辑地址。
那第二种链接方式叫做装入式动态链接,就是说这些目标模块不会先把它们链接起来,而是当这些目标模块放入内存的时候才会进行链接这个动作。
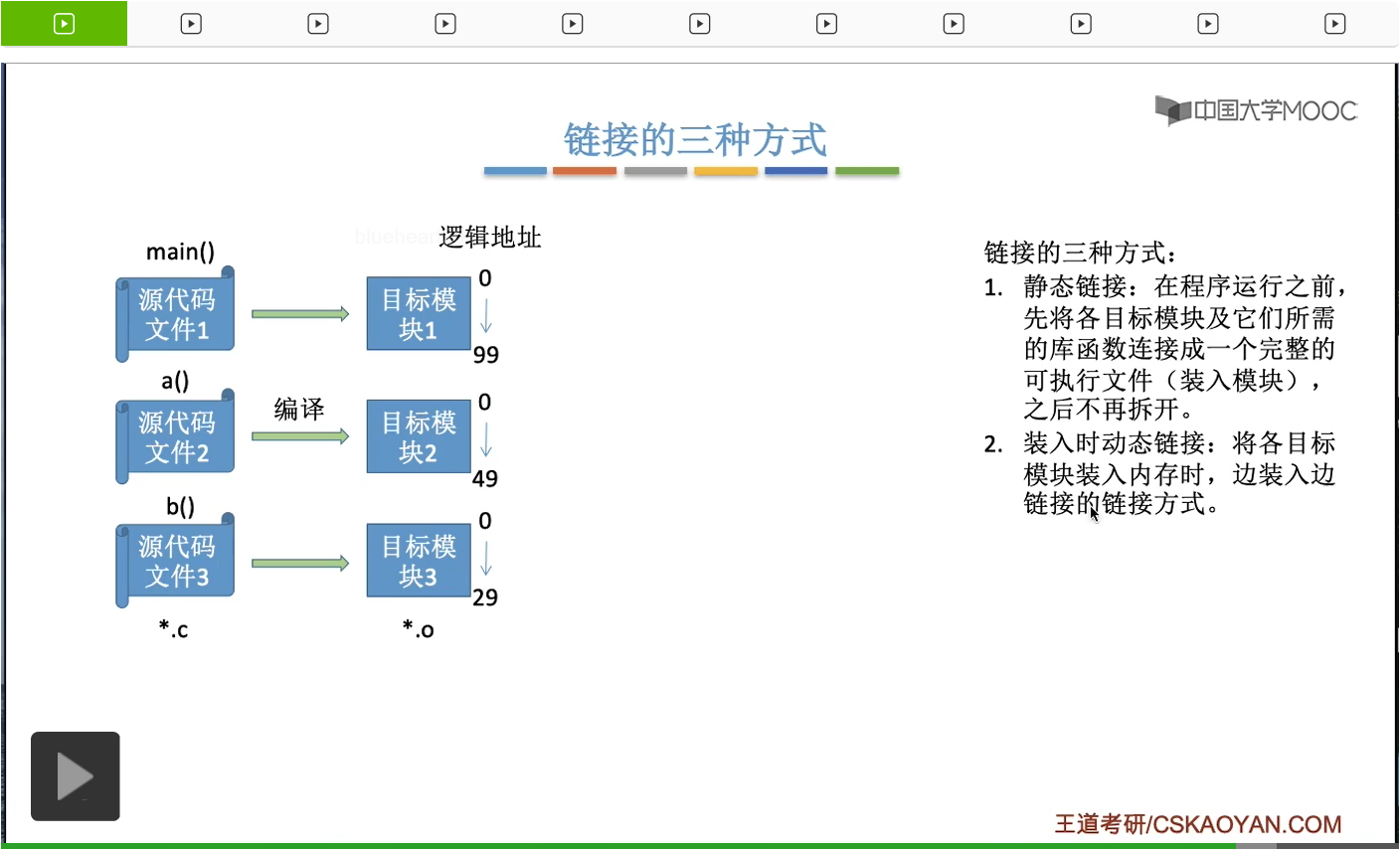
也就是说采用这种方式的话,这个进程的完整的逻辑地址是一边装入一边形成的。

那第三种方式叫做运行时动态链接,如果采用这种方式的话那么只有我们需要用到某一个模块的时候才需要把这个模块调入内存。比如说刚开始是main函数运行,那么我们就需要把目标模块1先放到内存当中,然后执行的过程当中可能又发现main函数需要调用到a这个函数,所以我们需要把目标模块2也把它放到内存当中,并且把它装入的时候同时进行一个链接的工作。那如果说b这个函数在整个过程当中都用不到的话,那目标模块3我们就可以不装入内存。所以采用这种方式很显然它的这个灵活性要更高,并且用这种方式可以提升对于内存的利用率。
而一个存储单元可以存放多少数据,这个我们需要看这个计算机它到底是按字节编址还是按字编址。如果是按字节编址的话,那么一个存储单元就是存放一个字节,也就是一个大B一个Byte。那内存地址其实就是给这些存储单元的一个编号,CPU可以根据内存地址这个参数来找到正确的存储单元。那之后我们又简单地介绍了指令工作的原理。一条机器指令由操作码和一些参数组成。操作码给CPU指明了你现在需要干一些什么事情,而参数指明了你现在需要怎么干。而这个参数当中可能会包含地址参数,而一般来说这个指令中所包含的地址参数指的都是逻辑地址也就是相对地址。所以为了让这个指令正常地工作,我们就需要完成从逻辑地址到物理地址的一个转换。那为了完成逻辑地址到物理地址的转换,我们又介绍了三种装入方式,分别是绝对装入、可重定位装入和动态运行时装入。其中可重定位装入又称作为静态重定位,而动态运行时装入又称为动态重定位。这三种装入方式是考研当中比较喜欢考查的内容。
那最后我们还介绍了从我们程序员写程序到最后的程序运行需要经历哪些步骤。首先是要编辑源代码文件,然后源代码文件经过编译形成若干的目标模块。目标模块经过链接之后形成装入模块,最后再把装入模块装入到内存。这个程序就可以开始正常地运行了。那我们还介绍了三种链接的方式分别是静态链接、装入时动态链接和运行时动态链接。其实经过刚才的讲解我们能够体会到,链接这一步就是要把各个目标模块的那些逻辑地址,把它们组合起来形成一个完整的逻辑地址,所以链接这一步其实就是确定这个完整的逻辑地址这样的一个步骤。而装入这一步又是确定了最终的物理地址,这个小节的内容其实考查的频率很低,只不过是为了让大家更深入地理解之后的内容所以才进行了一些补充。


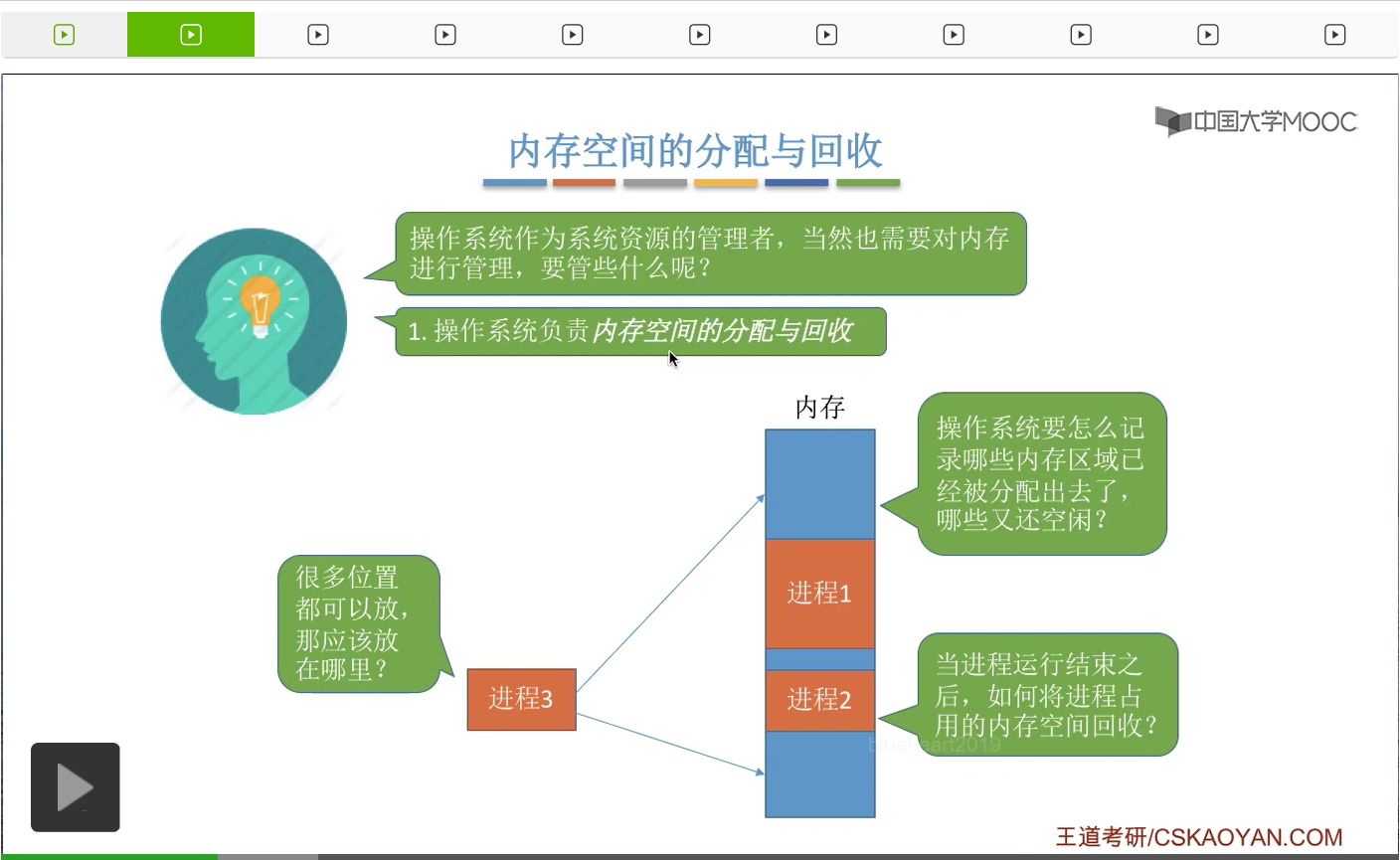
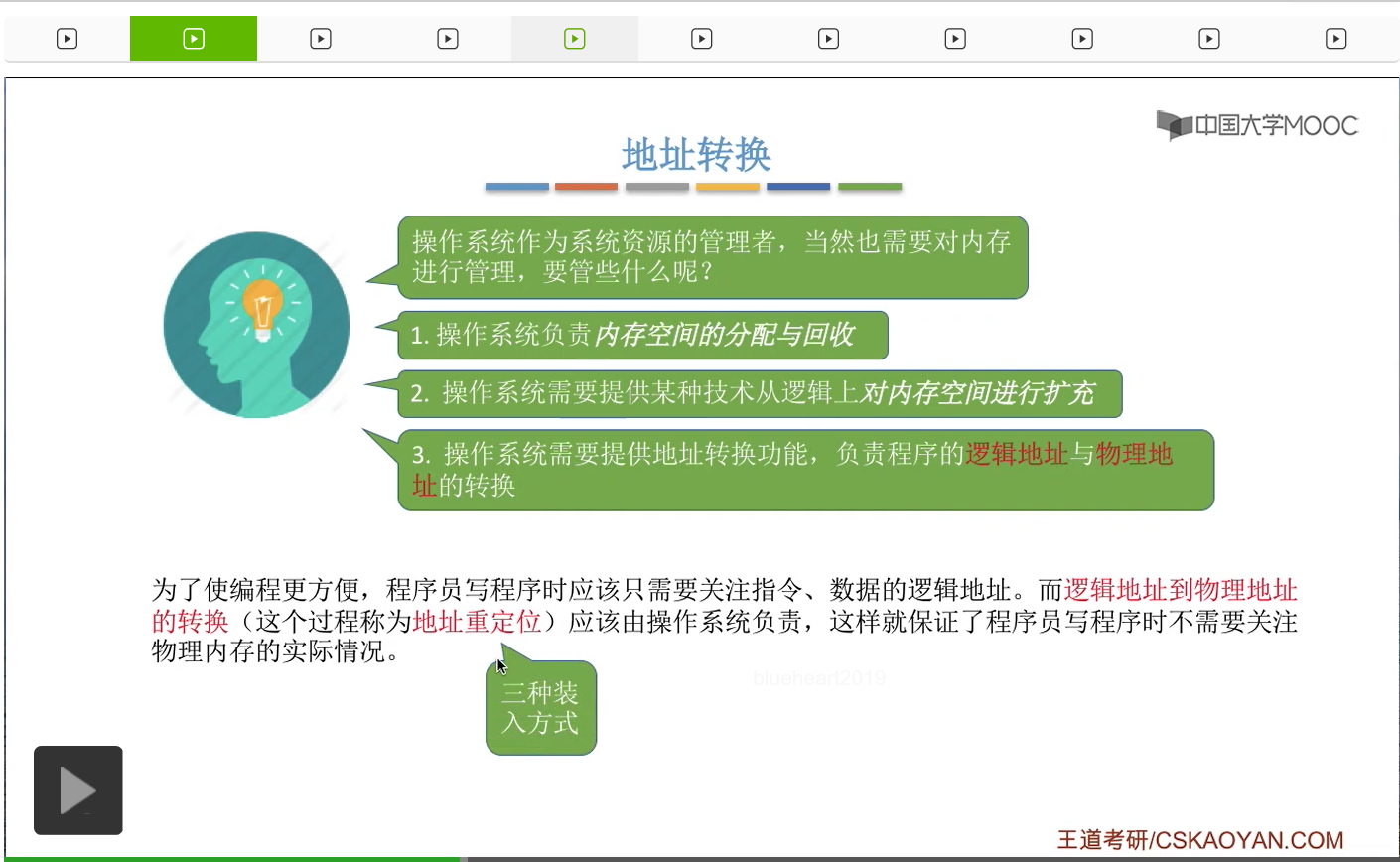
我们知道操作系统它作为系统资源的管理者,当然也需要对系统当中的各种软硬件资源进行管理,包括内存这种资源。那么操作系统在管理内存的时候需要做一些什么事情呢?我们知道各种进程想要投入运行的时候,需要先把进程相关的一些数据放入到内存当中,就像这个样子。那么内存当中,有的区域是已经被分配出去的,而有的区域是还在空闲的。操作系统应该怎么管理这些空闲或者非空闲的区域呢?另外,如果有一个新进程想要投入运行,那么这个进程相关的数据需要放入内存当中。但是如果内存当中有很多个地方都可以放入这个进程相关的数据,那这个数据应该放在什么位置呢?这也是操作系统需要回答的问题。第三,如果说有一个进程运行结束了,那么这个进程之前所占有的那些内存空间,应该怎么被回收呢?那所有的这些都是操作系统需要负责的问题。因此,内存管理的第一件事就是要操作系统来负责内存空间的分配与回收。那内存空间的分配与回收这个问题比较庞大,现在暂时不展开细聊,之后还会有专门的小节进行介绍。
计算机当中也经常会遇到实际的内存空间不够所有的进程使用的问题。所以操作系统对内存进行管理,也需要提供某一种技术,从逻辑上对内存空间进行扩充,也就是实现所谓的虚拟性,把物理上很小的内存拓展为逻辑上很大的内存。那这个问题也暂时不展开细聊,之后还会有专门的小节进行介绍。

第三个需要实现的事情是地址转换。为了让编程人员编程更方便,程序员在写程序的时候应该只需要关注指令、数据的逻辑地址。而逻辑地址到物理地址的转换,或者说地址重定位这个过程应该由操作系统来负责进行,这样的话程序员就不需要再关心底层那些复杂的硬件细节。所以内存管理的第三个功能就是应该实现地址转换。就是把程序当中使用的逻辑地址,把它转换成最终的物理地址。那么实现这个转换的方法,咱们在上个小节已经介绍过,
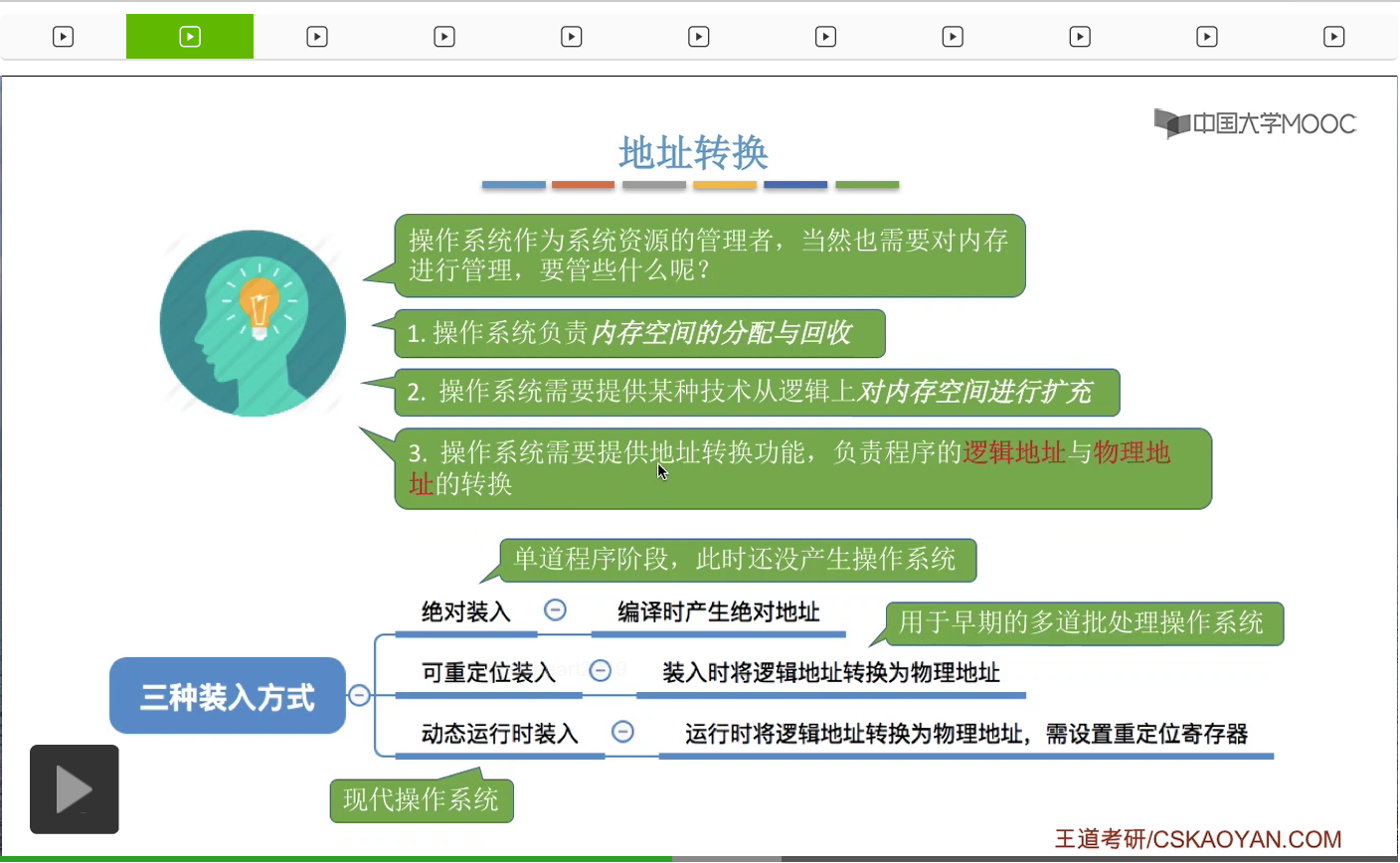
就是用三种装入方式分别是绝对装入、可重定位装入和动态运行时装入。绝对装入是在编译的时候就产生了绝对地址或者说在程序员写程序的时候直接就写了绝对地址。那么这种装入方式只在单道程序阶段才使用。但是单道程序阶段其实暂时还没有产生操作系统,所以这个地址转换其实是由编译器来完成的,而不是由操作系统来完成的。那第二种方式叫做可重定位装入,或者叫静态重定位,就是指在装入的时候把逻辑地址转换为物理地址,那这个转换的过程是由装入程序负责进行的。那装入程序也是操作系统的一部分。那这种方法一般来说是用于早期的多道批处理操作系统当中。那第三种装入方式叫做动态运行时装入或者叫动态重定位,就是运行的时候才把逻辑地址转换为物理地址,当然这种转换方式一般来说需要一个硬件——重定位寄存器的支持。而这种方式一般来说就是现代操作系统采用的方式,咱们之后在学习页式存储还有段式存储的时候会大量地接触这种动态运行时装入的方式。所以说操作系统一般会用可重定位装入和动态运行时装入这两种方式实现从逻辑地址到物理地址的转换。而采用绝对装入的那个时期暂时还没有产生操作系统。那这就是内存管理需要实现的第三个功能——地址转换。
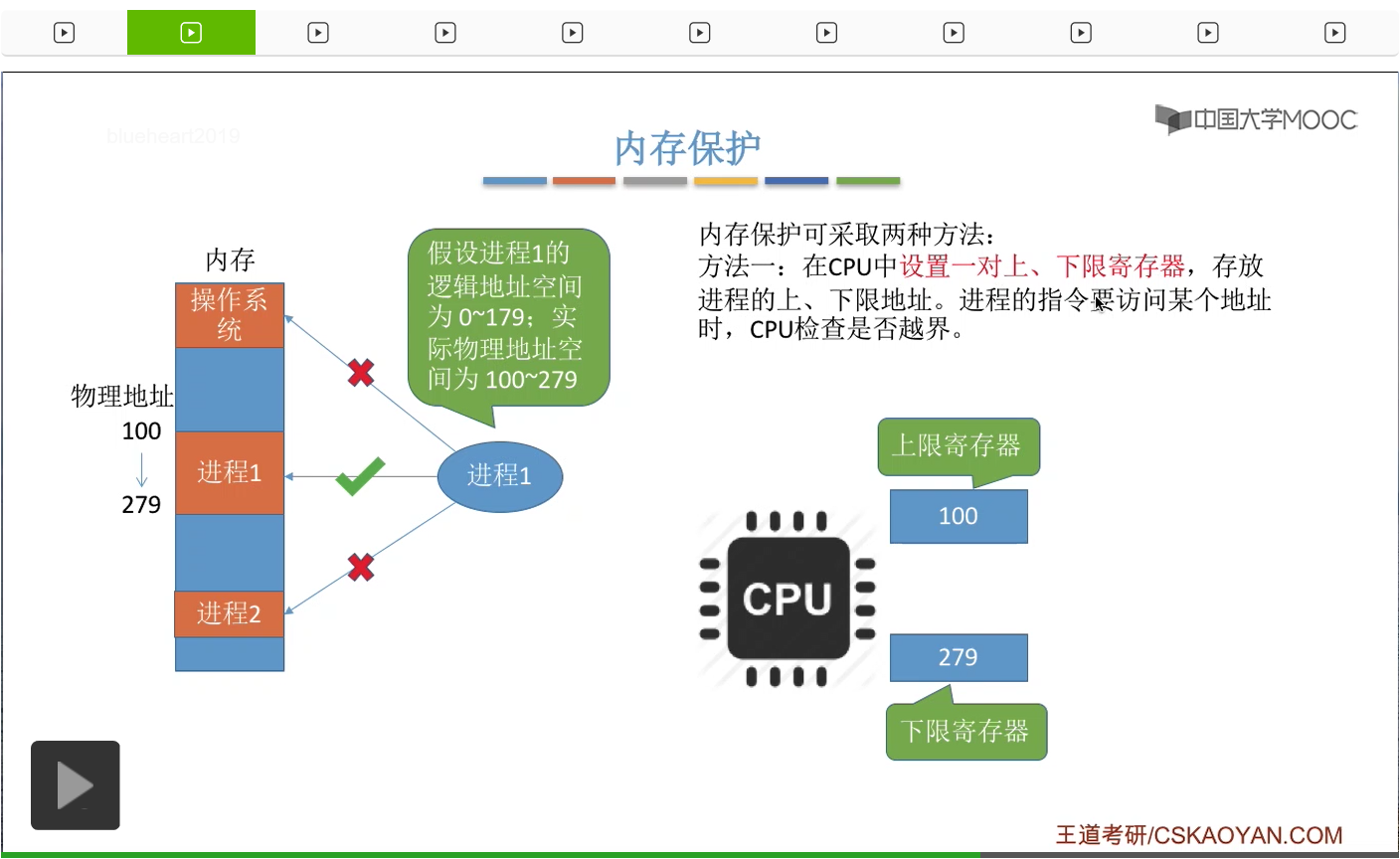
第四个功能叫内存保护。就是指操作系统要保证各个进程在各自存储空间内运行,互不干扰。

我们直接用一个图让大家更形象地理解。在内存当中一般来说会分为操作系统使用的内存区域还有普通的用戶程序使用的内存区域。那各个用戶进程都会被分配到各自的内存空间,比如说进程1使用的是这一块内存區域,进程2使用的是这一块内存区域。那如果说进程1想对操作系统的内存空间进行访问的话,很显然这个行为应该被阻止。如果进程1可以随意地更改操作系统的数据,那么很明显会影响整个系统的安全。另外如果进程1想要访问其他进程的存储空间的话,那么显然这个行为也应该被阻止。如果进程1可以随意地修改进程2的数据的话,那么显然进程2的运行就会被影响,这样也会导致系统不安全。所以进程1只能访问进程1自己的那個内存空间,所以这就是内存保护想要实现的事情。让各个进程只能访问自己的那些内存空间,而不能访问操作系统的也不能访问别的进程的空间。那我們可以采用這樣的方式來進行内存保護,就是在CPU當中設置一對上限寄存器和下限寄存器,分別用來存儲這個進程的内存空間的上限和下限。那如果进程1的某一条指令想要访问某一个内存單元的時候,CPU會根據指令當中想要訪問的那個内存地址和上下限寄存器的這兩個地址進行對比。只有在這兩個地址之間才允許進程1訪問,因爲只有這兩個地址之間的這個部分才屬於進程1的内存空間。那這是第一種方法,可以設置一對上下限寄存器。
第二種方法我們可以采用重定位寄存器和界地址寄存器來判斷此時是否有越界的嫌疑。那麽重定位寄存器又可以稱爲基址寄存器,界地址寄存器又稱爲限長寄存器。那重定位寄存器的概念咱們在上個小節已經接觸過,就是在動態運行時裝入那種方式裏,我們需要設置一個重定位寄存器,來記錄每一個進程的起始物理地址。界地址寄存器又可以稱爲限長寄存器,就是用來存放這個進程的最大邏輯長度的。比如說像進程1它的邏輯地址是0~179,所以界地址寄存器當中應該存放的是它的最大的邏輯地址也就是179。而重定位寄存器的話應該存放這個進程的起始物理地址,也就是100。那麽假如現在進程1想要訪問邏輯地址為80的那個内存單元的話,首先這個邏輯地址會和界地址寄存器當中的這個值進行一個對比。如果說沒有超過界地址寄存器當中保存的最大邏輯地址的話,那麽我們就認爲這個邏輯地址是合法的。如果超過了,那麽會抛出一個越界異常。那沒有越界的話,邏輯地址會和重定位寄存器的這個起始物理地址進行一個相加,最終就可以得到實際的想要訪問的物理地址也就是180。

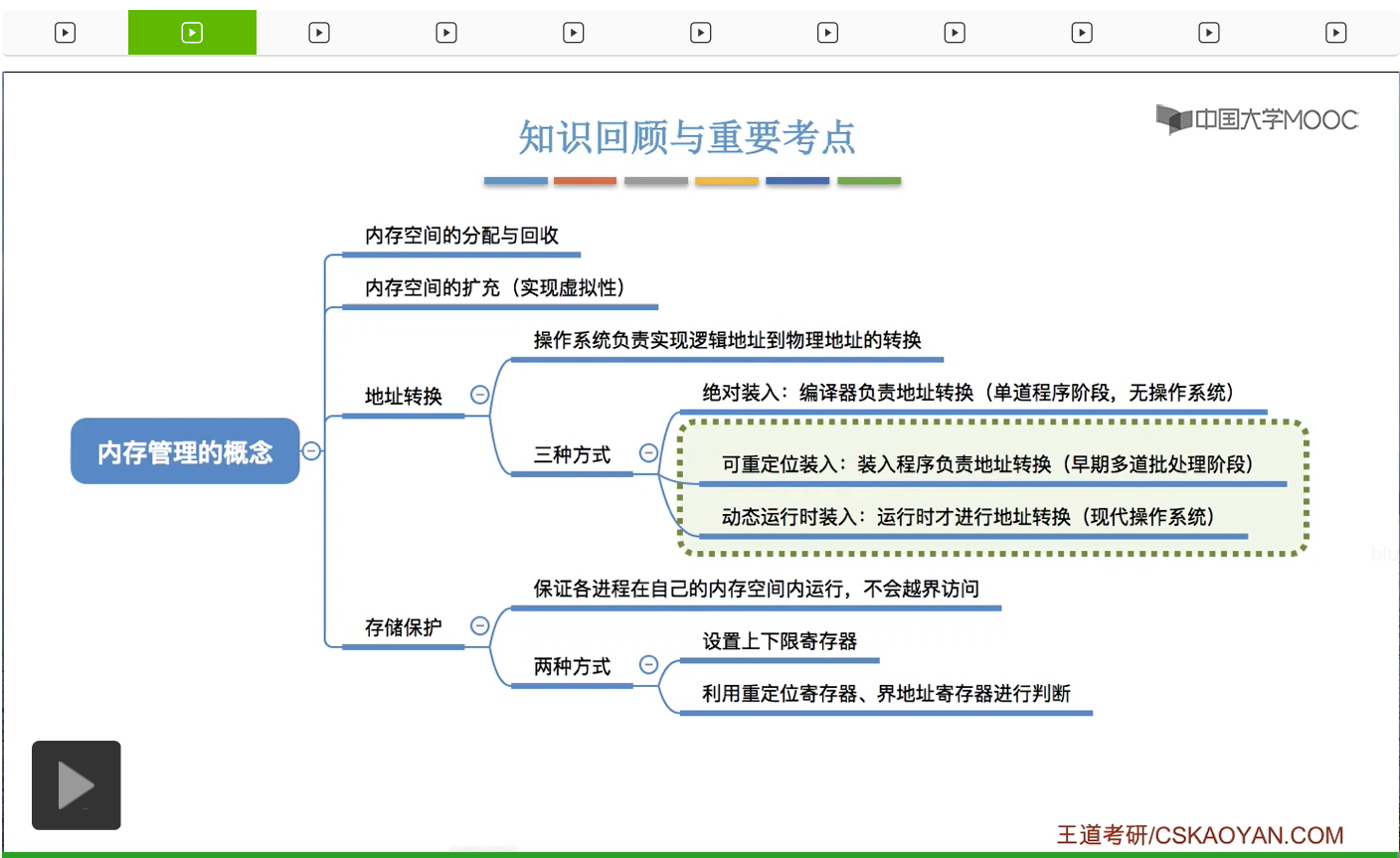
那这个小节中我们学习了内存管理的整体框架。内存管理总共需要实现四个事情,内存空间的分配与回收,内存空间的扩充以实现虚拟性,另外还需要实现逻辑地址到物理地址的转换。那么地址转换一般来说有三种方式,就是上个小节学习的内容——绝对装入、可重定位装入和动态运行时装入。其中绝对装入这个阶段其实是在早期的单道批处理阶段才使用的,这个阶段暂时还没有操作系统产生。而可重定位装入一般用于早期的多道批处理系统,现在的操作系统大多使用的是动态运行时装入。另外呢内存管理还需要提供存储保护的功能,就是要保证各个进程它们只在自己的内存空间内运行,不会越界访问。那一般来说有两种方式,第一种是设置上下限寄存器。第二种方式是利用重定位寄存器和界地址寄存器进行判断。那么重定位寄存器又可以叫做基址寄存器,而界地址寄存器又可以叫做限长寄存器。这两个别名大家也需要注意。那么本章之后内容还会介绍更多的内存空间的分配与回收,还有内存空间的扩充的一些相关策略。那这个小节的内容不算特别重要,只是为了让大家对内存管理到底需要做什么形成一个大体的框架。

那在之前的小節中我們已經學習到了操作系統對内存進行管理需要實現這樣四個功能。那地址轉換和存儲保護是上個小節詳細介紹過的。那這個小節我們會介紹兩種實現内存空間的擴充的技術——覆蓋技術和交換技術,那虛擬存儲技術會在之後用更多的專門的視頻來進行講解。

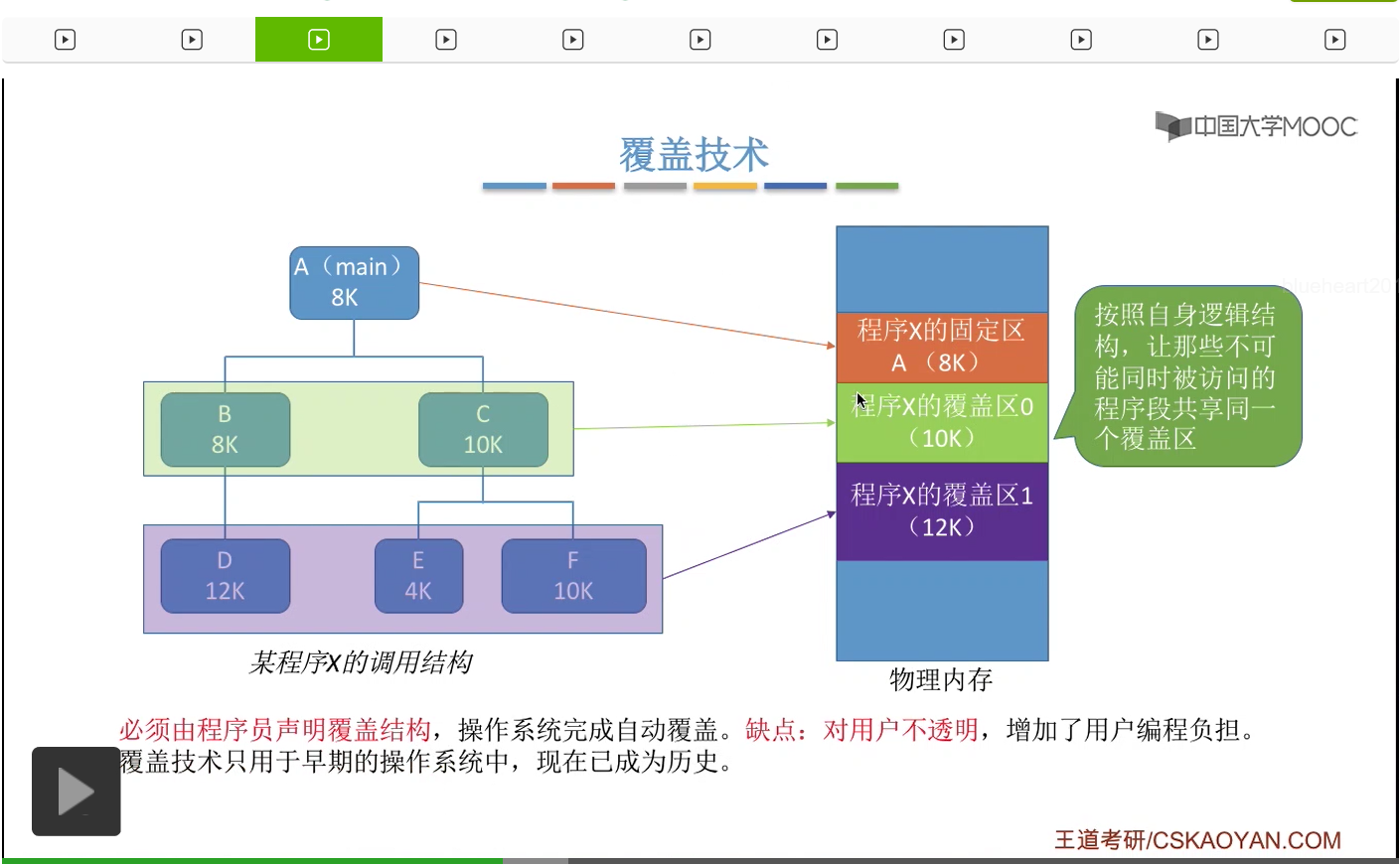
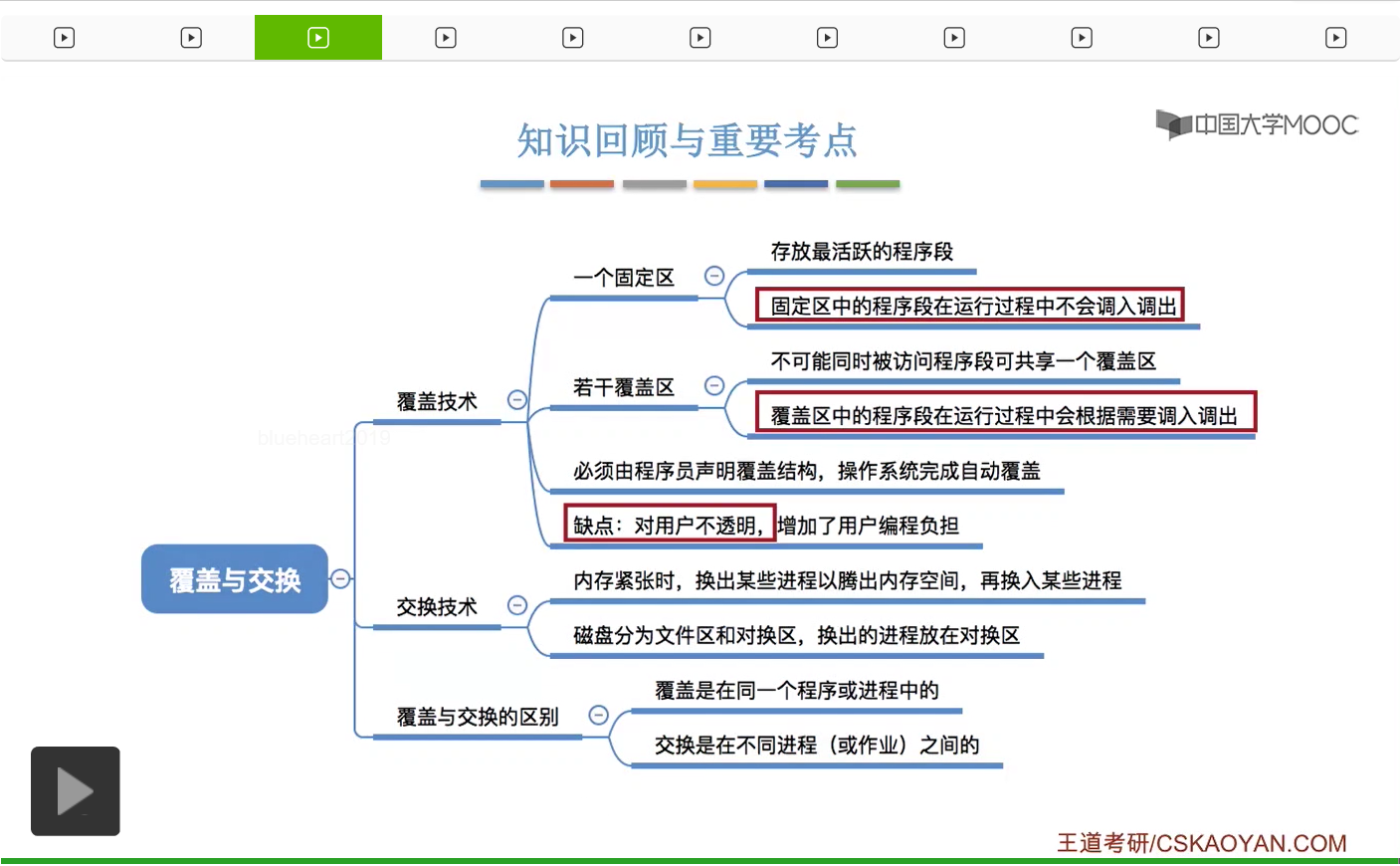
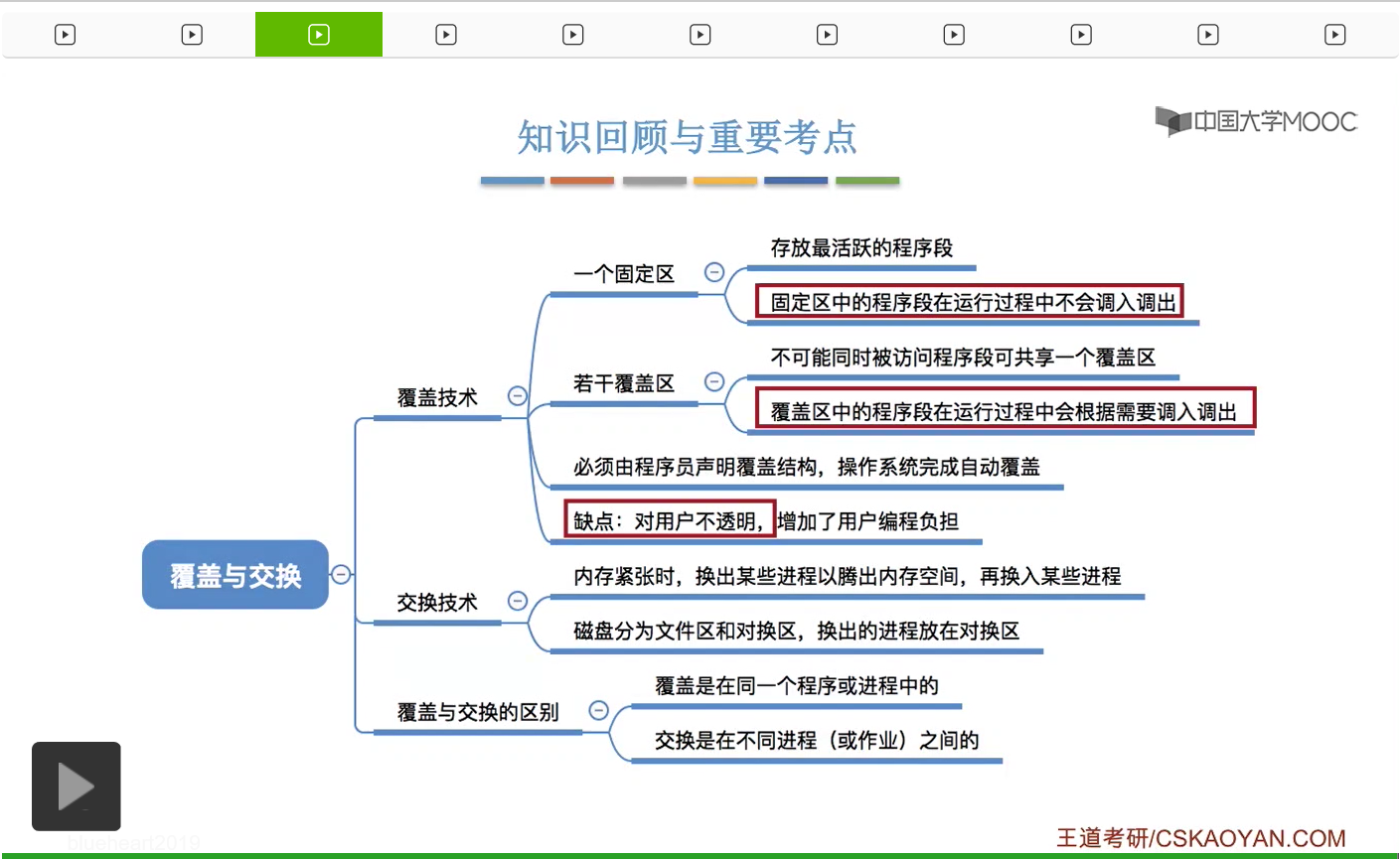
一般來説都很少有低於100MB字節的這種程序。所以可想而知1MB字節的大小很多時候應該是不能滿足這些程序的運行的。那么后来人们为了解决这个问题就引入了覆盖技术,就是解决程序大小超过物理内存总和的问题。比如说一个程序本来需要这么多的内存空间,但实际的内存大小又只有这么多。那怎么办呢?覆盖技术的思想就是要把程序分成多个段,或者理解为就是多个模块。然后常用的段就需要常驻内存,不常用的段只有在需要的时候才需要调入内存。那内存当中会分一个“固定区”和若干个“覆盖区”,常用的那些段需要放在固定区里,并且调入之后就不再调出,除非运行结束,这是固定区的特征。那不常用的段就可以放在“覆盖区”里,只有需要的时候才需要调入内存,也就是调入内存的覆盖区,然后用不到时候就可以调出内存。

A这个模块会依次调用B模块和C模块。注意是依次调用,也就是说B模块和C模块只可能被A这个模块在不同的时间段调用,不可能是同时访问B和C这两个模块。另外由于B模块和C模块不可能同时被访问,也就是说在同一个时间段内内存当中要么有B要么有C就可以了,不需要同时存在B和C这两个模块。所以我们可以让B和C这两个模块共享一个覆盖区,那这个覆盖区的大小以B和C这两个模块当中更大的这个模块为准,也就是10KB。因为如果我们把这个覆盖区设为10KB的话,那既可以存的下C也可以存的下B。那同样的,D、E、F这几个模块也不可能同时被使用。所以这几个模块也可以像上面一样共享一个覆盖区,覆盖区1,那它的大小就是按它们之间最大的这个也就是D模块的大小12KB来计算。所以如果说我们的程序有一个明显的这种调用结构的话,那么我们可以根据它这种自身的逻辑结构,让这些不可能被同时访问的程序段共享一个覆盖区。那只有其中的某一个模块被使用的时候,那这个模块才需要放到覆盖区里。所以采用了覆盖技术之后,在逻辑上看这个物理内存的大小是被拓展了的。不过这种技术也有一个很明显的缺点,因为这个程序当中的这些调用结构操作其实系统肯定是不知道的,所以程序的这种调用结构必须由程序员来显性地声明,然后操作系统会根据程序员声明的这种调用结构或者说覆盖结构,来完成自动覆盖。所以这种技术的缺点就是对用户不透明,增加了用户编程的负担。因此,覆盖技术现在已经很少使用了,它一般就只用于早期的操作系统中,现在已经退出了历史的舞台。
所以其实采用这种技术(交换技术/对换技术)的时候,进程是在内存与磁盘或者说外存之间动态地调度的。那之前咱們其实已经提到过一个和交换技术息息相关的知识点,咱们在第二章讲处理机调度的时候,讲过一个处理机调度层次的概念,分为高级调度、中级调度和低级调度。那其中中级调度就是爲了實現交換技術而使用的一種調度策略。就是說本來我們的内存當中有很多進程正在并發地運行,那如果某一個時刻突然發現内存空間緊張的時候我們就可以把其中的某些進程把它放到暫時換出外存。
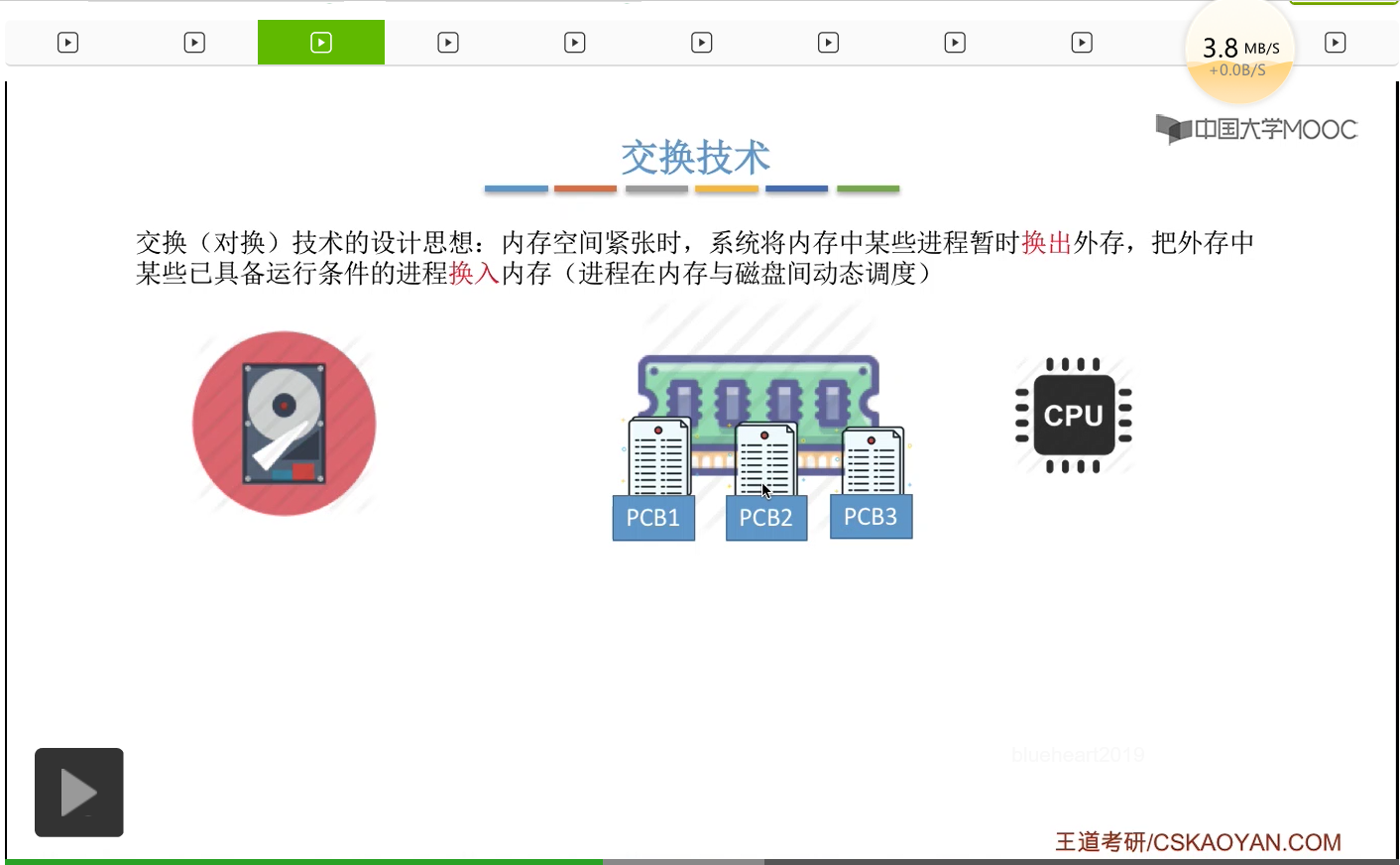
而進程相關的PCB會保留在内存當中,并且會插入到所謂的挂起隊列裏。那一直到内存空間不緊張了,内存空間充足的時候又可以把這些進程相關的數據再給換入内存。那爲什麽進程的PCB需要常駐内存呢?因爲進程被換出外存之後其實我們必須要通過某種方式記錄下來這個進程到底是放在外存的什麽位置,那這個信息也就是進程的存放位置這個信息,我們就可以把它記錄在與它對應的這些PCB當中。那操作系統就可以根據PCB當中記錄的這些信息,對這些進程進行管理了,所以進程的PCB是需要常駐内存的。
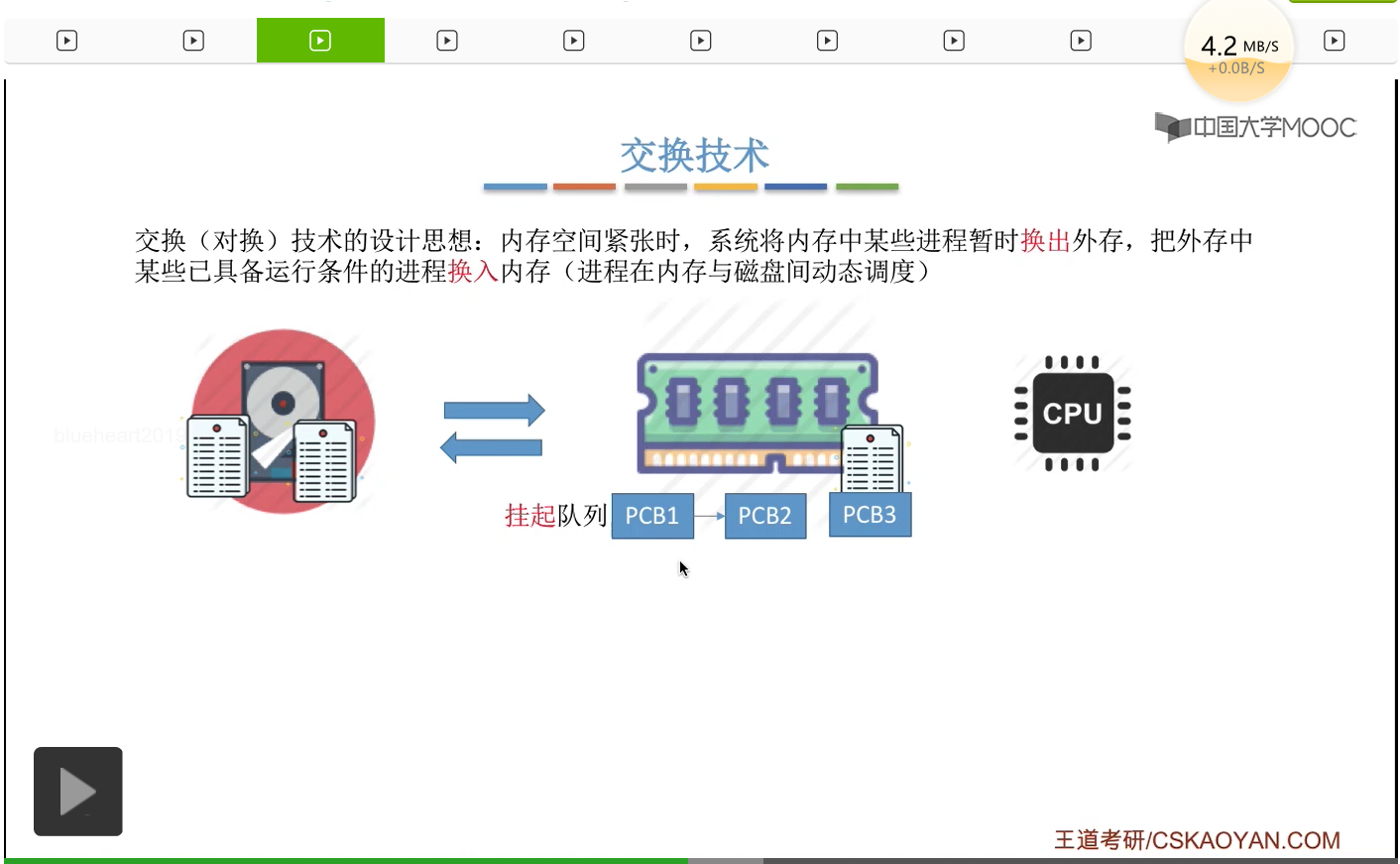
那麽中級調度或者説内存調度,其實就是在交換技術當中,選擇一個處於外存的進程把它換入内存這樣一個過程。那講到這個地方大家也需要再回憶一下低級調度和高級調度分別是什麽。

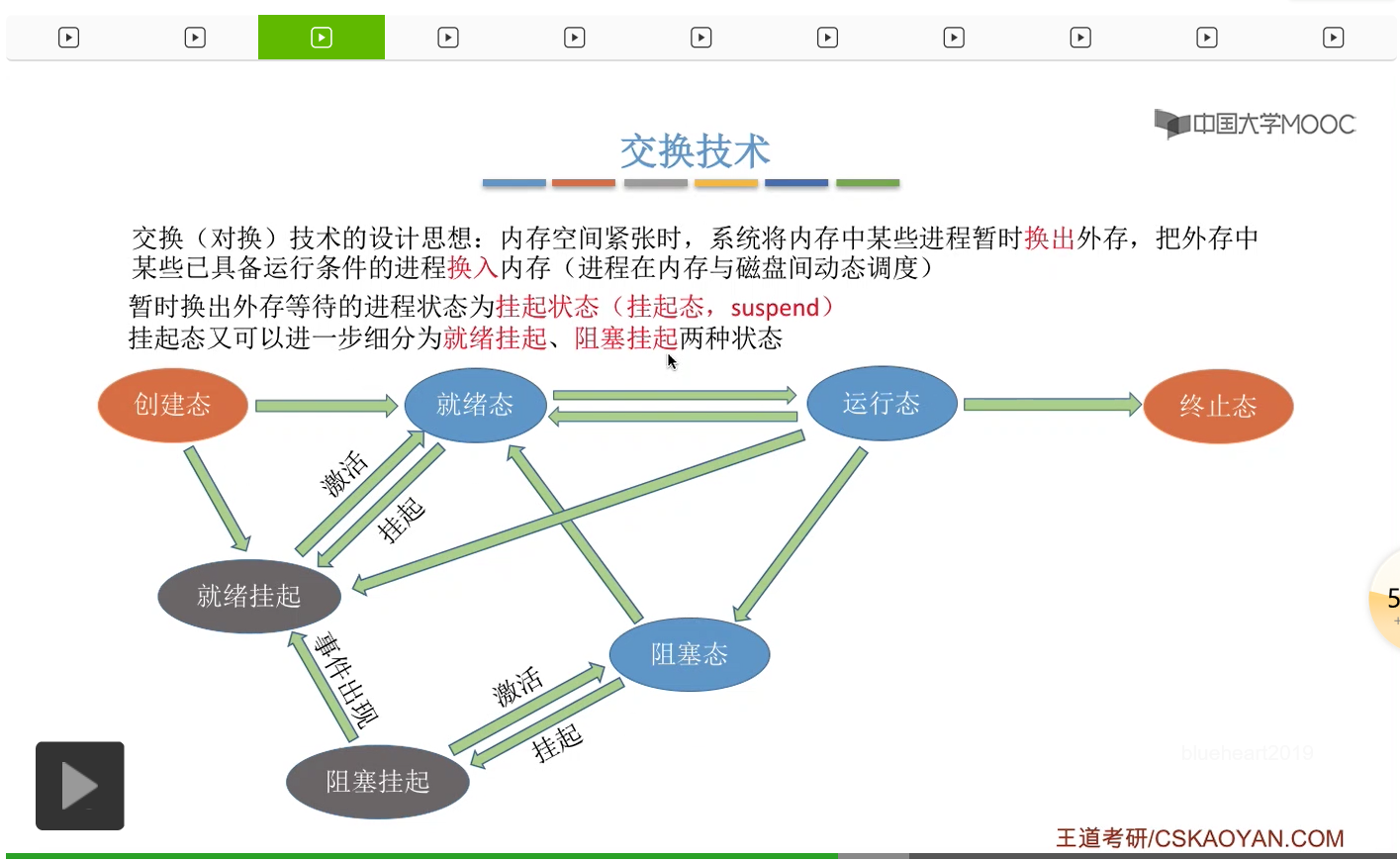
那既然提到了挂起我們就再來回憶一下和挂起相關的知識點。暫時換出外存等待的那些進程的狀態稱之爲挂起狀態或者簡稱挂起態。那挂起態又可以進一步細分為就緒挂起和阻塞挂起兩種狀態。在引入了這兩種狀態之後我們就提出了一種叫做進程的七狀態模型。那如果一個本來處於就緒態的進程被換出了外存,那這個進程就處於就緒挂起態。如果一個本來處於阻塞態的進程被換出外存的話,那麽這個進程就處於阻塞挂起態。那七狀態模型相關的知識點咱們在第二章當中已經進行過補充,這兒就不再贅述。那大家可以再結合這個圖回憶一下這些狀態之間的轉換是怎麽進行的,特別是中間的這三個最基本的狀態之間的轉換。所以采用了交換技術之後,如果說某一個時刻内存裏的空間不夠用了,那麽我們可以把内存中的某一些進程數據暫時換到外存裏,再把某一些更緊急的進程數據放回内存,所以交換技術其實也在邏輯上擴充了内存的空間。
在現代計算機當中,外存一般來説就是磁盤。那具有對換功能或者說交換功能的操作系統當中,一般來説會把磁盤的存儲空間分爲文件區和對換區這樣兩個區域。文件區主要是用來存放文件的,主要是需要追求存儲空間的利用率。所以在對文件區,一般來説是采用離散分配的方式。而這個地方一會兒再做解釋。那對換區的空間一般來説只占磁盤空間的很小的部分,注意被換出的進程數據一般來説就是存放在對換區當中的,而不是文件區。那由於對換區的這個換入換出速度會直接影響到各個進程并發執行的這種速度,所以對於對換區來説我們應該首要追求換入換出的速度。因此對換區通常會經常采用連續分配的方式。那這個地方大家理解不了暫時沒有關係,咱們在第四章文件管理的那個章節會具體地再進一步學習什麽是對換區什麽是文件區,并且到時候大家就能夠理解爲什麽離散分配方式可以更大地提高存儲空間的利用率,而連續分配方式可以提高換入換出的速度。那這個地方大家只需要理解一個結論,對換區的I/O速度或者説輸入輸出的速度,是要比文件區更快的。所以我們的進程數據被換出的時候,一般是放在對換區,換入的時候也是從對換區再換回内存。

一般來説交換會發生在系統當中有很多進程在運行并且内存吃緊的時候。那在這種時候,我們可以選擇換出一些進程來騰空内存空間那一直到系統負荷明顯降低的時候就可以暫停換出。比如說如果操作系統在某一段時間發現許多進程運行的時候都經常發生缺頁,那這就説明内存的空間不夠用,所以這種時候就可以選擇換出一些進程來騰空一些内存空間。那如果說缺頁率明顯下降,也就是說看起來系統負荷明顯降低了,我們就可以暫停換出進程了。那這個地方涉及到之後的小節會講到的缺頁還有缺頁率這些相關的知識點。這兒理解不了沒有關係,大家能夠有個印象就可以了。

首先我們可以考慮優先換出一些阻塞的進程。因爲處於就緒態的進程,其實是可以投入運行的。而處於阻塞態的進程,即使是在内存當中反正它暫時也運行不了了,所以我們可以優先把阻塞進程調出換到外存當中。第二,我們可以考慮換出優先級比較低的進程。那這個不用解釋,很好理解。第三,如果我們每次都是換出優先級更低的進程的話,那麽就有可能導致優先級低的進程剛被調入内存很快又被換出的問題。那這就有可能會導致優先級低的進程飢餓的現象。所以有的系統當中爲了防止這種現象,會考慮進程在内存當中的駐留時間。如果一個進程在内存當中駐留的時間太短,那這個進程就暫時不會把它換出外存。那這個地方再强調一點,PCB是會常駐内存的,并不會被換出外存。所以其實所謂的換出進程,并不是把進程相關的所有的數據一個不漏的全部都調到外存裏,操作系統爲了保持對這些換出進程的管理,那PCB這個信息還是需要放在内存當中。那麽這就是交換技術。


那这个小节我们学习了覆盖技术和交换技术相关的知识点。那这两个知识点一般来说只会在选择题当中进行考查。大家只要能够理解这两种技术的思想就可以了。那么可能稍微需要记忆一点的就是,固定区和覆盖区相关的这些知识点。在固定区当中的程序段,在运行过程当中是不会被调出的。而在覆盖区当中的程序段,在运行过程当中是有可能会根据需要进行调入调出的。另外,如果考查了覆盖技术的话,那么很有可能会把覆盖技术的缺点作为其中的某一个选项进行考查。那在讲解交换技术的过程当中我们补充了文件区和对换区相关的知识点,这些会在第四章中进行进一步的学习。那这个地方大家只需要知道换出的进程的数据一般来说是放在磁盘的对换区当中的。那最后我们再来看一下覆盖与交换这两种技术的一个明显的区别。其实覆盖技术是在同一个程序或者进程当中进行的。那相比之下交换技术是在不同进程或作业之间进行的,而暂时运行不到的进程可以调出外存。那比较紧急的进程可以优先被再重新放回内存。

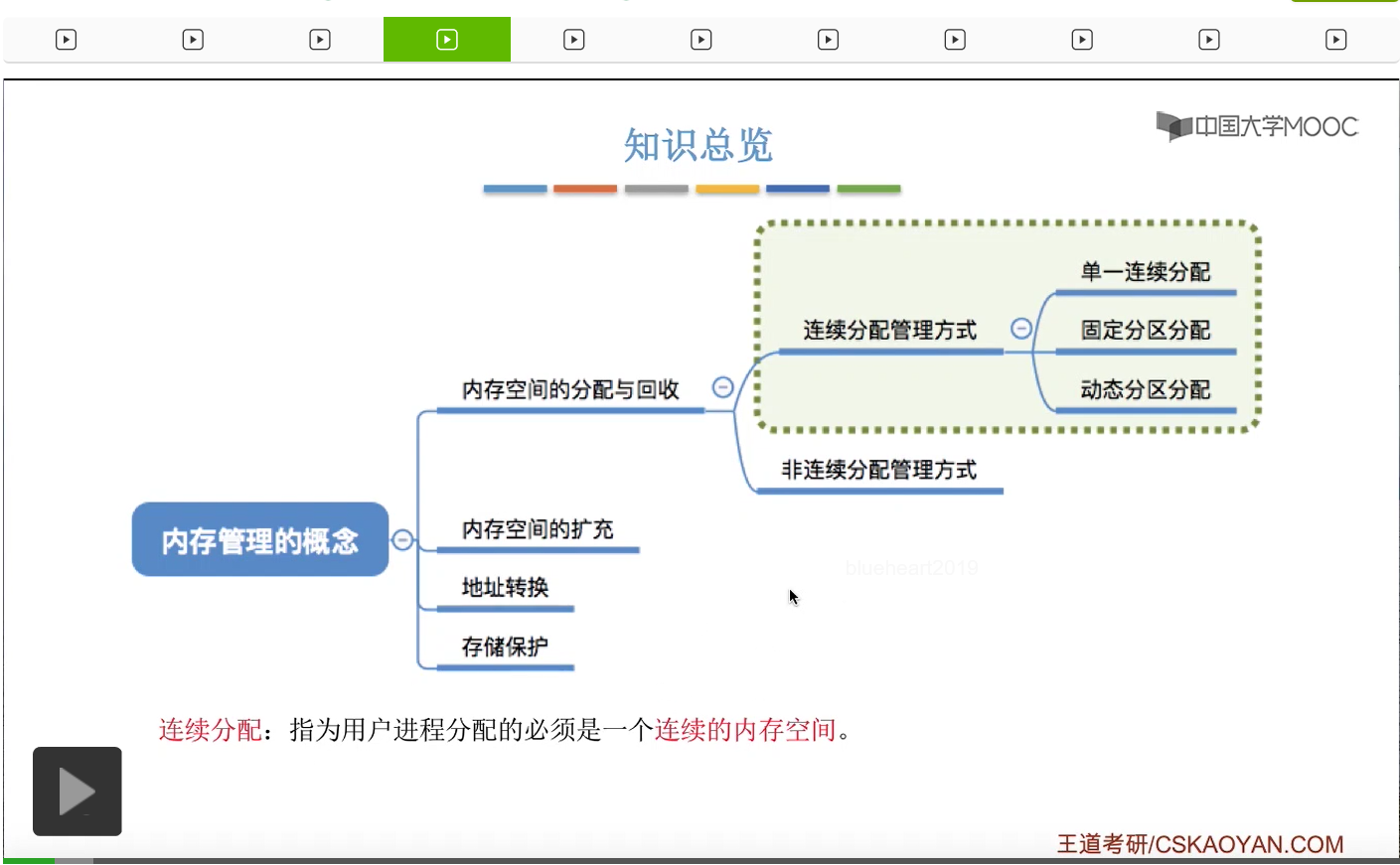
在之前的学习中我们知道,操作系统对内存进行管理,需要实现这样四个事情。那么内存空间的扩充,地址转换和存储保护,这是之前的小节介绍过的内容。从这个小节开始我们会介绍内存空间的分配与回收应该怎么实现。我们在这个小节中会先介绍连续分配管理方式,分别是单一连续分配,固定分区分配和动态分区分配。我们会按从上至下的顺序依次讲解。那么这儿需要注意的是,所谓的连续分配和非连续分配的区别在于,连续分配是指,系统为用户进程分配的必须是一个连续的内存空间。而非连续分配管理方式是指系统为用户分配的那些内存空间不一定是连续的,可以是离散的。
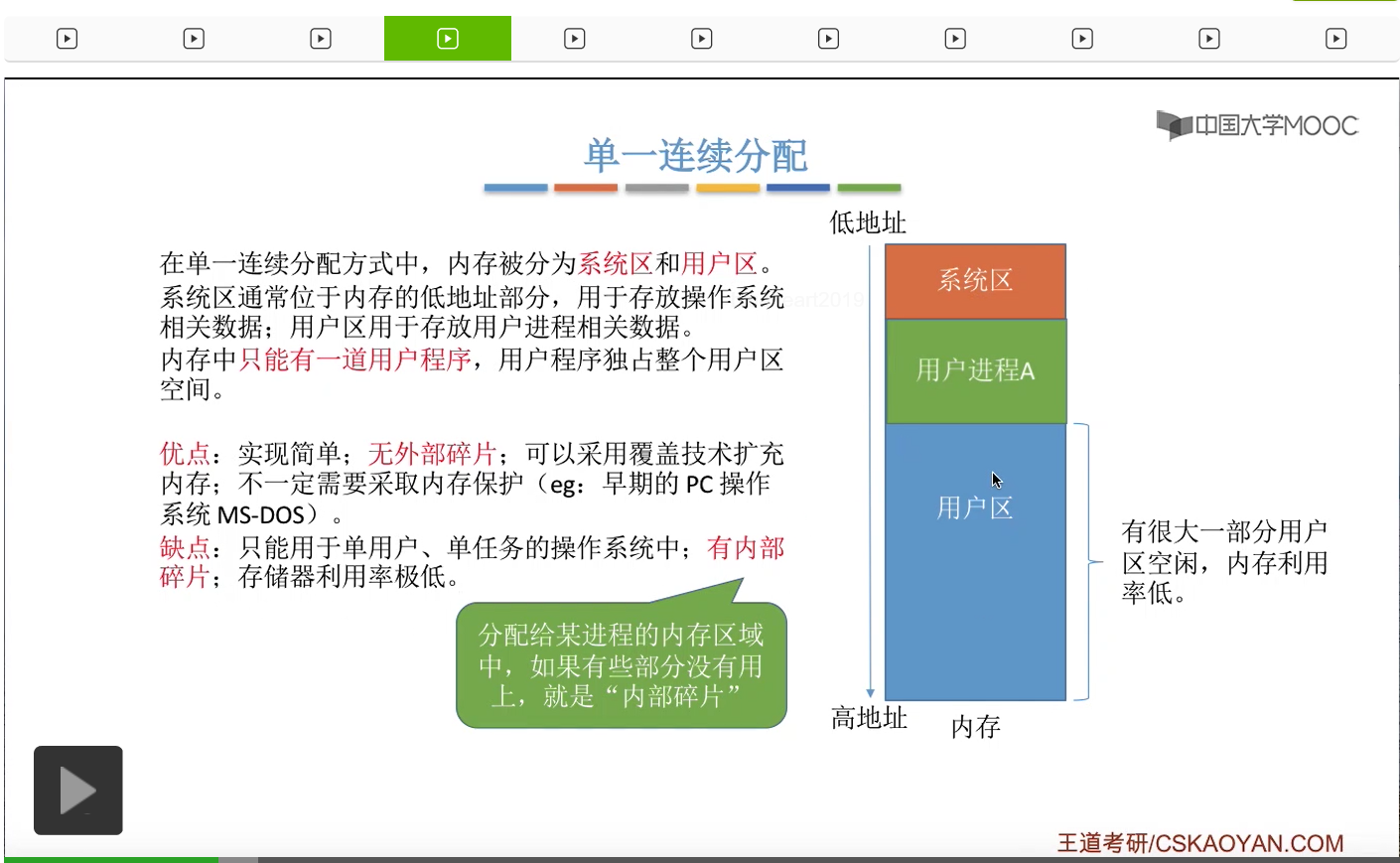
那么我们先来看单一连续分配方式。采用单一连续分配方式的系统当中,会把内存分为一个系统区和一个用户区。那系统区就是用于存放操作系统相关的一些数据,用户区就是用于存放用户进程或者说用户程序相关的一些数据。不过需要注意的是,采用单一连续分配方式的这种系统当中,内存当中同一时刻只能有一道用户程序。也就是说它并不支持多道程序并发运行,所以用户程序是独占整个用户区的,不管这个用户区有多大。比如说一个用户进程或者说用户程序,它本来只需要这么大的内存空间。
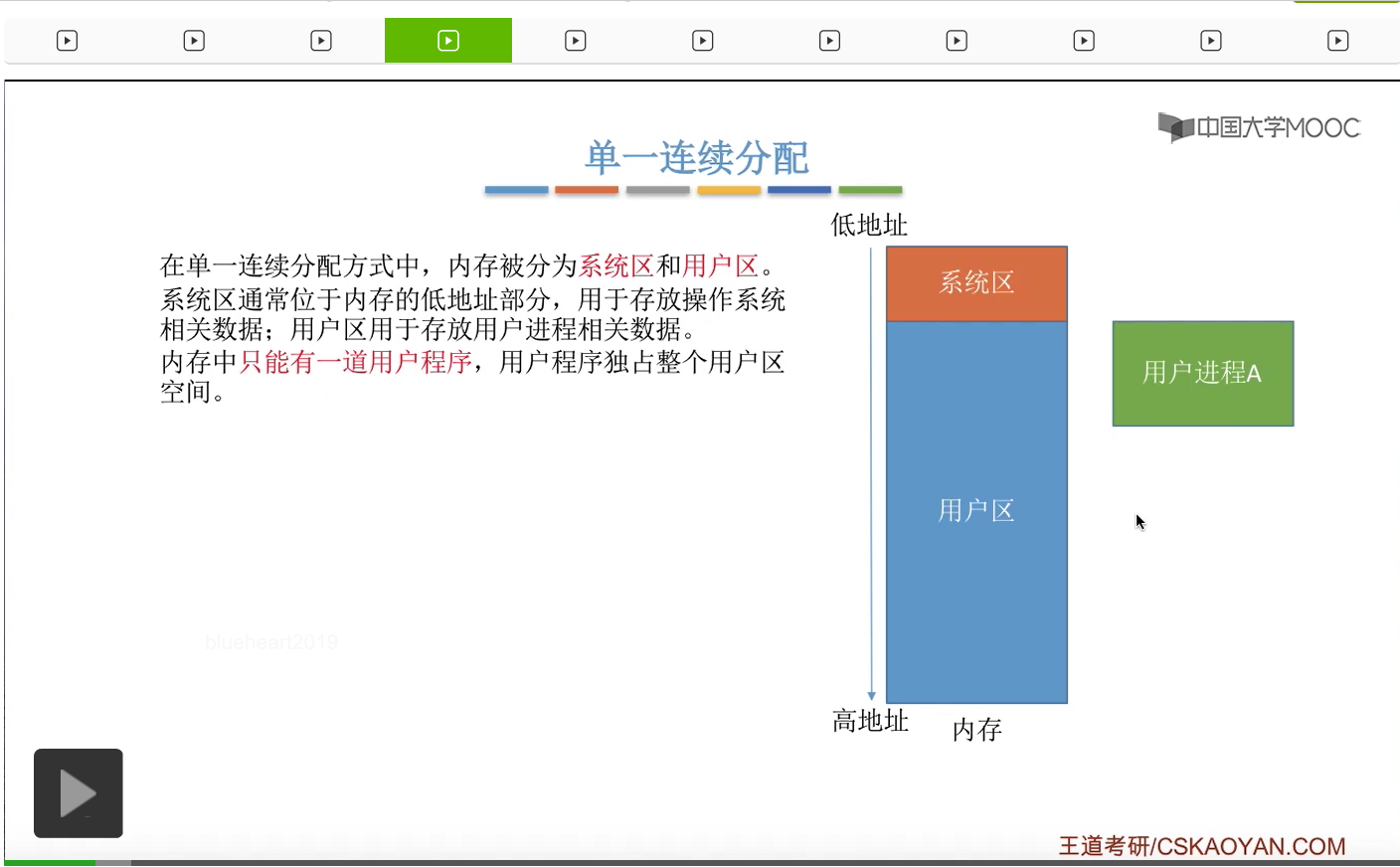
那当它放到内存的用户区之后,用户区当中其他那些空闲的区间其实也不会被分配给别的用户程序。所以说是整个用户程序独占整个用户区的这种存储空间的。所以这种方式其实优点很明显就是实现起来很简单,并且没有外部碎片。那外部碎片这个概念我们在讲到动态分区分配的时候再补充,这儿先有个印象。那由于整个系统当中同一时刻只会有一个用户程序在运行,所以采用这种分配方式的系统当中不一定需要采用内存保护。注意只是不一定,有的系统当中它也会设置那种越界检查的一些机制。但是像早期的个人操作系统,微软的DOS系统,就没有采用这种内存保护的机制。因为系统中只会运行一个用户程序,那么即使这个用户程序出问题了,那也只会影响用户程序本身,或者说即使这个用户程序越界把操作系统的数据损坏了,那这个数据一般来说也可以通过重启计算机就可以很方便地就进行修复。所以说采用单一连续分配方式的系统当中,不一定采取内存保护,那这也是它的优点。那另一方面,这种方式的缺点也很明显,就是只适用于单用户、单任务的操作系统,它并不支持多道程序并发运行,并且这种方式会产生内部碎片。那所谓的内部碎片,就是指我们分配给某一个进程或者说程序的内存区间当中,如果有某一个部分没有被用上,那这就是所谓的内部碎片。像这个例子当中,本来整个用户区都是分配给这个用户进程A的,但是有这么大一块它是空闲的,暂时没有利用起来。那本来给这个进程分配了,但是这个进程没有用上的这一部分内存区域就是所谓的内部碎片。所以这种方式也会导致存储器的利用率很低。那这是单一连续分配方式。

多道程序技术就是可以让各个程序同时装入内存,并且这些程序之间不能相互干扰,所以人们就想到了把用户区划分成了若干个固定大小的分区,并且在每一个分区内只能装入一道作业。也就是说每一道作业或者说每一道程序它是独享其中的某一个固定大小的分区的。那这样的话就形成了最早的可以支持多道程序的内存管理方式。那固定分区分配可以分为两种,一种是分区大小相等,另外一种是分区大小不等。如果说采用的是分区大小相等的策略的话,系统会把用户区的这一整片的内存区间分割为若干个固定大小并且大小相等的区域。
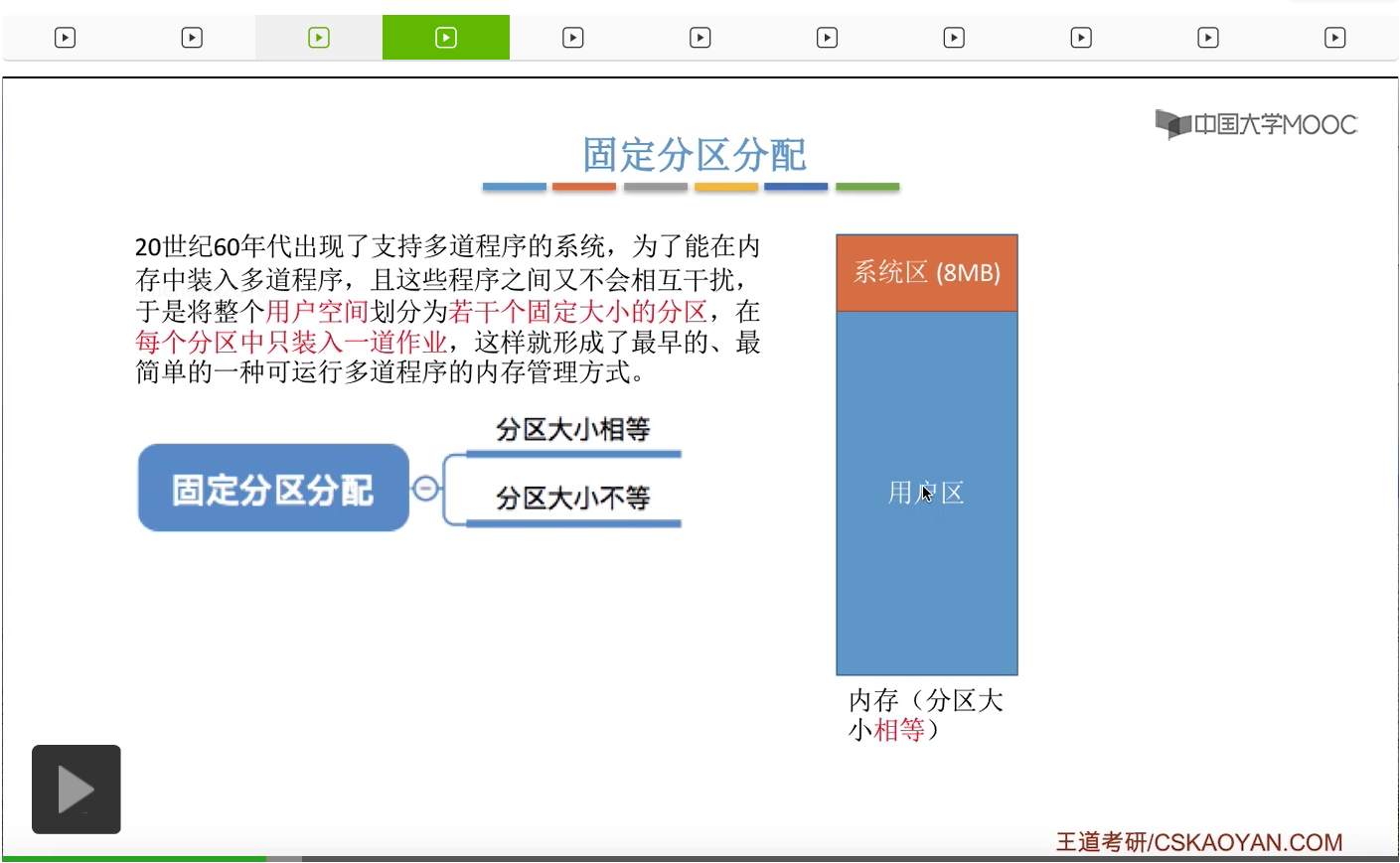
比如说每个区域十个字节,像这样子。那如果说采用的是分区大小不相等的这种策略的话,系统会把用户区分割为若干个大小固定但是大小又不相等的分区,比如说像这个样子。那这两种方式各有各的特点,如果说采用的是分区大小相等的这种策略的话,很显然会缺乏灵活性。比如说一些小的进程它可能只需要占用很小的一部分内存空间,但是由于每个分区只能装入一道作业,所以一个很小的进程又会占用一个比较大的、很多余的一个分区。那如果说一个有一个比较大的进程进入的话,那么如果这些分区的大小都不能满足这个大进程的需求,那么这个大进程就不能被装入这个系统,或者说只能采用覆盖技术,在逻辑上来拓展各个分区的大小。但这又显然又会增加一些系统开销。所以说分区大小相等的这种情况是比较缺乏灵活性的,不过这种策略即使在现代也是有很广泛的用途的。那由于这n个炼钢炉本来就是相同的对象,所以对这些相同的对象进行控制的程序当然也是相同的程序。所以如果采用这种把它分割为n个大小相等的区域来分别存放n个控制程序,让这n个控制程序并发执行,并发地控制各个炼钢炉的话,那在这种场景下的应用就是很适合的。那如果分区大小不等的话,灵活性会有所增加。比如说小的进程我们可以给它分配一个小的分区,而大的进程可以给它分配一个大的分区。那一般来说可以先估计一下系统当中会出现的大作业、小作业分别到底有多少。然后再根据大小作业的比例来对这些大小分区的数量进行一个划分。比如说可以划分多个小分区,适量的中等分区、然后少量的大分区。

那接下来我们再考虑下一个问题,操作系统应该怎么记录内存当中各个分区的空闲或者分配的这些情况呢?那一般来说我们可以建立一个叫做分区说明表的一个数据结构,用这个数据结构对各个分区进行管理。比如说如果系统当中内存的情况是这个样子,那么我们可以给它建立一个对应的分区说明表。那每一个表项会对应其中的某一个分区,那每一个表项需要包含当前这个分区的大小还有这个分区的起始地址还有这个分区是否已经被分配的这种状态。那像这样一张表其实我们可以建立一个数据结构,数据结构当中有这样一些属性,然后把这个用这个数据结构组成一个数组或者组成一个链表来表示这样一个表。那如果学过数据结构的同学这儿应该不难理解。那操作系统根据这个数据结构就可以知道各个分区的使用情况,如果说一个用户程序想要装入内存的话,操作系统就可以来检索这个表,然后找到一个大小能够满足并且没有被分配出去的分区,然后把这个分区分配给用户程序。之后再把这个分区对应的状态改成已分配的状态就可以了。那么固定分区分配实现起来其实也不算复杂,并且使用这种方式也不会产生外部碎片。那么外部碎片这个概念咱们再往后拖一拖,下一个分配方式当中会进行讲解。但是这种方式也有很明显的缺点。如果说一个用户程序太大了,大到没有任何一个分区可以直接满足它的大小的话,那么我们只能通过覆盖技术来解决这个分区大小不够的问题。但是如果采用了覆盖技术,那就意味着需要付出一定的代价,会降低整个系统的性能。另外,这种分配方式很显然也会产生内部碎片,比如说有一个用户程序它所需要的内存空间是10MB,那么扫描了这个表之后会发现,只有分区6可以满足10MB这么大的需求,所以这个用户程序就会被装到分区6里。但是由于这个用户程序会独占整个分区6,所以分区6总共有12MB,那么就有两兆字节的空间是分配给了这个程序,那这个程序又用不到的。那这一部分就是所谓的内部碎片。所以固定分区分配是会产生内部碎片的,因此它的内存利用率也不是特别高。
动态动态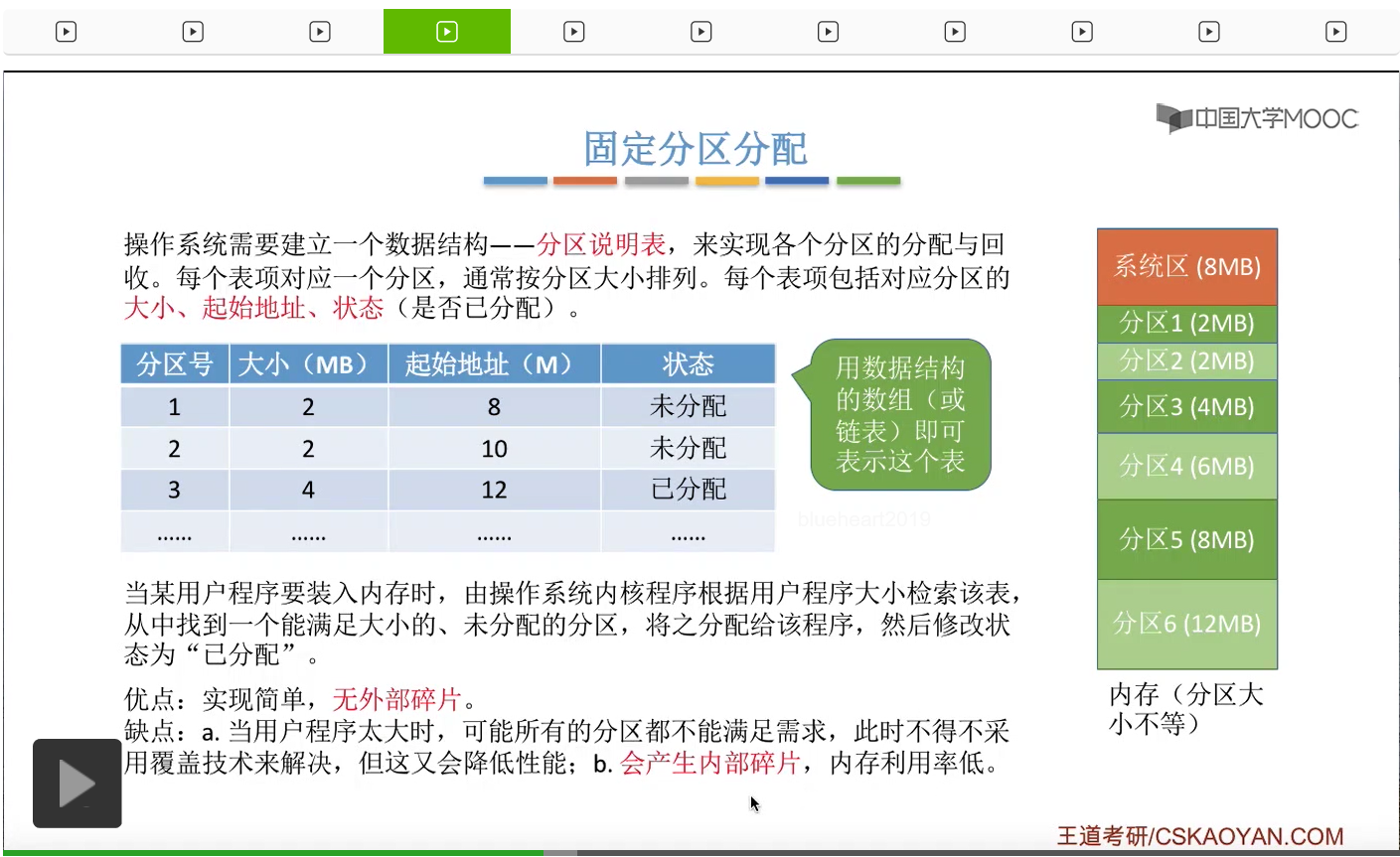
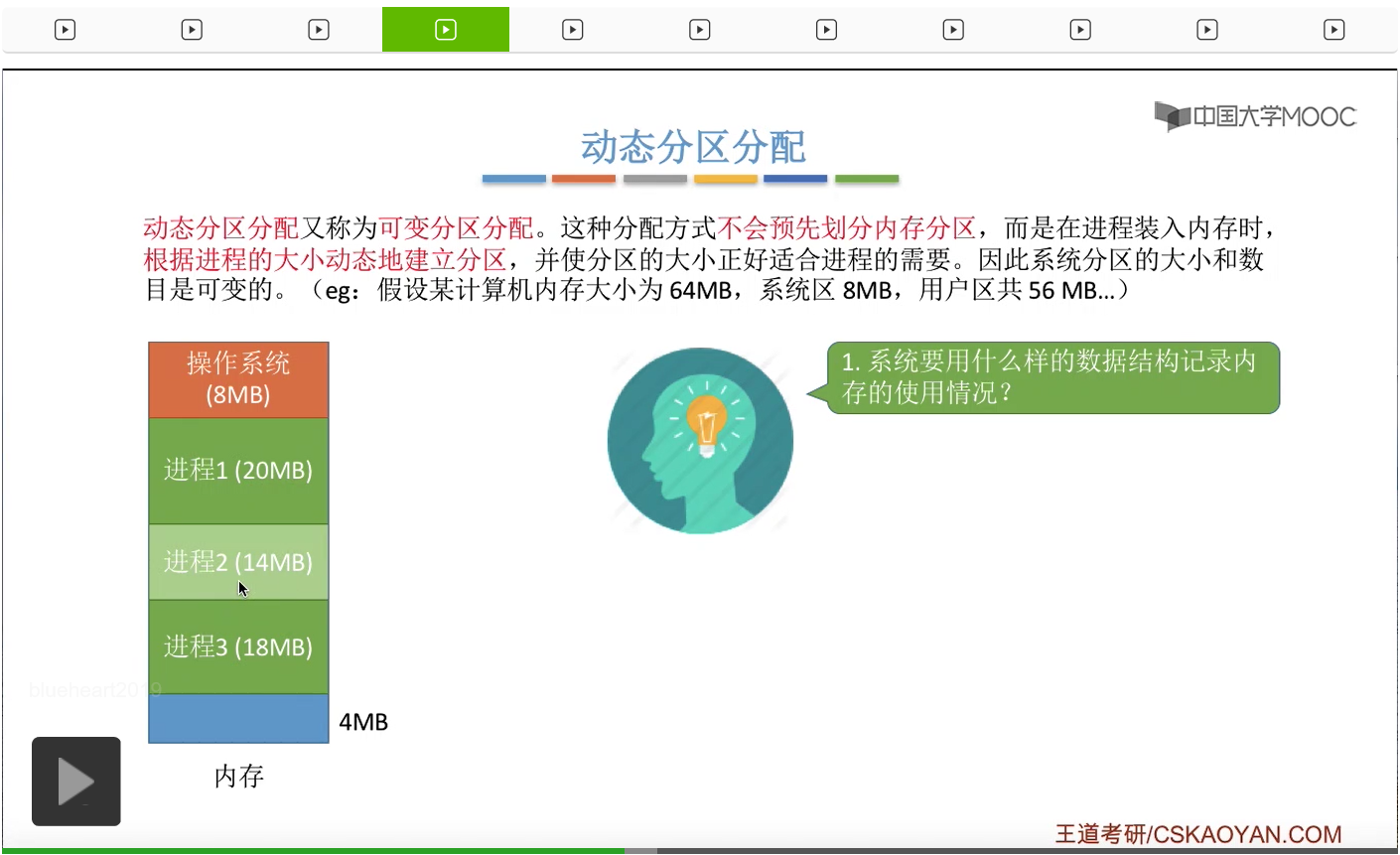
那么,为了解决这个问题人们又提出了动态分区分配的策略。动态分区分配又可以称作可变分区分配,这种分配方式并不会像之前固定分区分配那样预先划分内存区域。而是在进程装入内存的时候才会根据进程的大小动态地建立分区。而每一个分区的大小会正好适合进程所需要的那个大小。所以和固定分区分配不同,如果采用动态分区分配的话,系统当中内存分区的大小和数目是可以改变的。那我们来看一个例子。比如说一个计算机的内存大小总共是64MB字节,然后系统区会占8MB字节,那用户区就是56MB字节。刚开始一个用户进程1到达,它总共占用了20MB字节的分区,之后一个用户进程2到达,占用了14MB字节的分区,用户进程3到达,占用了18MB字节的分区。那么56MB字节的用户区总共只会占4MB字节的空闲分区。那么系统中这些分区的大小和数量是可变的,并且有些分区是已经被分出去的,有些分区又是没有被分出去的。操作系统应该用什么样的数据结构来记录这个内存的使用情况呢?这是我们之后要探讨的第一个问题。那再来看第二个问题,
如果此时占有14MB字节的进程2已经运行结束了,并且被移出了内存,那么内存当中就会有这样一片14MB字节的空闲区间,那此时如果有一个新进程到达,并且这个进程需要4兆字节的内存空间。那这一片空闲区间是14MB,这一片空闲区间是4MB。那到底应该放这一片还是放下面这一片呢?这又是第二个问题。当我们的内存当中有很多个空闲分区都可以满足进程的需求的时候,应该把哪个空闲区间分配给那个进程呢?这是第二个问题。
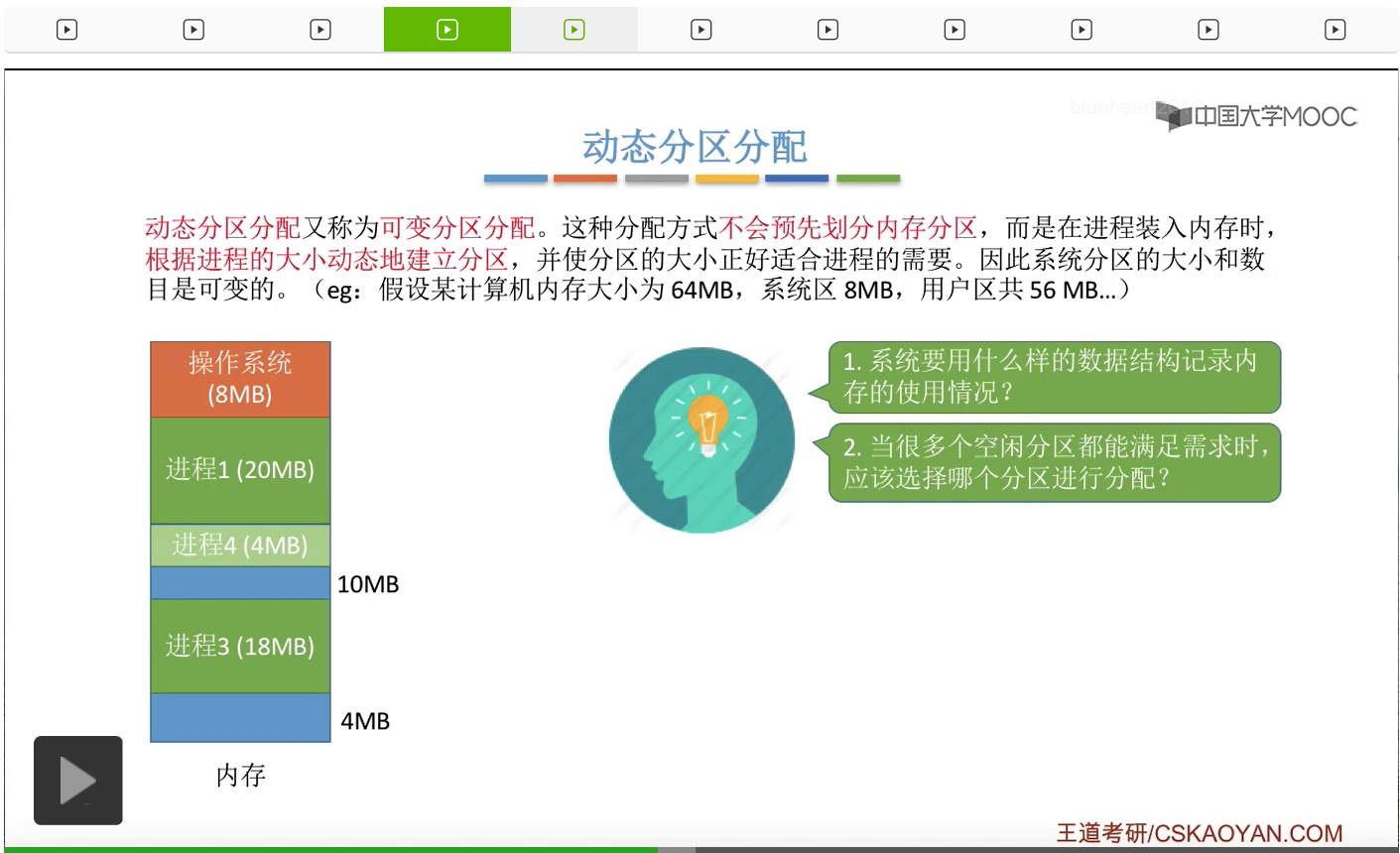
第三个问题,假设此时占18MB字节的进程三运行结束,并且被撤离了内存。那么内存当中就会出现18MB字节的一个新的空闲分区。那这个空闲分区应该怎么处理?是否应该和与它相邻的这些分区进行合并呢?这就是第三个问题,我们应该如何进行分区的分配和回收的操作。那接下来我们依次对这三个问题进行探讨。
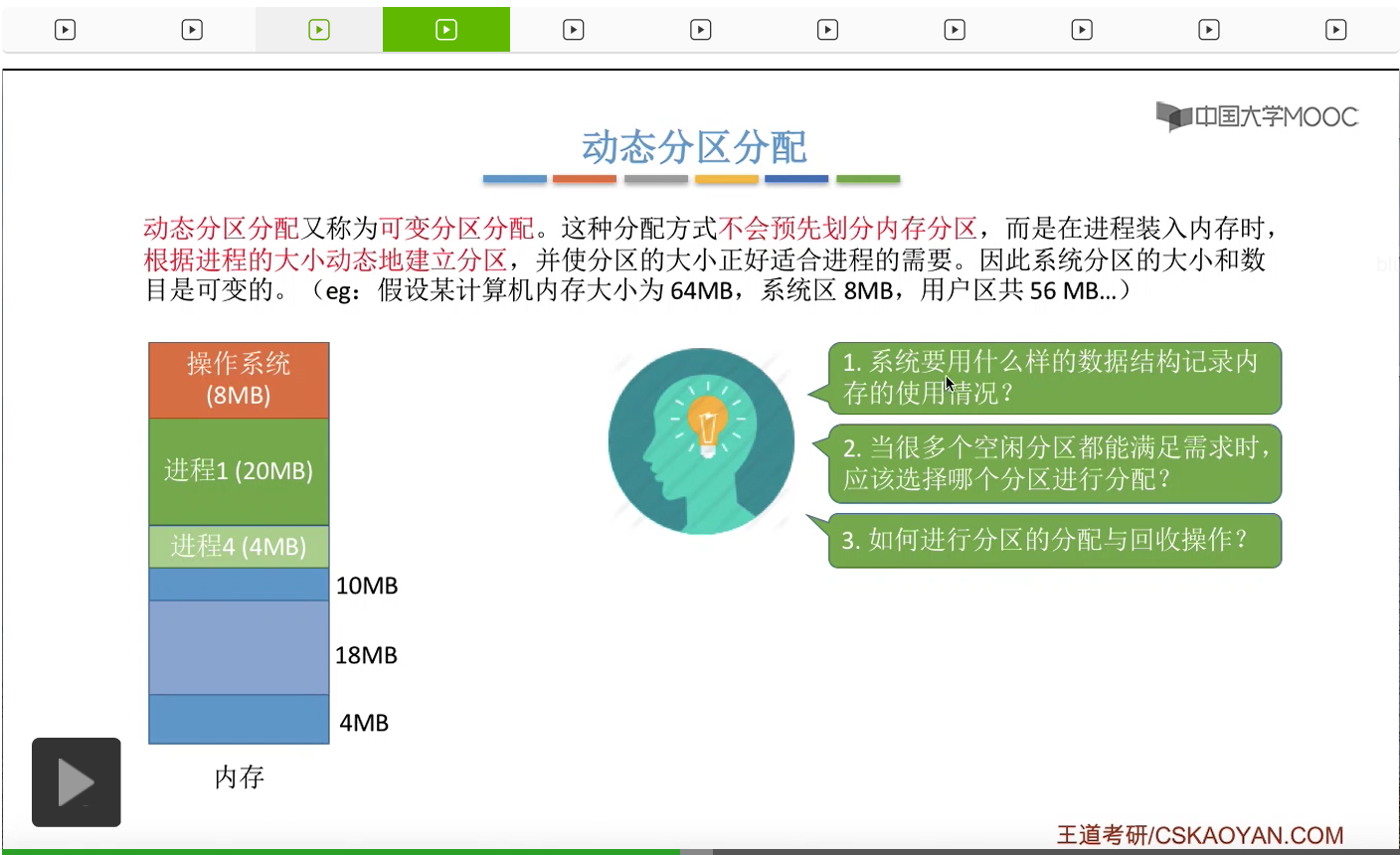
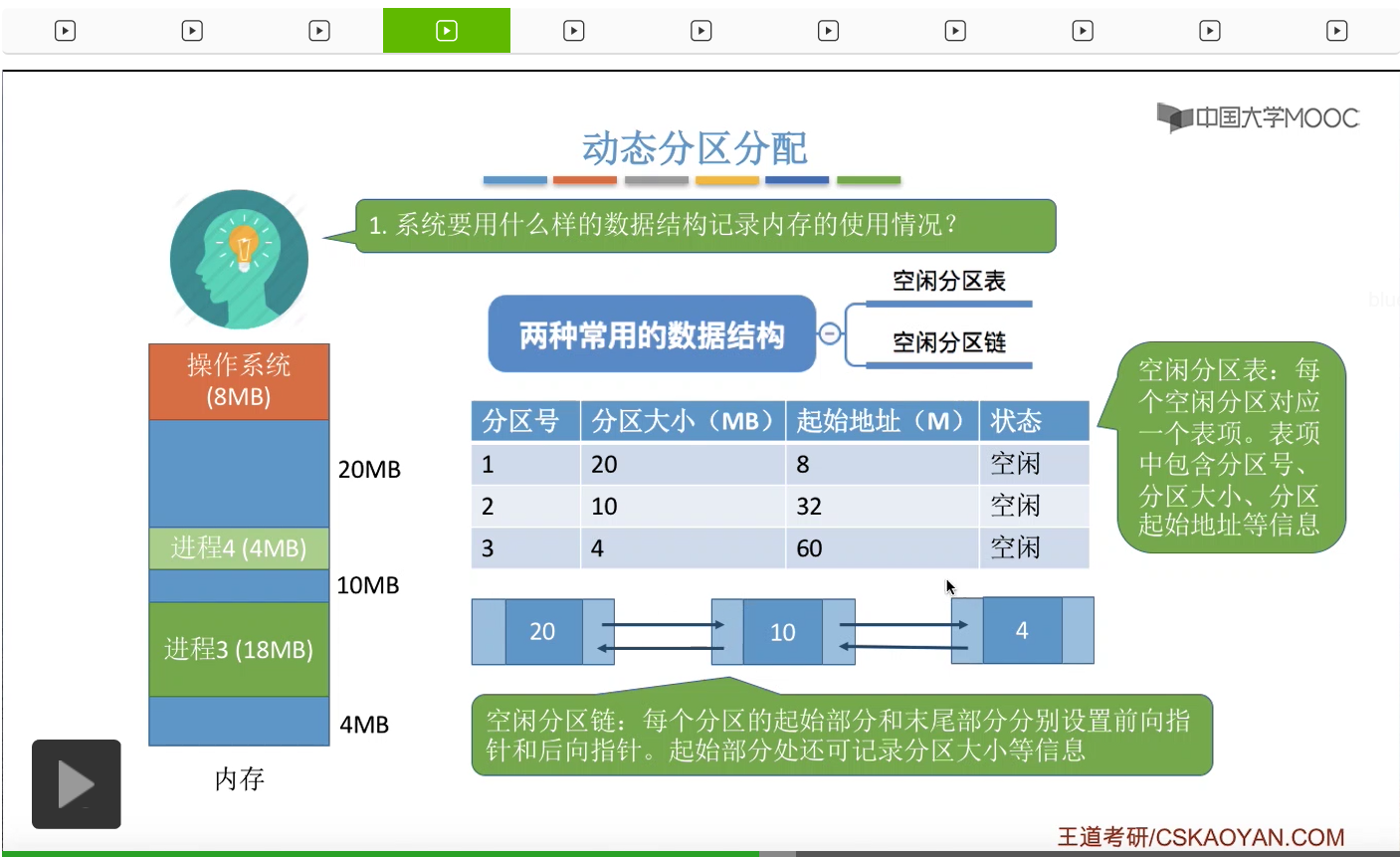
先来看第一个问题,操作系统应该用什么样的数据结构记录内存的使用情况?那一般来说会采用两种常用的数据结构,要么是空闲分区表,或者采用空闲分区链。比如某一个时刻系统当中内存的使用情况是这个样子。总共有三个空闲分区,那么如果采用空闲分区表的话,这个表就会有三个对应的表项,每一个表项会对应一个空闲分区,并且每一个表项都需要记录与这个表项相对应的空闲分区的大小是多少,起始地址是多少等等一系列的信息。那如果说没有在空闲分区表当中记录的那些分区当然就是已经被分配出去的。再来看第二种数据结构,空闲分区链。如果采用这种方式的话,那么每一个分区的起始部分和末尾部分,都会分别设置一个指向前面一个空闲分区和指向后面一个空闲分区的指针,就像这个样子。所以就会把这些空闲分区用一个类似于链表的方式把它们链接起来。那每一个空闲分区的大小,还有空闲分区的起始地址,结尾地址等等这些信息,可以统一地把它们放在各个空闲分区的起始部分。所以这是我们可以采用的两种数据结构——空闲分区表和空闲分区链。
那再来看第二个问题,当有很多空闲分区都可以满足需求的时候,到底应该选择哪个空闲分区进行分配呢?假如此时有一个进程5它只需要4兆字节的空间,那么这个空闲分区、这个分区还有这个分区这三个空闲分区都可以满足它这个需求。那我们应该用哪个分区进行分配呢?那由这个问题我们可以引出动态分区分配算法相关的问题。那所谓的动态分区分配算法,就是要从空闲分区表,或者空闲分区链当中,按照某一种规则,选择出一个合适的分区把它分配给此时请求的这个进程或者说作业。那由于这个分配算法对系统性能造成的影响是很大的,所以人们对于这个问题进行了很多的研究。那这个问题我们现在暂时不展开处理,会在下一个小节进行详细的介绍。

接下来我们再来看第三个问题,如何进行分区的分配与回收?那假设我们采用的是空闲分区表的这种数据结构的话,进行分配的时候需要做一些什么操作呢?那这个地方我们只以空闲分区表为例,其实空闲分区链的操作也是大同小异的。那假如说此时系统当中有这样三块空闲的分区,如果此时有一个进程需要申请四兆字节的内存空间,那假设我们采用了某一种算法,最后决定从这20MB的空闲分区当中摘出四兆分配给这个进程5,
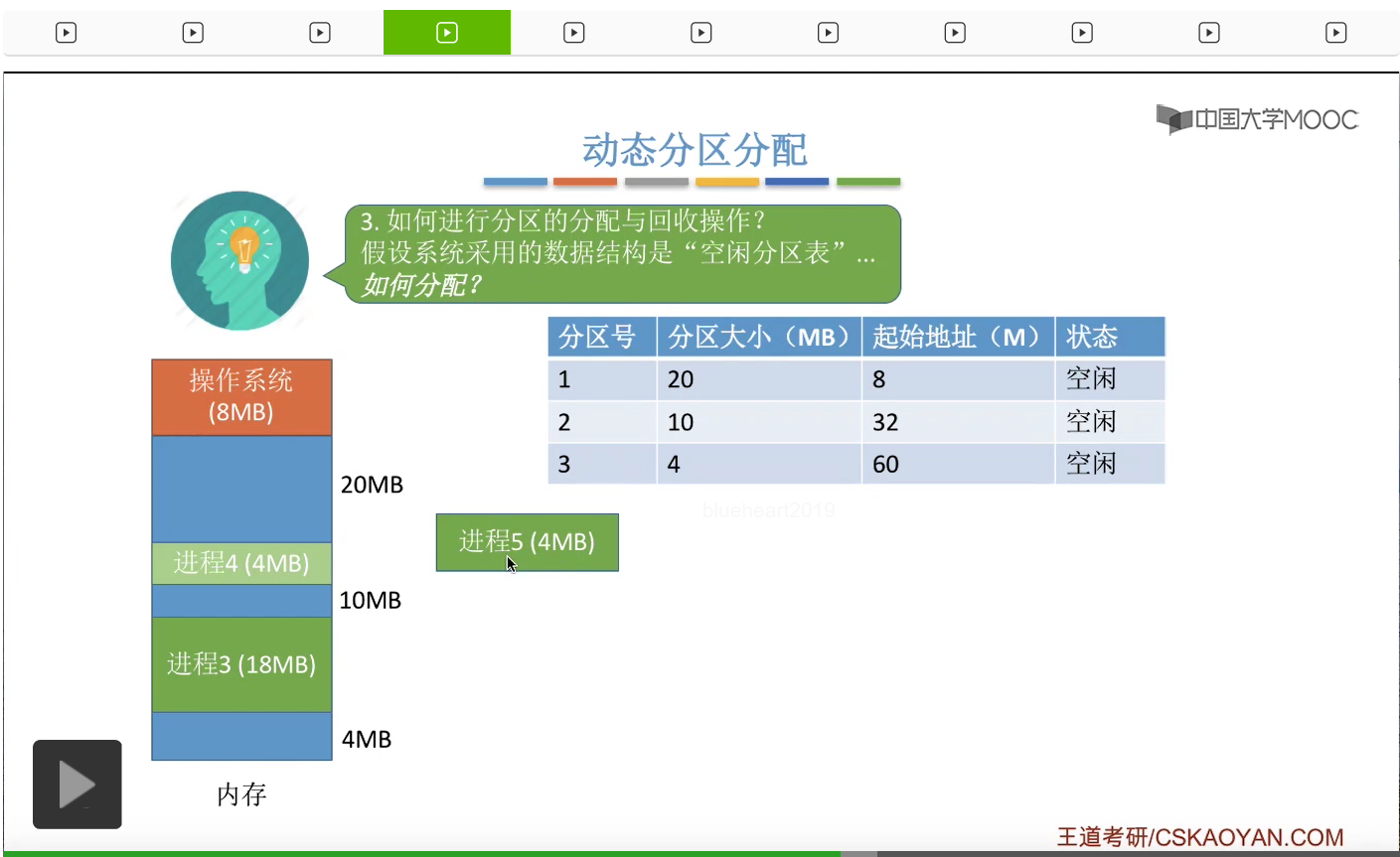
就像这样。那么我们需要对这个空闲分区表进行一定的处理,那由于这个空闲分区的大小本来就是比此次申请的这块内存区域的大小要更大的。所以即使我们从这个分区当中摘出一部分进行了分配,那么分区的数量依然是不会改变的。所以我们只需要在这个分区对应的那个表项当中,修改一下它的分区大小还有起始地址就可以了。那这是第一种情况。
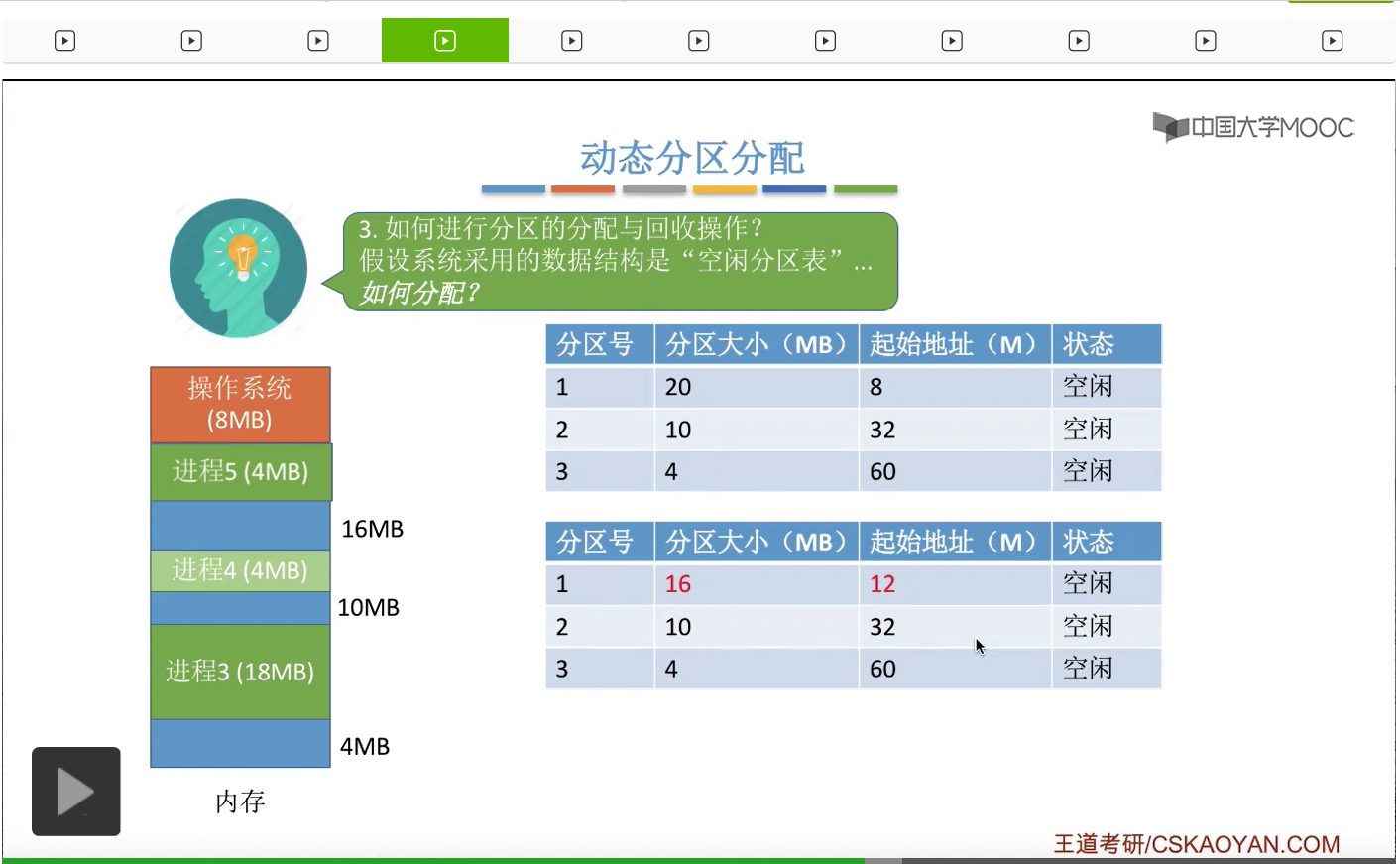
再来看第二种情况。还是相同的地址,有一个进程5需要4MB字节。那如果说我们采用了某种分配算法,最后决定把这4MB字节的空闲分区分配给这个进程5,
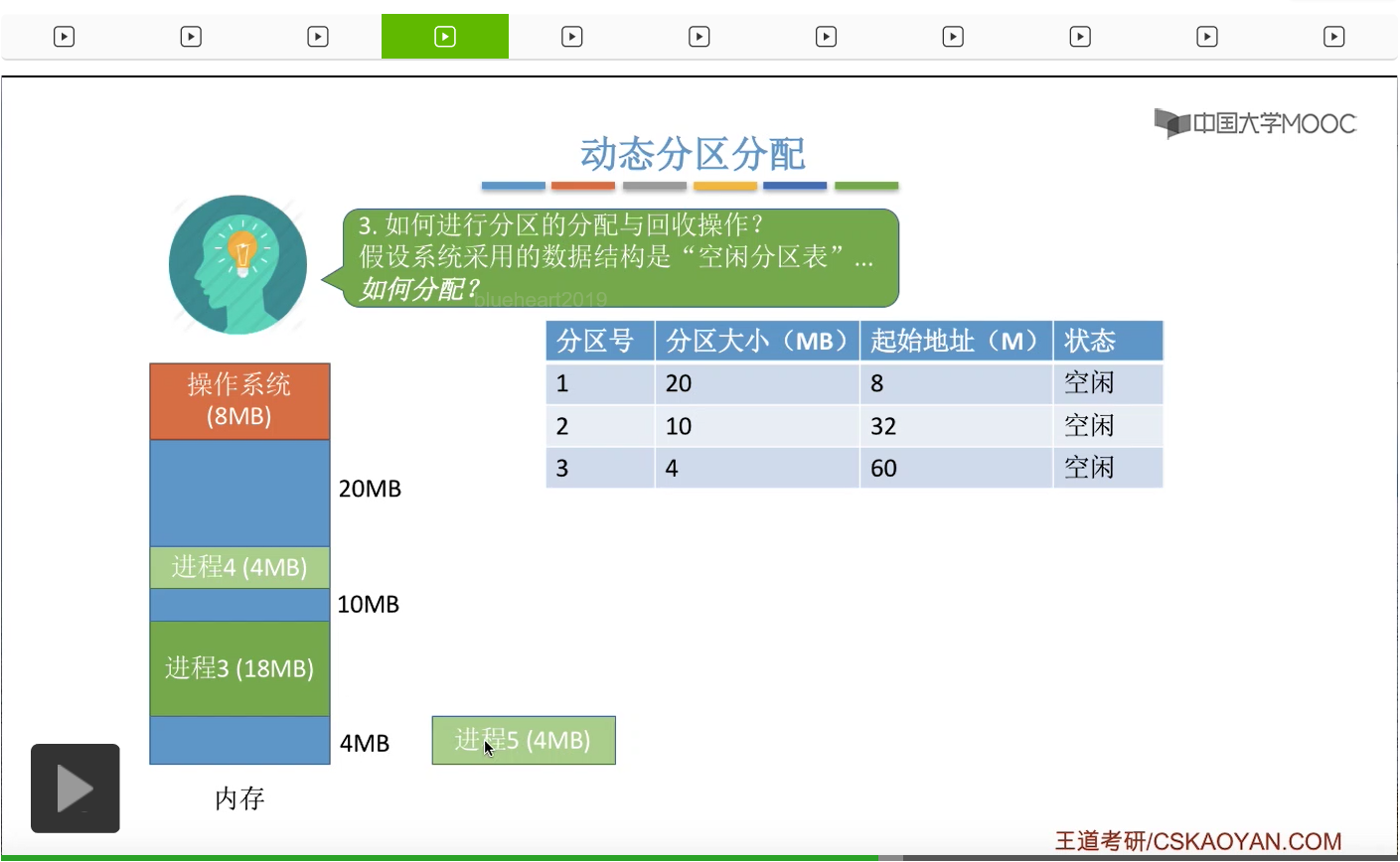
那么本来这个空闲分区的大小就和此次申请的这个内存空间大小是相同的,所以如果把这个分区、空闲分区全部分配给这个进程的话,那么显然空闲分区的数量会减1,所以我们需要把这个分区对应的这个表项给删除。那如果说我们采用的是空闲分区链的话,那我们就只需要把其中的某一个空闲分区链的结点给删掉,那这是分配的时候可能会遇到的两种情况。
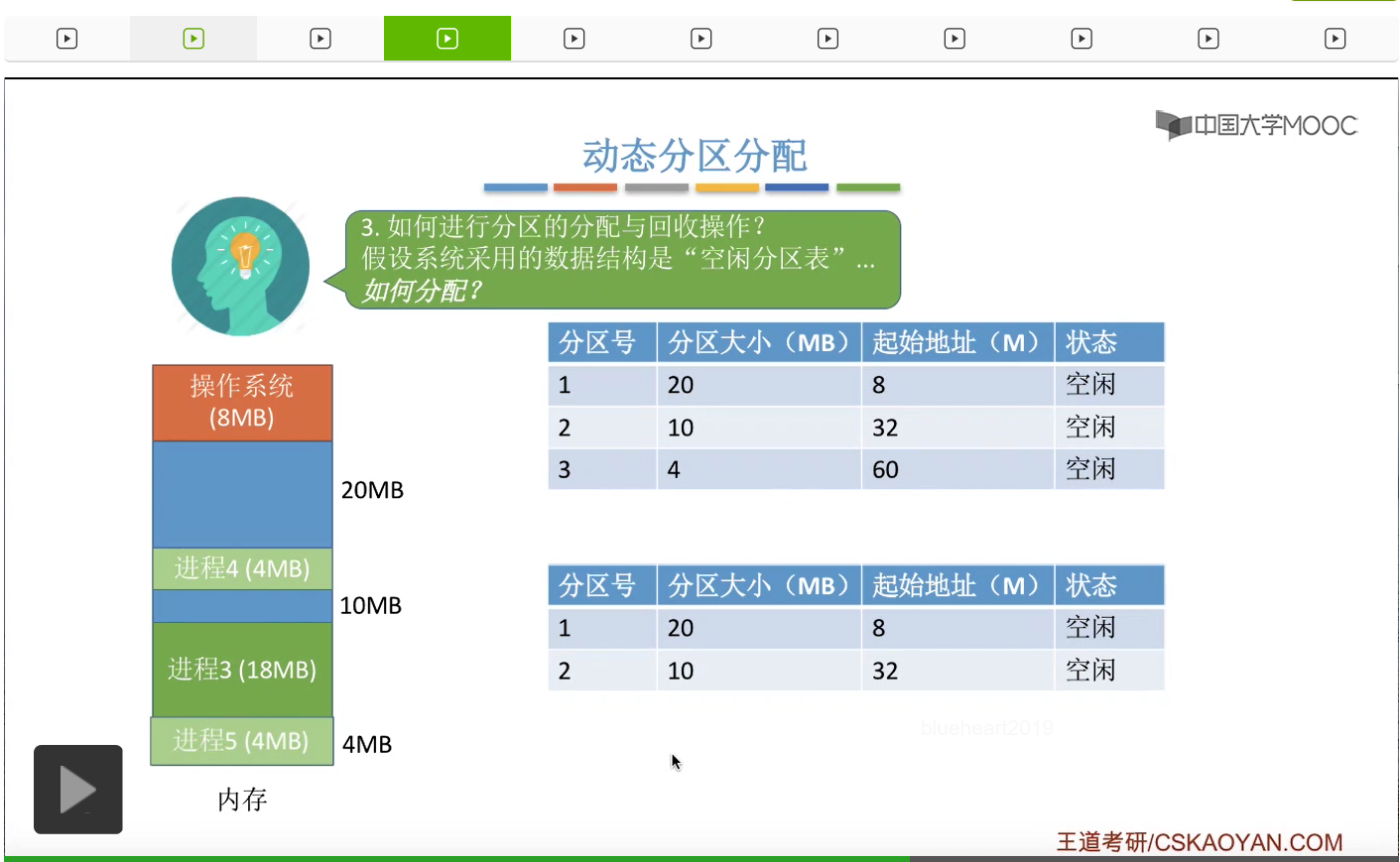
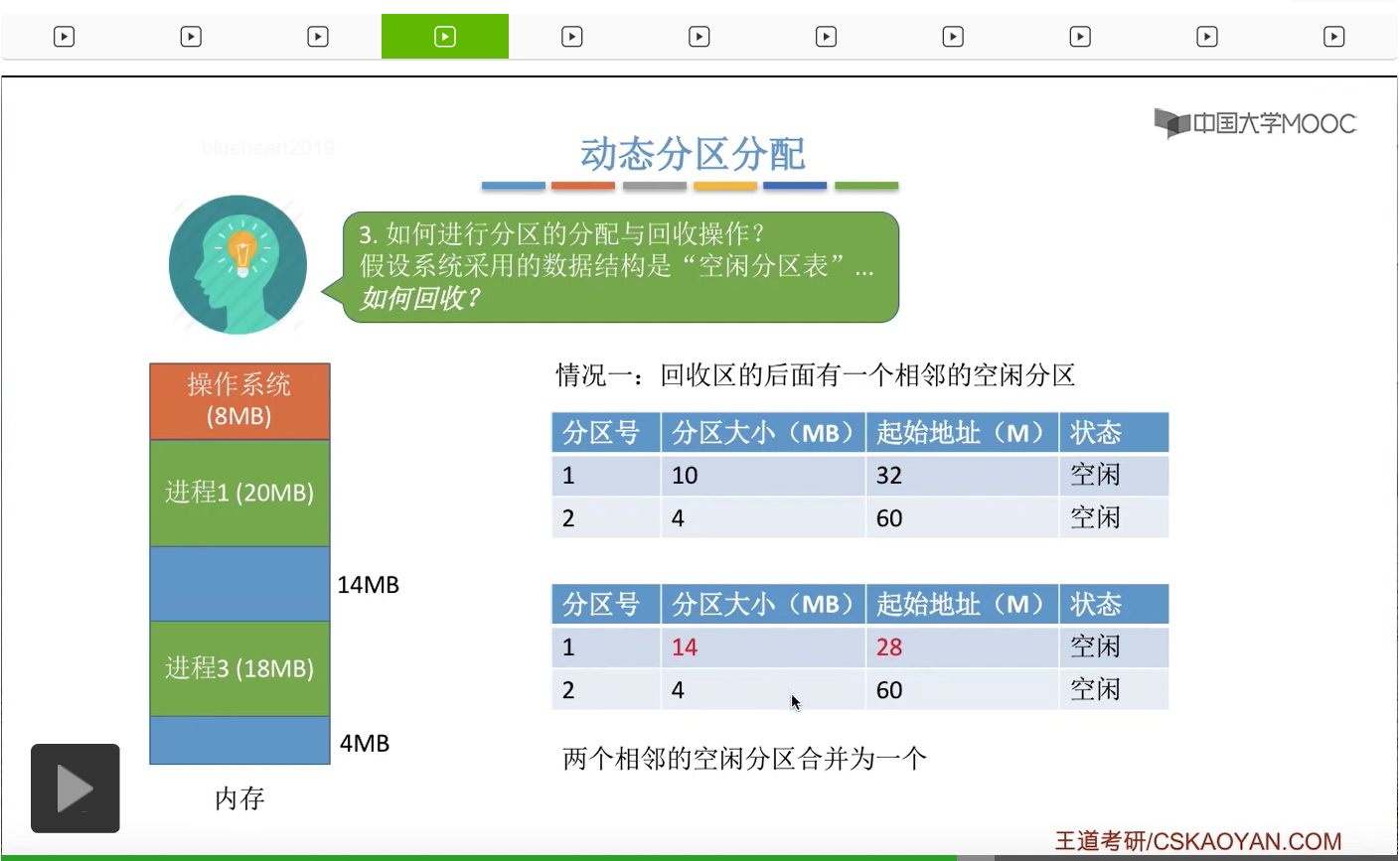
接下来我们再来看进行回收的时候可能会需要做一些什么样的处理?假设此时系统内存中的情况是这样的。那如果采用“空闲分区表”这种数据结构的话,那这个表应该是由两个表项分别对应一个10MB的空闲分区和一个4MB的空闲分区。那假设此时进程4已经运行结束了,我们可以把进程4占用的这4MB字节的空间给回收。那么此时这块回收的区域的后面,有一个相邻的空闲分区,也就是10MB的这块分区,

因此我们把这块内存分区回收之后,我们需要把空闲分区表当中对应的那个表项的分区大小和起始地址也进行一个更新。所以可以看到,如果两个空闲分区相邻的话,那么我们需要把这两个空闲分区进行合二为一的操作。
再来看第二种情况。假设此时进程三已经运行结束了,那么当进程三占用的这一块分区被回收之后,在它的前面也有一个相邻的空闲分区,
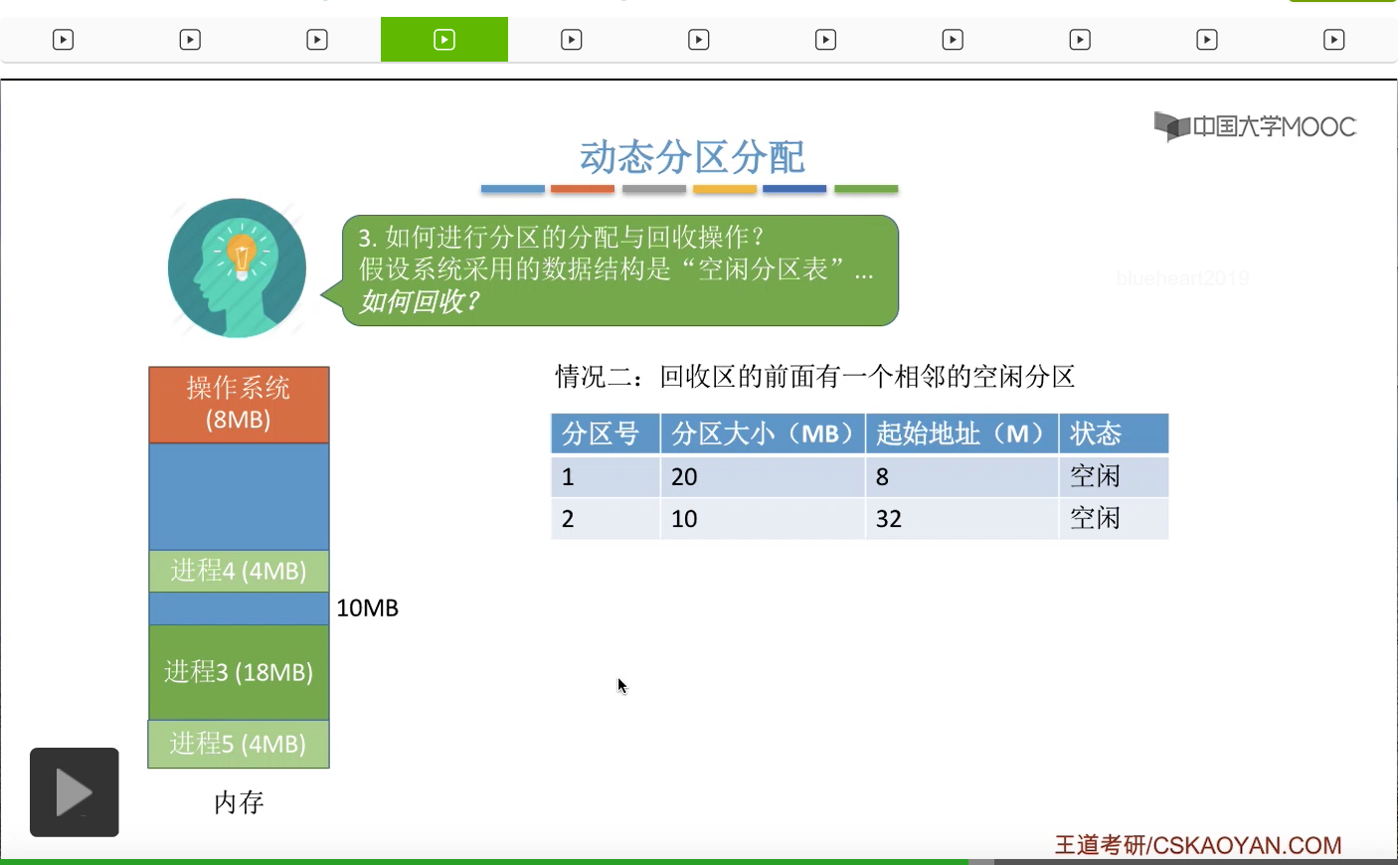
所以参照刚才的那种思路,我们也需要把这两块相邻的空闲分区进行合二为一的操作。那这和之前的那种情况其实是很类似的。
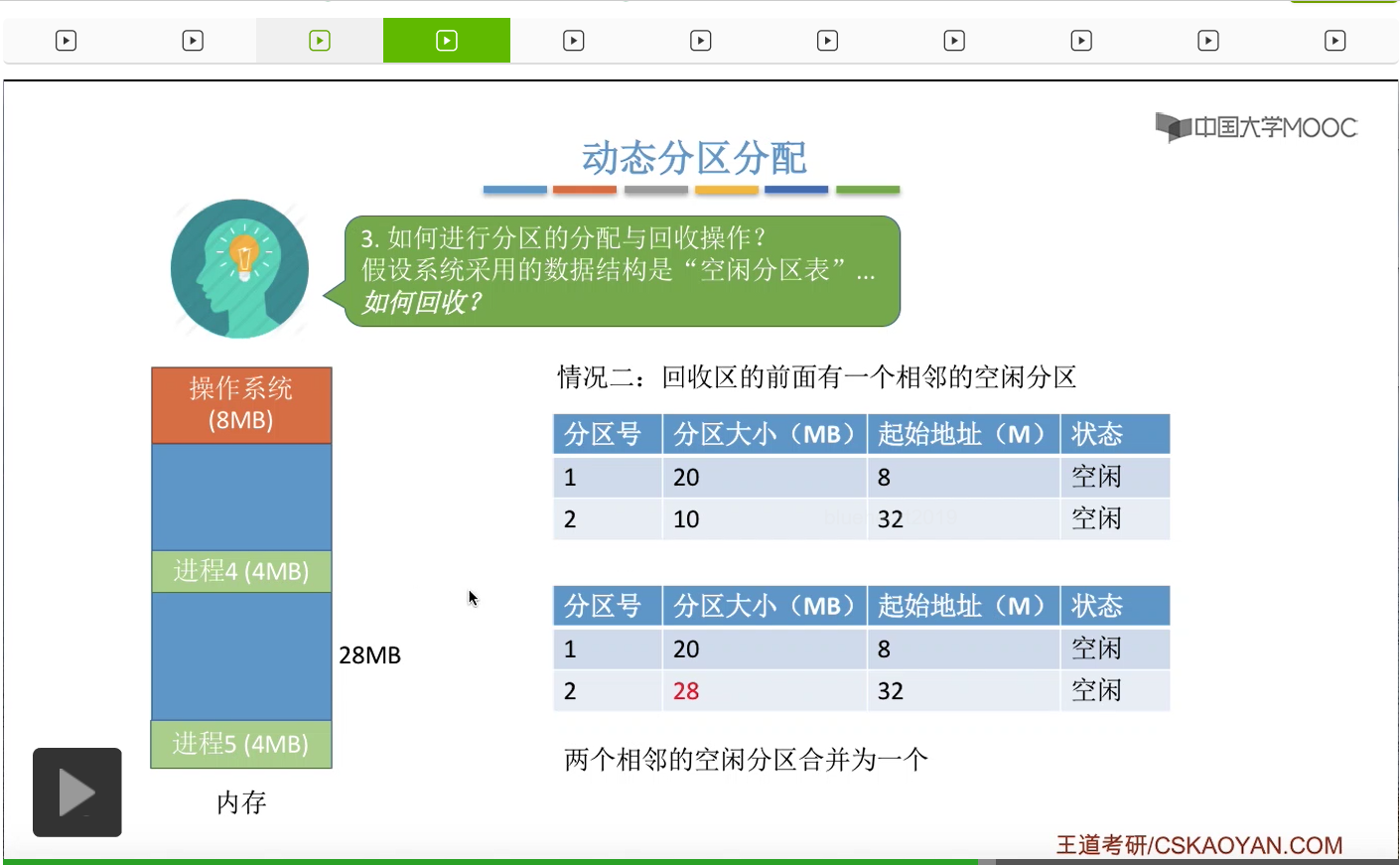
再看第三种情况。假设此时进程四已经运行结束,需要把这四兆字节给回收,那么进程四的前面和后面都会有一个相邻的空闲分区。所以本来我们的空闲分区表有三个表项,也就是有三个空闲分区,

但是当进程四的这块空间被回收之后,需要把这一整块的空间都进行一个合并。所以本来系统中有三个空闲分区,但如果把进程四回收之后就会合并为两个空闲分区。那当然我们也需要修改相应表项的这些分区大小、起始地址等等这一系列的信息。那这第三种情况需要把三个相邻的空闲分区合并为一个。

再来看第四种情况。假如回收区的前后都没有相邻的空闲分区的话,应该怎么处理。假设此时进程2已经运行结束,那么当进程2的这块内存区间被回收之后,
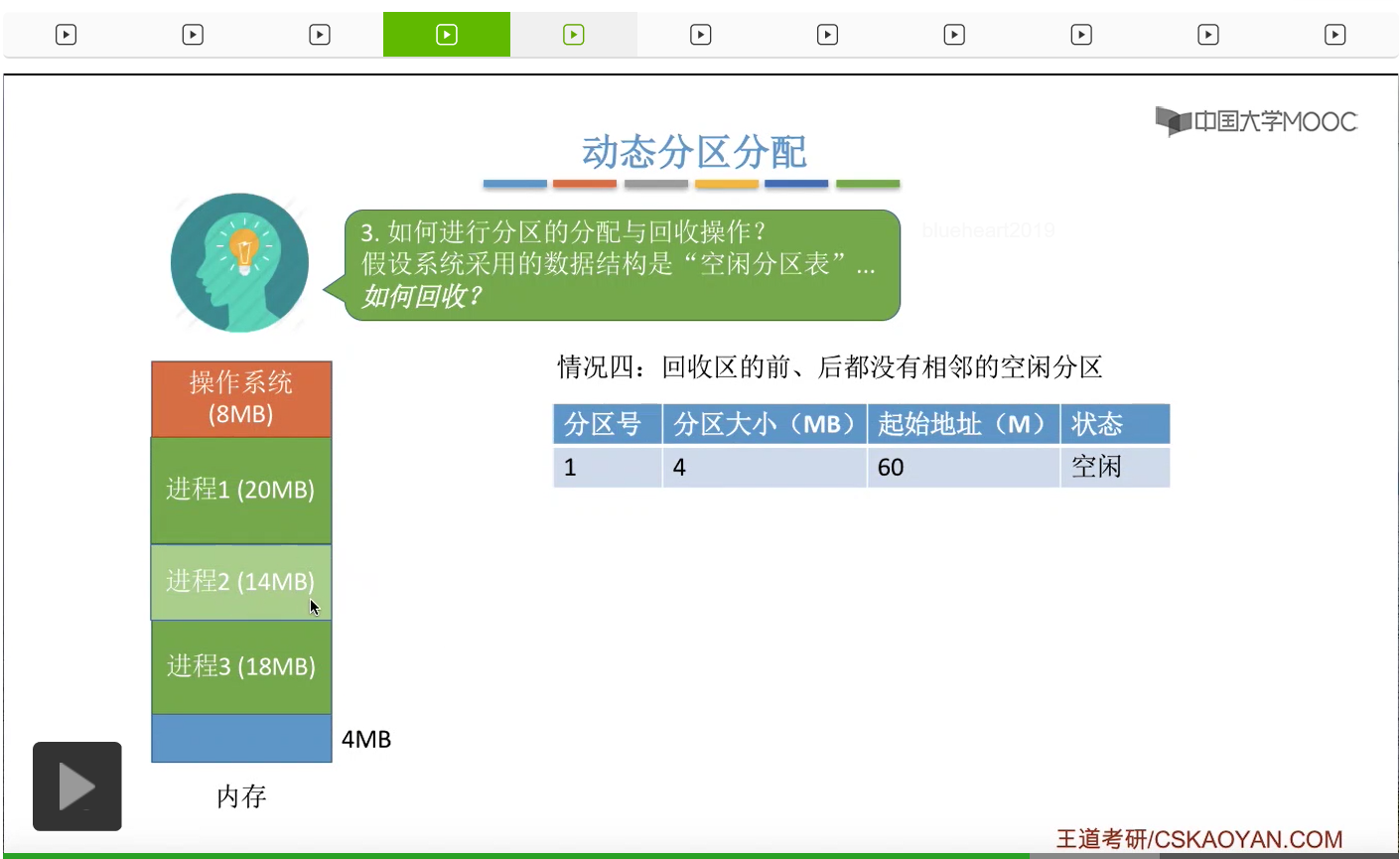
系统当中就出现了两块空闲分区。所以相应的我们当然也需要增加一个空闲分区表的表项。那通过刚才的这一系列讲解,大家可能会发现,我们对空闲分区表的这种顺序一般来说是采用这种按照起始地址的先后顺序来进行排列的。但是这个并不一定,各个表项的排序我们一般来说需要根据我们采用哪种分区分配算法来确定。比如说有的时候我们按照分区从大到小的顺序排列会比较方便,有的时候我们按照分区大小从小到大进行排列比较方便。当然也有的时候我们就像现在这样按照起始地址的先后顺序来进行排列会比较方便。那这个地方会到下一个小节进行进一步的解释。那到这个地方,我们就回答了之前提出的三个问题,第一个问题我们需要用什么样的数据结构来记录内存的使用情况。一般来说会使用两种数据结构——空闲分区表或者空闲分区链。那第二个问题涉及到动态分区分配算法就会在下一个小节中进行进一步的解释。第三个问题我们讨论了怎么对内存的空间进行分配与回收。进行分配与回收的时候需要对这些数据结构进行什么处理。那特别需要注意的是,在回收的过程中,我们有可能会遇到四种情况。不过本质上我们可以用一句话来进行总结,在进行内存分区回收的时候如果说回收了之后发现有一些空闲分区是相邻的,那么我们就需要把这些相邻的空闲分区全部给合并。

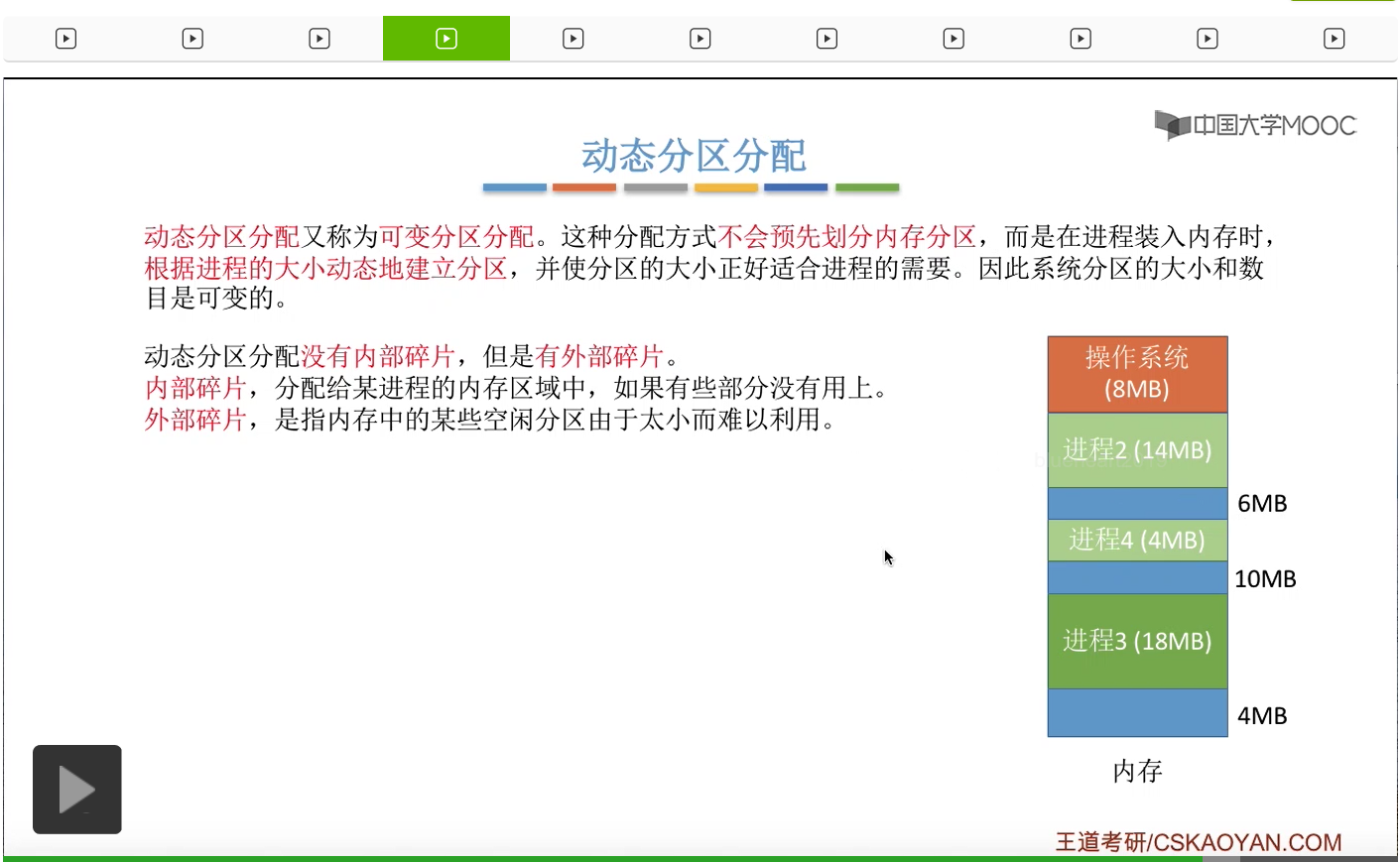
那接下来我们再来讨论一下动态分区分配关于内部碎片和外部碎片的问题。这儿我们给出了内部碎片和外部碎片的完整的定义,内部碎片是指分配给某个进程的内存区域当中,如果说有些部分没有用上,那么这些部分就是所谓的内部碎片。注意是分配给这个进程但是这个进程没有用上的那些部分。而外部碎片是指内存当中的某些空闲分区由于太小而难以利用。那因为各个进程需要的都是一整片连续的内存区域,所以如果这些空闲的分区太小的话那么任何一个空闲分区都不能满足进程的需求,那这种空闲分区就是所谓的外部碎片。

比如说我们系统当中依次进入了进程1、进程2、进程3它们的大小分别是这样。然后这个时候内存当中只剩下一片空闲的内部区域,就是4M字节这么大。那么此时如果进程2暂时不能运行,

我们可以暂时把它换出到外存当中。那于是这块就有14M字节的空闲区域。

那接下来进程4到达占用4M字节,

那这一块就应该是10M字节的大小。之后如果进程1也暂时不能运行,那么我们可以把进程1暂时换出外存。

于是这个地方可以空出20M字节的连续的空闲区间。

那接下来如果进程2又可以恢复运行了,它再回到内存当中,它又占用了其中的14M字节。

于是这一块就只剩下6M字节。
那接下来如果说进程1也就是20M字节的这个进程又可以执行了又想回到内存的话,那么此时会发现内存当中的任何一个区域都已经不能满足进程1的这个需求了。所以这就产生了所谓的外部碎片。这些空闲区间是暂时没有分配给任何一个进程的,但是由于它们都太小了太零碎了所以没办法满足这种大进程的需求。那像这种情况下,其实内存当中总共剩余的内存区间其实是6+10+4,也就是总共有20M字节。也就是说内存当中空闲区间的总和其实是可以满足进程1的需求的。所以在这种情况下,我们可以采用紧凑技术或者是拼凑技术来解决外部碎片的问题。那紧凑技术很简单,

其实就是把各个进程挪位,

把它们全部攒到一起,

然后挪出一个更大的空闲、连续的空闲区间出来。

这样的话,这块空闲区间就可以满足进程1的需求了。那这个地方大家也可以停下来回忆一下咱们刚才提到的换入换出技术和中级调度相关的一些概念,这是咱们之前讲过的内容。那显然咱们之前介绍的三种装入方式当中,动态重定位的方式其实是最方便实现这些程序或者说进程在内存当中移动位置这件事情的,所以我们采用的应该是动态重定位的方式。另外,紧凑之后我们需要把各个进程的起始地址给修改掉。那进程的起始地址这个信息一般来说是存放在进程对应的PCB当中。当进程要上CPU运行之前,会把进程的起始地址那个信息放到重定位寄存器里,或者叫基址寄存器里。那大家对这些概念还有没有印象呢?

那这个小节我们介绍了三种连续分配管理的分配方式。连续分配的特点就是为用户进程分配的必须是一个连续的内存空间。那么我们分别介绍了单一连续分配、固定分区分配和动态分区分配这三种分配方式。
那之前咱们留下了一个问题,单一连续分配和固定分区分配都不会产生外部碎片。那由于采用这两种分配方式的情况下,不会出现那种暂时没有被分配出去但是又由于这个空闲区间太小而没有办法利用的这种情况,所以这两种分配方式是不会产生外部碎片的。那对于是否有外部碎片还是内部碎片这个知识点经常在选择题当中进行考查,大家千万不能死记硬背,一定要在理解了各种分配方式的规则的这种情况下,能够自己分析到底有没有外部碎片,有没有内部碎片。另外,动态分区分配方式当中对外部碎片的处理“紧凑”技术也是曾经作为选择题的选项进行考查过,这个地方也需要有一些印象。那在回收内存分区的时候我们可能会遇到的这四种情况也是曾经在真题当中考查过所以这个点也需要注意。不过只需要抓住一个它的本质,相邻的空闲区间是需要合并的,我们只要知道这一点就可以了。另外呢我们也需要对空闲分区表和空闲分区链这两种数据结构相关的概念还有它们的原理也要有一个印象。

在这个小节中我们会学习动态分区分配算法相关的知识点,

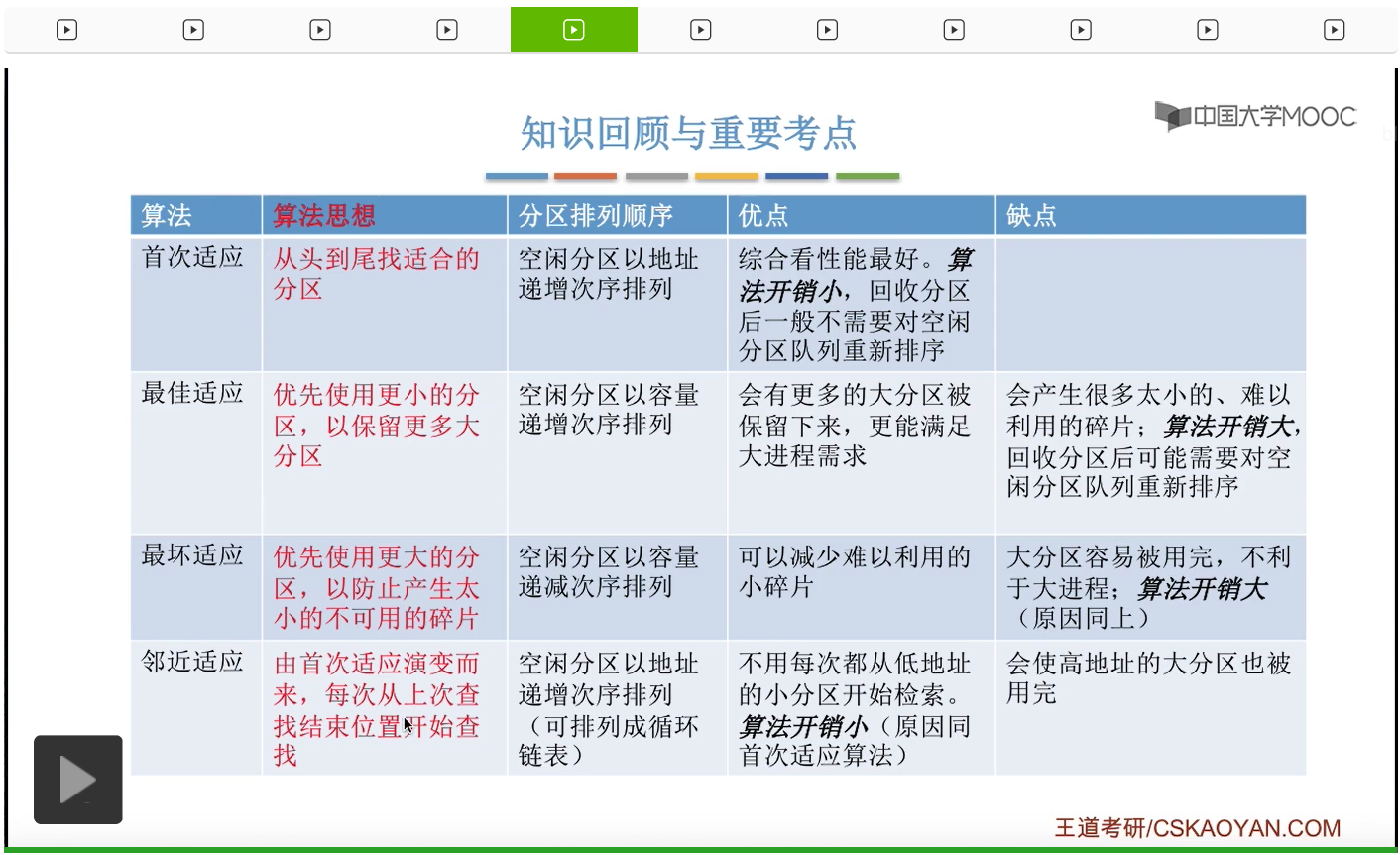
那这是我们上小节遗留下来的问题。在动态分区分配方式当中,如果有很多个空闲分区都能够满足进程的需求,那么我们应该选择哪个分区进行分配呢?这是动态分区分配算法需要解决的问题。那考试当中,要求我们掌握的有这样四种算法,首次适应、最佳适应、最坏适应、邻近适应这四种,我们会按从上至下的顺序依次讲解。

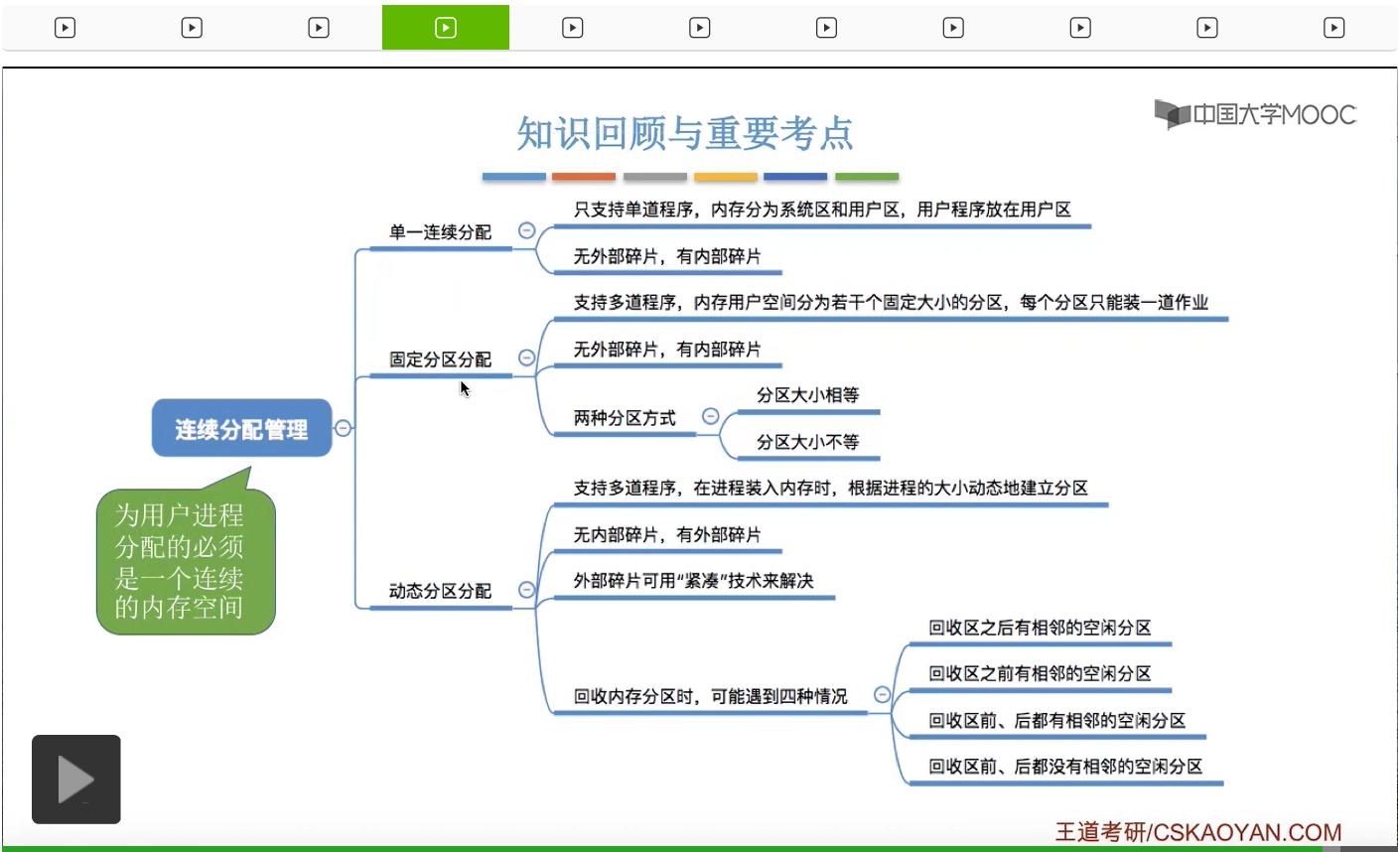
首先来看首次适应算法。这种算法的思想很简单,就是每次从低地址部分开始查找,找到第一个能够满足大小的空闲分区。所以按照这种思想,我们可以把空闲分区按照地址递增的次序进行排列,而每一次分配内存的时候我们就可以顺序地查找空闲分区链或者空闲分区表,找到第一个大小能够满足要求的空闲分区进行分配。那这个地方提到了空闲分区链和空闲分区表,这是两种常用于表示动态分区分配算法当中内存分配情况的数据结构。那如果我们此时系统当中内存的使用情况是这样的,那采用空闲分区表的话,我们就可以得到一个这样的表。每一个空闲分区块都会对应一个空闲分区表的表项,那这些空闲分区块是按地址从低到高的顺序依次进行排列的。那如果采用空闲分区链的话,其实也类似,也是按照地址从低到高的顺序把这些空闲分区块依次地链接起来。那这个算法对这两种数据结构的操作其实是很类似的,无非就是从头到尾依次检索,然后找到第一个能够满足要求的分区。所以这个地方我们就以空闲分区链为例子。空闲分区表的操作其实也类似。
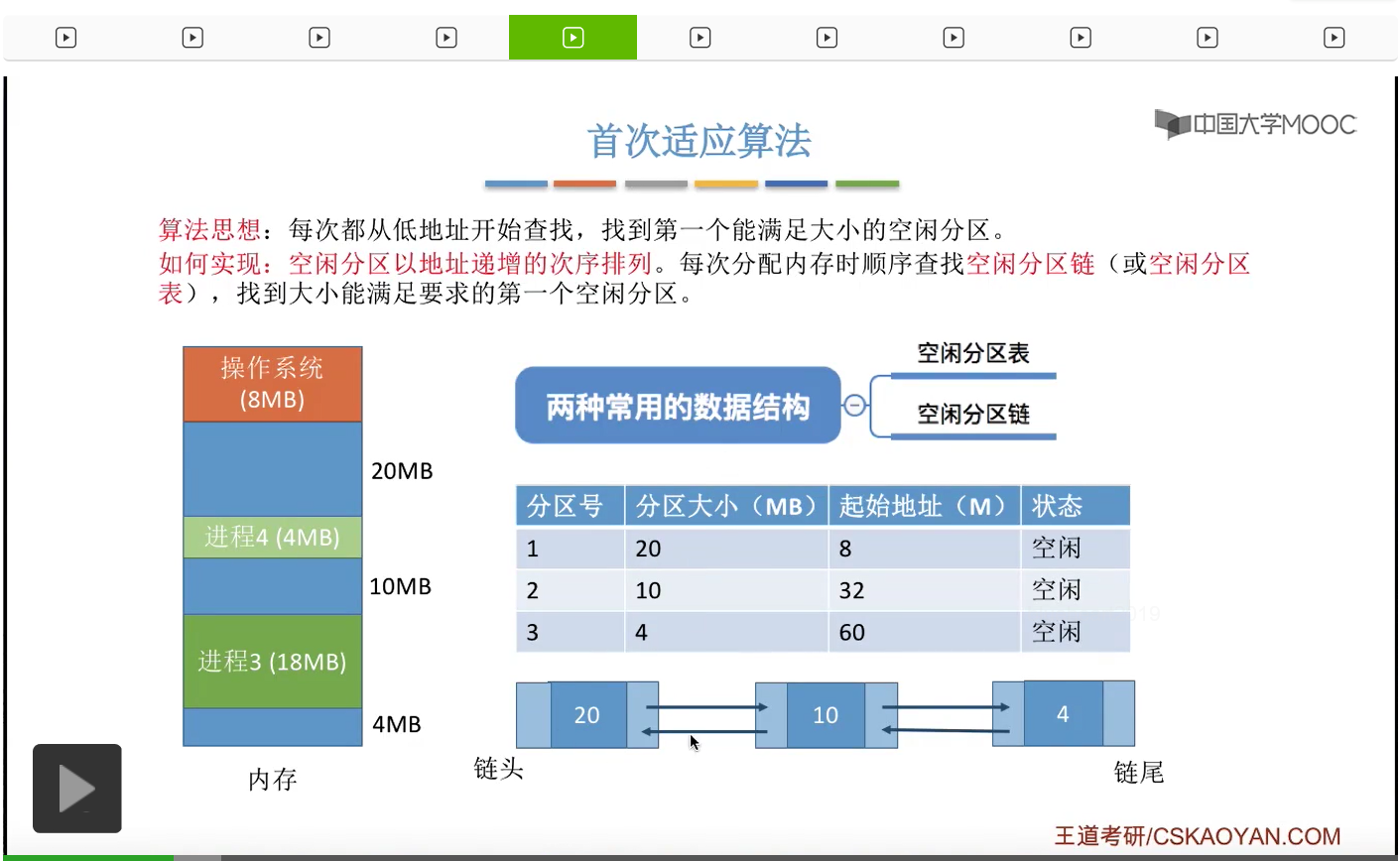
那按照首次适应算法的规则,那如果说此时有一个进程要求15M字节的空闲分区,那么我们会从空闲分区链的链头开始,依次查找找到第一个能够满足大小的分区。那经过检查发现第一个20M字节的这个空闲分区,已经可以满足这个要求。

所以我们会从20M字节的空闲分区当中,摘出15M分配给进程5,于是这个地方会剩余5M字节的空闲分区。
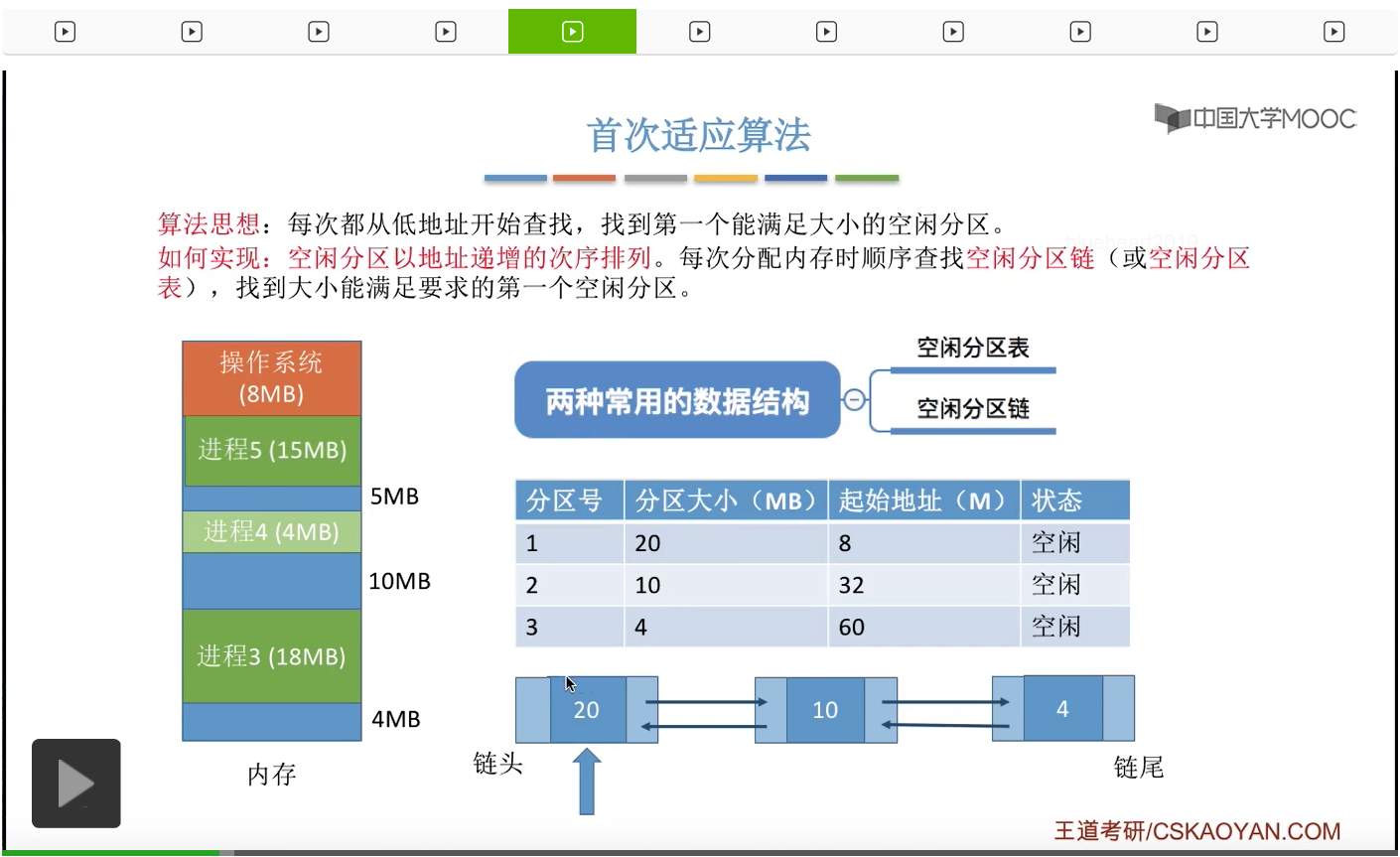
那相应的,我们需要把空闲分区链的对应结点的这些数据包括分区的大小还有分区的起始地址等等这一系列的数据都进行修改。
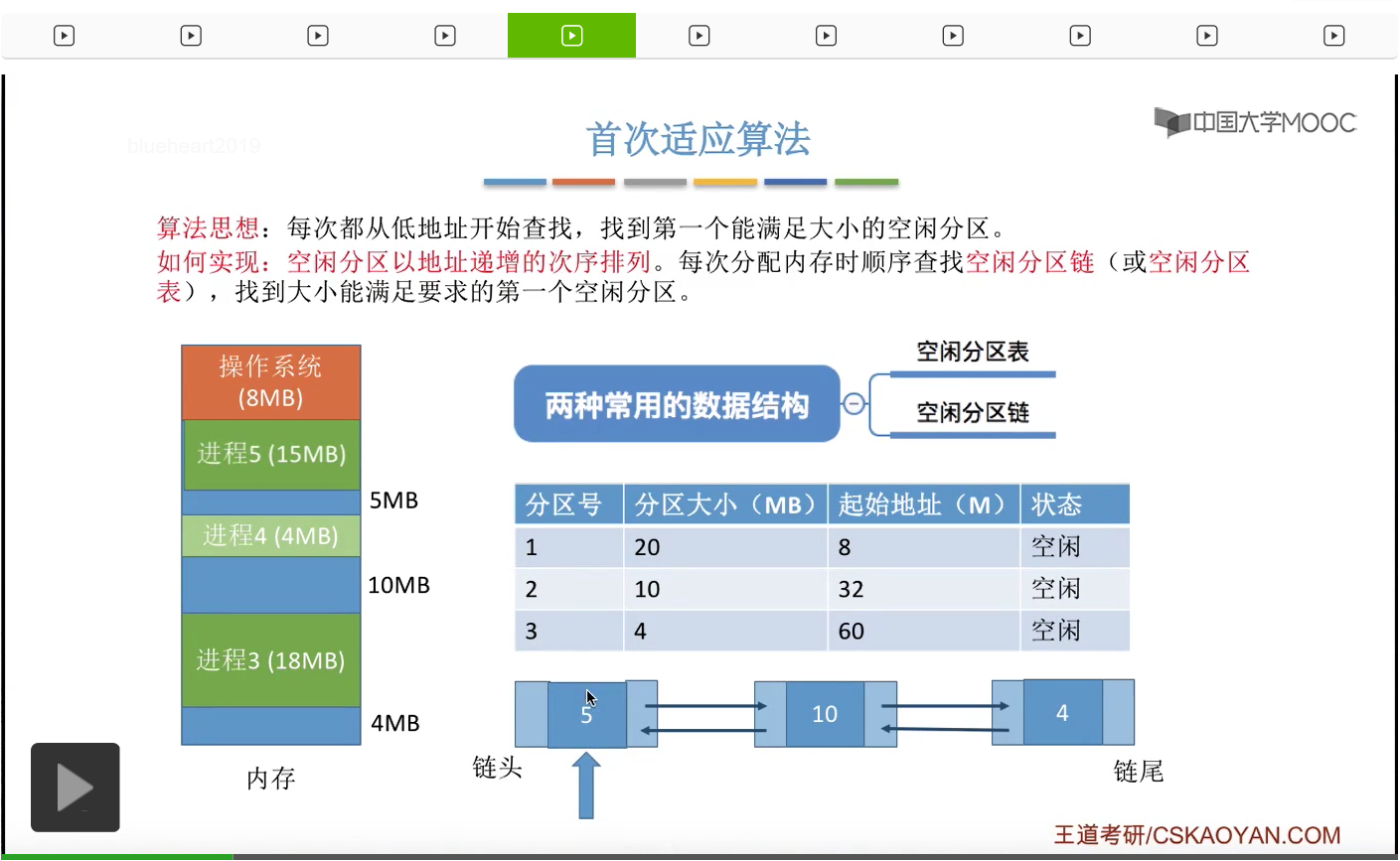
那么此时如果还有一个进程到来,它需要8M字节的内存空间。那我们依然还是会从空闲分区链的链头开始依次检索,
那经过一系列的检索会发现,
第二个空闲分区的大小是足够的,于是我们会从第二个空闲分区10M字节当中,
摘出8M分配给进程6。那这个地方会剩余2M字节的空闲分区。所以我们和刚才一样,也需要修改空闲分区链当中相应的分区大小还有分区的起始地址这一系列的信息。那这个地方就不再展开赘述。所以这就是首次适应算法的一个规则,我们按照空闲分区以地址递增的次序进行排列,并且每一次分配内存的时候我们都会从链头开始依次往后寻找,找到第一个能够满足要求的空闲分区进行分配。
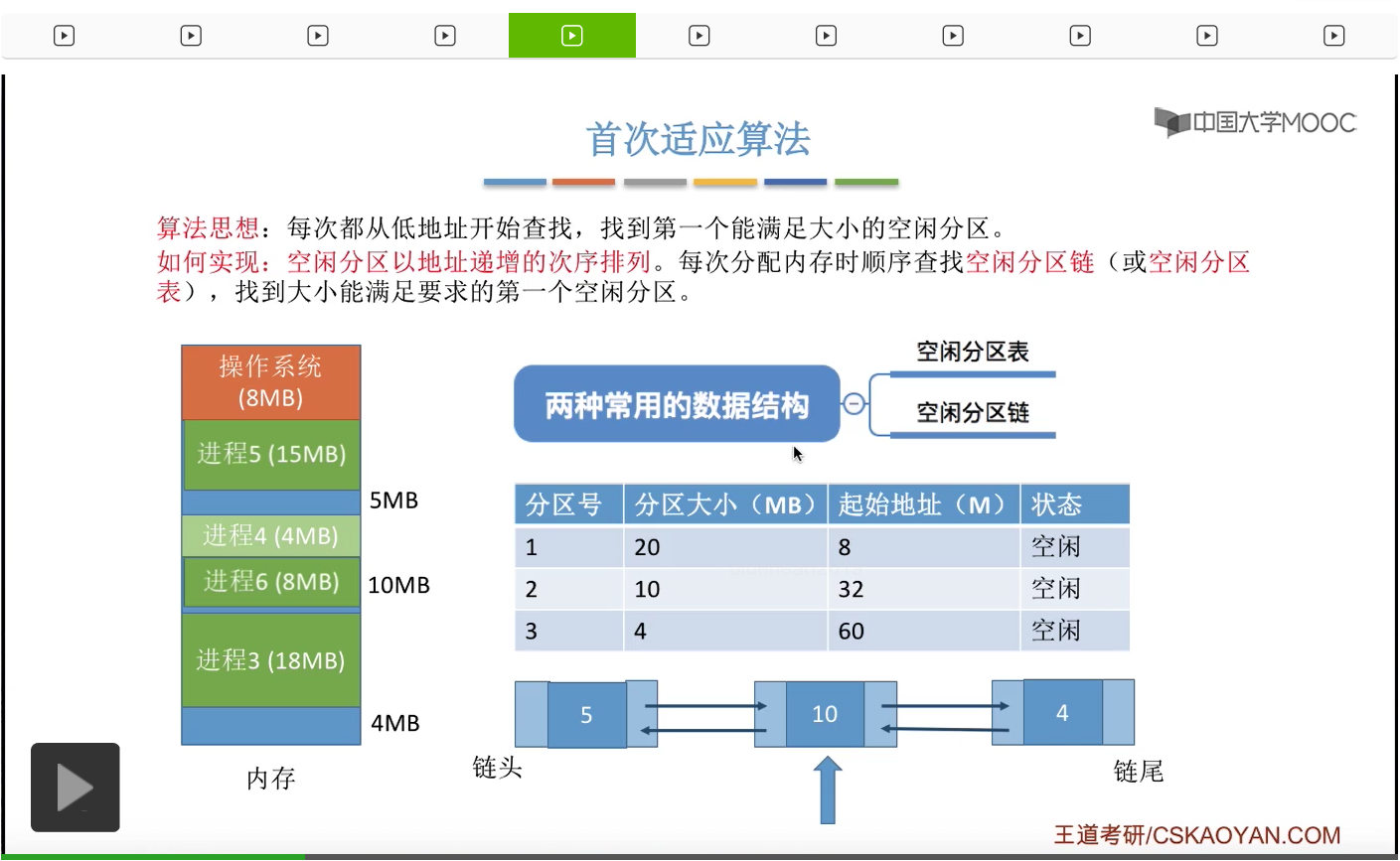
接下来来看最佳适应算法,这种算法的思想其实也很好理解。由于动态分区分配算法是一种连续分配的方式,那既然是连续分配就意味着我们系统为各个进程分配的空间必须是连续的一整片区域。所以我们为了保证大进程到来的时候有大片的连续空间可以供大进程使用,所以我们可以尝试尽可能多地留下大片的空闲区间。那也就是说,我们可以优先地使用更小的那些空闲区间。所以最佳适应算法会把空闲分区按照容量递增的次序依次链接。那每次分配内存的时候会从头开始依次查找空闲分区链或者空闲分区表,找到大小能够满足要求的第一个空闲分区。那由于这个空闲分区是按容量递增的次序排序排列的,所以我们找到的第一个能够满足的空闲分区,一定是能够满足但是大小又最小的空闲分区。那这样的话我们就可以尽可能多地留下大片的空闲分区了。那这个地方还是一样,我们就以空闲分区链作为例子,空闲分区表的操作其实也类似。如果说系统当中的内存使用情况是这个样子,那么我们按照空闲分区块的大小从小到大也就是递增的次序链接的话,那应该是4、10、20这样的顺序链接。如果说此时有一个新的进程到达,那这个进程需要9M字节的内存空间的话,按照最佳适应算法的规则,我们会从链头开始依次往后检索,找到第一个能够满足要求的空闲分区也就是10M字节。
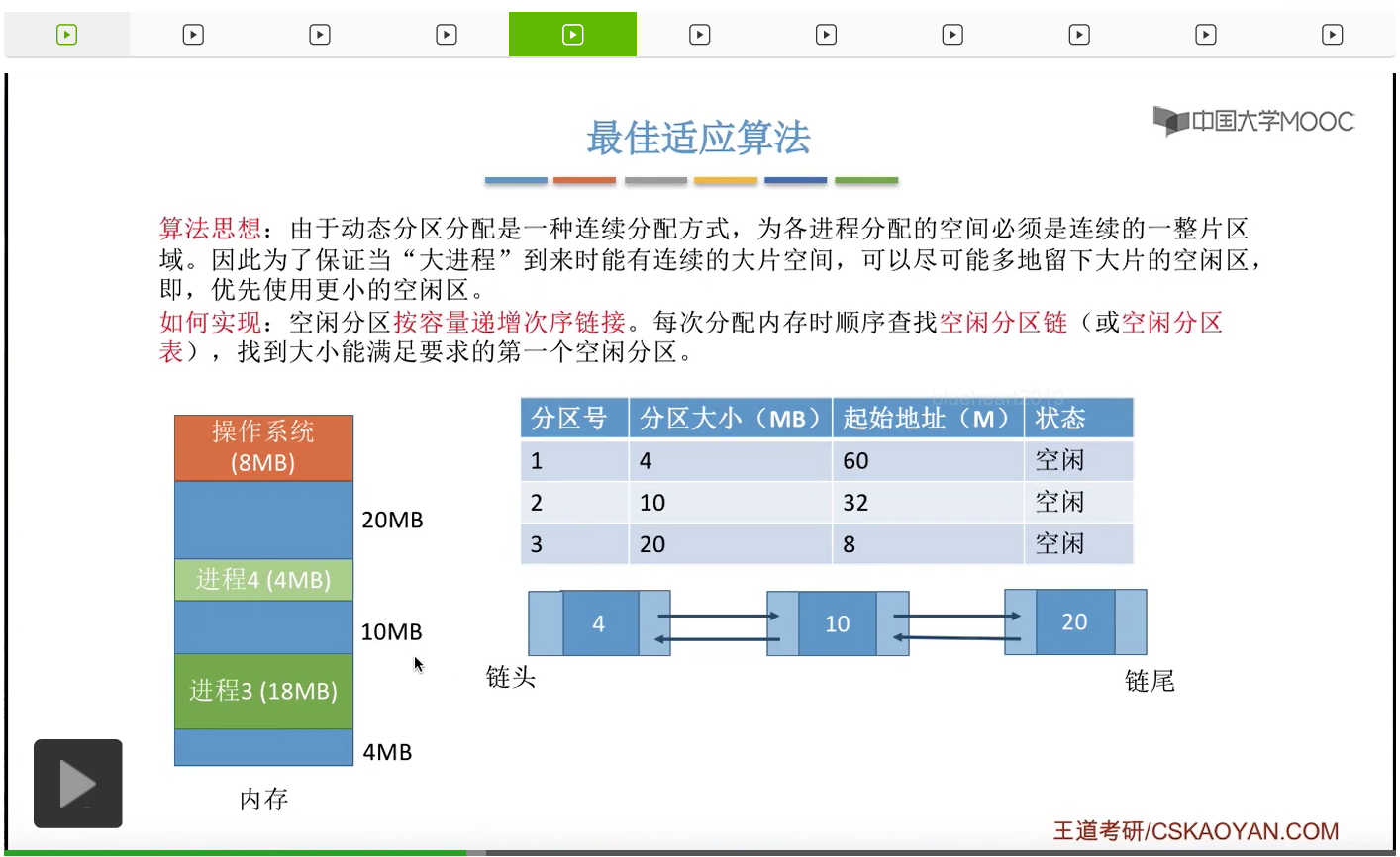
于是我们会从这10M字节当中摘出其中的9M分配给这个进程,那这个地方就要只剩下1M字节的大小。但是由于最佳适应算法要求我们空闲分区必须按照容量递增的次序进行链接,所以这个地方变成了1M之后我们就需要对这个整个空闲分区链进行重新排序,
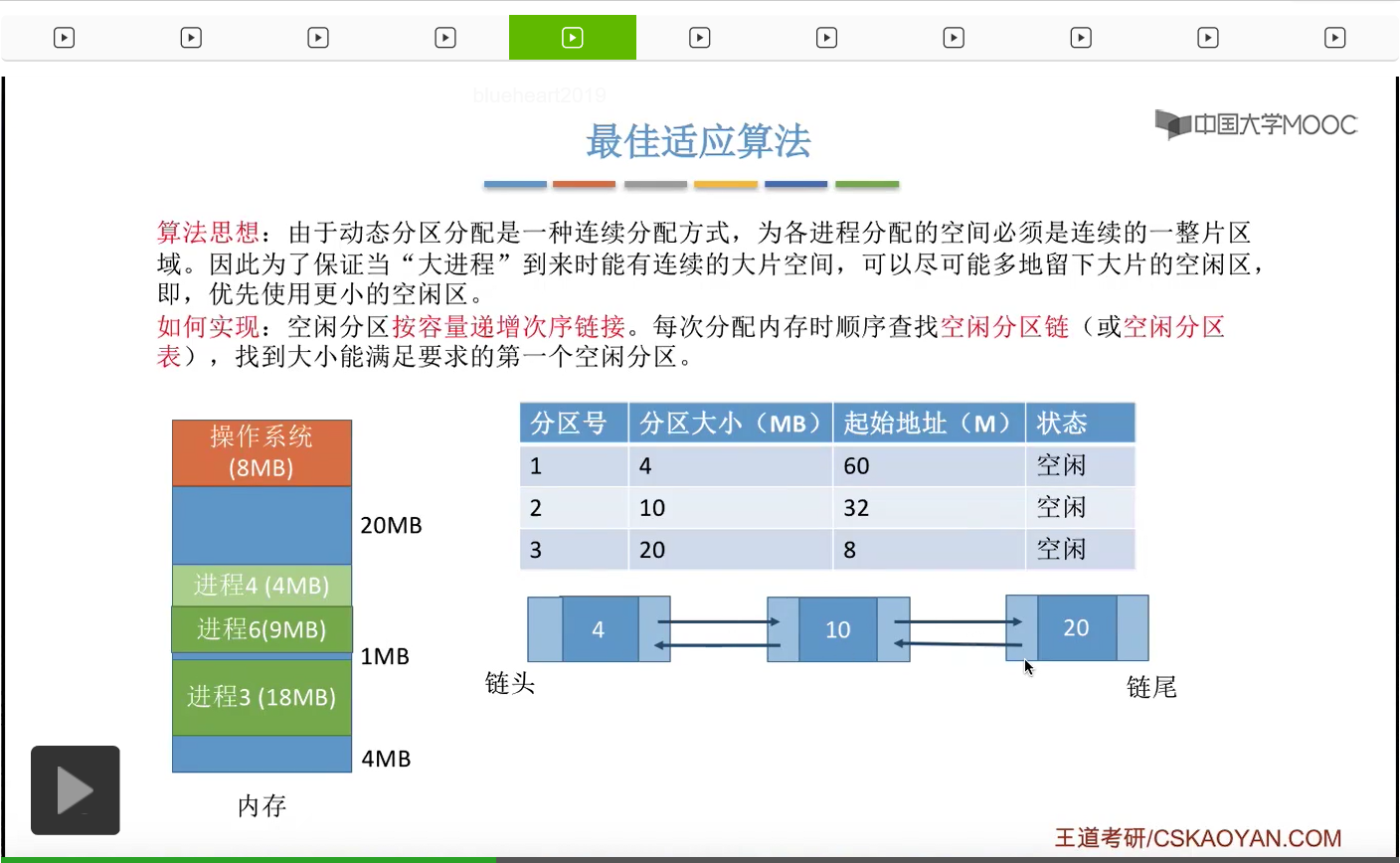
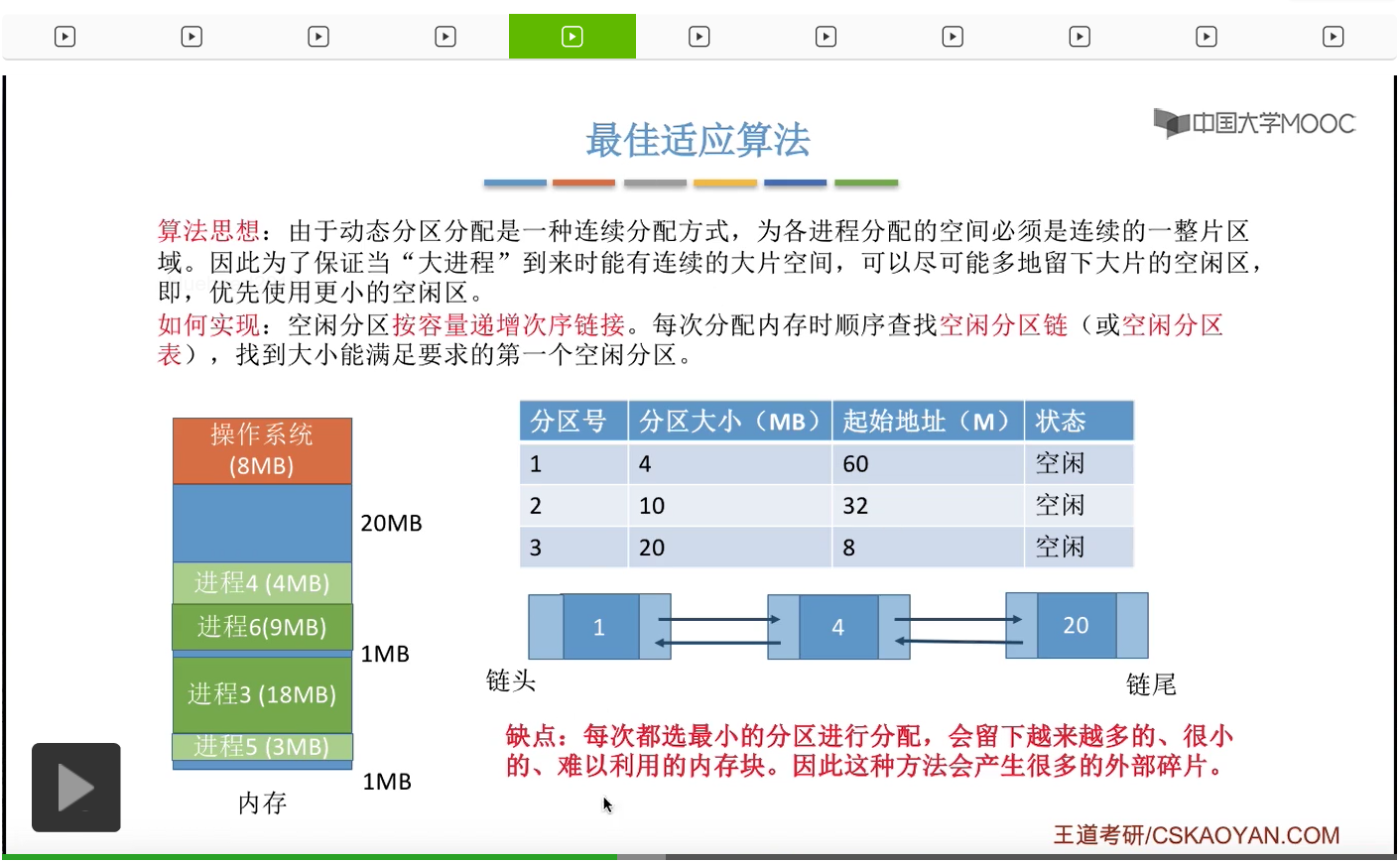
那最后会更新为这个样子,也就是把更小的这个空闲分区挪到这个链的链头的位置。那之后如果还有另外一个进程需要到达它需要3M字节的空闲分区的话,那同样的我们也需要从链头开始依次查找,于是发现这个分区是可以满足的。

那么第二个进程3M字节我们就可以从4M当中摘出3M给它分配,那这个地方也会变成只有1M字节的空闲分区。那我们之后就需要把这个结点对应的那些空闲分区大小、空闲分区的起始地址这些信息进行更新。那这个地方进行更新之后,整个空闲分区链依然是按照容量递增的次序进行链接的,所以我们不需要像刚才那样进行重新排列。那这个地方就不再展开细聊了。那从刚才的这个例子当中我们会发现最佳适应算法有一个很明显的缺点,由于我们每一次选择的都是最小的能够满足要求的空闲分区进行分配,所以我们会留下越来越多很小的、很难以利用的内存块。比如说这个地方有1M字节这个地方又有1M字节,那假如我们所有的进程都是两M字节以上,那这两个地方的碎片就是我们难以利用的,所以采用这种算法的话是会产生很多很多的外部碎片的。那这是最佳适应算法的一个缺点。
那于是为了解决这个问题,人们又提出了最坏适应算法。它的算法思想和最佳适应刚好相反,由于最佳适应算法留下了太多难以利用的小碎片,所以我们可以考虑在每次分配的时候优先使用最大的那些连续空闲区,这样的话我们进行分配之后,剩余的那些空闲区就不会太小,所以如果采用最坏适应算法的话,我们可以把空闲分区按照容量递减的次序进行排列。而每一次分配内存的时候就顺序地查找空闲分区链,找出大小能够满足要求的第一个空闲分区。那由于这个地方空闲分区是按容量递减的次序进行排列的,所以链头第一个位置的那个空闲分区肯定是能够满足要求的。如果第一个都满足不了要求,那剩下的后面的那些空闲分区,肯定都比第一个空闲分区更小,那别的那些空闲分区肯定也不会满足。那还是来看一个具体的例子。假设此时系统当中内存使用情况是这样。那我们采用空闲分区表和空闲分区链可以表示出此时的这些空闲分区的情况。那按照最坏适应算法的规则,我们需要按照容量递减的次序依次把这些空闲分区进行排列,也就是20、10、4。那此时假如有个进程它需要3M大小的内存空间,那由于链头的第一个空闲分区就可以满足,所以我们会从其中摘出3M进行分配,
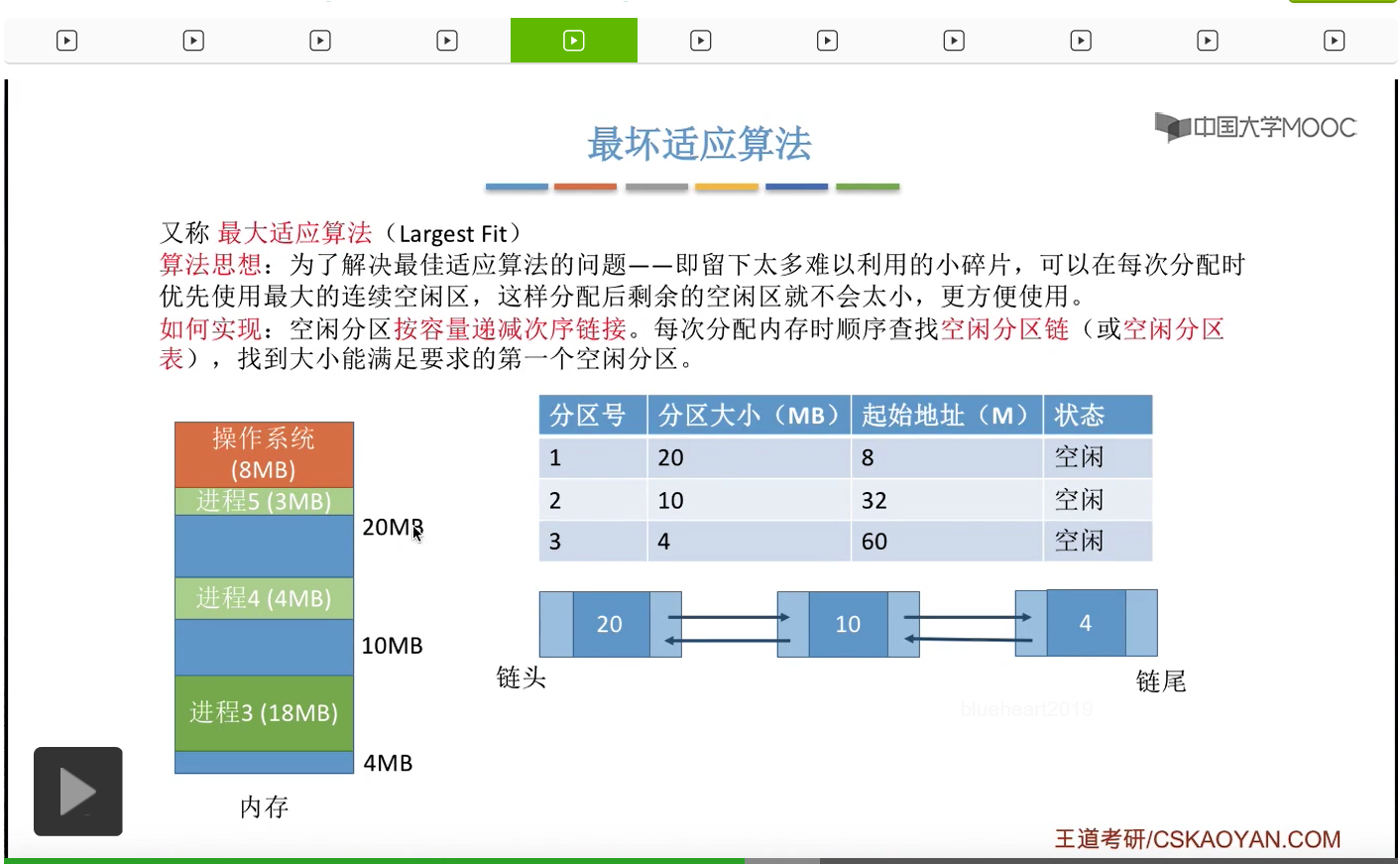
那这个地方就变成了还剩17M。那接下来还有一个进程也到达,它需要9M内存,
那同样的我们也是从这链头的这17M当中摘出其中的9M分配给进程6,于是进行数据的更新。那更新了之后我们会发现,
此时这个空闲分区链,已经不是按照容量递减的次序进行排列的,所以我们需要把这个空闲分区链进行重新排序,也就是变成这个样子,10、8、4,依然保持按容量递减的次序进行链接,那如果有下一个进程到达的话,那我们第一个需要检查的就是10这个空闲分区。那从这个例子当中可以看到,最坏适应算法确实解决了刚才最佳适应算法留下了太多难以利用的碎片的问题。但是最坏适应算法又造成了一个新的问题,由于我们每次都是选择最大的分区进行分配,所以这就会导致我们的那些大分区会不断不断地被分割为一个一个小分区。那如果之后有一个大进程到达的话就没有连续的大分区可用了。比如说此时来了一个20M的大进程,那这个大进程就无处安放。所以这是最坏适应算法的一个明显的缺点。
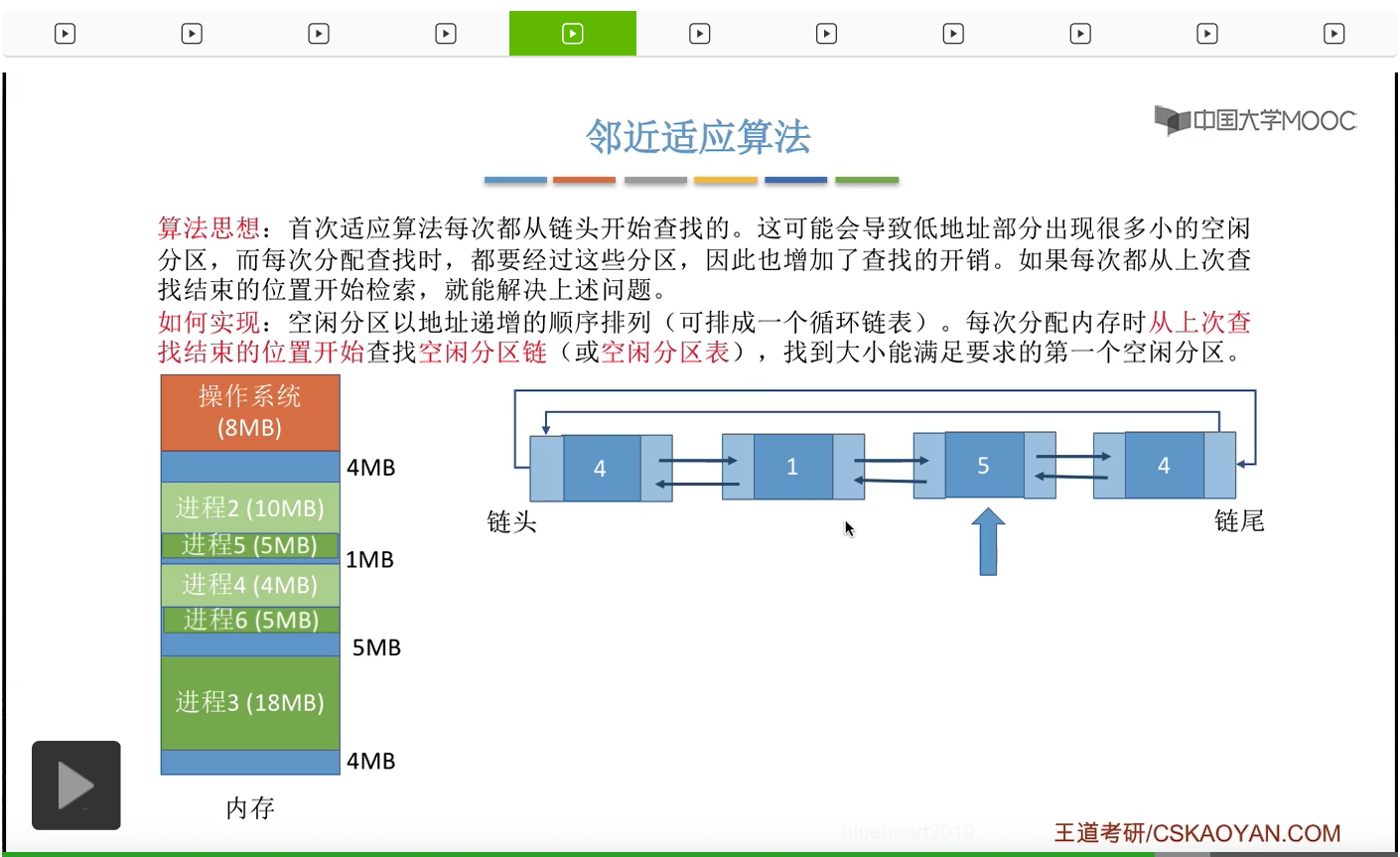
那接下来我们再来看第四种,邻近适应算法,这种算法的思想其实是为了解决首次适应算法当中存在的一个问题。首次适应算法每一次都会从链头开始查找,这有可能会导致低地址部分会出现很多很小的难以利用的空闲分区,也就是碎片。但是由于首次适应算法又必须按照地址从低到高的次序来排列这些空闲分区,所以我们在每次分配查找的时候都需要经过低地址部分那些很小的分区,这样的话就有可能会增加查找的一个开销。所以如果我们能够从每次都从上一次查找结束的位置开始往后检索的话,是不是就可以够解决之前所说的这个问题了呢?所以邻近适应算法和首次适应算法很像,它也是把空闲分区按照地址递增的顺序进行排列,当然我们可以把它排成一个循环链表,这样的话比较方便我们检索。那每一次分配内存的时候都是从上次结束的位置开始往后查找,找到大小能够满足的第一个空闲分区。那假如说此时系统当中的内存使用情况是这样,那我们可以把这些空闲分区按照地址递增的次序依次进行排列,排成一个循环链表。那刚开始如果说有一个进程到达,它需要5M字节的内存空间,刚开始我们会从链头的位置开始查找,
那第一个不满足,
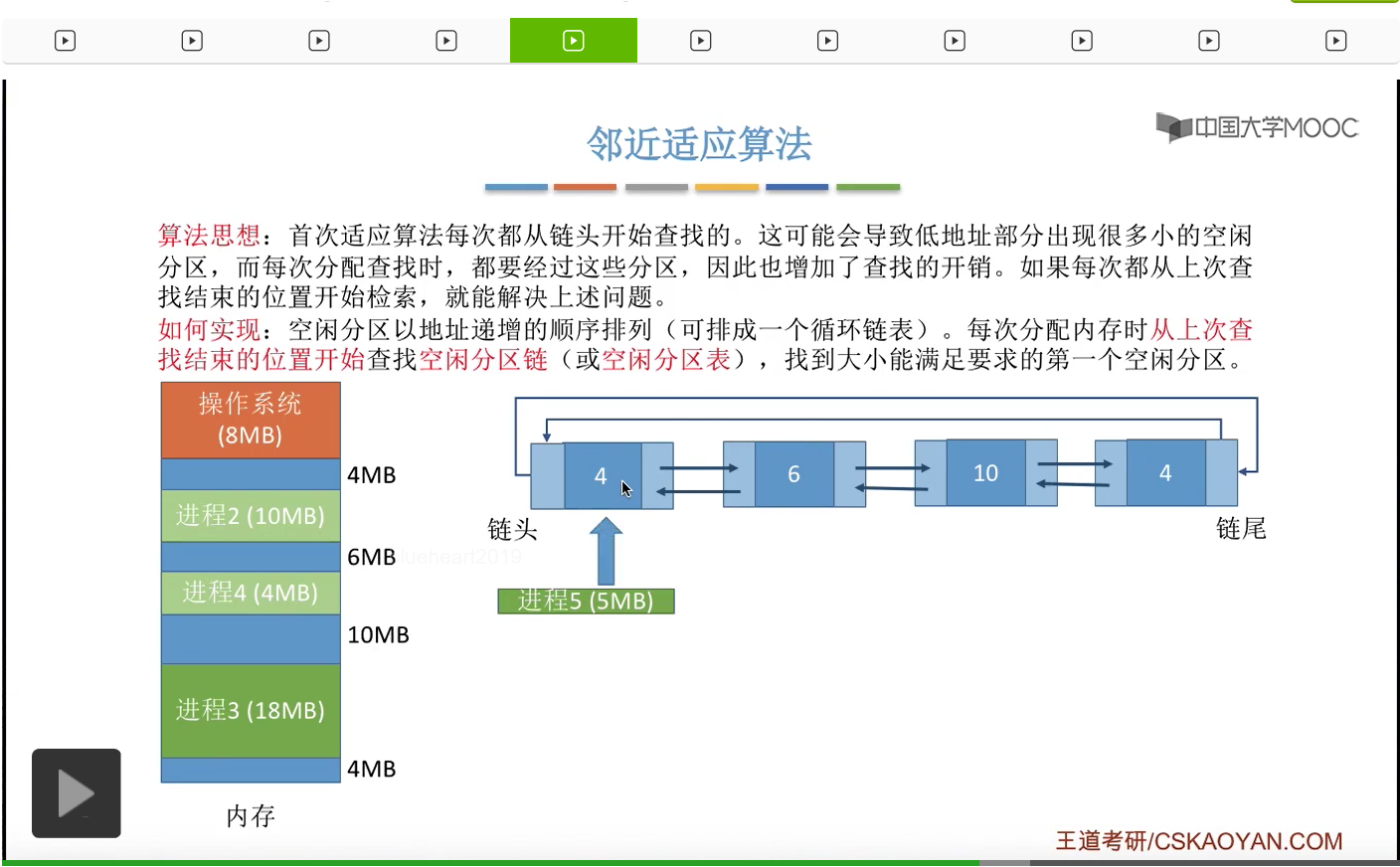
那第二个6M是满足的。

于是我们会从6M当中摘出5M分配给它,
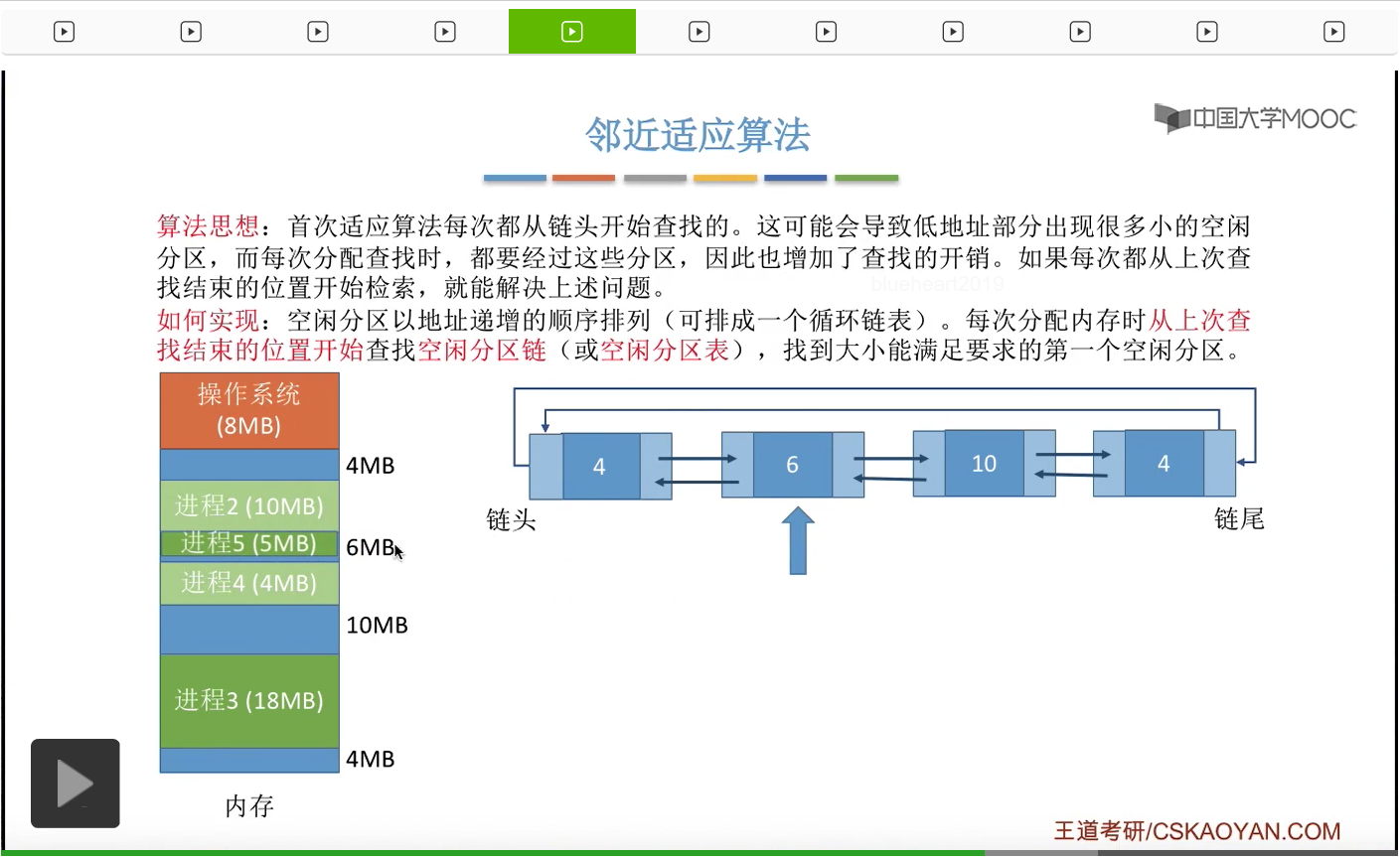
那这个地方就还剩余1M字节。于是我们需要更新这个分区链当中对应的结点,包括分区的大小还有分区的起始地址。但是有没有发现,采用邻近适应算法还有首次适应算法,我们只需要按照地址依次递增的次序来进行排列,所以即使这个地方内存分区的大小发生了一个比较大的变化,但是我们依然不需要对整个链表进行重新排列,所以这也是邻近适应算法还有首次适应算法比最佳适应算法和最坏适应算法更好的一个地方。算法的开销会比较小,不需要我们再花额外的时间对这个链表进行重新排列。

那假如此时有一个新的进程到达,它需要5M字节的空间。那按照邻近适应算法的规则,我们只需要从上一次查找到的这个位置依次再往后查找就可以了,

所以这个不满足,
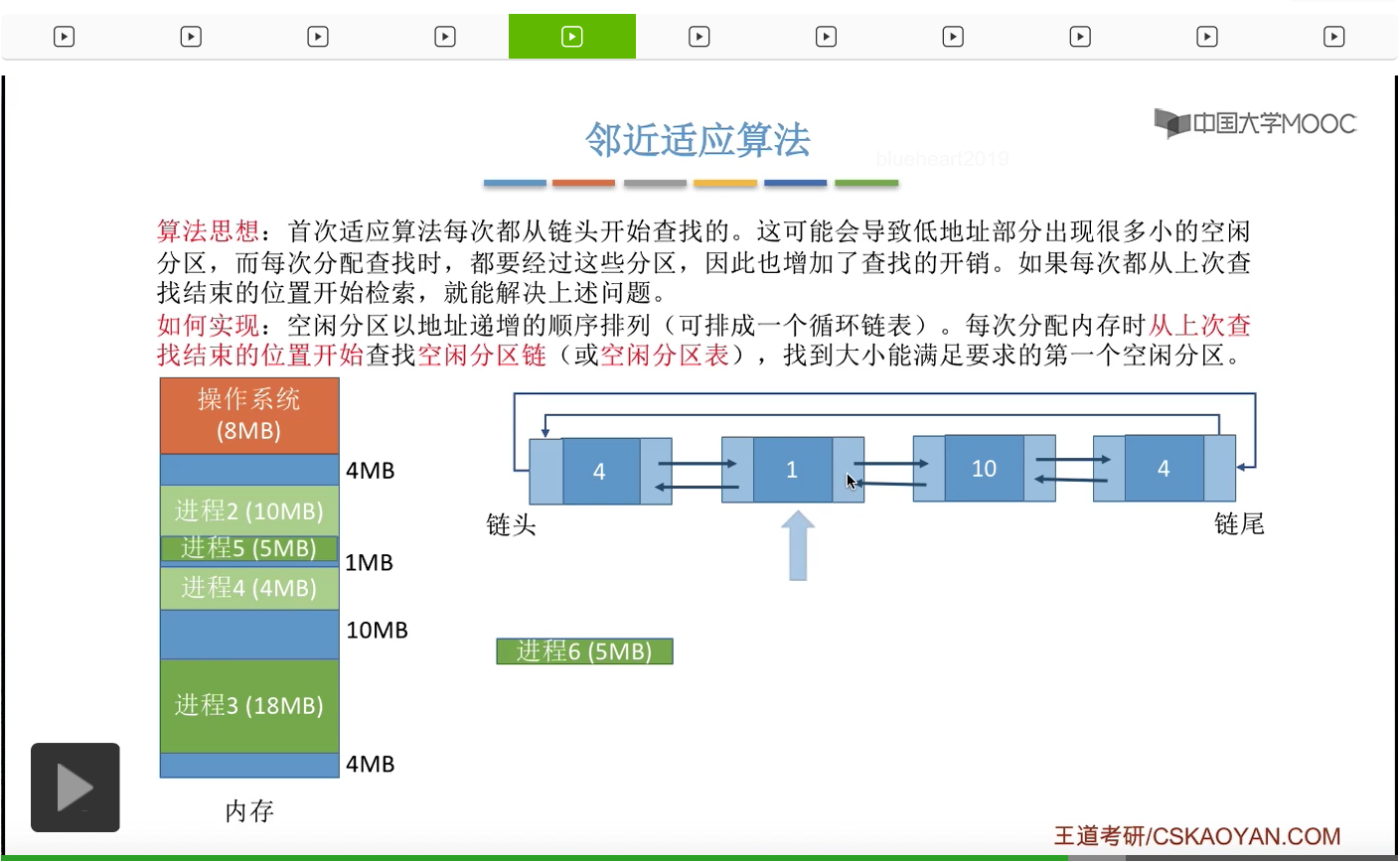
那我们看下一个,10M是满足的,

于是会从10M当中摘出5M进行分配,
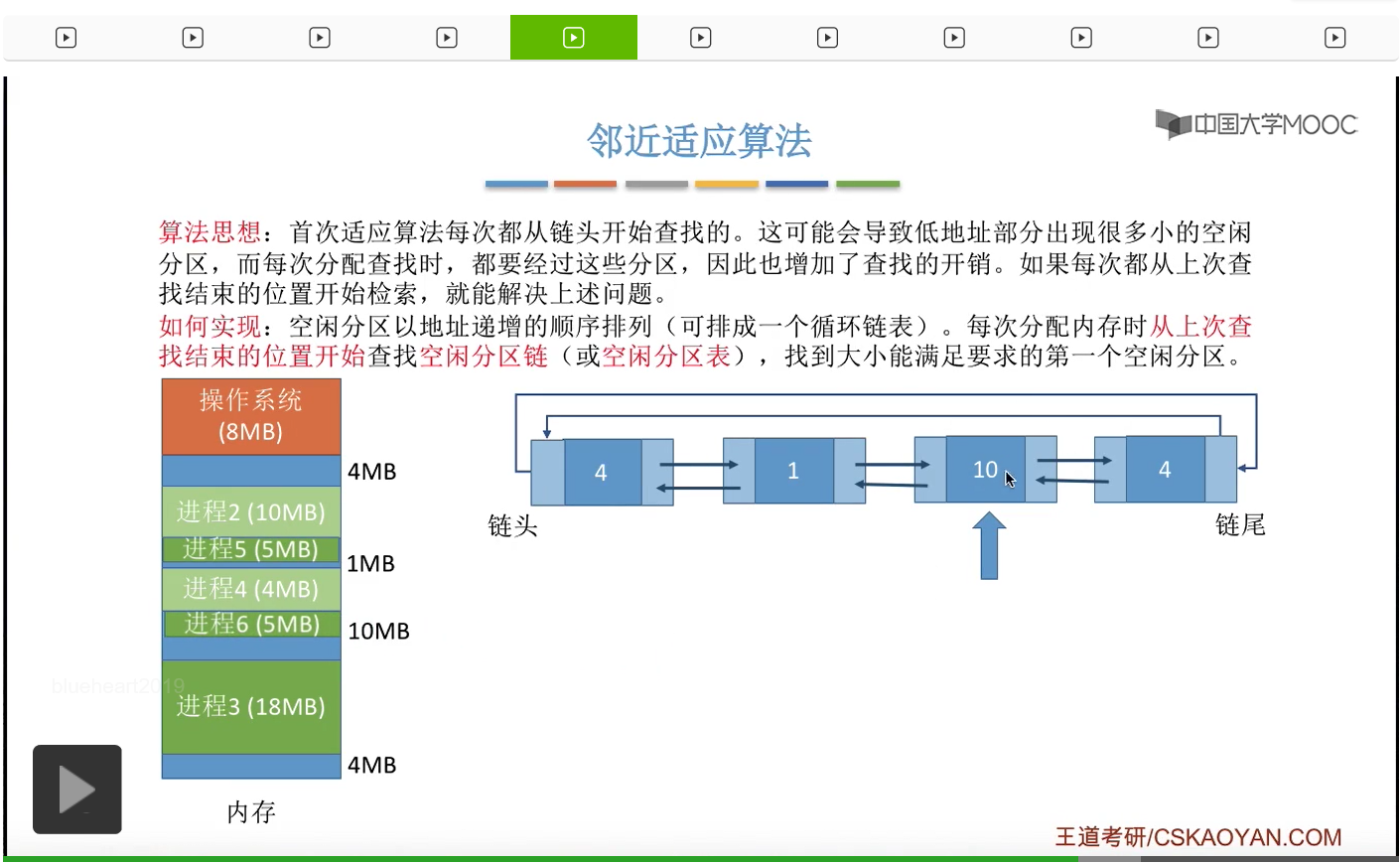
然后更新相应的这些数据结构。那这个地方大家有没有发现,如果此时我们采用的是首次适应算法的话,如果此时需要分配5M的内存空间,那么我们依然会从链首的位置开始往后查找,所以第一个4M不满足,第二个1M不满足,第三个10M才能满足,那就会有三次查找。那如果说我们采用的是邻近适应算法的话,我们只需要从这个位置开始往后查找,也就是查两次就可以了,所以这是邻近适应算法比首次适应算法更优秀的一个地方。首次适应算法会导致低地址部分留下一些比较小的碎片,但是我们每一次开始检索都需要从低地址部分的这些小碎片开始往后检索,所以这就会导致首次适应算法在查找的时候可能会多花一些时间,不过这并不意味着邻近适应算法就比首次适应算法更优秀很多。
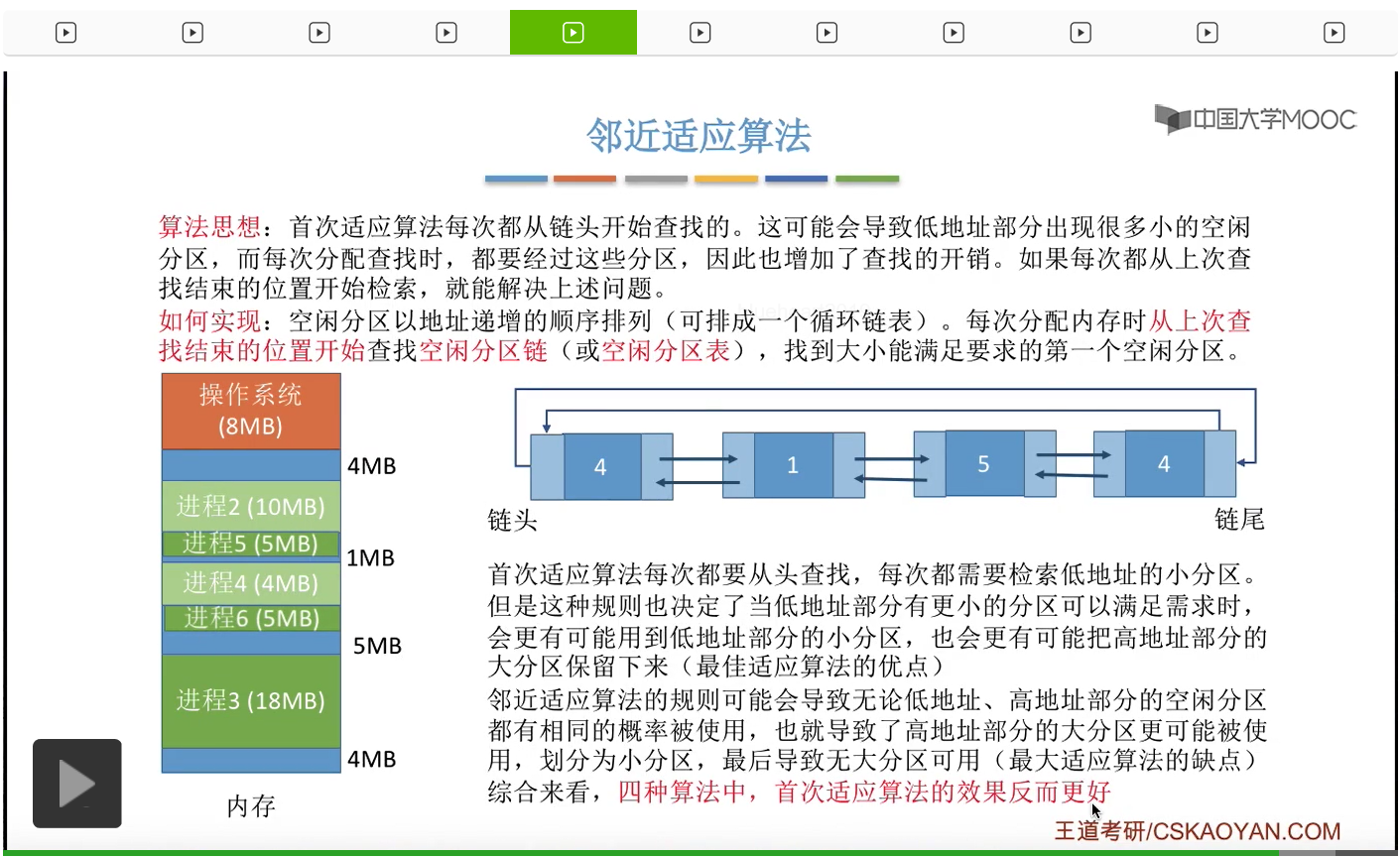
其实邻近适应算法又造成了一个新的问题。在首次适应算法当中,我们每次都需要从低地址部分的那些小分区开始依次往后检索,但是这种规则也决定了,如果说在低地址部分有更小的分区可以满足我们的需求的时候,我们就会优先地使用低地址部分的那些小分区,这样的话就意味着高地址部分的那些大分区就有更大的可能性被保留下来。所以其实首次适应算法当中也隐含了一点最佳适应算法的优点。那如果我们采用的是邻近适应算法的话,由于我们每一次都是从上一次检查的位置开始往后检查,所以我们无论是低地址部分还是高地址部分的空闲分区,其实都是有相同的概率被使用到的,所以这就导致了和首次适应算法相比,高地址部分的那些大分区,更有可能被使用被划分成小分区,这样的话高地址部分的那些大分区也很有可能被我们用完,那之后如果有大进程到达的话就没有那种连续的空闲分区可以进行分配了。所以其实邻近适应算法的这种策略也隐含了一点最大适应算法的缺点。所以综合来看,其实刚才介绍的这四种适应算法当中,反而首次适应算法的效果是最好的。
好的那么这个小节我们介绍了四种动态分区分配算法,分别是首次适应、最佳适应、最坏适应和邻近适应。那这个小节的内容很容易作为选择题进行考查,甚至有可能作为大题进行考查。其实我们只需要理解各个算法的算法核心思想就可以分析出这些算法的这些空闲分区应该怎么排列,它们的优点是什么,缺点是什么。那这几个算法当中,比较不容易理解的其实是邻近适应算法的优点和缺点,但是刚才咱们也进行了详细的分析这儿就不再重复了。那这个地方大家会发现,各个算法提到的算法开销的大小问题,那这个地方的算法开销指的是为了保证我们的空闲分区是按照我们规定的这种次序排列的,在最佳适应和最坏适应这两种算法当中,我们可能需要经常对整个空闲分区链进行重新排序,所以这就导致了算法开销更大的问题。而首次适应和邻近适应我们并不需要对整个空闲分区链进行顺序地检查和排序,所以这两种算法的开销是要更小的。那么这些算法大家还需要通过课后习题的动手实践来进行进一步的巩固。
在这个小节中我们会学习一个很重要的高频考点,同时也是这门课的难点,叫做分页存储管理。

那在之前的小节中我们学习了几种连续分配存储管理方式,所谓的连续分配就是指,操作系统给用户进程分配的是一片连续的内存区域,而非连续分配就是指,它给用户进程分配的可以是一些离散的、不连续的内存区域。那这个小节我们会首先学习第一种,非连续的分配管理方式,叫做基本分页存储管理。

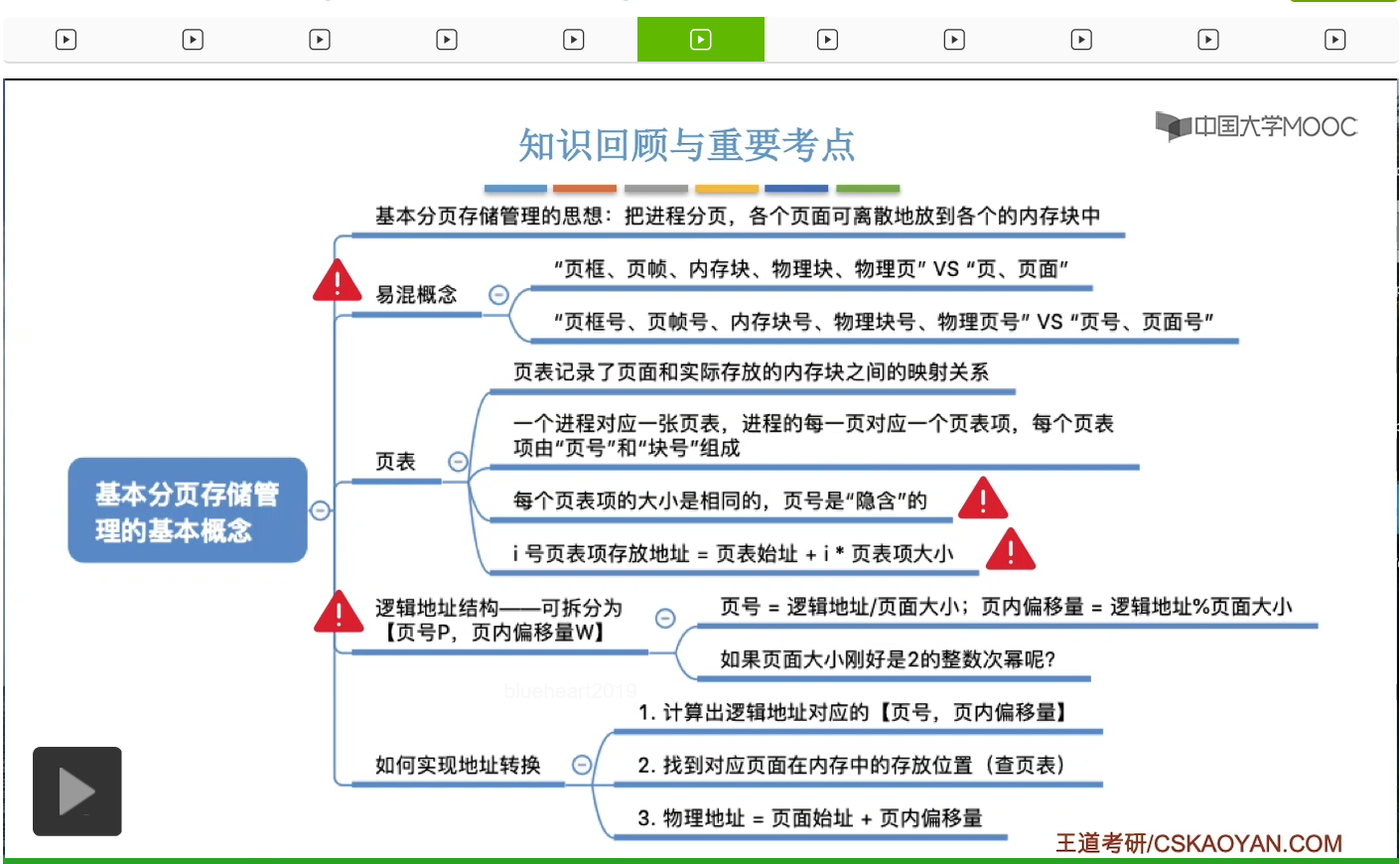
那首先来认识一下什么叫分页存储。那如果一个系统支持分页存储的话,那么系统会把内存分为一个一个大小相等的区域,比如说一个区域的大小是4KB,那这样的一个区域称为一个页框或者叫一个页帧,当然它还有别的一些名词,不同的教材或者不同的题目上大家可能会看到各种各样的名词出现,不过需要知道它们指的都是页框。那系统会给每个页框一个编号,并且这个编号是从零开始的,这个编号就叫做页框号,或者叫页帧号、内存块号、物理块号、物理页号。那接下来我们思考一下,内存里边它存放的其实无非就是各个进程的数据对吧,包括进程的代码啊、进程的指令啊等等这些数据,所以为了把各个进程的这些数据把它放到各个页框当中,因此操作系统也会把各个进程的这些逻辑地址空间把它分为与这个页框大小相等的一个一个的部分。比如说我们这个地方举的例子进程A,它的逻辑地址空间是0-16K-1,也就是16K,所以这个进程的大小应该是16KB这么多。把它分为与页框大小相等的一个一个部分,因此每个部分就是4KB这么多。并且系统也会给进程的各个页进行一个编号,这个编号就称作为页号或者叫页面号。
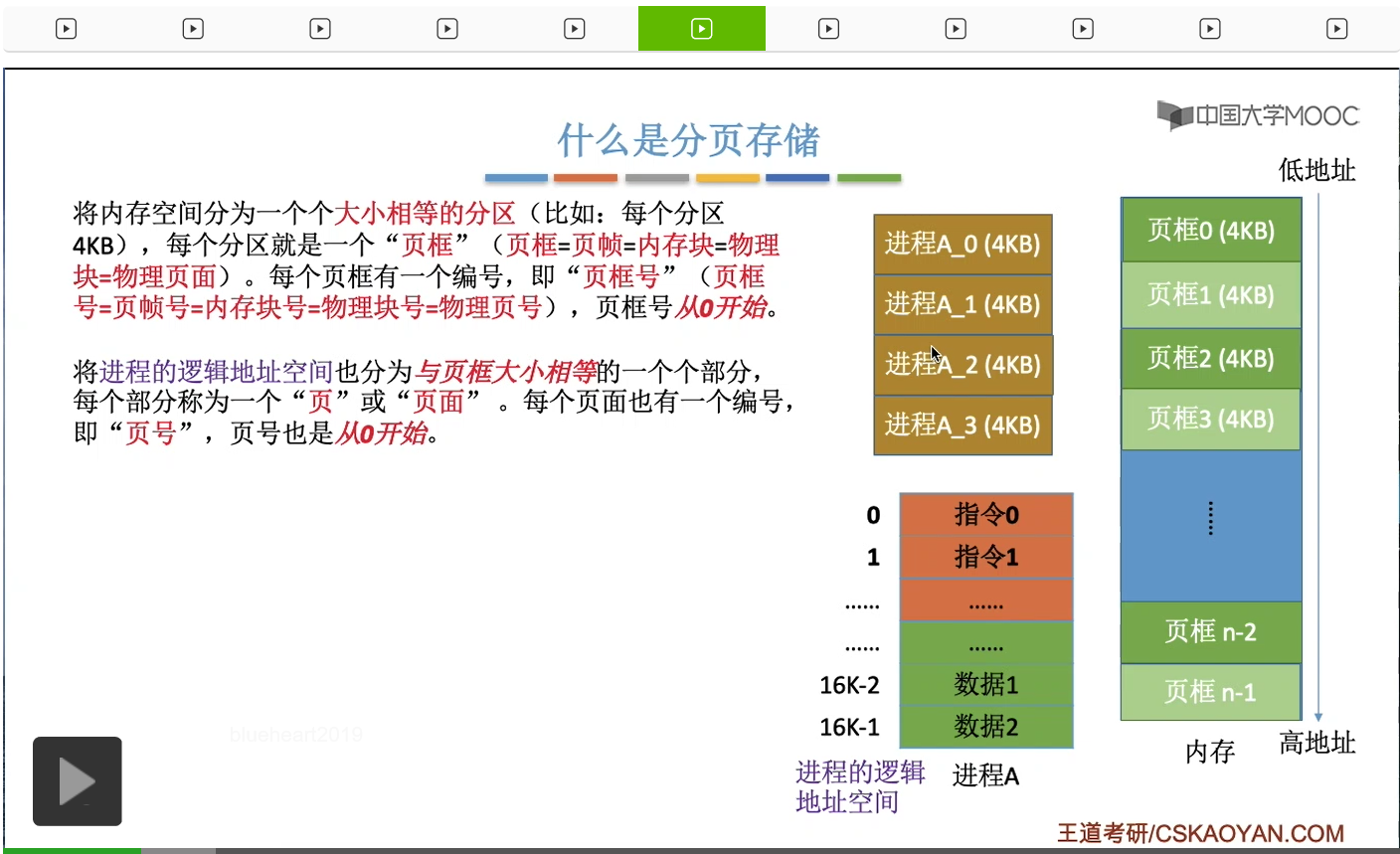
那进程的各个页会被放到内存的各个页框当中,所以进程的页面和内存的页框是有一一对应、一一映射的关系的。那这个地方建议大家暂停,好好地来区分一下这几个很容易混淆的概念,特别是页、页面、页框和页帧。这四个术语在刚开始学习的时候,很容易认为它们指的是同一个东西。但其实不是,页框和页帧它指的是内存在物理上被划分为的这样一个一个的部分,这个叫页框。而页和页面指的是进程在逻辑上被划分为的一个一个的部分。那除了页框页帧之外,有的教材当中也会把页框称为内存块、物理块或者叫物理页面,并且在我们的课后习题当中,这些名词都有可能出现,所以这个地方建议大家特别注意一下这些很容易混淆的概念。那到这儿我们就初步了解了什么叫分页存储。接下来要思考的问题是这样的,刚才我们不是说进程的页面和内存的这个页框它有一一对应的关系吗?那操作系统是怎么记录这种一一对应关系的呢?

这就涉及到一个很重要的数据结构,叫做页表。操作系统会给每一个进程都建立一张页表。并且这个页表一般是存放在内存的控制块当中的,也就是PCB当中。那刚才我们说过,进程的逻辑地址空间会被分为一个一个的页面,那每一个页面就会对应页表当中的一个页表项。所谓的页表项,大家可以理解为就是这个页表当中的一行。那页表项当中包含了页号和块号这样的两个数据,所以这样的一个页表就可以记录下来这个进程的各个页面和实际存放的内存块之间的映射关系。注意内存块其实就是页框,只不过内存块这个术语可能更不容易让人混淆一些,所以我们在接下来的讲解当中更多地会使用的是内存块这样的表述方式。不过大家自己答题的时候,建议使用页框这个术语。因为去看英文书的话,其实这个术语它的英文叫做page frame,所以大部分的教材其实习惯翻译成页框。因此,建议大家答题的时候使用的是页框这个术语。好的,那么再回到页表这个数据结构,从刚才的分析当中我们知道,页表它由这样一个一个的页表项组成。那接下来我们要思考的问题是这样的,首先,这些页表项是存在内存里的,那每一个页表项需要占几个字节的空间呢?第二个问题是操作系统要怎么利用页表来实现逻辑地址到物理地址的转换。
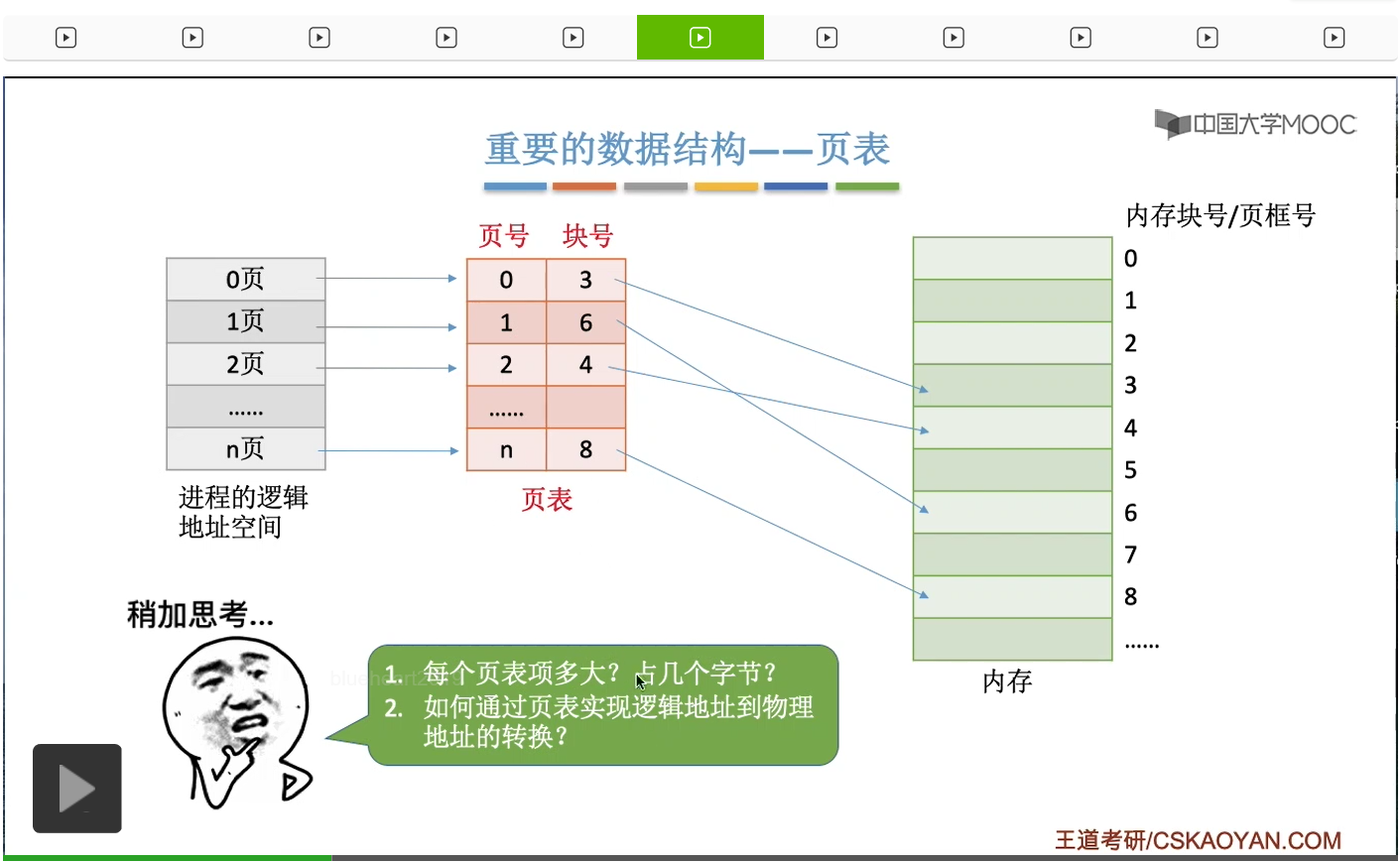
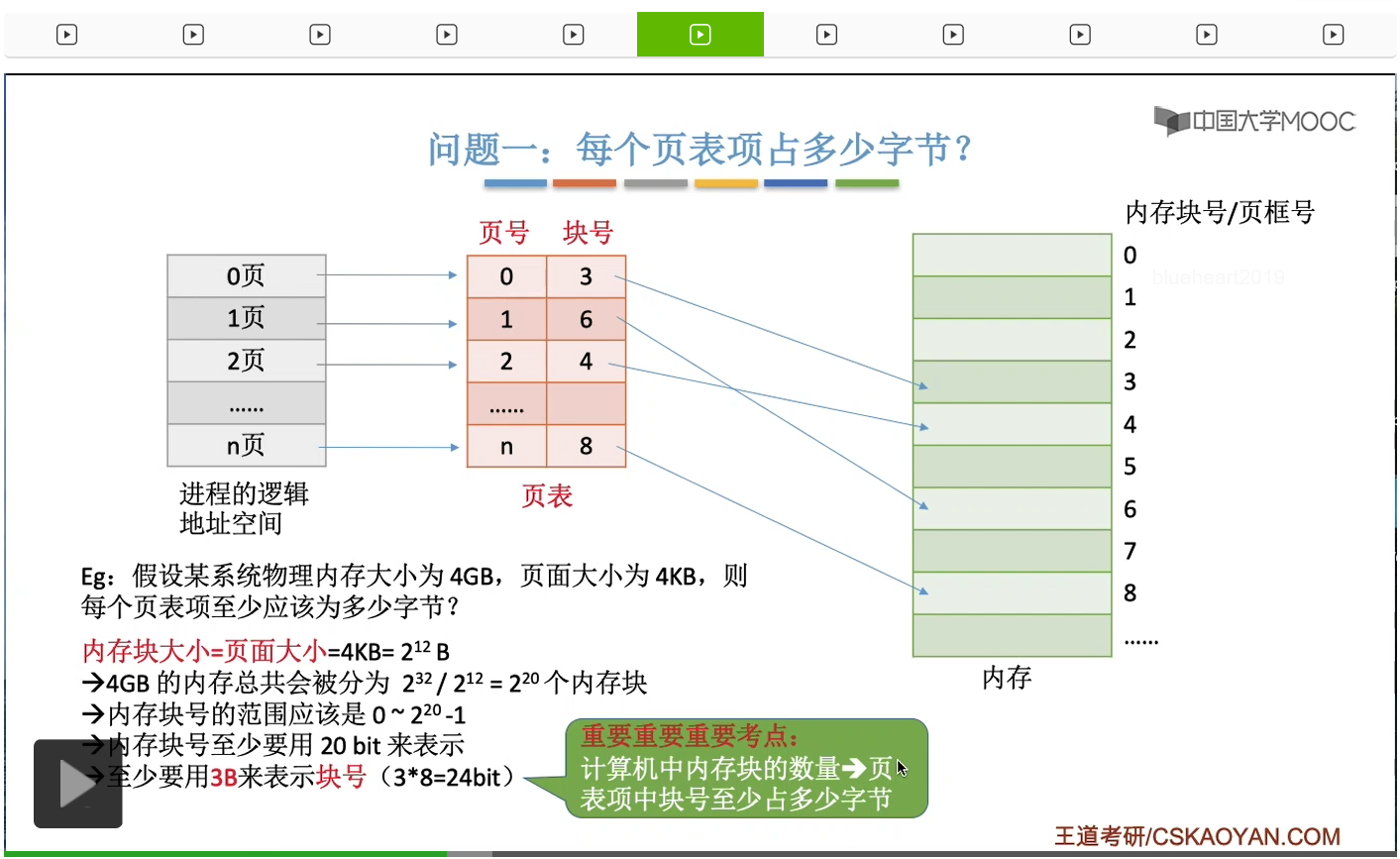
那首先我们来分析第一个问题,直接结合一个例子来理解。不过呢计算机分配存储空间它是以字节为单位分配,而不是以比特为单位分配。
1GB=2^10MB=2^20KB=2^30B 4GB=2^32B 1KB=2^10B 4KB=2^12B 20bit<3B
那接下来我们再来看一下这个页号又需要占多少个字节呢?直接告诉大家答案。页号是不需要占存储空间的。因为各个页表项在内存中连续存放,所以页号可以是隐含的。什么意思呢?那刚才我们得出的结果是一个块号它至少需要占用三个字节,并且这些页表项在内存当中都是连续存放的。那如果在内存中只存储块号而没有存储页号的话,那我们又怎么找到页号为i的这个页面对应的页表项呢?其实很简单,只要我们知道了这个页表它在内存当中存放的起始地址X,我们就可以用X+3*I就得出这个i号页表项它的存放地址了。那学过数据结构的线性表,相信这个地方并不难理解。其实就相当于是一个数组,对于普通的数组而言,数组的下标我们也不需要花存储空间来存放对吧。因此我们得出结论,页表当中的这个页号可以是隐含的,它并不占用存储空间。那结合之前的结论我们知道,一个页表项它在逻辑上其实是包含了页号和块号这样的两个信息,但是在物理上它其实只需要存放块号的这个信息,只有块号需要占用存储空间。那如果这个进程它的页号是0-n号,也就是说它总共有n+1个页面的话,那么存储这个进程的页表就至少需要3*(n+1)这么多个字节。那我们通过页表可以知道各个页面它存放在哪个内存块当中。
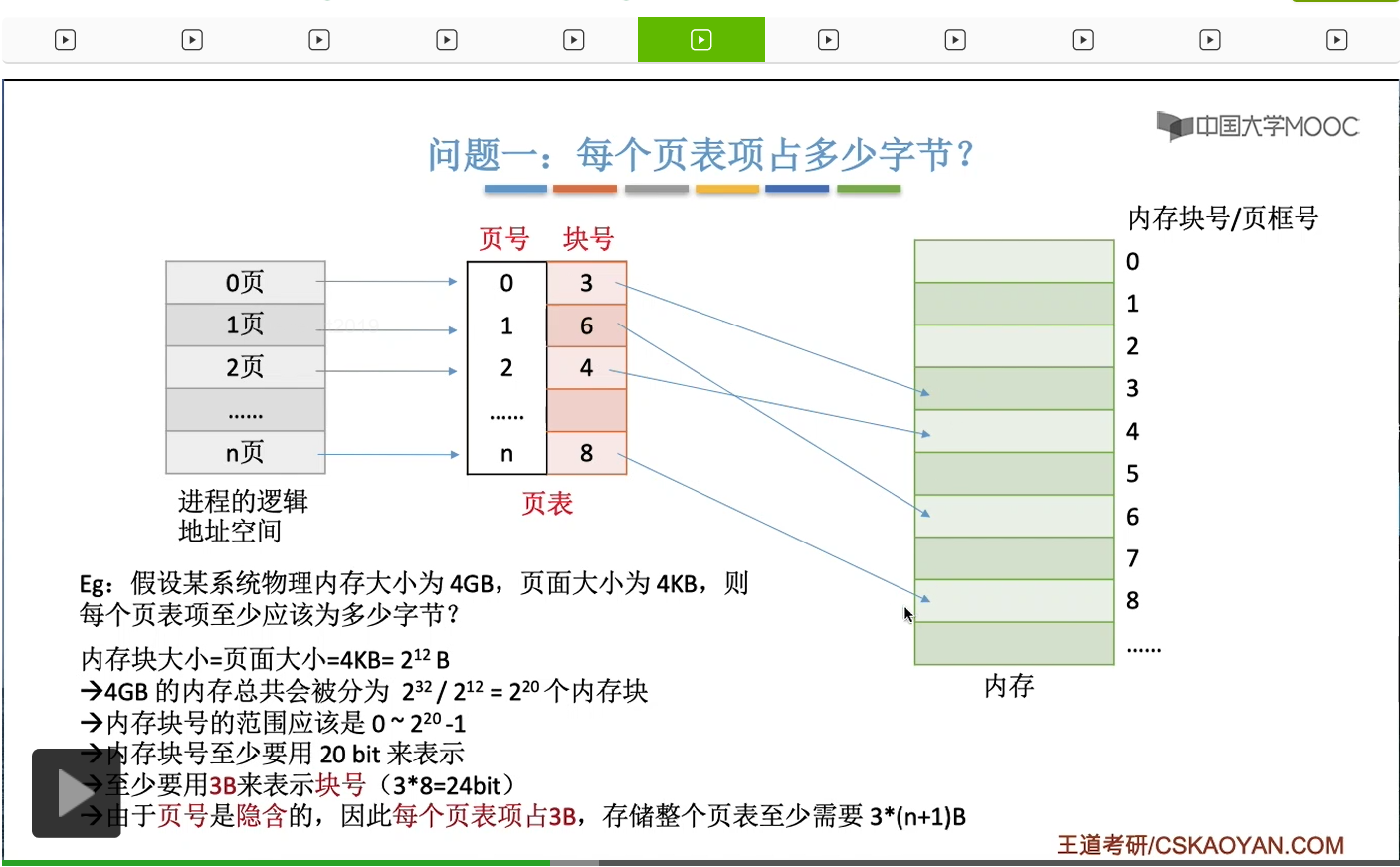
但是需要注意、需要强调的是,这个地方它记录的只是内存的块号,而不是具体的内存块的起始地址。如果我们要计算一个内存块的起始地址的话,我们需要用这个块号再乘以内存块的大小。这个地方大家需要特别地注意体会一下,不然做题的时候很容易出错。好的那么到这儿我们就弄清楚了第一个问题。

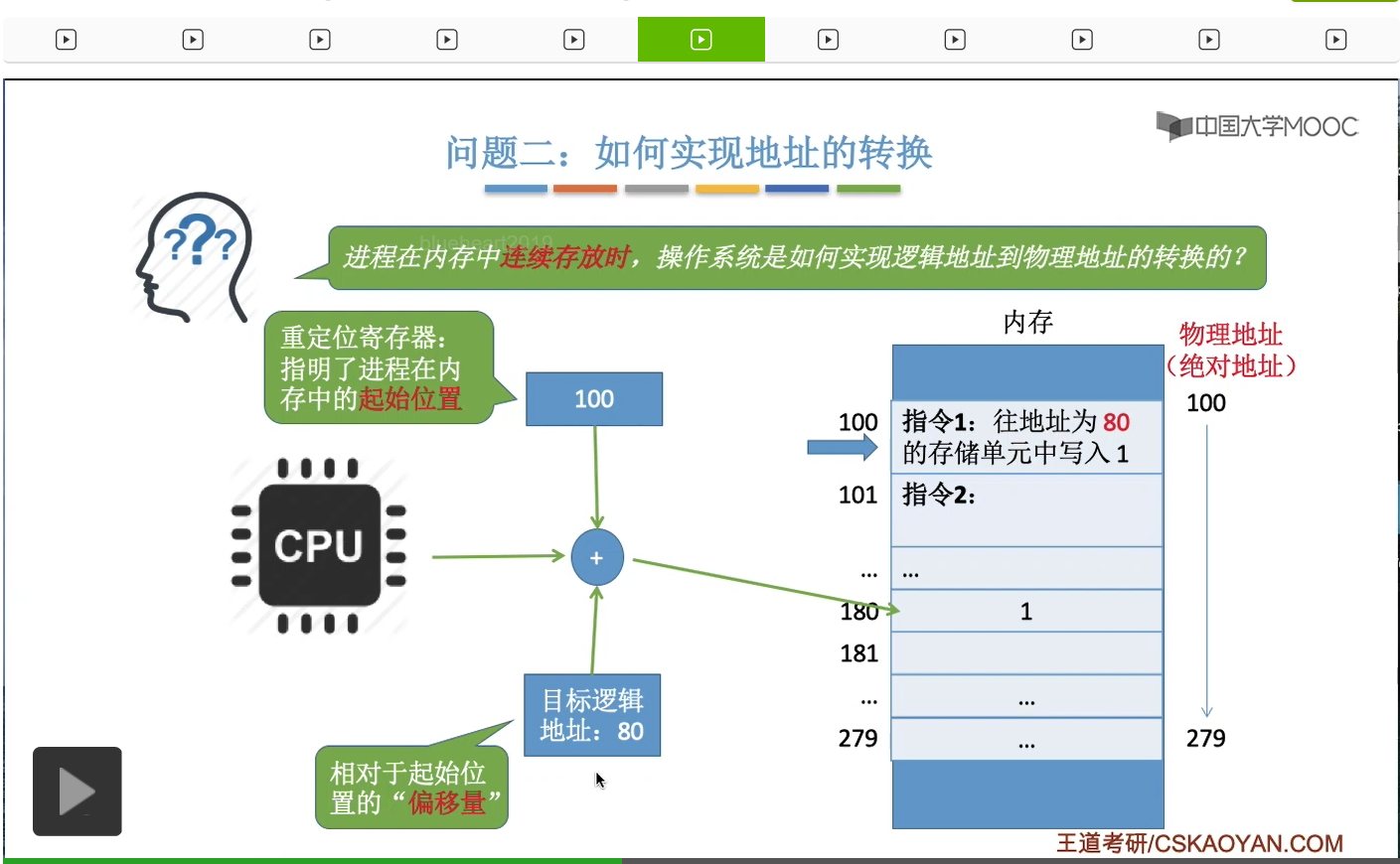
接下来要探索的是第二个问题,如何实现地址的转换,也就是逻辑地址转换到物理地址。那我们先来回忆一下,我们之前在讲连续存放那种方式的时候,操作系统是怎么实现这种地址的转换的呢?如果一个进程它在内存当中连续存放,那么我们只需要知道这个进程它的起始地址,然后把接下来要访问的那个逻辑地址和起始地址相加就可以得到它最终的物理地址了,那这是连续存放的时候。那这个逻辑地址我们可以把它理解为是一种偏移量,也就是说相对于它的起始地址而言往后偏移了多少。
那如果采用分页存储的话,那这个地址转换要怎么进行呢?

这个进程会被放到内存的各个位置当中,不过有这样的一个特点,虽然进程的各个页面在内存中是离散的存放的,但是各个页面的内部它都是连续的。注意体会这个特点。那基于这个特点,我们来看一下,如果要访问逻辑地址A,应该怎么来进行呢?首先我们可以确定这个逻辑地址A,它应该对应的是进程的哪个页面。也就是说要确定这个逻辑地址A它所对应的页号。接下来操作系统就可以用这个页号去查询页表,然后找到这个页面它存放在内存当中的什么位置。那第三步我们要确定的是,逻辑地址A它相对于这个页面的起始位置而言的“偏移量”是多少。因为各个页面内部都是连续存放的嘛,所以我们只需要把这个逻辑地址A它所对应的页面在内存当中的起始地址,再加上这个逻辑地址的页内偏移量W,就可以得到这个逻辑地址A所对应的物理地址了。那这个就是实现地址变换的一个基本的思路。那在之前的讲解当中我们了解了怎么利用页表来找到一个页面在内存当中的起始地址。

那接下来我们要探讨的就是怎么确定逻辑地址所对应的页号和页内偏移量。
还是结合一个例子来理解。

那在这个例子当中,一个页面的大小是50个字节。那熟悉二进制乘法或者无符号左移、无符号右移这些操作的同学,可能很容易理解这个原理。但对于跨考的同学来说也许会觉得它比较神奇但不知道为什么会这样。那如果想要了解呈现这种规律背后的原理的话,建议可以去看一下无符号左移、无符号右移和二进制的乘法、二进制的除法之间的一个联系。好的扯远了,回到我们的这个主题上来。

那除此之外它还有另外一个优点。我们刚才讲页表的时候强调过一个问题,页表当中记录的是内存块号而不是内存块的起始地址,所以如果我们要计算一个内存块的起始地址的话,需要进行一个这样的乘法运算。但是如果内存块的大小刚好是2的整数幂,计算起来就没有那么麻烦。我们假设1号页面它存放的内存块号是9,如果用二进制表示的话9这个数就应该是1001。那这么完美的特性其实就是因为页面大小、内存块的大小刚好是2的整数次幂,所以在地址转换的过程当中,我们只要查到页表当中存放的这个内存块号,再把这个内存块号和逻辑地址的页内偏移量进行一个拼接其实就可以得到最终的物理地址了。如果不是2的整数次幂的话,页面在内存中的起始地址必须用这样的乘法的方式来进行,这也会导致硬件的效率降低。

那经过刚才的这两个例子我们可以看到,页面大小是2的整数次幂有这样的两个好处。这个地方大家再结合文字好好体会一下就可以了,就不再重复。

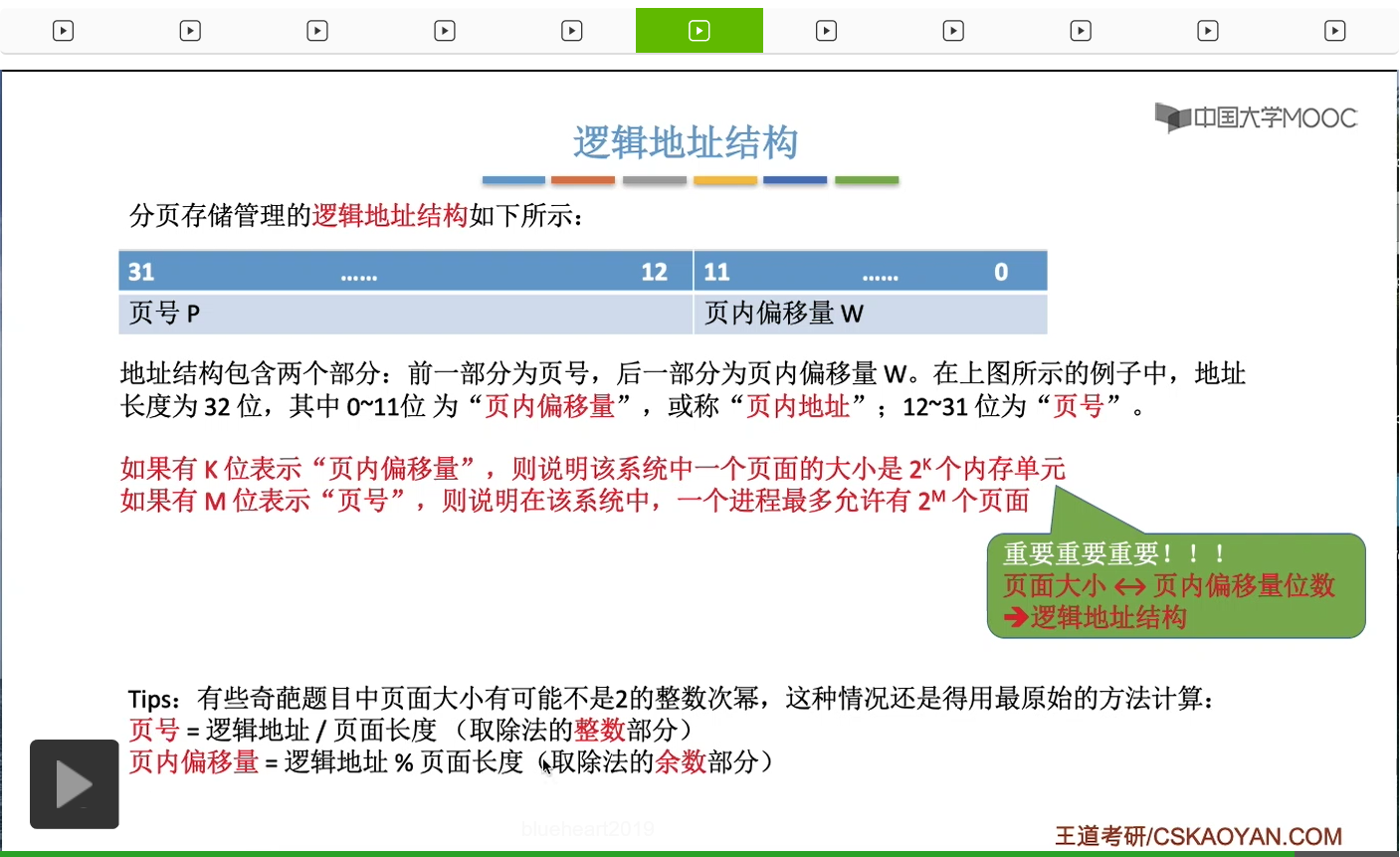
那如果页面大小是2的整数次幂的话,我们可以把逻辑地址把它分为这样的两个部分,分别是页号和页内偏移量。总之呢,只要知道页内偏移量的位数就可以推出页面大小,同样的知道页面大小也可以反推出页内偏移量应该占多少位,从而就可以确定逻辑地址的结构,这一点也是考题当中非常非常高频的一个考点,大家在做题的时候会经常遇到。当然,有的题目当中它的页面大小有可能不是2的整数次幂,那对于这种题目来说我们要计算页号和页内偏移量,还是只能用最原始的那种算法,用除法来得到页号,用取余得到页内偏移量。
系统会把进程分页,会把各个页面离散地放到各个内存块当中,或者说放到各个页框当中。那由于各个页面会依次放到各个内存块当中,所以需要记录这种页面和内存块之间的映射关系,因此需要有一个很重要的数据结构叫做页表。页表由一个一个的页表项组成,并且页表项在内存中是连续存放的,各个页表项大小相等。注意,页号是隐含的,不需要占用存储空间。那我们只需要知道页表在内存当中存放的起始地址并且知道页号和页表项的大小就可以算出i号页表项存放在什么位置了。那最后我们还介绍了分页存储的逻辑地址结构,可以分为页号和页内偏移量这样两个部分。如果页面的大小刚好是2的整数次幂,那么硬件在拆分逻辑地址,在进行物理地址的计算的时候,都会更快。所以一般来说,页面大小都是2的整数次幂。当然,这个小节中我们还介绍了在分页存储这种管理方式当中,怎么实现逻辑地址到物理地址的转换,具体的转换过程大家现在只需要有个大体的印象就可以。下个小节当中我们还会结合一些硬件的细节,再进一步地阐述地址转换的过程。

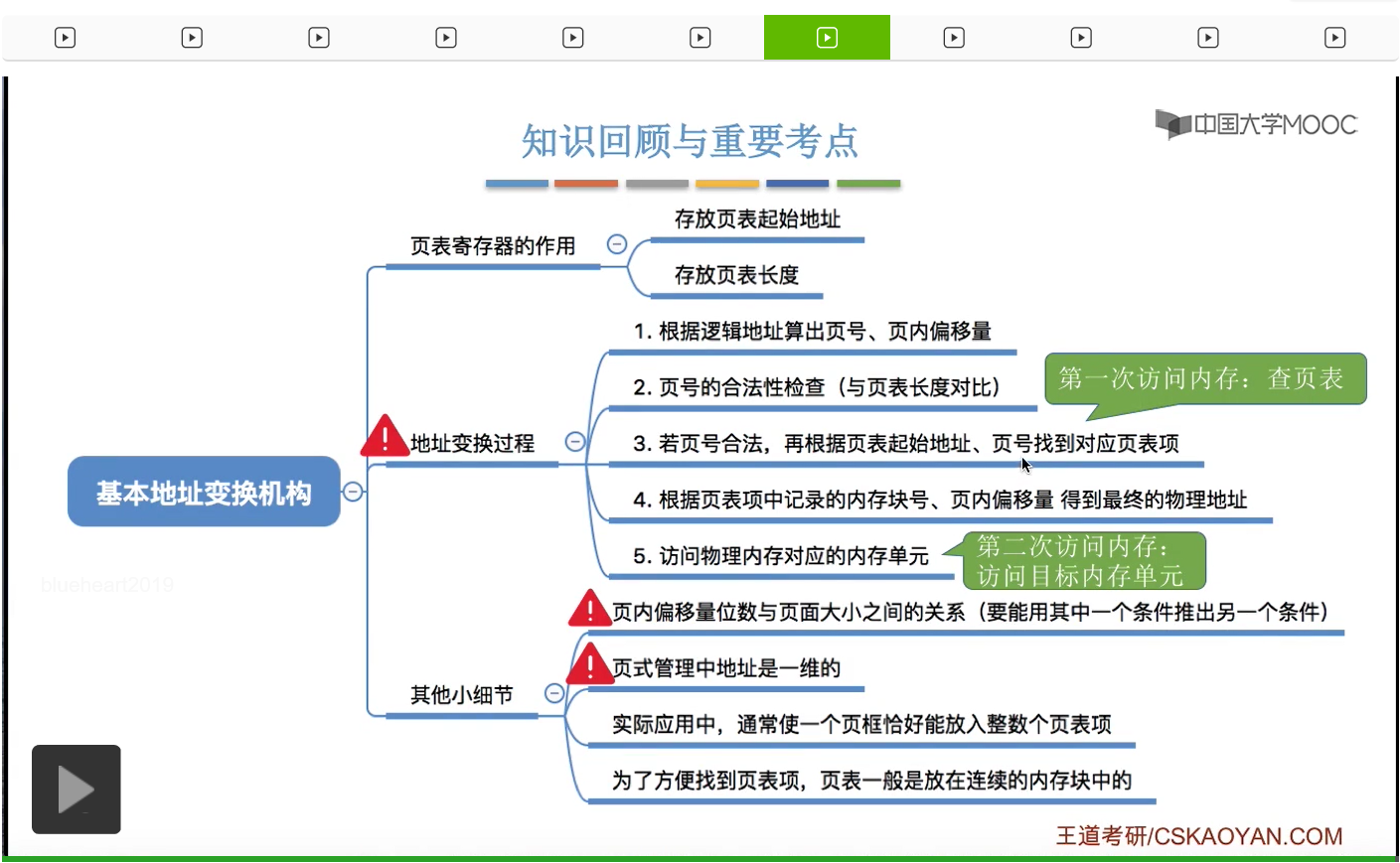
那这个小节的内容也属于基本分页存储管理。其实所谓的基本地址变换机构,就是在基本分页存储管理当中用于实现逻辑地址到物理地址转换的一组硬件机构。那我们在学习这个小节的过程当中,需要重点掌握这些变换机构的工作原理还有流程,这个小节的内容十分重要,既有可能作为选择题也有可能结合大题进行考查。
那通过上个小节的讲解我们知道,在分页存储管理当中,如果要把逻辑地址转换成物理地址的话,总共需要做四件事,第一,要知道逻辑地址对应的页号。第二,还需要知道逻辑地址对应的页内偏移量,第三我们需要知道逻辑地址对应的页面在内存当中存放的位置到底是多少。第四,我们再根据这个页面在内存当中的起始位置和页内偏移量就可以得到最终的物理地址了。那为了实现这个地址转换的功能,系统当中会设置一个页表寄存器,用来存放页表在内存当中的起始地址还有页表的长度这两个信息。在进程没有上处理机运行的时候,页表的起始地址还有页表长度这两个信息是放在进程控制块里的。只有当进程被调度,需要上处理机的时候,操作系统内核才会把这两个数据放到页表寄存器当中。那我们接下来用一个动画的形式看一下从逻辑地址到物理地址的转换应该是什么样一个过程。

我们知道操作系统会把内存分为系统区和用户区,那在系统区当中会存放着一些操作系统对整个计算机软硬件进行管理的一些相关的数据结构,包括进程控制块PCB也是存放在系统区当中的。那如果说一个进程被调度,它需要上处理机运行的话,进程切换相关的那些内核程序就会把这个进程的运行环境给恢复,那这些进程运行环境相关的信息本来是保存在PCB当中的。那之后这个内核程序会把这些信息把它放到相应的一系列寄存器当中,包括页表寄存器。页表寄存器当中存放着这个进程的页表的起始地址还有页表的长度,另外呢像程序计数器PC也是需要恢复的。程序计数器是指向这个进程下一条需要执行的指令的逻辑地址,逻辑地址A。那么接下来我们来看一下怎么把这个逻辑地址转换成实际的物理地址,也就是说CPU怎么在内存当中找到接下来要执行的这条指令。
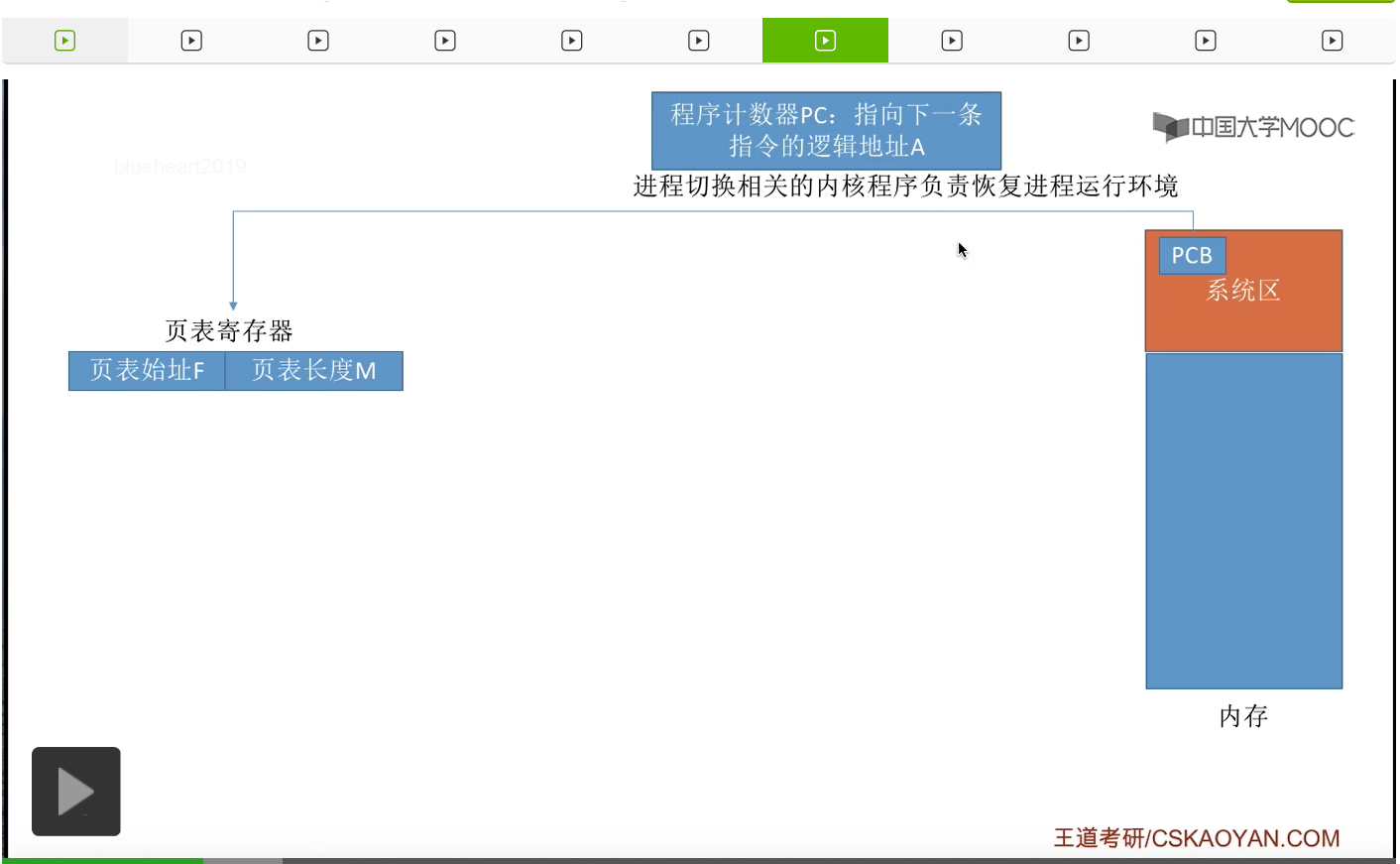
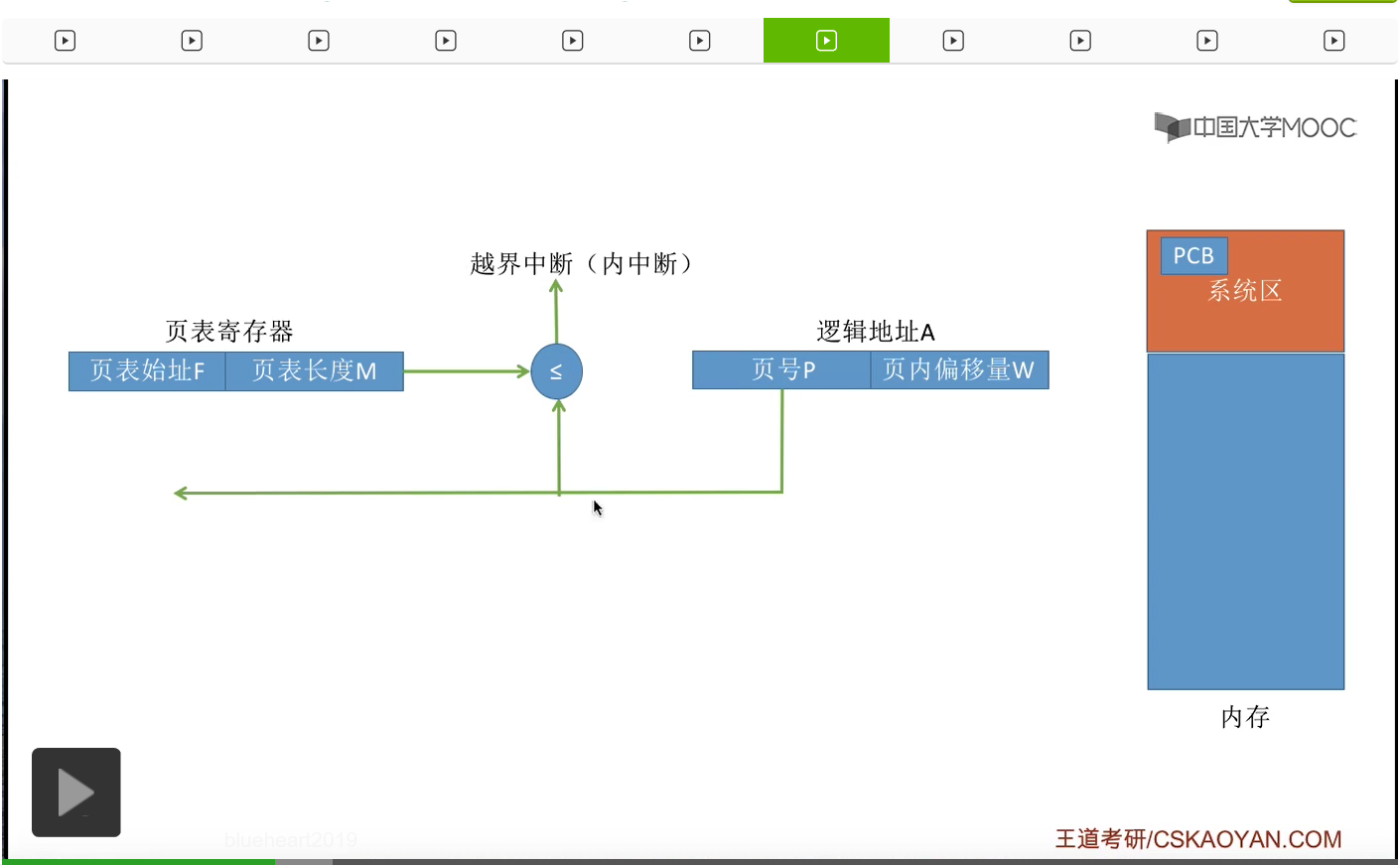
那从上个小节的讲解中我们知道,采用分页存储管理方式的这种系统当中,逻辑地址结构肯定是固定不变的。在一个逻辑地址当中,页号有多少位,页内偏移量有多少位这些操作系统都是知道的。所以只要知道了逻辑地址A,那么就可以很快地切分出页号和页内偏移量这样的两个部分。那接下来会对页号的合法性进行一个检查。一个进程的页表长度M指的是这个进程的页表当中有M个页表项,也就意味着这个进程的页面总共有M页。所以如果此时想要访问的页号已经超出了这个进程的页面数量的话,那么就会认为此时想要访问的这个逻辑地址是非法的,这样就需要抛出一个越界中断。那如果说这个页号是合法的,
那么接下来会用这个页号和页表始址来进行计算,找到这个页号对应的页表项到底是多少。那通过上个小节的讲解我们知道,页表当中的每一个页表项的长度其实是相同的,所以其实只要我们知道了页号还有页表起始地址,再知道我们每一个页表项的长度,我们就可以算出我们想要访问的页号对应的页表项所存放的位置。那既然知道了它存放的内存块号,我们就可以再用内存块号结合内存偏移量得到最终的物理地址,然后就可以顺利地访问逻辑地址A所对应的那个内存单元了。所以整个过程做了这样几件事,第一是根据逻辑地址算出了页号和页内偏移量。第二需要检查这个页号是否越界,是否合法。第三,如果这个页号是合法的,那么我们会根据页号还有页表始址来计算出这个页号对应的页表项应该是在什么地方,然后找到相应的页表项。第四,在我们得知了这个页面存放的内存块号之后,我们就可以用内存块号还有页内偏移量来计算出最终的物理地址。然后最后再对这个物理地址进行访问。那在考试当中,经常会给出一个逻辑地址还有页表然后让我们计算对应的物理地址,所以大家需要对上面所说的这些过程都非常熟悉。
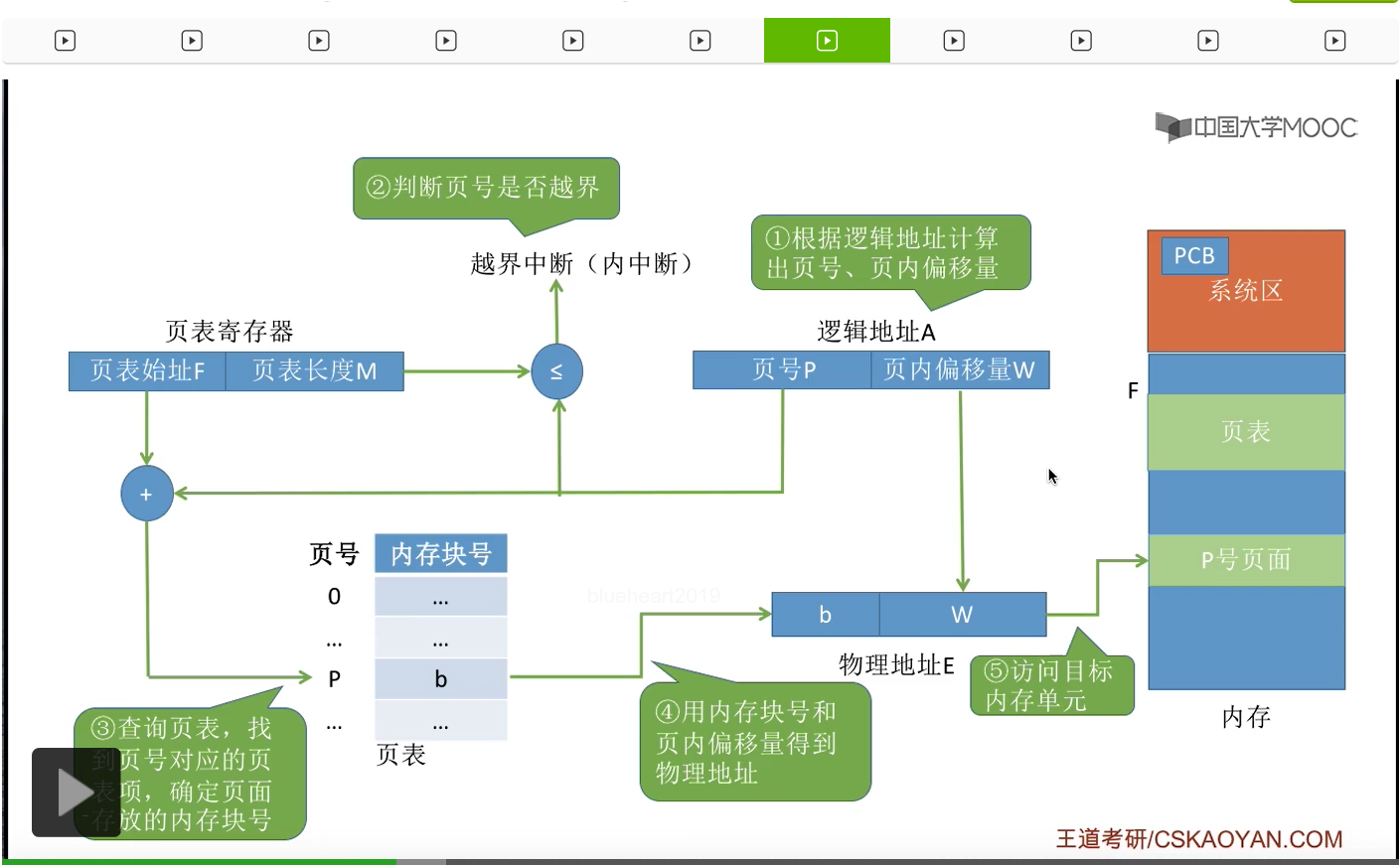
那接下来我们再用文字的方式再给出一个描述,虽然说这个内容比较重复,但是也是因为这个部分的内容极其重要,所以想多让大家过几遍。特别是页表长度还有页表项长度这两个概念一定要着重注意一下。

那这个地方的验证这儿就暂时不展开,大家下去动手尝试一下。

页号2对应的内存块号b=8,也就是2号页面应该存在内存块号为8的地方。按字节寻址就意味着这个系统当中每个地址对应的是一个字节。逻辑地址结构中,页内偏移量占10位,这个信息很重要,页内偏移量的位数其实就直接决定了一个页面的大小是多少。那么偏移量占10位的话,那么就说明一个页面的大小是2的10次方个字节,也就是1KB。所以这种说法和上面这种说法其实是等价的,在做题的时候一定要注意这个页内偏移量还有页面大小之间的这种对应关系。那进行地址的转换第一步我们应该根据这个条件算出页号和页内偏移量。由于题目当中给出的是这种十进制表示的逻辑地址,所以我们用除法还有取余操作这样的方式来计算会更方便一些。而根据题目当中给出的条件,页号2对应的内存块号b=8,也就说明,页号为2的页表项是存在的,因此页号2肯定没有越界。并且查询页表之后已经知道这个页面应该是存放在内存块号为8的地方。那第三步,我们知道了内存块号、知道了页号、页内偏移量我们就可以计算物理地址。物理地址=内存块号*每个页面的大小(或者说每一个内存块的大小)+页内偏移量。其实在分页存储管理(页式存储管理)的系统当中,只要我们确定了每个页面的大小是多少,那么逻辑地址的结构肯定就已经确定了。所以页式管理当中的地址是一维的,我们并不需要告诉系统除了逻辑地址以外的别的信息,不需要显式地告诉它页内偏移量占多少,页号占多少。因为这些信息都是确定的,所以在页式管理当中,我们想要让系统把逻辑地址转换成物理地址,只需要告诉系统一个信息,也就是逻辑地址的值,不需要再告诉系统别的任何信息。那因为只需要告诉它一个信息,因此这个地址是一维的。那这就是我们手动地模拟基本地址变换机构转换地址的一个过程。很多初学者会忽略的是,对页号进行越界检查的这一步操作,所以这个地方需要留个心眼。

但是1365个页表项并不能占满整个页框。这个页框还会剩余一个字节的页内碎片。那由于这个地方只剩一个字节的空闲区域了,所以下一个页表项只能存放在下一个页框当中,它不能跨页框地存储。+1就是为了消除这一字节剩余的误差。所以说可以发现,如果说我们的这些页表项并不能装满整个页框的话,那在查找页表项的时候其实是会造成一些麻烦的。所以为了解决这个问题,我们可以把每个页表项的长度再拓展一下,把它拓展到四个字节。这样的话我们就可以保证每个页框刚好可以存放整数个1024个页表项,并且不会有任何的这种页内碎片,

就像这个样子。这样的话,我们要查询1024号的页表项,我们就不需要像上面这么麻烦了。因为这个页框当中不会有任何的页内碎片,所以在理论上来说,页表项的长度最短三个字节就可以表示所有的这些内存块号的范围。但实际的应用当中,为了方便页表的查询,经常会让一个页表项占更多的字节,使得每个页面恰好可以装得下整数个页表项。不过即使这个页表项长度是3个字节,其实也没问题,只不过在查询页表的时候可能会需要做一些更麻烦的处理。如果在题目当中要我们算页表项的长度最小应该是多少,那我们按照3字节这样的思路来处理就可以了。四个字节这样的处理只是实际应用当中为了方便而采用的一种策略。那经过刚才的这个例子大家有没有发现,一个进程如果它的页表太大,也就是页表项太多的话,那么这个进程的页表一般来说装到内存里也是会尽可能地让它装在连续的一些内存块当中。因为这样的话我们都可以用一个统一的计算方式就可以得到我们想要得到的那个页表项所存储的位置。

好的,那么在这个小节当中我们学习了如何使用基本地址变换机构这一系列的硬件来实现地址转换的一个过程。那基本地址变换机构当中,最重要的硬件就是页表寄存器。大家需要知道页表寄存器有什么作用。那这个小节中,最重要的是要掌握地址变换的整个过程。我们要知道计算机是怎么一步一步实现这些地址变换的,并且还要能用手动的方式、手算的方式来模拟出整个地址变换的过程。那这一部分是大题和小题的极高频的出题点。那除了地址变换过程之外,我们在讲解的过程中,也补充了一些小的细节。比如说页内偏移量的位数和页面大小之间是有一个对应关系的。那如果说题目当中给出了页内偏移量的位数,大家需要能够推出页面的大小。同样的,如果告知我们页面大小,也要能够推出页内偏移量的位数。如果知道地址、逻辑地址的总位数的话,我们还要能够写出整个逻辑地址的地址结构。那这个小知识点在计算题当中是很容易用到的。那除了这个之外,页式管理的地址是一维的。这一点也经常在选择题当中进行考查。那大家要理解什么叫一维,所谓的一维就是说,我们要让CPU帮我们找到某一个逻辑地址对应的物理地址的话,我们只需要告诉CPU一个信息,也就是逻辑地址的值,并不需要再告诉它其他的任何信息,所以这是一维的含义。那另外的两个小细节只是为了能够让大家更充分地了解这种页式管理的这种机制才补充的,当然考试当中一般来说不会考查。那除了这些内容之外,我们还需要注意一个很重要的知识点。在CPU得到一个想要访问的逻辑地址之后,一直到实际访问的这个逻辑地址对应的内存单元的整个过程当中,总共需要进行两次访问内存的操作。第一次访问内存是在查询页表的时候进行的,第二次访问内存是在实际访问目标内存单元的时候进行的。那在下个小节当中我们会探讨一种新的地址变换机构,是否能用一种别的地址变换机构来减少访问内存的次数,从而加快整个地址变换还有访问的过程呢?那这是下个小节想要探讨的问题。
 在这个小节中我们会学习具有快表的地址变换机构。
在这个小节中我们会学习具有快表的地址变换机构。

那上个小节中我们学了基本地址变换机构,还有逻辑地址到物理地址转换的一个过程。那在基本地址变换机构的基础上,如果引入了快表的话,就可以让这个地址变换的过程更快,所以这个小节中我们首先会介绍什么是快表,并且会介绍引入了快表之后,地址变换的过程有什么区别。最后我们会解释为什么引入快表之后,可以让计算机的整体效率、整体性能都得到很高的提升。
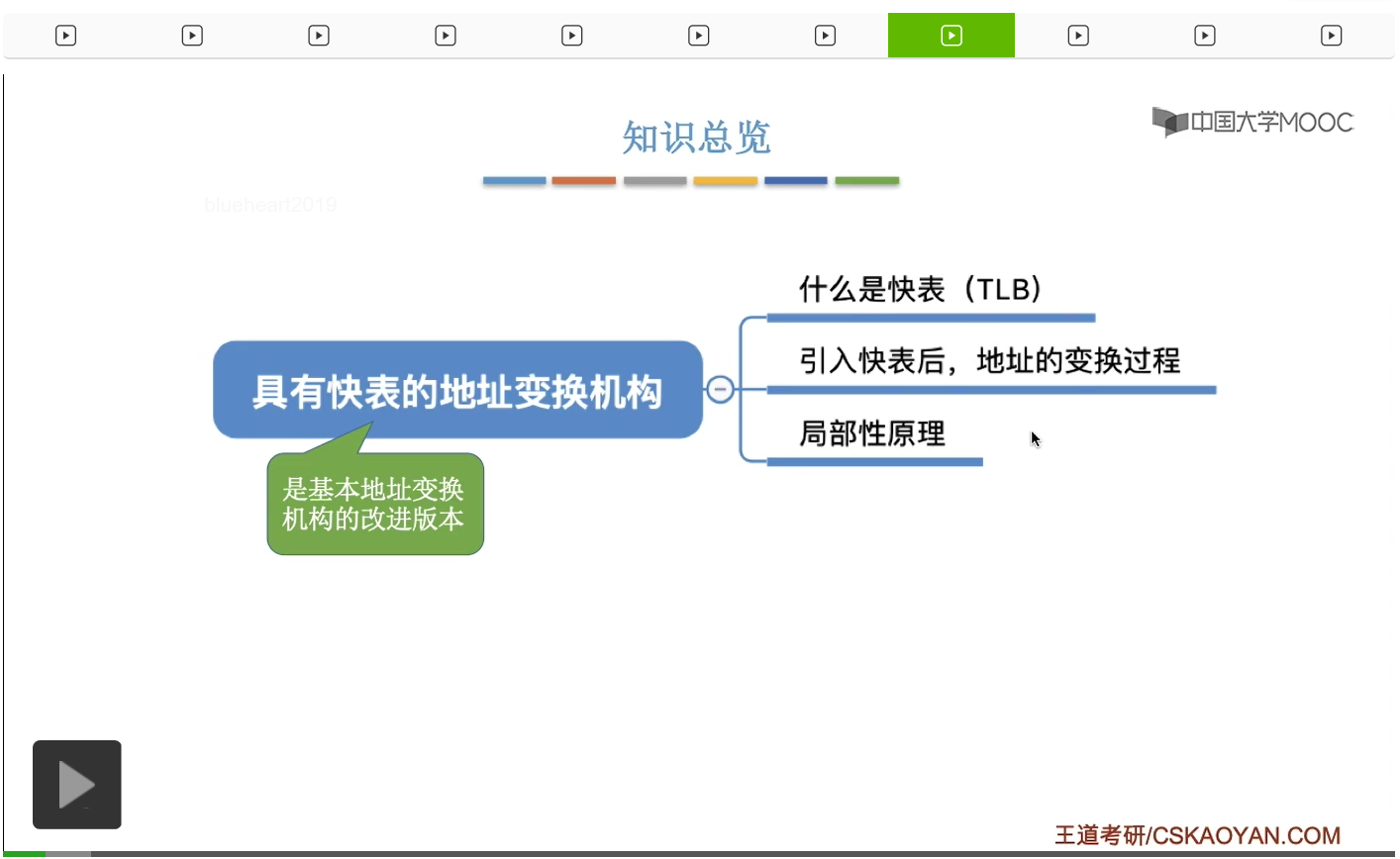
注意TLB它不是内存,它是一种高速缓存。那快表中存放的是最近我们访问过的一些页表项的副本,这样的设计可以让地址变换速度更快。页表其实是存放在内存当中的,在引入了快表之后,我们可以把存放在内存中的页表称为慢表。因为访问内存中的这个页表的速度更慢,而访问快表当中存放的这些页表项的速度会更快,所以这是快表和慢表名字的由来。但是由于硬盘的读写速度很慢,而CPU处理数据的速度又很快,因为硬盘速度慢而拖累CPU的速度,导致系统整体性能的降低。内存的速度要比硬盘快好几十倍,所以我们把CPU要访问的那些数据先放到内存中就可以缓和CPU和硬盘之间的速度矛盾。把内存当中最近有可能会被频繁访问到的东西放到高速缓存里,进一步地缓和CPU和存储设备之间的一个速度矛盾。高速缓存它本质上也是用于存取数据的一个硬件设备。缓存并不是内存,CPU访问高速缓存的速度要比访问内存的速度要快的多。因此如果我们可以把最近想要访问的那些页表项的副本把它存到这个快表这种高速缓存当中,那么CPU在地址变换的时候查询页表的这个速度就会快的多了。快表TLB它和我们平时所说的那种狭义上的高速缓存,狭义上的Cache其实也是有区别的。快表的查询速度要比慢表快很多。
那接下来我们要探讨的问题是,既然快表的查询速度快那么多,那能不能把整个页表都放在快表当中呢?其实这个原因不难理解,因为快表这种存储硬件的造价更贵,因此在成本相同的情况下,快表可以存的东西肯定没有那么多。所以我们系统当中存储分级的这个思想和我们这儿提到的这个例子其实是一模一样的。

所以为了兼顾系统整体的运行效率,同时也要考虑这个造价成本,因此才采用了这种多级的存储设备。好的那么刚才我们从硬件的角度理解了快表为什么要比慢表更快,那接下来我们再从这个操作系统的角度来看一下快表到底有什么作用。

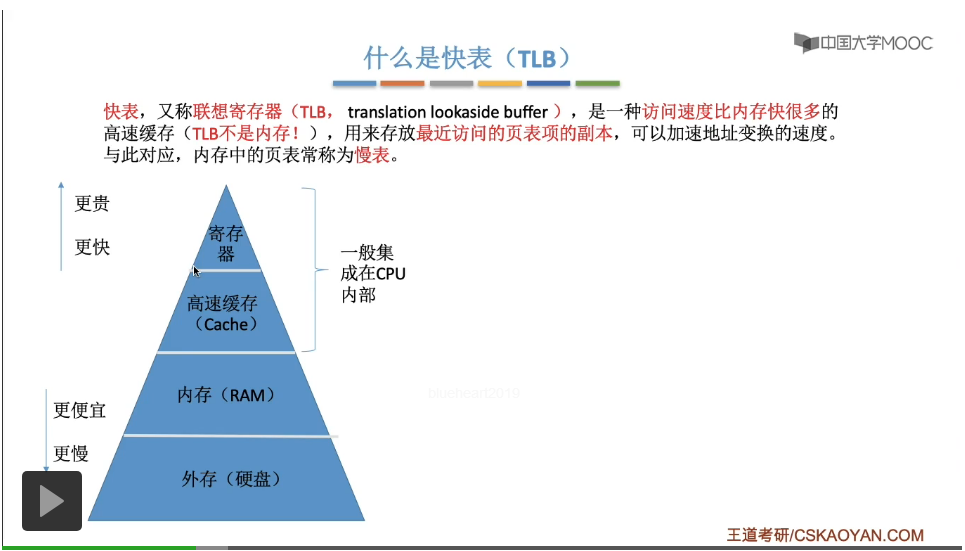
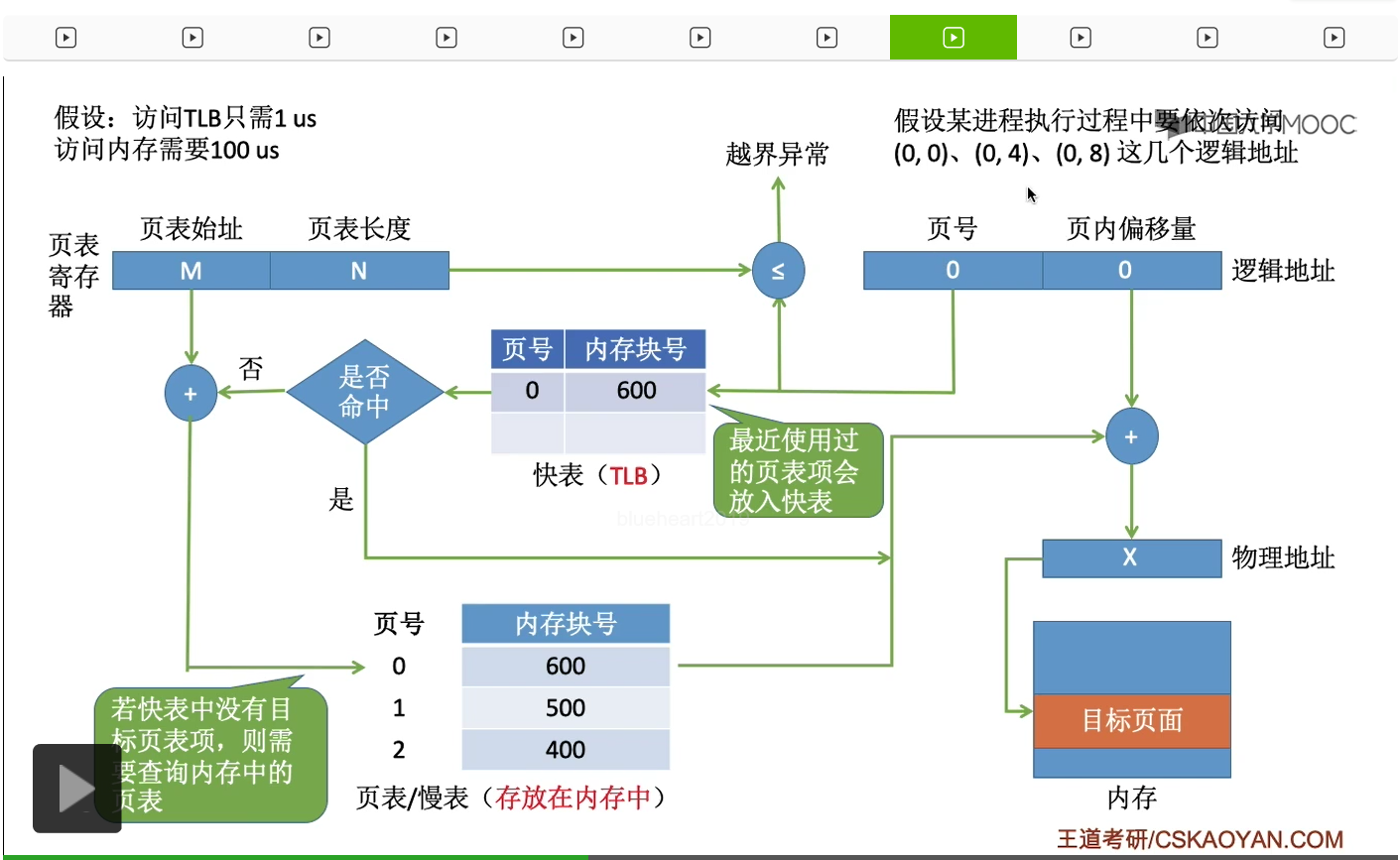
我们来看这样的一个例子,(0,0)、(0,4)、(0,8)这样的几个逻辑地址,那前面的这个是指页号,后面的这个指的是页内偏移量。这个进程的页表存放在内存当中,是这个样子。那当这个进程上处理机运行的时候,系统会清空快表的内容。注意啊,快表是一个专门的硬件,当进程切换的时候,快表的内容也需要被清除。
那我们假设访问快表、访问TLB只需要1微秒的时间,而访问内存需要100微秒的时间。接下来我们来看一下快表是如何工作的。
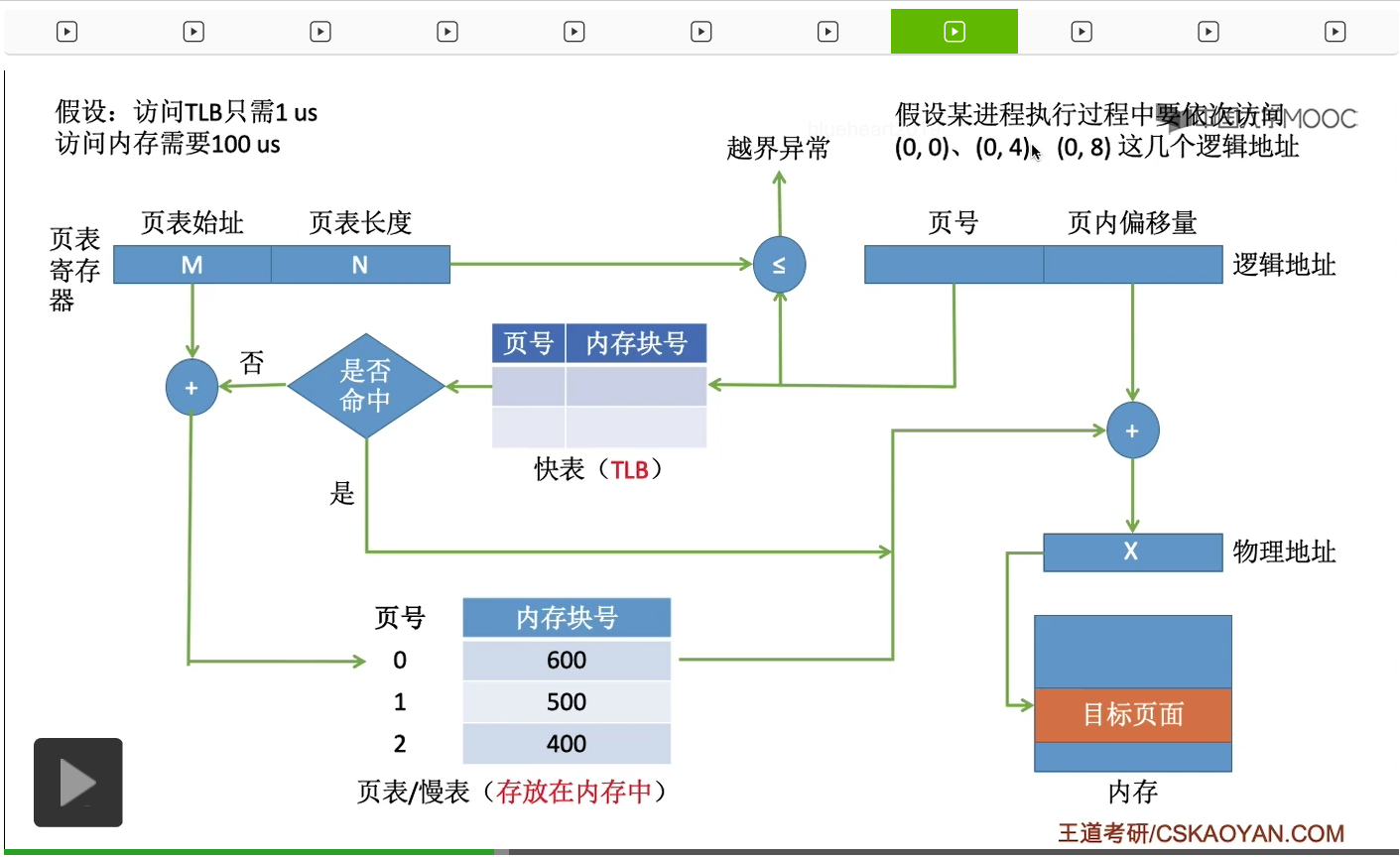
那首先这个进程它想要访问的逻辑地址是页号为0、页内偏移量也为0的这个逻辑地址。首先这个页号需要和页表寄存器当中的页表长度进行比对,进行越界异常的检查,然后发现这个页号并没有越界。接下来就会查询快表,但是由于这个进程刚上处理机运行,因此快表此时的内容是空的。在快表中找不到页号为0所对应的页表项,因此快表没有命中。那由于快表没有命中,因此接下来就不得不去访问内存当中存放的慢表,所以接下来通过页表始址还有页号计算出对应的页表项存放的位置。于是,在查询完慢表之后就可以知道,0号页面它所存放的内存块号是600。注意,在访问了这个页表项之后,同时也会把这个页表项把它复制一份放到快表当中。同时,刚才不是已经查到这个页面所对应的内存块号了吗?那么通过这个内存块号和页内偏移量就可以得到最终的物理地址。最后,就可以访问这个逻辑地址所对应的内存单元了。那这是进程访问的第一个地址。
接下来这个进程想要访问的地址是页号为0、页内偏移量为4的这个地址。那同样的,刚开始会进行一个越界异常的判断,发现没有越界。所以接下来会根据页号来查询快表,需要确认一下这个页号所对应的页表项是否在快表当中。那由于刚才我们已经把它复制到了快表当中,因此这一次的查询就可以命中。
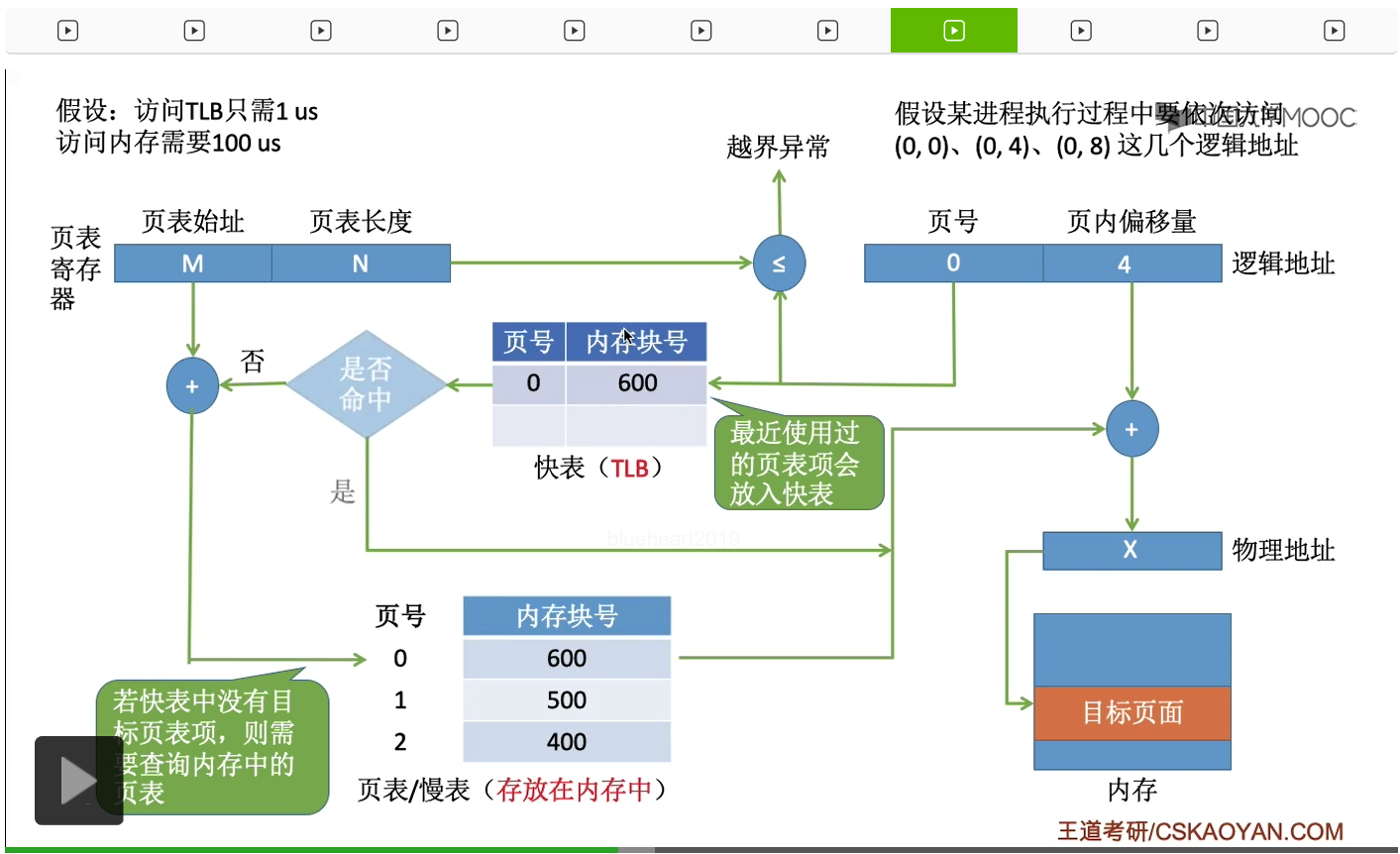
而快表命中之后,系统就可以直接知道,0号页面它存放的内存块号是600,因此接下来它就不需要再查询内存当中的慢表而是直接用这个内存块号和页内偏移量得到最终想要访问的物理地址,然后进行访存。
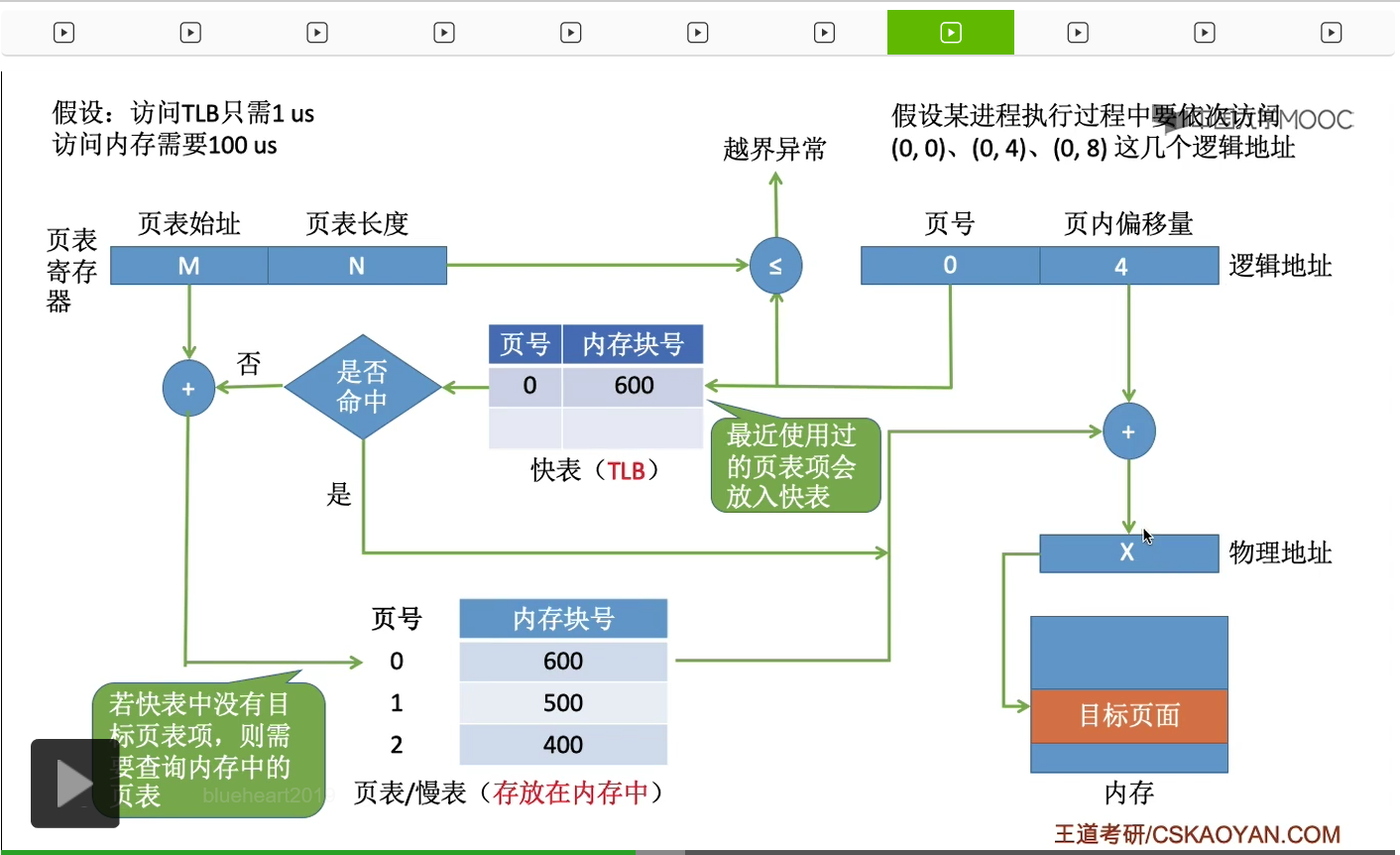
因此,如果快表命中的话,就不需要再访问内存中的慢表了。
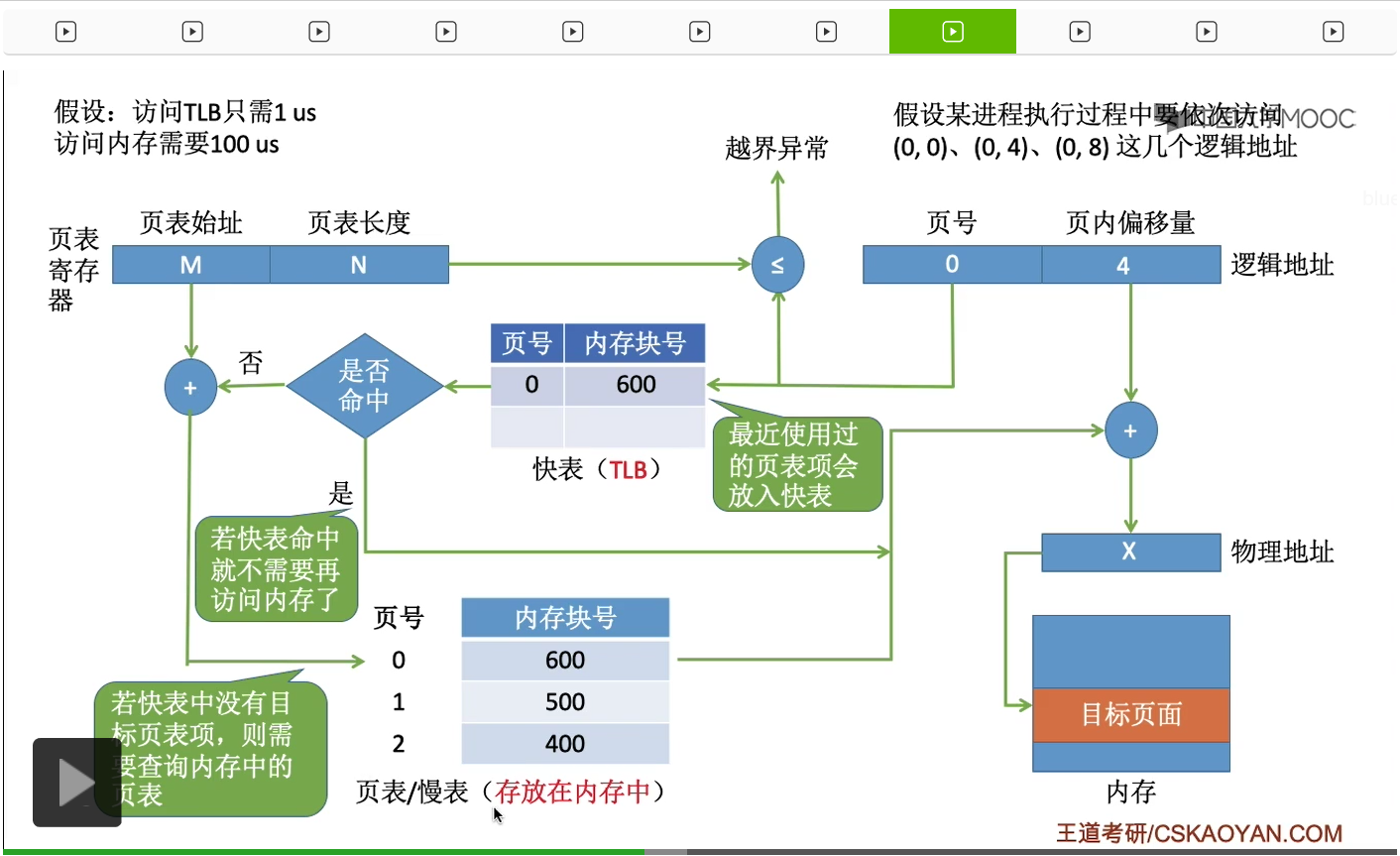
那最后的这个地址其实也是一样的。也是会先进行越界的检查,
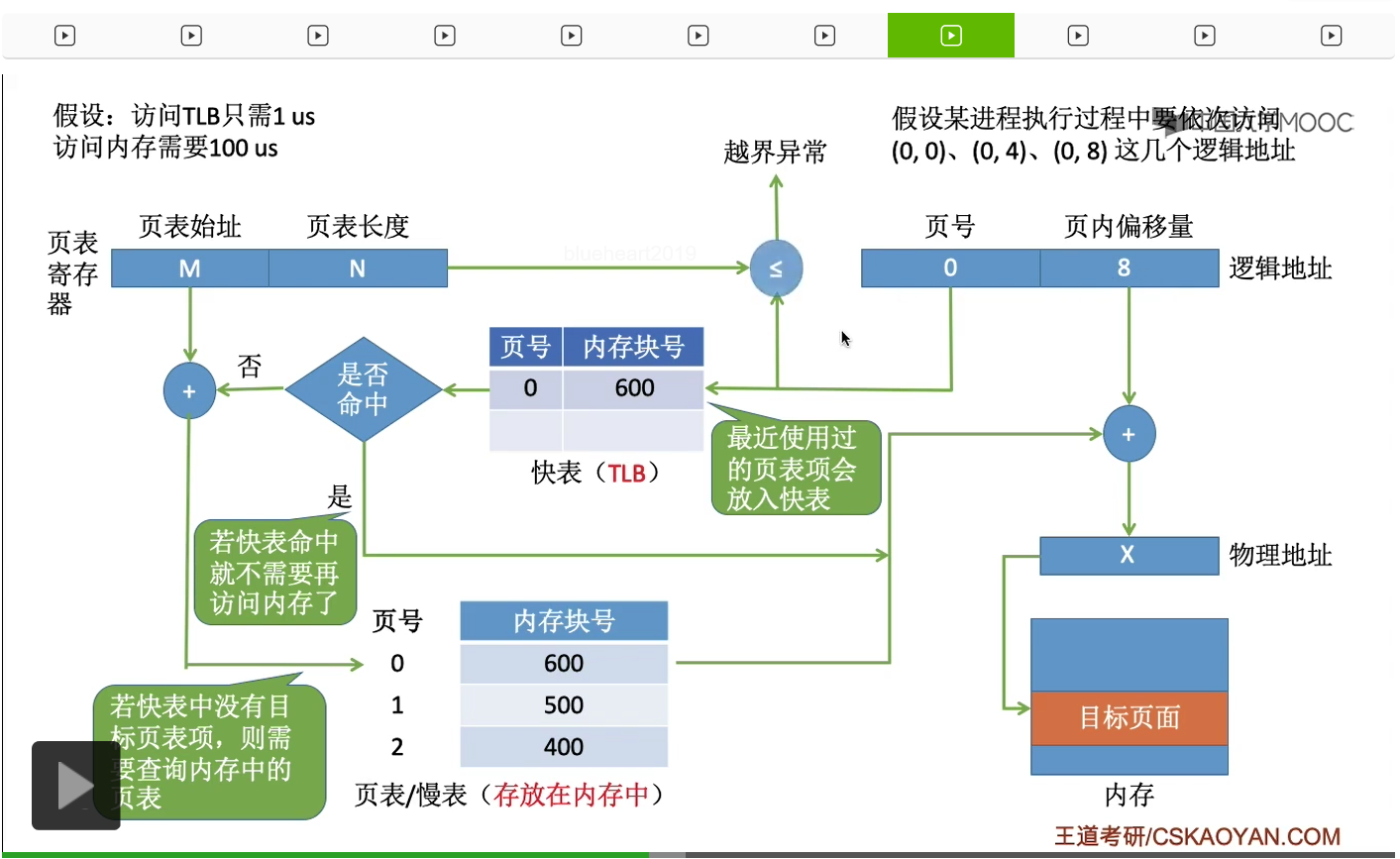
然后查询快表结果快表命中。于是系统可以直接根据查询快表的结果,得到最终的这个物理地址,然后访问最终需要访问的这个内存单元。那如果这个系统中没有快表的话,每一次地址变换的过程肯定都需要查询内存中的慢表,而访问一次内存需要100微秒的时间,因此每一次地址变换都需要花100微秒。而如果说引入了快表的话,那只要快表命中,我们的地址变换过程就只需要花费1微秒的时间,所以这也是为什么快表能够加快地址变换的一个原因。
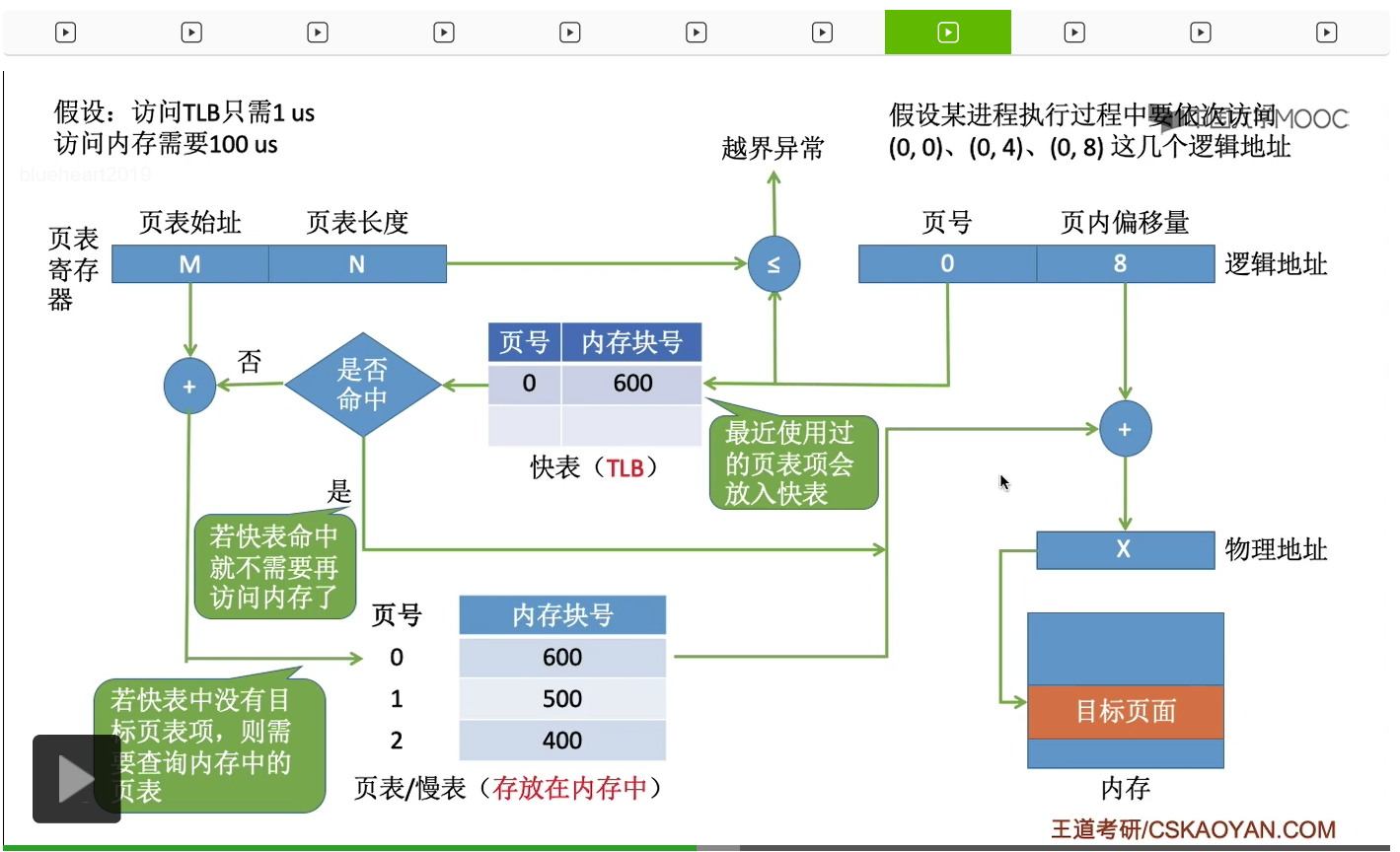
那需要注意的是,快表中存放的是进程页表当中的一部分副本。因为之前我们已经说了,快表虽然速度更快,但是造价其实也要比内存高很多,因此为了控制成本,快表的容量就不会特别大,所以快表当中只有可能存放慢表中的一部分页表项的副本,不过这已经可以让系统的效率有很大的提升了,这个我们之后还会继续细聊。
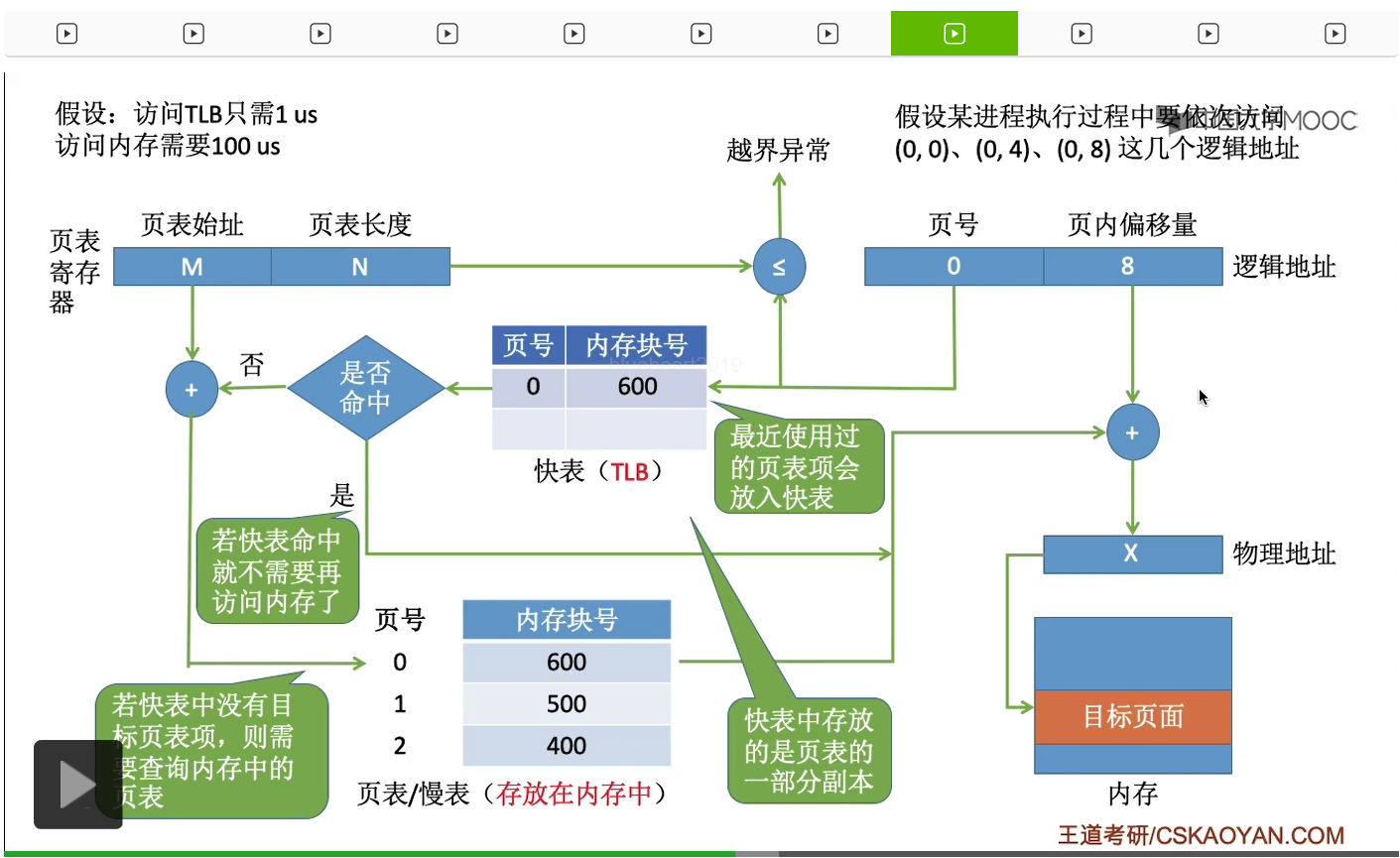
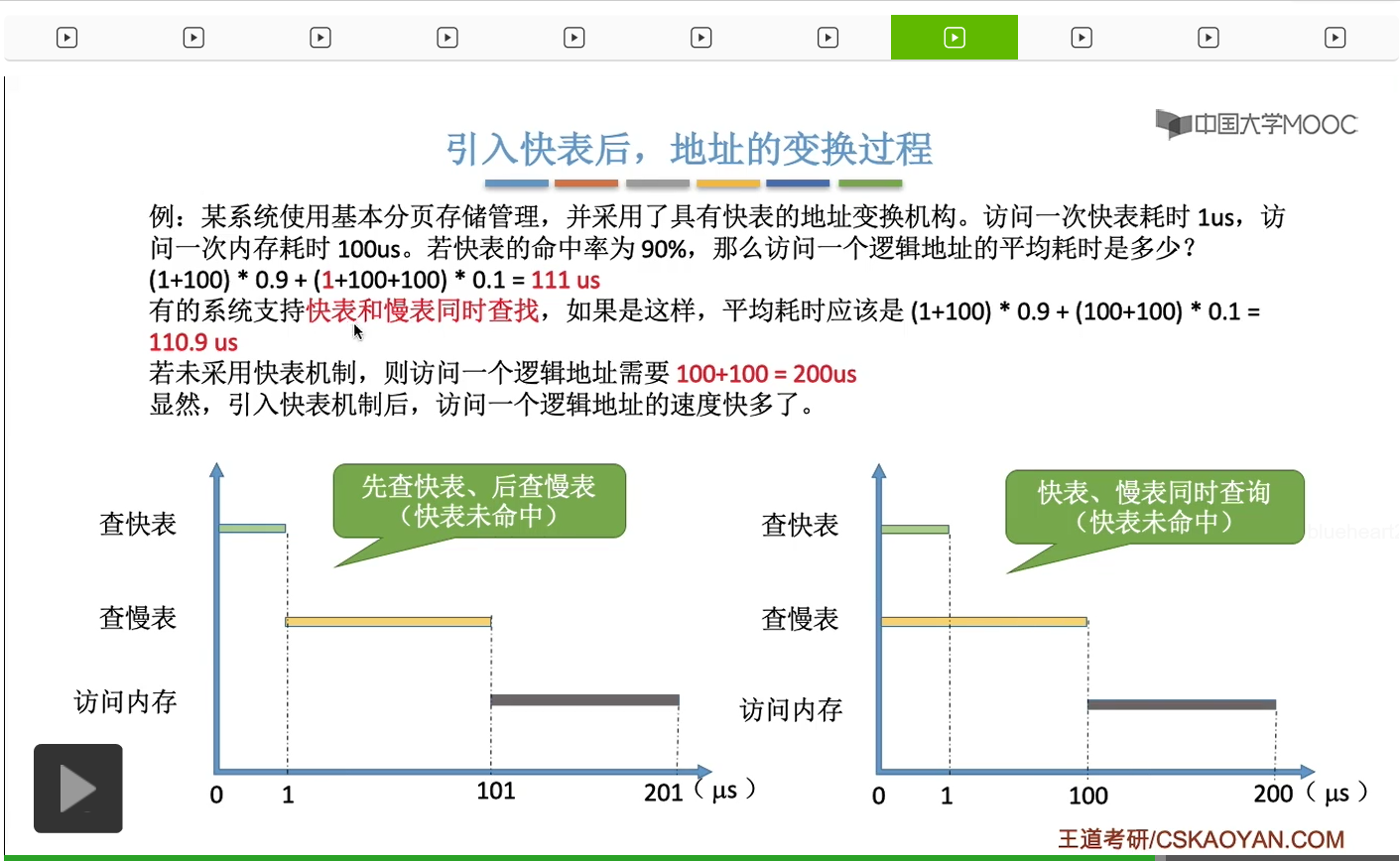
那接下来我们用文字的方式来总结一遍,引入了快表机构之后,地址变换的过程。首先通过这个逻辑地址,我们可以得到页号和页内偏移量,然后进行了越界判断之后,会把这个页号和快表当中所有的这些页号进行对比。只不过查询快表的速度要比查询慢表的速度快很多。如果慢表命中,也就是找到了这个页号对应的表项的话,那么就可以直接通过快表当中存放的那些信息,直接得到最终的物理地址,最终再访问我们想要访问的那个内存单元。所以在引入了快表机构之后,如果快表命中的话,我们访问一个逻辑地址,只需要一次访存。也就是访问我们最终想要访问的那个地址单元的时候才需要访存,而地址转换的过程当中,不需要访存。当然,如果快表没有命中的话,那么我们依然需要访问内存当中的页表,所以在这种情况下,我们要访问一个逻辑地址就需要两次访存。第一次访存是查询内存当中存放的页表,第二次访存是访问我们最终想要访问的那个内存单元。那需要注意的是,在我们查询慢表之后,同时也需要把慢表当中的页表项给它复制到快表当中。而如果快表已经存满了,那么我们需要按照一定的算法,淘汰快表当中的某一些页表项进行替换。那这个是我们之后置换算法当中会学习的一个内容,这儿就暂时不展开。总之在引入了快表之后,系统在进行地址变换的时候,它会优先查询快表。只有快表没有命中的时候,它才会去查询内存当中的页表。那由于查询快表的速度要比查询慢表的速度快很多,所以这就可以使这个系统的整体效能得到提升。基于局部性原理,一般来说快表的命中率可以达到90%以上。什么是局部性原理,我们一会儿再解释。我们先来看一下假设快表的命中率可以达到90%的话,它到底可以让这个系统性能提升多少。那根据上面的分析我们知道,系统在访问一个逻辑地址的时候,它首先会查询快表,会消耗1微秒的时间。如果快表命中的话,那么系统就可以直接得到最终想要访问的物理地址并且访问这个物理地址对应的内存单元。那访问这个内存单元总共需要100微秒的时间。所以如果快表命中的情况下,访问这样的一个地址总共就需要耗费1+100这么多的时间。那再来看第二种情况,如果快表没有命中的话,首先系统会查询快表消耗1微秒的时间,接下来由于快表没有命中,所以系统需要访问内存当中的慢表。那查询慢表其实就需要访问一次内存,所以这儿就需要消耗100微秒的时间。那得到最终的物理地址之后,还需要访问最终想要访问的内存单元,因为这儿还需要加上100微秒。那发生这种情况的概率是10%,所以我们给它乘上0.1的权重。那如果这个系统没有快表机构的话,那每一次访问逻辑地址肯定都需要先查询内存中的慢表,然后最终再访问我们的目标内存单元。总之大家在做题的时候,需要注意的点就是,题目当中有没有告诉你快表和慢表是同时查找的。还是说,只有快表查询未命中的时候,再查询慢表。那不管怎样,在引入了快表之后,肯定这个地址变换的过程都快了很多,系统效能得到了大幅度的提升。

那接下来我们来解释一下刚才所说的这个快表和慢表同时查找到底是什么意思。我们的第一个例子当中我们是默认了系统先查询快表,也就是先消耗了1微秒的时间。当快表查询未命中的时候,它才会开始查询慢表。那查询慢表的过程又需要消耗100微秒的时间,而如果快表和慢表同时查询的话,情况就会变成这样。快表和慢表是同时开始查询的,而在1微秒的时候系统发现,这个快表查询未命中。但是在这个时刻,其实慢表也已经查了一微秒的时间,因此接下来再消耗99微秒就可以得到这个慢表的查询结果。那通过这个甘特图相信并不难理解,什么叫快表和慢表同时查找,什么叫先查快表,快表未命中的时候再查慢表。这是做题的时候大家需要注意的一个小细节。那接下来我们来思考一个问题,为什么TLB当中只存放了页表中的一部分就可以让系统的效能提升那么多呢?
这其实是因为著名的局部性原理。程序当中的变量,数组还有变量i,这些变量是存放在23号页面当中的。因为10号页面当中,存放的是它的这些代码指令。而这个数组在内存中其实是连续地存放的。那由于局部性原理,也就是说这个程序在某段时间内可能会频繁连续地访问某几个特定的页面,因此在地址变换的过程中,只要它访问的是同一个页面,那么它查询页表的时候其实查到的也都是同一个页表项。所以只要我们把慢表当中的页表项把它复制到快表当中,那这样就可以让地址变换的速度快很多了,因为就不需要每次查询慢表。那这就是为什么快表机构能够大幅度地提升系统效能的一个原因。
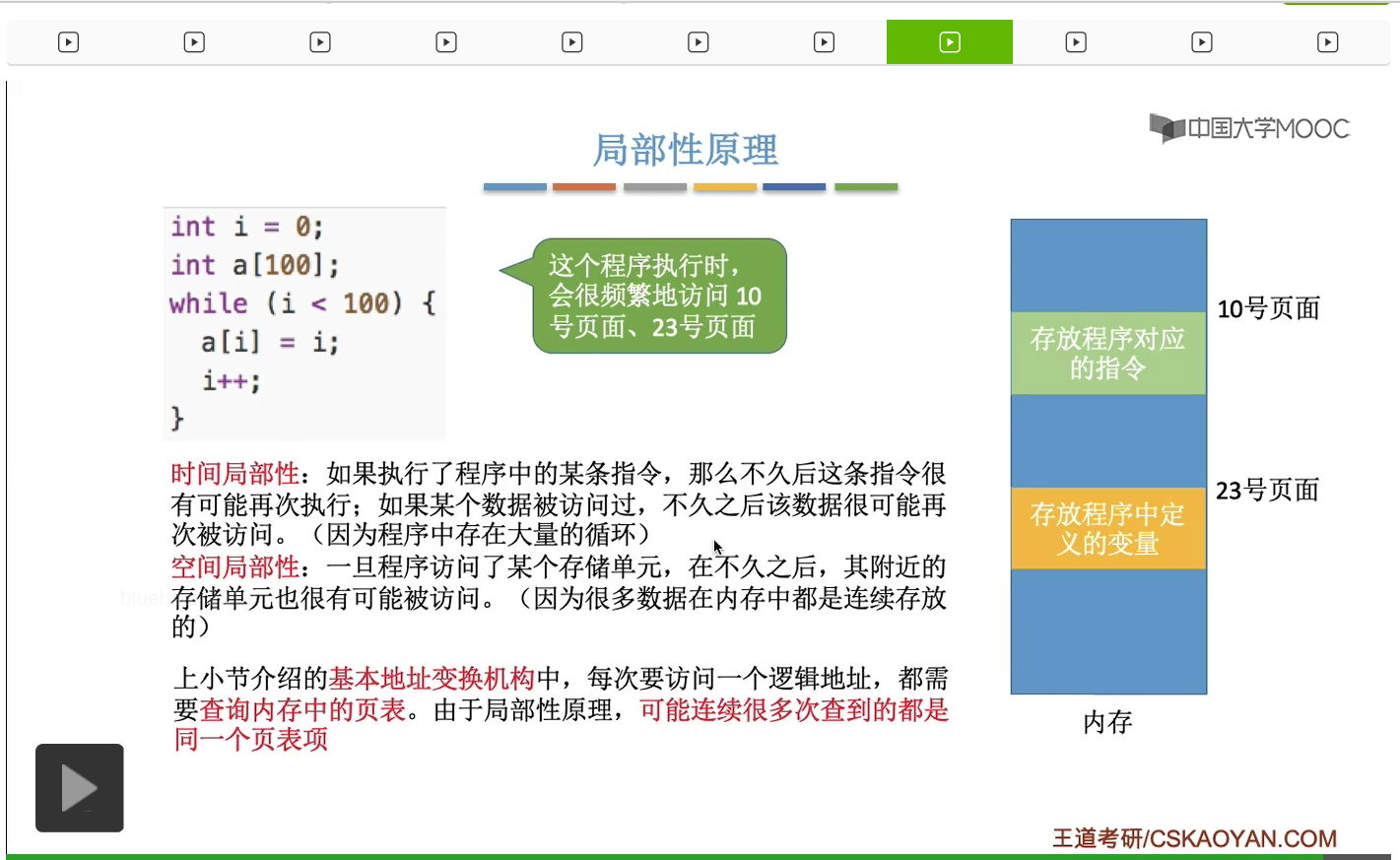
在没有引入快表之前,我们访问一个逻辑地址至少需要两次访存。第一次访存是查询内存当中的页表,第二次访存才是访问我们最终想要访问的那个内存单元。而在引入了快表之后,如果快表命中的话,那么就只需要一次访存。如果快表未命中的话,我们仍然需要两次访存,仍然需要查询内存中的慢表。TLB当中我们只存有页表项的副本,存放的是页表项的副本,而普通的高速缓存当中存放的是其他数据的副本。所以TLB和Cache还是有区别的,不能混为一谈。

介绍两级页表相关的一系列知识点。

最后我们还会强调几个两级页表问题在考试当中有可能会作为考点的一个很重要的几个细节。那我们会按照从上至下的顺序依次讲解。
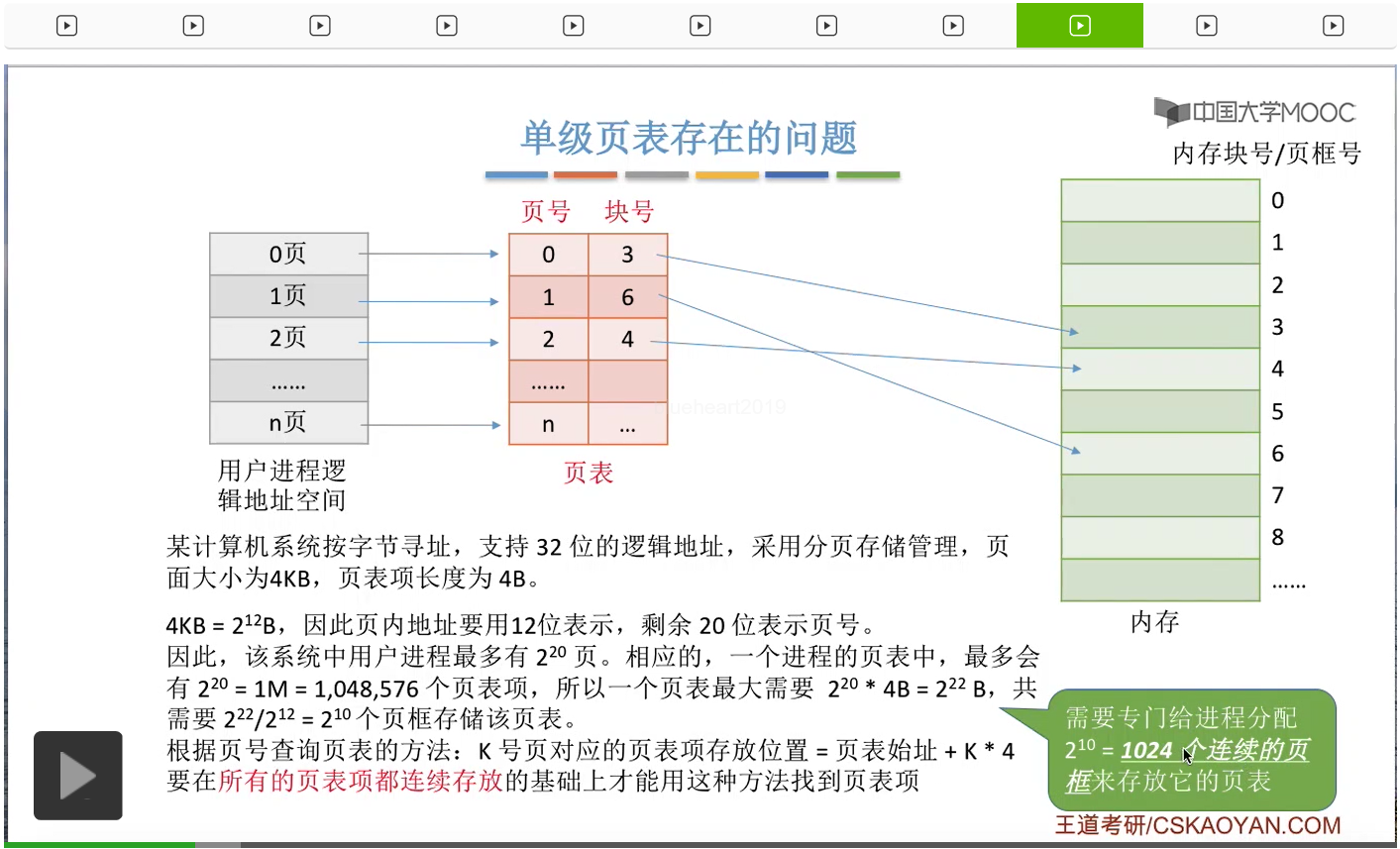
首先来看咱们之前介绍过的单级页表机制存在什么问题?而我们知道每一个页面需要对应一个页表项,那么这么多的页面就需要对应同等的2的20次方个页表项。而每个页表项的大小是4个字节,所以总共就需要2的22次方个字节来存储这个进程的页表。那这么多的字节,总共就是2的10次方个页框,也就是1024个页框。但是之前咱们讲过,为了实现通过页号查询对应的页表项这件事情,那么一般来说整个页表都是需要连续地存放在内存当中的。因此在这个系统当中,一个进程光它的页表就有可能需要占用连续的1024个页框来存放。那要为一个进程分配这么多的连续的内存空间,这显然是比较吃力的,并且这已经丧失了我们离散分配这种存储管理方式的最大的一个优点,所以这是单级页表存在的第一个很明显的缺陷、问题。
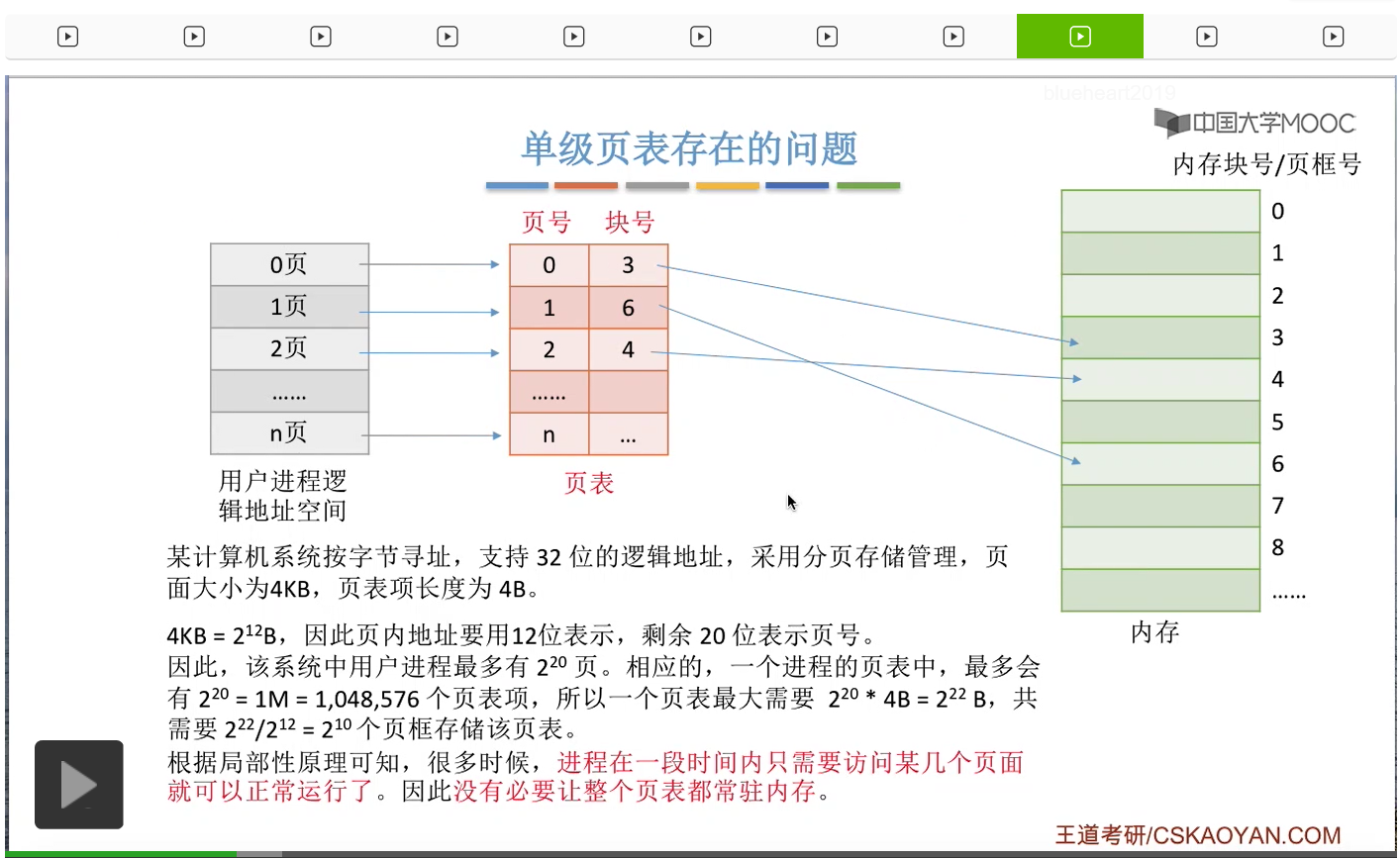
那第二个问题,由之前我们介绍过的局部性原理我们可以知道,很多时候其实进程在一段时间内只需要访问某几个特定的页面就可以正常地运行了。因此,我们没有必要让进程的整个页表都常驻内存,我们只需要让进程此时会用到的那些页面对应的页表项在内存当中保存就可以了,所以这是单级页表存在的第二个问题。
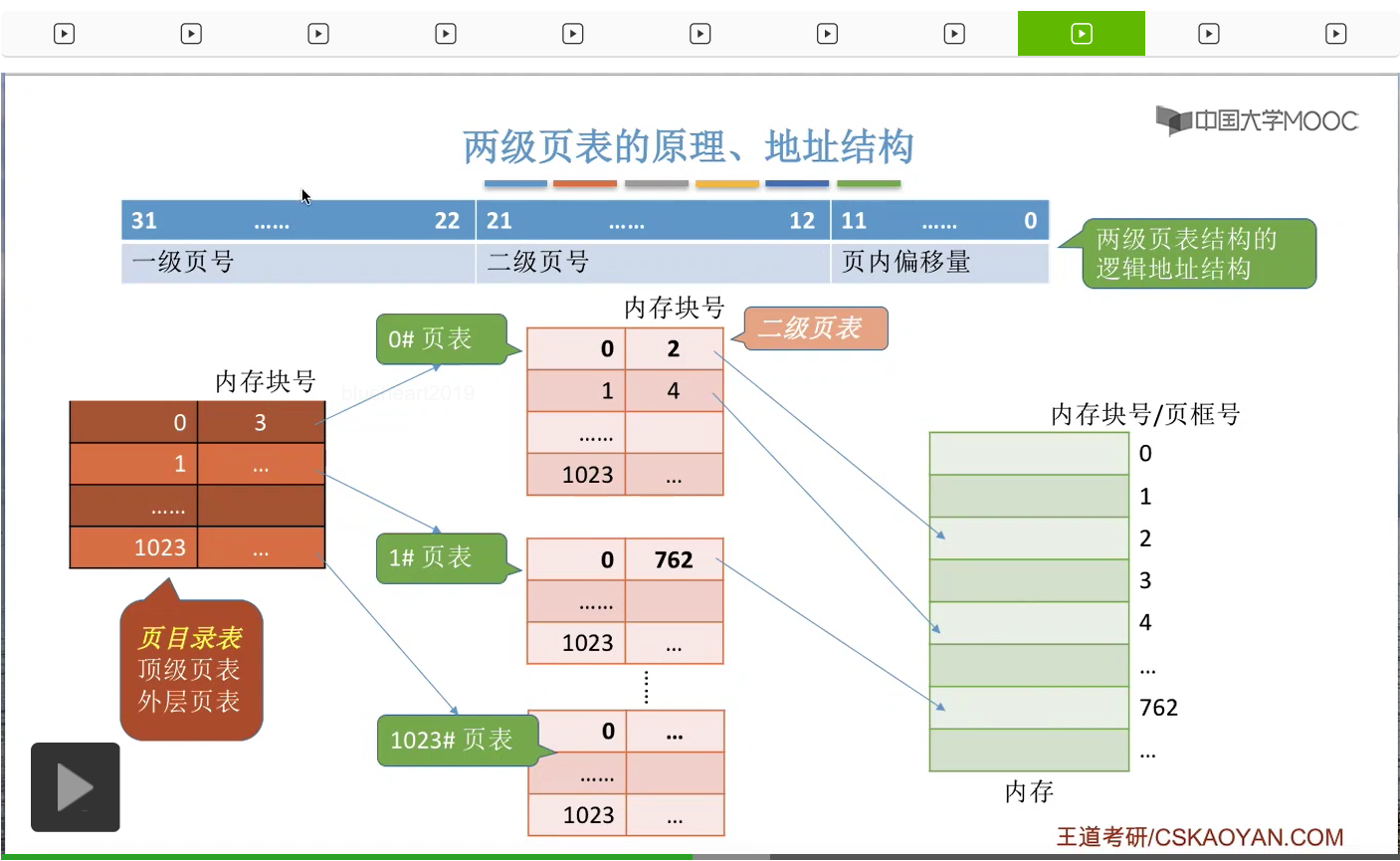
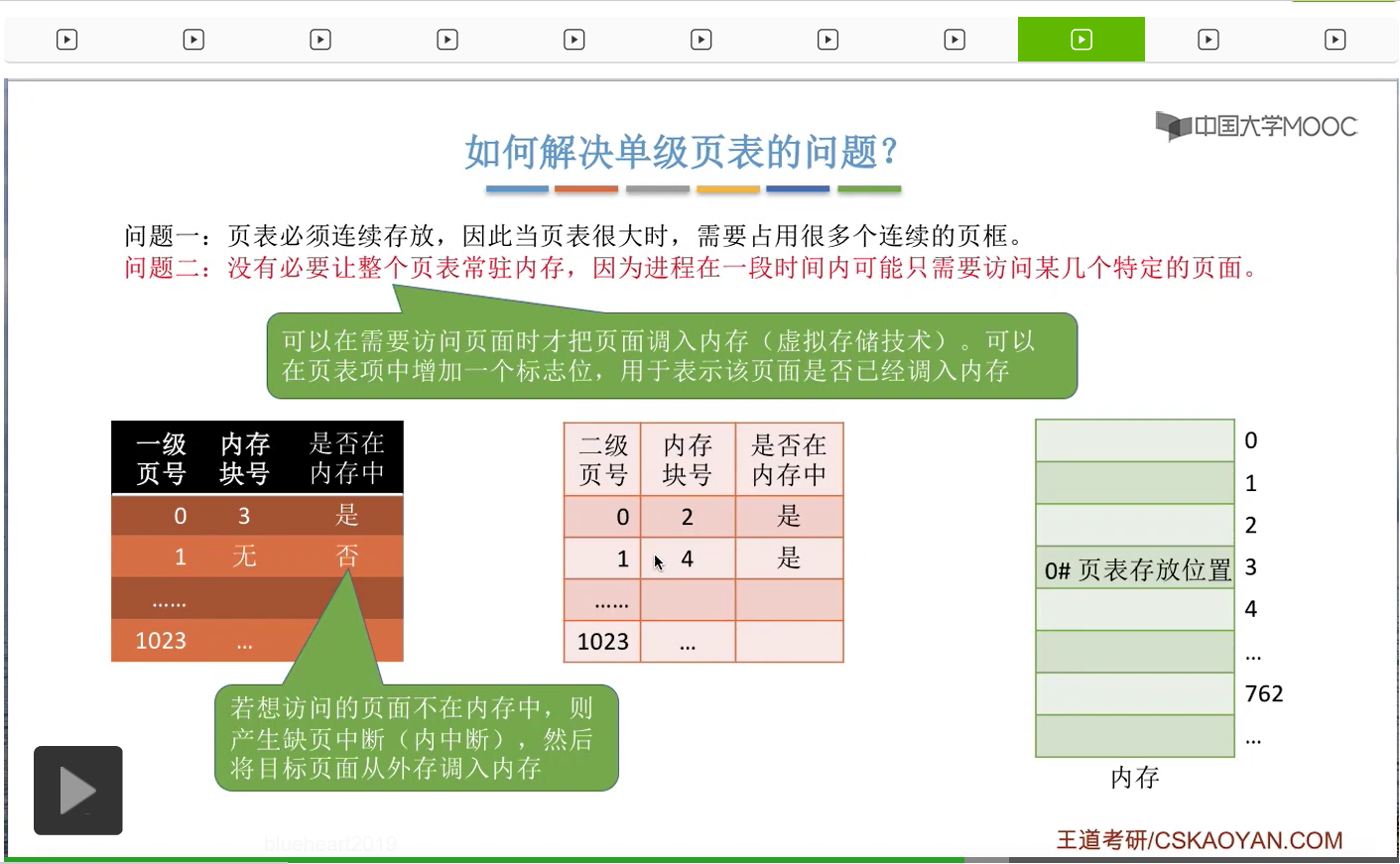
那么从刚才的分析当中我们知道,单级页表存在两个明显的问题。第一个问题就是页表必须连续地存放,所以如果页表很大的话,那么光页表就需要占用连续的很多个页框。那这和我们离散分配存储管理的这种思想其实是相悖的,所以我们要尝试解决这个问题。那第二个问题就是,我们没有必要让整个页表都常驻内存,因为进程在一段时间内可能只需要访问某几个特定的页面就可以顺利地执行了,那这是基于局部性原理得出的一个结论。那我们首先讨论第一个问题应该怎么解决。其实我们可以参考一下我们之前解决进程在内存当中必须连续存储的这个问题的时候,提出的那种思路。那我们之前的做法其实很简单,就是把进程的地址空间进行分页,然后再为进程建立一张页表,用来记录它的各个页面之间的顺序,还有保存的位置这些信息。那同样的思路其实我们也可以用来解决一个页表必须连续存储、连续占用多个页框的问题。那我们可以把这个很长的页表进行分组,让每一个内存块刚好可以放入一个分组。那为了保证我们把这些分组离散地放到各个内存块之后,还能够知道这些分组之间的先后顺序,因此我们依然是像需要模仿之前的这种思路,为这些分组再建立一个页表,然后这个页表就称为页目录表,或者叫外层页表,或者叫顶层页表。当然408的真题当中比较喜欢用的是页目录表这个名词。那这个地方观看这些文字描述会比较抽象,我们直接结合图像来进行进一步的理解。

那既然我们的页号有20位,就意味着在这个系统当中,一个进程最多有可能会有2^20次方个页面,那相应的也会有2^20次方个页表项。如果用十进制表示的话,这些页表项的编号应该是0-1048575(这其实就是2^20-1这么一个数)。那现在由于这个页表的长度过大,所以我们按照之前所说的那种思路,我们可以把这么大的一个长长的页表,把它拆分成一个一个的小分组,那每个小分组的大小可以让它刚好能够装入一个内存块。那我们每个内存块或者说每个页面的大小是4KB,而页表项的大小是4B,所以一个内存块、一个页面可以存放4K/4=1K个页表项,那么换算成十进制,就应该是1024个页表项。因此,我们可以把这么大的页表,拆分成一个一个的小分组,
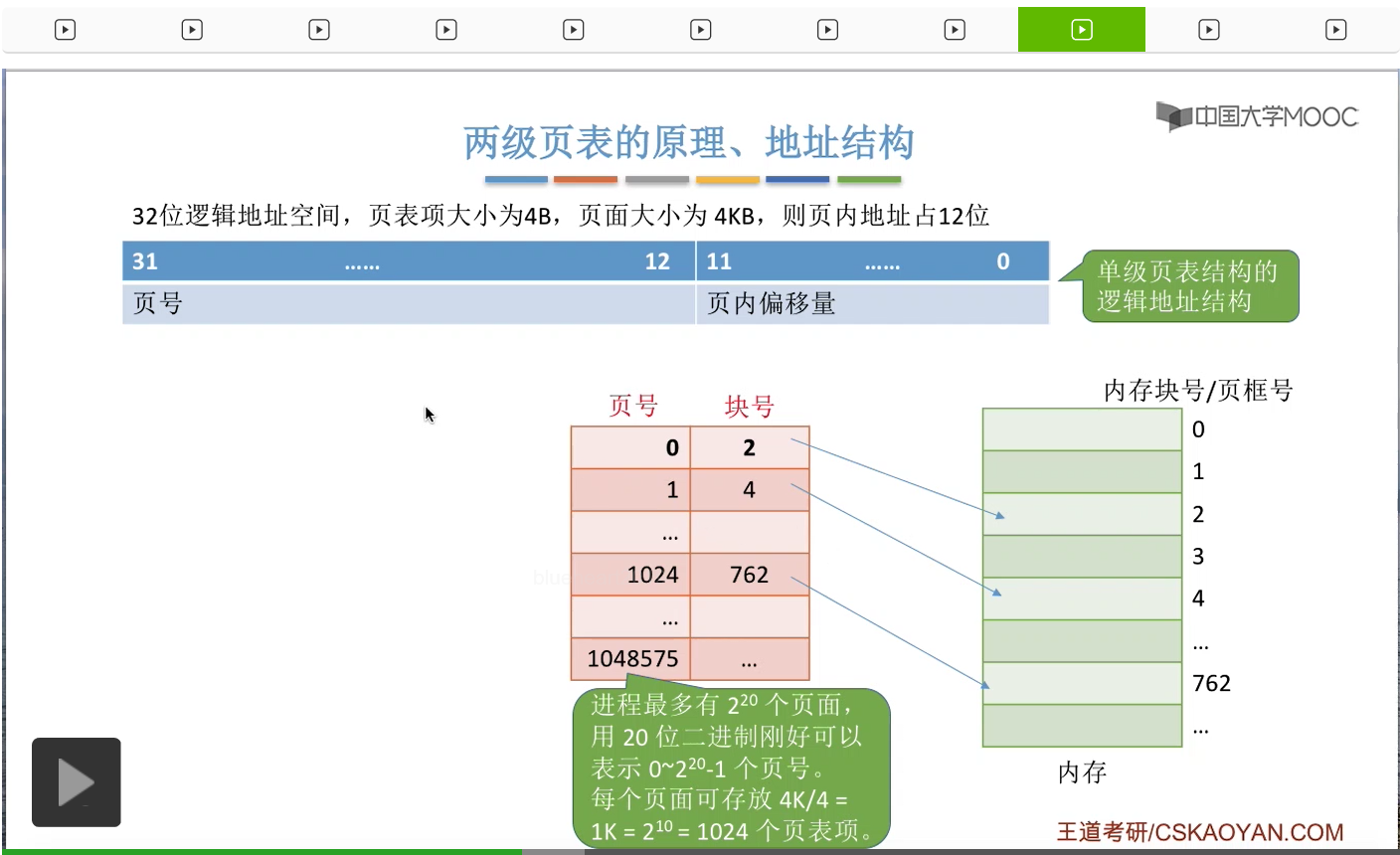
每一个分组的页表项有1024个,就像这个样子。另外,我们可以给这些小页表进行编号。那进行这样的拆分之后,最后总共就会形成1024个一个一个的小页表。那这个地方可以稍微注意一下的是,以前在这个大页表当中,编号为1024的这个页表项在进行拆分以后,应该是变成了第二个小页表当中的第一个页表项,所以可以看到这个页表项和这个页表项的这个块号是一样的,只不过页号变为了从0开始。
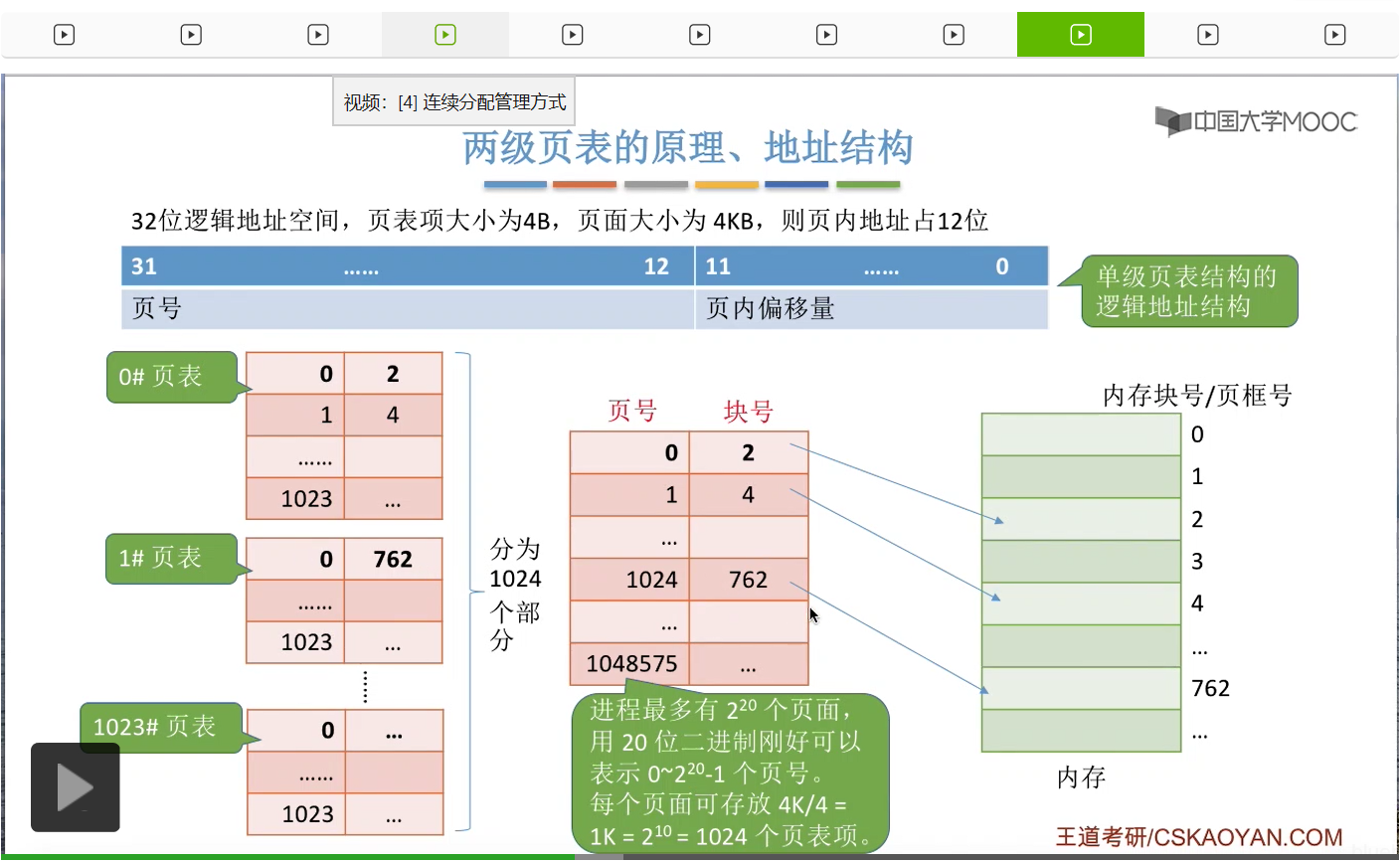
那我们继续往下分析,在把大页表拆分这样的一个一个的小页表之后,由于每个小页表的大小都是4KB,因此每个小页表都可以依次放到不同的内存块当中。所以为了记录这些小页表之间的相对顺序,还有它们在内存当中存放的块号、位置,
那我们需要为这些小页表再建立上一级的页表,这一级的页表就叫做页目录表或者叫顶级页表、外层页表。
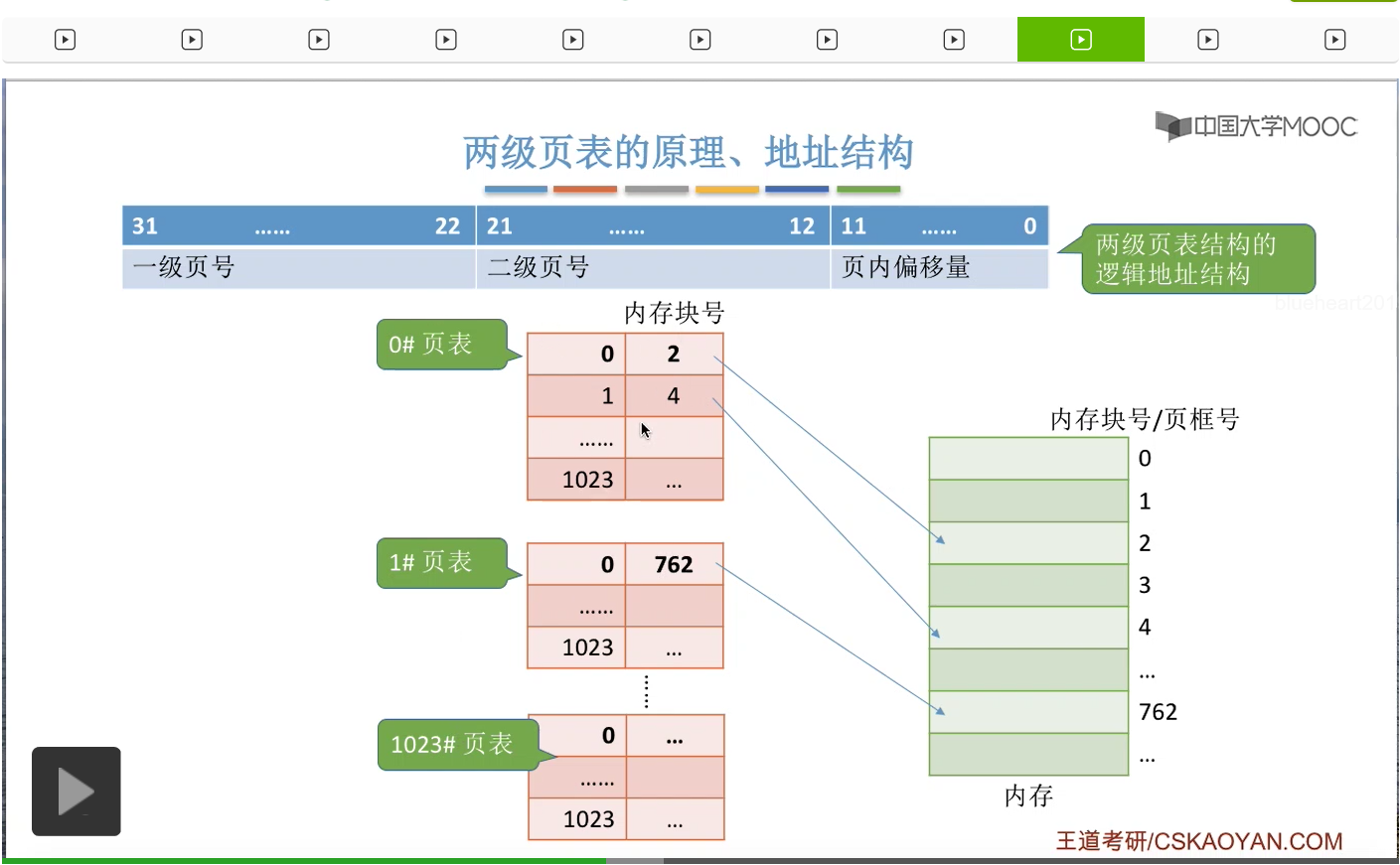
那相应的,这一层的小页表我们可以把它称为二级页表。那从这个图当中也可以很直观地看到,页目录表其实是建立了二级页表的页号,还有二级页表在内存当中存放的块号之间的一个映射的关系。所以如果此时我们想要找到0号页表的话,那么我们可以通过页目录表就可以知道0号页表是存放在3号内存块里的,所以只要在3号内存块这个地方来找0号页表就可以了。那在采用了这样的两级页表结构之后,逻辑地址的结构也需要发生相应的变化。我们可以把以前的20位的页号,拆分成两个部分。第一个部分是10位的二进制,用来表示一级页号,第二部分也是10位二进制,用来表示二级页号。
那10位的二进制大家会发现,刚好是可以表示0-1023这么一个范围,
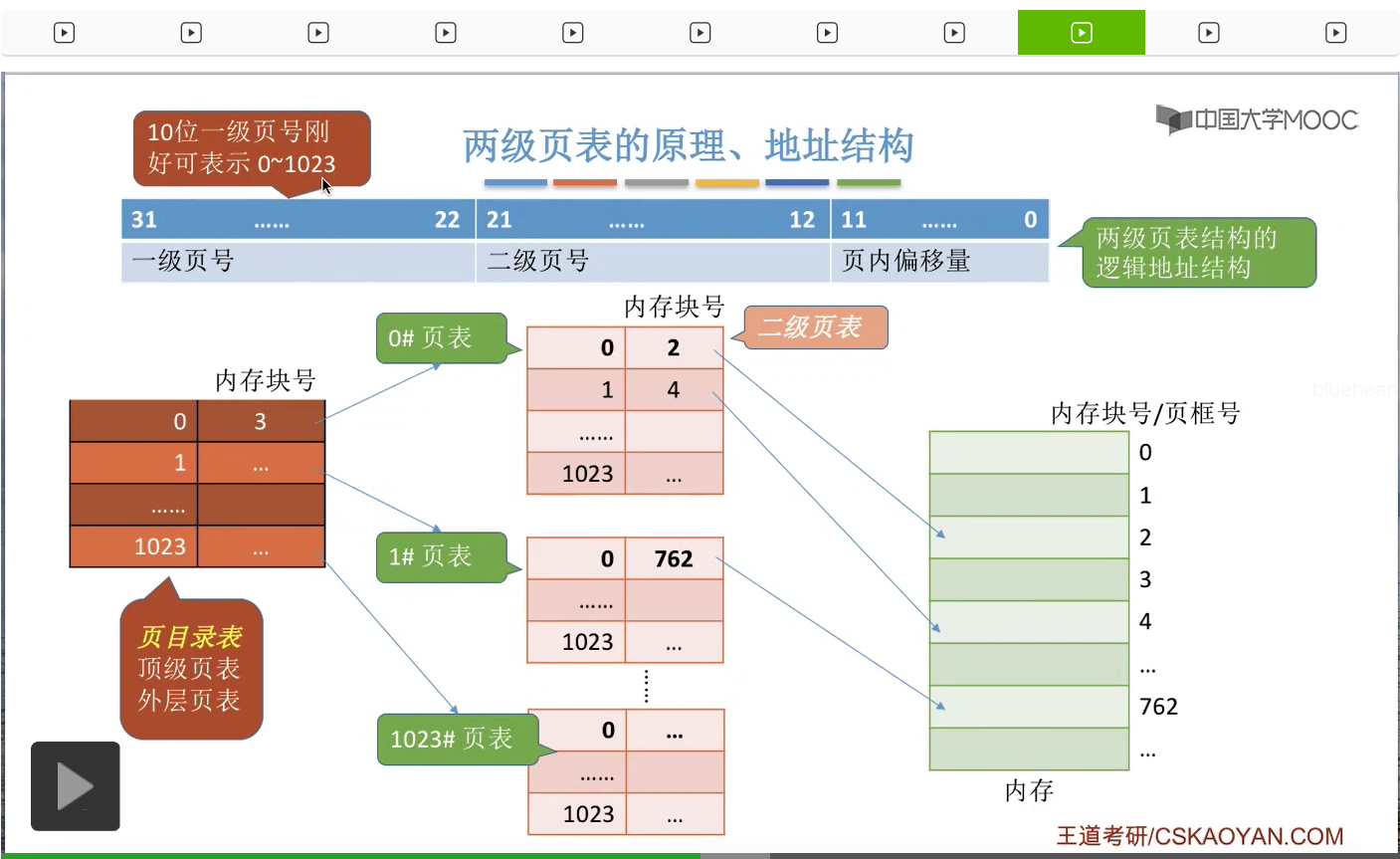
所以用一级页号来表示这个范围是刚好的。
那相应的二级页号这十个二进制位,就是用来表示二级页表当中的这些页号。
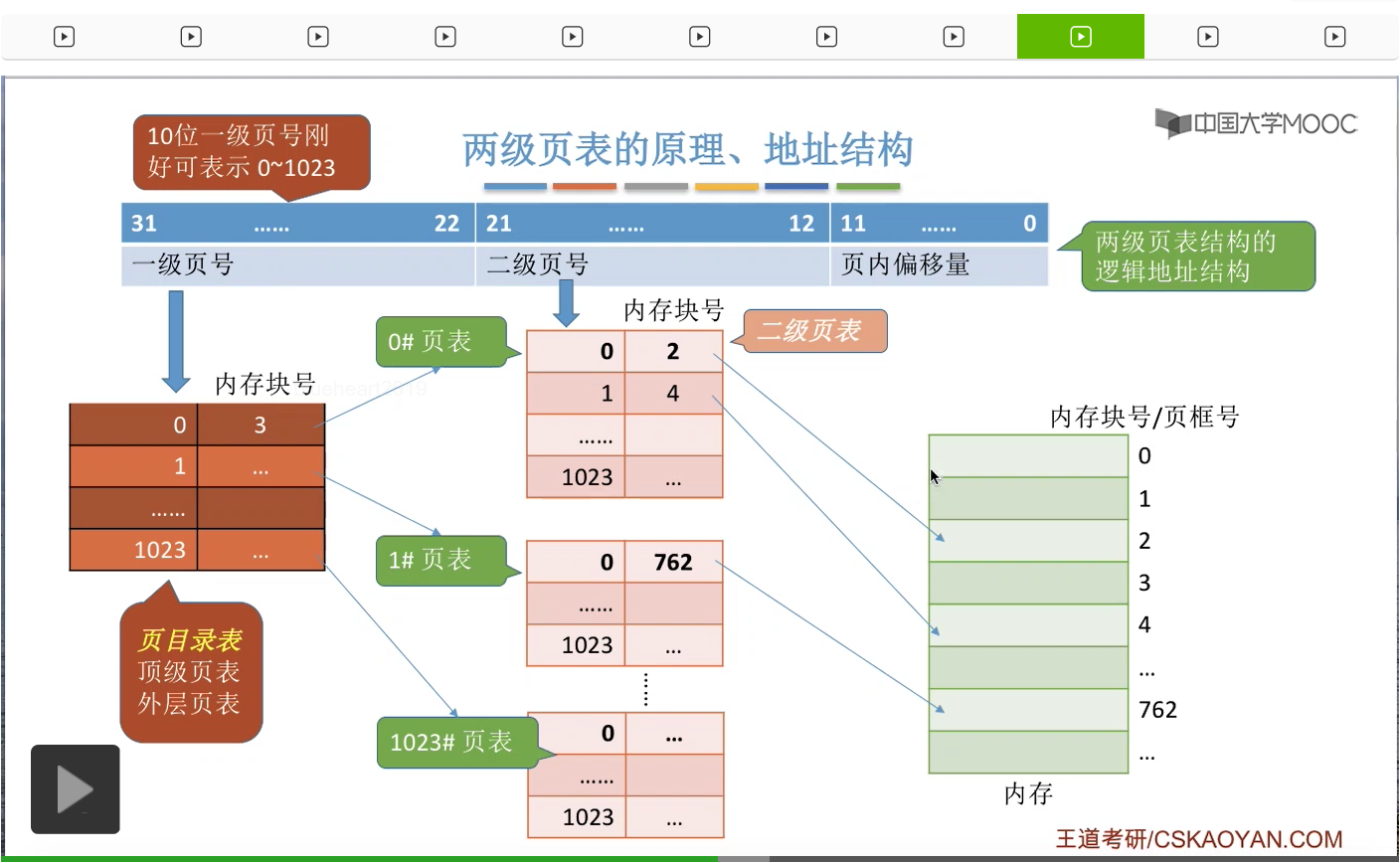
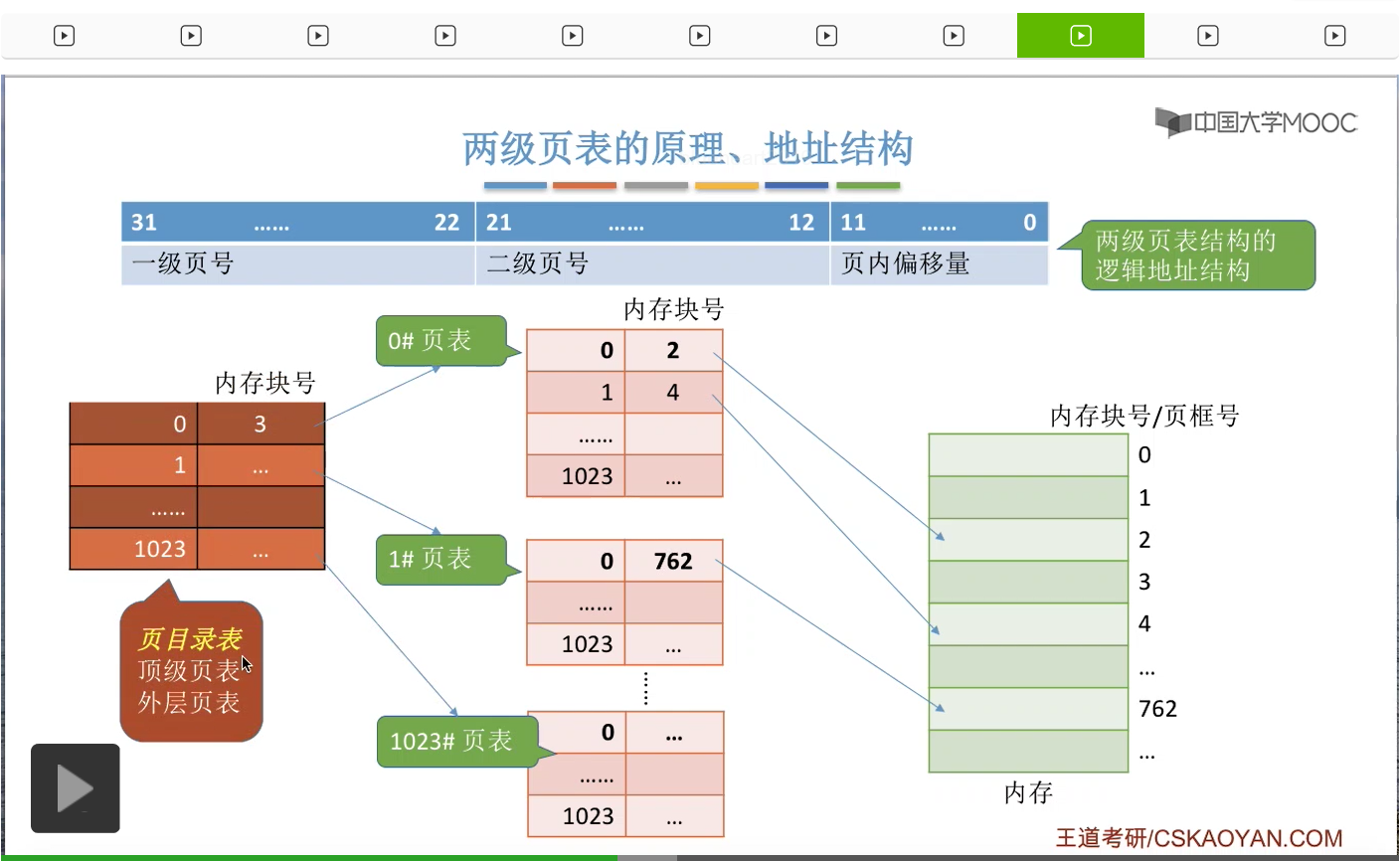
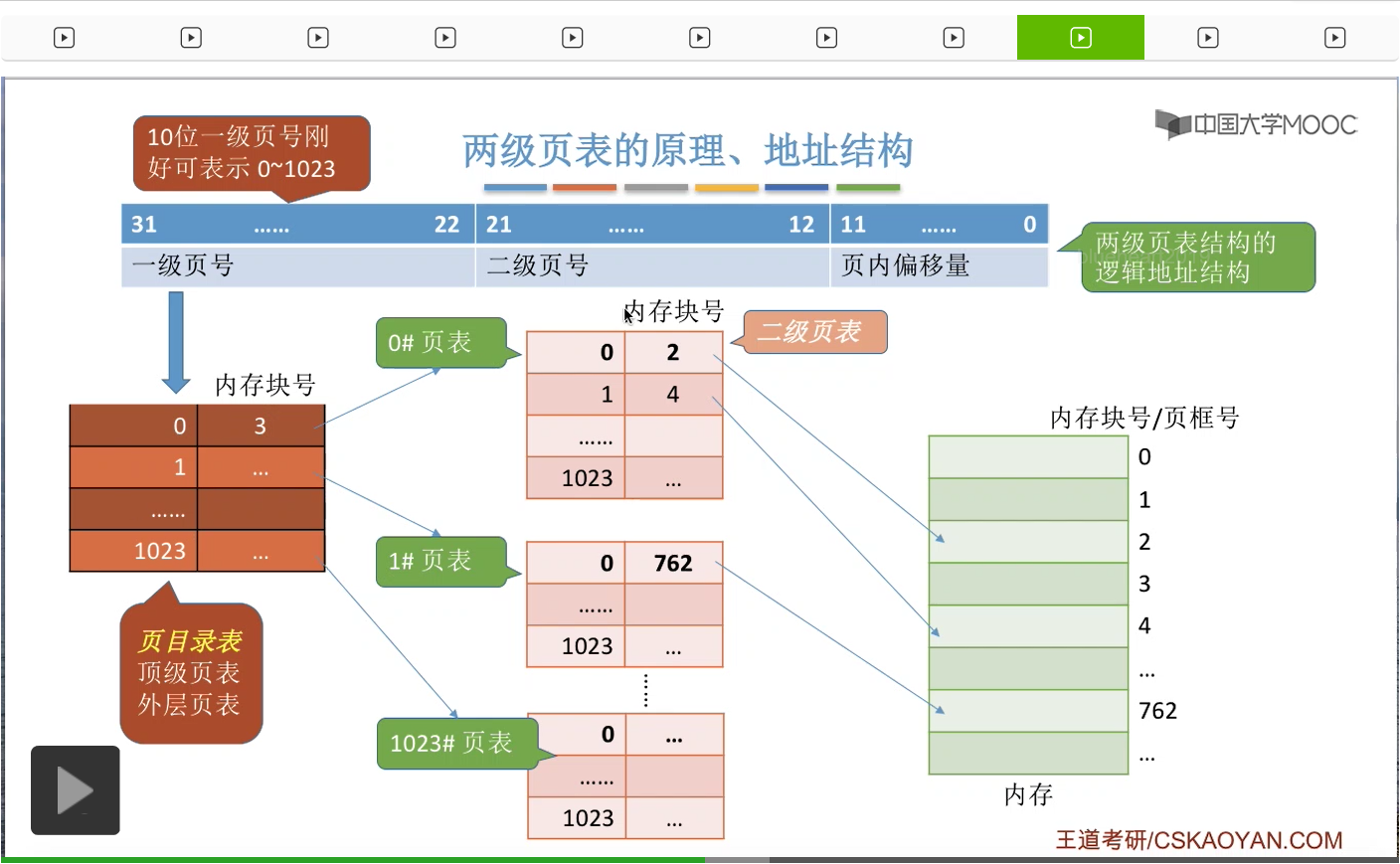
那接下来我们再结合这个例子来看一下我们应该怎么实现地址的变换?那么要进行这个地址变换,我们要做第一件事情就是根据我们的地址结构把逻辑地址拆分成三个部分,也就是一级页号,二级页号还有页内偏移量这么三个部分。那第二步,我们可以从PCB当中知道我们的页目录表在内存当中存放的位置到底是哪里。
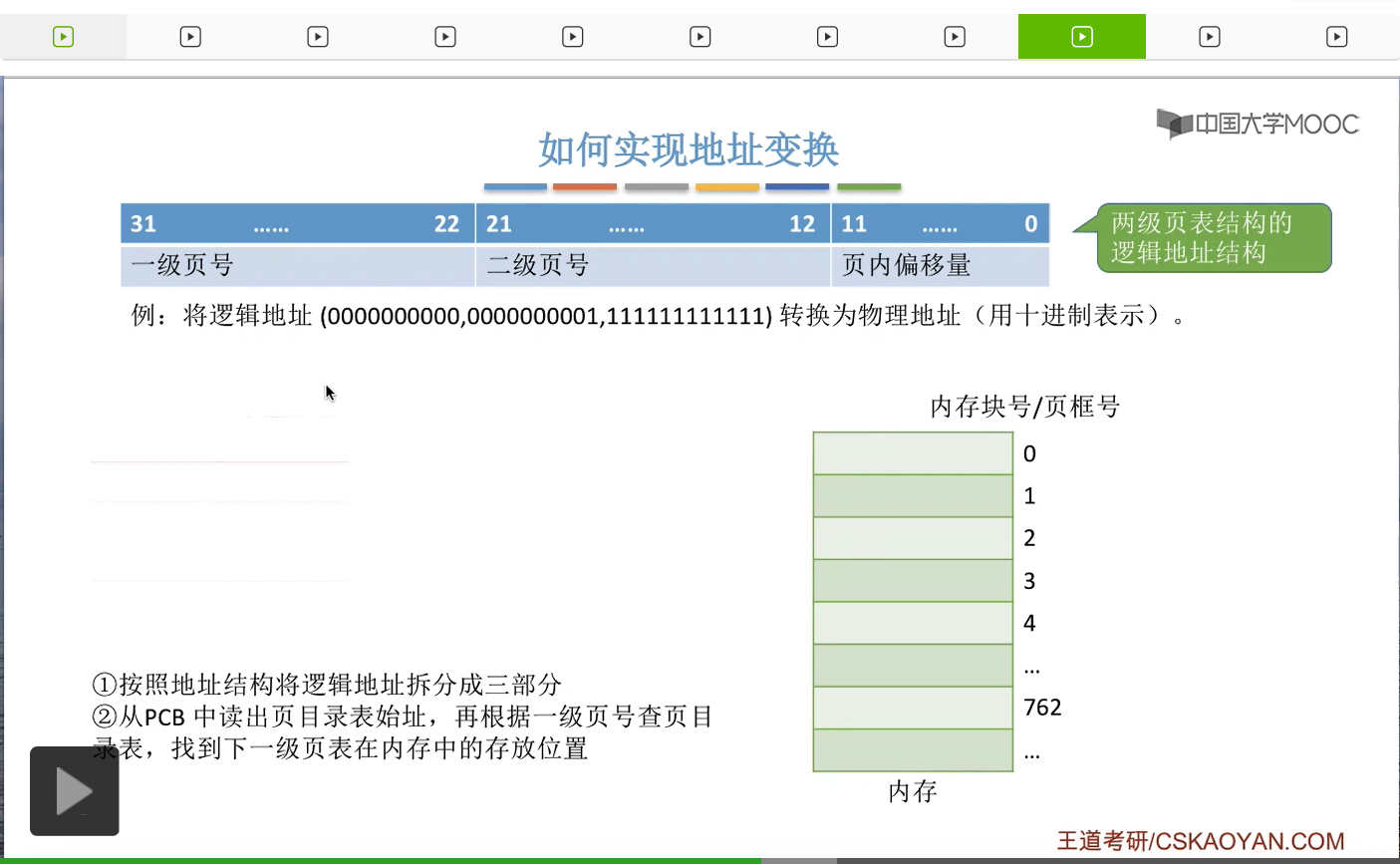
那这样的话我们就可以根据一级页号来查询页目录表了。那一级页号是0,所以我们查到的表项应该是这个表项。那从这个页表项当中我们可以知道,0号的二级页表存放在内存块号为3号的地方,也就是这个位置。
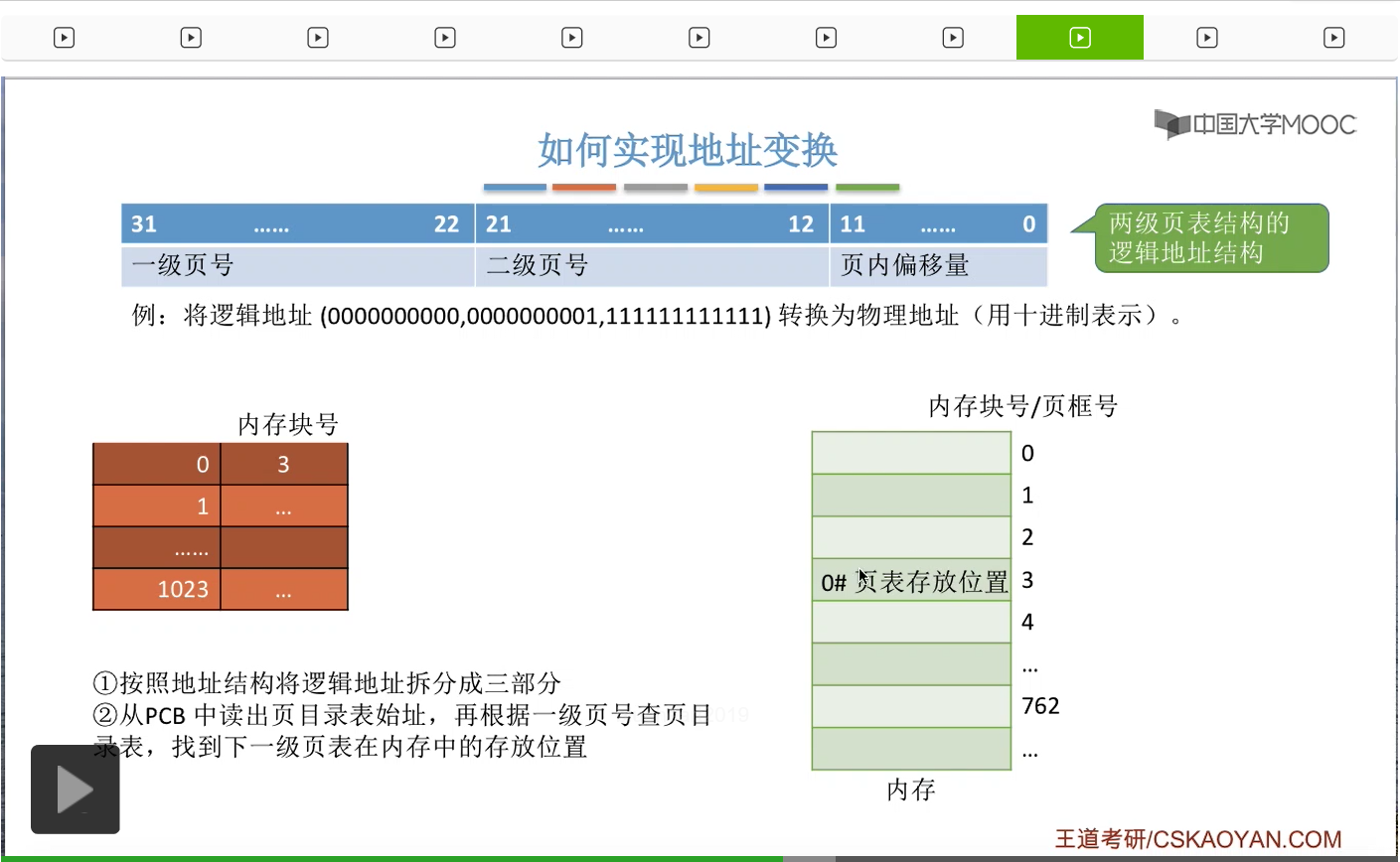
所以我们可以从这个位置读出二级的页表,然后开始用二级页号来再进行查询。那二级页号是1,所以我们查询到的页表项应该是这一项。那通过这个页表项我们就可以知道,最终我们想要访问的地址应该是在4号内存块里的。
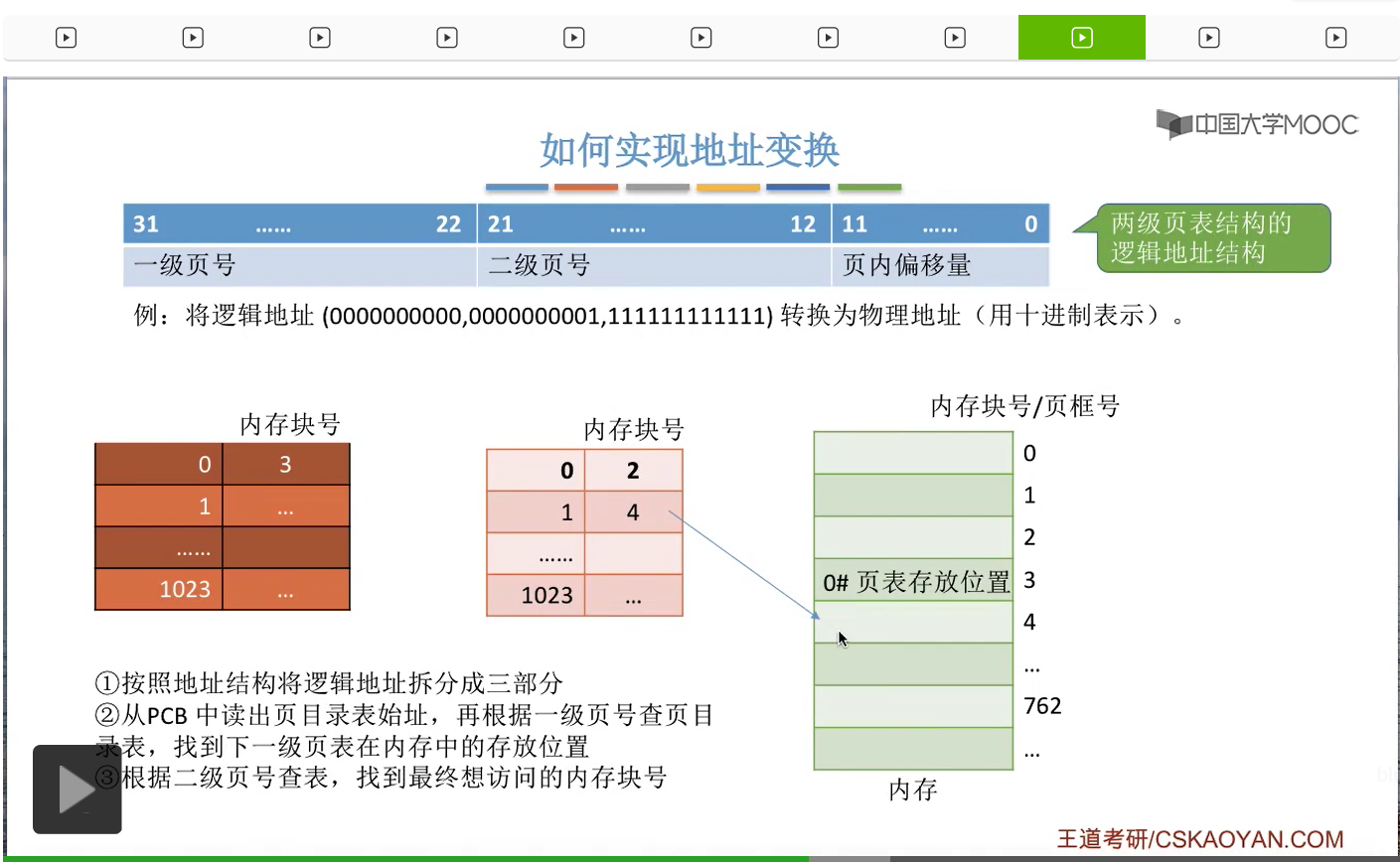
所以接下来我们就可以根据最终要访问的内存块号和页内偏移量得出我们最终的物理地址了。
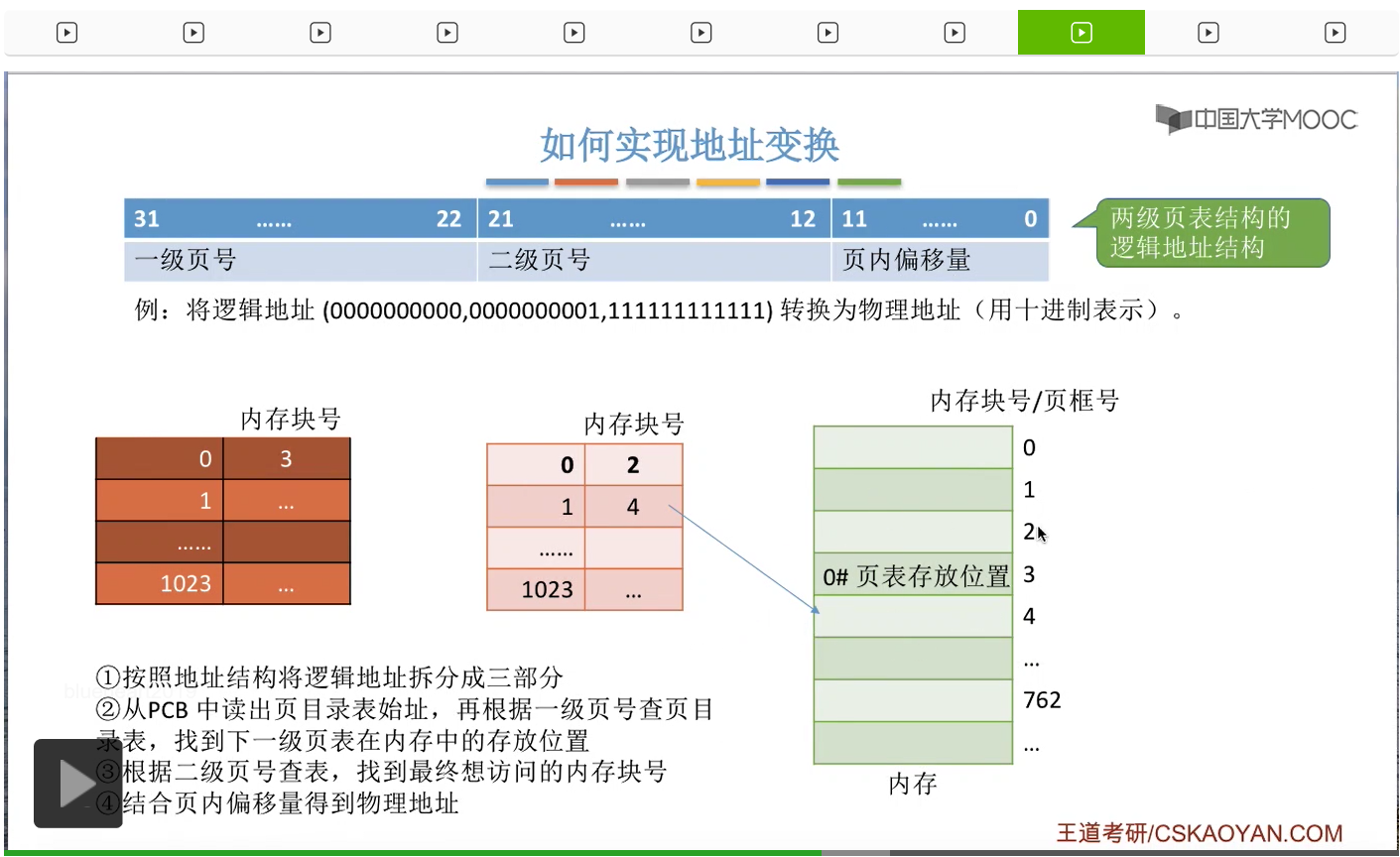
那由于我们想要访问的是4号内存块,并且每个内存块的大小是4KB,也就是4096个字节,所以4号内存块的起始地址应该是4*4096就等于16384。另外,页内偏移量把它转换为十进制之后,应该是1023。所以我们可以用内存块的起始地址再加上页内偏移量的这个数字就可以得到最终的物理地址,17407了。

那经过刚才的一系列分析我们就解决了我们之前提出的第一个问题。当页表很大的时候,其实我们可以采用两级页表的这种结构来解决这个页表必须连续地占用多个页框的问题。那接下来我们再来看一下第二个问题应该怎么解决。其实如果说不让整个页表常驻内存的话,那么我们可以在需要访问页面的时候才把页面调入内存。其实这是咱们之后会介绍的虚拟存储技术。这个在之后的小节当中会有更详细的介绍,这儿只是先简单地提一下它的思想。

那我们可以给每一个页表项增加一个标志位,用来表示这个页表项对应的页面到底有没有调入内存。

那如果说此时想要访问那个页面暂时还没有调入内存的话,那么就会产生一个缺页中断。然后操作系统负责把我们想要访问的那个目标页面从外存调入内存。那缺页中断肯定是我们在执行某一条指令,这个指令想要访问到某一个暂时还没有调入的页面的时候产生的,所以这个中断信号和当前执行的指令有关,因此这种中断应该是属于内中断。那这个部分的内容咱们在之后的小节当中还会有更详细的介绍。
那接下来我们再来强调几个在考试当中需要特别注意的小细节。第一个,如果我们采用的是多级页表机构的话,那么各级页表的大小不能超过一个页面。那这个限制的条件我们在做题的时候应该怎么应用呢?我们直接来看一个例子。那由于采用多级页表的时候,各级页表的大小不能超过一个页面,所以说各级页表当中页表项最多不能超过2^10个。那相应的,各级页号所占的位数也不能超过10位。所以28位的页号我们可以把它分成3个部分,一级页号占8位,二级页号10位,三级页号也占10位。那相应的,这样的话我们就需要再建立更高一级的页表,最终会形成三级页表的一个结构。那三级页表的原理,和两级页表的原理其实是一模一样的,这个地方就不再展开赘述。那这个地方假如说我们只是采用了两级页表的结构的话,那么第一级的页号就会占18位,也就是说在页目录表中,最多有可能会有2^18个页表项。那这么多的页表项,显然是不能放在一个页面里的,所以这就违背了采用多级页表的时候,各级页表的大小不能超过一个页面这样的一个条件,因此,如果我们只把它分成两级是不够的。那这就是我们需要注意的第一个细节,这个很有可能作为考点在选择题甚至是结合大题来进行考查。

那第二个我们需要注意的点是,两级页表的访存次数的分析。假设我们没有采用快表机制的话,那么第一次访存应该是访问内存当中的页目录表,也就是顶级页表。第二次访存应该是访问内存当中的二级页表。第三次访存才是访问最终的目标内存单元。所以采用两级页表结构的话,我们要访问一个逻辑地址需要进行三次访存。那还记得我们分析的单级页表的访存次数问题吗?如果采用的是单级页表结构的话,那么第一次访存就是查询页表,第二次访存就是访问我们最终想要访问的内存单元。所以单级页表在访问一个逻辑地址的时候,只需要进行两次访存。因此,两级页表虽然解决了我们之前提出的单级页表的那两大问题,但是这种内存空间的利用率的上升,付出的代价就是,逻辑地址变换的时候,需要进行更多一次的访存,这样的话就会导致我们要访问某一个逻辑地址的时候,需要花费更长的时间,所以这是两级页表相比于单级页表来说的一个很明显的缺点。那如果我们继续分析三级页表、四级页表结构当中的访存次数的话,会发现三级页表访问一个逻辑地址需要访存四次,四级页表需要访存五次,五级页表需要访存六次。所以其实是有一个规律,如果没有快表机构的话,那么N级页表在访问一个逻辑地址的时候,访存次数应该是N+1次。那这就是我们需要注意的两个很重要的小细节。

好的那么这个小节当中我们介绍了两级页表相关的知识点。我们从单级页表存在的两个问题出发,来依次探讨了这两个问题应该怎么解决。特别是第一个。那采用了两级页表结构之后,我们就可以解决第一个问题。但第二个问题的解决需要采用虚拟存储技术,这个咱们会在之后的小节进行更详细的讲解。那在本节当中,我们需要重点理解两级页表的逻辑地址结构。还需要注意页目录表、外层页表、顶级页表这几个说法,不过在408当中,最常用的是页目录表这个术语。另外,大家也需要理解采用了两级页表之后,如何实现逻辑地址到物理地址的转换。那这个转换过程其实和咱们之前介绍的单级页表并没有太大的差异,无非就是还需要多查一级的页表而已。那这个过程需要能够自己分析。那最后,我们强调了两个我们需要注意的小细节,第一个小细节,多级页表当中,各级页表的大小不能超过一个页面。所以说,如果两级页表不够的话,那么我们可以进行更多的分级。第二个小细节,我们要需要自己能够分析多级页表的访存次数,那N级页表访问一个逻辑地址是需要N+1次访存的。
那另外,大家还需要能够根据题目给出的逻辑地址位数,页面大小,页表项大小这几个条件来确定多级页表的逻辑地址结构。那这些内容还需要大家结合课后习题来进行巩固和消化。
在这个小节中我们会学习另一种离散分配的存储管理方方式,叫基本分段存储管理。

那这种管理方式,和咱们之前学习的分页存储最大的区别其实就是,离散分配的时候,所分配的地址空间的基本单位是不同的。那这个小节中,我们会首先介绍什么是分段。那分段的这个概念、思想其实有点类似于我们分页存储管理当中的分页。而之后我们会介绍什么是段表。段表就有点类似于分页存储管理当中的页表。另外,在离散分配存储管理方式当中,咱们避免不了一定要谈的问题是怎么实现地址变换。最后,我们会对分段和分页这两种管理方式进行一个对比。那我们会按照从上至下的顺序依次讲解。
那首先来看一下什么是分段。每一个段就代表一个完整的逻辑模块。比如说0号段的段名叫MAIN,然后0号段存放的就是main函数相关的一些东西。然后1号段存放的是某一个子函数。2号段存放的是进程A当中某些局部变量的这些信息。那可以看到,每一个段都会有一个段名。这个段名是程序员在编程的时候使用的。另外呢,每个段的地址都是从0开始编址的。所以,进程A本来是有16KB的地址空间。那分段之后,第一个段,0号段,它的地址空间就是0-7KB-1,总共的大小就是7KB。然后1号段是0-3K-1,总共的大小是3KB,2号段也一样。那操作系统在为用户进程分配内存空间的时候,是以段为单位进行分配的。每个段在内存当中会占据一些连续的内存空间,并且各段之间可以不相邻。比如说0号段占据的是从80K这个地址开始的连续的4KB的内存空间,而1号段占据的是从120K这个地址开始连续的3KB的地址空间。那由于分段存储管理当中,是按照逻辑功能来划分各个段的,所以用户编程会更加方便,并且程序的可读性会更高。比如说用户可以用低级语言、汇编语言写这样两条指令。那第一条指令是把分段D当中的A单元内的值读到寄存器1当中。第二个指令是把寄存器1当中的内容存到X分段当中的B单元当中。那由于各个分段是按逻辑功能模块来划分的,并且这些段名也是用户自己定义的,所以用户在读这个程序的时候就知道这两句代码做的事情,就是把某个全局变量的值赋给X这个子函数当中的某一个变量。因此对于用户来说采用了分段机制之后,程序的可读性还是很高的。那在用户编程的时候,使用的是段名来操作各个段。但是在CPU具体执行的时候,其实使用的是段号这个参数,
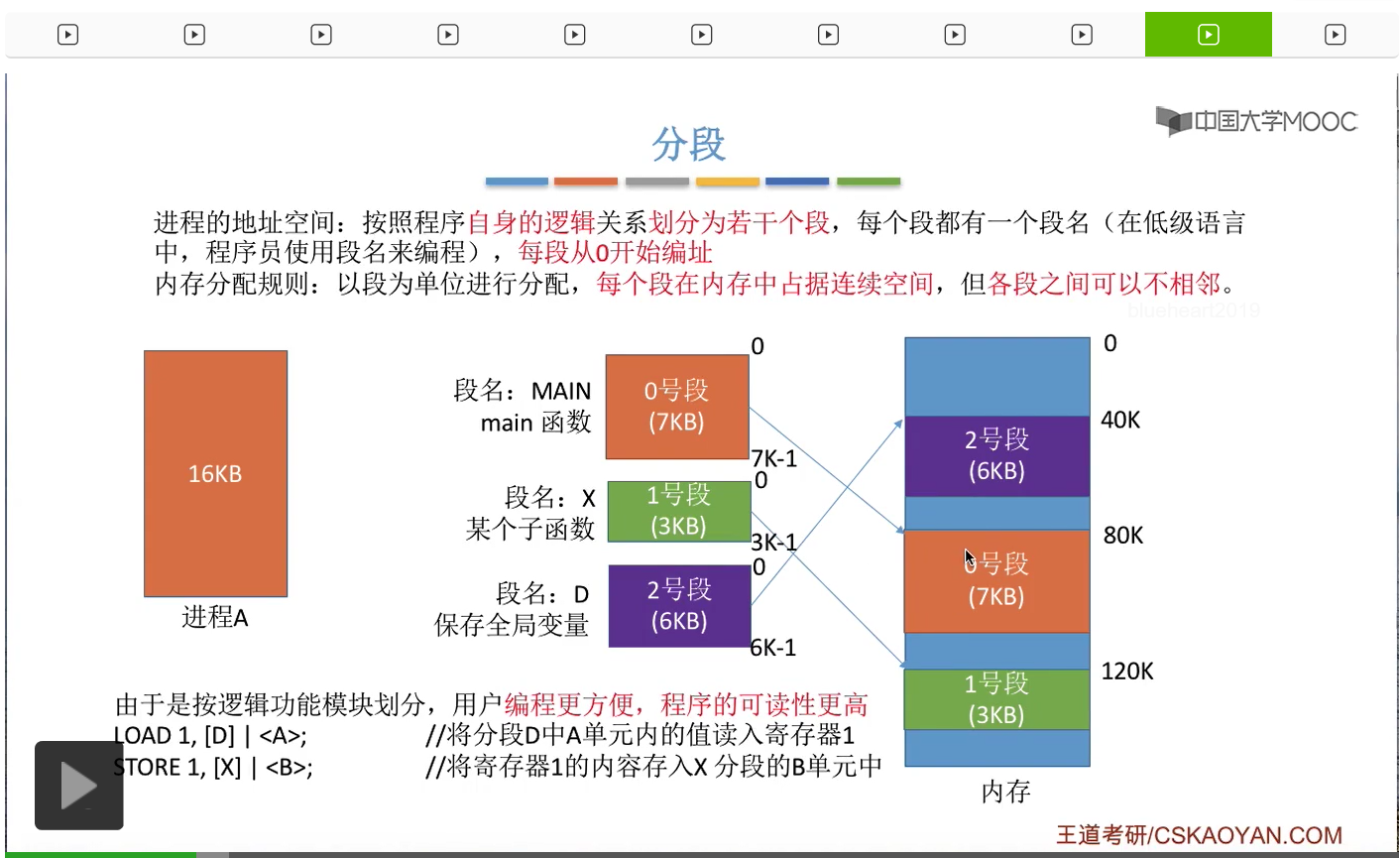 所以在编译程序其实会把这些段名转换成与它们各自相对应的这些一个一个段号,然后CPU在执行这些指令的时候,是根据段号来区分各个段的。
所以在编译程序其实会把这些段名转换成与它们各自相对应的这些一个一个段号,然后CPU在执行这些指令的时候,是根据段号来区分各个段的。
那在采用了分段机制之后,逻辑地址结构就变成了这个样子。由段号和段内地址(或者叫段内偏移量)组成。比如说像这个例子当中,段内地址是占了0-15总共16位,然后段号是16-31,总共占的也是16位。那在考试当中我们需要注意的一个很高频的考点就是,段号的位数决定了每个进程最多可以分多少个段。而段内地址的位数决定了每个段的最大长度是多少。那我们以这个例子为例来看一下16位的段号和16位的段内地址,最大可以支持几个分段,每个段的最大长度又是多少。那我们假设这个系统是按字节编址的,也就是说一个地址对应的是一个字节的大小。那段号占16位,所以在这个系统当中,每个进程最多可以有2^16个段,也就是64K个段。因为16位的二进制数,最多也就能用来表示这样一个范围的数字。那同样的,段内地址也是占16位,并且这个系统是按字节编址的,所以每个段的最大长度应该是2的16次方也就是64KB这样的一个大小。那刚才我们提到的这两句用汇编语言写的指令,

在经过编译程序编译之后,段名会被编译程序翻译成对应的段号。而这里提到的A单元、B单元这样的助记符,会被编译程序翻译成段内地址,也就是这个第二个部分。就像这个样子,每个段名会被翻译成与它们对应的各个段号,另外,各个段之间的这些用助记符表示的内存单元,会被最终翻译为这个段当中的段内地址。那这就是分段相关的一些最基本的概念。

那接下来我们再来看下一个问题。既然我们的程序被分为了多个段,并且各个段是离散地存储在内存当中的。

为了保证程序能够正常地运行,所以操作系统必须能够保证要能从物理内存当中找到各个逻辑段存放的位置。因此,为了记录各个段的存放位置,
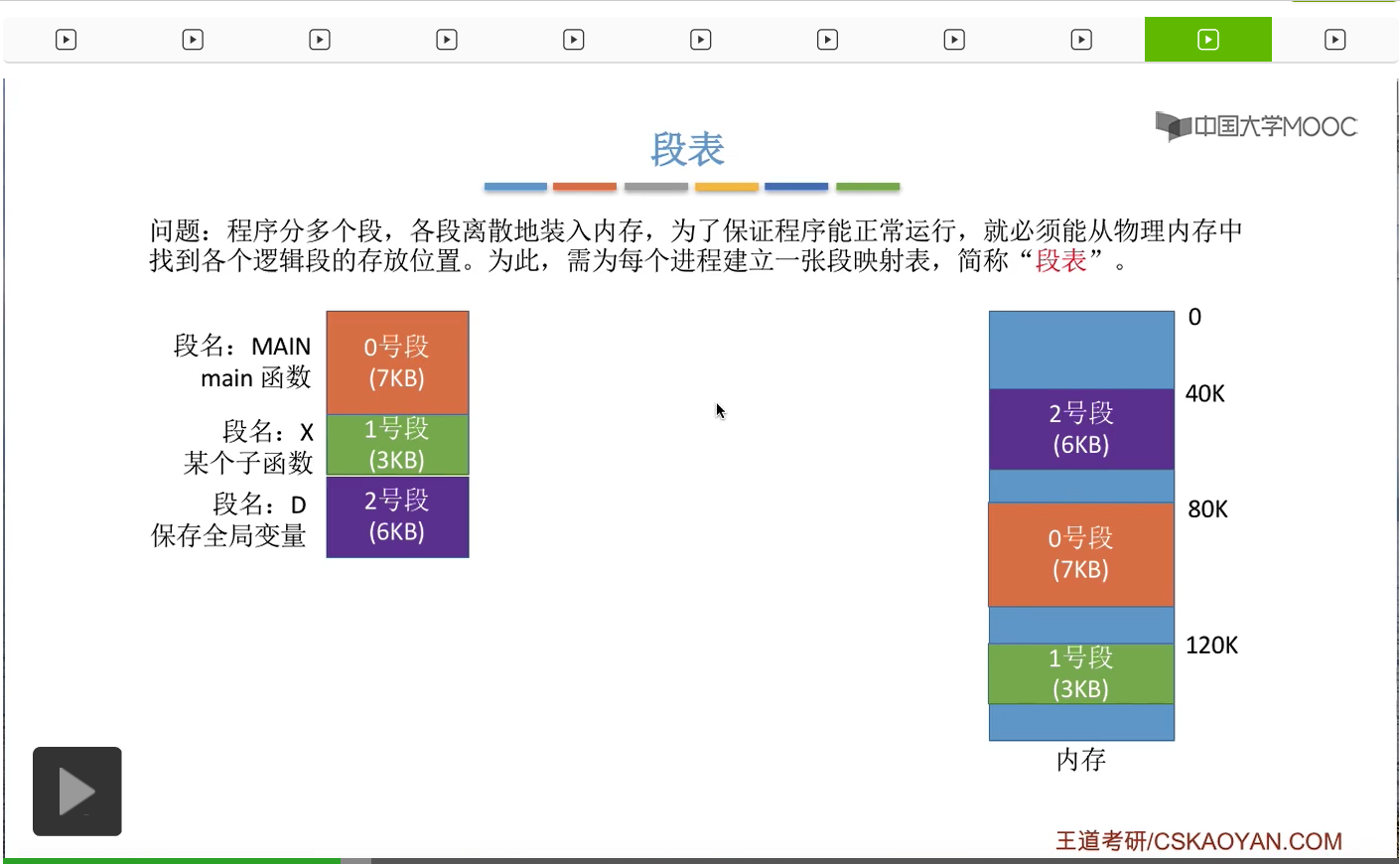
操作系统会建立一张段映射表,简称“段表”,就像这个样子。

那用段表记录了各个逻辑段在内存当中的存放的位置。那这个地方大家会发现,段表的作用其实和咱们之前学习的页表的作用是比较类似的。页表是建立了各个逻辑页面到实际的物理页框之间的映射关系,而段表是记录了各个逻辑段到实际的物理内存存放位置之间的映射关系。那每个段表由段号、段长和段基址组成。这个段基址其实就是段在内存当中的存放的起始位置,那从这个图当中我们也能很直观地看到,每个段会对应一个段表项。那相比于页表来说,段表当中多了一个更不同的信息就是段长,因为每个分段的长度可能是不一样的。而我们在分页存储管理当中,每个页面的长度肯定都是一样的。所以在分页内存管理当中,页长是不需要这样显式地记录的。但是在分段存储管理当中,段的长度是需要这样显式地记录在段表当中。

那第二点我们需要注意的是,我们的各个段表项的长度其实是相同的。也就是说,这些一行一行的段表项,在内存当中所占的空间,是大小是相同的。比如说,这个系统按照字节寻址,并且采用分段存储管理方式。逻辑地址结构,段内地址是16位,段的长度不可能超过2的16次方字节。所以在各个段表项当中,用16位就肯定可以表示这个段的最大段长了。那假设这个系统的物理内存大小是4GB,那也就是2的32次方个字节。那这么大的物理内存的地址空间,可以用32位的二进制来表示,所以对于基址,也就是内存的某一个地址这个数据,我们只需要用32个二进制位就可以表示了。因此每个段的段表项,其实只需要16+32位也就是48位总共6个字节就可以表示一个段表项。因此在这个系统当中,操作系统可以规定每一个段表项的长度就是固定的6个字节。前两个字节表示的是段长,而后面四个字节表示的是这个段存放的在内存当中的起始地址。
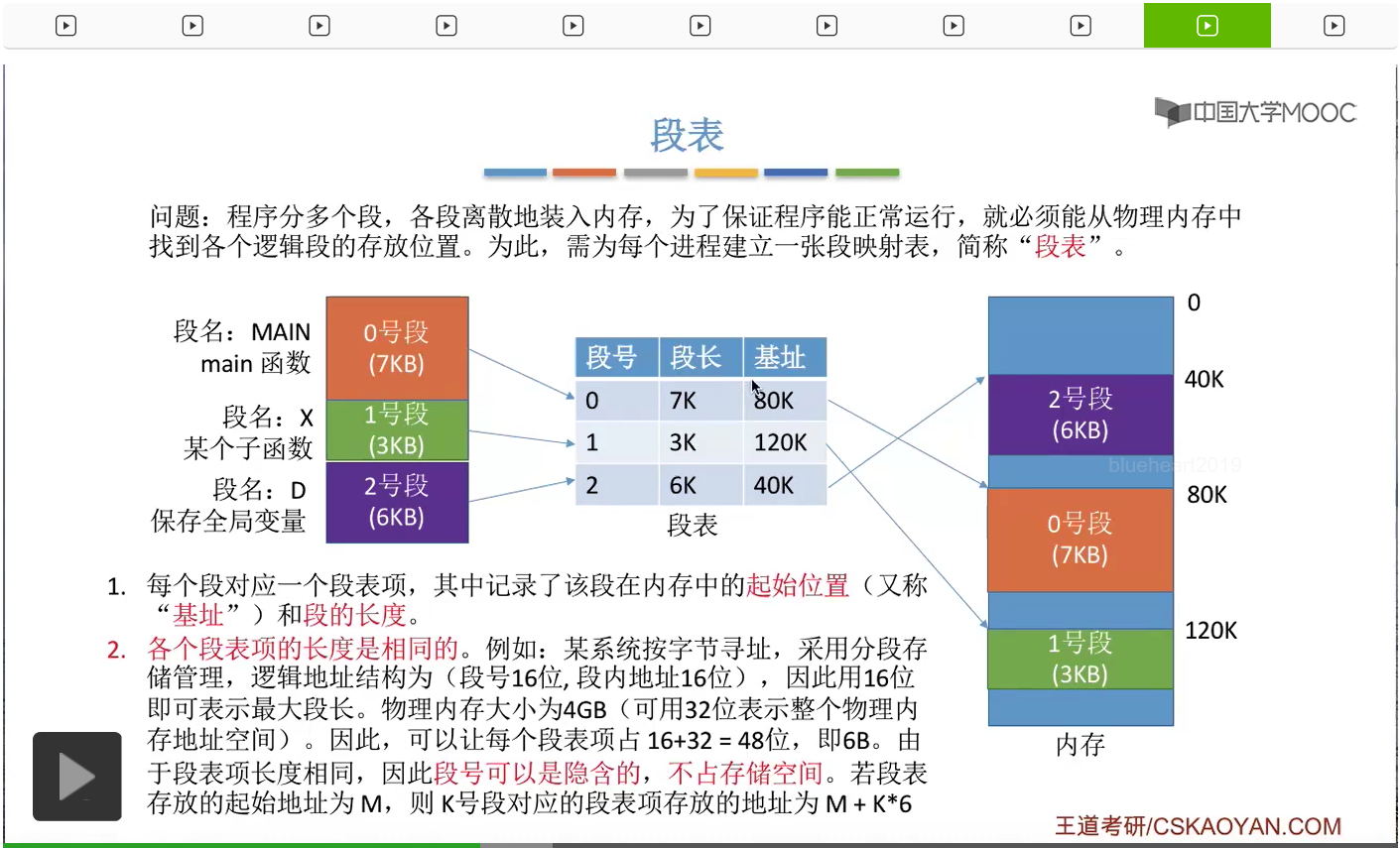
所以和页表类似,这个地方的页号可以是隐含的,页号并不占存储空间。那我们在查询段表的时候,只要我们能够知道段表在内存当中的起始地址M,那我们想要查询K号段对应的段表项,那我们只需要用段表的起始地址M,再加上K乘以每个段表项的大小6个字节,那就可以得到我们想要找到的那个段对应的段表项在内存当中的什么位置了。所以即使这个段号是隐含的,没有显式地给出。但是我们依然可以根据段号来查询这个段表。
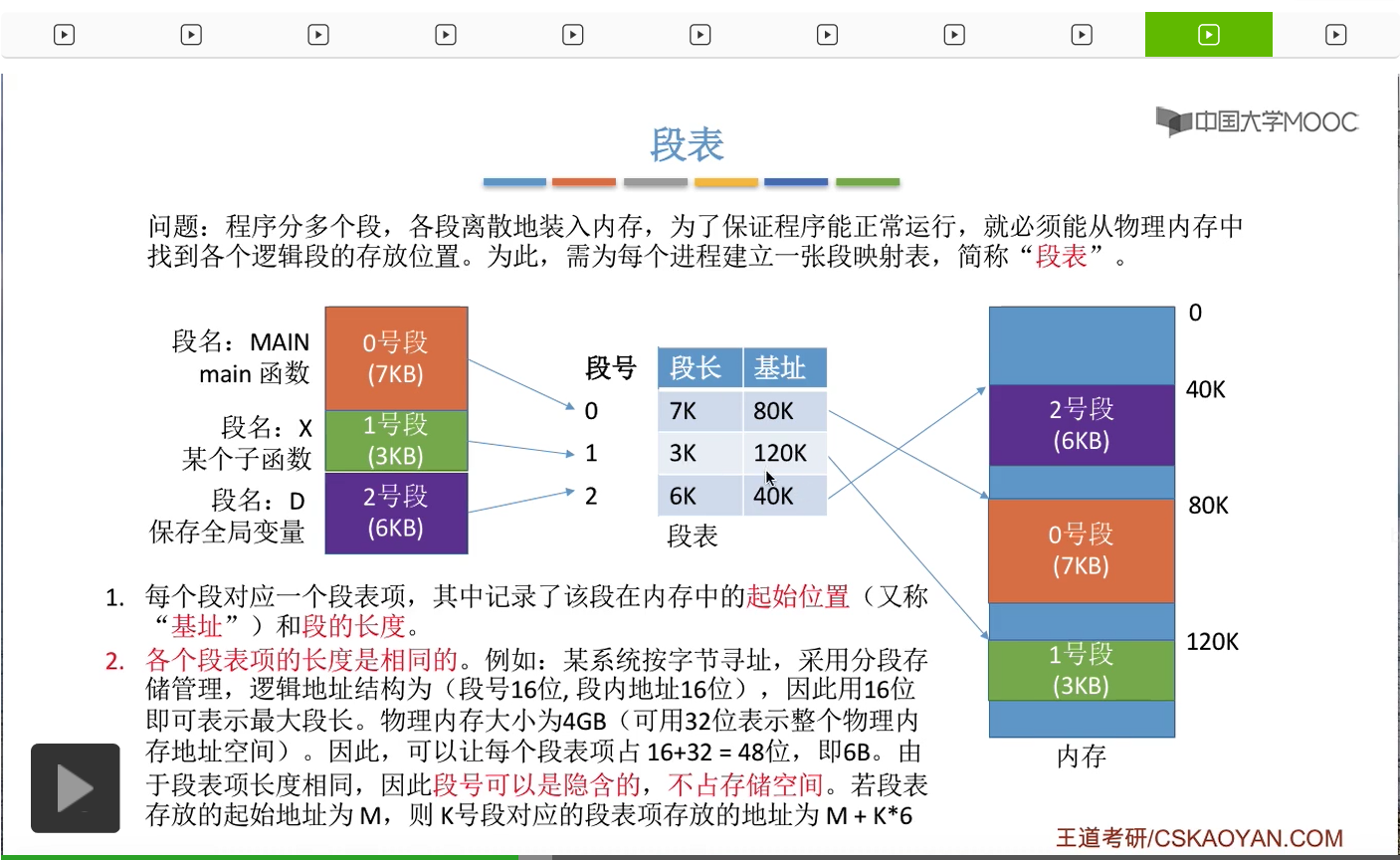
那接下来我们再来看一下采用了分段存储管理之后,地址变换的过程是什么样的。那还是以刚才提到的这个指令为例,这个用汇编语言写的指令经过编译程序编译之后,会形成一条等价的机器指令。比如说这条机器指令就是告诉CPU,从段号为2,段内地址为1024的这个内存单元当中取出内容,放到寄存器1当中。不过在计算机硬件看来,段号、段内地址这些逻辑地址其实是用二进制表示,比如说是这个样子。那前面的红色的这16位表示的是段号,而后面的黑色的这16位表示的是段内地址。所以CPU在执行指令的时候,或者说在访问某一个逻辑地址的时候,需要把这个逻辑地址变换为物理地址。
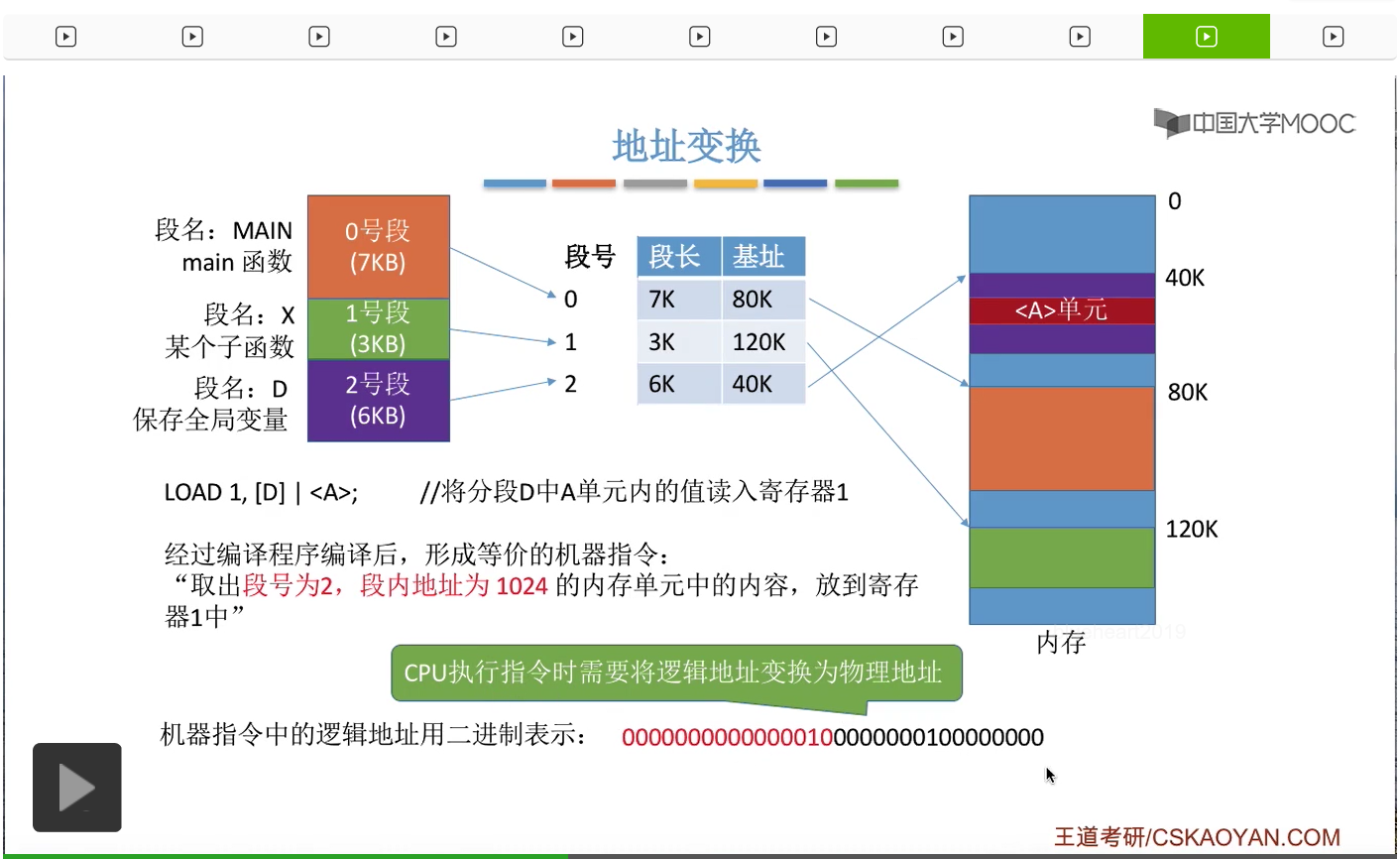
那我们看一下具体的变换过程。在内存的系统区当中,存放着很多用于管理系统当中的软硬件资源的数据结构,包括进程控制块PCB也是存放在系统当中的。那当一个进程要上处理机运行之前,进程切换相关的那些内核程序会把进程的运行环境给恢复,那这就包括一个很重要的硬件寄存器当中的数据的恢复。这个寄存器叫做段表寄存器,用于存放这个进程对应的段表在内存当中的起始地址还有这个进程的段表长度到底是多少。因此段表存放的位置还有段表长度这两个信息在进程没有上处理机运行的时候是存放在进程的PCB当中的。那当进程上处理机运行的时候,这两个信息会被放到很快的段表寄存器当中。那当知道了段表的起始地址之后,就可以知道段表是存放在内存当中的什么地方。
那接下来这个进程的运行过程当中,避免不了要访问一些逻辑地址。

比如说要访问逻辑地址A。那么系统会根据逻辑地址得到段号S和段内地址W,这是第一步要做的事。第二步,知道了段号之后,需要用段号和段表长度进行一个对比来判断一下段号是否产生了越界。如果段号大于等于段表长度的话,就会产生越界中断。那么接下来就会由中断处理程序来负责处理这个中断。如果没有产生中断的话,就会继续执行下去。这个地方稍微注意一下,段号是从0开始的,段表长度至少是1,所以当S=M的时候,其实也是会产生越界中断的。那在确定这个段号是合法的没有越界之后,就会根据段号还有段表始址来查询段表,找到这个段号对应的段表项。那之前咱们提过,由于各个段表项的大小是相同的,所以用段表始址+段号*段表项的长度就可以找到我们要找的目标段对应的段表项在内存中的位置了,那接下来就可以读出这个段表项的内容。第四步,在找到了这个段号对应的段表项之后,系统还会对这个逻辑地址当中的段内地址W进行一个检查,看看它是否已经超过了这个段的最大段长,那如果段内地址大于等于这个段的段长的话,就会产生一个越界中断,否则继续执行。那这一步也是和我们页式管理当中区别最大的一个步骤。因为在页式管理当中,每个页面的页长肯定是一样的,所以系统并不需要检查页内偏移量是否超过了页面的长度。但是在分段存储管理方式当中又不同,各个段的长度不一样,所以一定需要对段内地址进行一个越界的检查,所以这一步是需要着重注意的。那我们继续往下,因为我们此时已经找到了目标段的段表项,
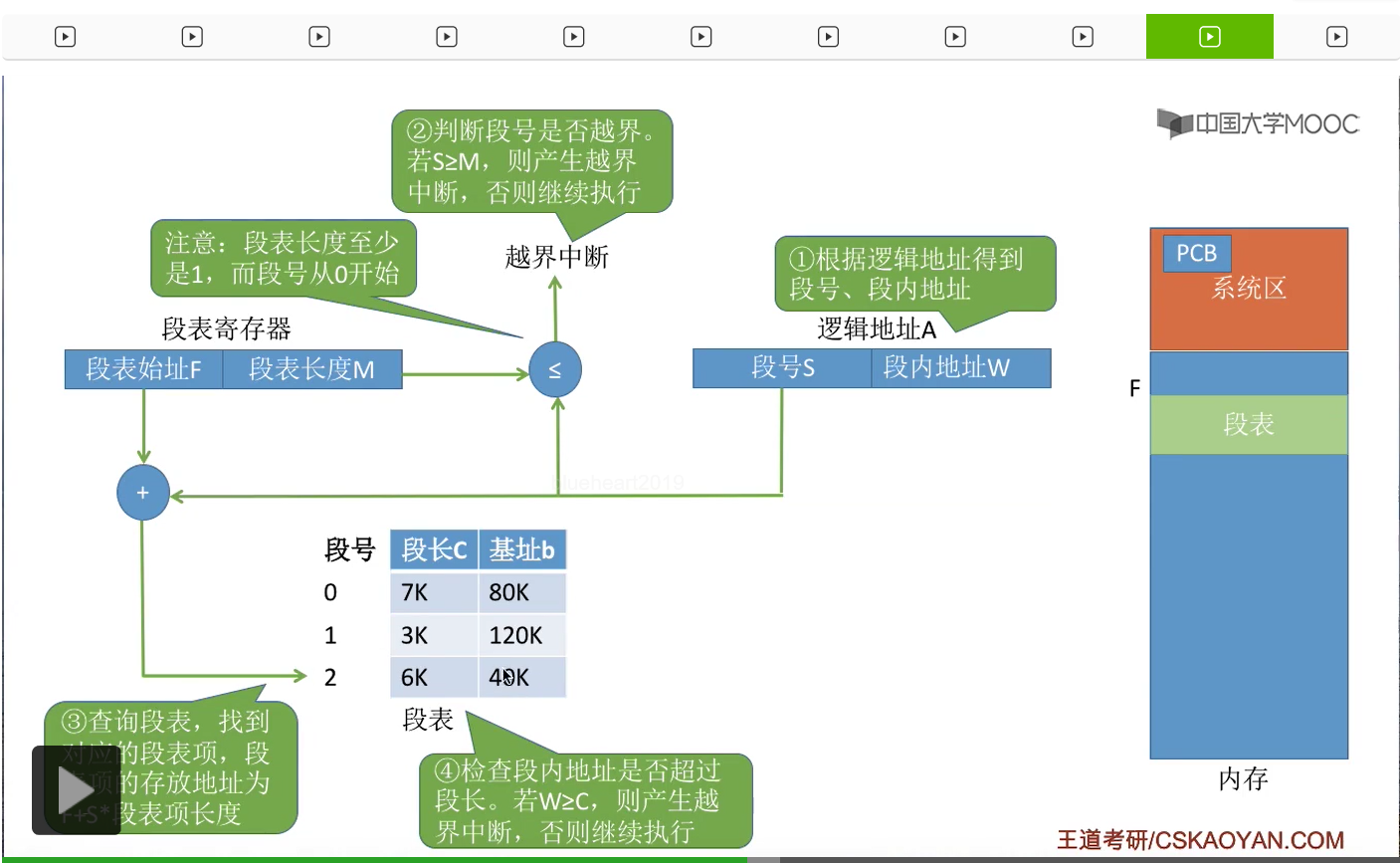
所以我们就知道目标段存放在内存当中的什么地方。那最后我们根据这个段的基址,也就是这个段在内存当中的起始地址,再加上这个最终要访问的段内地址就可以得到我们最终想要的物理地址了。
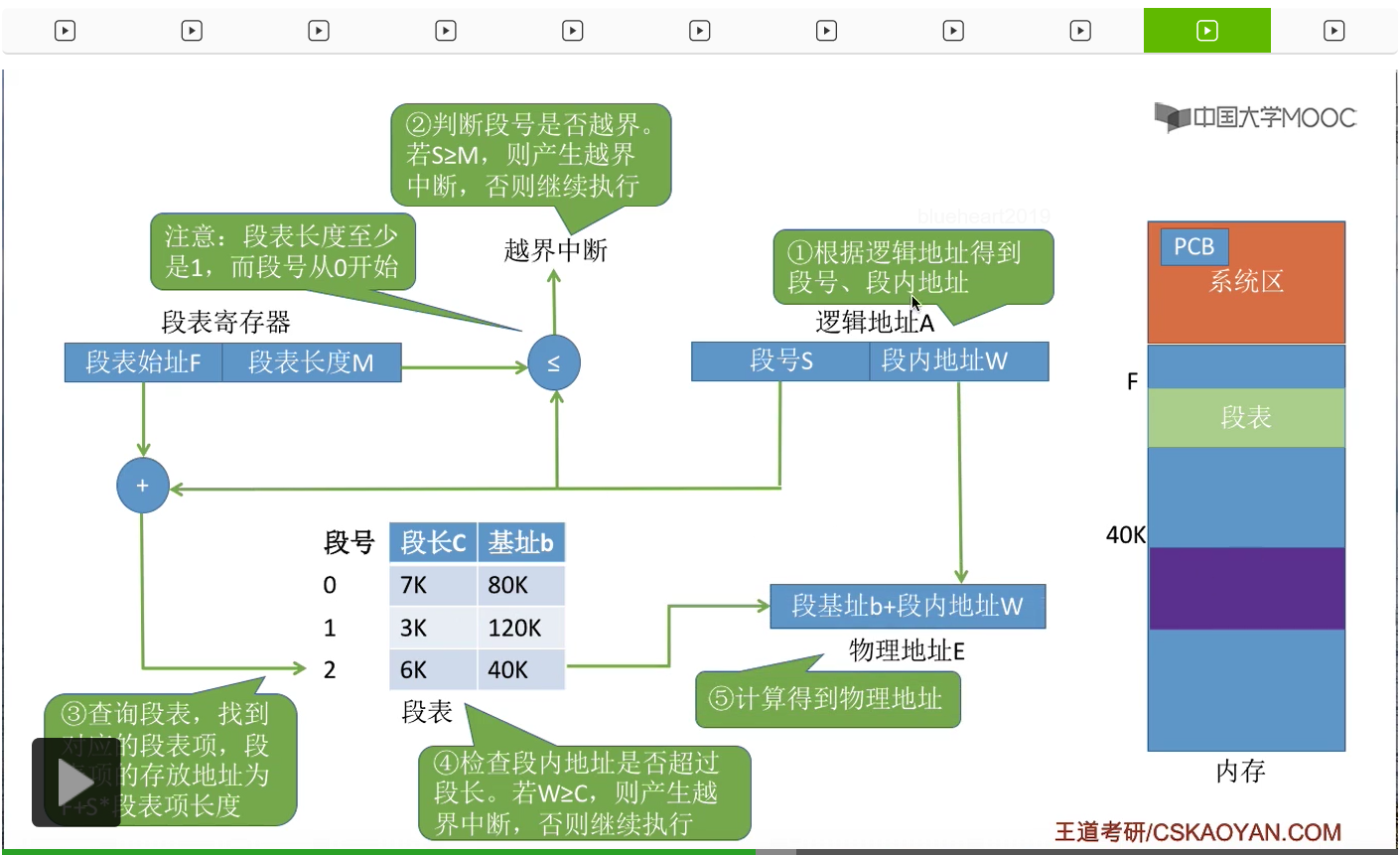
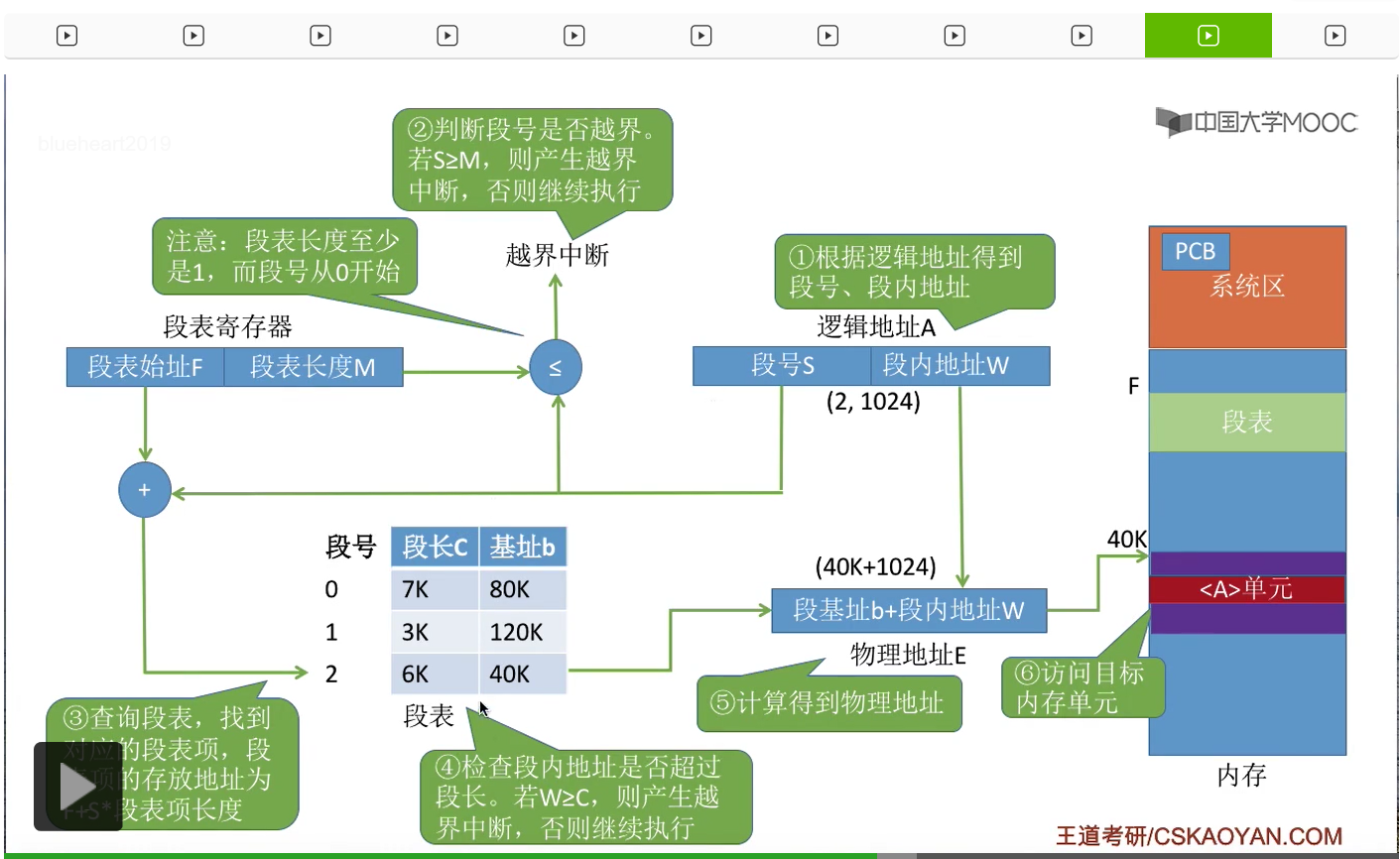
那我们以之前提到的这个逻辑地址为例,进行一次完整的分析。如果说此时要访问的逻辑地址的段号是2,然后段内地址是1024的话,那首先需要用段号2和段表长度M进行一个检查,那显然此时这个进程的段表长度应该是3,因为它有3个段,所以段号是小于段表长度的,因此段号合法,所以就可以进行下一步,用段号和段表始址查到这个段号对应的段表项,那这样的话就找到了2号段对应的段表项。那接下来需要对段内地址的合法性进行一个检查。段内地址和段长进行对比,发现2号段的段长是6K,而段内地址是1024,也就是1K,所以段内地址是小于段长的,因此在这个地方并不会产生越界中断,可以继续进行下去。那接下来通过这个段表项我们知道了这个段在内存当中存放的起始地址是40K,所以用这个段的起始地址40K再加上段内地址W也就是1024,那这样的话我们就得到了最终想要访问的目标内存单元,也就是A那个变量存放的位置,那这样的话就完成了对这个逻辑地址的一个访问。那分段存储管理当中的这个地址变换的过程,需要和分页存储管理的过程进行一个对比记忆。那其实大家着重需要关注的是,分段和分页最大的区别就在于,在分页当中,每个页面的长度是相同的,而分段当中每个段的长度是不同的,所以在分页管理当中,并不需要对页内偏移量(页内地址)进行越界的检查。但是在分段管理当中,我们一定需要对段内地址也就是段内偏移量和段长进行一个对比检查,那这就是分段和分页这两种存储管理方式当中进行地址变换过程时候最大的一个区别。
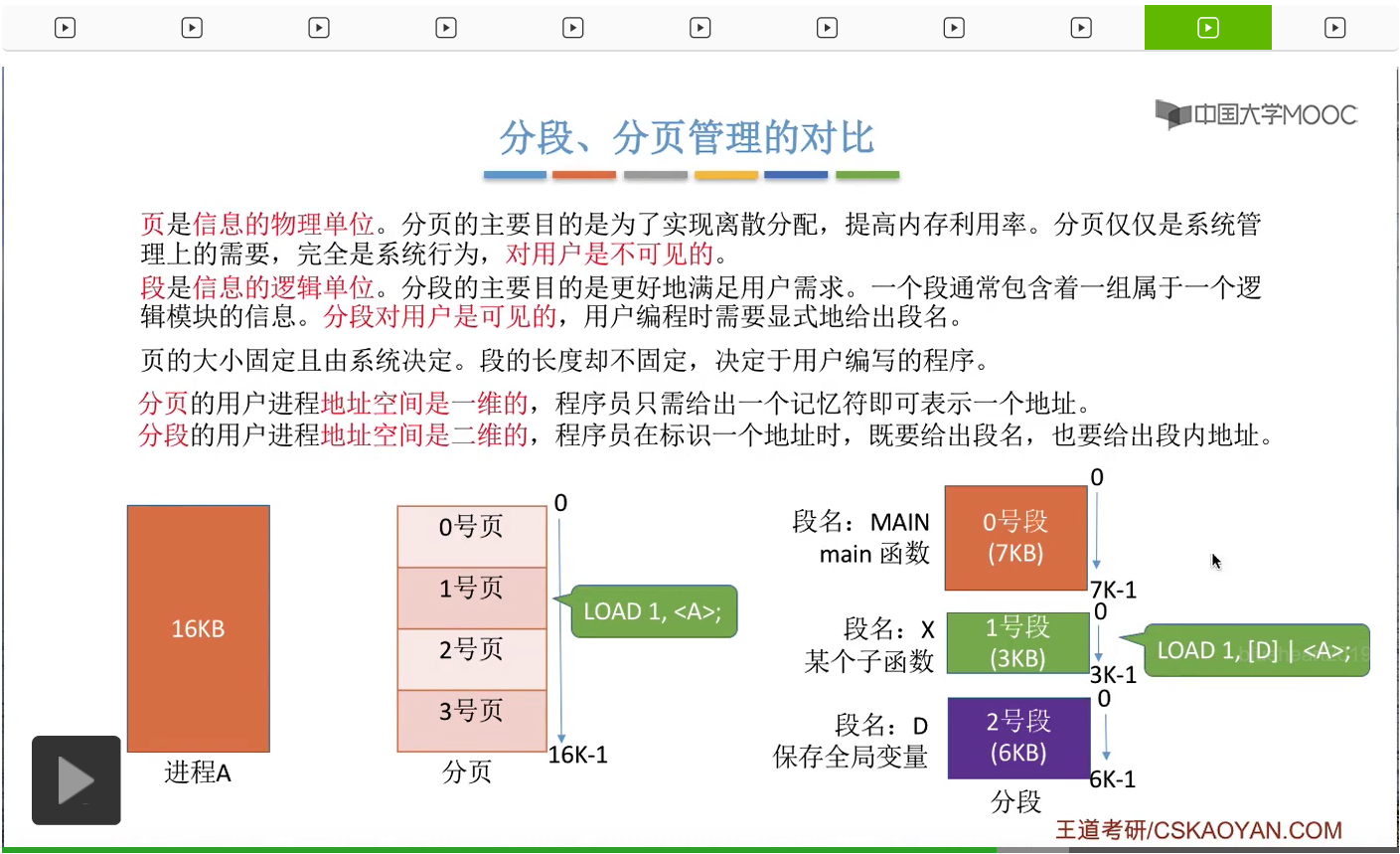
那接下来我们再把分段和分页这两种管理方式进行一个统一的对比。在分页的时候只考虑各个信息页面的物理大小,比如说每个页面是4KB。但是在分段的时候必须考虑到信息的这些逻辑关系,比如说某一个具有完整逻辑功能的模块,单独地划分成一个段。那另外,分段的主要目的是为了实现离散分配,提高内存利用率。但是分段的主要目的是为了更好地满足用户需求,方便用户编程。所以分页其实仅仅只是系统管理上的需要,它只是一个系统行为,对用户是不可见的。也就是说,用户是并不知道自己的进程到底是分为了几个页面,甚至不知道自己的进程是不是被分页了,但相比之下分段对于用户是可见的,用户在编程的时候就需要显式地给出段名。所以用户其实是知道自己的程序会被分段,甚至知道会被分为几个段,每个段的段名是多少。另外,页的大小是固定的,并且这个页面的大小是由系统决定的。但段的长度却不固定,取决于用户编写的程序到底是什么样一个结构。

那从地址空间的角度来说,分页的用户进程,地址空间是一维的。比如说,一个用户进程的大小总共是16KB,那么在用户看来,它的整个进程的逻辑地址空间,应该是从0-16K-1。那用户在编程的时候,只需要用一个记忆符就可以表示一个地址,比如说用一个记忆符A来表示某个页面当中的某一个内存单元。
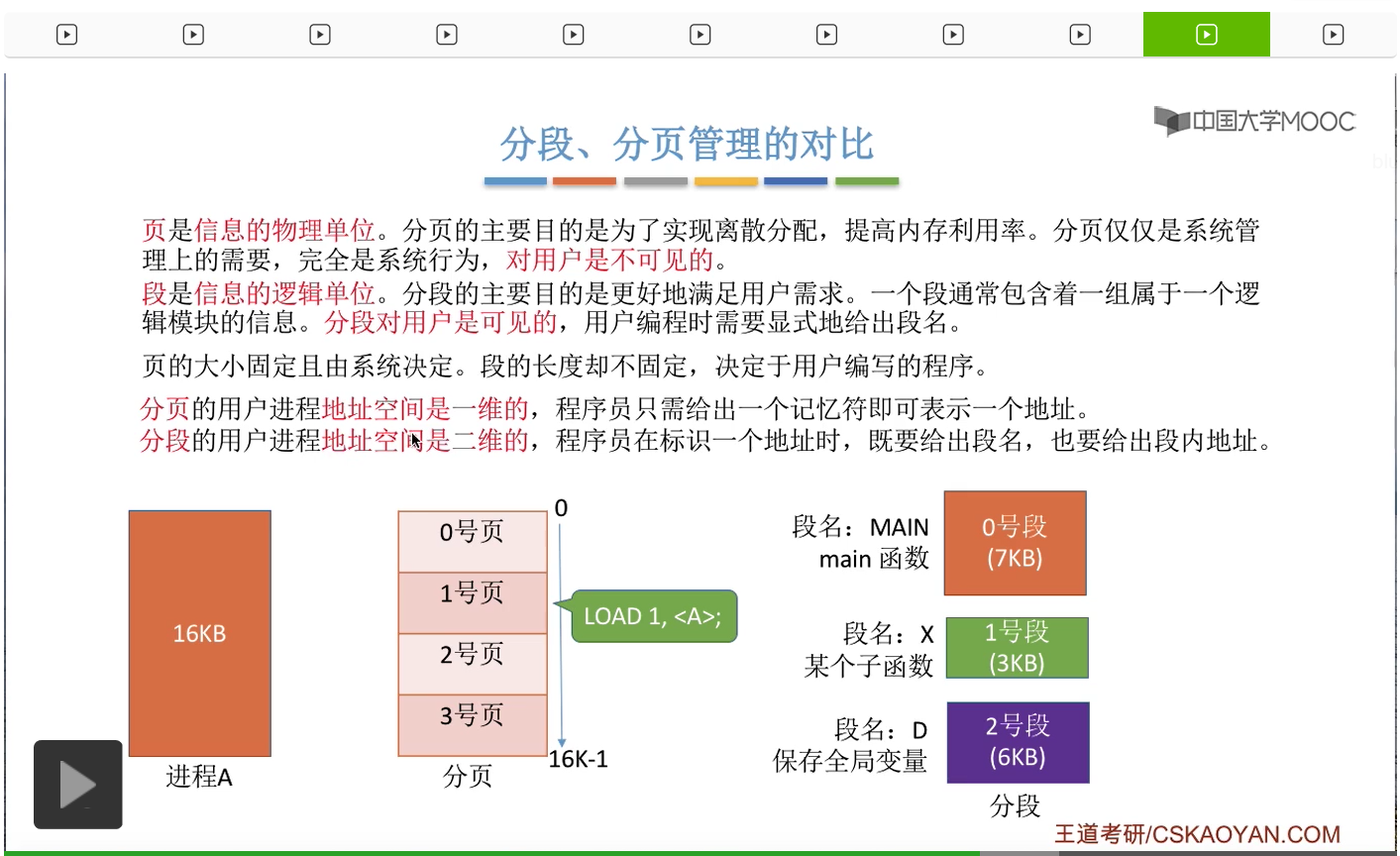
但如果系统采用的是分段存储管理的话,那么用户进程的地址空间是二维的,用户自己也知道自己的进程会被分为0、1、2这么几个段,并且每个段的这个逻辑地址都是从0开始的,
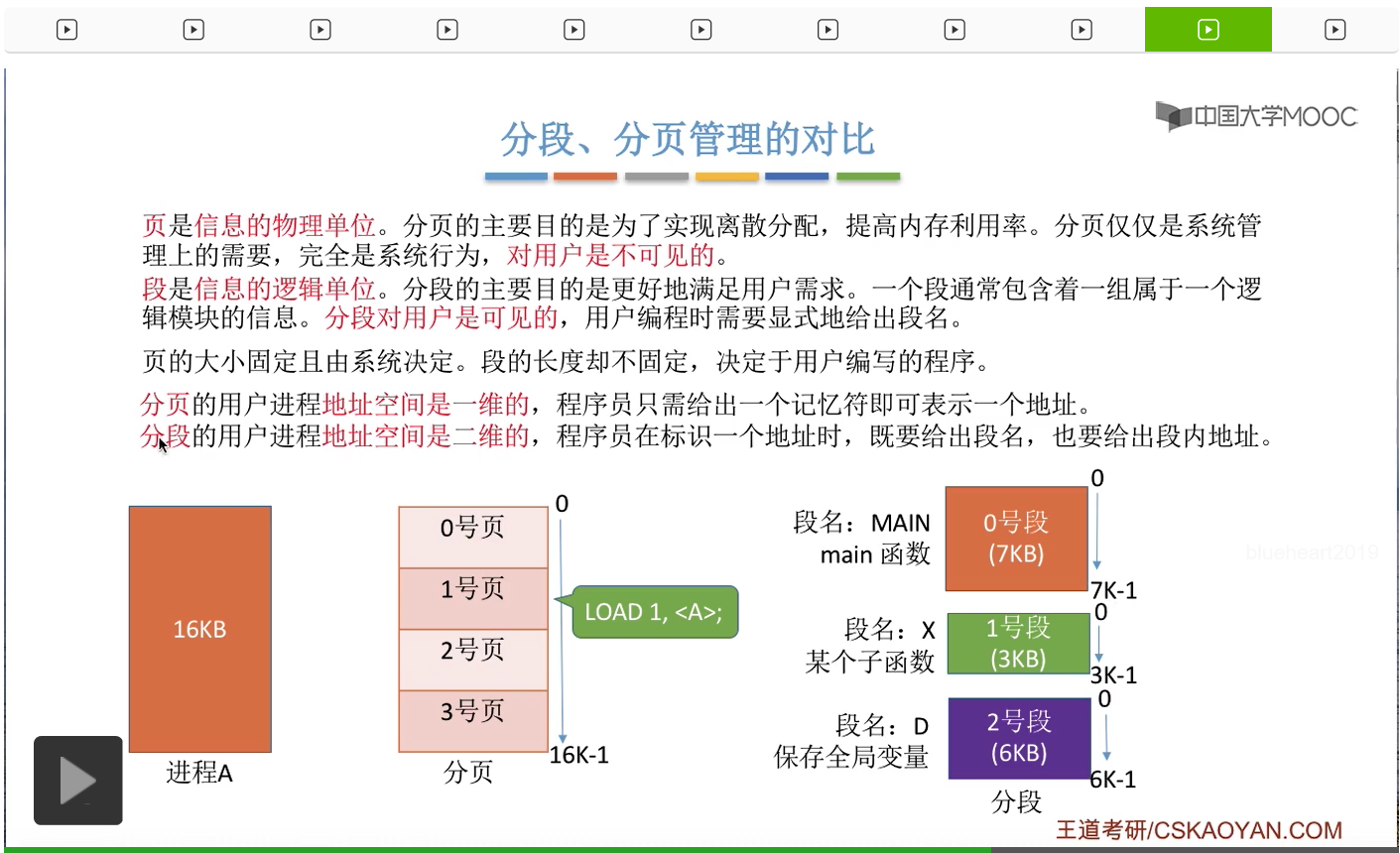
所以在分段管理的这种系统当中,用户编程的时候既需要给出段名,也需要给出段内地址。
比如说咱们之前提到的这个汇编语言指令,用户需要显式地给出段名还有段内地址。那因此,在分页管理当中,在用户自己看来,自己的这个进程的地址空间是连续的,但是在分段存储管理当中,用户自己也知道自己的进程地址空间是被分为了一个一个的段,并且每个段会占据一连串的连续的地址空间。因此,分页当中进程的地址空间是一维的,而分段的时候,进程的地址空间是二维的。那这个点在选择题当中还是很容易进行考查的。
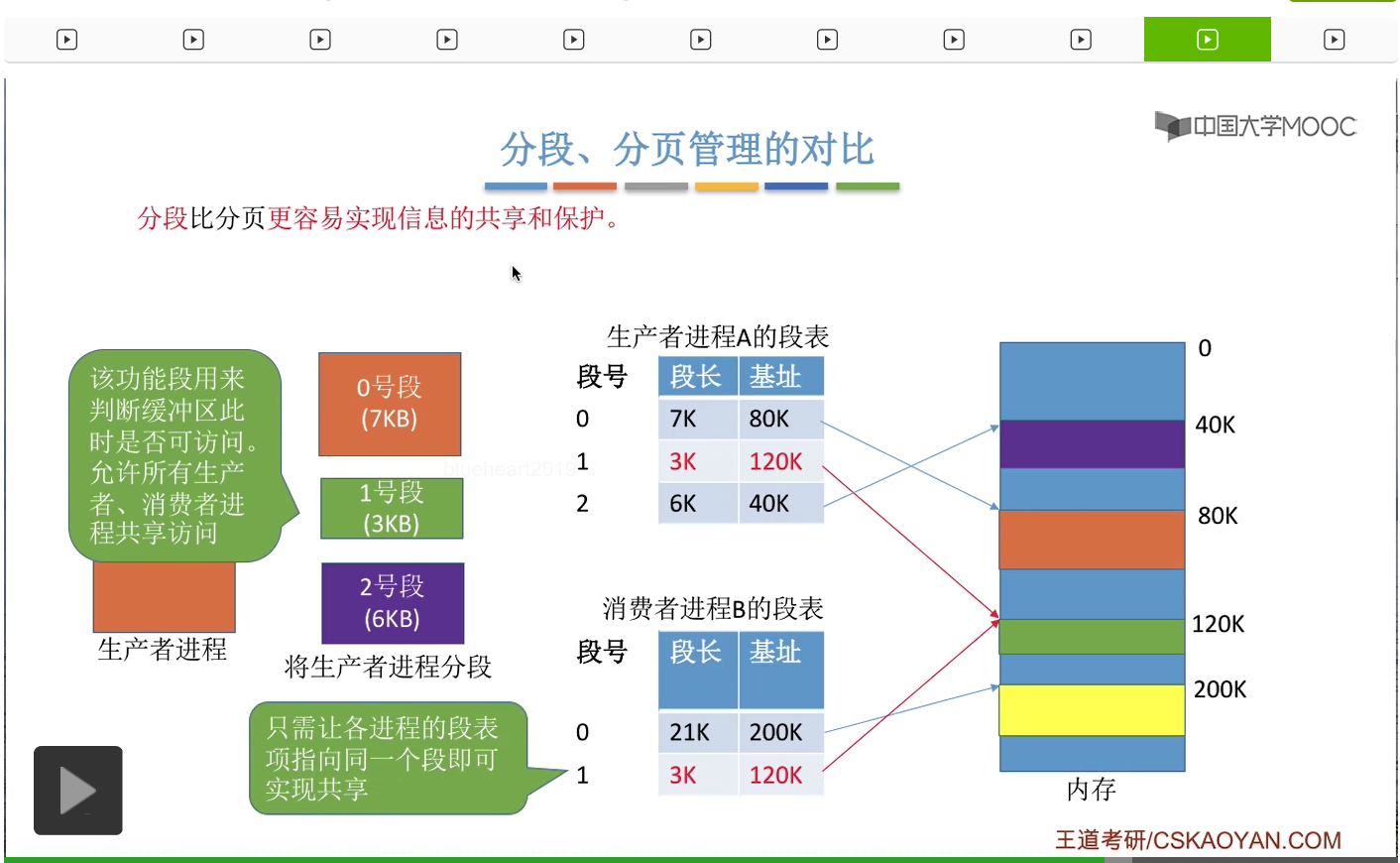
那除了之前所说的那些不同之外,分段相比于分页来说最大的一个优点应该是它更容易实现信息的共享和保护。比如说一个生产者进程,总共是16KB这么大,

那么它可能会被分为这样的三个段。其中一号段是用来实现判断缓冲区此时是否可以访问这样一个功能,那其实除了这个生产者进程之外,其他的生产者进程消费者进程它们也需要判断缓冲区此时是否可以访问。因此,这个段当中的代码,应该允许各个生产者进程、消费者进程共享地访问。那怎么实现共享地使用这个段呢?

假设我们的这个生产者进程它有这样的一个段表。它的1号段也就是判断缓冲区的那个段,是存放在内存的120K这个地址开始的这个内存空间当中的。
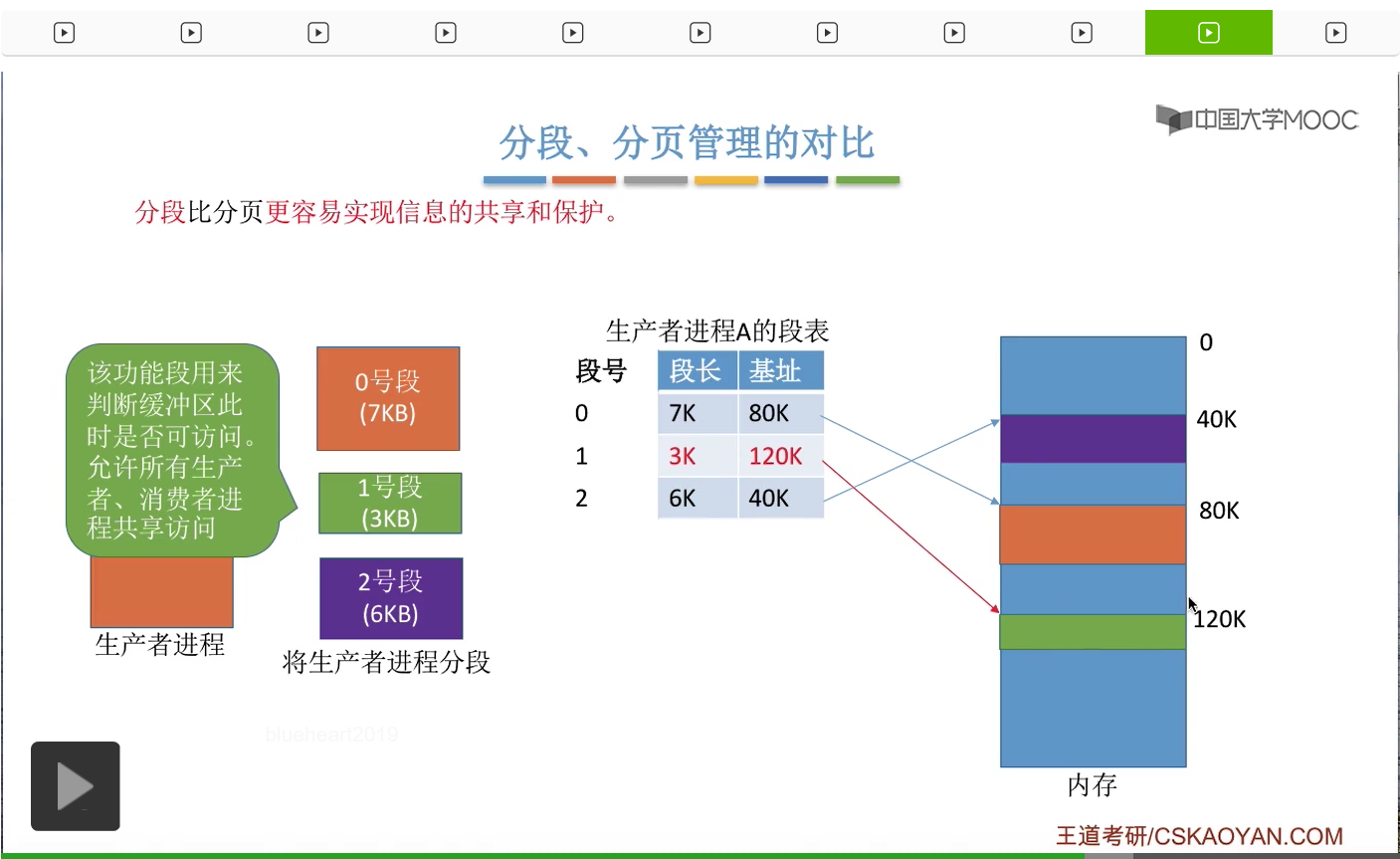
那如果说消费者进程想要和它共享地使用这个1号段的话,那么很简单,可以让消费者进程的某一个段表项同样是指向这个段存放的起始地址的。所以如果我们想要实现共享的话,就要让各个进程的某一个段表项指向同一个段就可以了。
那这个地方需要注意的是,只有纯代码或者叫可重入代码也就是不能被修改的代码,可以被共享地访问。那这种代码不属于临界资源,各个进程即使并发地访问这一系列的代码也不会因为并发产生问题。
比如说有一个代码段只是简单地输出“Hello World!”这么一个字符串,那么所有的进程并发地访问这个代码段那显然是不会出问题的。但是对于可修改的代码段来说,是不可以共享的。因此,对于代码来说,只有纯代码这种不属于临界资源的代码可以被共享地访问。那这是在分段存储管理方式当中实现共享的一个很简单的方式。

那接下来我们再来看一下为什么分页管理当中不方便实现这种信息的共享。假设我们把这个消费者进程进行分页的话,那么第一个页是0号段当中的前半部分的位置占4KB,那第二个页它会包含0号段当中的3KB和1号段当中的1KB,那这两个总共组成了4KB的页面。那类似于的,第三个页面也会包含一半1号段的内容,还有另一半是2号段的内容。
所以如果采用分页这种方式的话,那么我们如果让消费者的某一个页表项也指向这个生产者进程的分页的话,那么显然是不合理的。因为生产者进程的这个分页当中,只有绿色部分是允许被消费者进程共享的,但是橙色部分不应该被消费者进程所共享。

因此,由于页面它并不是按照逻辑模块来进行划分的,所以我们就很难实现共享,并不像分段那么方便。

那其实对于信息的保护,原理也是类似的。比如说在生产者进程当中,1号段应该是允许被其他进程访问的。那我们只需要把这个段标记为允许其他进程访问,其他的那些段标记为不允许其他进程访问。那这就很简单地就实现了对于各个段的保护。
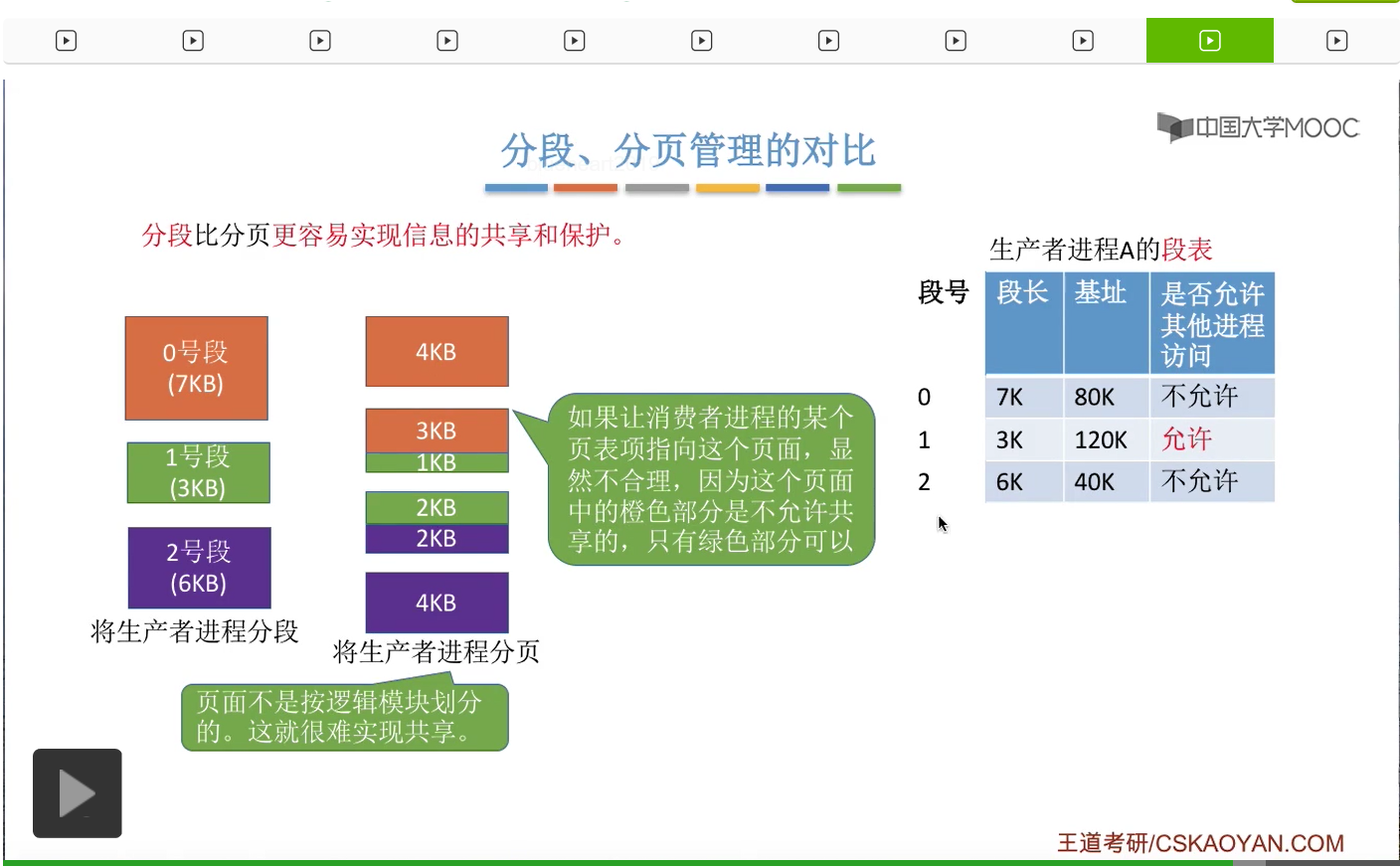
但是如果采用分页存储管理的话,1号页和2号页当中只有一部分也就是绿色这些部分是允许其他进程访问的,而其他的橙色和紫色的部分,不应该允许被其他进程访问。所以这样的话我们其实不太方便对各个页面进行标记到底是否允许被其他进程访问。因此,采用分页存储的时候,更不容易实现对信息的保护和共享这两个功能。
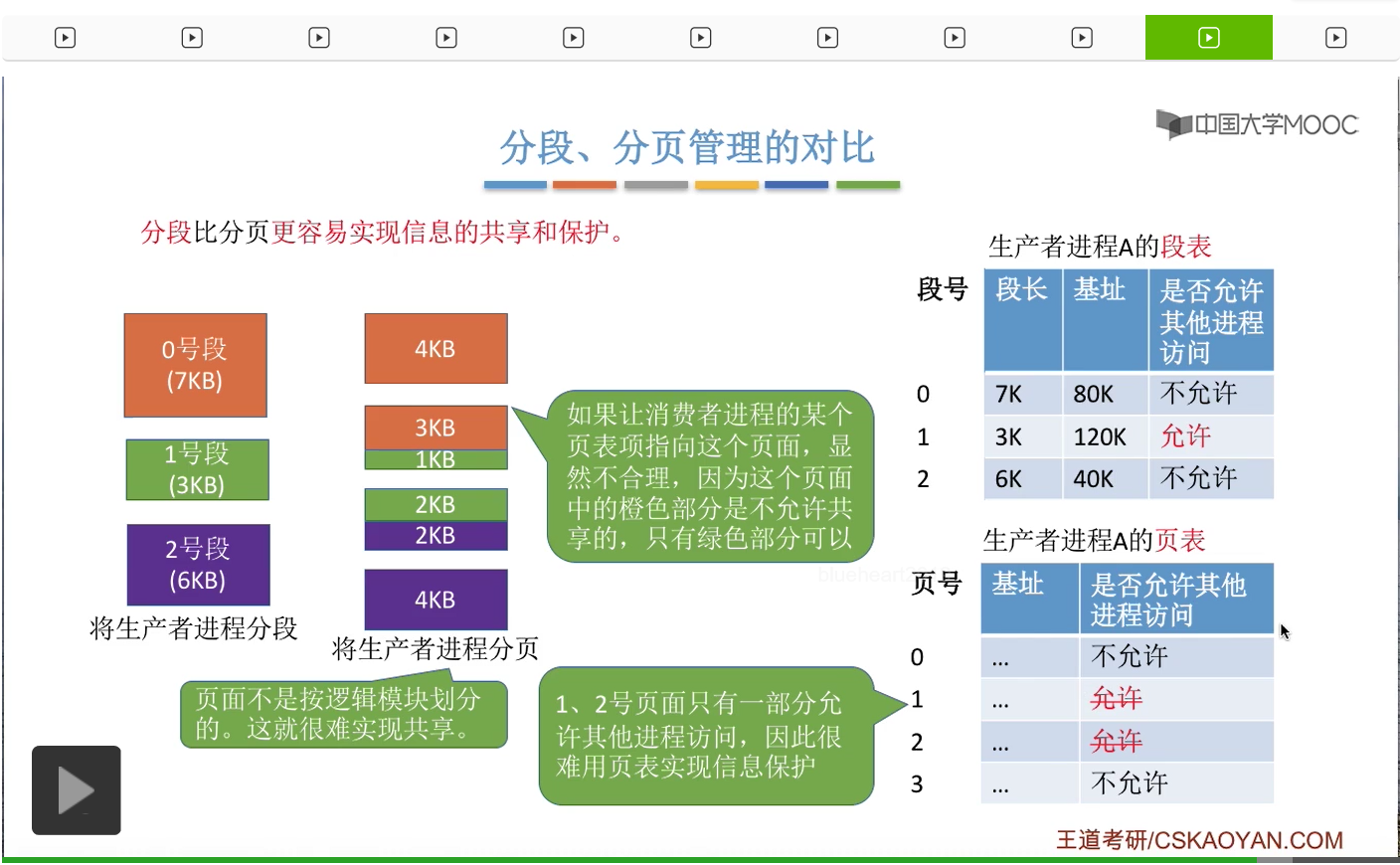
那这是关于信息的共享和保护,通过刚才的讲解,相信不难理解。那接下来我们再来探讨我们在分段和分页这两种方式当中,访问一个逻辑地址需要几次访存。如果我们采用的是单级页表的分页存储管理的话,那么第一次访存应该是查询内存当中的页表,第二次访存才是查询最终的目标内存单元。那这个过程咱们在之前已经分析过很多次,就不再展开。所以采用单级页表的分页存储管理,总共需要两次访存。

那如果采用分段的话,第一次访存是查询内存当中的段表,第二次访存是访问目标内存单元。所以采用分段的时候,也是总共需要两次访存。那在分页存储管理当中我们知道,我们可以引入快表机构来减少在进行地址转换的时候访问内存的次数。所以其实在分段管理当中也类似,我们也可以引入快表机构,然后可以把近期访问过的段表项放到快表当中,那这样的话只要快表能够命中,那么我们就不需要再到内存当中查询段表,我们就可以少一次访存。那这就是分段和分页管理的一个对比。

那在学习了分页存储管理之后,这个小节的内容其实并不难理解。我们介绍了什么是分段,在分段存储管理当中,逻辑地址结构是什么样的。另外,我们介绍了和页表很类似的段表,只不过对于段表来说,大家需要着重注意的是,每个段表项当中,一定会记录这个段的段长是多少。那在分页存储管理当中,每个页面的长度是不需要显式地在页表当中记录的。因为各个页面的长度一样,而在分段存储当中,各个段的长度是不一样的。所以这是它们俩之间的一个最明显的一个区别。那由于各个段的段长不一样的,所以在地址变换的时候大家也需要注意,在找到了对应的段表项之后,还需要对段长和段内地址进行一个对比的检查,看一下段内地址是否越界。那除了这个步骤之外,其他的那些步骤其实和页式管理当中,地址变换的过程也是大同小异的。那分段和分页的对比这些知识点,是很容易在选择题当中进行考查的。所以大家还是需要理解这些点。那这个小节的内容还需要大家通过课后的习题再进行进一步的实践巩固,也需要能够根据题目当中给出的信息来手动地完成这个地址变换的过程。

那段页式管理其实是分段和分页这两种管理方式的一个结合。那之后我们会介绍分段和分页这两种方式、这两种思想的一种结合,从而引出了段页式管理方式。那之后我们还会介绍在段页式管理当中,段表和页表与分段、分页管理当中的段表、页表有什么相同和不同的地方。那最后我们还会介绍怎么实现从逻辑地址到物理地址的变换。那我们会按照从上至下的顺序依次讲解。
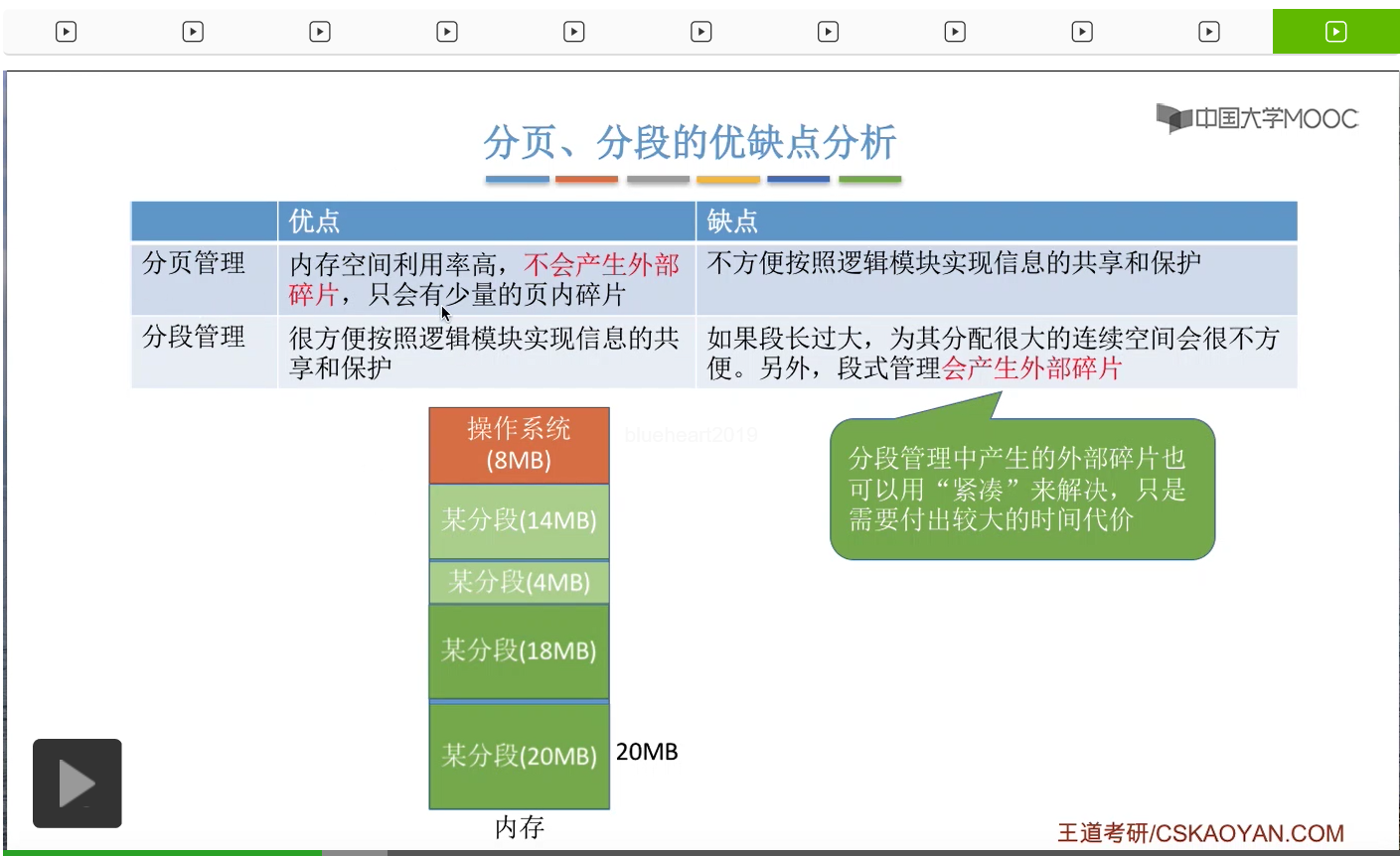
由于分页是按照信息的物理结构来进行划分的,所以我们不太方便按照逻辑模块、逻辑结构来实现对信息的共享和保护。分段是按照信息的逻辑结构来进行划分的,因此采用这种方式就很方便按照逻辑模块实现信息的共享和保护。不过缺点呢,如果说我们的段很长的话,就需要为这个段分配很长很大的连续空间,那很多时候分配很大的连续空间会不太方便。那另外,段式管理是hi会产生外部碎片的,它产生外部碎片的原理其实和动态分区分配很类似。比如说一个系统的内存本来是空的,

那么先后来了三个分段,它们都需要占用连续的这种存储空间。

那这个地方有4M字节的空闲区间,

那之后这个分段用完了,于是把它撤离内存。

那接下来又来了一个分段,占4M字节。

如果它占用了这个分区的话,那这个地方就会产生10M字节的一个空间。

那接下来如果上面这个段也撤离了,

那接下来再来了一个分段,也是占14M字节,

那这个地方就会产生6M字节的空闲的区间。

那在接下来如果还有一个分段到来,它总共需要占20M字节的这种连续的内存区间。那由于此时这些空闲区间并不连续,所以虽然它们的大小总和是20M字节,

但是这个分段是放不进内存当中的,因为分段必须连续地存放。所以很显然,段式管理是会产生这些难以利用的外部碎片的。

不过,对于外部碎片的解决,其实和咱们之前介绍的那种动态分区分配也一样,


可以通过这种紧凑的方式,

来创造出更大的一片连续的空间。

但是紧凑技术需要付出比较大的时间代价,所以显然这种处理方式也并不是一个很完美的解决方式。所以基于分页管理和分段管理的这些优缺点,人们又提出了分段和分页这两种思想的一个结合,于是产生了段页式管理,段页式管理就具备了分页管理和分段管理的各自的优点。
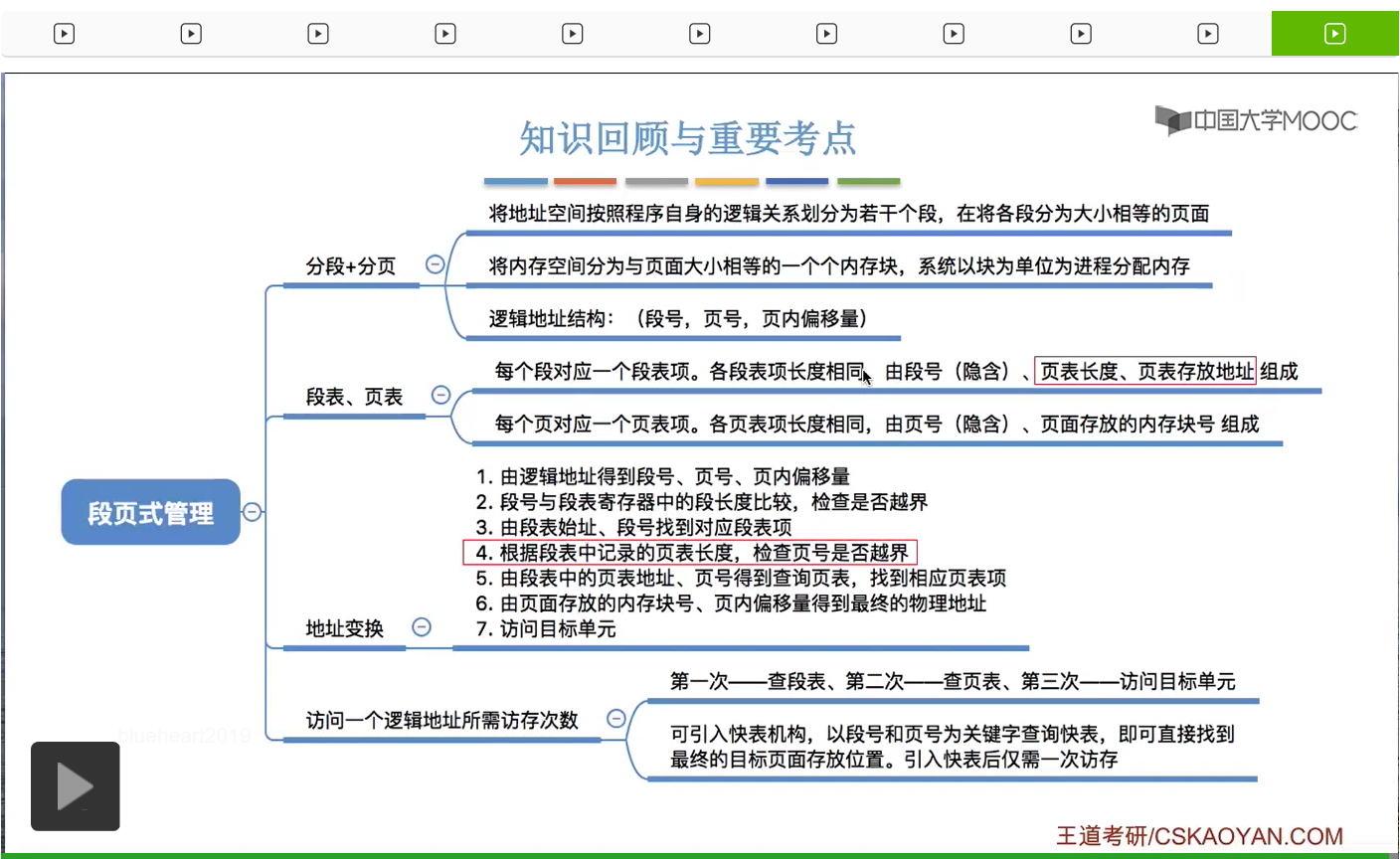
在采用段页式管理的系统当中,一个进程会按照逻辑模块进行分段。之后各个段还会进行分页,比如说每个页面的大小是4KB,那么0号段本来是7KB它会被分为4KB和3KB这样两个页面。
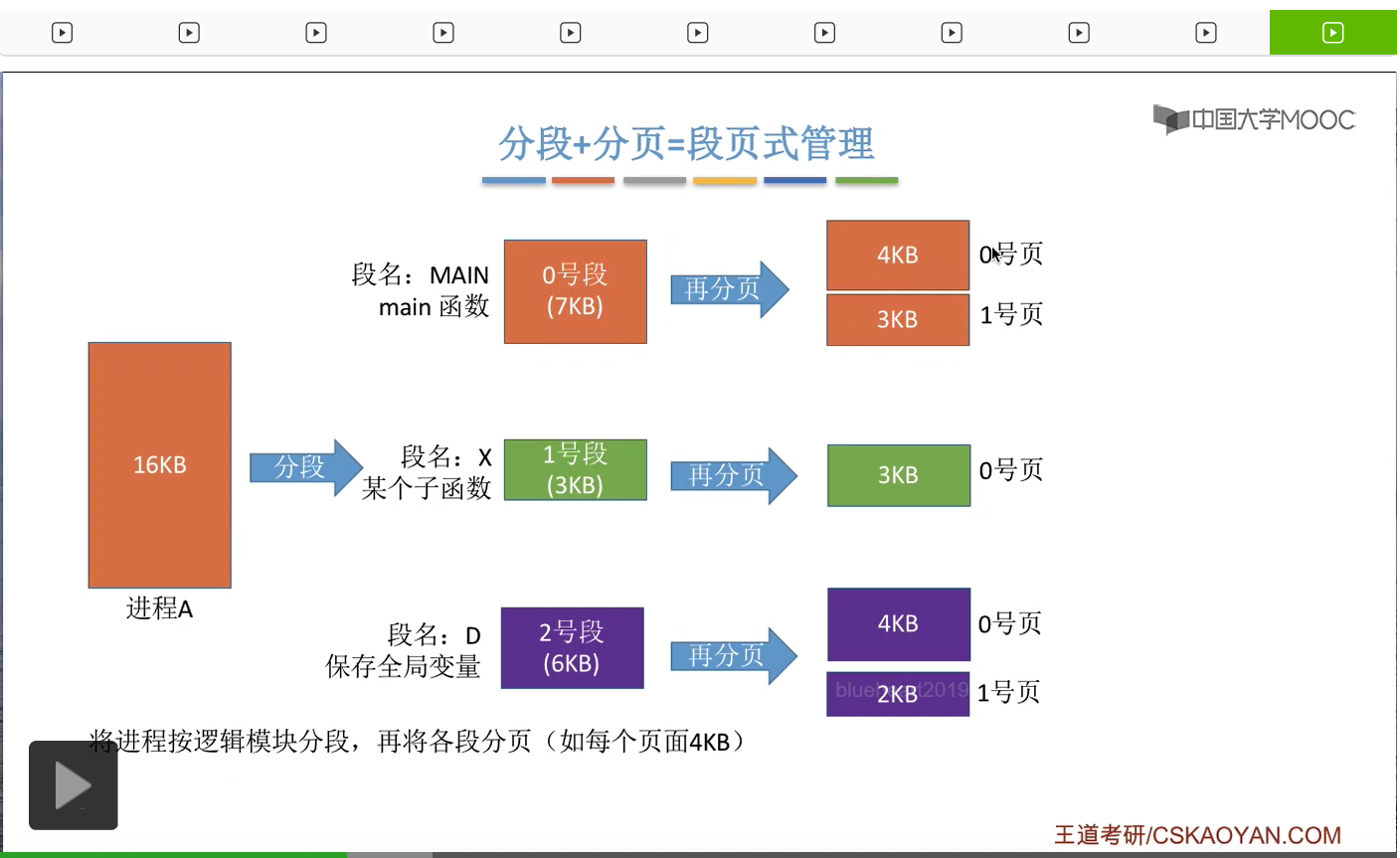
那对于内存来说,内存空间也会被分为大小相等的内存块,或者叫页框、页帧、物理块。那每一个内存块的大小和系统当中页面的大小是一样的,也就是4KB。那最后,进程的这些页面会被依次放到内存当中的各个内存块当中。
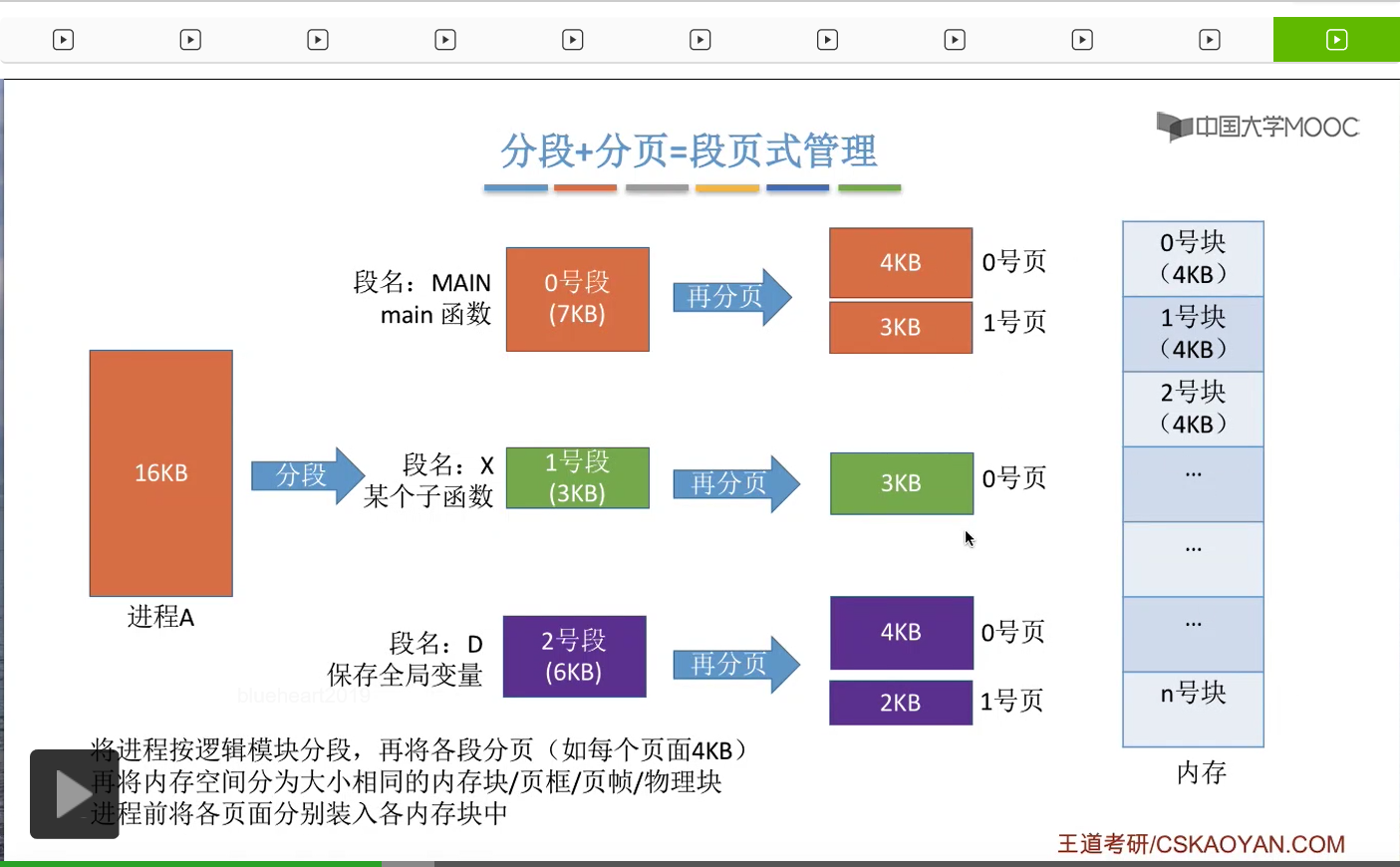
那我们在上个小节中学过,如果采用的是分段管理的话,那么逻辑地址结构是由段号和段内地址组成的。而在段页式管理当中我们会发现,一个进程被分段之后,各个段还会被再次分页,所以对于段页式管理来说,它的逻辑地址结构,应该是由段号、页号还有页内偏移量组成。那这个地方的页号和页内偏移量其实就是分段管理当中的段内地址进行再拆分的一个结果。

那在考试当中需要的注意的是,段号的位数决定了我们一个进程最多可以分几个段,而页号的位数决定了每个段最大会有多少页,页内偏移量的位数又决定了页面的大小和内存块的大小。

所以如果一个系统当中它的地址结构是这样的,并且这个系统是按字节寻址的话,那么段号占16位,所以这个系统当中每个进程最多可以有2^16也就是64K个段。而页号占4位,所以每个段最多会有2^4=16页。另外页内偏移量占12位,所以每个页面/每个内存块的大小是2^12=4096=4KB。
那在段页式管理当中,分段这个过程对用户来说是可见的,程序员在编程的时候需要显式地给出段号和段内地址这样两个信息。但是把各个段进行分页的这个过程,对用户来说是不可见的,这只是一个系统的行为。系统会把段内地址自动地划分为页号和页内偏移量这样两个部分。所以对于用户来说,他在编程的时候,只需要关心段号和段内地址这两个信息,而剩下的分页是由操作系统完成的。因此段页式管理的地址结构是二维的。那与此相对的,段式管理当中地址结构也是二维的。而页式管理当中,地址结构是一维的。

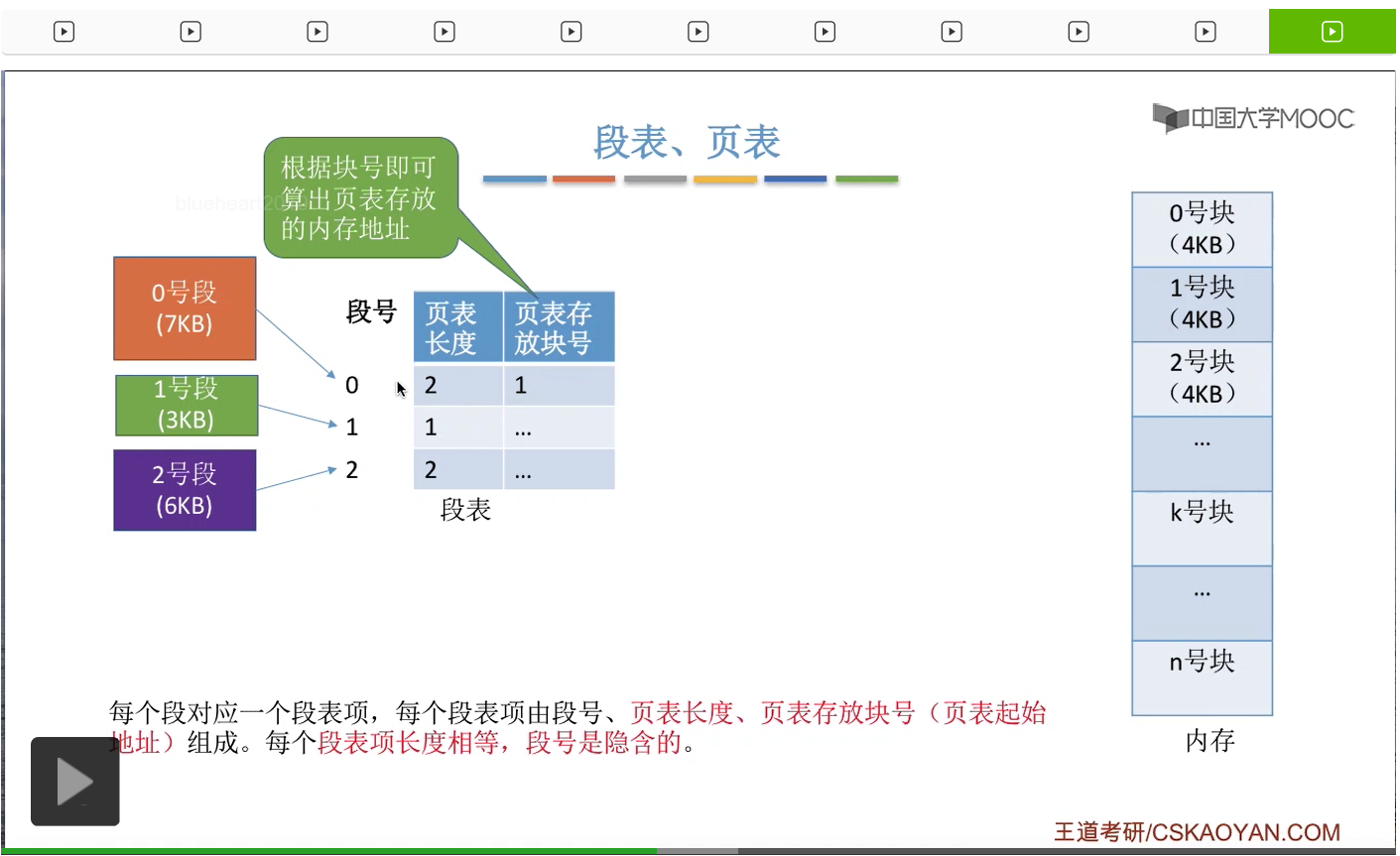
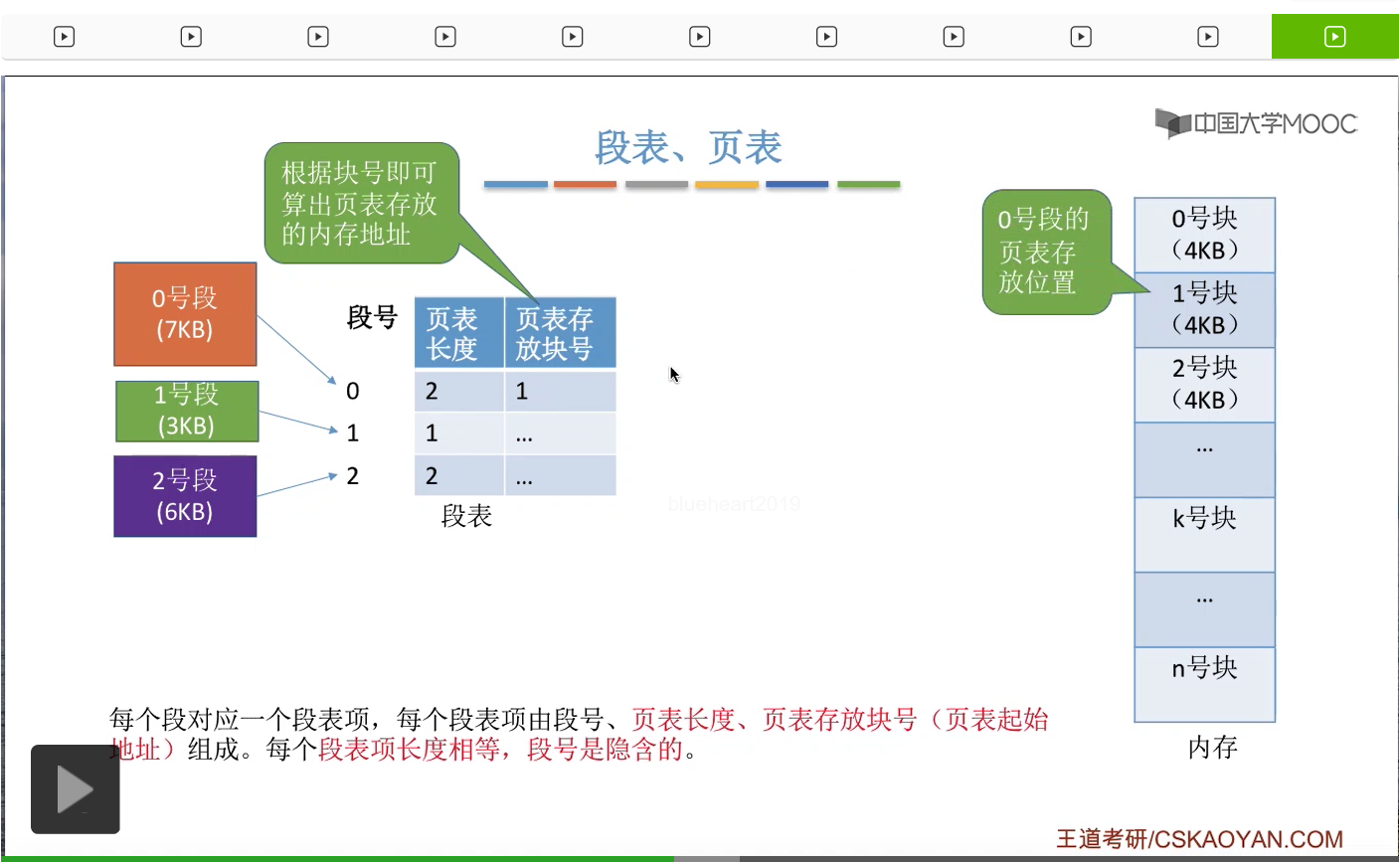
那与之前咱们介绍的分页和分段管理当中的思想相同,对进程分段再分页之后,我们也需要记录各个段、各个页面存放的一个位置。所以系统会为每个进程建立一个段表,进程当中的各个段会对应段表当中的一个段表项。而每个段表项由段号、页表长度和页表存放块号组成。那由于每个物理块的大小是固定的,所以只要知道页表存放的物理块号,其实就可以知道页表存放的实际的物理地址到底是多少了。那比如说我们要查找0号段对应的页表,
那么我们知道这个页表存放在内存为1号块的地方,也就是这个位置。于是就可以从这个内存块当中读出0号段对应的页表。
那由于0号段长度是7KB,而每个页面大小是4KB,所以它会被分成两个页面,相应的这两个页面就会依次对应页表当中一个页表项。每一个页表项记录了每一个页面存放的内存块号到底是多少。
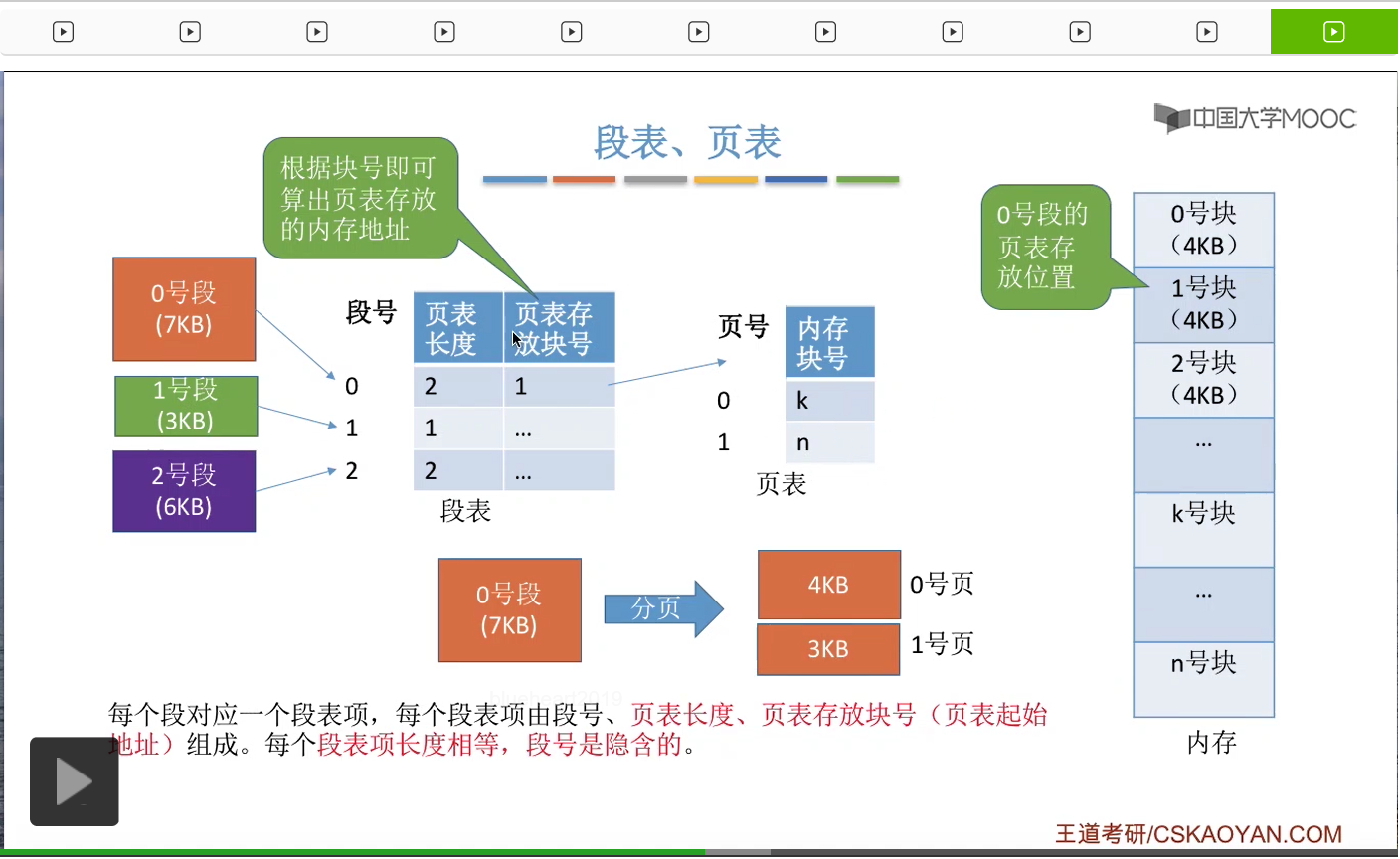
所以通过刚才的讲解大家会发现,在段页式管理当中,段表的这个结构和段式管理当中的段表是不一样的。段式管理当中的段表记录的是段号还有段的长度,还有段的起始地址这么三个信息。而段页式管理当中,记录的是段号、页表长度、页表存放块号这么三个信息,也就是后面的这两个信息不太一样。而对于页表来说,段页式管理和分页管理的页表结构基本上都是相同的,都是记录了页号到物理块号的一个映射关系。那各个段表项的长度是相等的,所以段号可以是隐含的。各个页表项的长度也是相等的,所以页号也是可以隐含的。那这两点咱们在之前的小节有详细地介绍过,这儿就不再展开。那从这个分析当中我们会发现,一个进程只会对应一个段表,但是每个段会对应一个页表,因此一个进程有可能会对应多个页表。再重复一遍,一个进程会对应一个段表,但是一个进程有可能会对应多个页表。
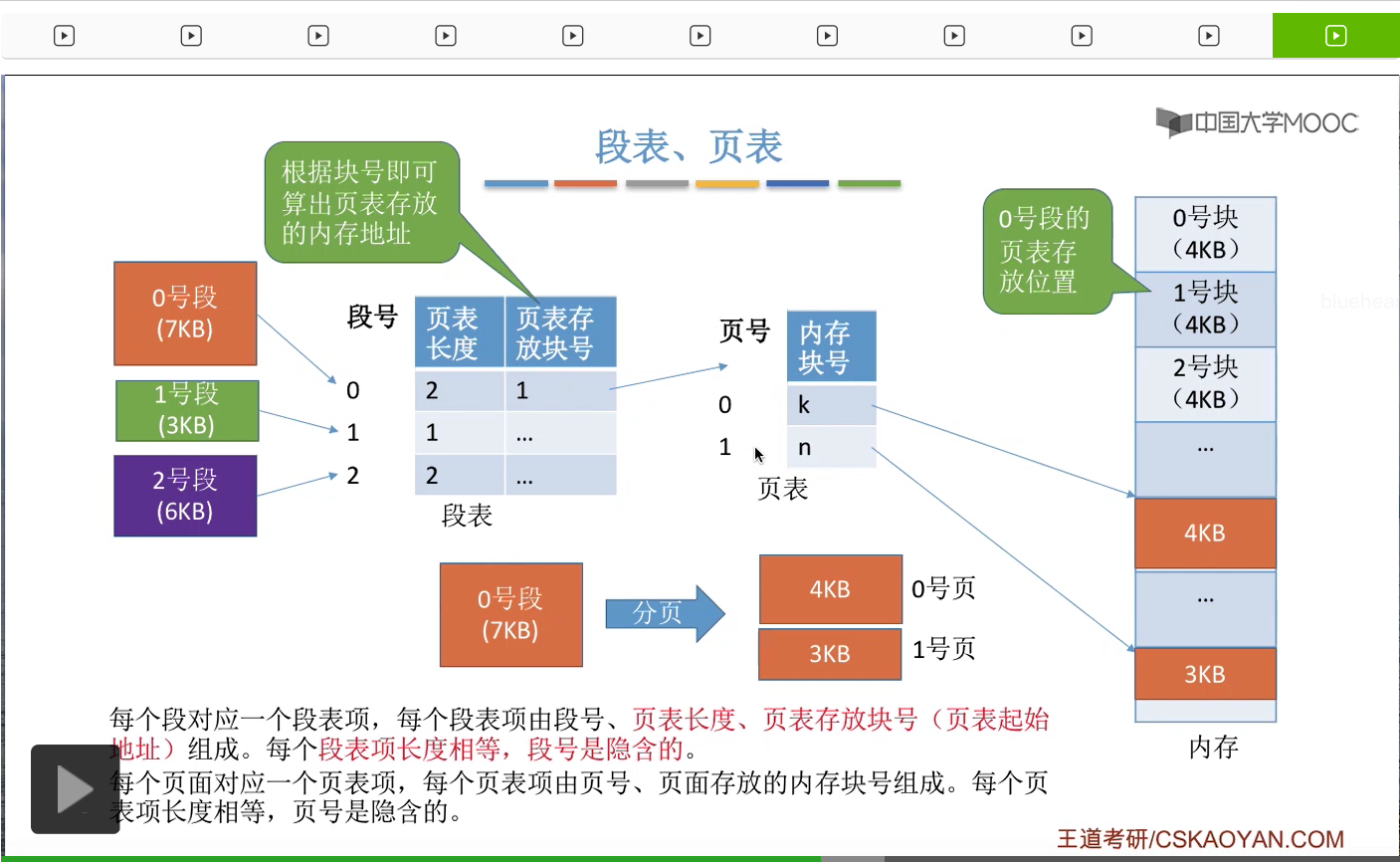
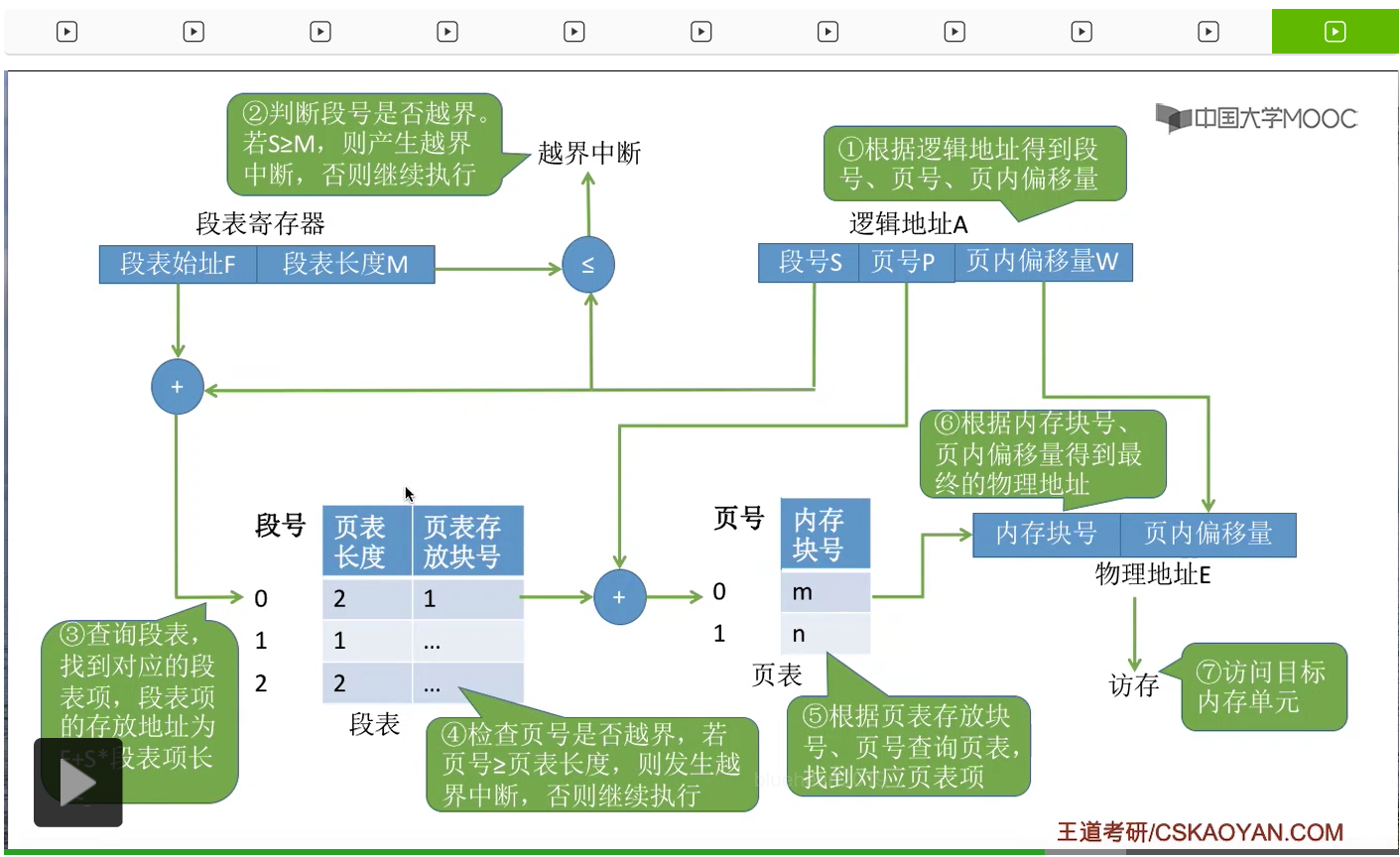
那么接下来我们再来看一下怎么实现段页式管理当中的这种逻辑地址转换为物理地址的这个过程。首先需要知道的是系统当中也会有一个段表寄存器这么一个硬件,然后在这个进程上处理机运行之前,会从PCB当中读出段表始址还有段表长度这些信息然后放到段表寄存器当中。

那在进行地址转换的时候,第一步是需要根据逻辑地址得到段号、页号还有页内偏移量这么三个部分。

那第二步需要把段号和段表长度进行一个对比,检查段号是否越界,是否合法。如果越界的话就会抛出一个中断,之后由中断处理程序进行处理。如果没有越界的话,就证明段号合法,就可以继续执行。

那接下来一步可以根据段号还有段表始址来计算出这个段号对应的段表项在内存当中的位置。这样的话,就找到了我们想要找的这个段表项。
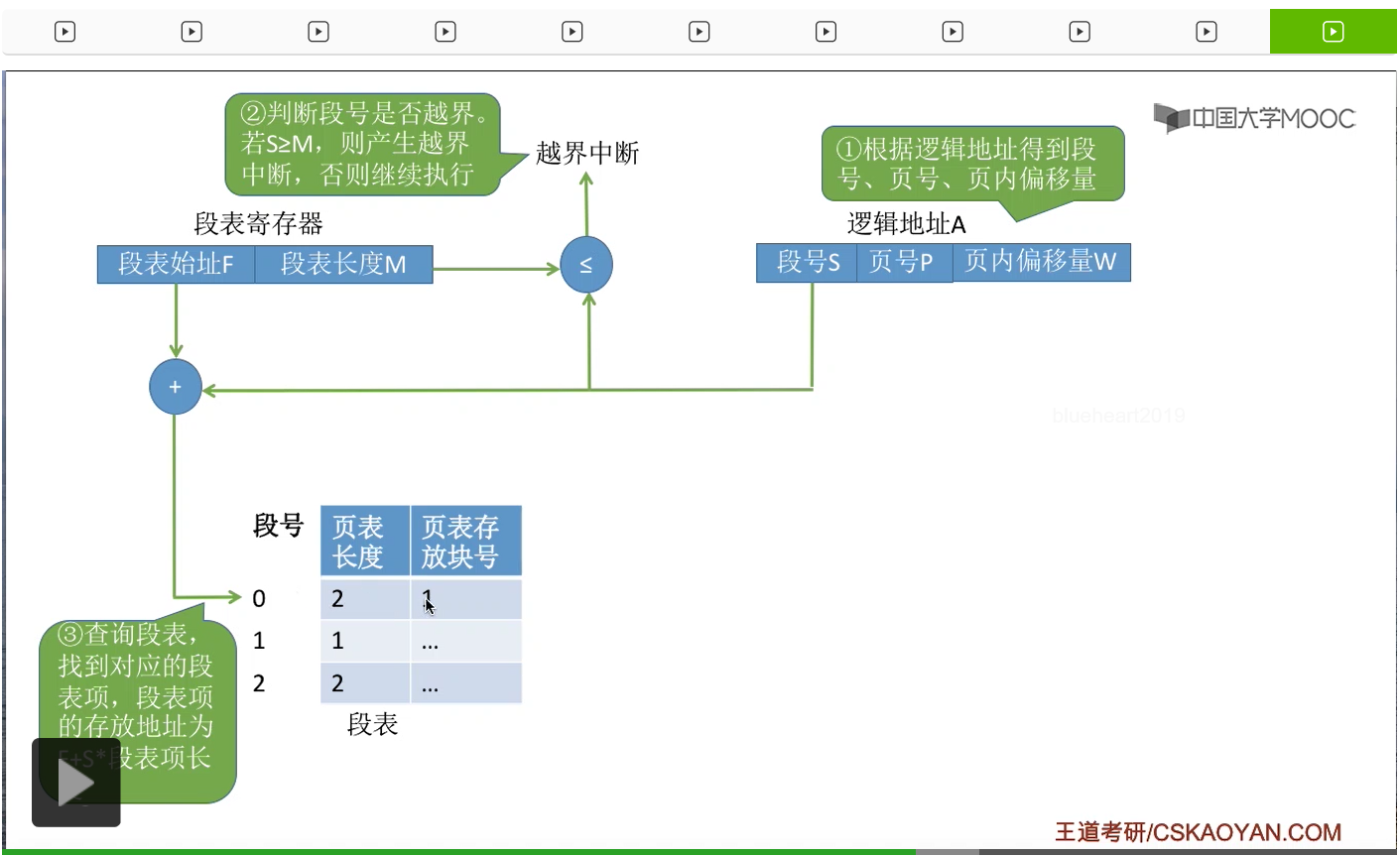
接下来一步需要注意,由于各个段的长度是不一样的,所以各个段把它们分页之后,可能分为数量不等的不同的一些页面。比如说有的段长一些,它就可以分为两个页面。有的段短一些,只需要用一个页面。所以由于各个段分页之后页面数量可能不同,因此这个地方我们也需要对页号的合法性进行一个检查,看看页号是否已经越界。如果页号没有超出页表长度的话,那么就可以继续往下执行。那通过这个页号我们知道了页表存放的位置,
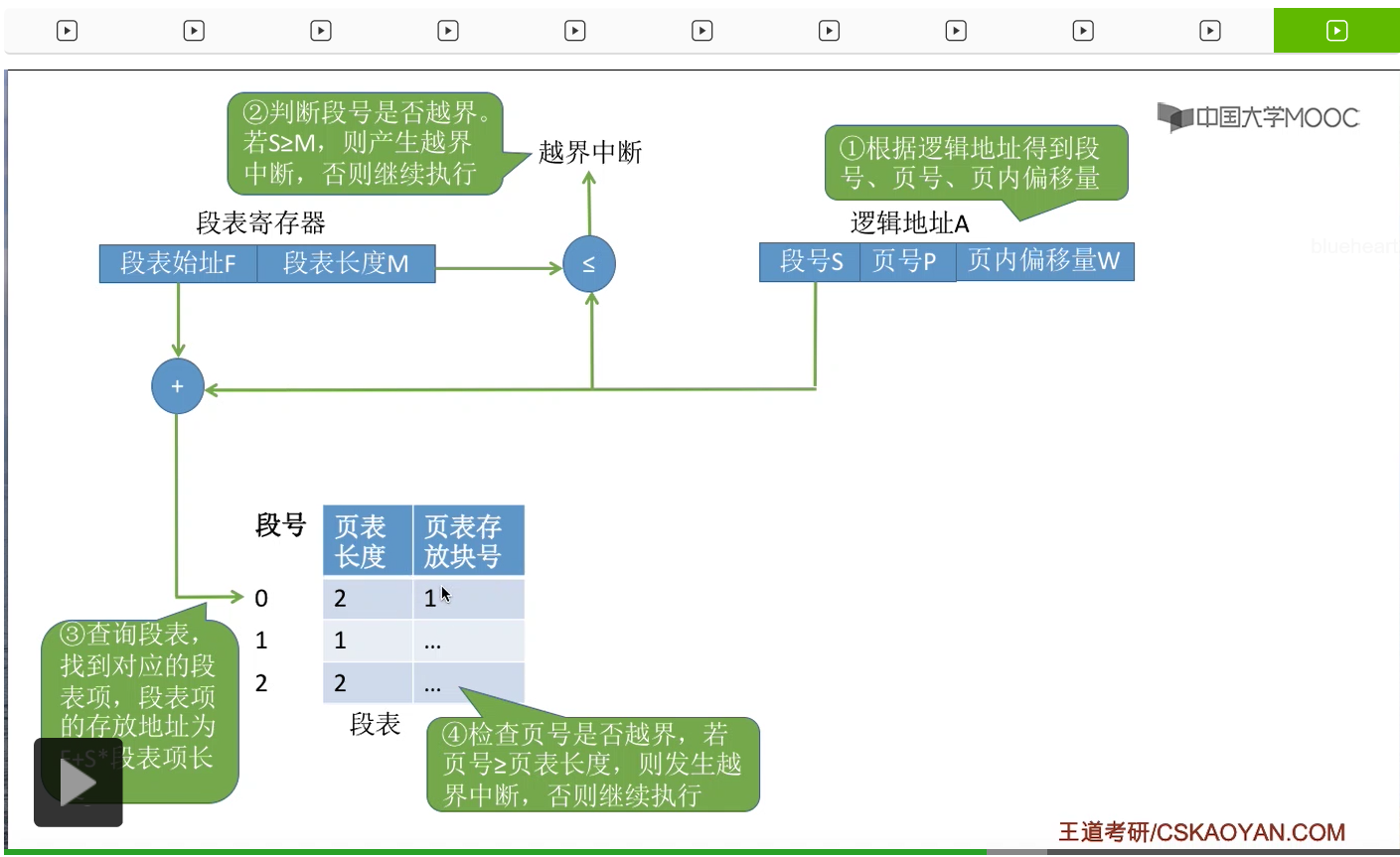
于是就可以从这个位置读出页表。于是可以根据页号来找到我们想要找的那个页表项,那找到这个页表项之后我们就知道这个页面在内存当中存放的位置。
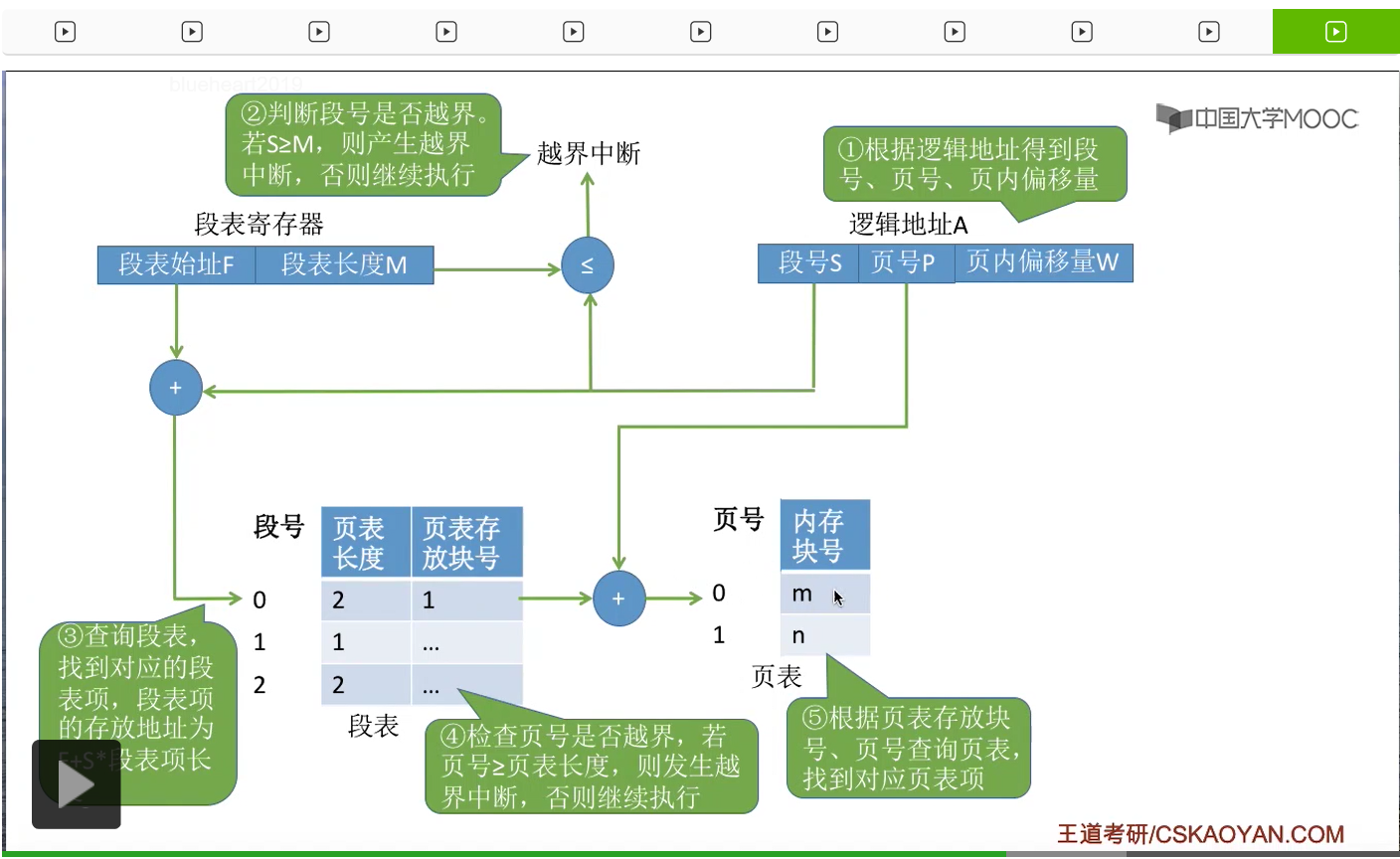
所以最后我们可以根据页表项当中对应的这个内存块号和页内偏移量进行二进制的拼接,最终形成要访问的物理地址。那最终我们就可以根据这个物理地址进行访存,访问目标内存单元。因此在段页式管理当中,进行地址转换的这个过程总共需要三次访存。
第一次是访问内存当中的段表,第二次访存是访问内存当中的页表,第三次访存才是访问最终的目标内存单元。那我们之前也介绍过,在分页和分段这两种管理方式当中,可以用引入快表机构的方式来减少地址转换过程当中访存的次数。
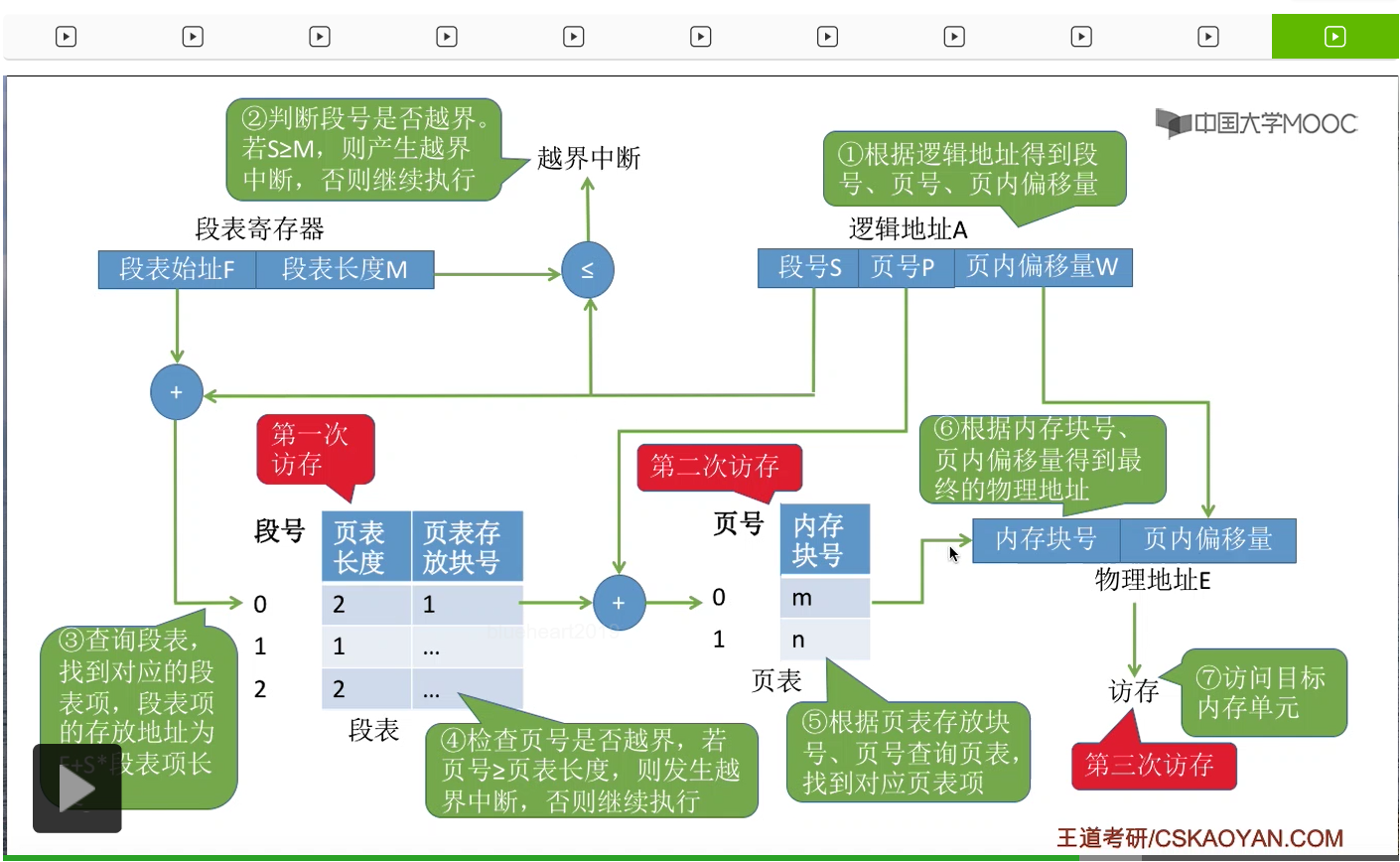
所以这个地方我们也可以用相同的思路。我们可以引入快表机制,用段号和页号作为快表的查询的关键字。那如果快表命中的话,我们就可以知道我们最终想要访问的那个页面到底在什么位置。因此,只要快表命中,我们就不需要再查询段表和页表了,这样的话我们仅需要一次访存也就是最终访问目标内存单元这一次。那么这就是段页式管理方式当中进行地址变换的一个过程。需要着重注意的是,这一步就是检查页号是否越界,那这个段式存储当中检查段内地址是否越界是比较类似的。需要检查的本质原因就在于各个段的长度可能是不相等的,因此需要进行这样一个合法性的检查。

段页式管理当中,逻辑地址结构由段号、页号和页内偏移量这么三个部分构成。但是用户在编程的时候只需要显式地给出段号和段内地址,之后会由系统自动地把段内地址拆分为页号和页内偏移量这么两个部分。因此由于用户只需要提供段号和段内地址这么两个信息,因此段页式管理当中,地址结构是二维的。那显然分段对于用户来说是可见的,但是分页是操作系统管理的一个行为,对于用户来说不可见。那么在这个小节当中我们还介绍了段表和页表的结构还有原理。需要注意的是,段页式管理中的段表,和分段管理当中的段表结构是不太一样的。段页式管理当中,段表由段号、页表长度和页表存放地址这么三个信息组成。但是在分段管理当中,由段号、段的长度还有段的起始地址这么三个信息组成,所以段表是不太一样的。但是页表的话和分页存储当中的页表的结构是相同的,都是由页号还有页面存放的内存块号来组成。那之后我们介绍了地址变换的过程,那比起分页和分段的地址变换过程来说,段页式管理需要先查询段表,之后还需要再查询页表,并且在找到段表项之后还需要对页表长度还有页号进行一个对比检查,看看页号是否已经越界。那同学们需要理解这个过程,能够自己写出来它的地址变换过程到底是什么样的。那最后我们还分析了段页式管理当中访问一个逻辑地址所需要的访存次数。第一次访存是需要查段表,第二次访存是查页表,第三次访存才是访问目标内存单元。那如果我们引入了快表机构之后,就可以以段号还有页号作为关键字去查询快表,如果快表命中的话,那么仅需要一次访存。
请求分页管理方式相关的一系列知识点。

请求分页管理方式是在基本分页管理方式的基础上进行拓展从而实现的一种虚拟内存管理技术。那相比于基本分页存储管理,操作系统还需要新增两个最主要的功能。
第一个功能就是请求调页的功能。系统需要判断一个页面是否已经调入内存,如果说还没有调入内存,也就是页面缺失的话,那么还需要将页面从外存调到内存当中,那这是请求调页功能。
第二个需要提供的功能是页面置换功能。就是当内存暂时不够用的时候,需要决定把哪些页面换出到外存。

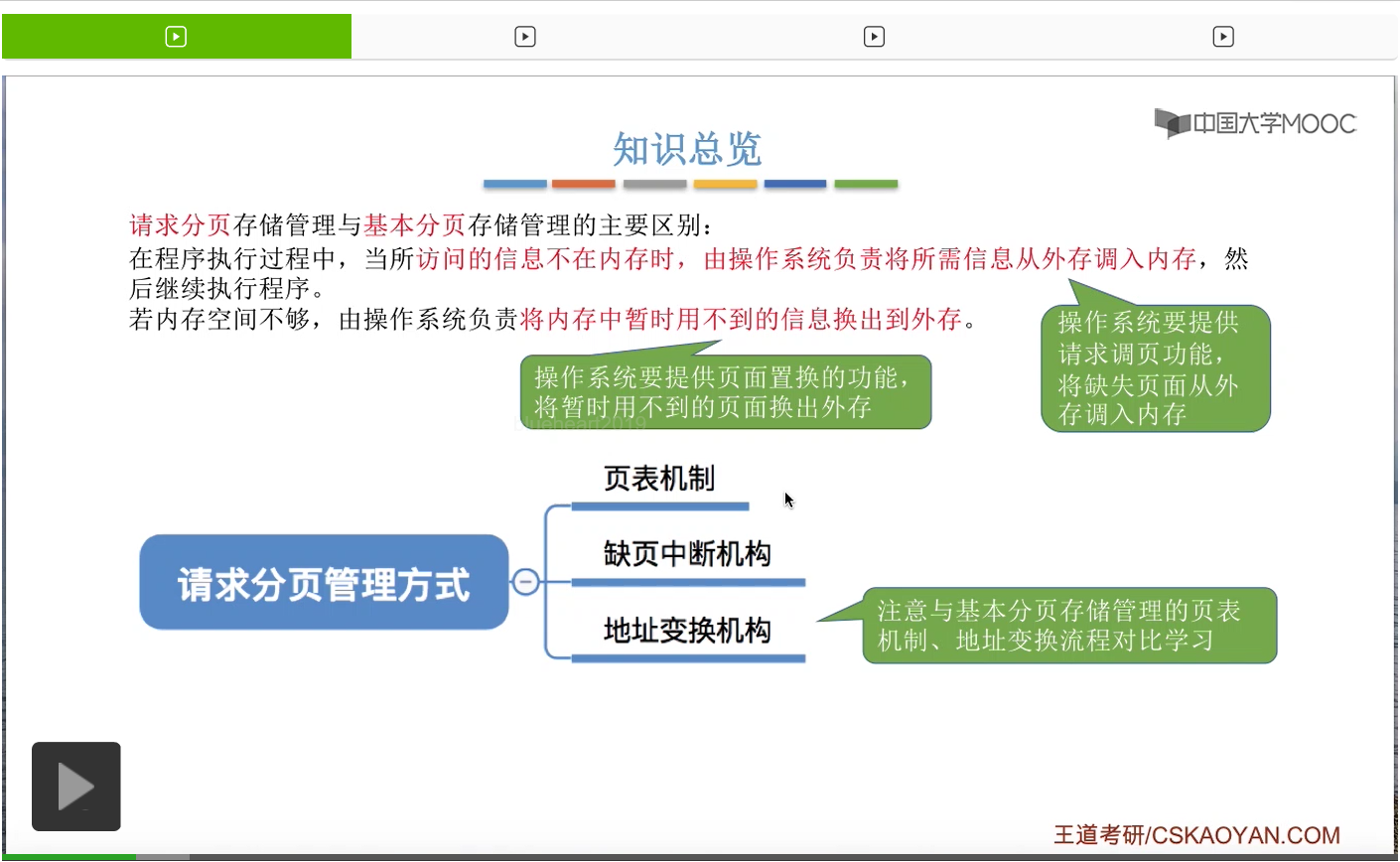
那针对于这两个功能如何实现,我们会介绍在请求分页管理方式当中页表机制与基本分页存储管理方式当中有哪些相同和不同的地方。另外,为了实现请求调页的功能,那请求分页管理系统当中引入了缺页中断机构,
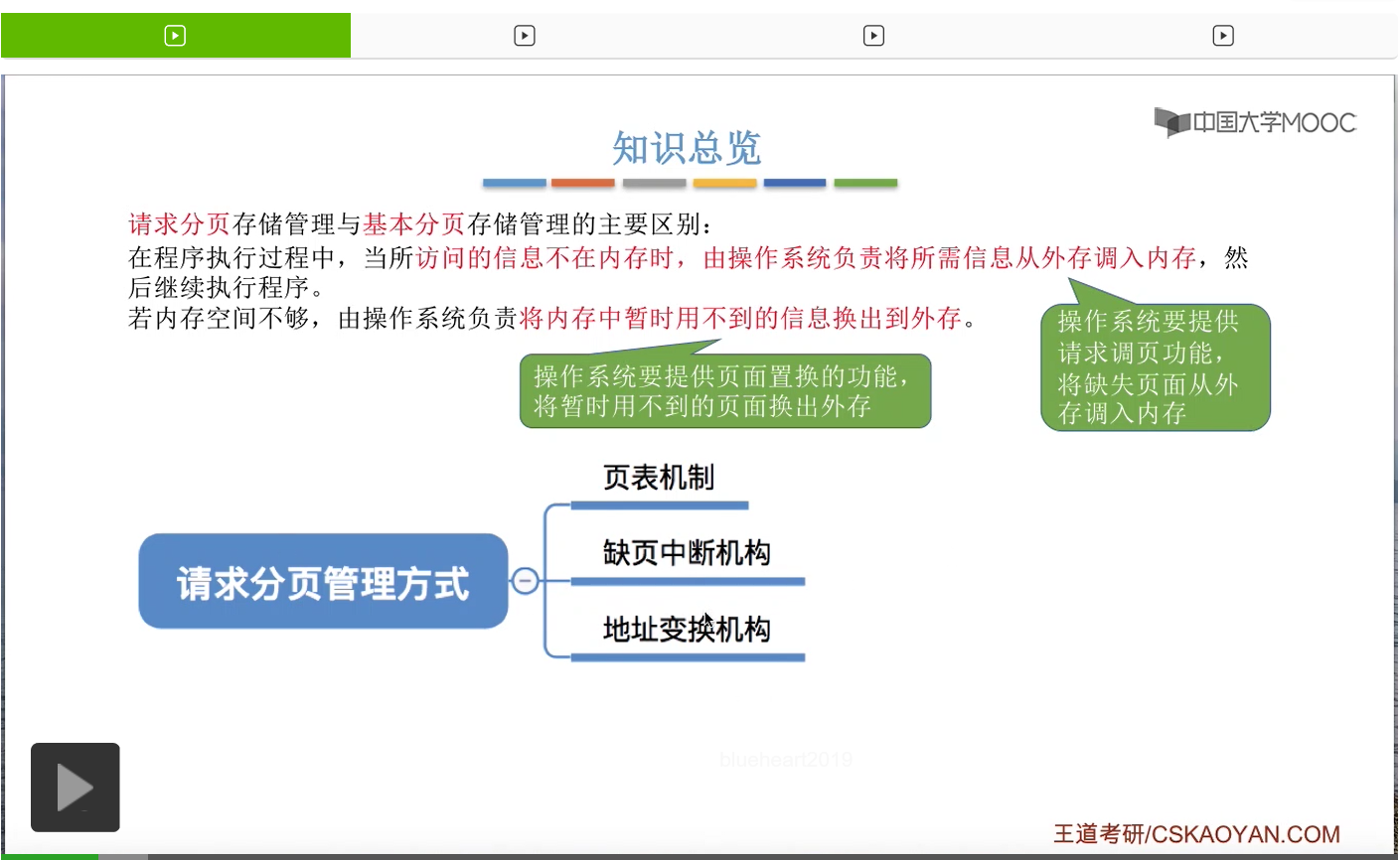
最后我们会介绍在这种管理方式当中,地址变换到底是什么样一个过程。那在学习这个小节的时候,需要注意和基本分页存储管理方式进行一个对比。那首先我们来看一下这种管理方式和基本分页管理方式的页表机制有哪些相同和不同的地方。那我们还是从如何实现页面置换和请求调页这两个功能的角度出发,来分析页表机制应该怎么设计。
所以为了知道这些信息,那么肯定需要把这些信息记录在某种数据结构当中。那页表其实就是一个很好的地方。
另外,为了实现页面置换功能,那么操作系统肯定需要通过某种规则来决定到底是把哪个页面换出到外存,所以我们需要记录每个页面的一些指标,然后操作系统根据这个指标来决定到底换出哪一页。另外呢,如果说一个页面在内存当中没有被修改过,那么这个页面其实换出外存的时候不用浪费时间再写回外存。因为它没有修改过,所以外存当中保存的那个副本其实和内存当中的这个数据是一模一样的。那只有页面修改过的时候才需要把它换到外存当中,把以前旧的那个数据覆盖。所以操作系统也需要记录各个页面是否被修改这样的信息。
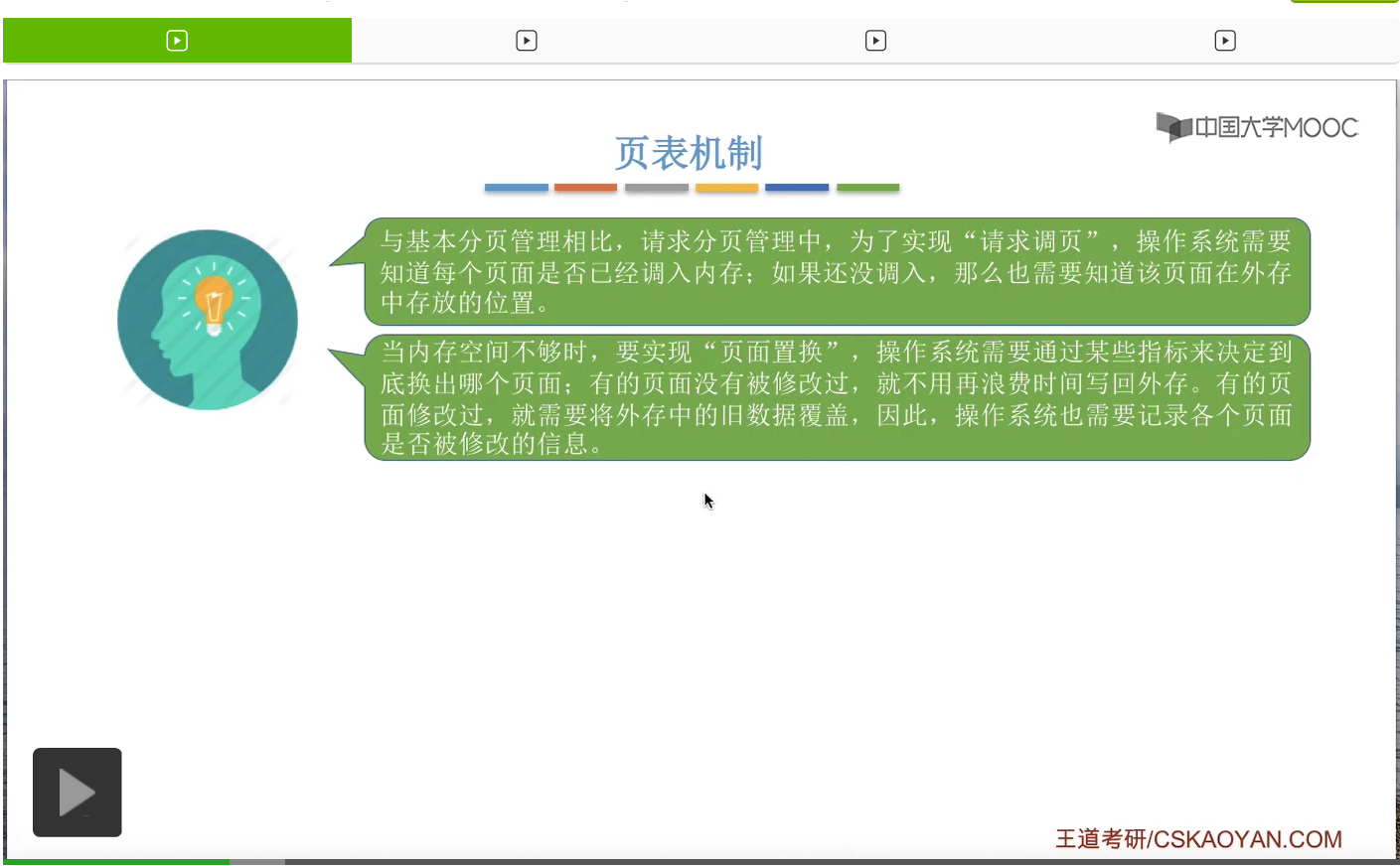
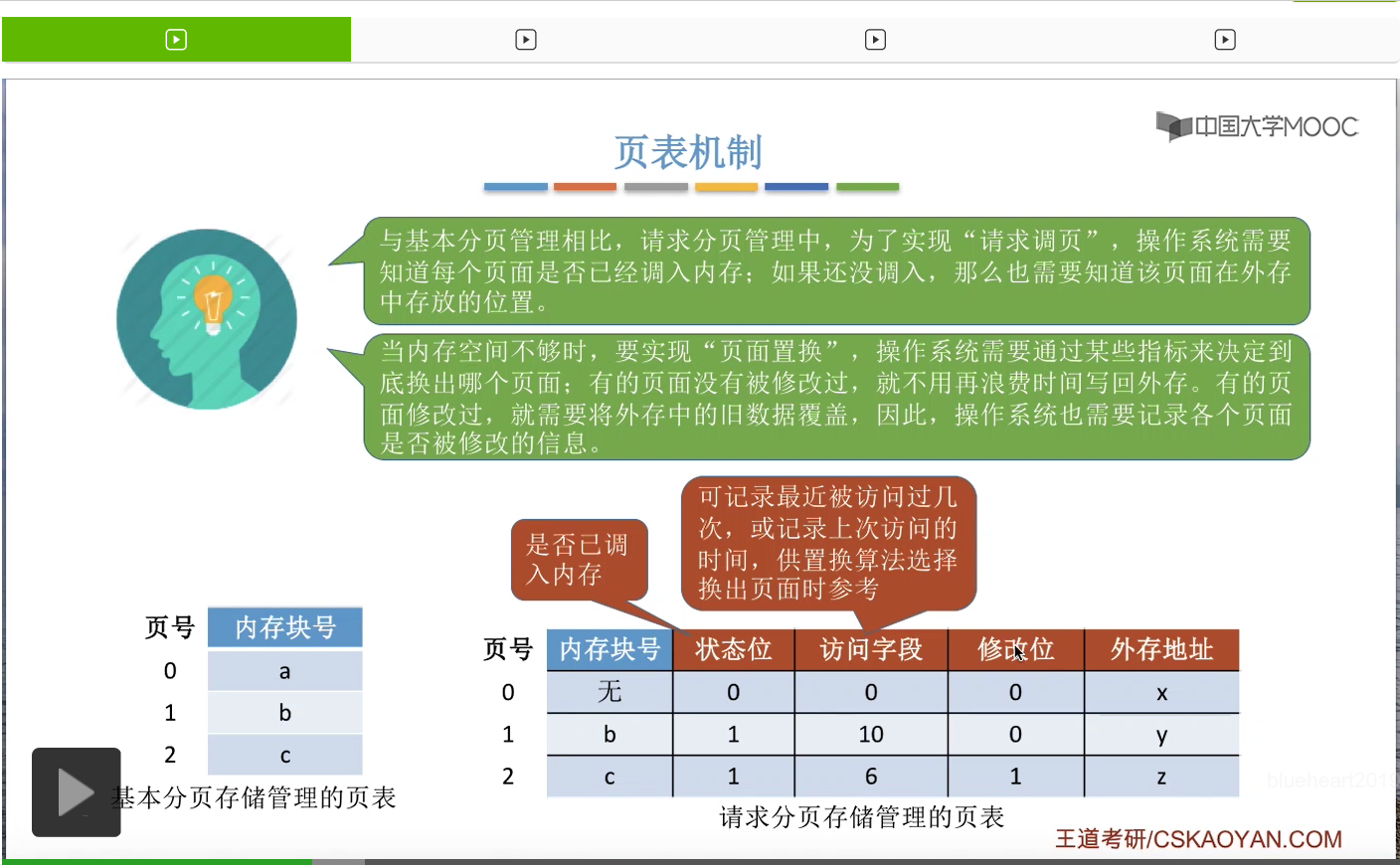
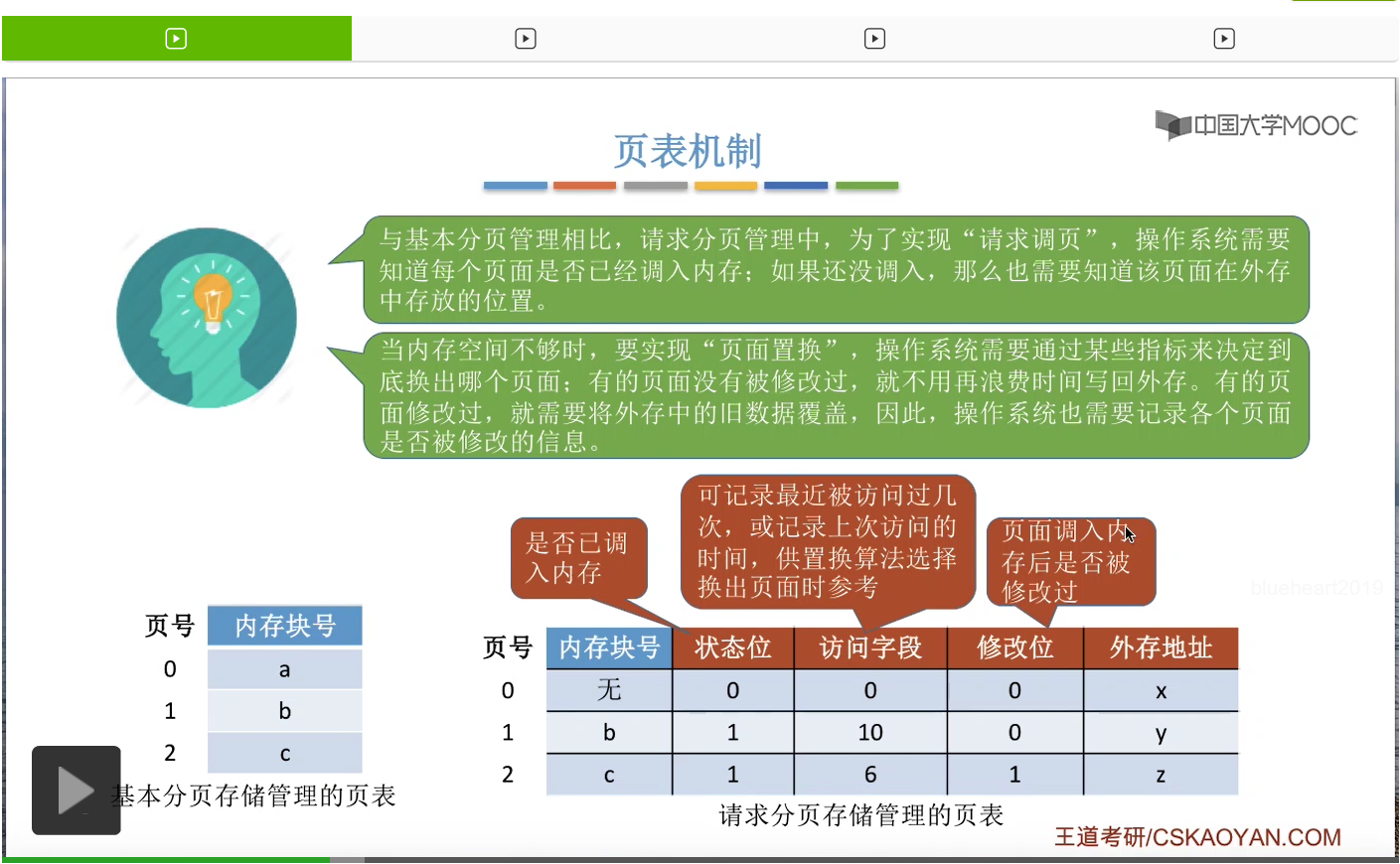
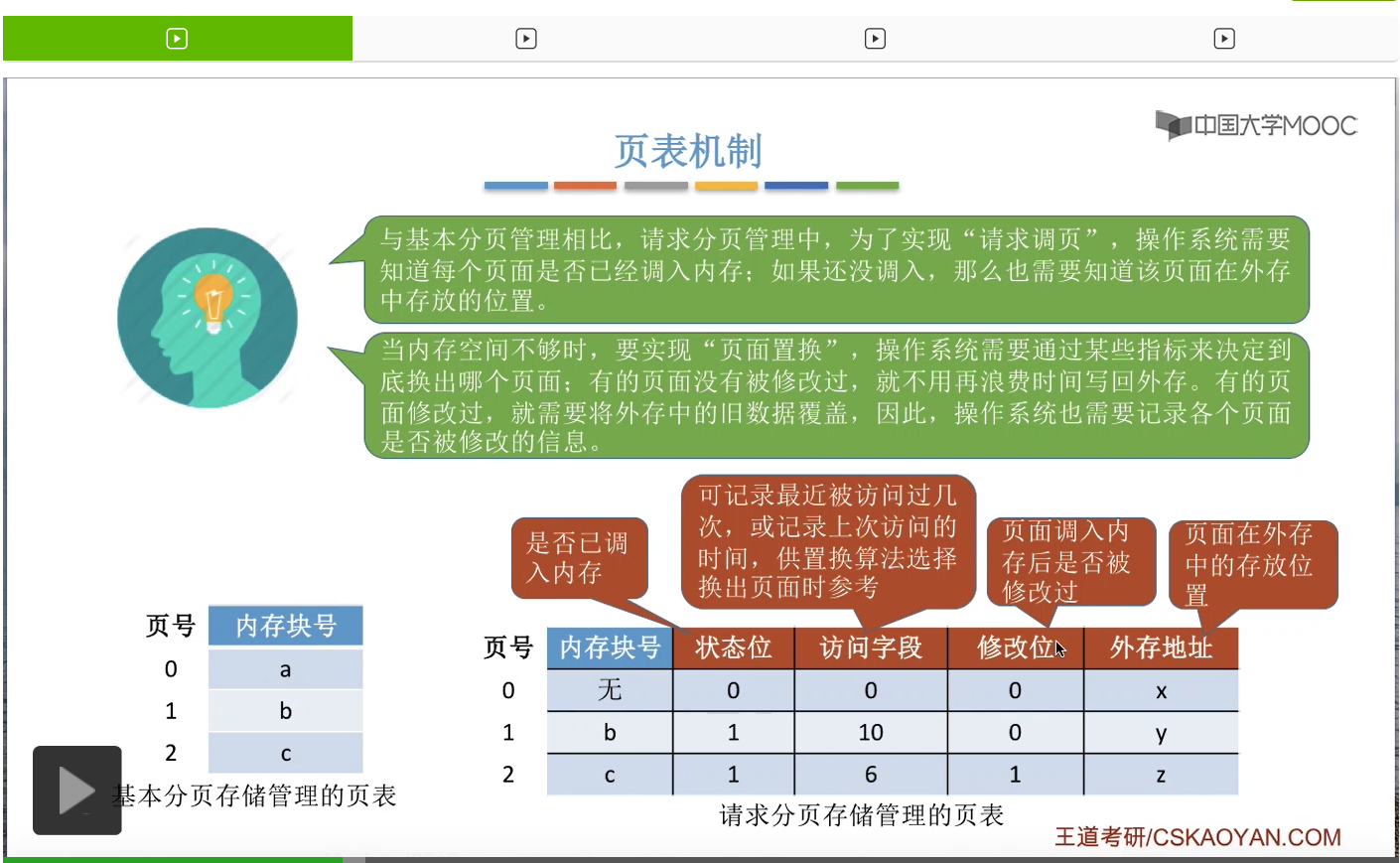
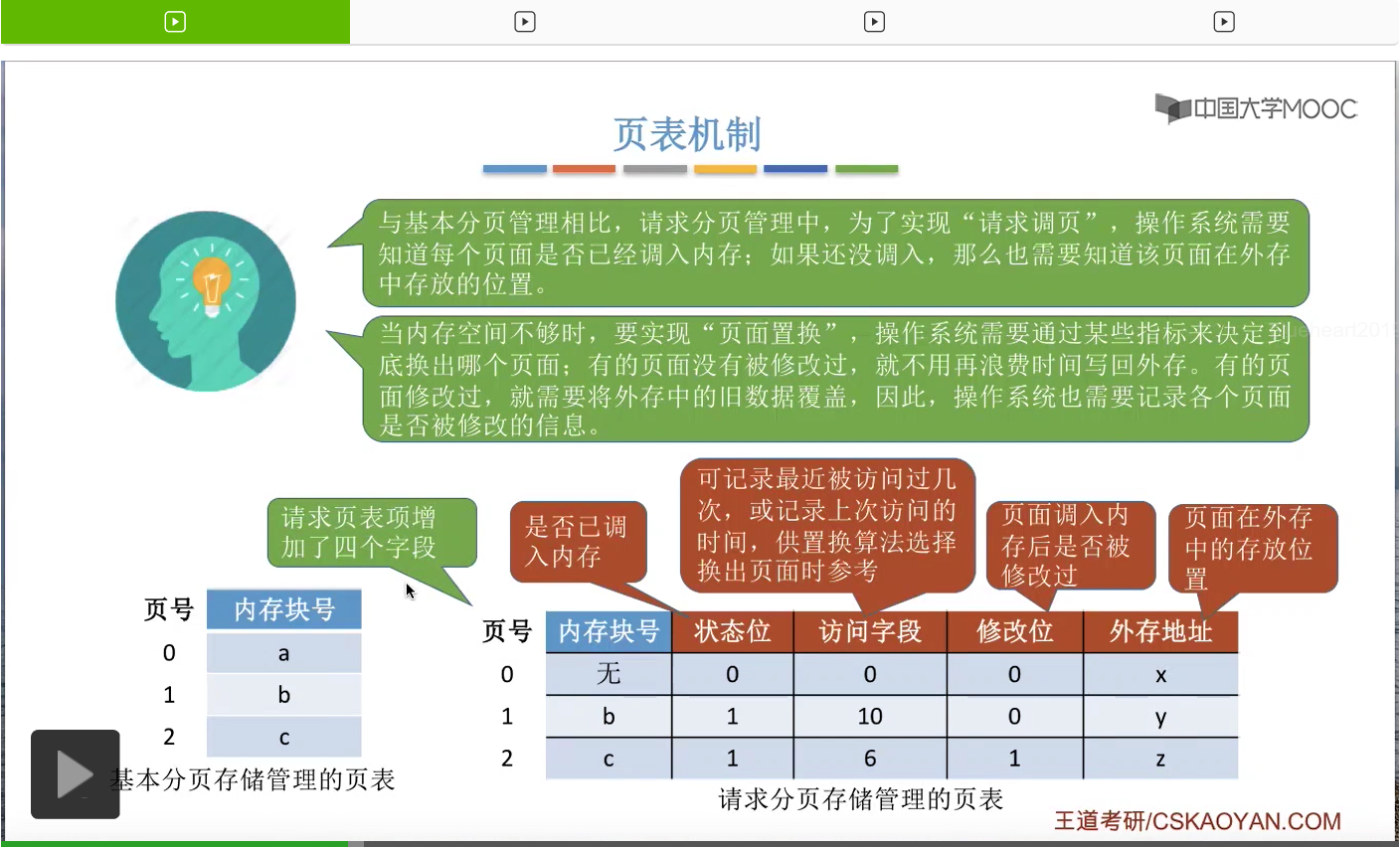
因此,相比于基本分页的页表来说,请求分页存储管理的页表增加了这样的四个字段,

第一个是状态位,状态位就是用于表示此时这个页面到底是不是已经调入内存了。比如说在这个表当中,0号页面的状态位是0,表示0号页面暂时还没有调入内存,那1号页面的状态位是1,表示1号页面此时已经在内存当中了。

第二个新增的数据是访问字段。操作系统在置换页面的时候,可以根据访问字段的这些数据来决定到底要换出哪一个页面。所以我们可以在访问字段当中记录每个页面最近被访问过几次,我们可以选择把访问次数更少的那些页面换出外存。或者我们也可以在访问字段当中记录我们上一次访问这个页面的时间,那这样的话我们可以实现优先地换出很久没有使用的页面这样的事情。所以这是访问字段的功能。
那第三个新增的数据是修改位,就是用来标记这个页面在调入内存之后是否被修改过。因为没有被修改过的页面是不需要再写回外存的。那不写回外存的话就可以节省时间。
第四个需要增加的数据就是各个页面在外存当中存放的位置。
那这是请求分页存储管理方式当中的页表新增的四个字段。
那在有的地方也会把这个页表称为请求页表,然后这个页表称为基本页表或者简称页表。那这是请求分页存储管理当中页表机制产生的一些变化,新增的一些东西。那这也是实现请求调页和页面置换的一个数据结构的基础。
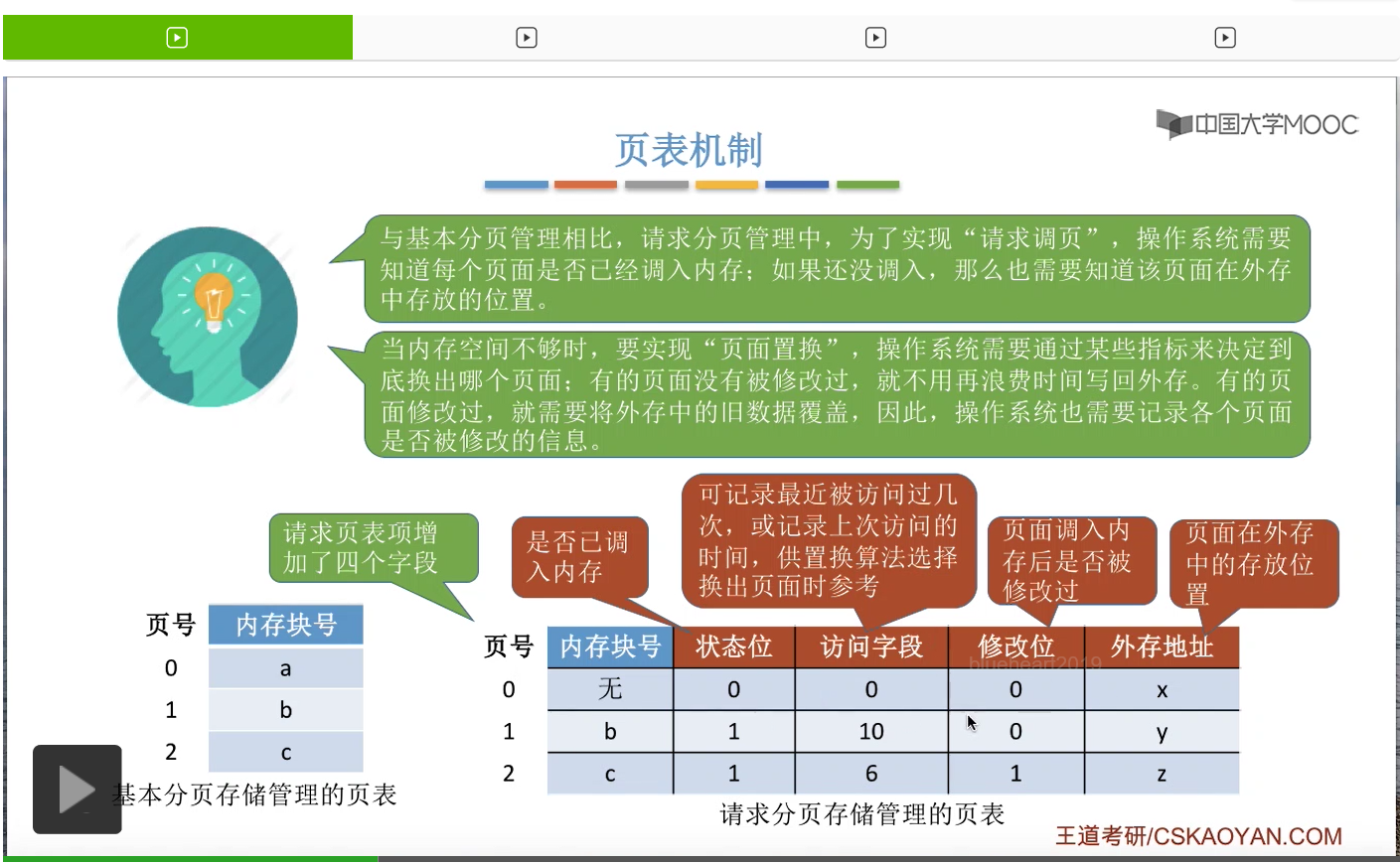
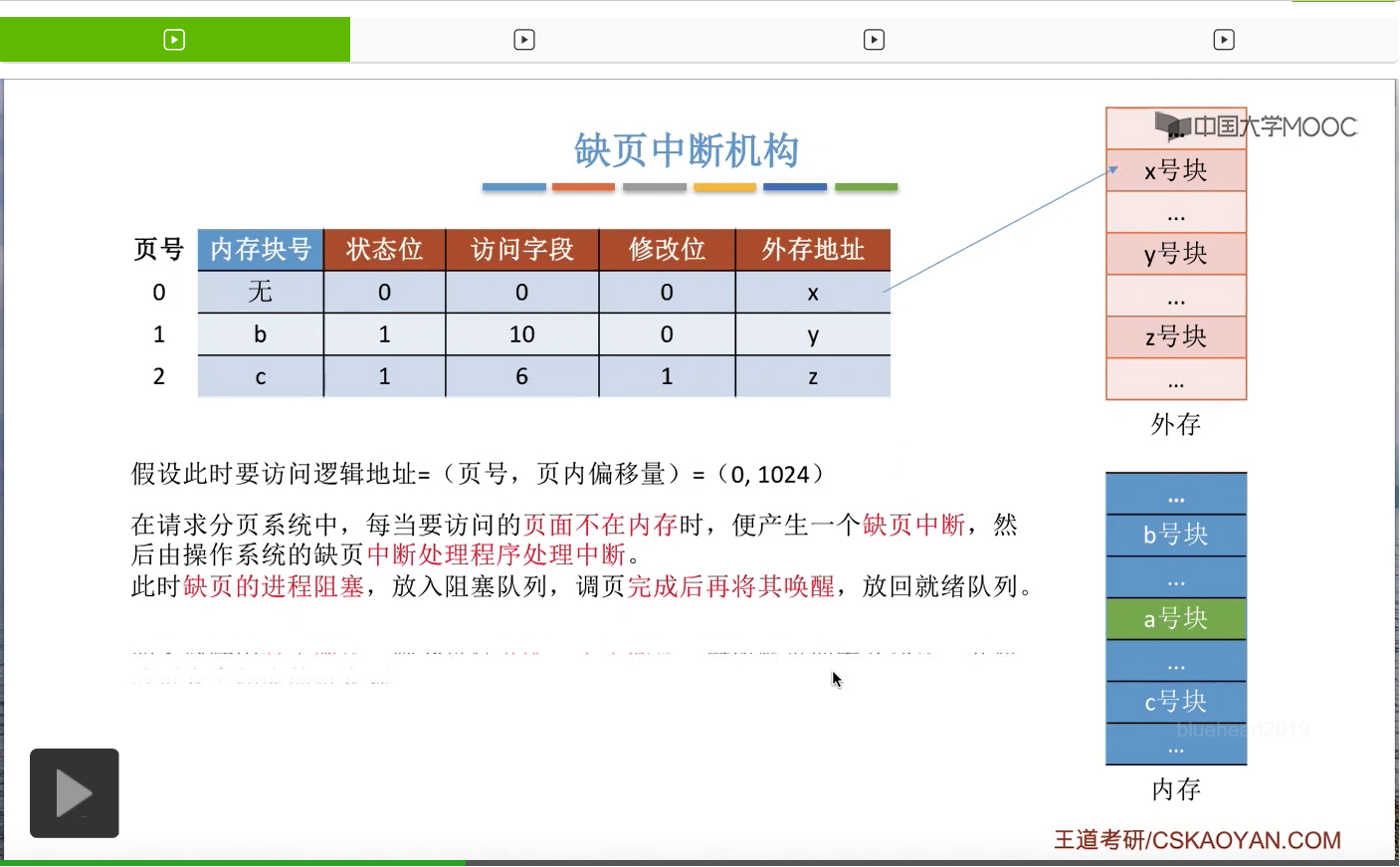
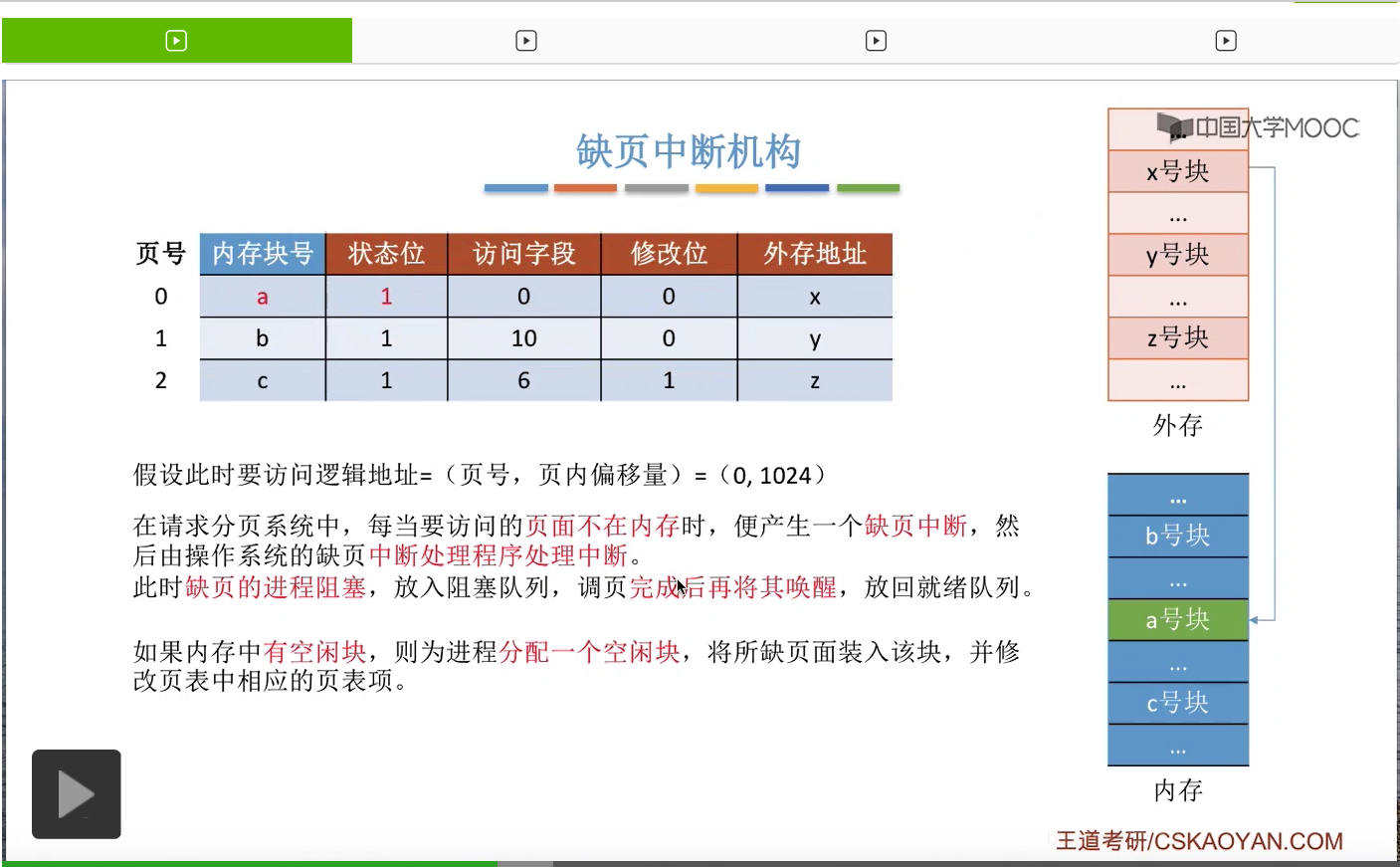
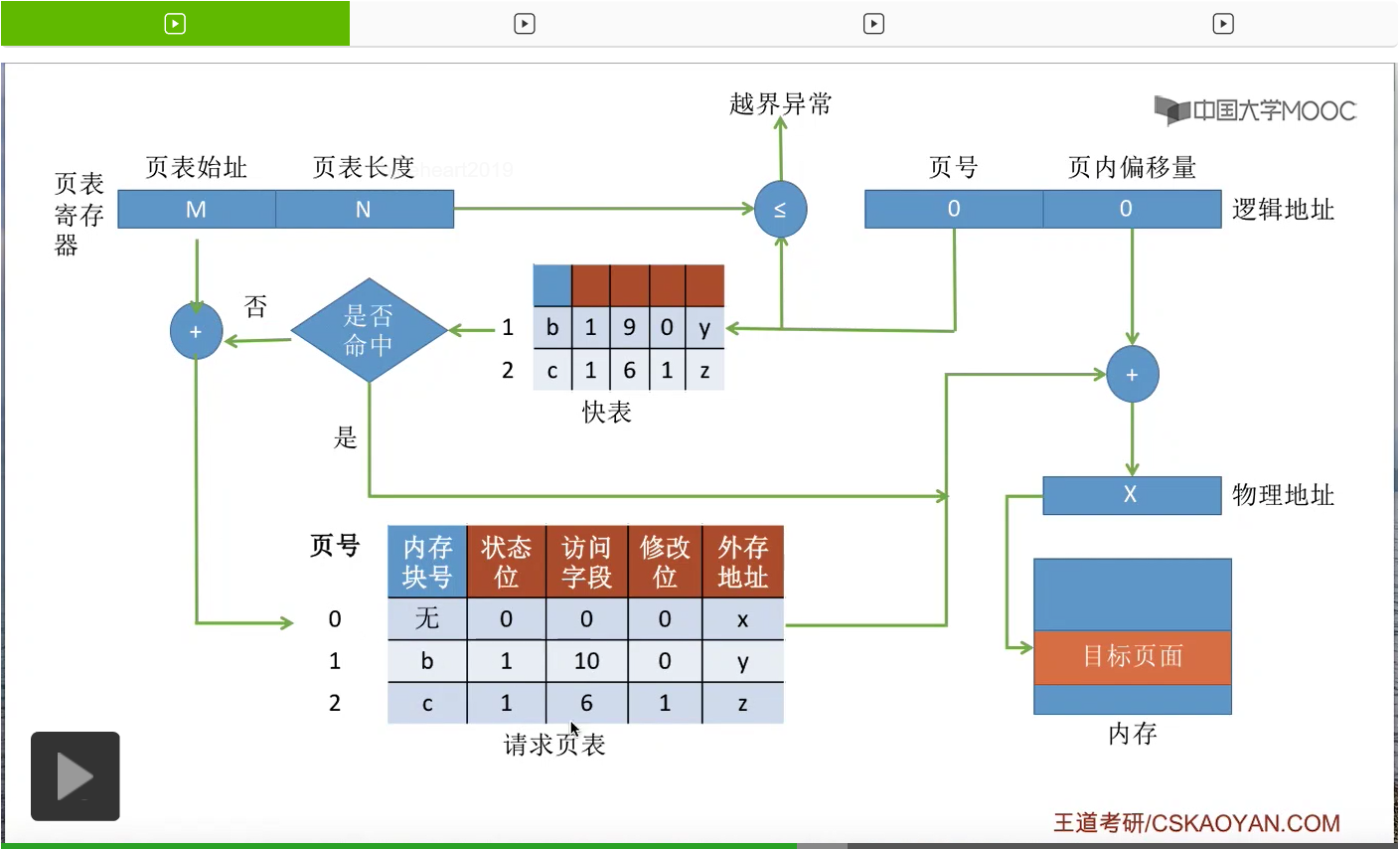
那为了实现请求调页功能,系统当中需要引入缺页中断机构。我们直接来结合一个例子来理解缺页中断机构工作的一个流程。假设在一个请求分页的系统当中,要访问一个逻辑地址,页号为0,页内偏移量为1024。那么为了访问这个逻辑地址,需要查询页表。那缺页中断机构,会根据对应的页表项来判断此时这个页面是否已经在内存当中。如果说没有在内存当中,也就是这个状态位为0的话,那么会产生一个缺页中断信号,之后操作系统的缺页中断处理程序会负责处理这个中断。那由于中断处理的过程需要I/O操作,把页面从外存调入内存,所以在等待I/O操作完成的这个过程当中,之前发生缺页的这个进程应该被阻塞,放入到阻塞队列当中。只有调页的事情完成之后,才把它再唤醒,重新放回就绪队列。
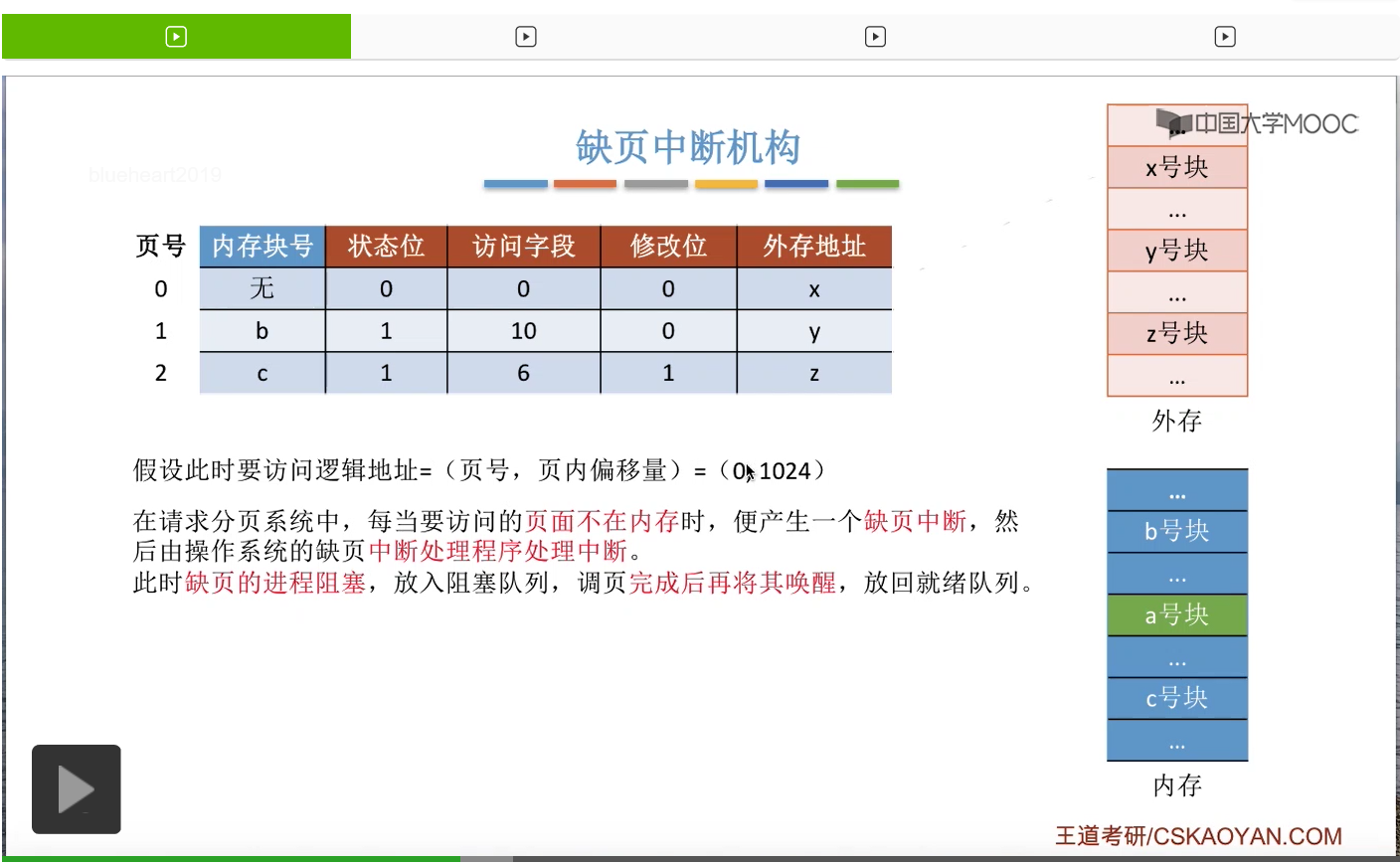
那通过这个页表项就可以知道这个页面在外存当中存放在什么地方。
那如果说此时的内存当中有空闲的块,比如说a号块空闲的话,那就可以把这个空闲块分配给此时缺页的这个进程,再把目标页面从外存放到内存当中。

那相应的也需要修改页表项当中对应的一些数据,那这是第一种情况,就是有空闲的内存块的情况。
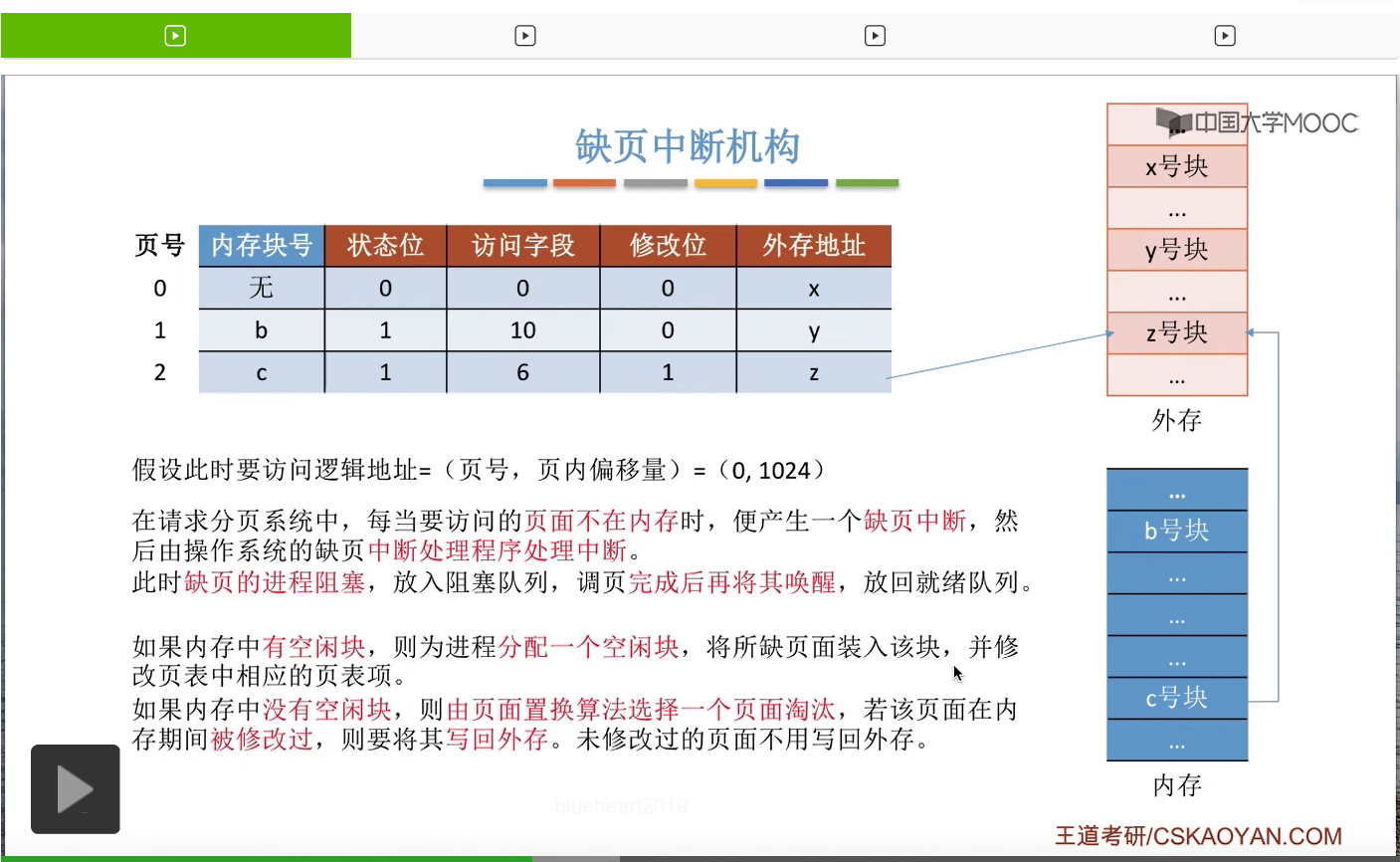
第二种情况,如果说此时内存中没有空闲块的话,那么需要由页面置换算法通过某种规则来选择要淘汰一个页面。

比如说页面置换算法选中了要淘汰2号页面,那由于2号页面的内容是被修改过的,所以2号页面的内容需要从内存再写回外存,把外存当中的那个旧数据给覆盖掉。那这样的话,2号页面以前占有的c号块就可以空出来让0号页面使用了。
于是,可以把0号页面从外存调入内存当中的c号块。
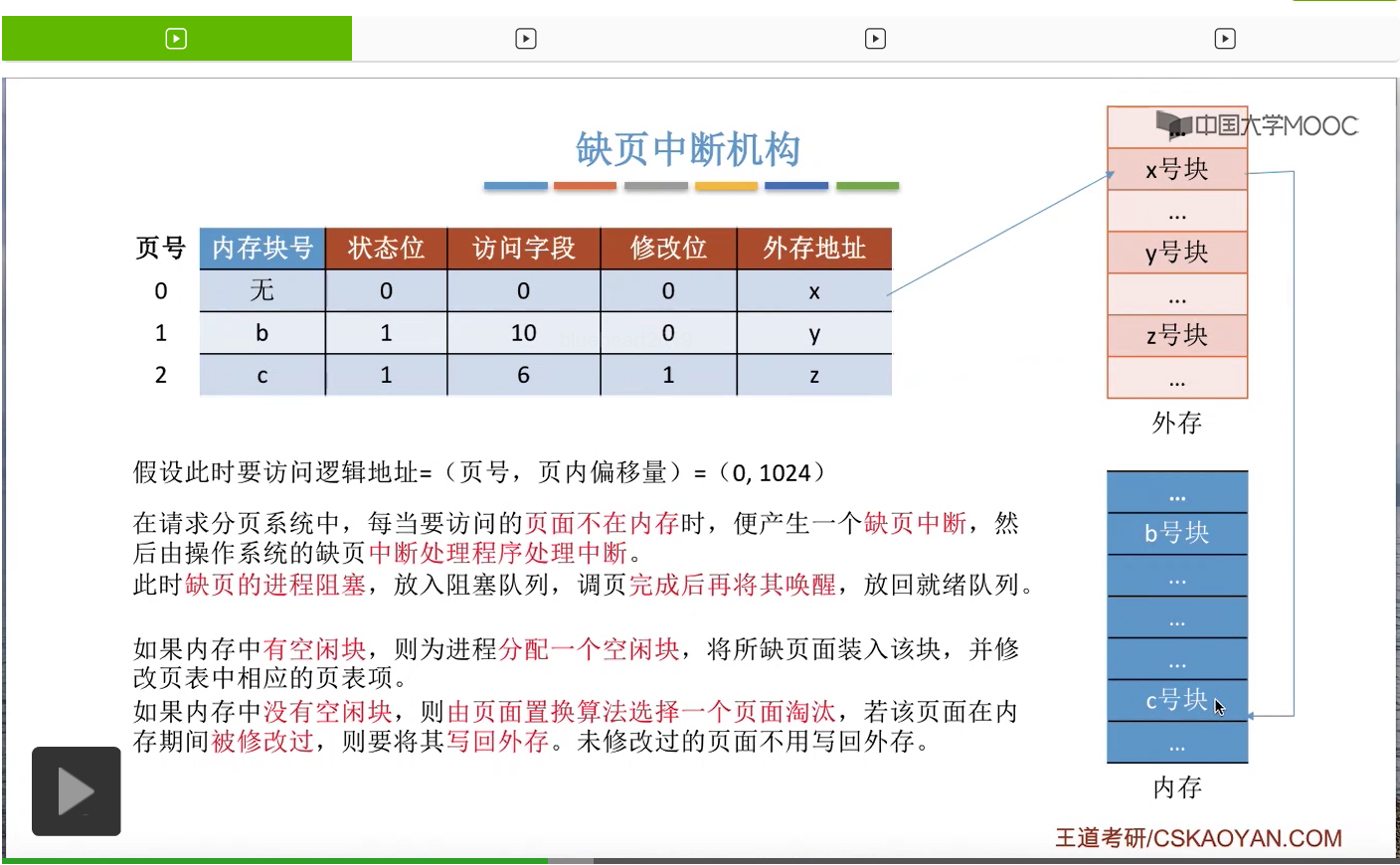
那相应的,我们也需要把换出外存的页面还有换入外存的页面相应的那些数据给更改,那这是第二种情况。就是内存当中没有空闲块的时候,需要用页面置换算法淘汰一个页面。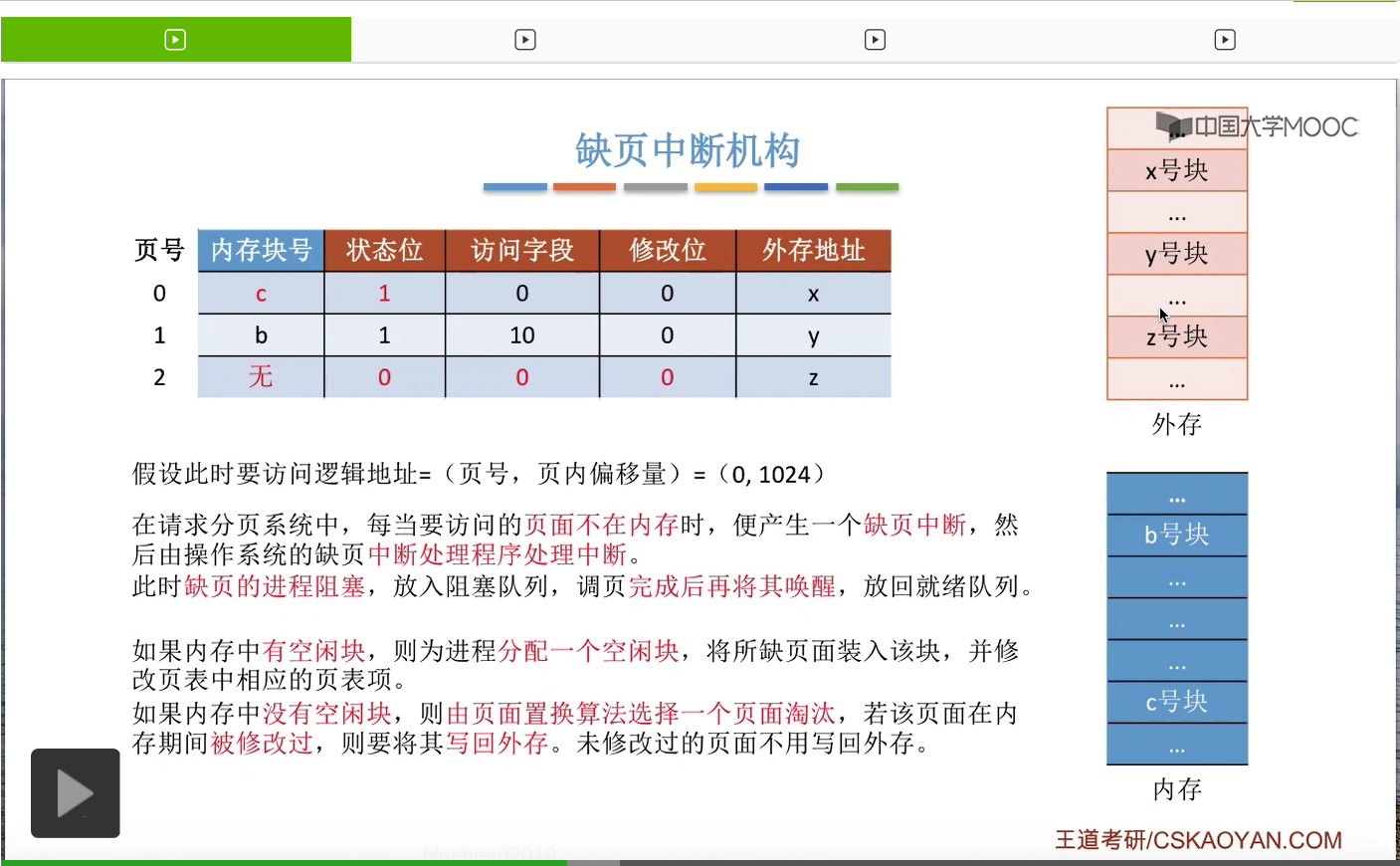
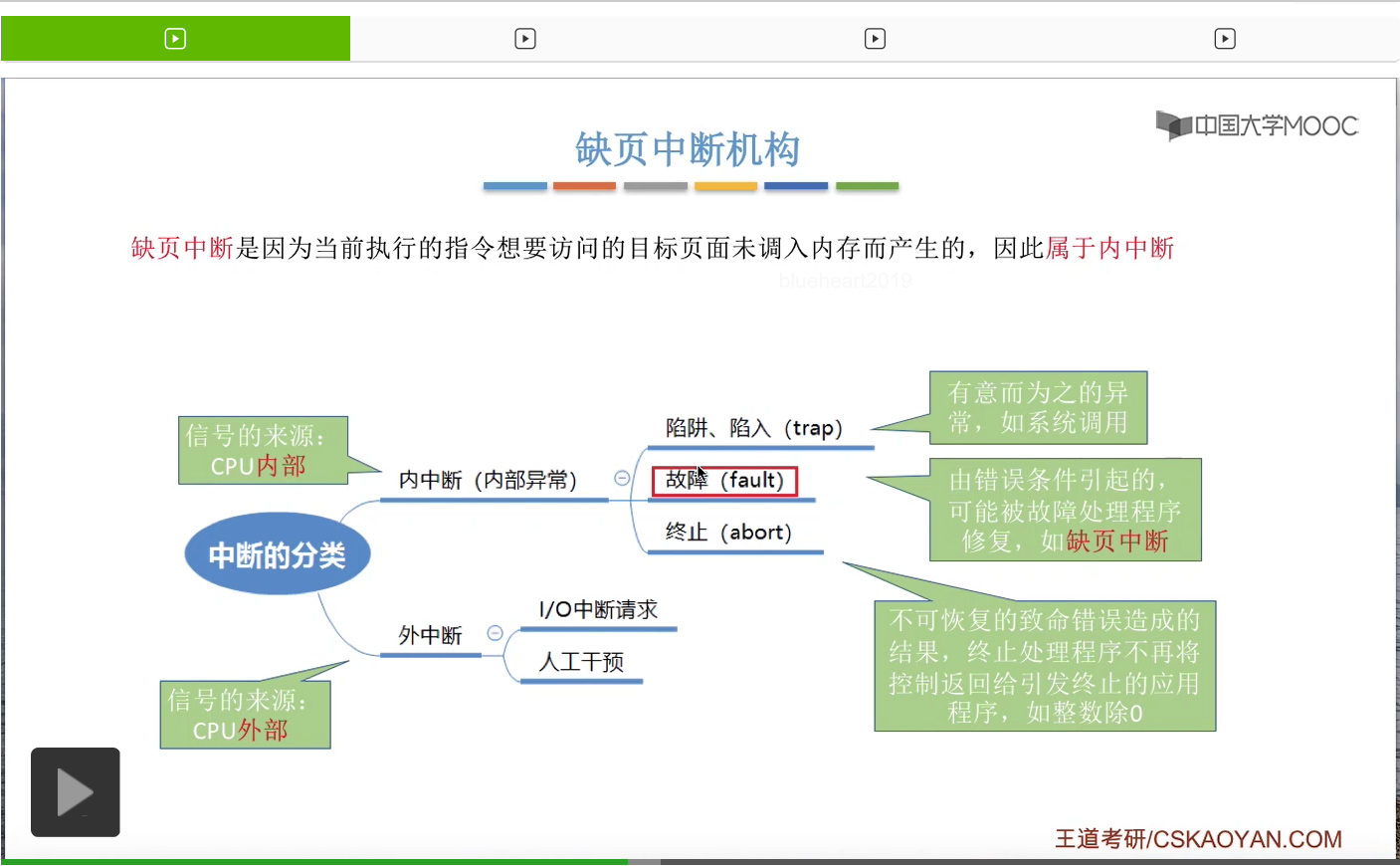
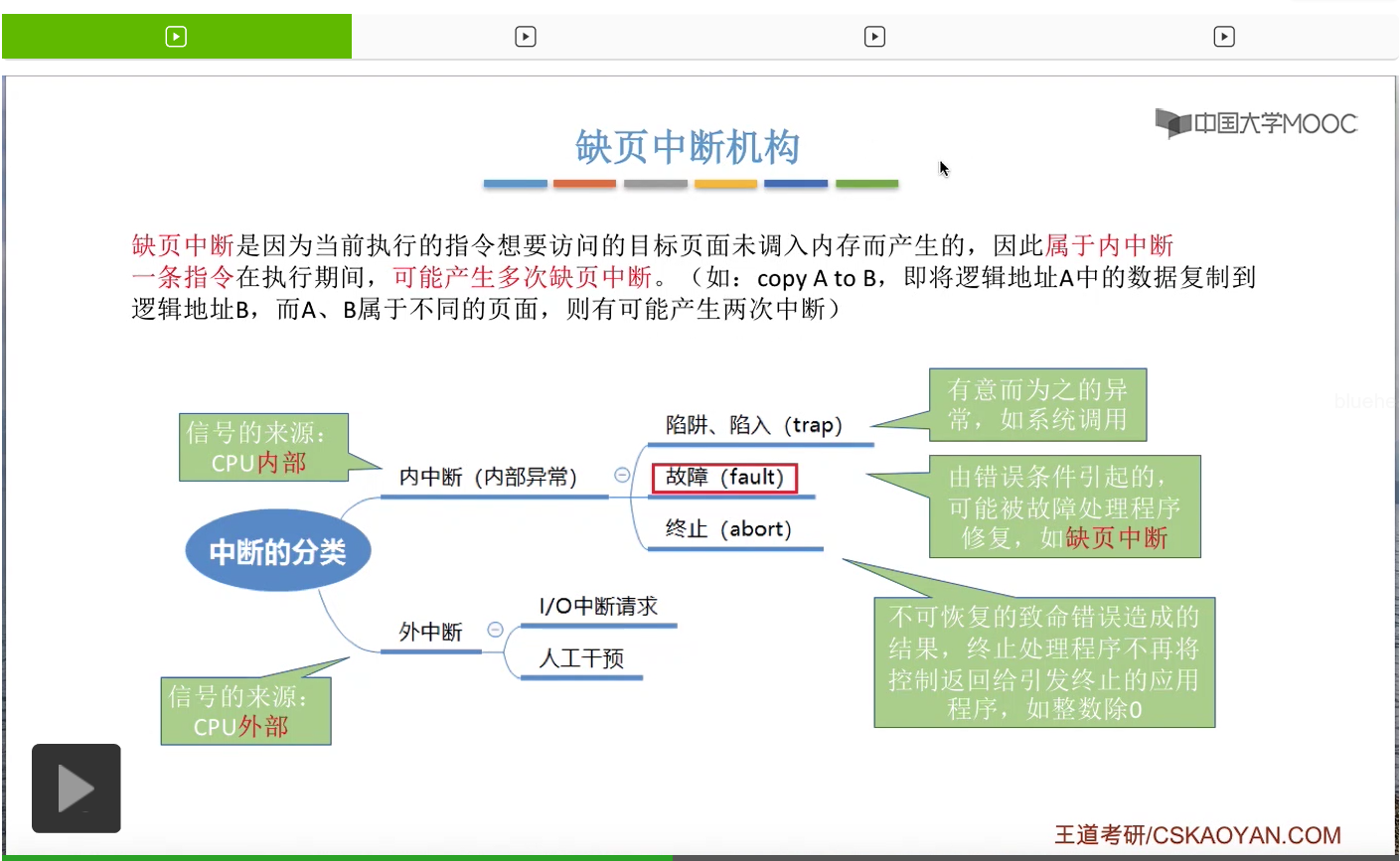
那缺页中断的发生肯定和当前执行的指令是有关的。由于这个指令想要访问某一个逻辑地址,而系统又发现这个逻辑地址对应的页面还没有调入内存,因此才发生了缺页中断。那由于它和当前执行的指令有关,因此缺页中断是属于内中断的。
还记得咱们之前讲的内中断和外中断的分类吗?内中断可以分为陷阱、故障还有终止这样三种类型。其中故障这种内中断类型是指有可能被故障处理程序修复的,比如说缺页中断这种异常的情况是有可能被操作系统修复的,因此它是属于故障这种分类。
另外呢我们需要注意的是,一条指令在执行的过程当中,有可能会产生多次缺页中断。因为一条指令当中可能会访问多个内存单元,比如说把逻辑地址A当中的数据复制到逻辑地址B当中。那如果说这两个逻辑地址属于不同的页面,并且这两个页面都没有调入内存的话,那么在执行这一条指令的时候就有可能会产生两次中断。那通过之前的讲解我们会发现,引入了缺页中断机构之后,系统才能实现请求调页这样的事情。
那接下来我们再来看一下请求分页存储管理与基本分页存储管理相比,在地址变换的时候需要再多做一些什么事情。

第一个事情,在查找到页面对应的页表项的时候,一定是需要对这个页面是否在内存这个状态进行一个判断。

第二个事情,在地址变换的过程当中,如果说我们发现此时想要访问的页面暂时没有调入内存,但是此时内存当中又没有空闲的内存块的时候,那么在这个地址变换的过程当中,也需要进行页面置换的工作,换出某一些页面来腾出内存空间。

第三个与基本分页存储管理不同的就是,当页面调入或者调出,或者页面被访问的时候,需要对与它对应的这些页表项进行一个数据的修改。所以我们在理解和记忆请求分页存储管理当中地址变换过程的时候,需要重点关注这三件事情需要在什么时候进行。
那与基本分页存储管理相同,请求分页存储管理在逻辑地址变换为物理地址的过程当中,需要做的第一件事情同样是检查页号的合法性,看一下页号是否越界。那如果页号没有越界的话,就会查询此时在快表当中有没有这个页号对应的页表项,那如果快表命中,就可以直接得到最终的物理地址。如果快表没有命中的话,就需要查询内存当中的慢表。
那在找到对应的页表项之后,需要检查此时这个页面是否已经在内存当中。如果说这个页面此时没有在内存当中的话,那缺页中断机构会产生一个缺页中断的信号,之后就会由操作系统的缺页中断处理程序进行处理包括请求调页还有页面置换那一系列的事情。那当然,当页面调入之后也需要修改这个页表项对应的一些数据。

那这个地方注意一个细节。在请求分页管理方式当中,如果说能够在快表当中找到某一个页面对应的页表项。那么就说明这个页面此时肯定是在内存当中的,如果一个页面被换出了外存的话,那么快表项当中对应的这些页表项也应该被删除。所以只要快表命中,那么就可以直接根据这个内存块号还有页内偏移量得到最终的物理地址了,这个页面肯定是在内存当中的。那这个地方并没有像基本分页管理方式当中那样,一步一步很仔细地分析。那其实大家只需要关注请求分页管理方式与基本分页管理方式相比,不同的这些步骤就可以了。

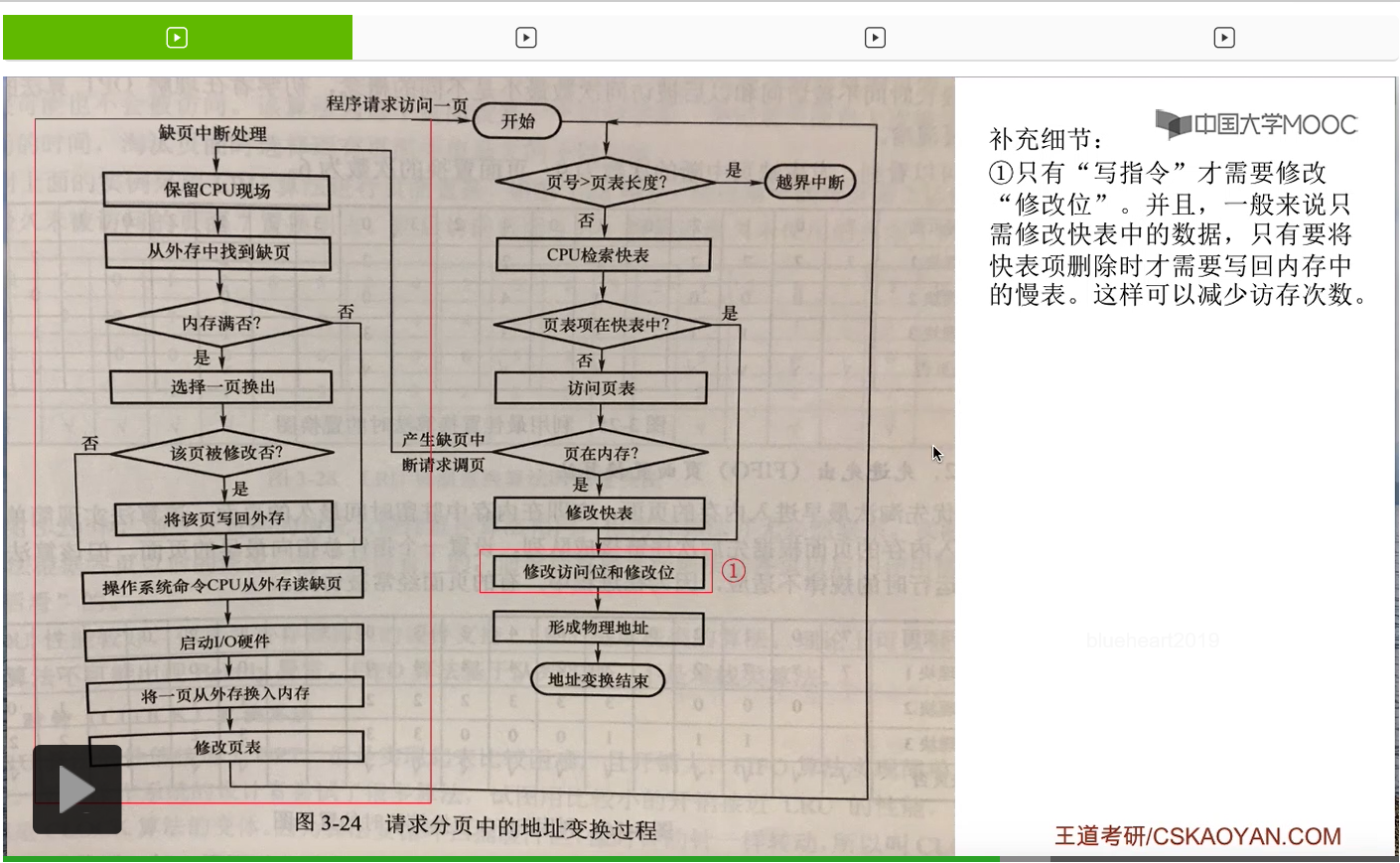
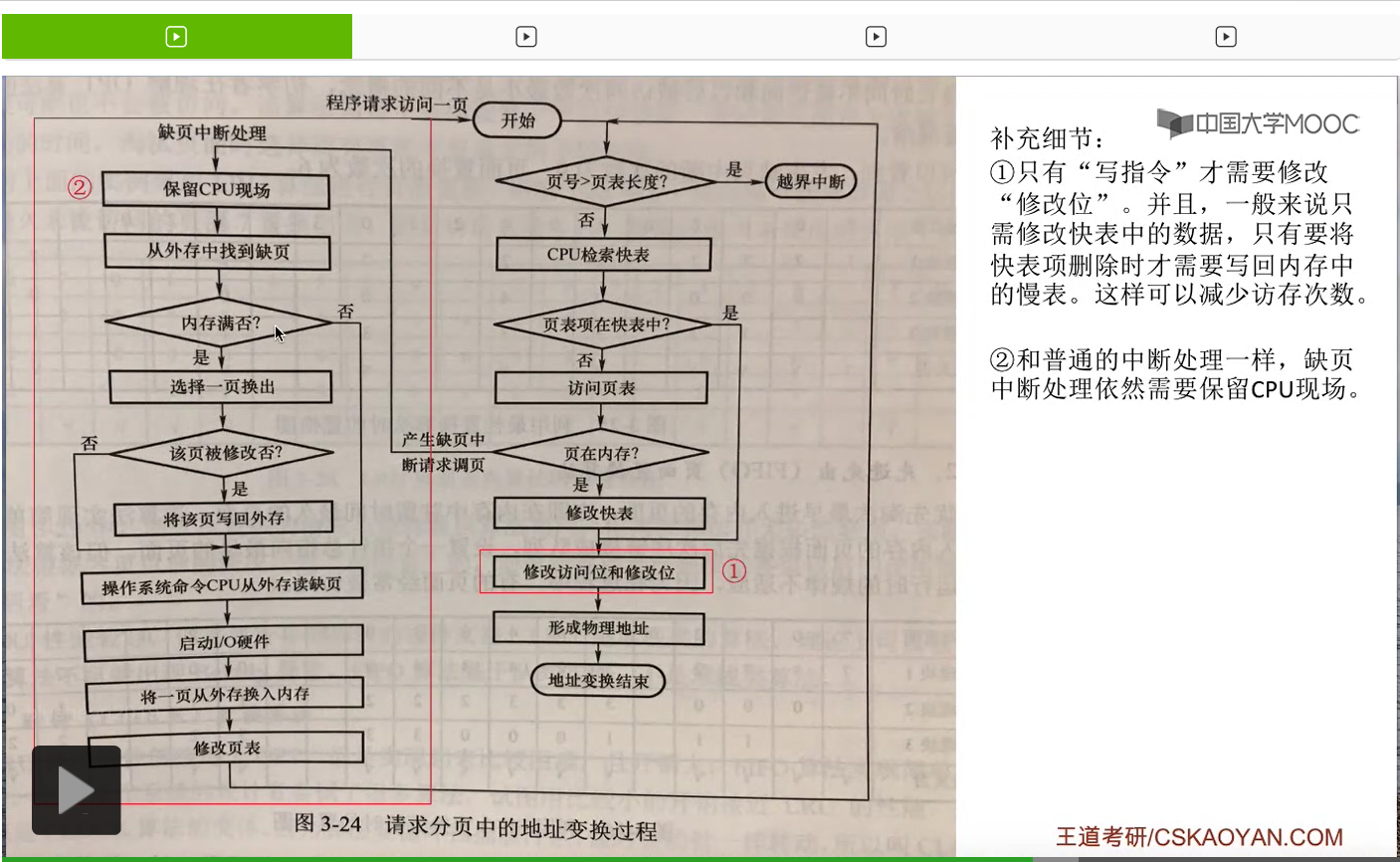
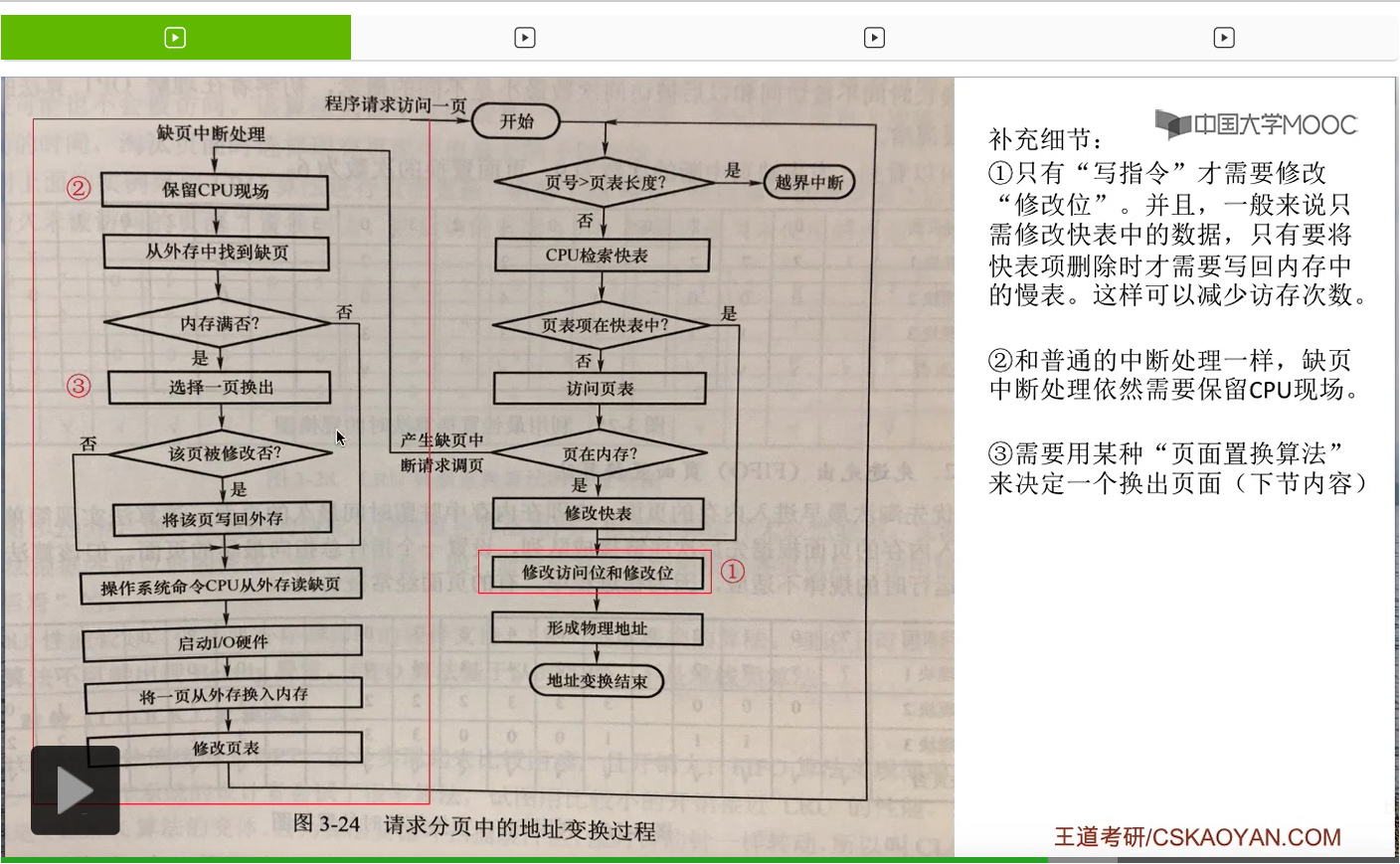
那其实课本当中给出了一个很完整的请求分页管理方式当中,地址变换的一个流程图。大家需要重点关注的是这两个红框部分当中的内容。这些内容就是请求分页管理方式与基本分页管理方式相比增加的一些步骤和内容。
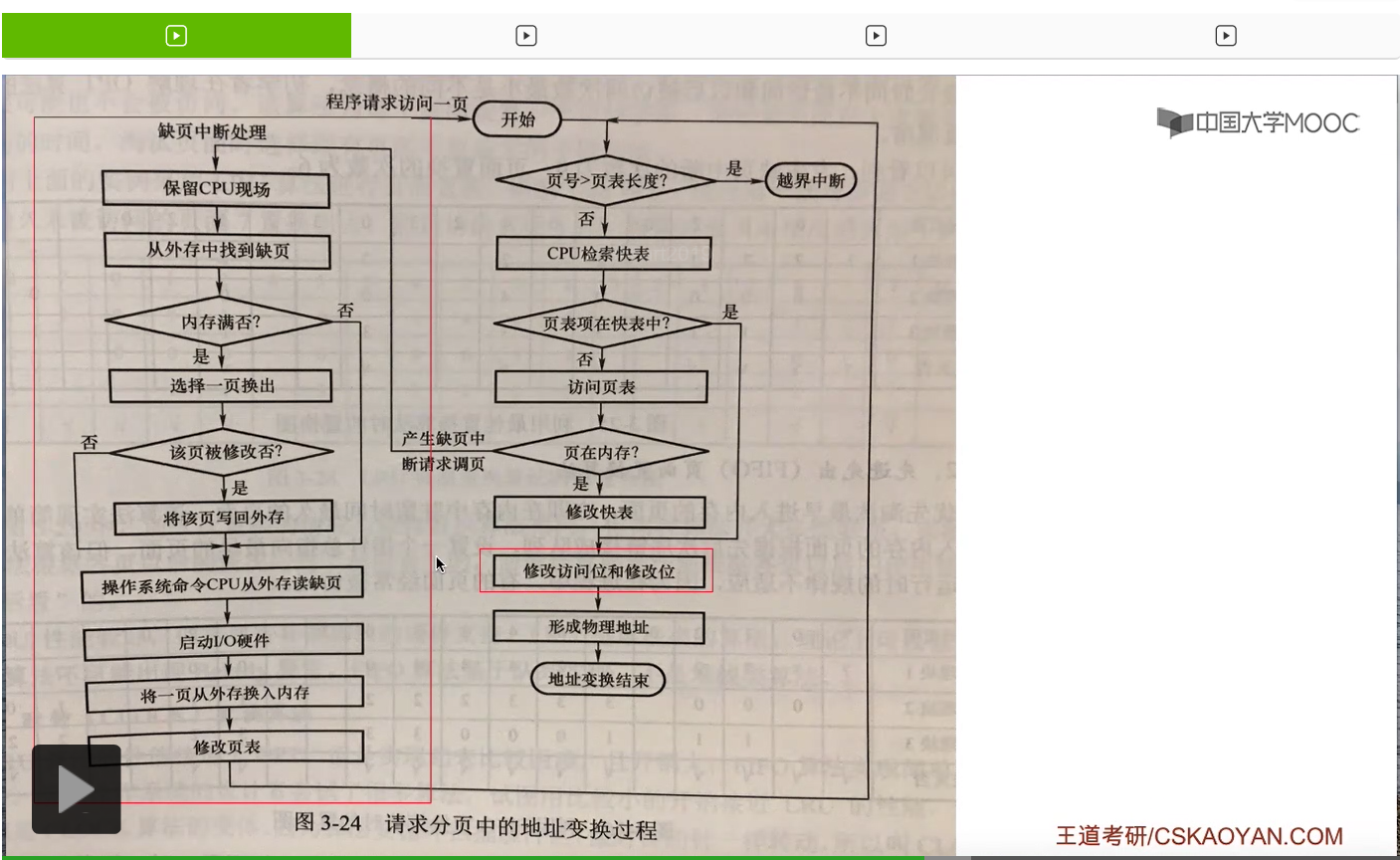
那这儿根据这个图补充几个大家可能注意不到的细节。第一个地方,通过这个图,特别是这个步骤,大家有可能会发现,似乎只要访问了某一个页面,那么这个页面相关的修改位是不是就需要修改呢?其实并不是。只有执行写指令的时候,才会改变这个页面的内容。如果说执行的是读指令,那么就其实不需要修改这个页面对应的修改位。并且一般来说,在访问了某一个页面之后,只需要把这个页面在快表当中对应的表项的那些数据修改了就可以了。那只有它所对应的那些表项要从快表当中删除的时候,才需要把这些数据从快表再复制回慢表当中。那采取这样的策略的话就可以减少访问内存当中慢表的次数,可以提升系统的性能。
第二个需要注意的地方是,在产生了缺页中断之后,缺页中断处理程序也会保存CPU现场。那这个地方其实和普通的中断处理是一样的。在中断处理的时候,需要保存CPU的现场,然后让这个进程暂时进入阻塞态。那只有这个进程再重新回处理机运行的时候,才需要再恢复它的CPU现场。
第三个需要注意的地方是,内存满的时候需要选择一个页面换出。那到底换出哪个页面,这是页面置换算法要解决的问题,也是咱们下个小节当中会详细介绍的内容。
第四个需要注意的点是,如果我们要把页面写回外存,或者要把页面从外存调入内存的话,那么需要启动I/O硬件。所以其实把页面换入换出的工作都是需要进行慢速的I/O操作的。因此,如果换入换出操作太频繁的话,那系统会有很多的时间是在等待慢速的I/O操作完成的。因此页面的换入换出不应该太频繁。
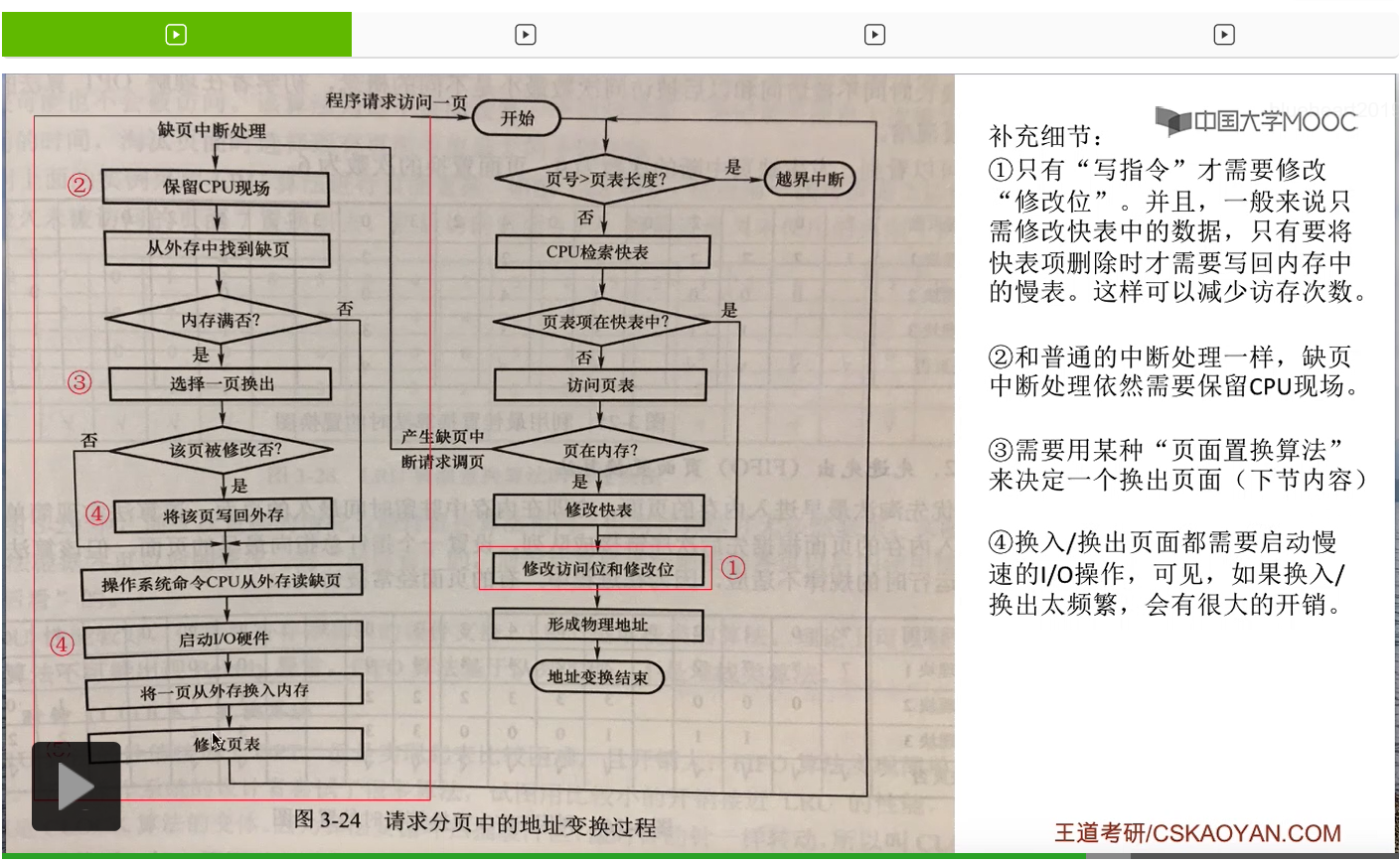
第五个需要注意的地方。当我们把一个页面从外存调入内存之后,需要修改内存当中的页表,但是其实我们同时也需要把这个页表项复制到快表当中。

所以由于新调入的页面在快表当中是有对应的页表项的,因此在访问一个逻辑地址的时候,如果发生了缺页,那么地址变换变换的步骤应该是这样的:第一步首先是查询快表,如果快表没有命中的话,才会查询内存当中的慢表。然后通过慢表会发现此时页面并没有调入内存当中。之后系统会进行调页相关的操作,那在页面调入之后,不仅要修改内存当中的慢表,也需要把这个页表项同时加入到快表当中。于是之后可以直接从快表当中得到这个页面存放的位置,而不需要再查询慢表。

那这是地址变换过程当中大家需要注意的几个点。那其他的流程其实并不难理解,右半部分的这些流程其实和基本分页存储管理方式进行地址变换的这个过程是大同小异的,只不过是增加了修改这个页表项相应的内容这样一个步骤。然后左半部分是新增的一系列处理,那要做的无非也就是两件事。第一件事就是当我们发现所要访问的页面没有在内存当中的时候,需要把页面从外存调入内存。那如果说内存此时已经满了,那需要做页面置换的工作。那当调页还有页面置换这些工作完成之后,也需要对页表还有快表当中的对应的一些数据进行修改。所以其实只要理解了我们应该在什么时候请求调页,又应该在什么时候进行页面置换,当调页和页面置换完成之后,又需要对哪些数据结构进行修改。只要知道这三个事情,那就可以掌握请求分页管理方式地址变换的这些精髓了。

与基本分页管理方式相比,请求分页管理方式在页表当中增加了状态位、访问字段、修改位还有外存地址这样几个数据。那大家需要理解这几个数据分别有什么作用。那之后我们介绍了缺页中断机构,那在引入了缺页中断机构之后,如果一个页面暂时没有调入内存,那就会产生一个缺页中断信号,然后之后系统会对这个缺页中断进行一系列的处理。另外呢,大家需要注意的是缺页中断它是一个内中断,它和当前执行的指令有关。并且一条指令在执行的过程当中有可能会访问到多个内存单元,而这些内存单元有可能是在不同的页面当中的,因此一条指令执行的过程当中有可能会产生多次缺页中断。那最后我们介绍了请求分页管理方式的地址变换机构,其实我们只需要重点关注与基本分页方式不同的那些地方。第一,在找到页表项的时候需要检查页面是否在内存当中,由此来判断此时是不是需要请求调页。那在调页的过程当中如果发现此时内存当中已经没有空闲块,那我们还需要进行换出页面的操作。另外,在调入和换出了一些页面之后,我们也需要修改与这些页面对应的那些页表项。那除了这些步骤以外,其他的其实和基本分页存储管理当中地址变换的过程并没有太大的区别。那这个小节的内容在于理解,不需要死记硬背。大家还需要通过课后习题进行进一步的巩固和理解。
在这个小节中我们会学习请求分页存储管理当中很重要的一个知识点考点————页面置换算法。

那么通过之前的学习我们知道,在请求分页存储管理当中,如果说内存空间不够的话,那么操作系统会负责把内存当中暂时用不到的那些信息先换出外存。那页面置换算法其实就是用于选择到底要把哪个页面换出外存。
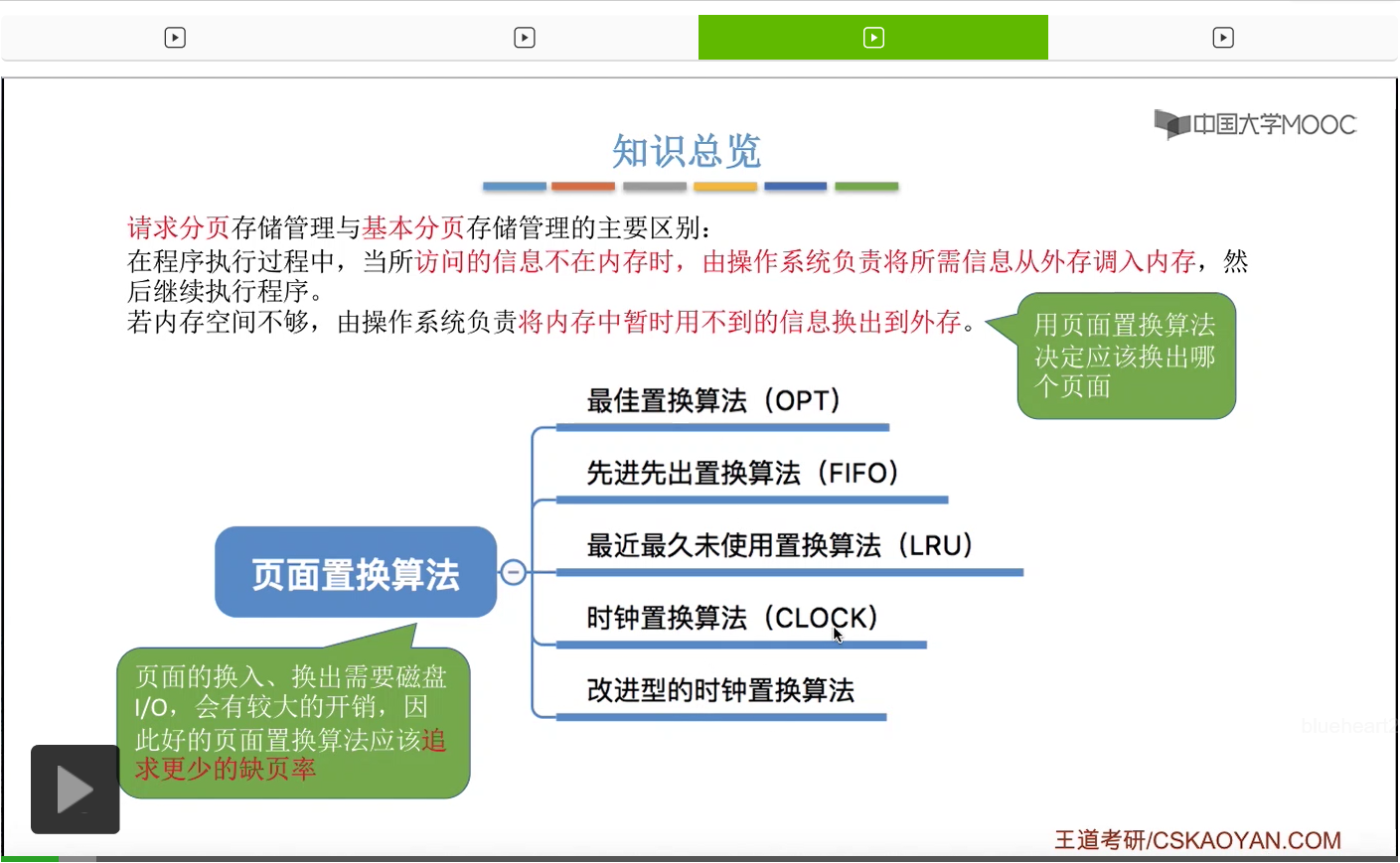
那通过之前的学习我们知道,页面的换入换出其实是需要启动磁盘的I/O的,因此它是会造成比较大的时间开销。所以一个好的页面置换算法应该尽可能地追求更少的缺页率,也就是让换入换出的次数尽可能地少。那这个小节中,我们会介绍考试中要求我们掌握的五种页面置换算法,分别是最佳置换、先进先出、最近最久未使用还有时钟置换、改进型的时钟置换这样五种。那除了注意它们的中文名字之外,大家注意也需要能够区分它们的英文缩写到底分别是什么。
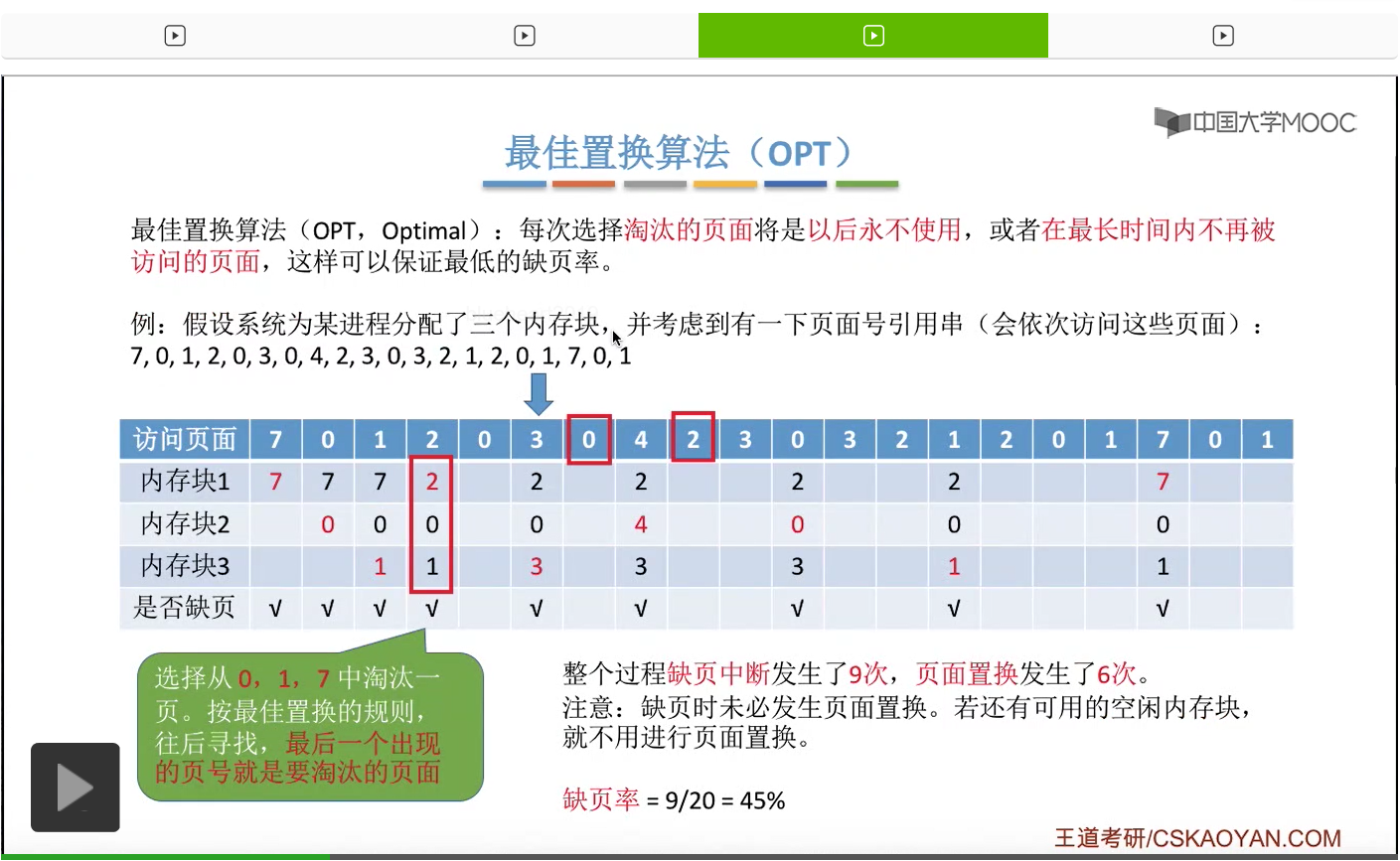
那我们按从上至下的顺序依次介绍。首先来看什么是最佳置换算法,其实最佳置换算法的思想很简单。由于置换算法需要追求尽可能少的缺页率,那为了追求最低的缺页率,最佳置换算法在每次淘汰页面的时候选择的都是那些以后永远不会被使用到的页面,或者在之后最长的时间内不可能再被访问的页面。
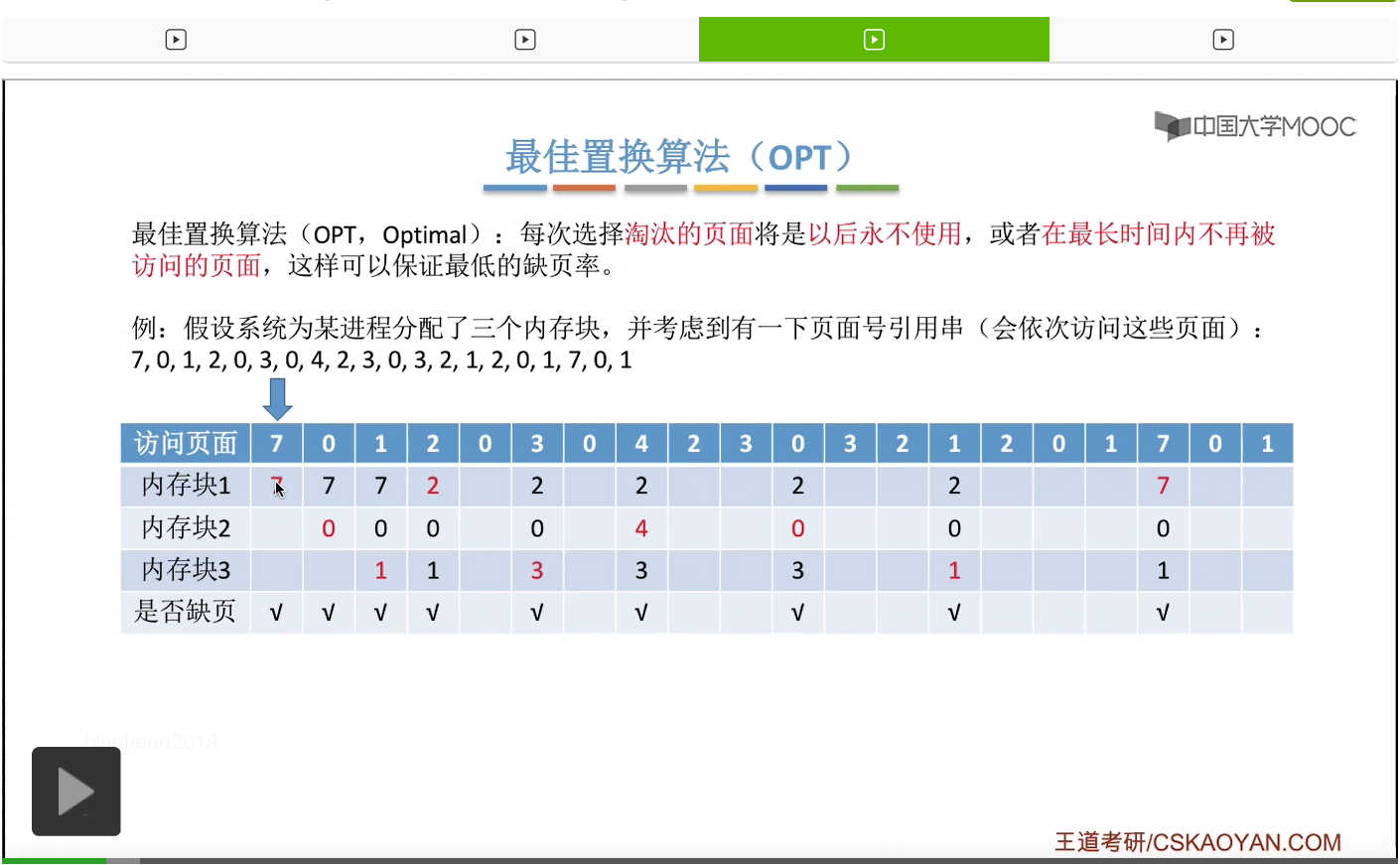
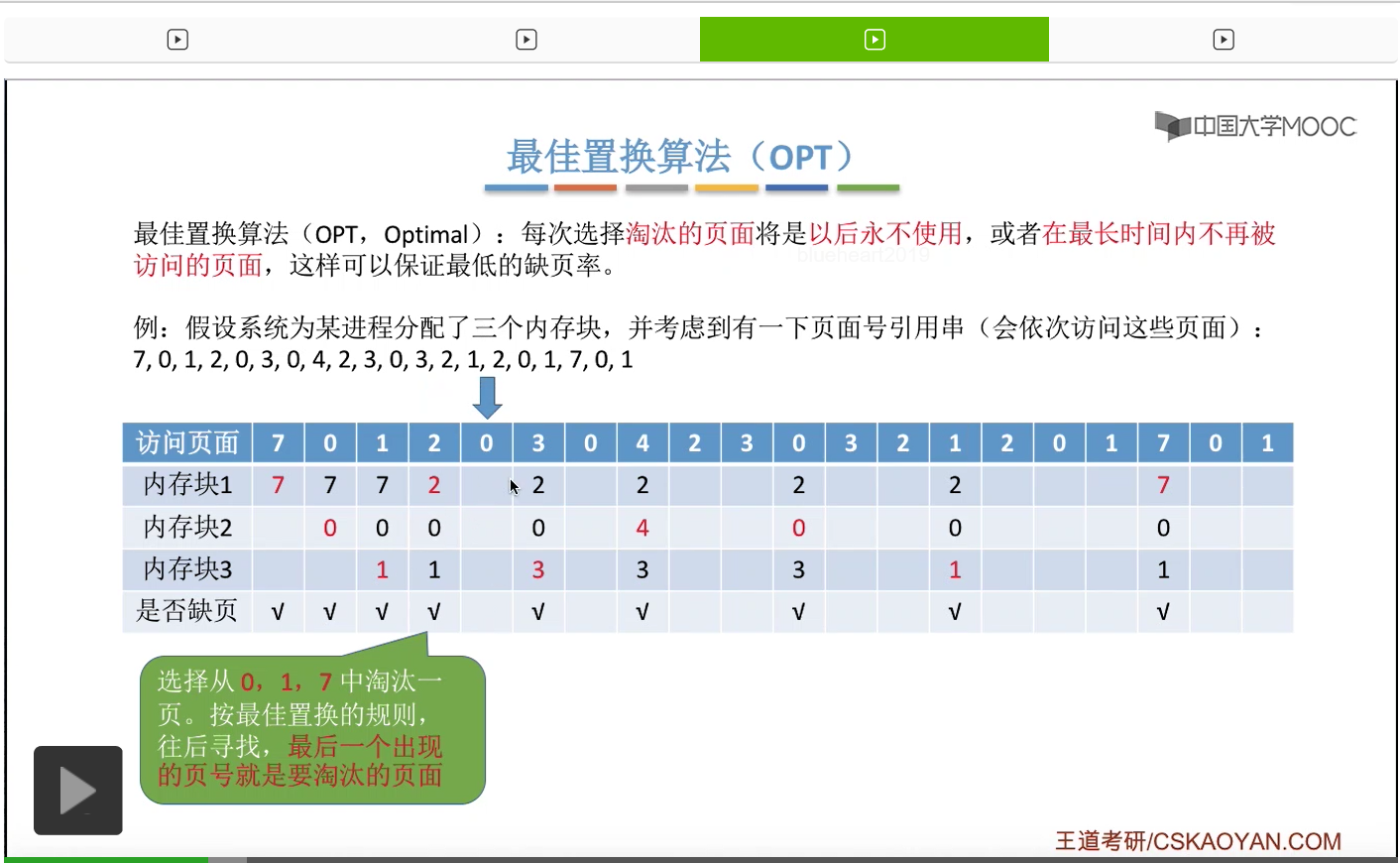
那根据最佳置换算法的规则,我们要选择的是在今后最长时间内不会被使用到的页面,所以其实我们在手动做题的时候,可以看一下它的这个序列。

我们从当前访问的这个页号开始往后寻找,看一下此时在内存当中的0、1、7这三个页面出现的顺序到底是什么。那最后一个出现的序号肯定就是在之后最长时间内不会再被访问的页面。

所以从这儿往后看,0号页面是最先出现的,

然后一直到这个位置我们发现1号页面也开始出现了。所以0、1、7这三个页面当中0号和1号会在之后依次被使用,但是7号页面是在之后最长的时间内不会再被访问到的页面。因此我们会选择淘汰7号页面,然后让2号页面放入到7号页面原先占有的内存块也就是内存块1当中,因此2号页面是放在这个位置的。
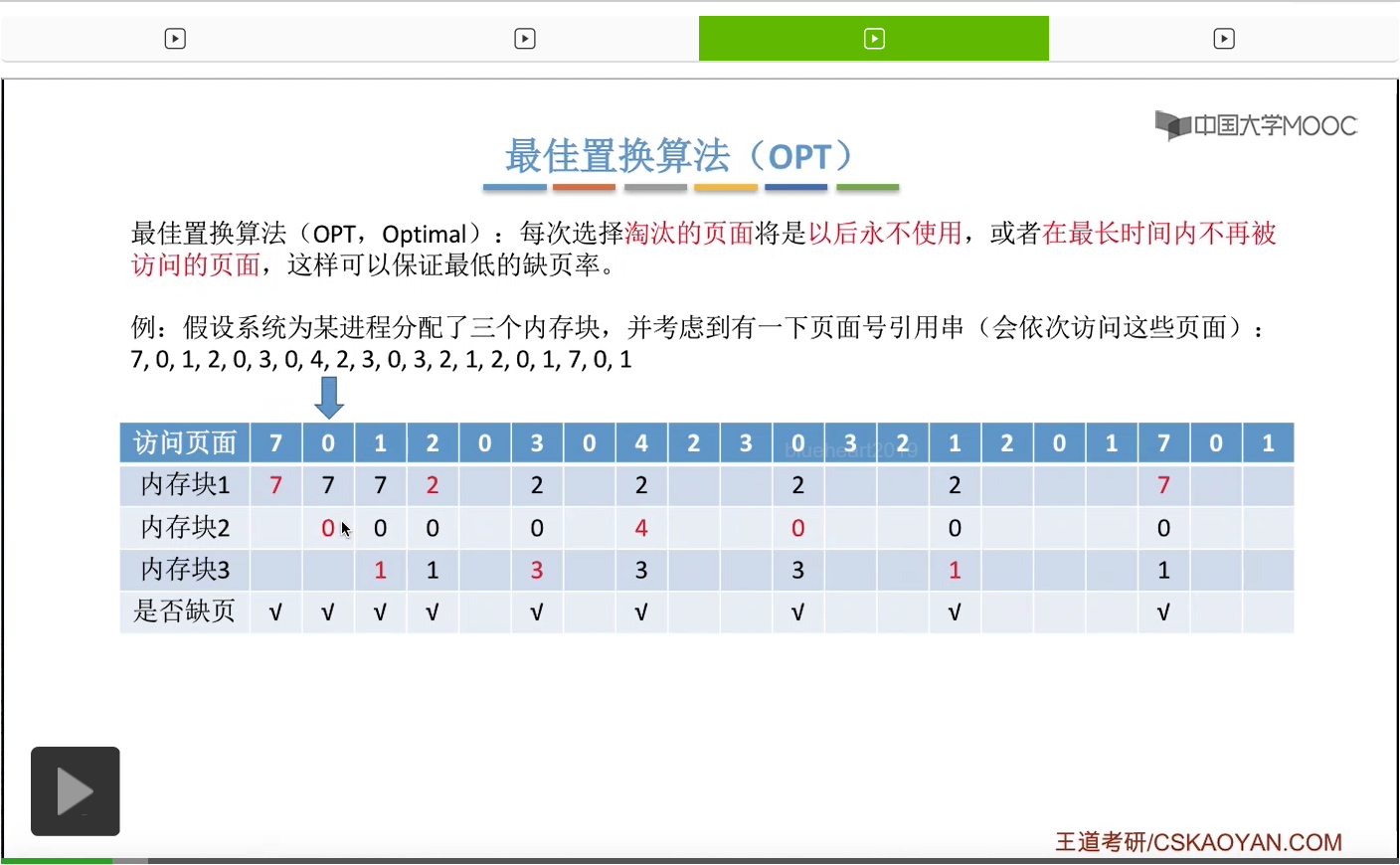
那接下来要访问的0号页面已经在内存当中了,所以此时不会发生缺页,可以正常地访问。
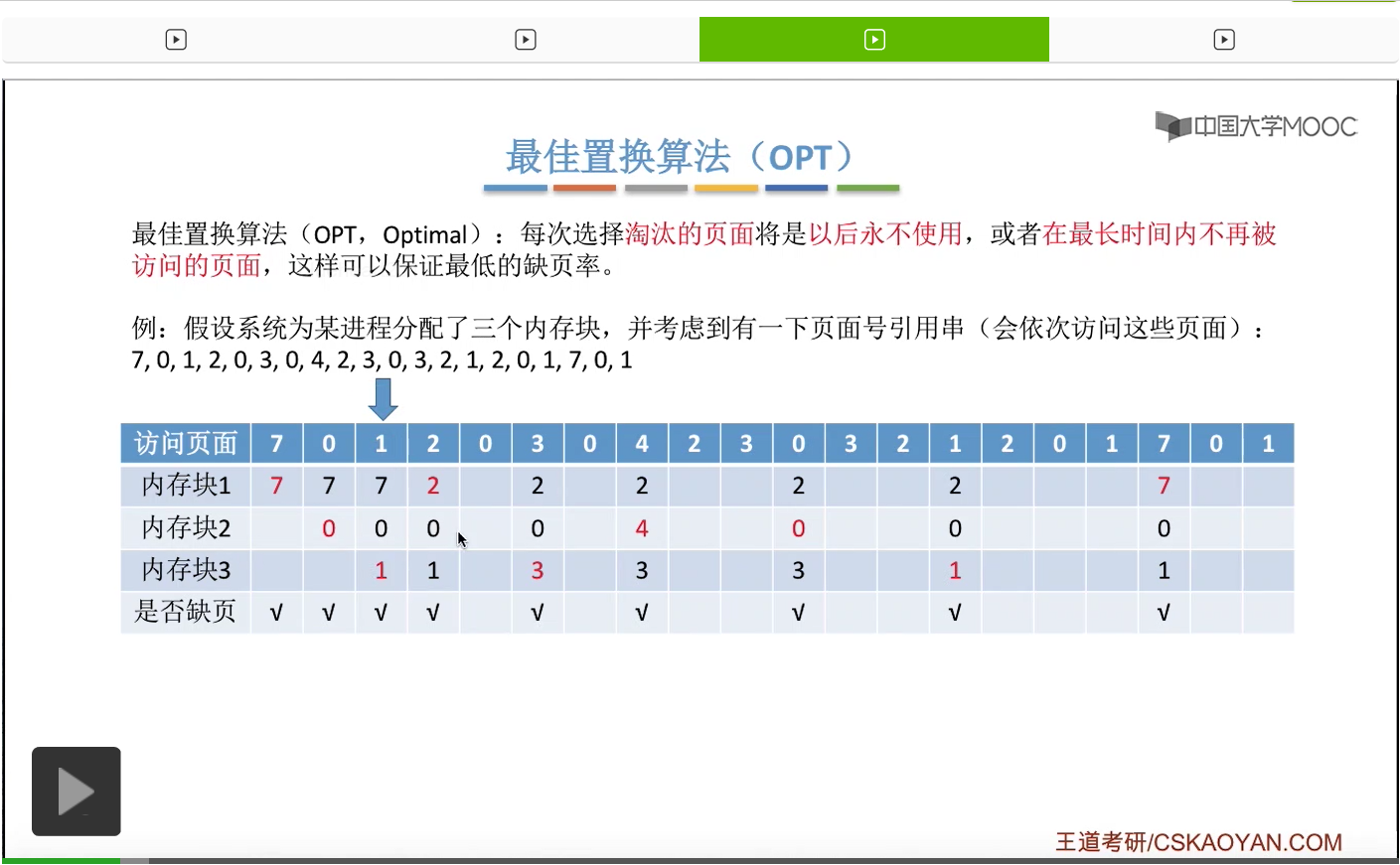
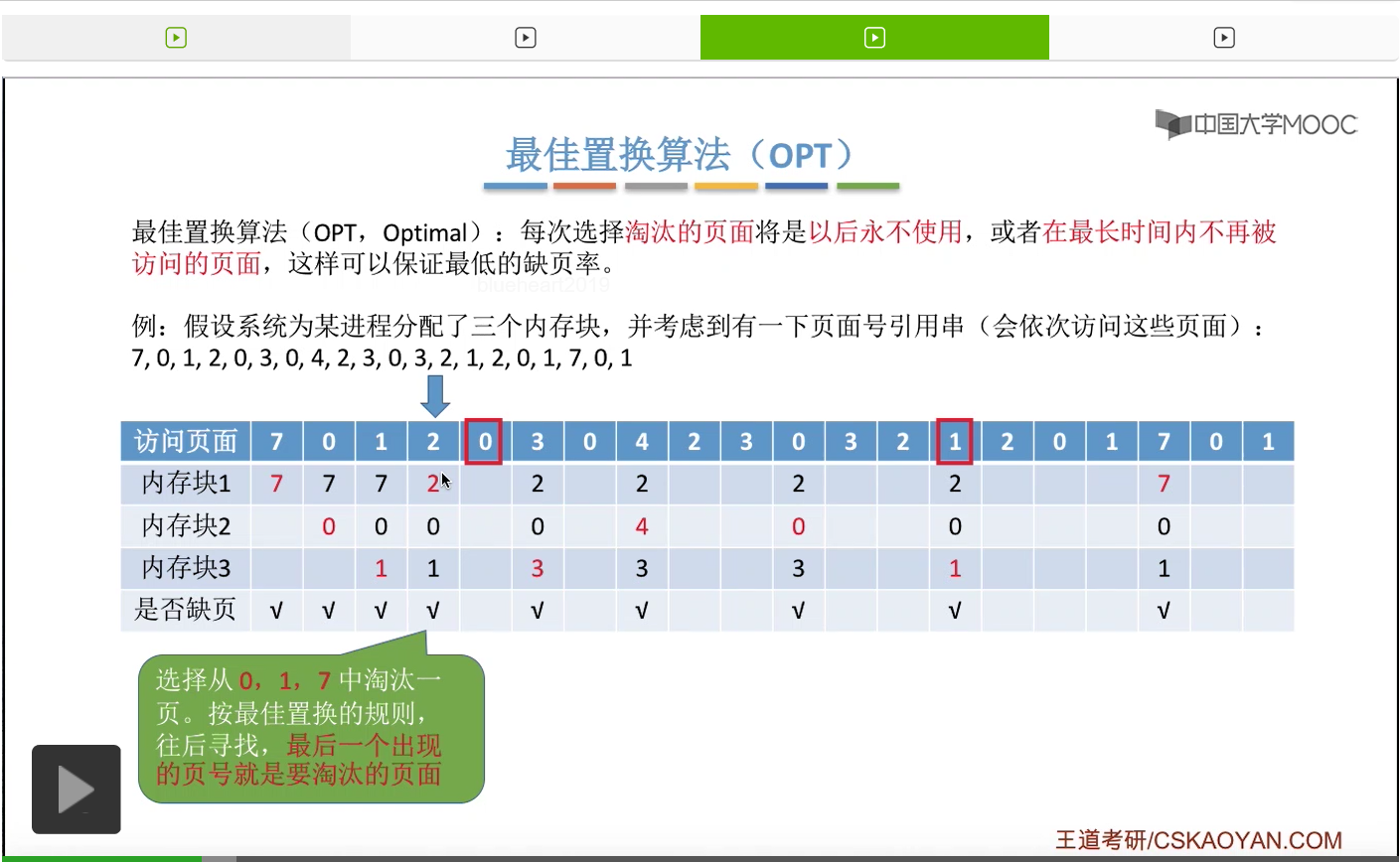
再之后访问3号页面,也会发现,此时3号页面并没有在内存当中,所以我们依然需要用这个置换算法选择淘汰一个页面。
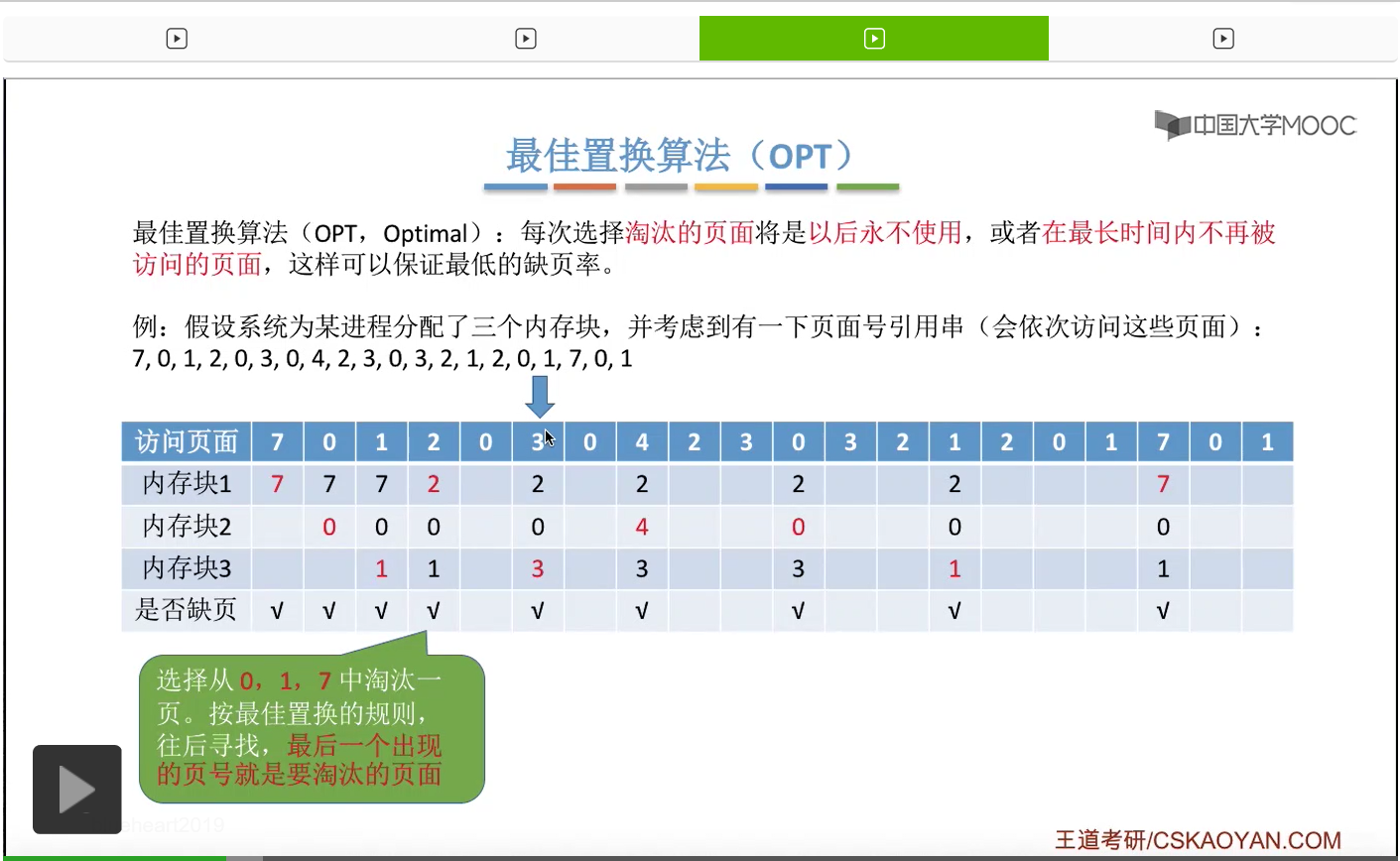
那和刚才一样,我们从这个位置开始往后寻找,看一下此时内存当中存放的2、0、1这三个页面出现的先后顺序。那么我们会发现,2、0、1当中,那么1号页面就是最后一个出现的,因此1号页面是在今后最长时间内不会再被访问的页面,所以我们会选择把2、0、1这三个页面当中的1号页面给淘汰,先换出外存,然后3号页面再换入1号页面以前占有的那个内存块,也就是内存块3当中,所以3号页面是放在这个地方的。那对于之后的这些页面序号的访问我们就不再细细地分析了,大家可以自己尝试着去完善一下这个表。
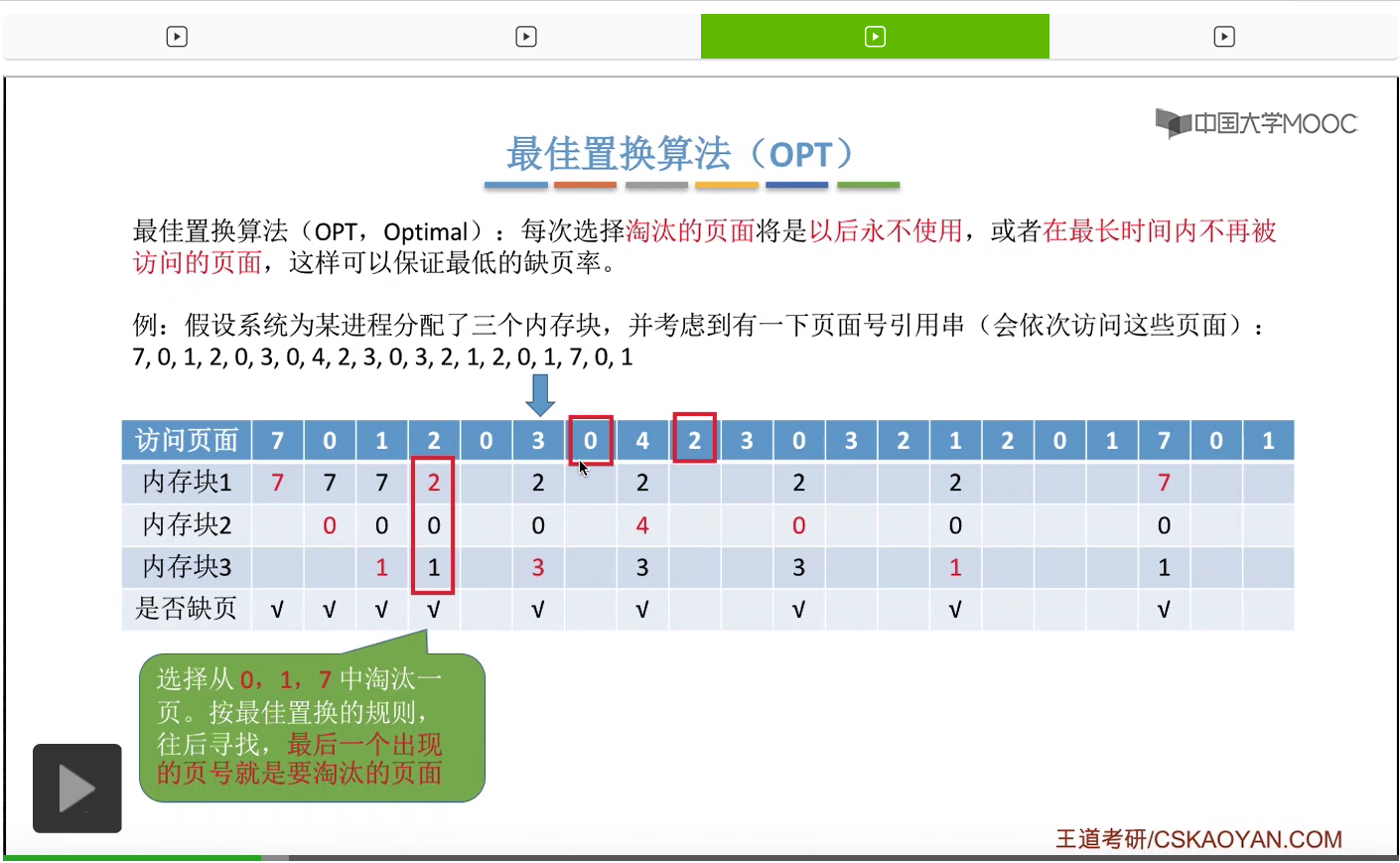
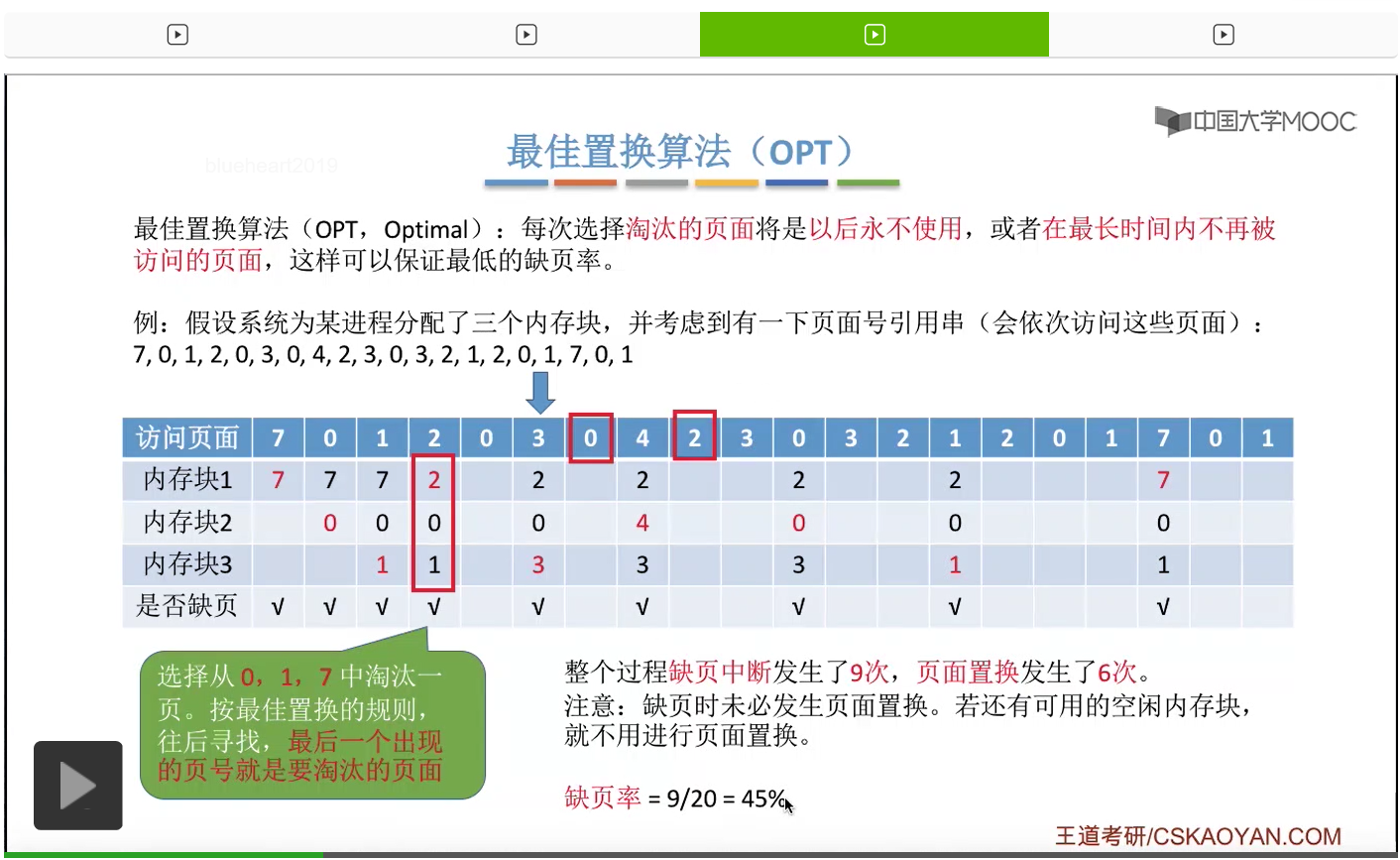
那最终我们会发现整个访问这些页面的过程当中,缺页中断发生了9次,也就是这儿打勾的这些位置发生缺页中断,但是页面置换只发生了6次。所以大家一定需要注意,缺页中断之后未必发生页面置换。只有内存块已经都满了的时候才发生页面置换。因此刚开始访问7、0、1这三个页面的时候,虽然它们都没有在内存当中,但是由于刚开始内置有空闲的内存块,虽然发生了缺页中断,虽然会发生调页,但是并不会发生页面置换这件事情。那只有所有的内存块都已经占满了之后,再发生缺页的话那才需要进行页面置换这件事情。因此缺页中断总共发生了9次,但页面置换只发生了6次,前面的3次只是发生了缺页,但是并没有页面置换。那缺页率的计算也很简单,我们只需要把缺页中断次数再除以我们总共访问了多少次的页面就可以得到缺页率是45%。那这是最佳置换算法。
那其实页面置换执行的前提条件是我们必须要知道之后会依次访问的页面序列到底是哪些。
不过在实际应用当中,只有在进程执行的过程当中,才能一步一步地知道接下来会访问到的到底是哪一个页面。所以操作系统其实根本不可能提前预判各个页面的访问序列,所以最佳置换算法它只是一种理想化的算法,在实际应用当中是无法实现的。
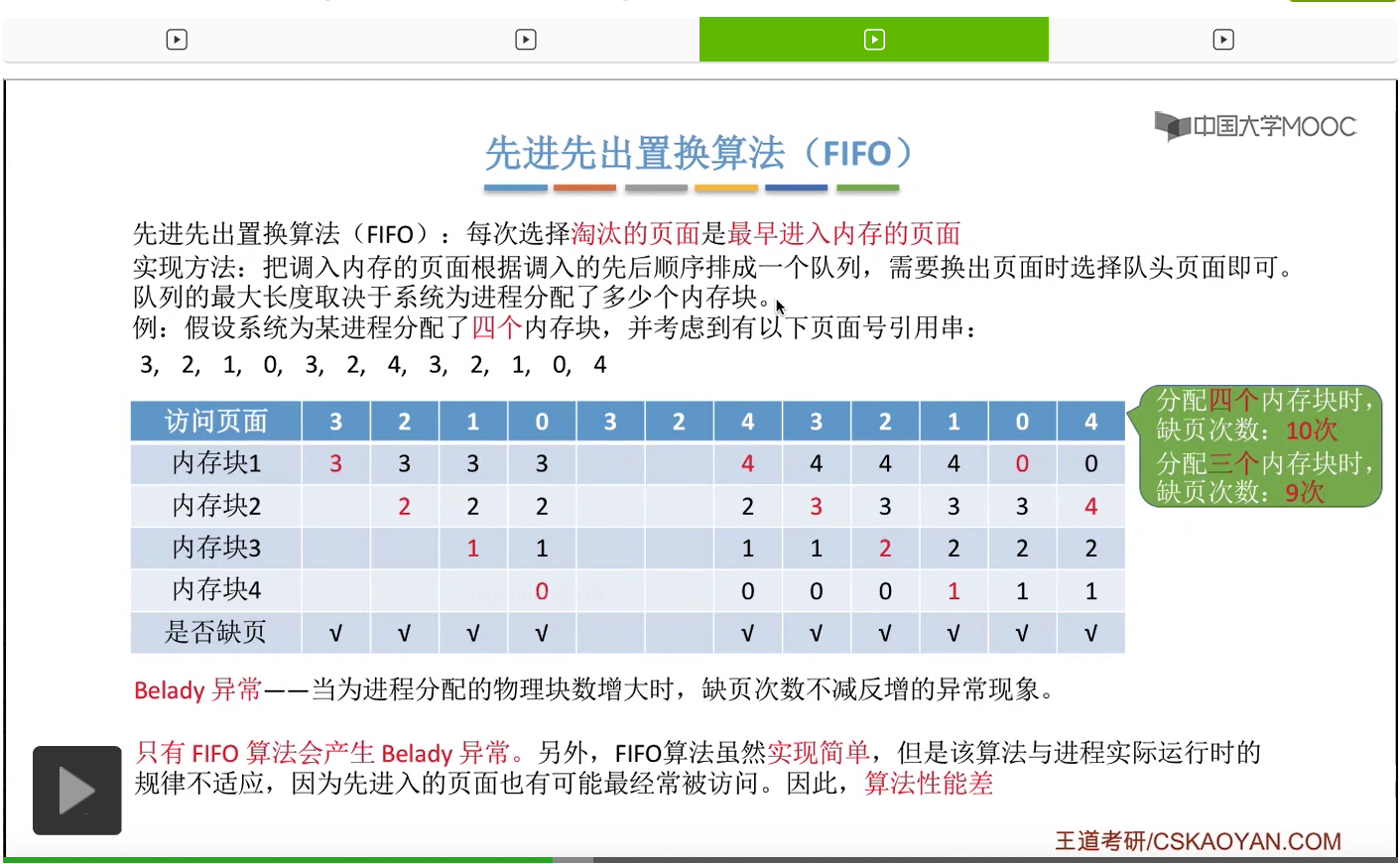
那接下来我们再来看第二种————先进先出置换算法。这种算法的思想很简单,每次选择淘汰的页面,是最早进入内存的页面。所以在具体实现的时候,可以把调入内存的这些页面根据调入的先后顺序来排成一个队列,当系统发现需要换出一个页面的时候,只需要把队头的那个页面淘汰就可以了。那需要注意的是,这个队列有一个最大长度的限制,那这个最大长度取决于系统为进程分配了多少个内存块。

那我们还是来看一个例子。
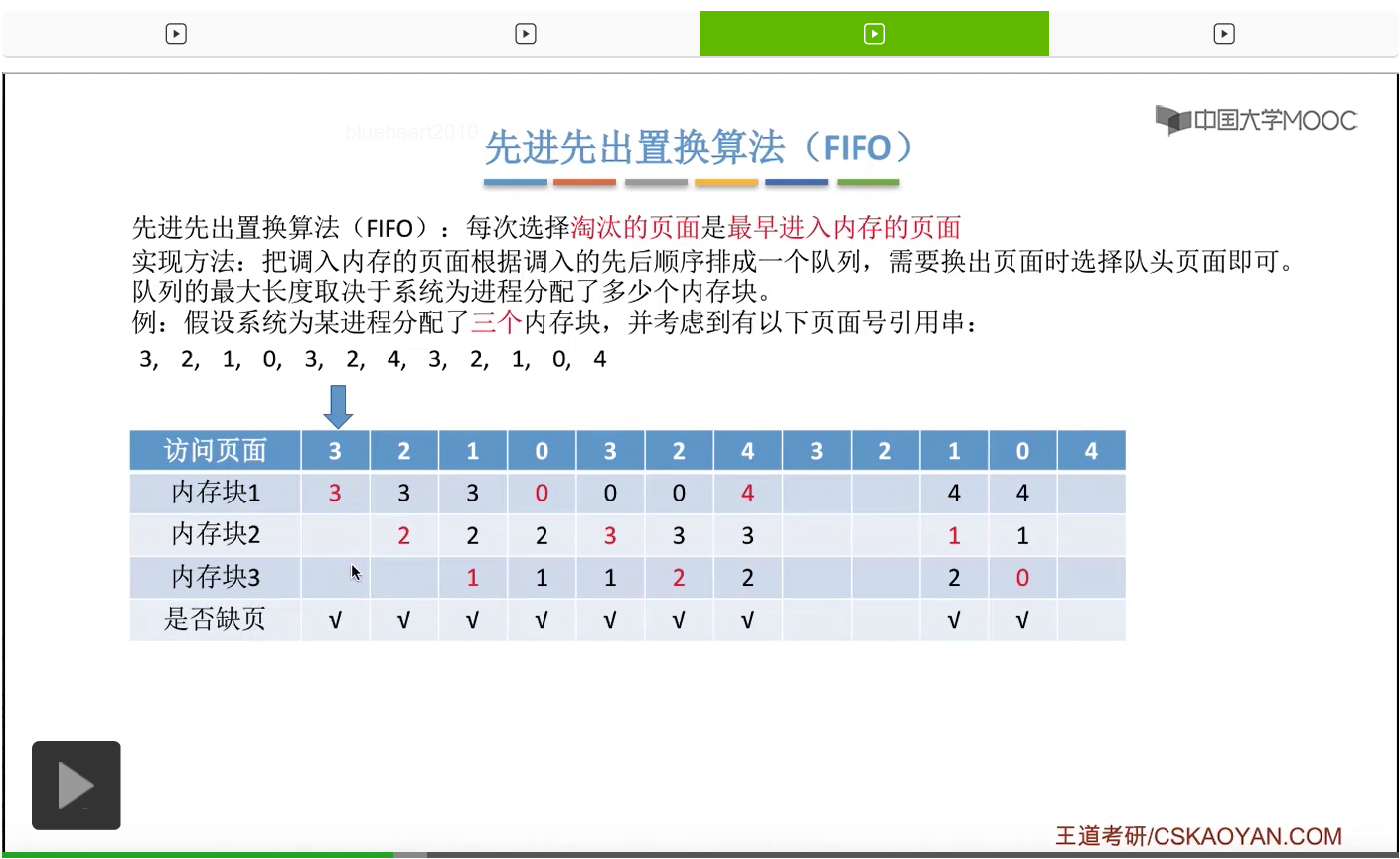

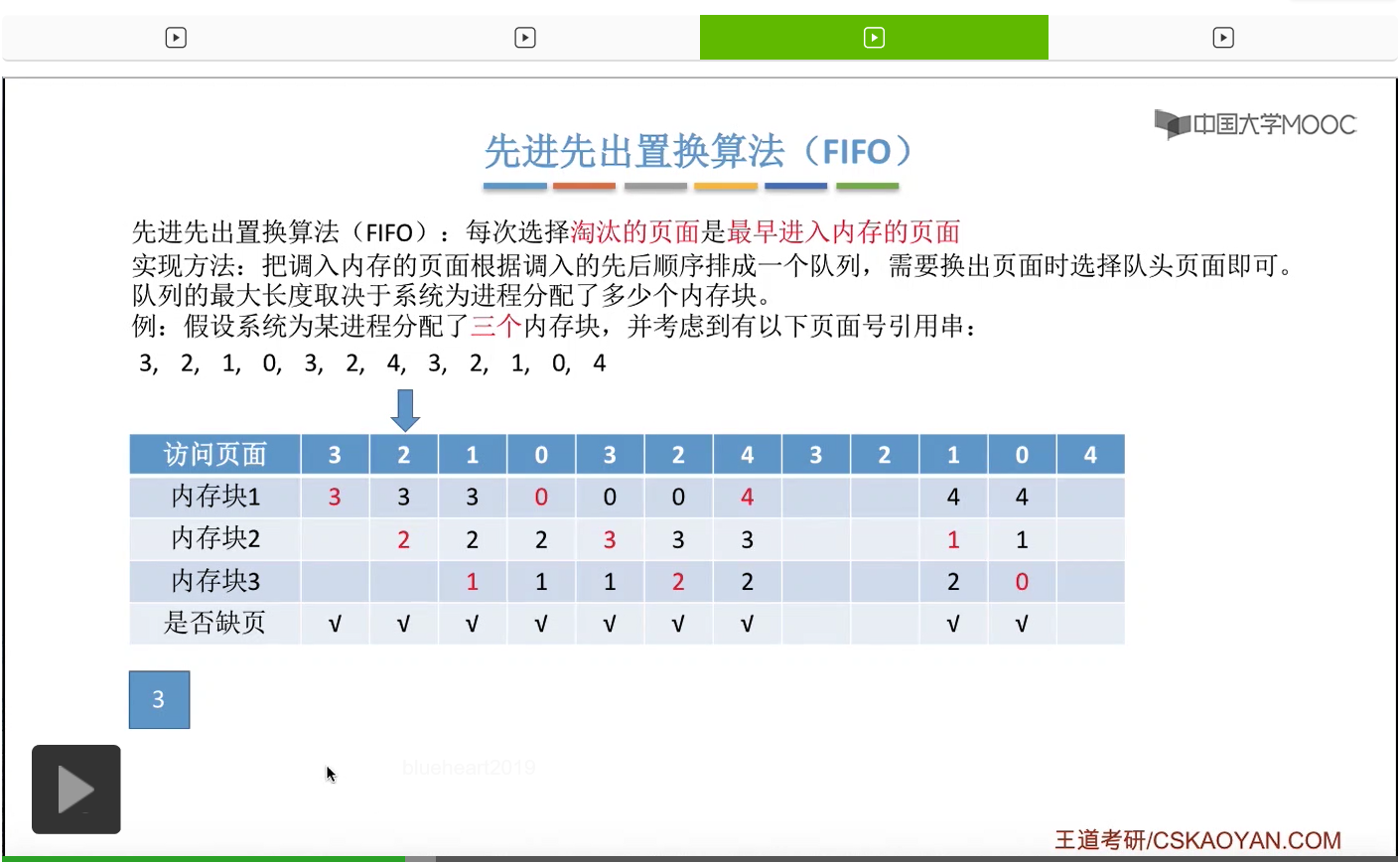
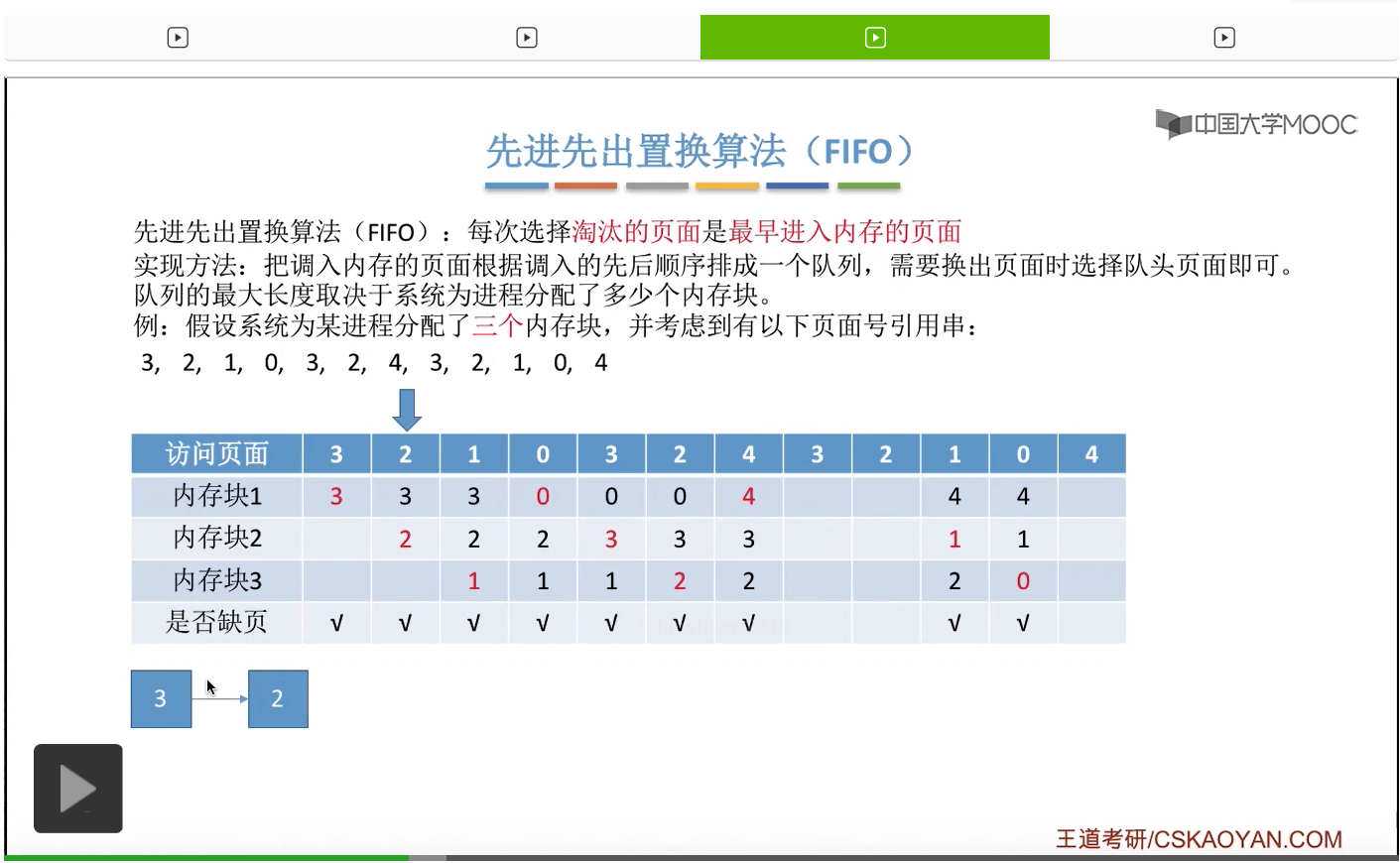
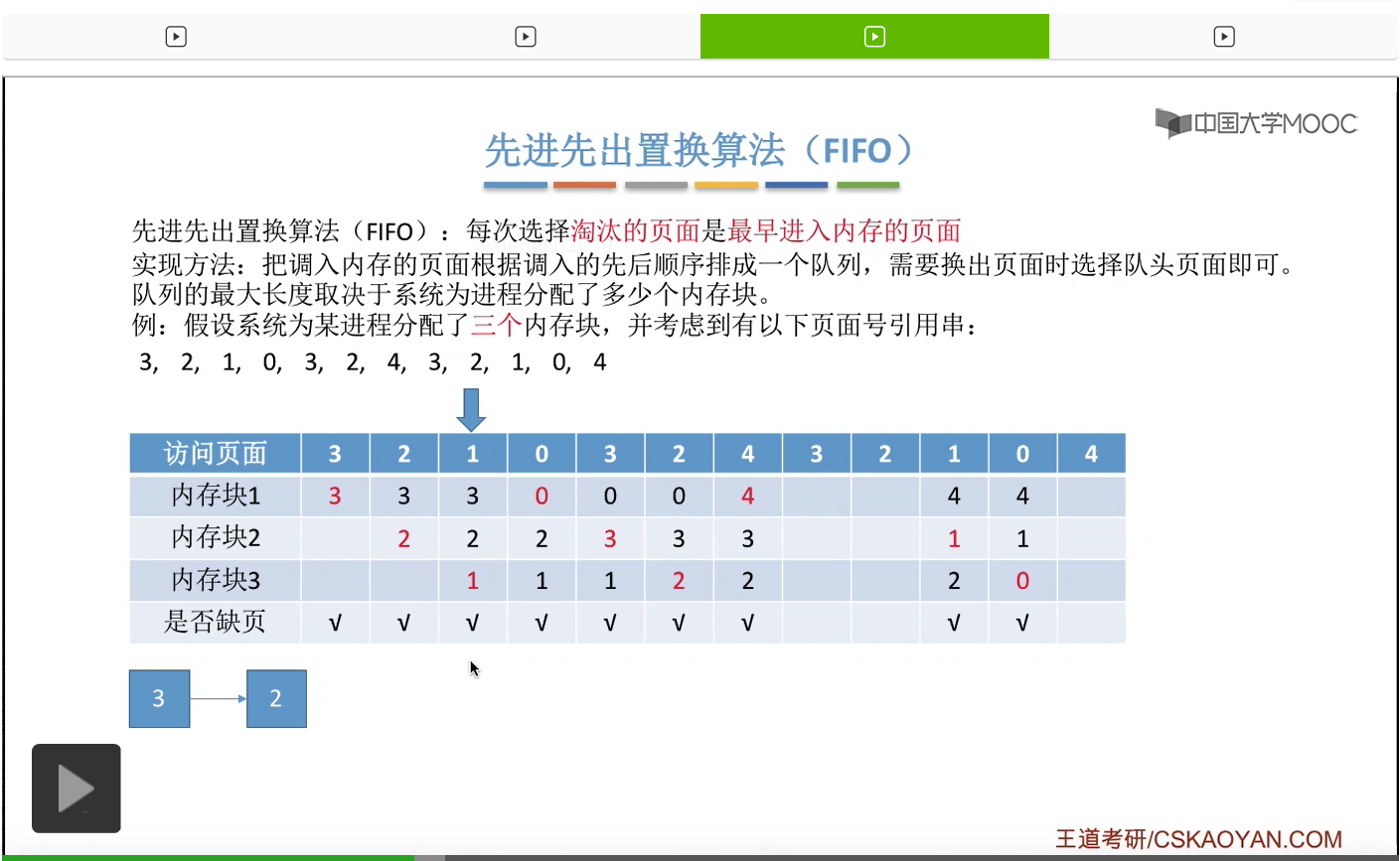

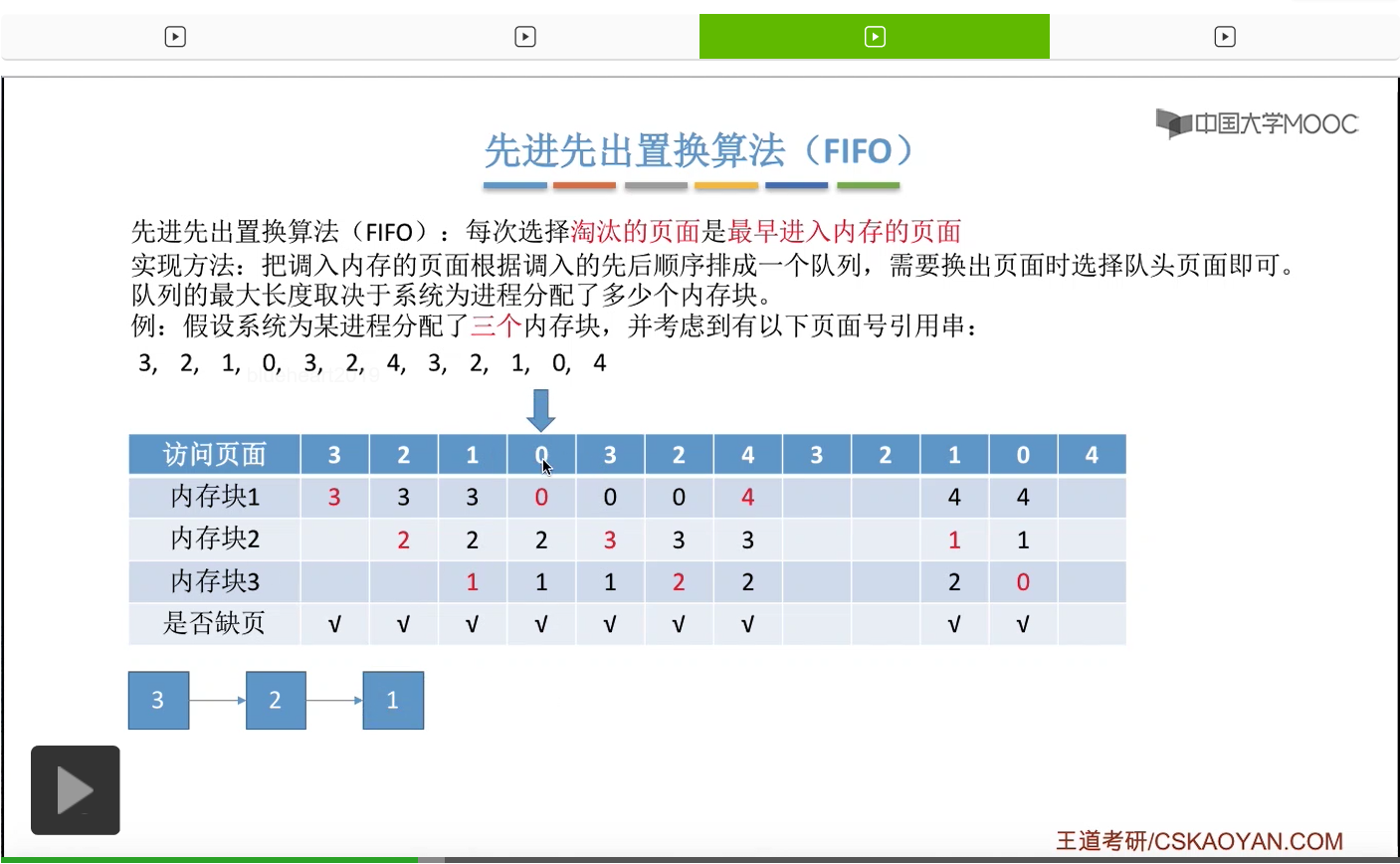
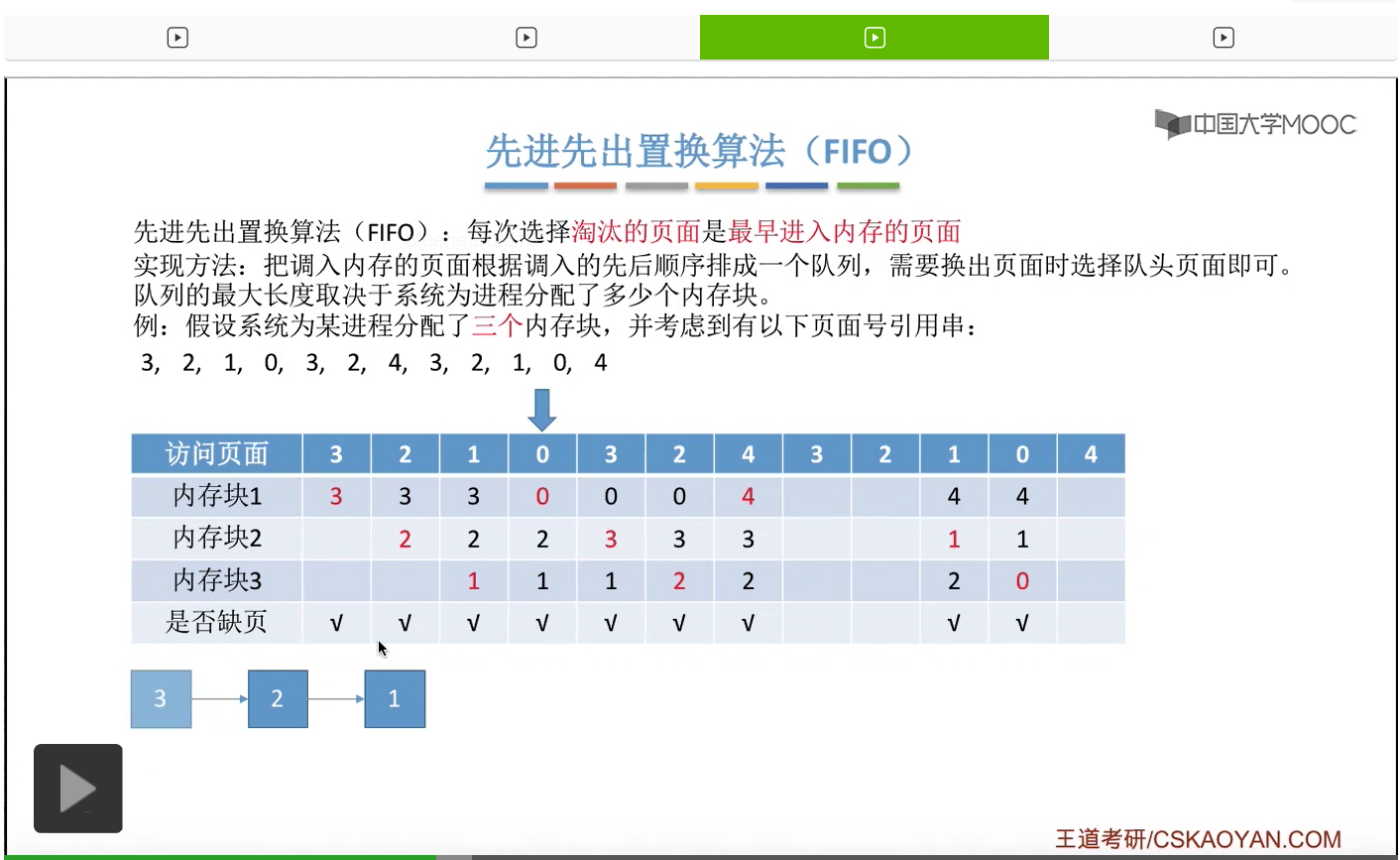
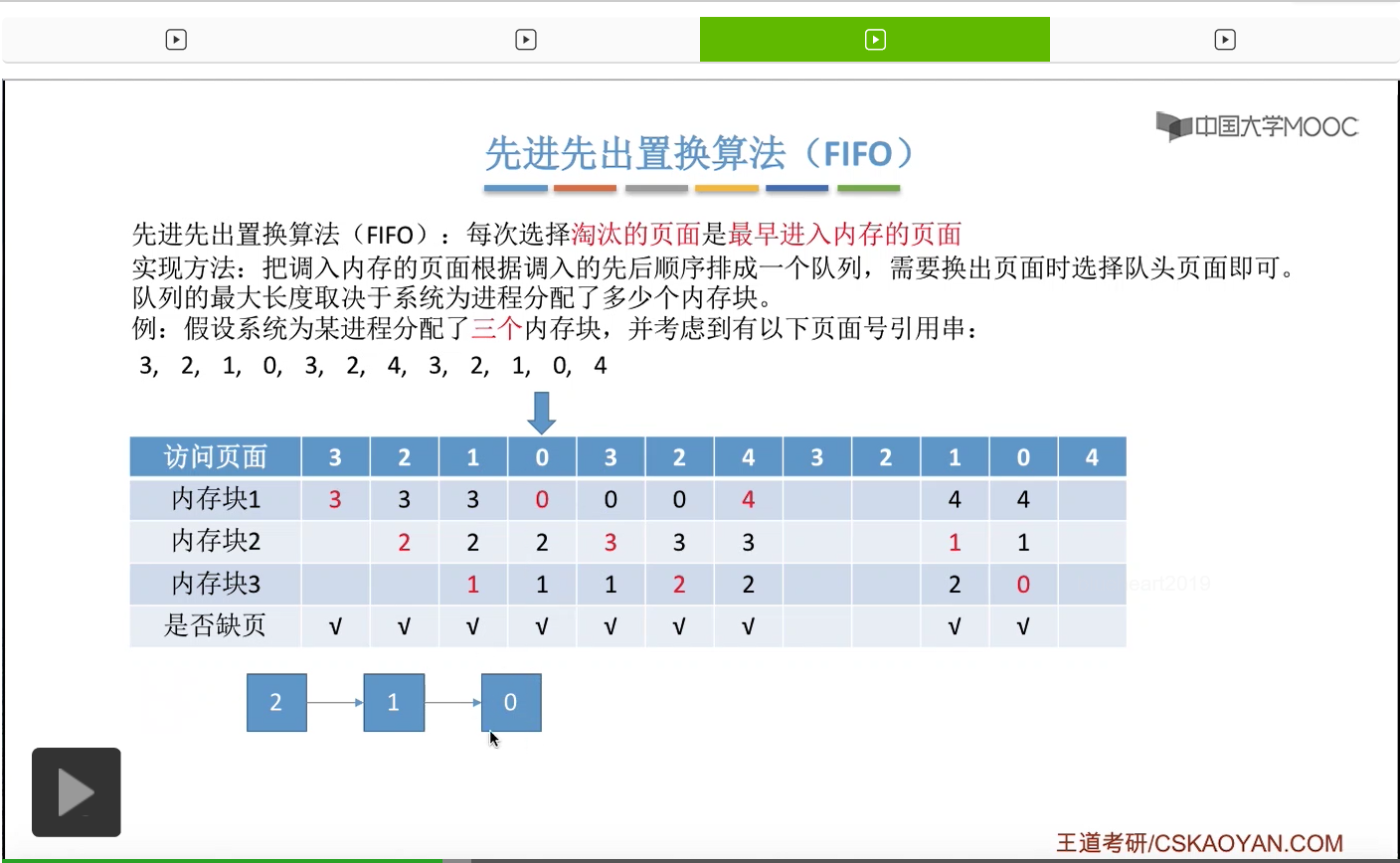
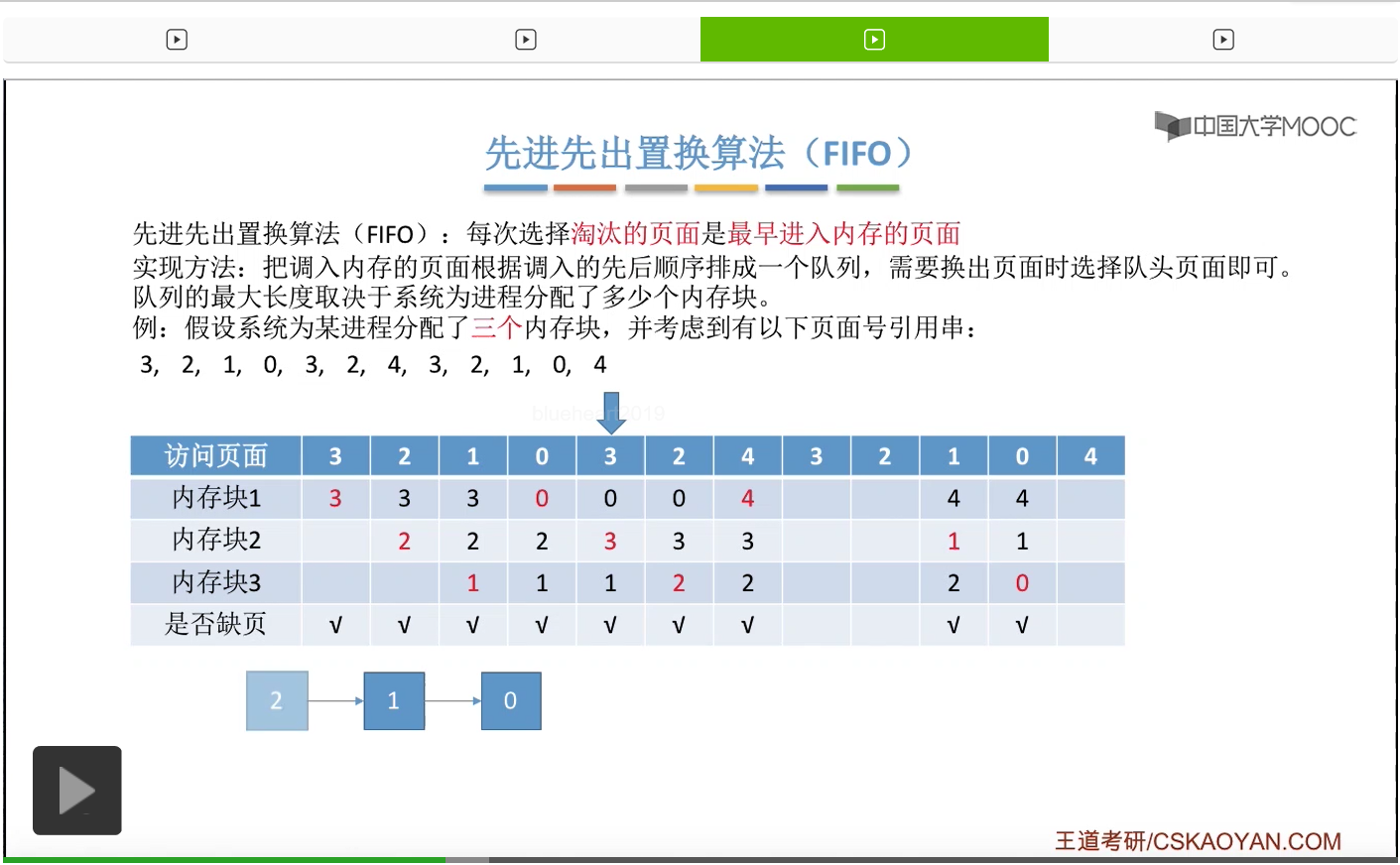
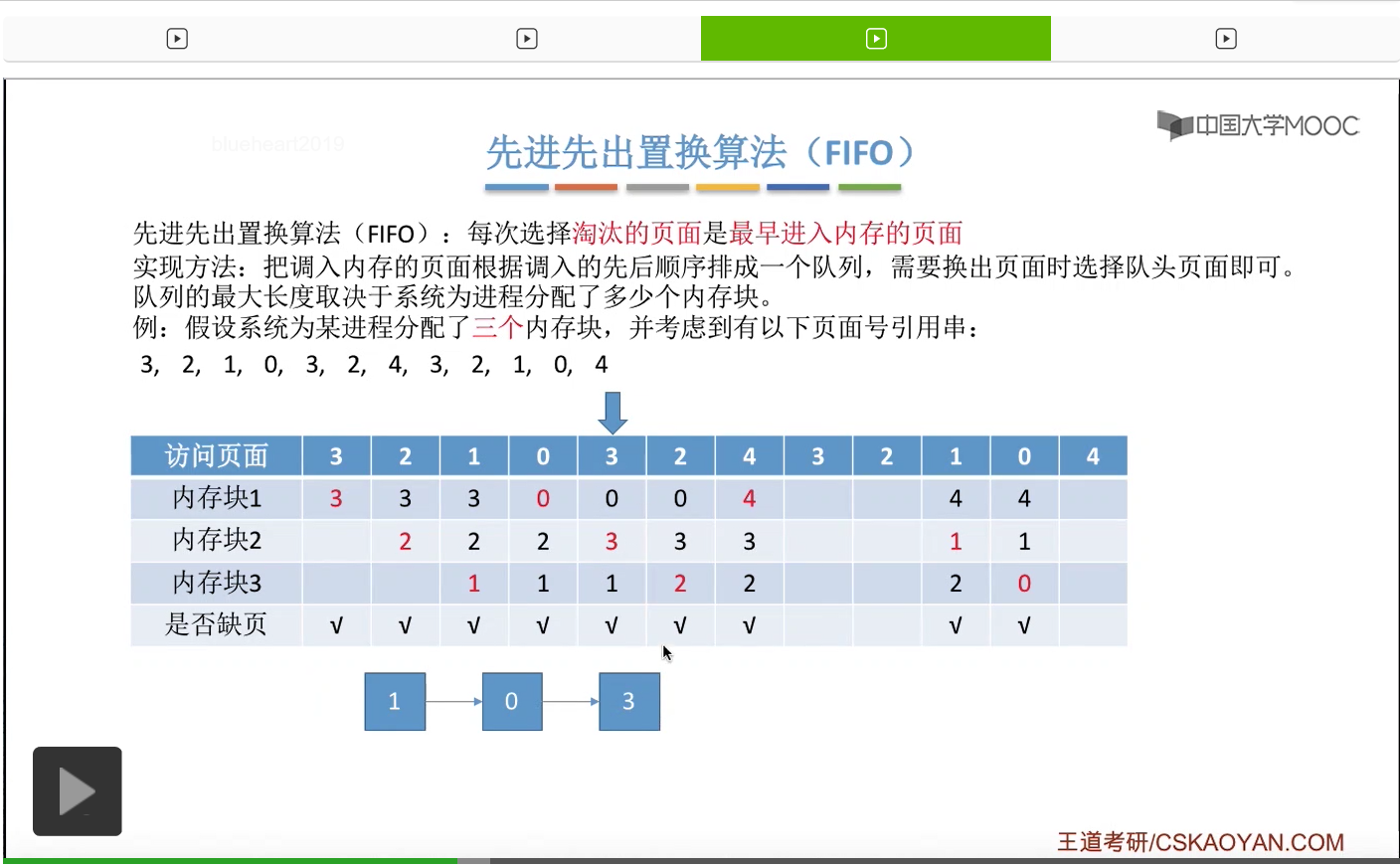

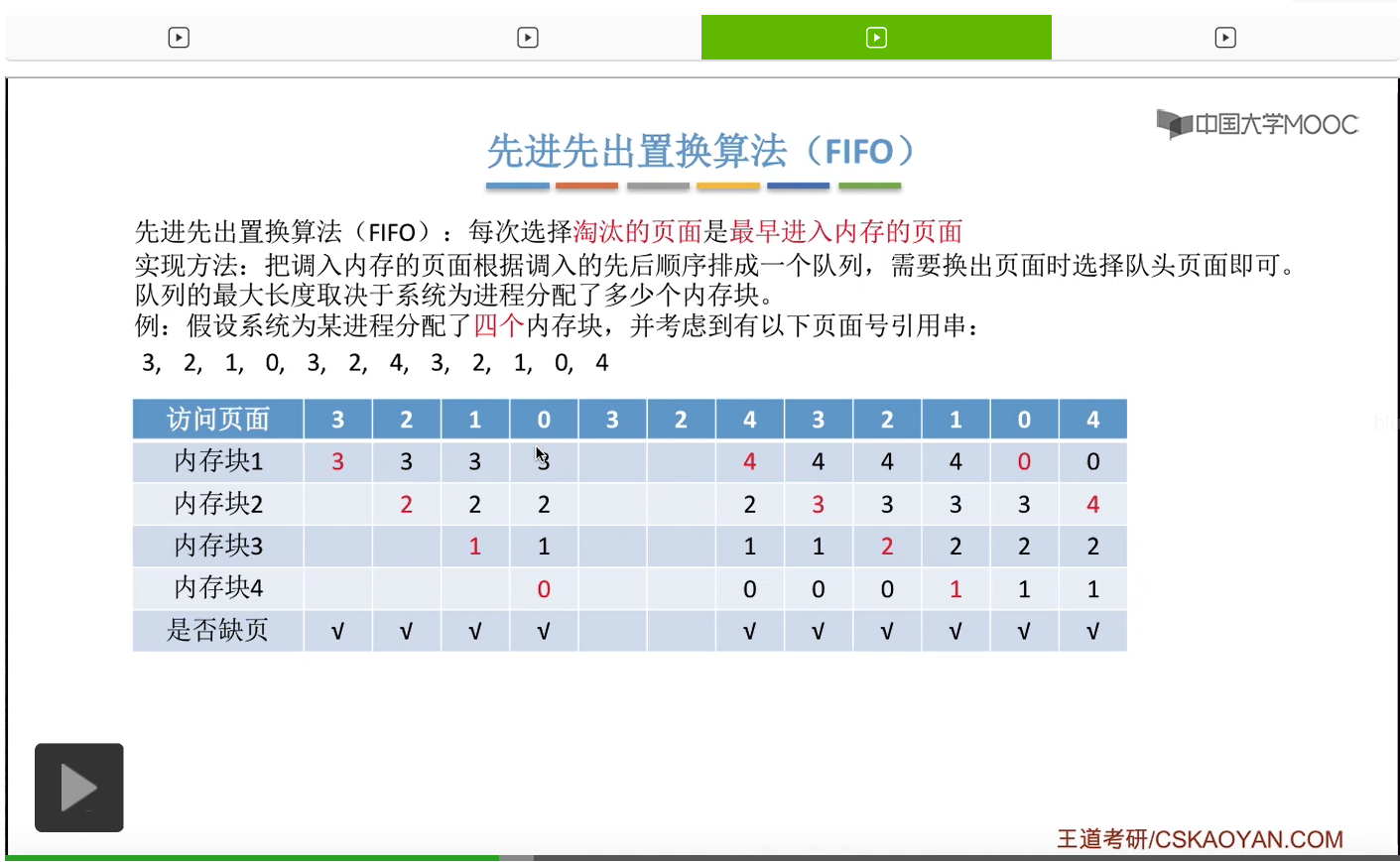
为一个进程分配的内存块越多,那这个进程的缺页次数应该越少才对啊。所以像这个地方我们发现的这种现象,就是为进程分配物理块增大的时候,缺页次数不增反减的这种现象就称作为Belady异常。
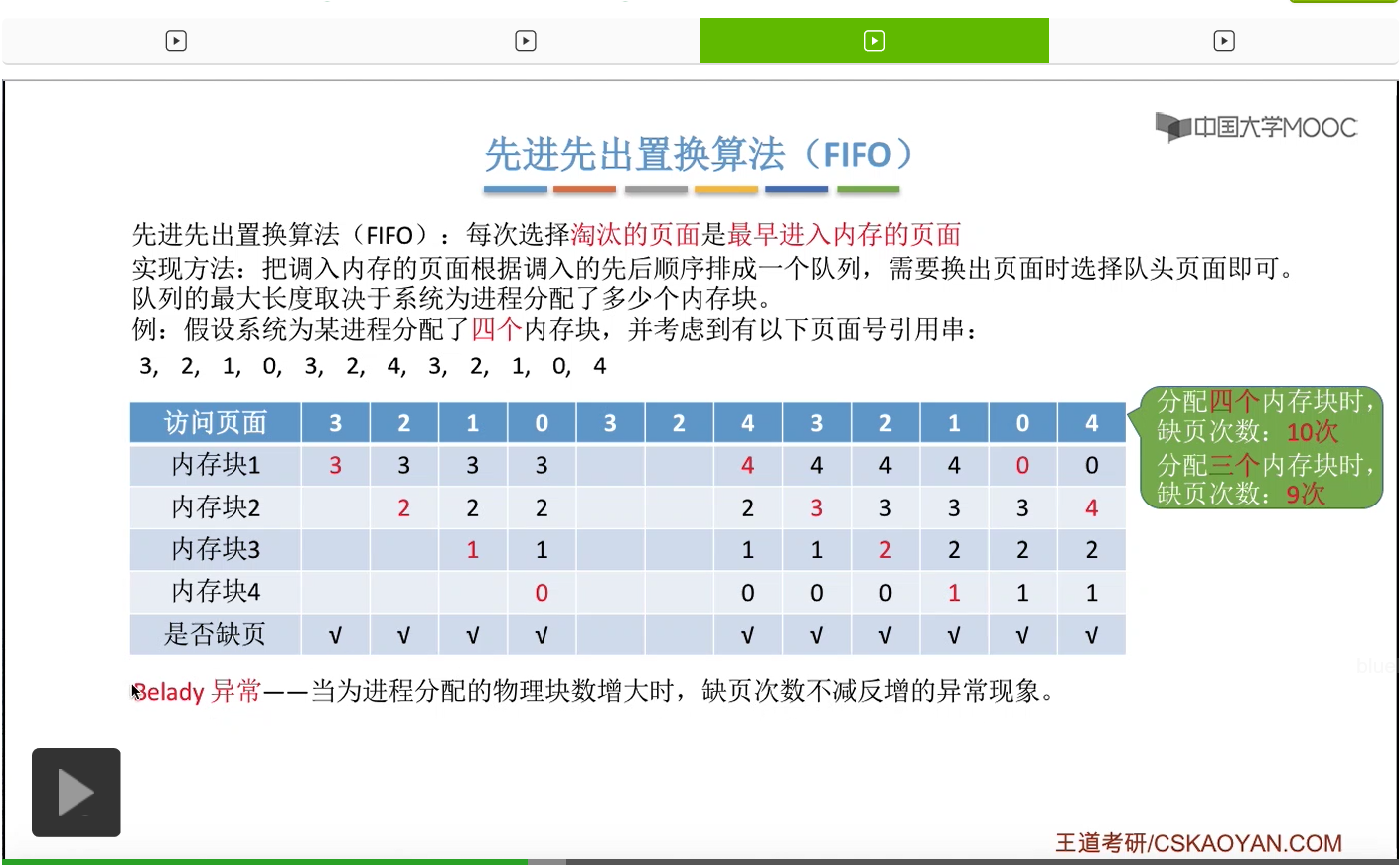
那在我们要学习的所有的这些算法当中,只有先进先出算法会产生这种Belady异常。所以虽然先进先出算法实现起来很简单,但是先进先出的这种规则其实并没有考虑到进程实际运行时候的一些规律。因为先进入内存的页面其实在之后也有可能会被经常访问到,所以只是简单粗暴地让先进入的页面淘汰的话,那显然这是不太科学的,所以先进先出置换算法的算法性能是很差的。
那接下来我们再来看第三个————最近最久未使用置换算法,英文缩写是LRU(least recently used),大家也需要记住它的这个英文缩写。很多题目出题的时候就直接用这个LRU来表示置换算法。那这个算法的规则就像它的名字一样,就是要选择淘汰最近最久没有使用的页面。
所以为了实现这件事,我们可以在每个页面的页表项当中的访问字段这儿,记录这个页面自从上一次被访问开始,到现在为止所经历的时间t。那我们需要淘汰一个页面的时候,只需要选择这个t值最大的,也就是最久没有被访问到的那个页面进行淘汰就可以了。那我们依然还是结合一个例子。如果一个系统为进程分配了四个内存块,然后有这样的一系列的内存访问序列。

那首先要访问的是1号页。此时有内存块空闲,所以1号页放到内存块1当中。
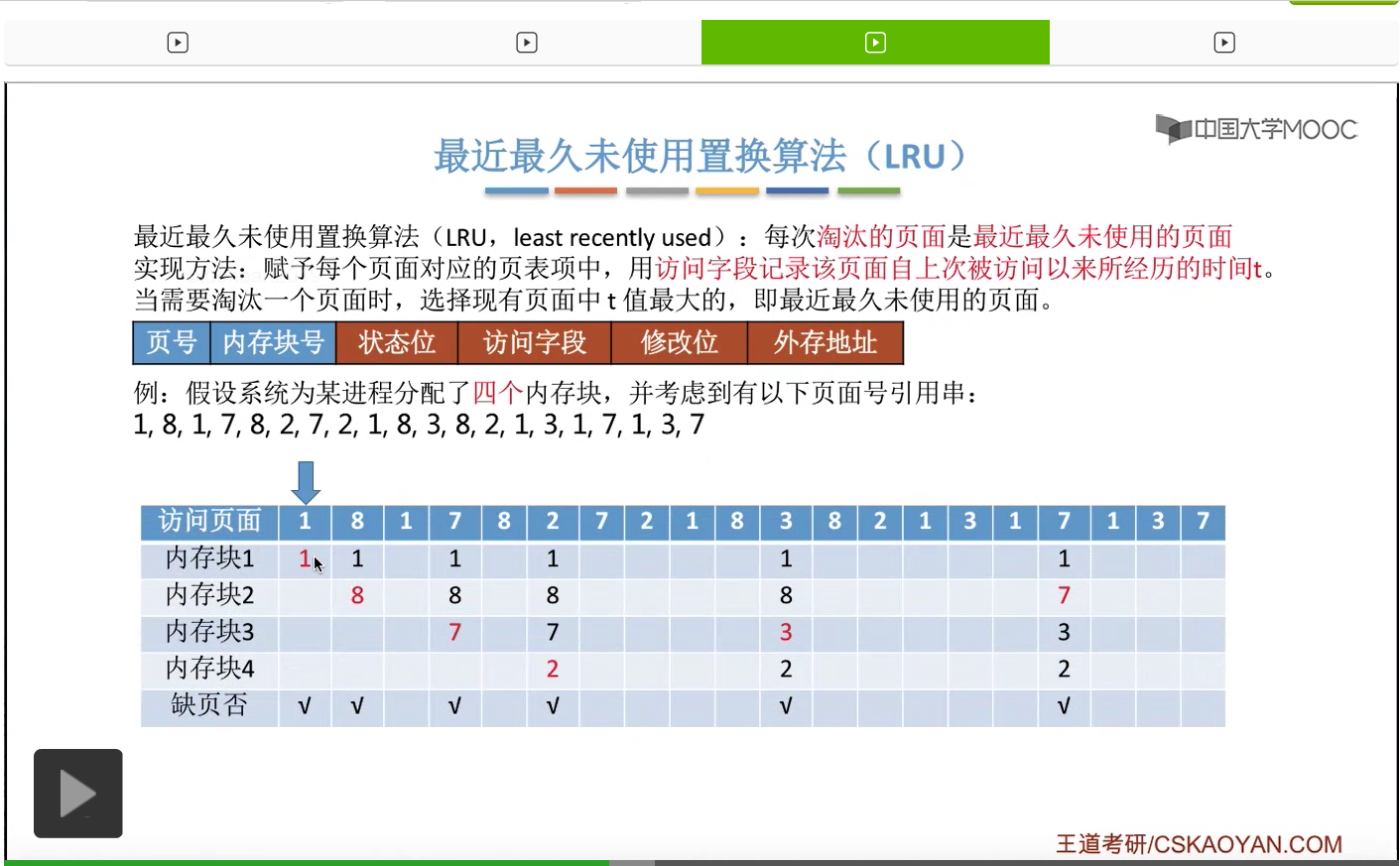
然后第二个访问8号页面,也可以直接放到空闲的内存块2当中。
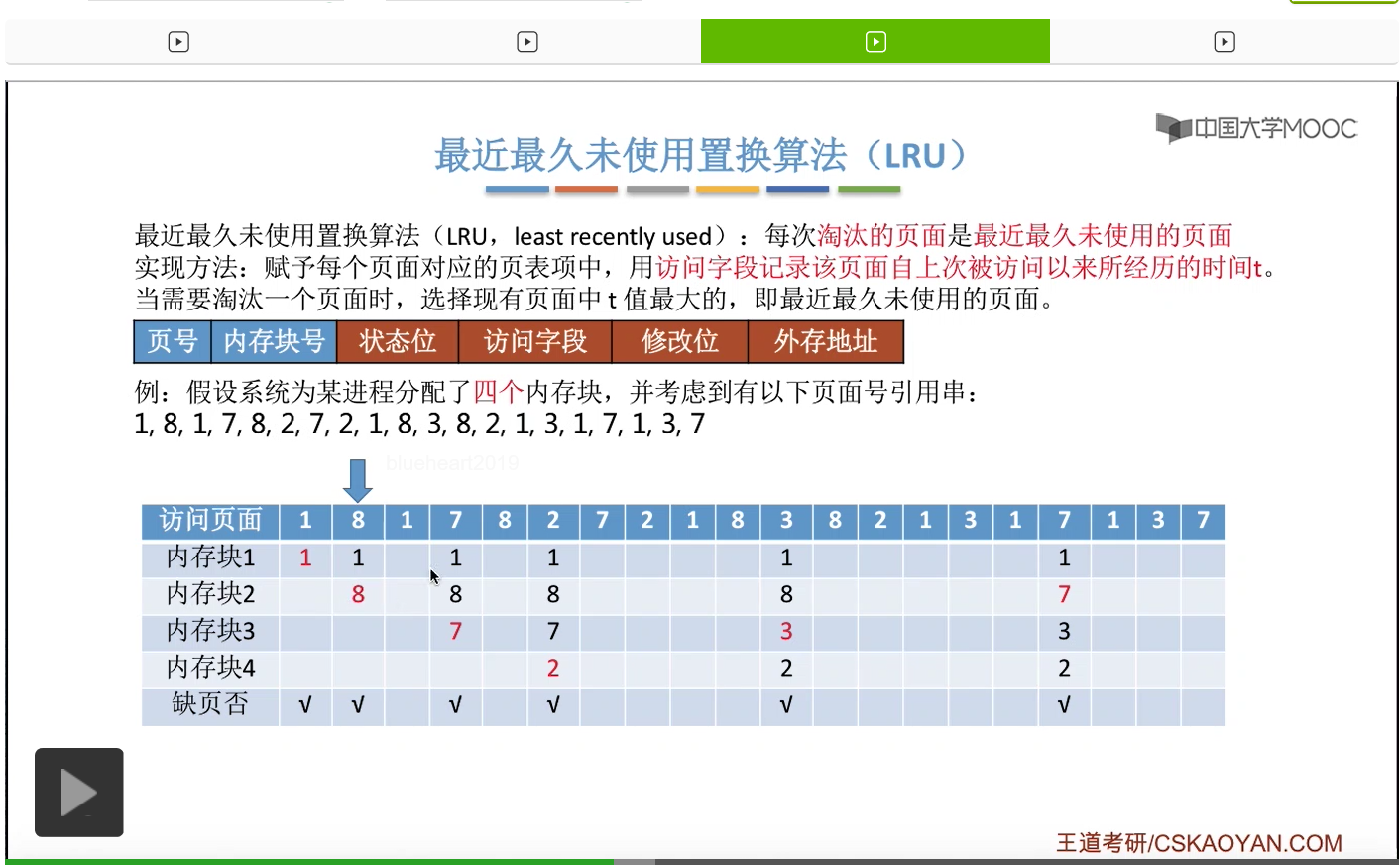
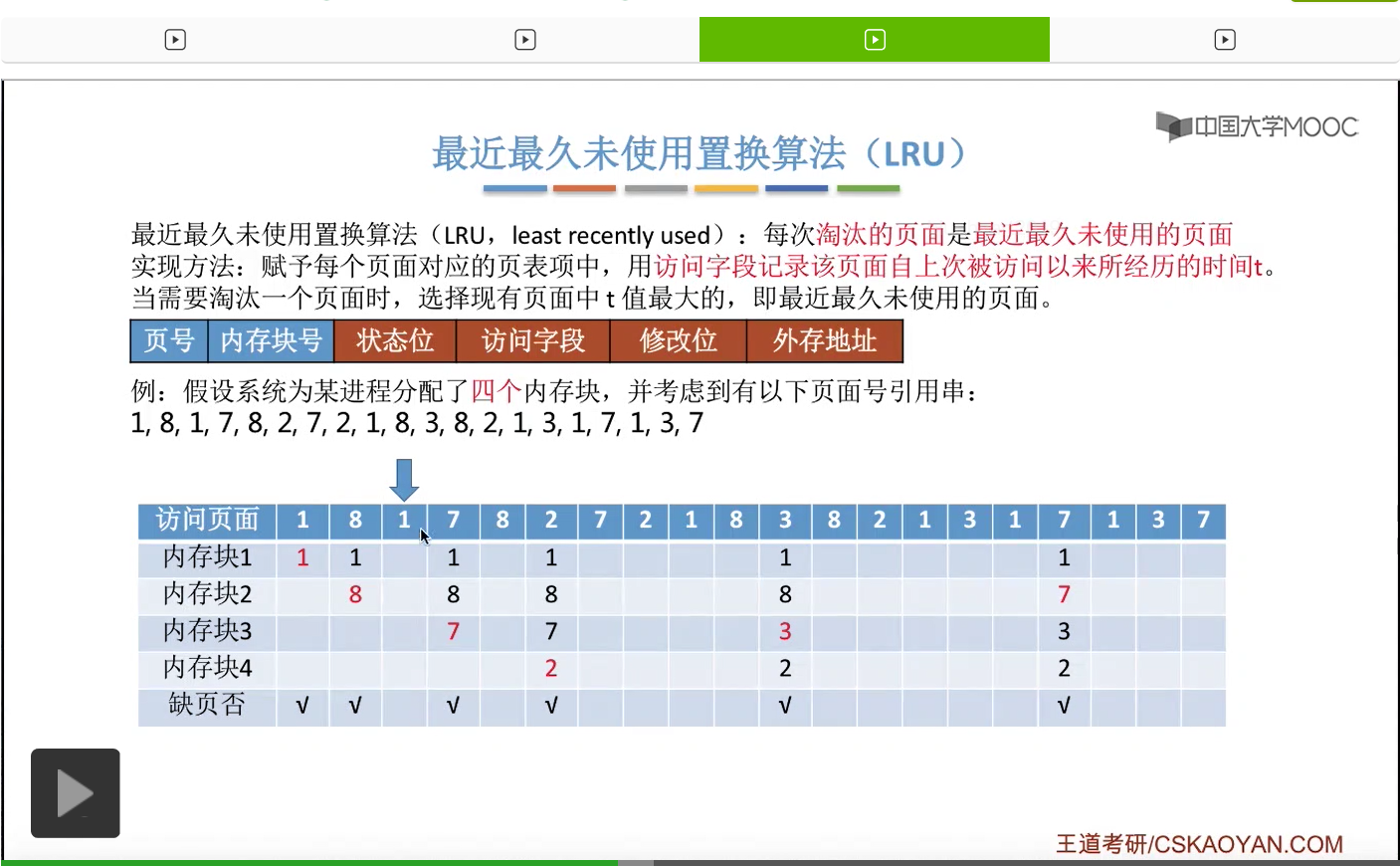
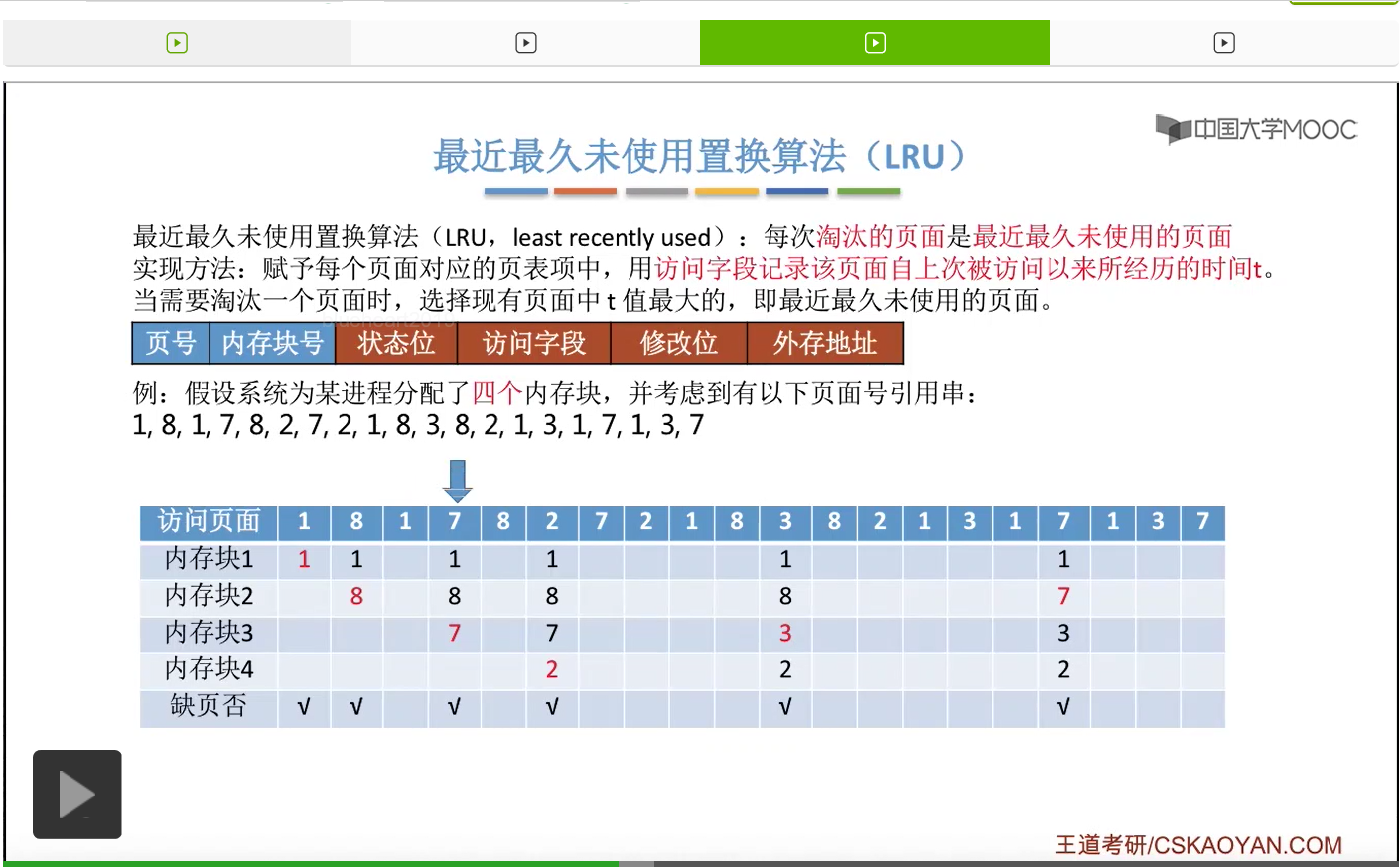
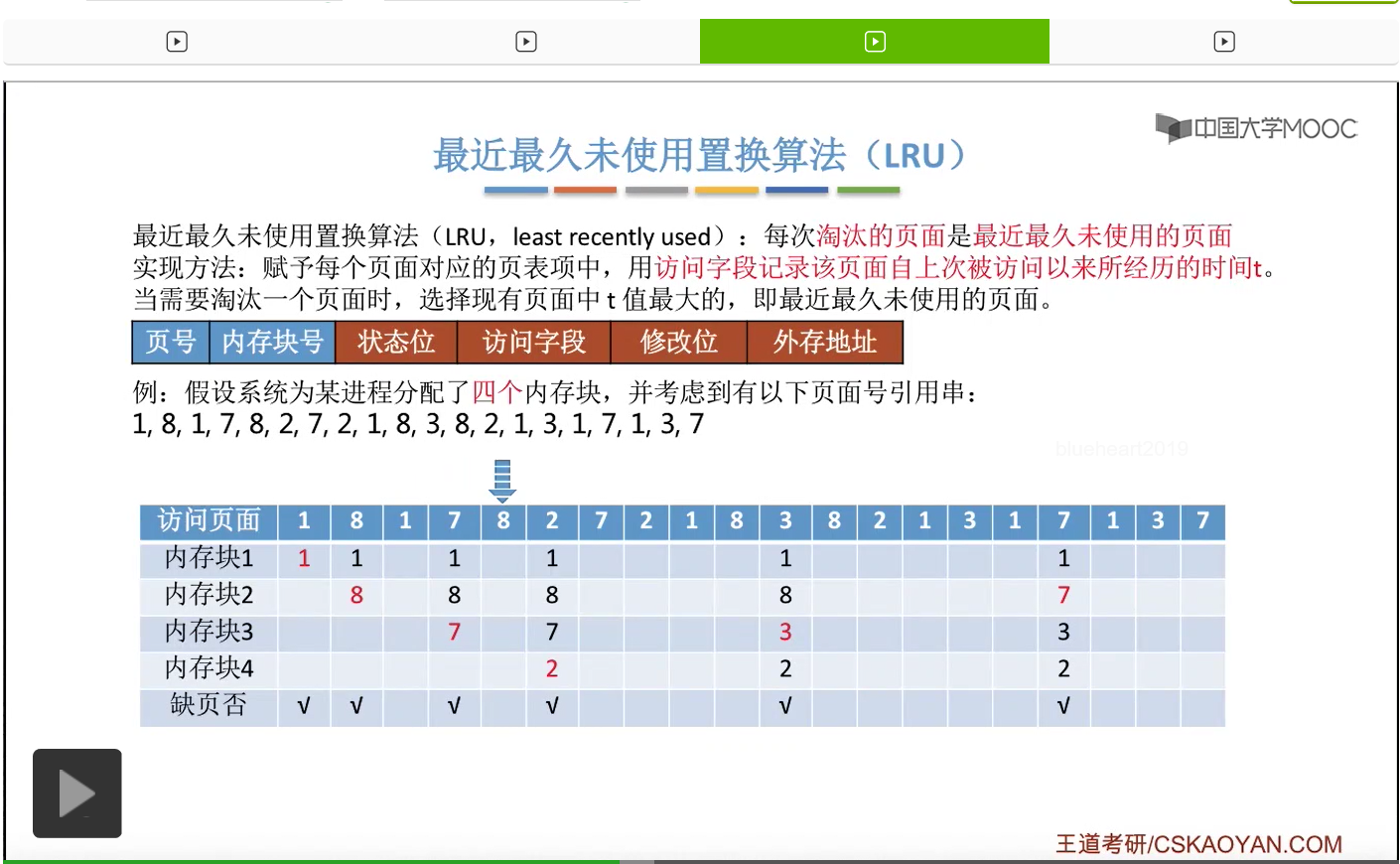

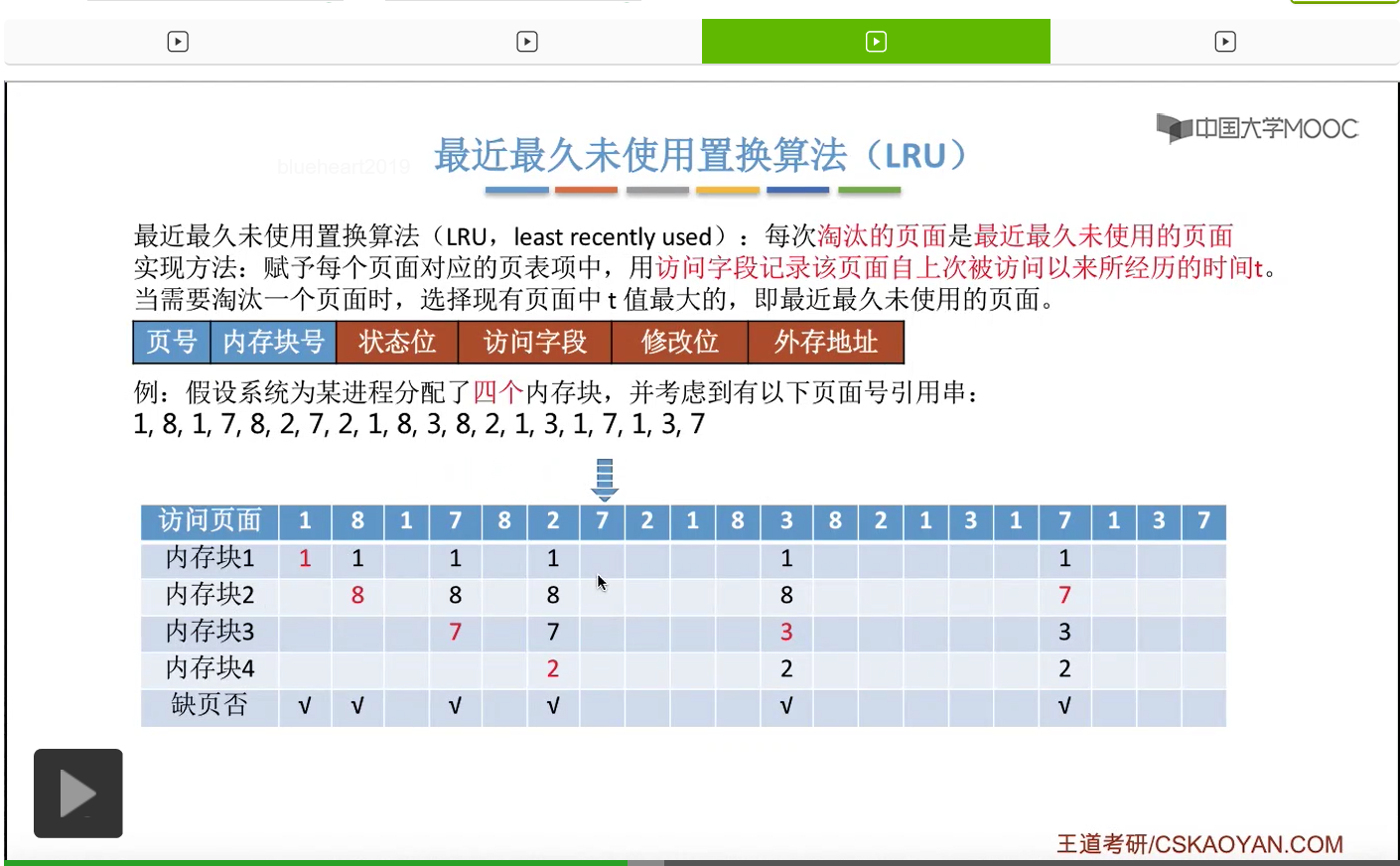
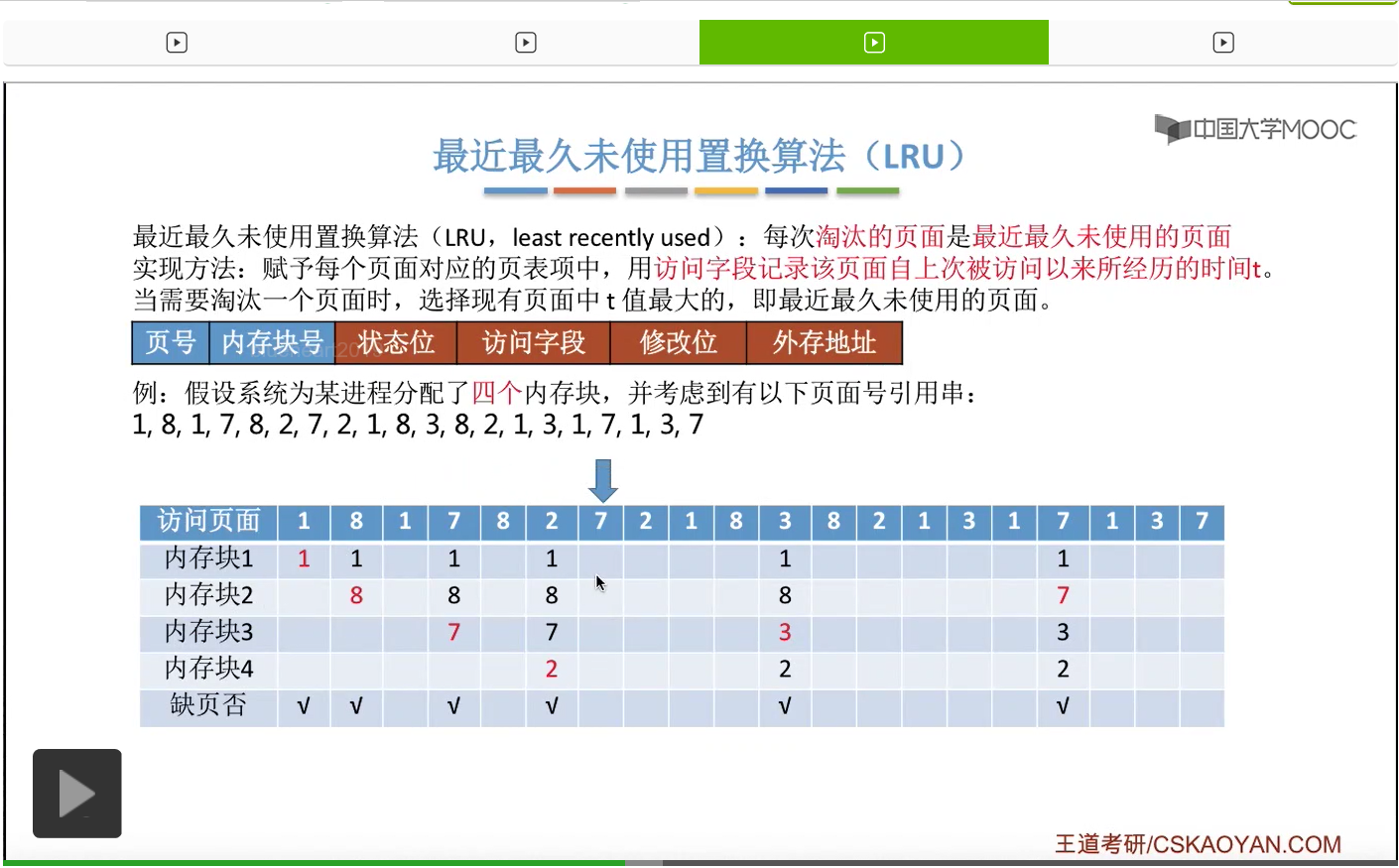
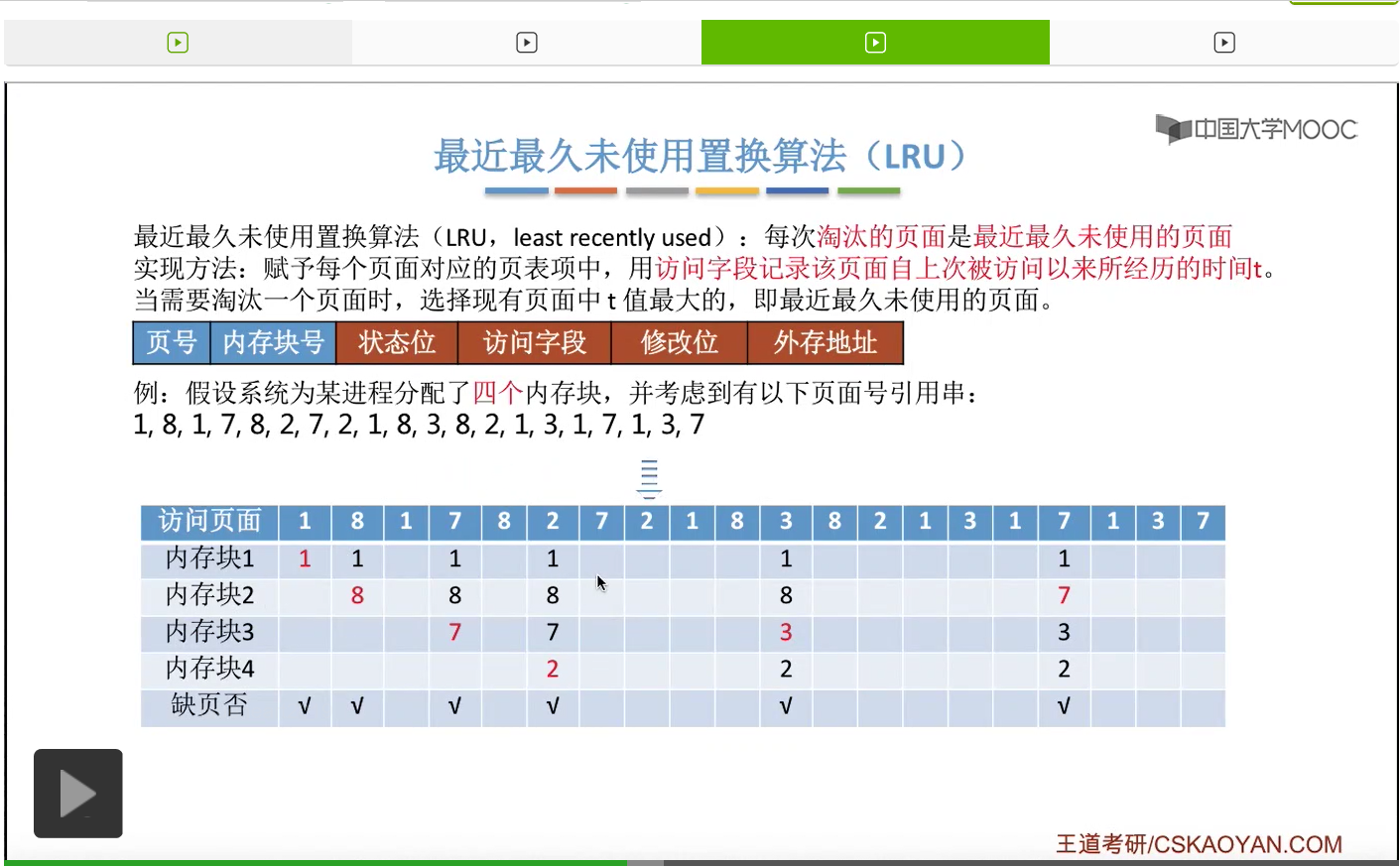


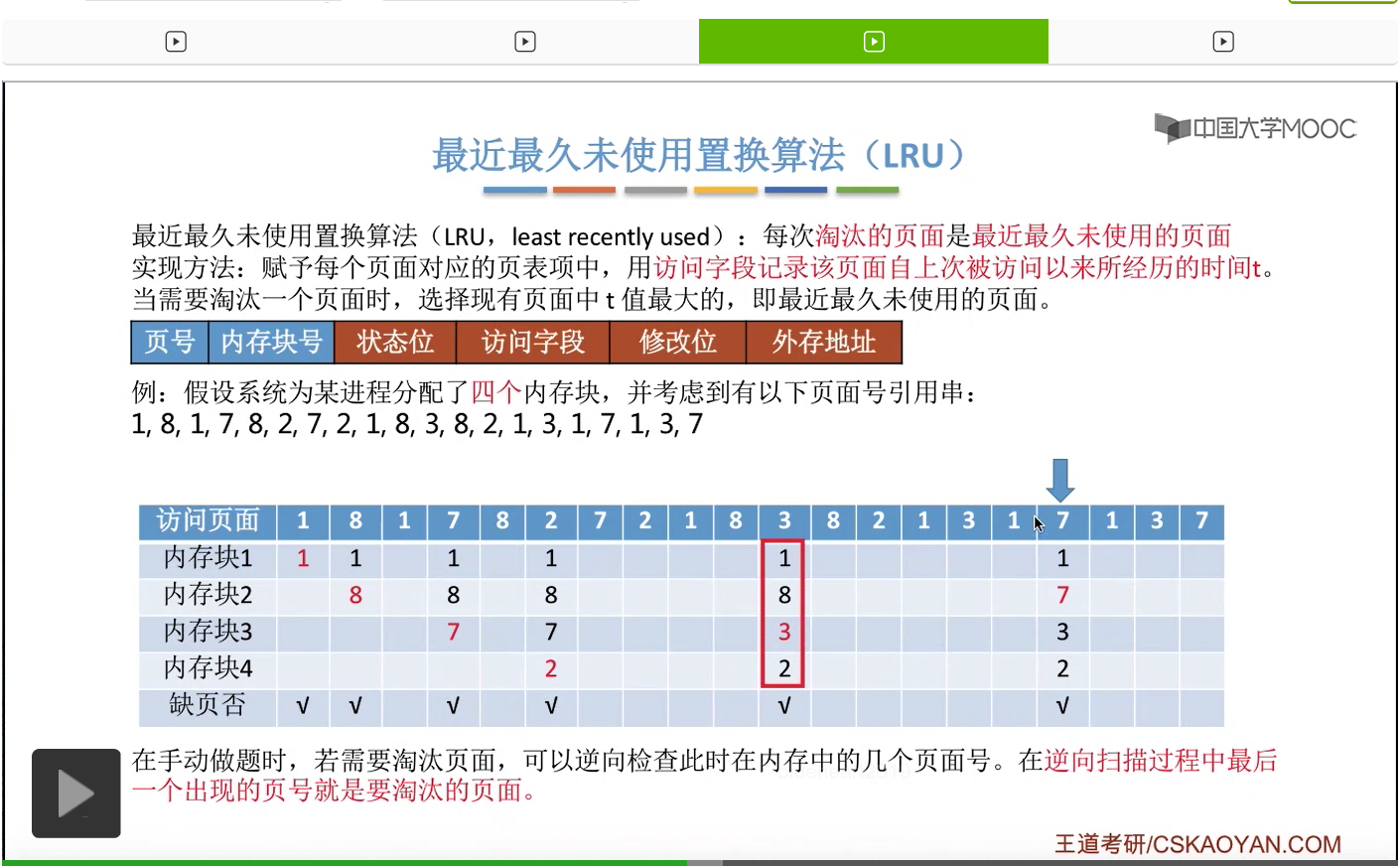
那一直到后面访问到这个3号页面的时候,由于此时给这个进程分配的4个内存块都已经用完了,所以必须选择淘汰其中的某个页面。那如果我们在手动做题的时候,可以从这个页号开始逆向地往前检查此时在内存当中拥有的1、8、7、2这几个页号从逆向扫描来看,出现的先后顺序是什么样的。那最后一个出现的页号,那肯定就是最近最久没有使用的页面了。

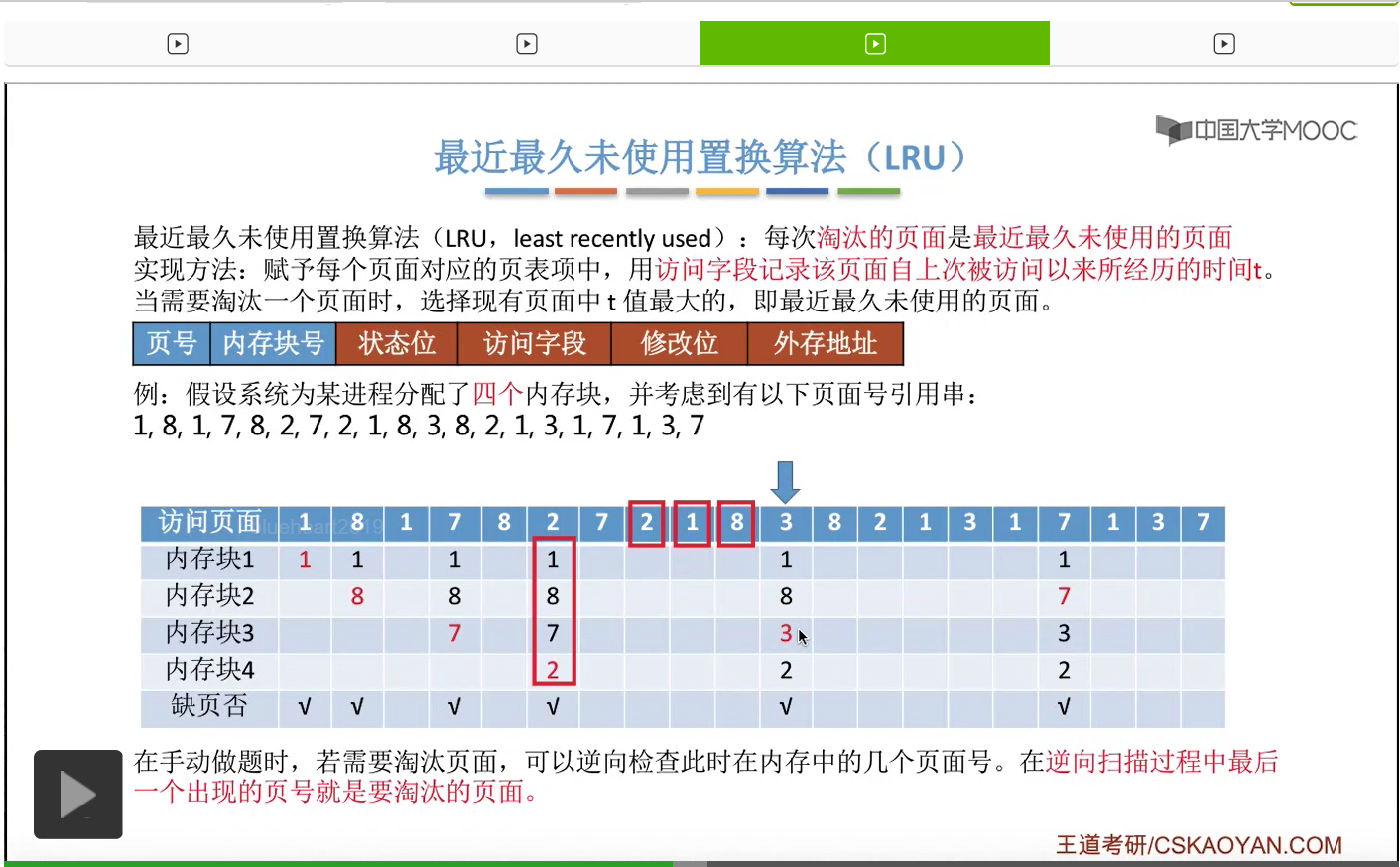
那同样的,在之后的这一系列访问当中都不会发生缺页,一直到访问到7号页的时候,又发生了一次缺页,并且需要选择淘汰一个页面。
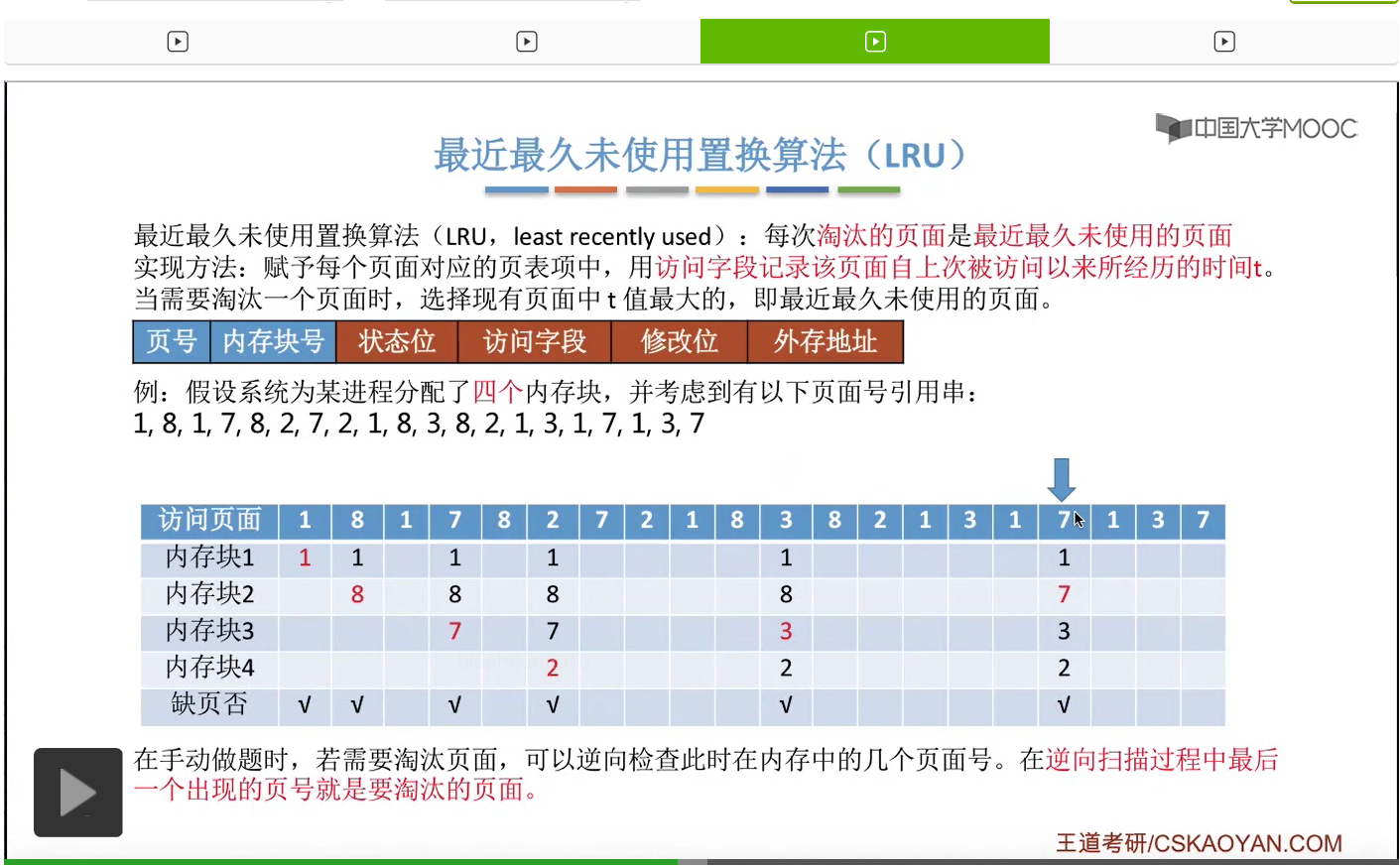
那和之前一样,我们从这个地方开始逆向地往前检查,看一下这几个页号出现的顺序分别是什么样的。
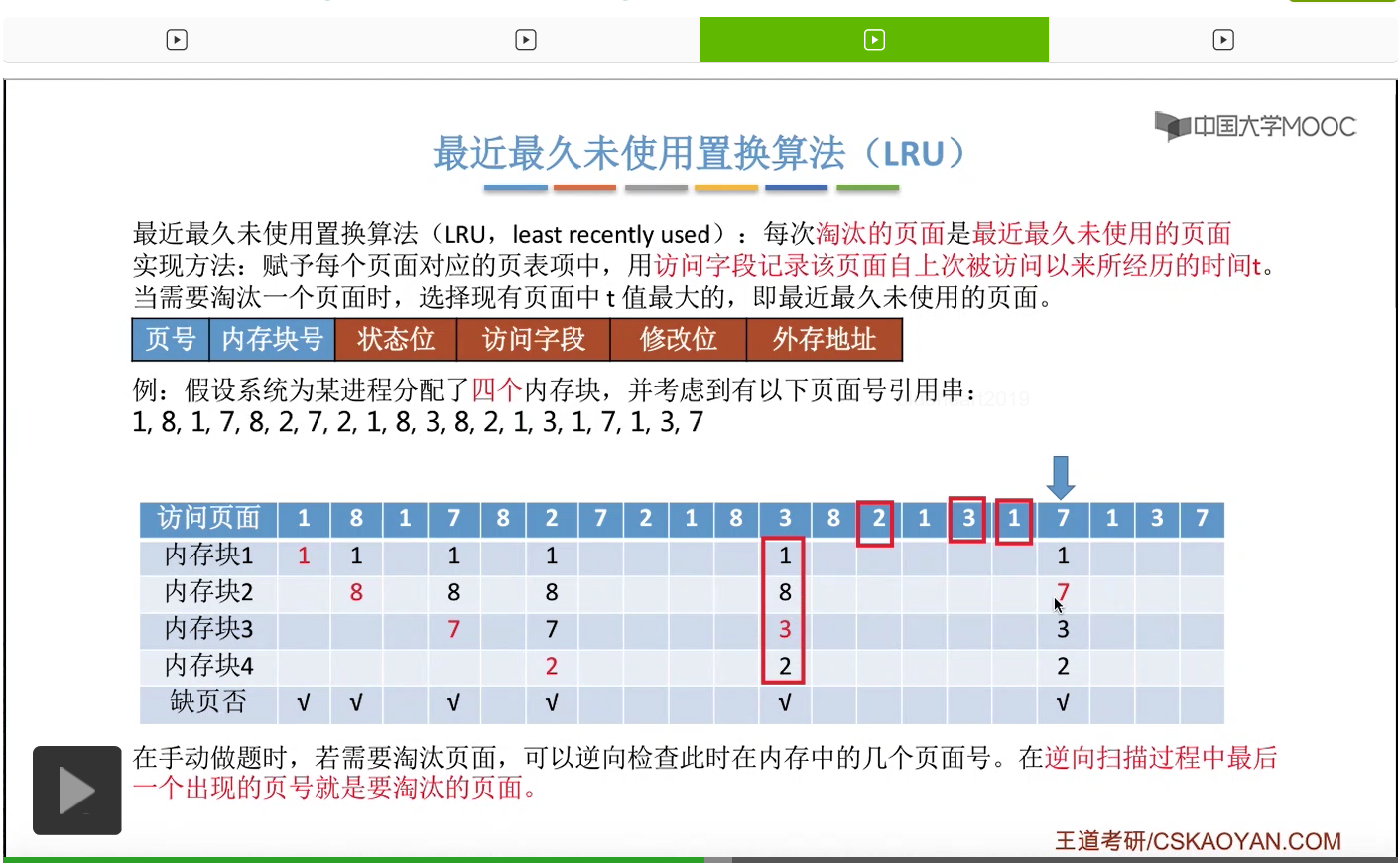
那最近最久未使用置换算法在实际的应用当中其实是需要专门的硬件的支持的,所以这个算法虽然性能很好,但是实现起来会很困难,并且开销很大。那在我们学习的这几个算法当中,最近最久未使用这个算法的性能是最接近最佳置换算法的。

那接下来我们再来看第四种————时钟置换算法。之前我们学到的这几种算法当中,最佳置换算法性能是最好的,但是无法实现。先进先出算法虽然实现简单,但是算法的性能很差,并且也会出现Belady异常。那最近最久未使用置换算法虽然性能也很好,但是实现起来开销会比较大。所以之前提到的那些算法都不能做到算法效果还有实际开销的一个平衡,因此人们就提出了时钟置换算法。它是一种性能和开销比较均衡的算法,又称为CLOCK算法,或者叫最近未用算法(NRU,Not Recently Used),英文缩写是NRU。

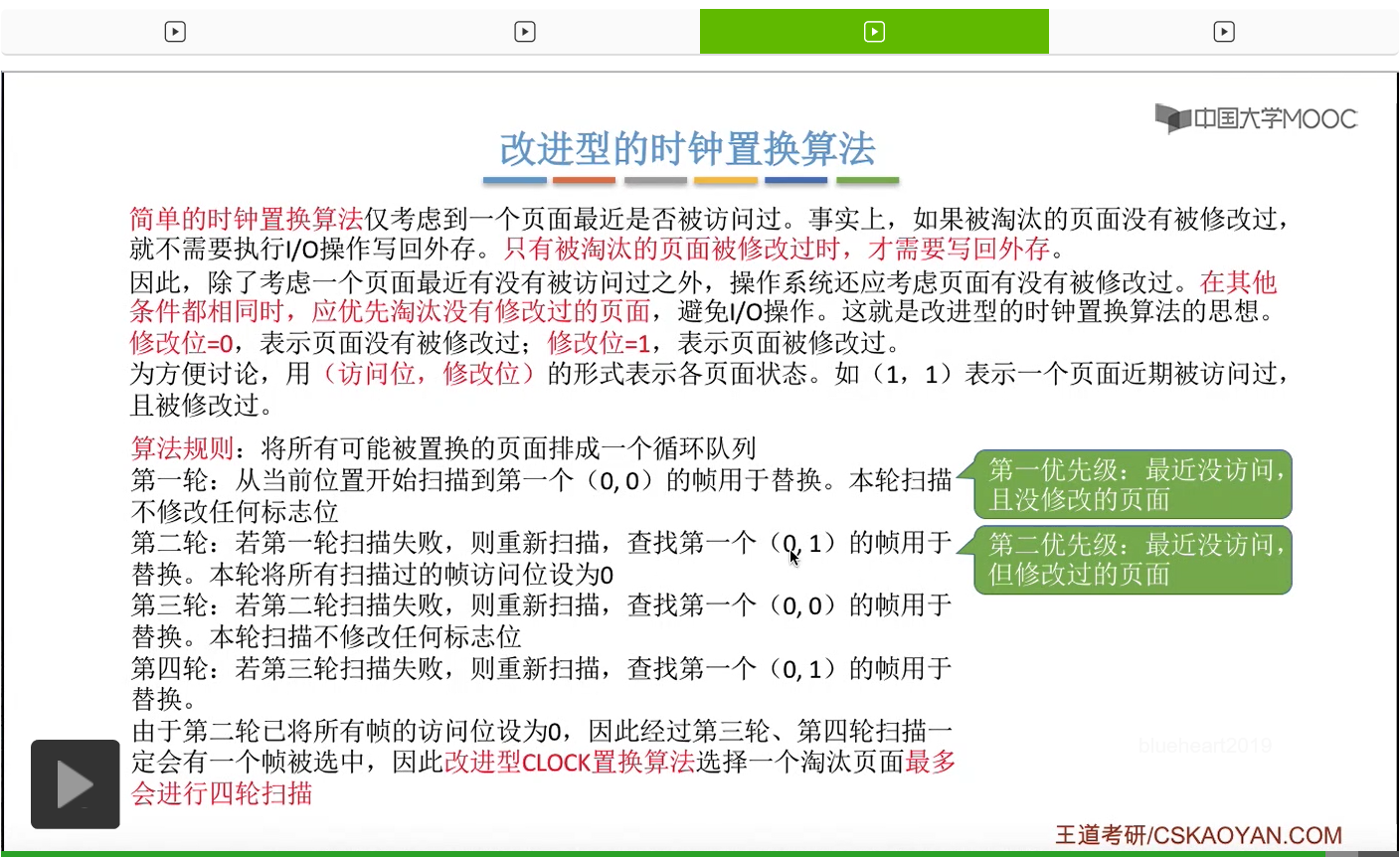
那在考试中我们需要掌握两种时钟置换算法,分别是简单的时钟置换算法还有改进型的时钟置换算法。那我们先来看简单的这种算法。首先我们要为每个页面设置一个访问位,访问位为1的时候就表示这个页面最近被访问过,访问位为0的时候表示这个页面最近没有被访问过。因此如果说访问了某个页面的话,那需要把这个页面的访问位变为1。那内存中的这些页面需要通过链接指针的方式把它们链接成一个循环队列。那当需要淘汰某个页面的时候,需要扫描这个循环队列,找到一个最近没有被访问过的页面,也就是访问位为0的页面。但是在扫描的过程中,需要把访问位为1的这些页面的访问位再重新置为0,所以这个算法有可能会经过两轮的扫描。如果说所有的页面访问位都是1的话,那第一轮扫描这个循环队列就并不会找到任何一个访问位为0的页面。只不过在第一轮扫描当中,会把所有的页面的访问位都置为0,所以第二轮扫描的时候就肯定可以找到一个访问位为0的页面。所以这个算法在淘汰一个页面的时候最多会经历两轮的扫描。

那光看这个文字的描述其实还很抽象的,我们直接来看一个例子。那刚开始由于有5个空闲的内存块,所以前五个访问的这个页号1、3、4、2、5都可以顺利地放入内存当中。只有在访问到6号页的时候,才需要考虑淘汰某个页面。

那么在内存当中的1、3、4、2、5这几个页面会通过链接指针的方式链接成一个这样的循环队列。

















时钟置换算法的一个运行的过程,并且通过刚才的这个例子大家会发现,这个扫描的过程有点像一个时钟的那个时针在不断地转圈的一个过程。所以为什么这个算法要叫做时钟置换算法,它其实是一个很形象的比喻。那其实经过刚才的分析,我们也很容易理解,为什么它还称作最近未用算法。因为我们会为各个页面设置一个访问位,访问位为1的时候表示最近用过,访问位为0的时候表示最近没有用过。但是我们在选择淘汰一个页面的时候,是选择那种最近没有被访问过也就是访问位为0的页面,因此这种算法也可以称作为最近未用算法。

那接下来我们再来学习改进型的时钟置换算法。其实在之前学习的这个简单的时钟置换算法当中,只是很简单地考虑到了一个页面最近是否被访问过。但通过之前的讲解我们知道,如果一个被淘汰的页面没有被修改过的话,那么是不需要执行I/O操作而把它写回外存的。所以如果说我们能够优先淘汰没有被修改过的页面的话,那么实际上就可以减少这些I/O操作的次数,
从而让这个置换算法的性能得到进一步的提升。那这就是改进型的时钟置换算法的一个思想。
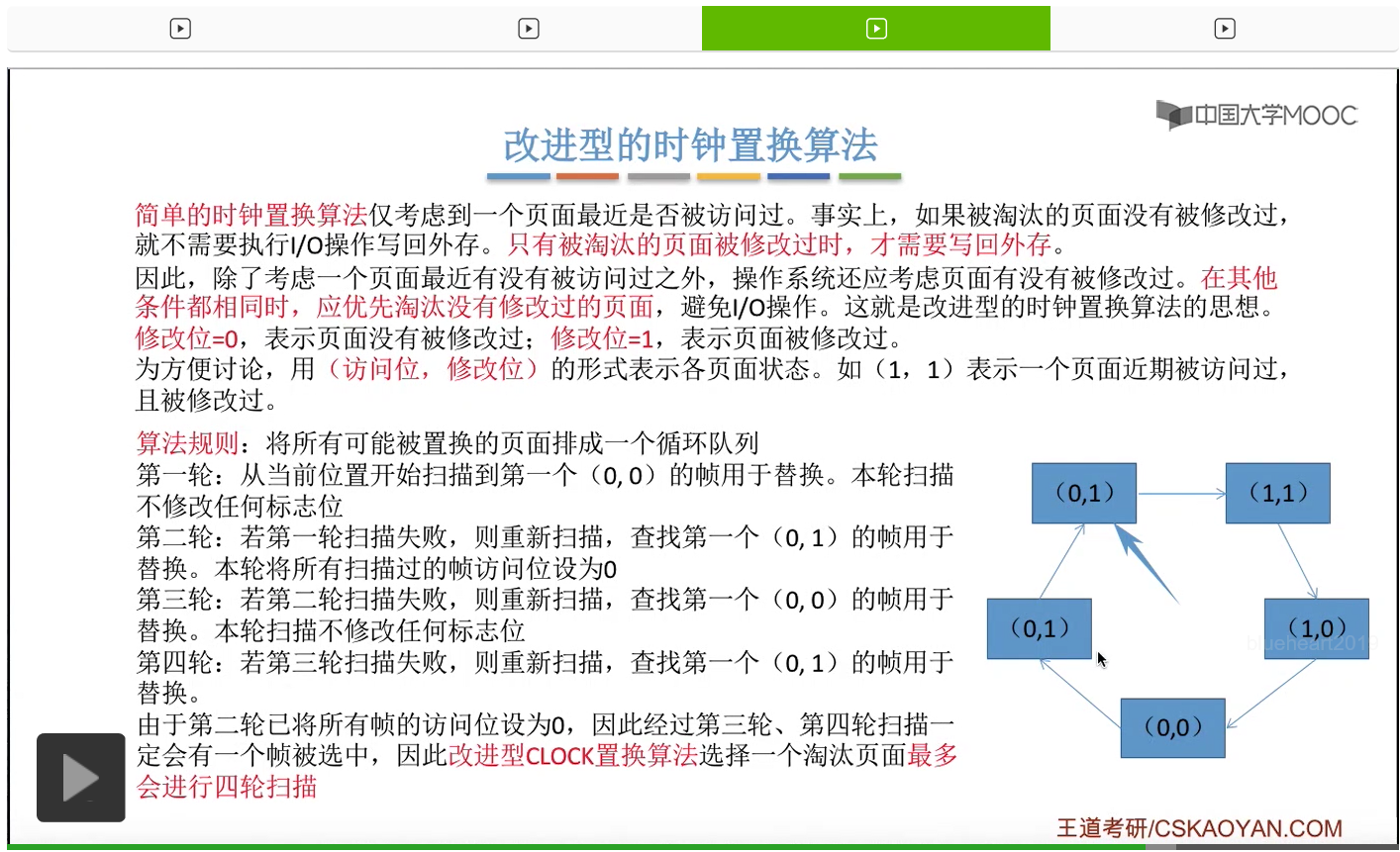
所以为了实现这件事,我们还需要为各个页面增加一个修改位,修改位为0的时候表示这个页面在内存当中没有被修改过,那修改位为1的时候表示页面被修改过。那我们在接下来的讨论当中,会用访问位、修改位这样二元组的形式来标识各个页面的状态。比如说访问位为1、修改位也为1的话那就表示这个页面近期被访问过,并且也曾经被修改过。

那和简单的时钟置换算法一样,我们也需要把所有的可能被置换的页面排成一个循环队列。

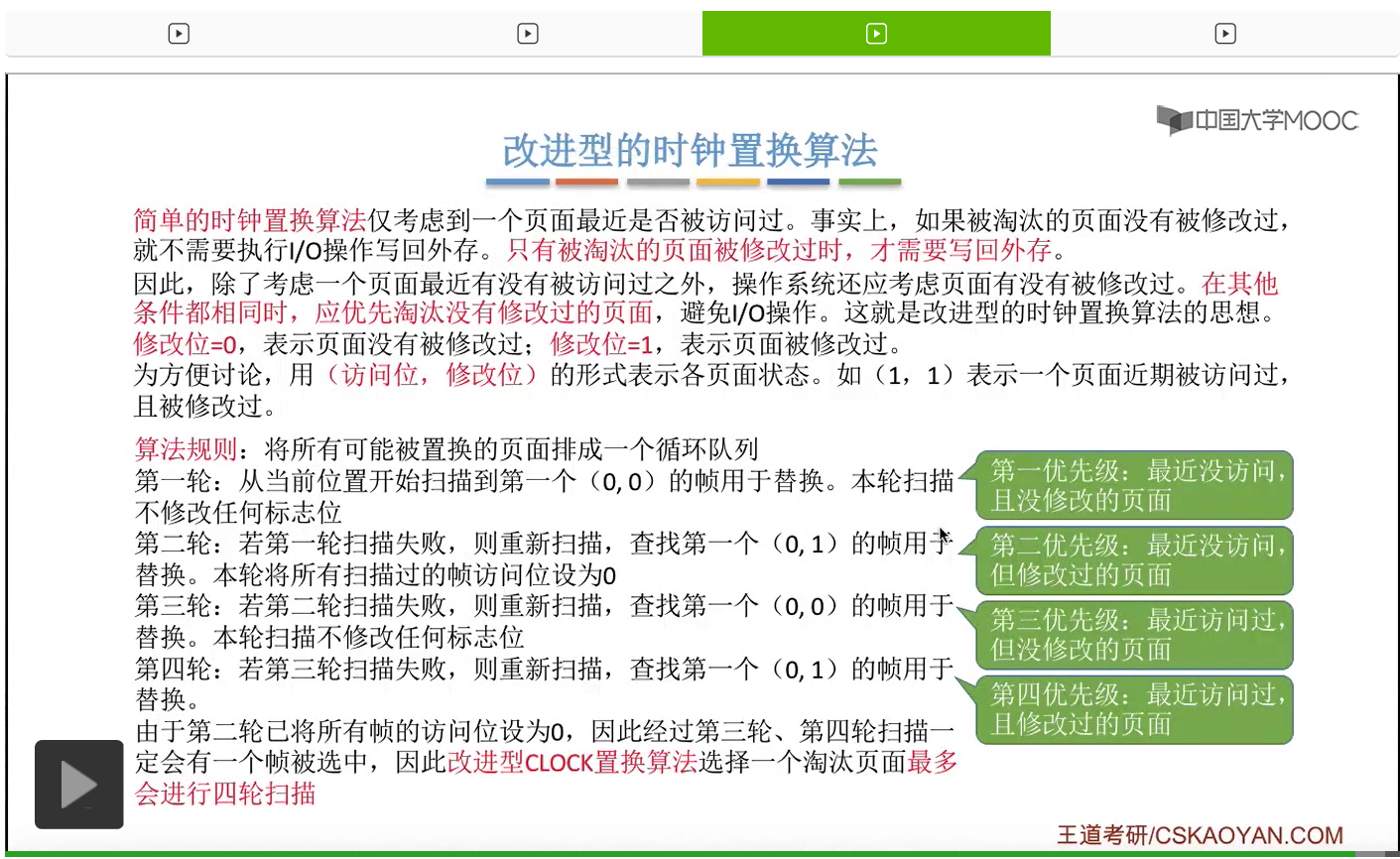
在第一轮扫描的时候,会从当前位置开始往后依次扫描,尝试找到第一个最近没有被访问过并且也没有修改过的页面,对它进行淘汰,那第一轮扫描是不修改任何的标志位的。那如果第一轮扫描没有找到(0,0)这样的页面的话,就需要进行第二轮的扫描。第二轮的扫描会尝试找到第一个最近没有被访问过但是被修改过的这个页面进行替换。并且被扫描过的那些页面的访问位,都会被设置为0。那如果第二轮扫描失败,需要进行第三轮扫描。第三轮扫描会尝试找到第一个访问位和修改位都为0的这个页面,进行淘汰。并且第三轮扫描并不会修改任何的标志位。
那如果第三轮扫描失败的话,还需要进行第四轮扫描。找到第一个(0,1)的页帧用于替换。那由于第二轮的扫描已经把所有的访问位都设为了0了,所以经过第三轮、第四轮的扫描之后,肯定是可以找到一个要被淘汰的页面的。所以改进型的这种时钟置换算法,选择一个淘汰页面,最多会进行四轮扫描。
那其实这个过程光看文字描述也是很抽象的,不太容易理解。假设系统为一个进程分配了5个内存块,那当这个内存块被占满之后,各个页面会用这种链接的方式连成一个循环的队列。

那此时如果要淘汰一个页面的话,需要从这个队列的队头开始依次地扫描。



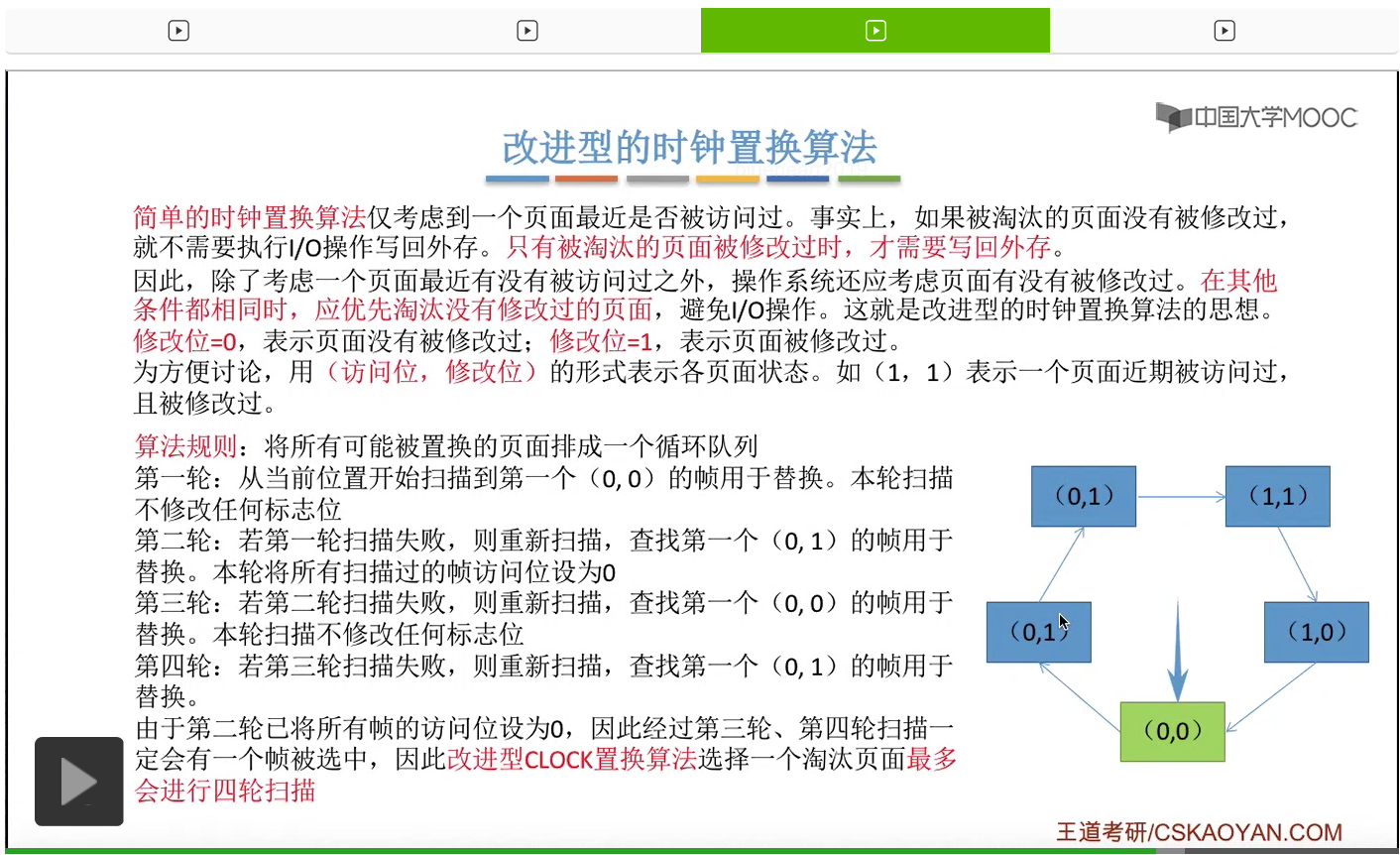

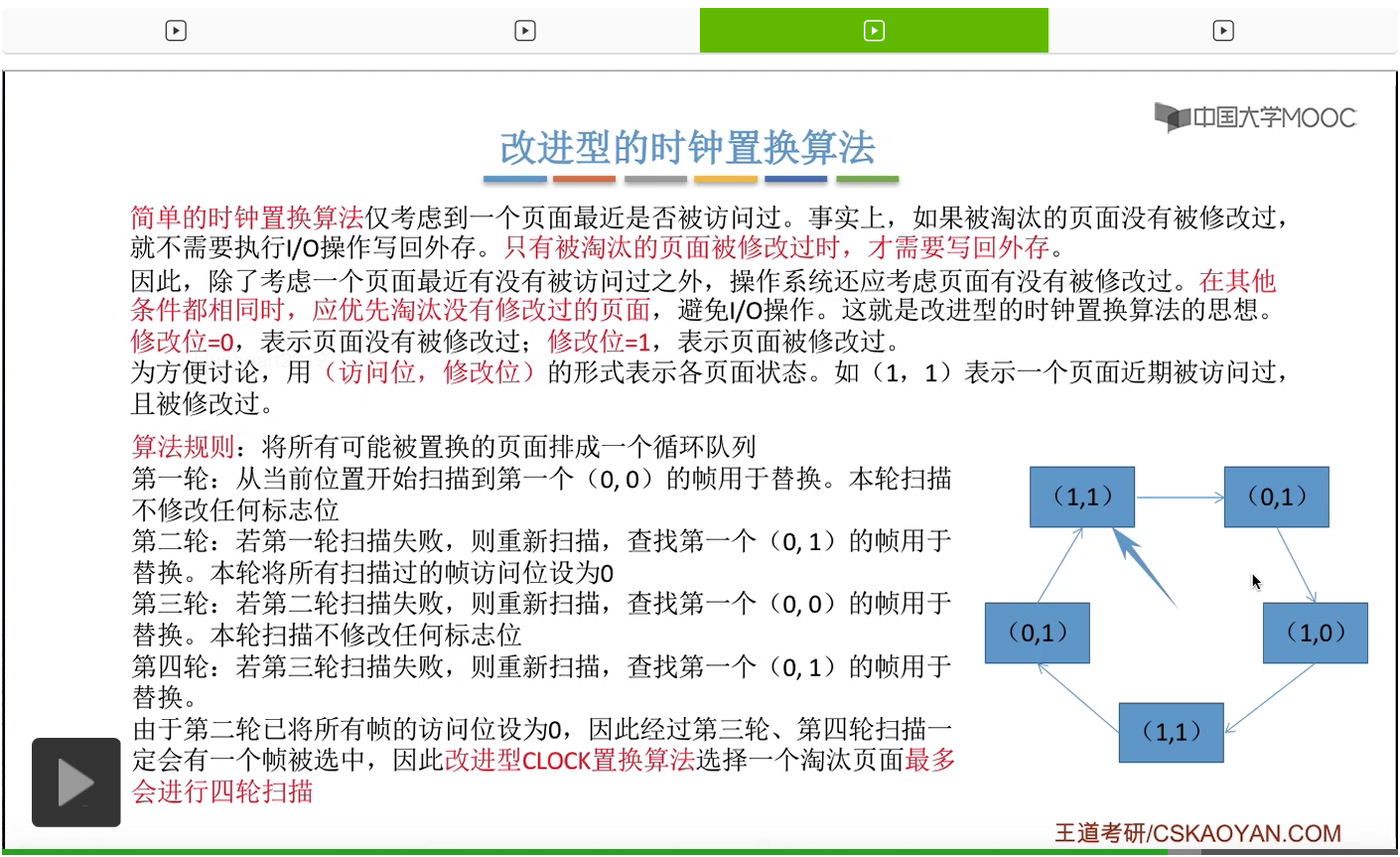
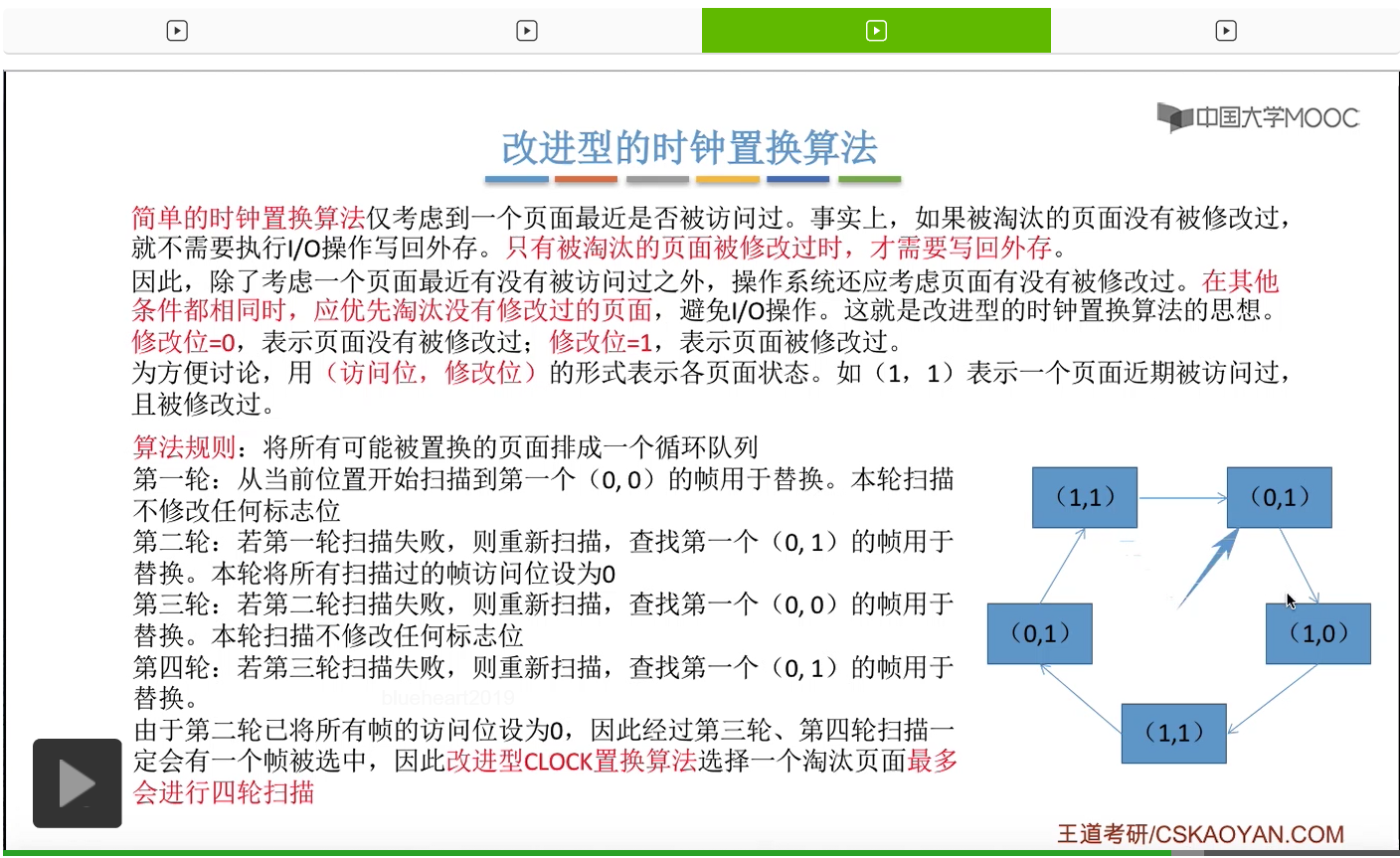
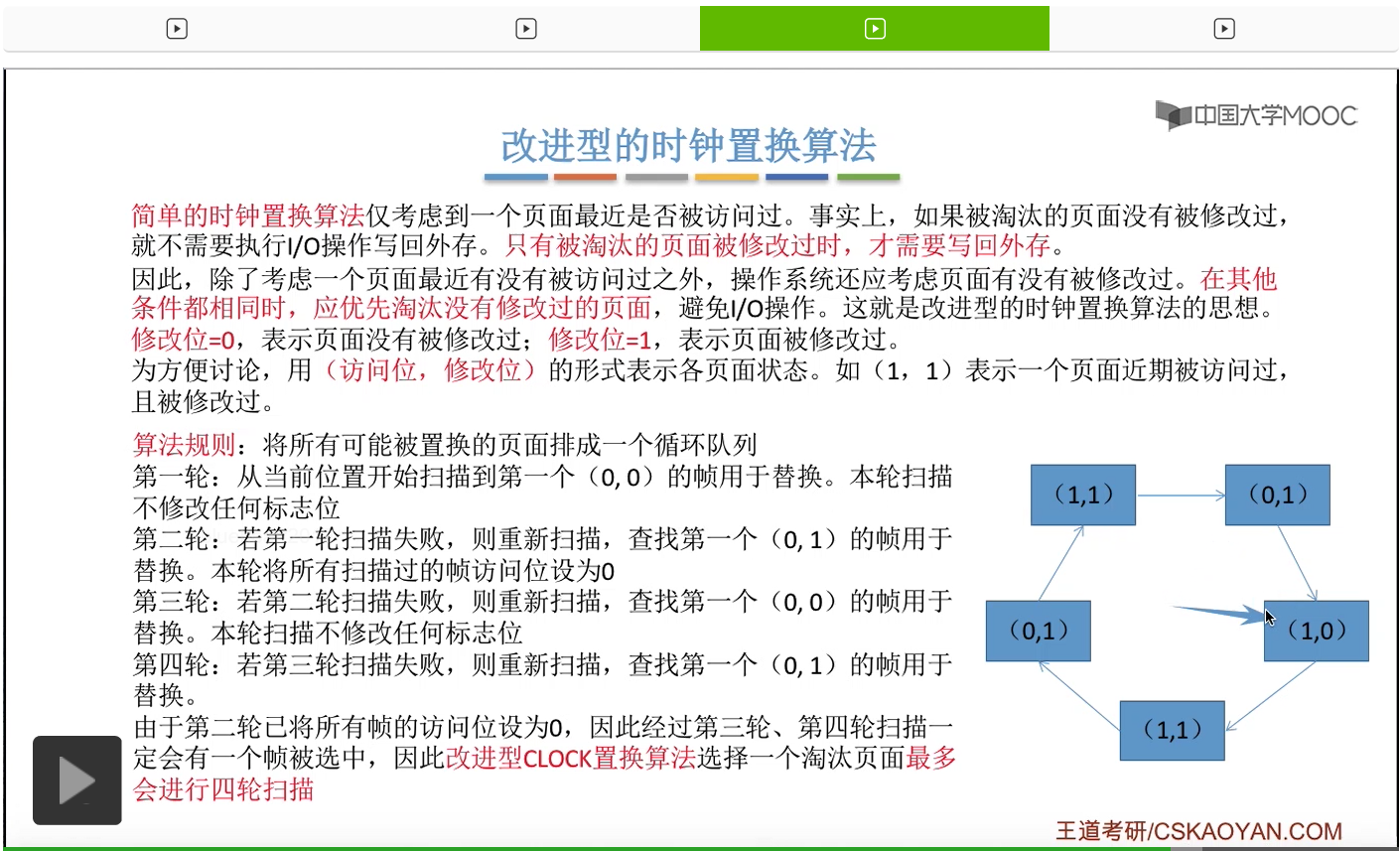


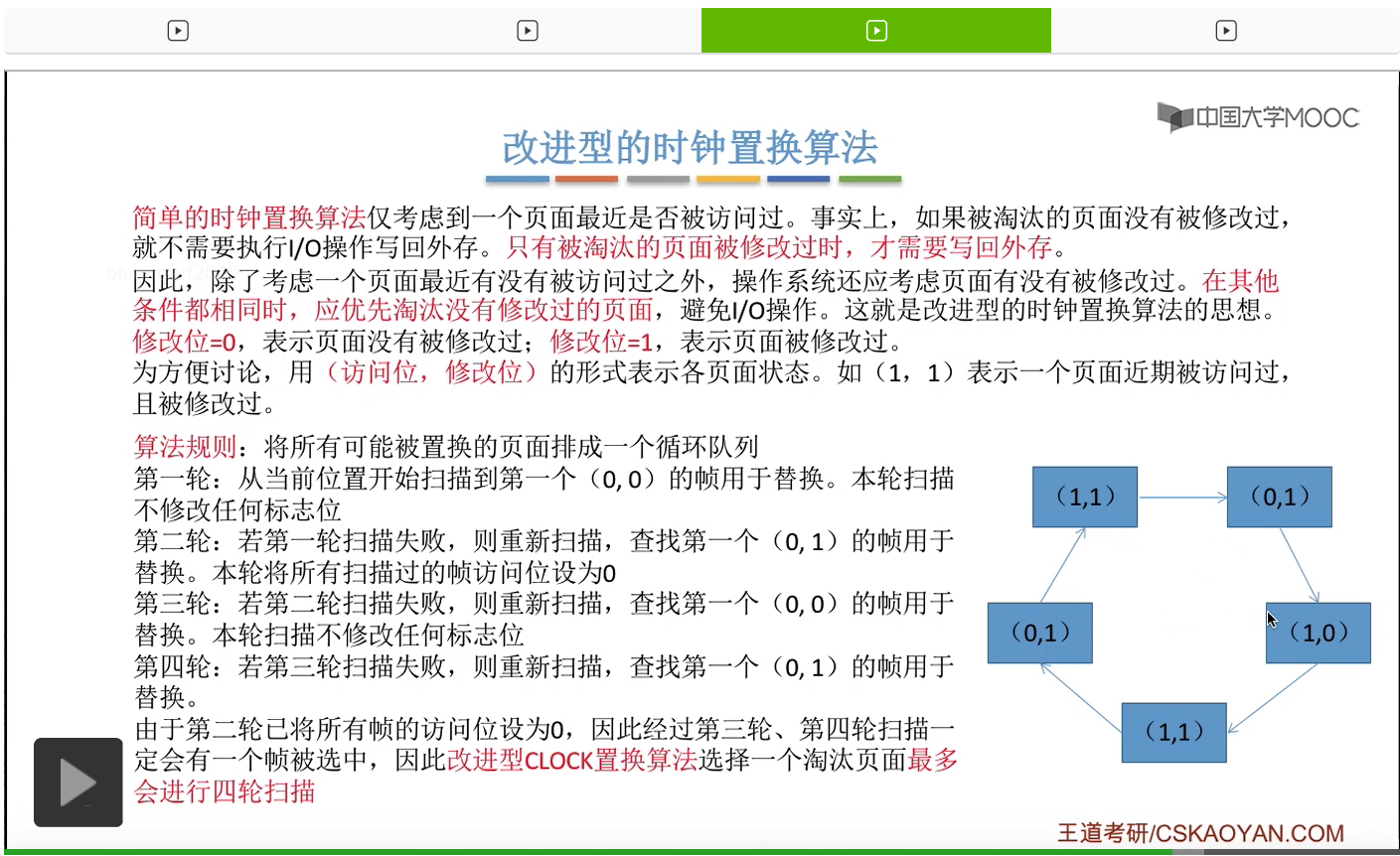



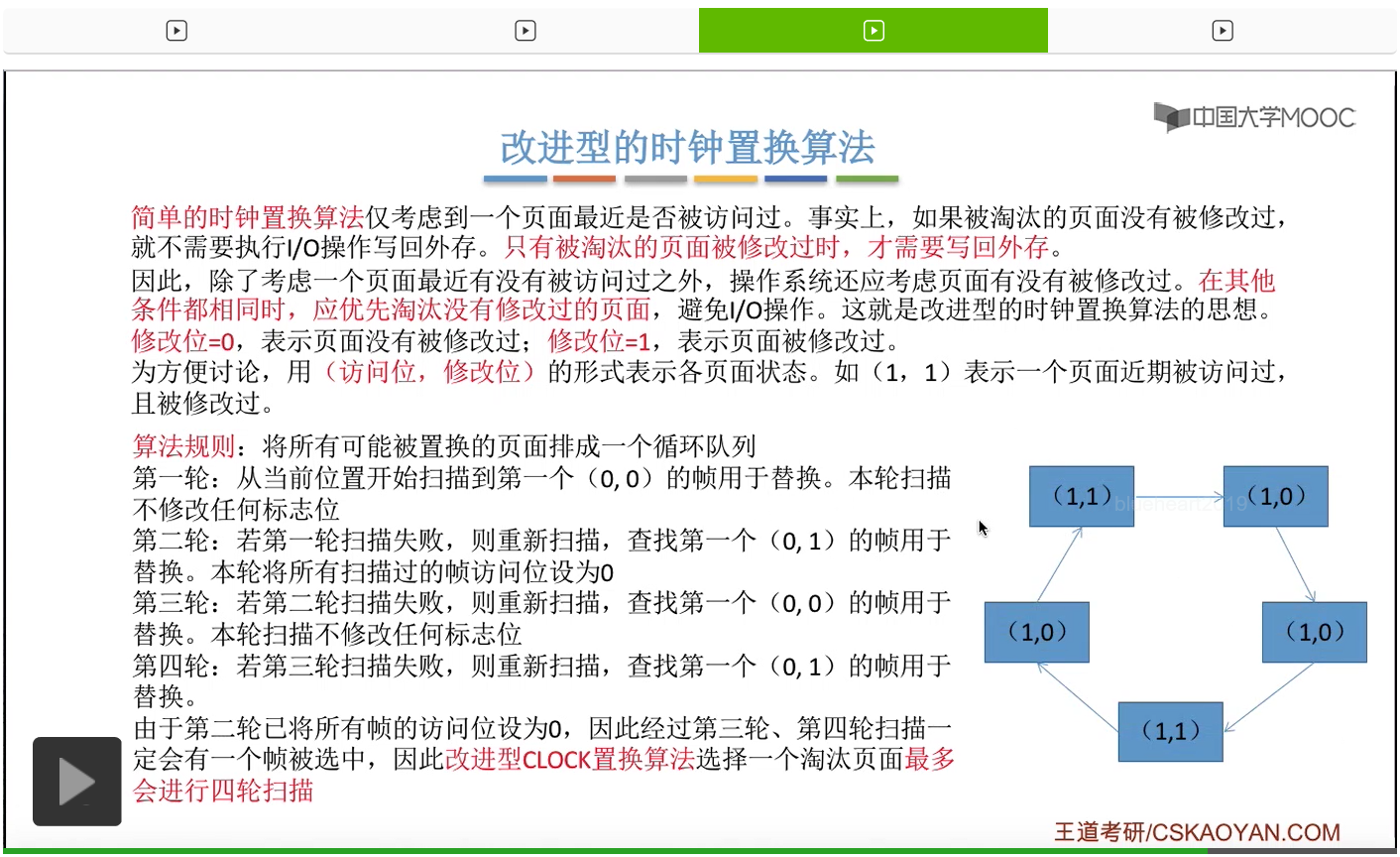
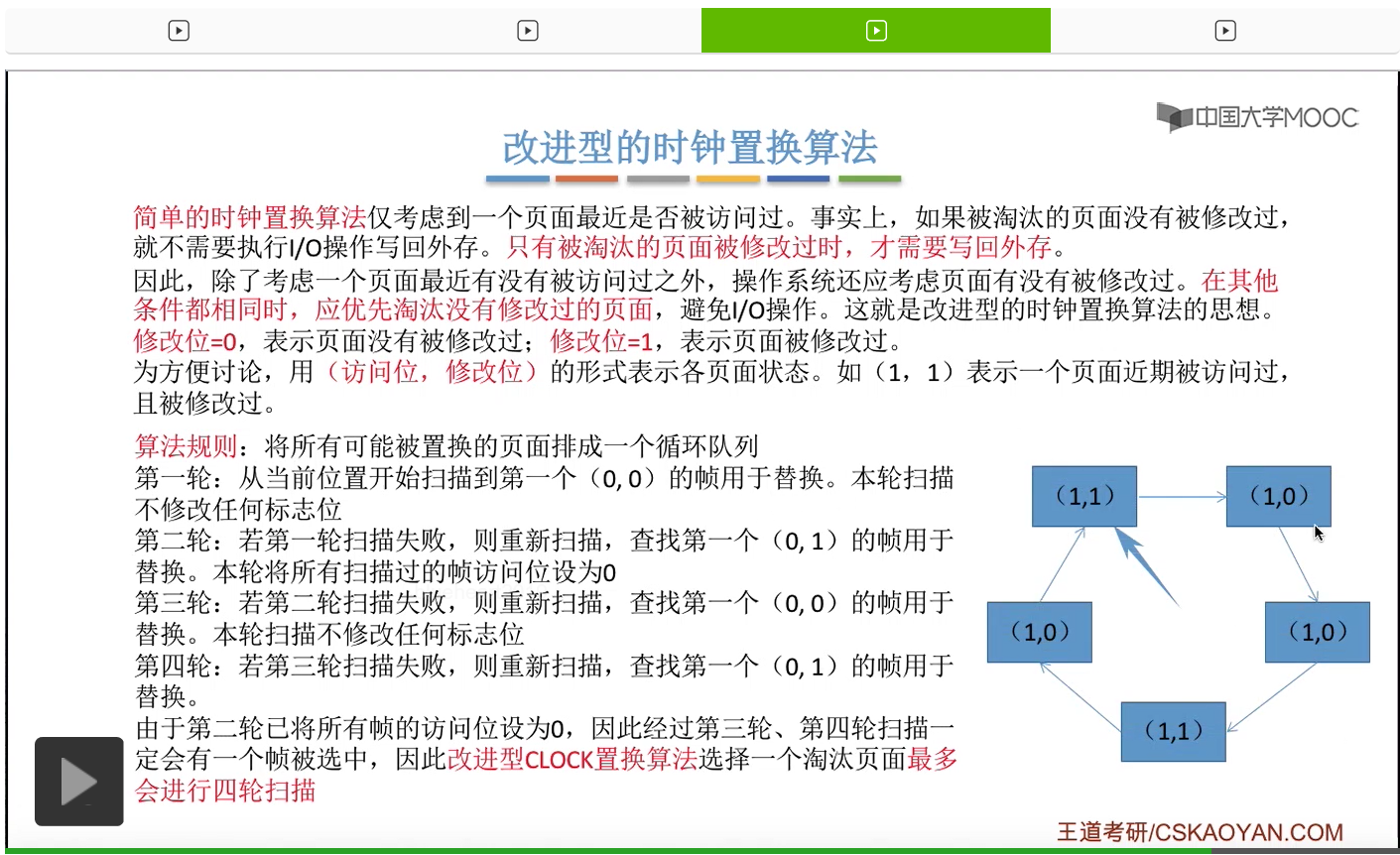
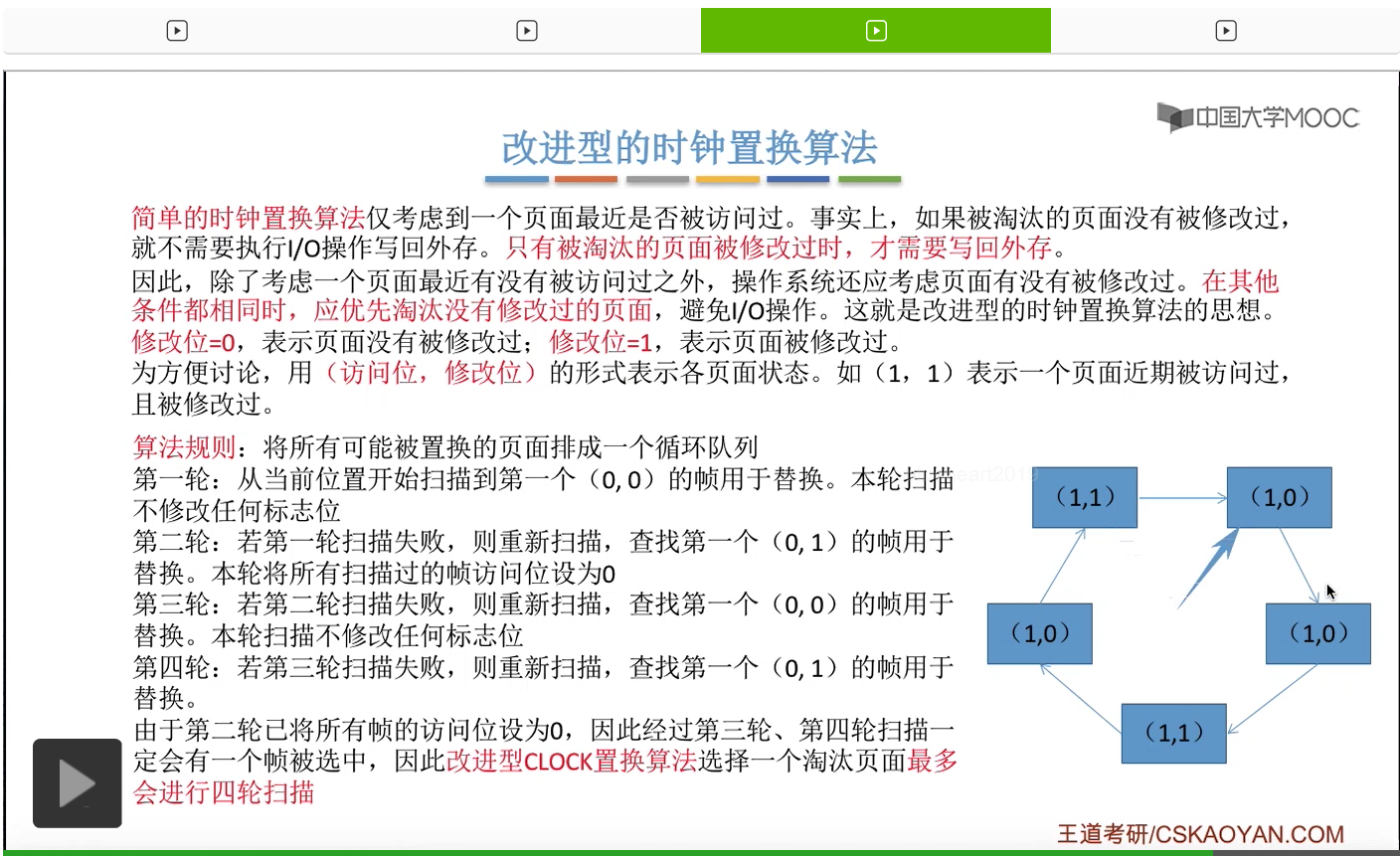
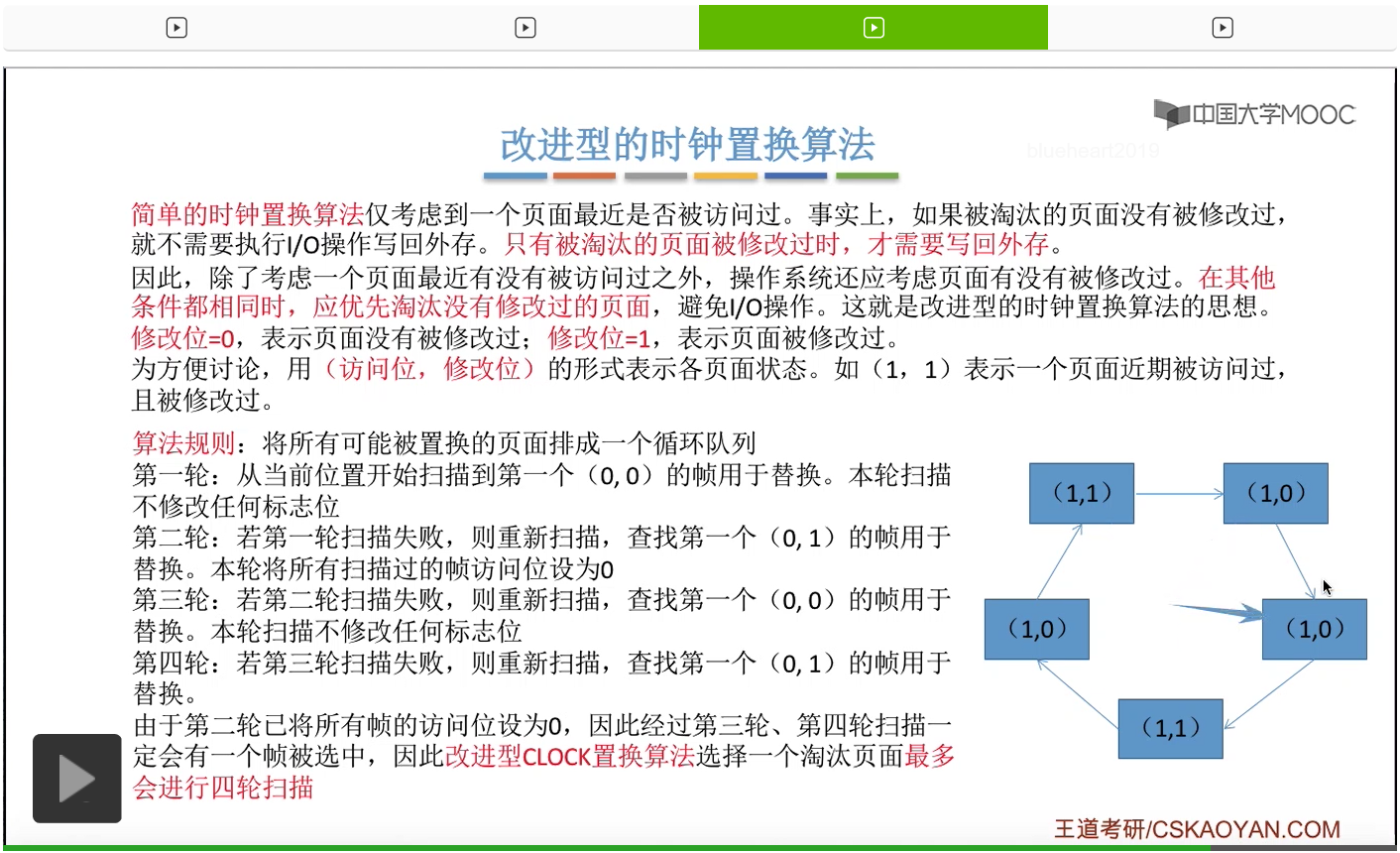

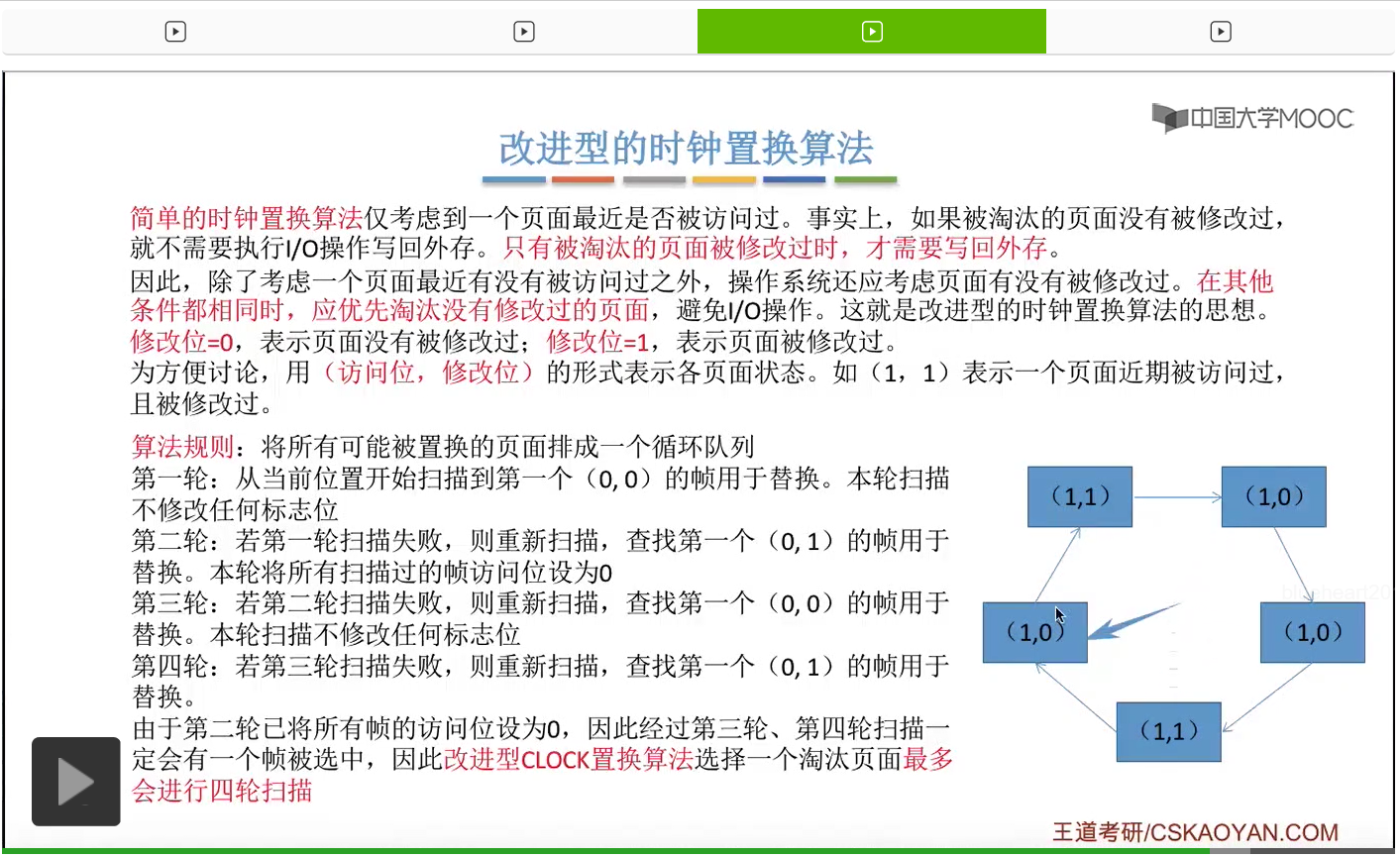
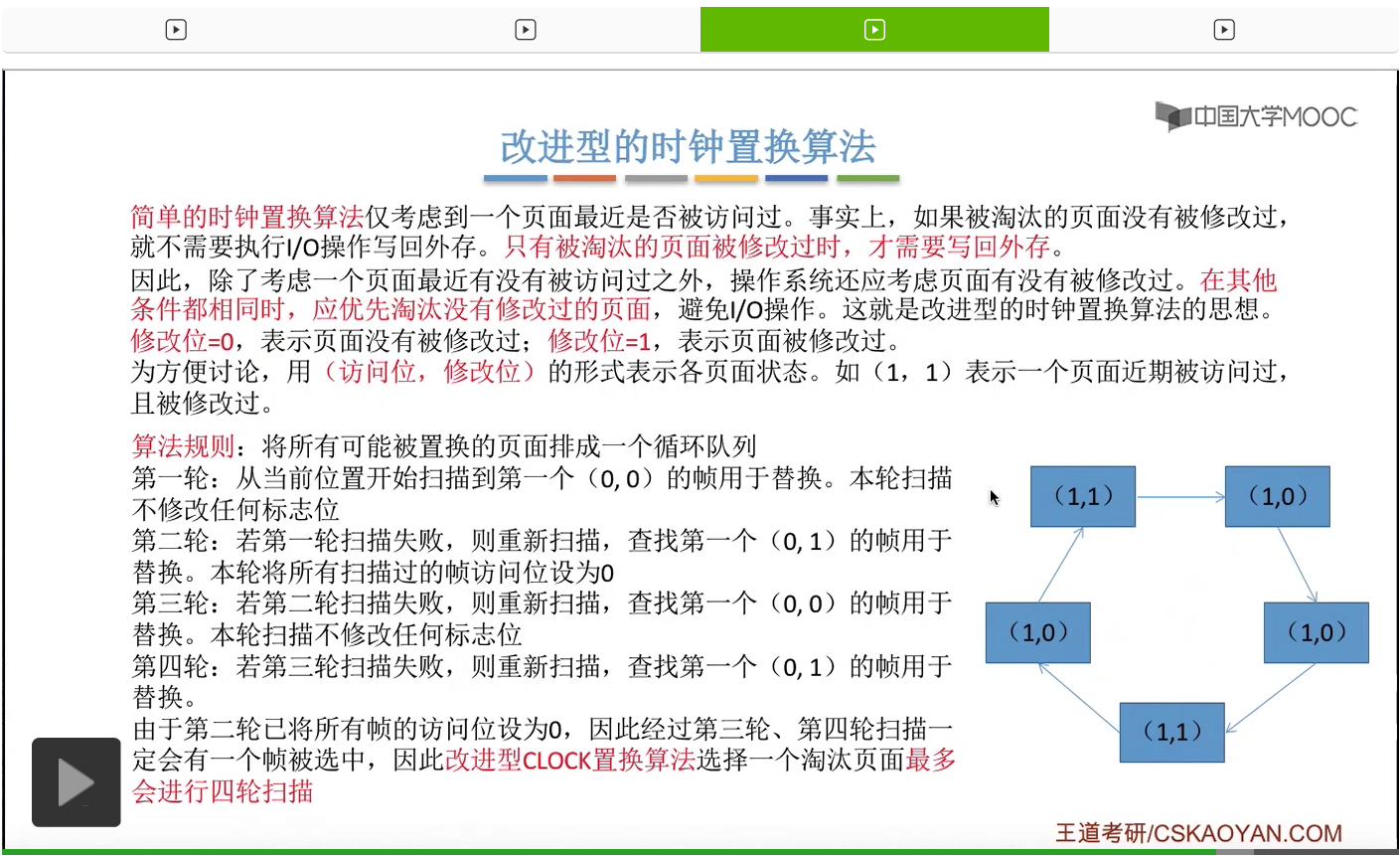

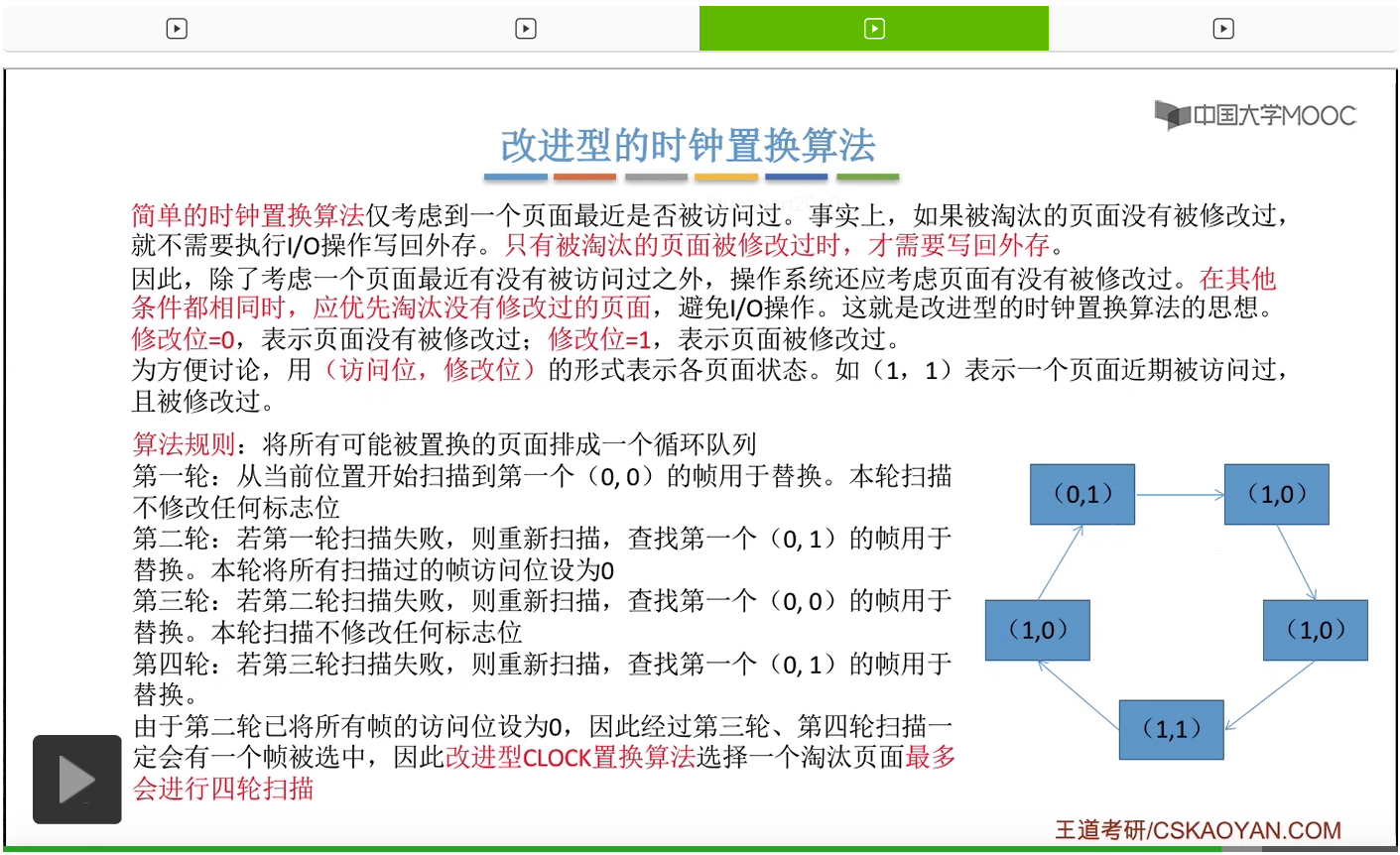

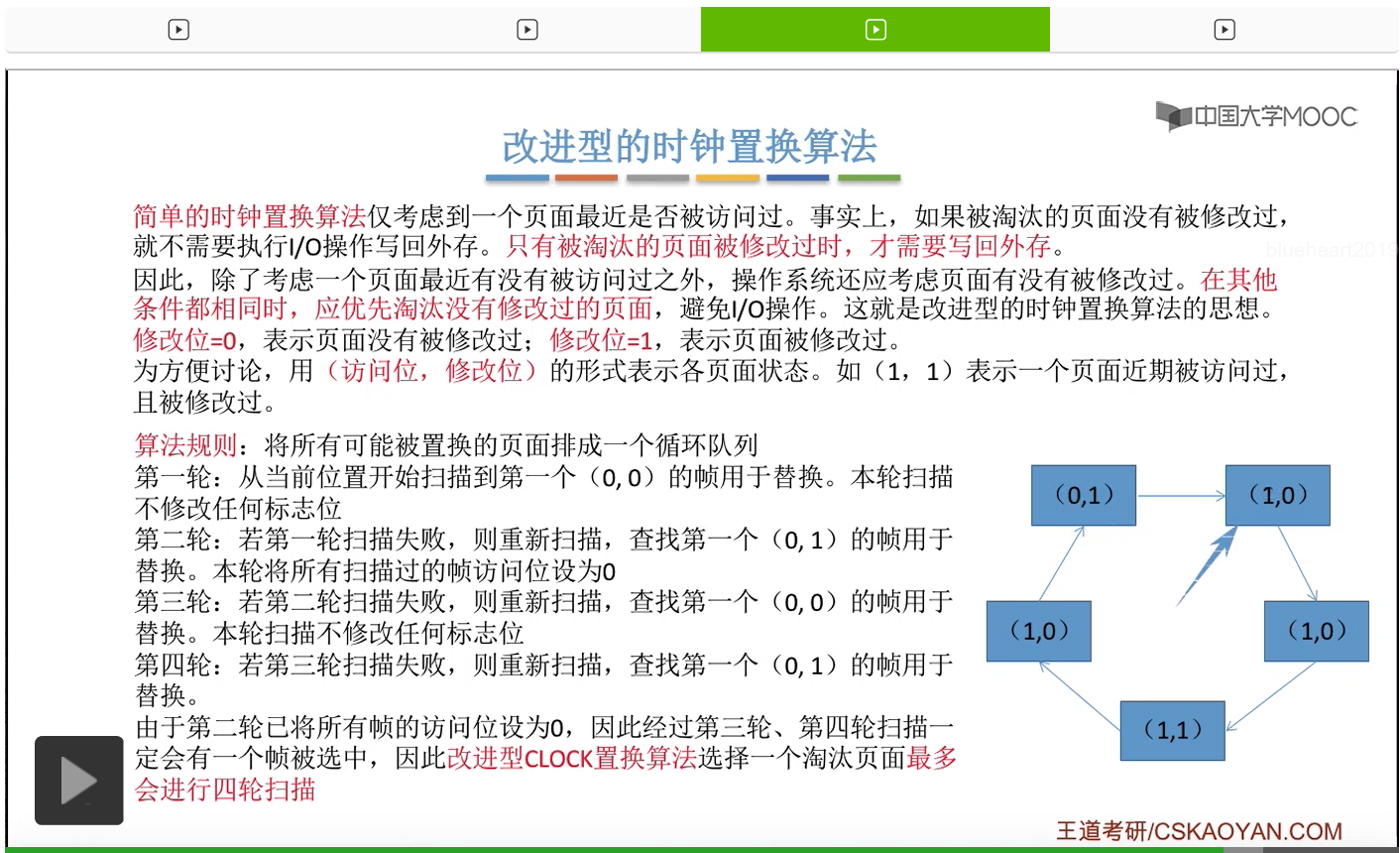

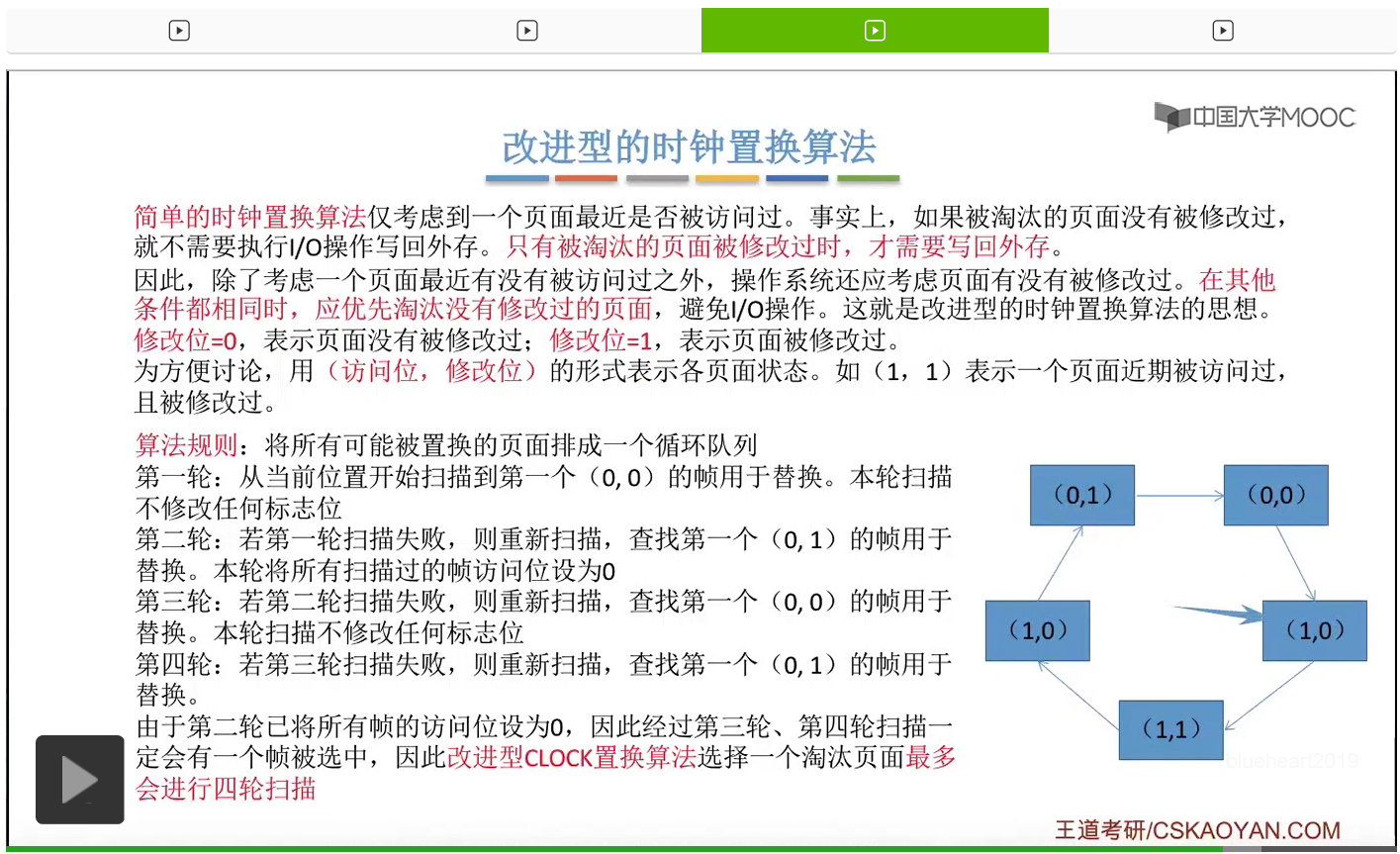
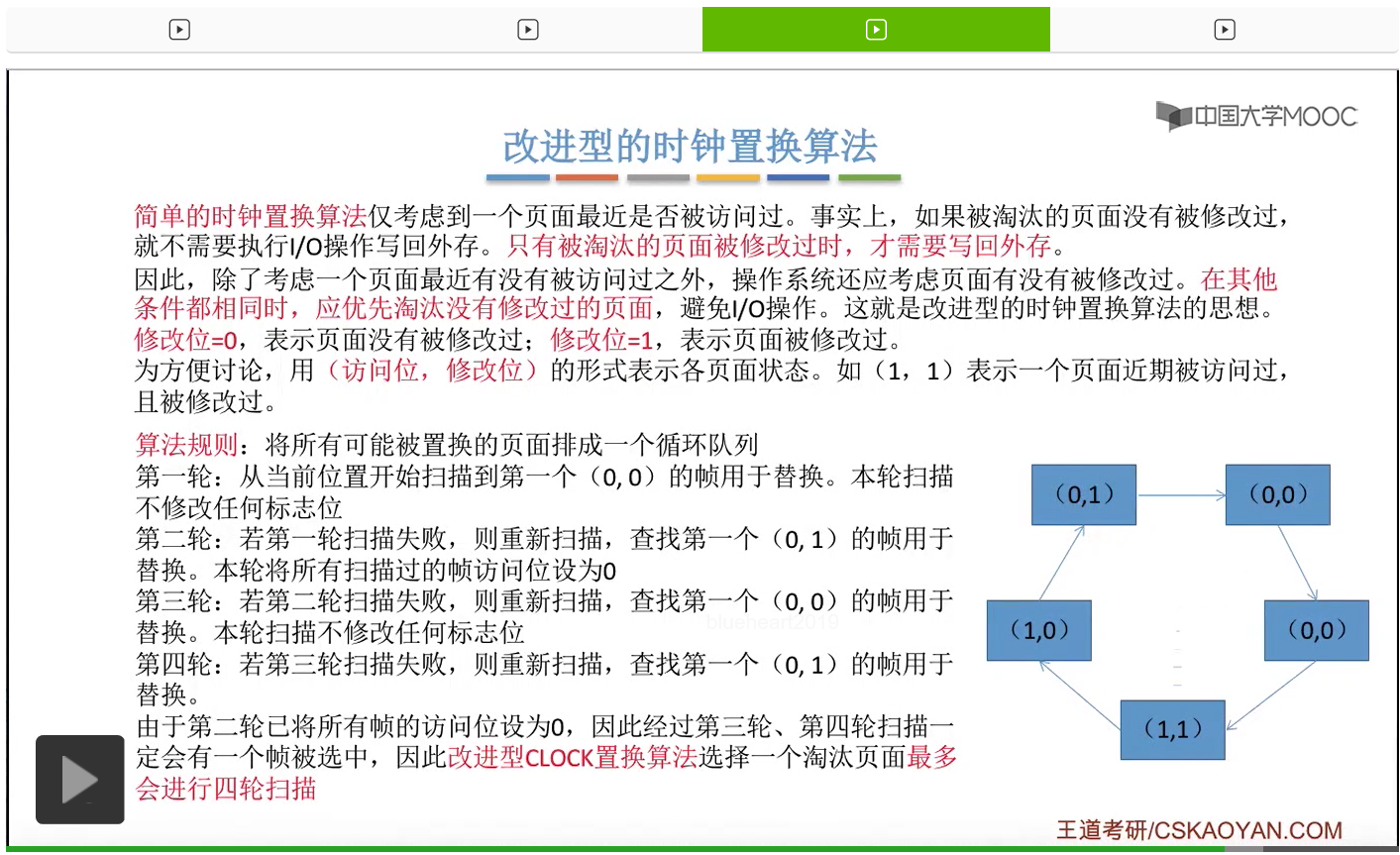
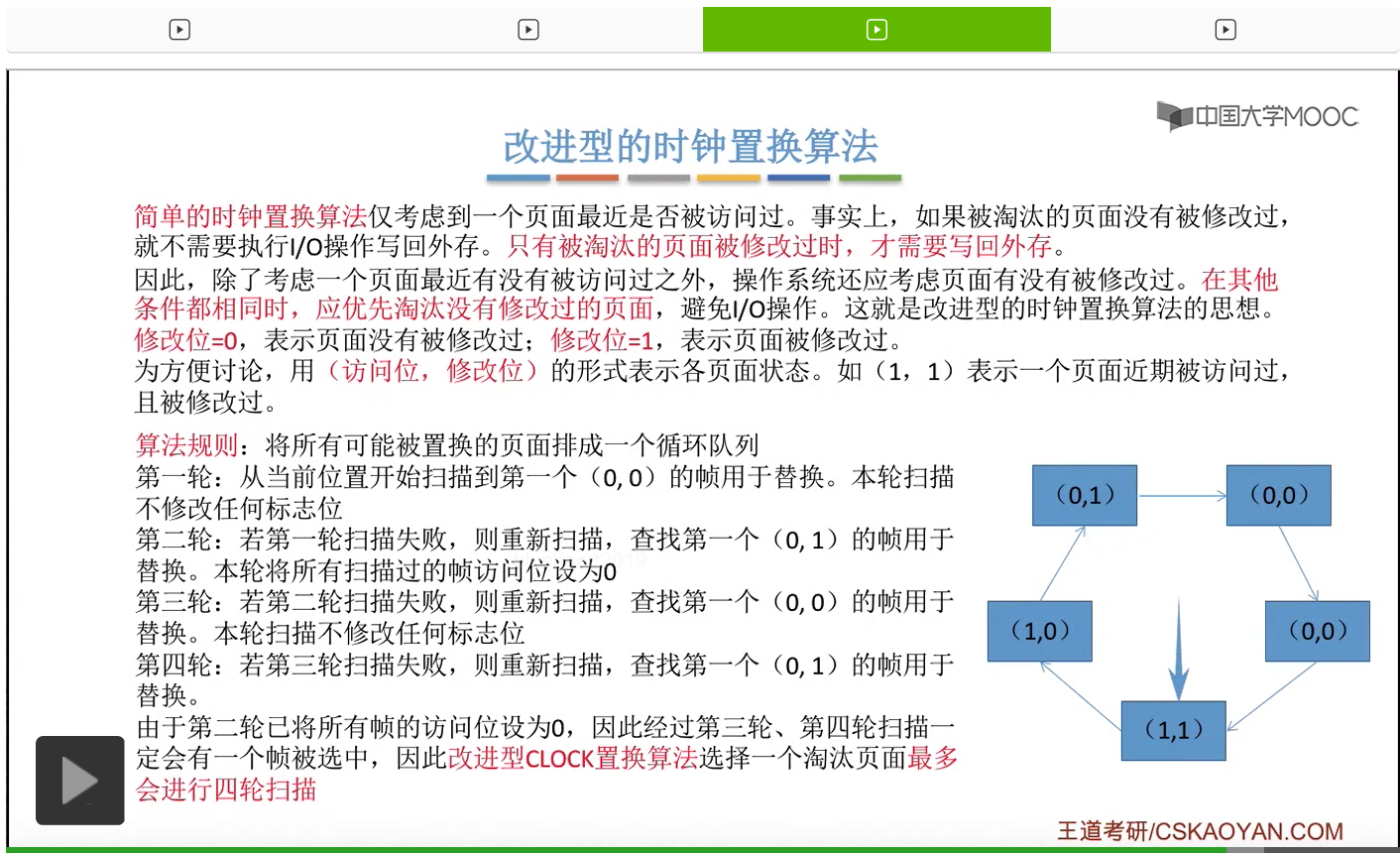
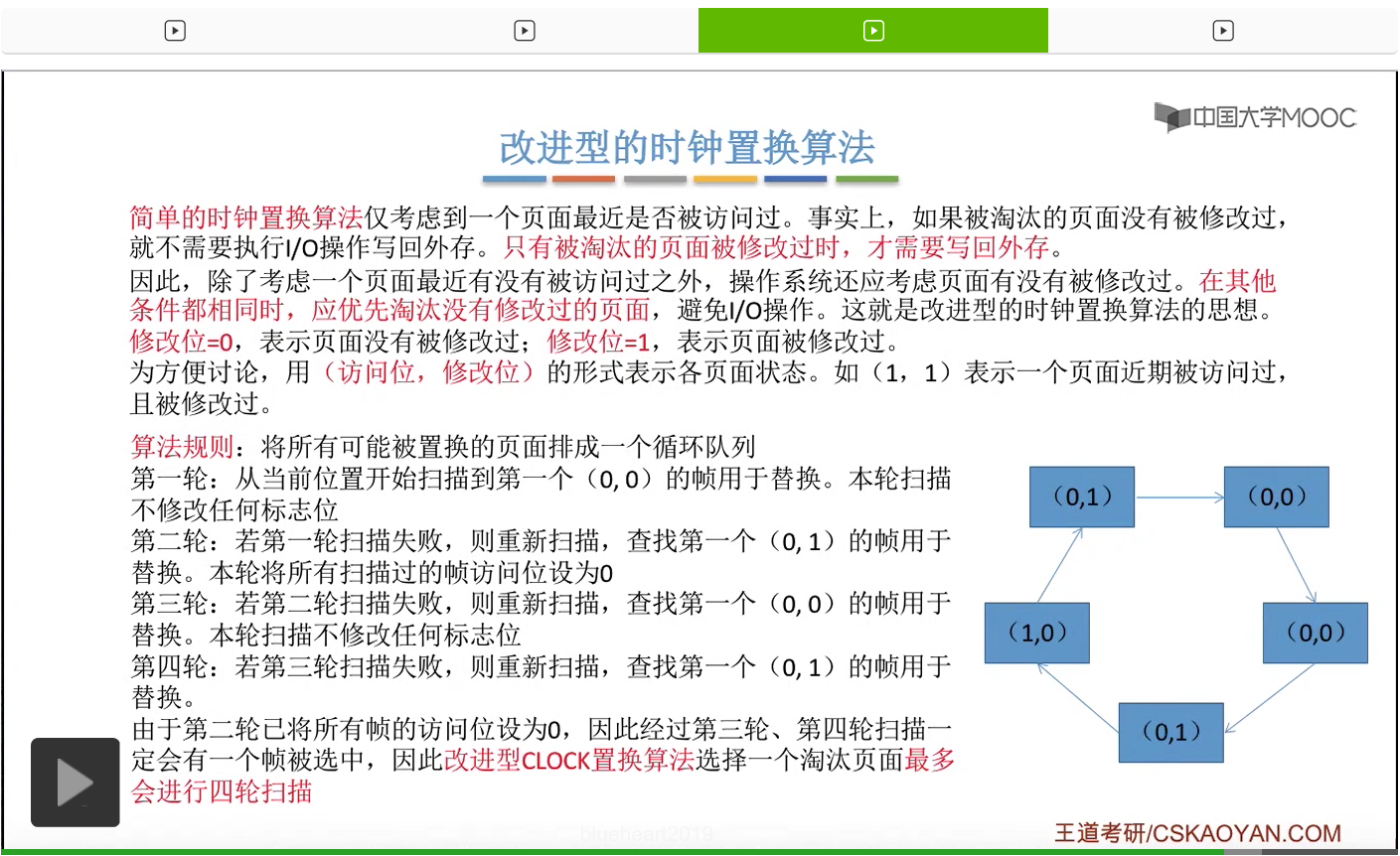
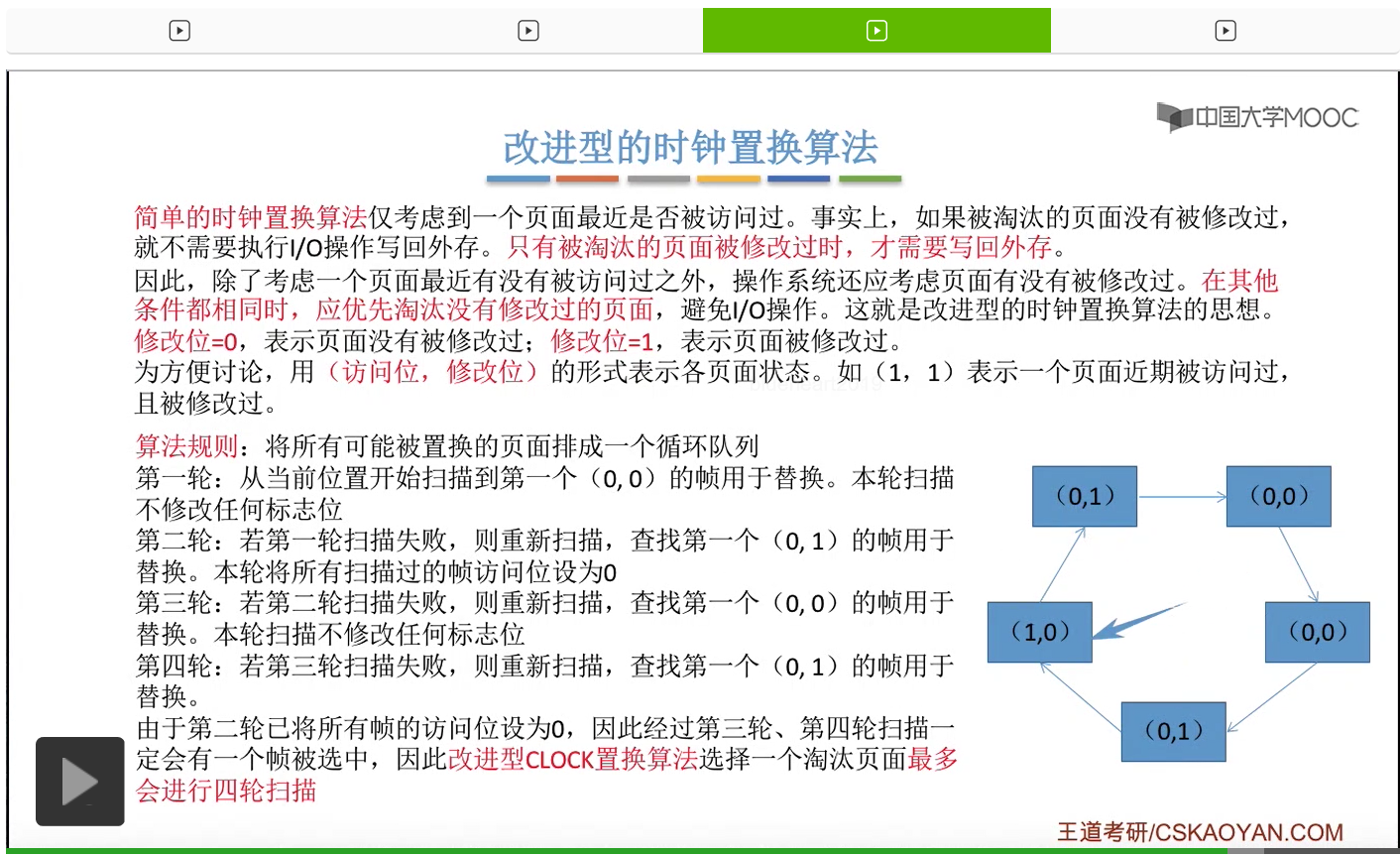
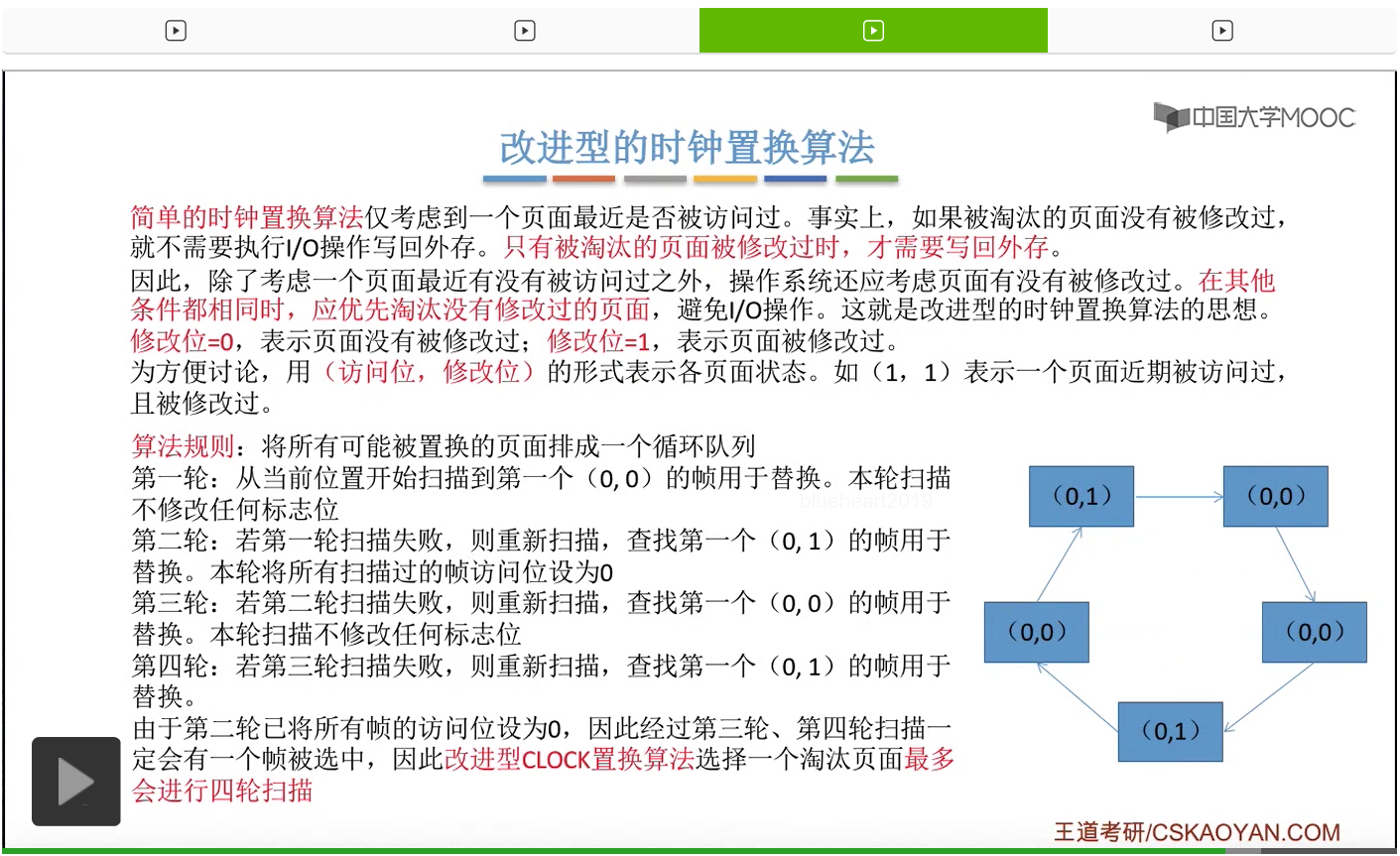
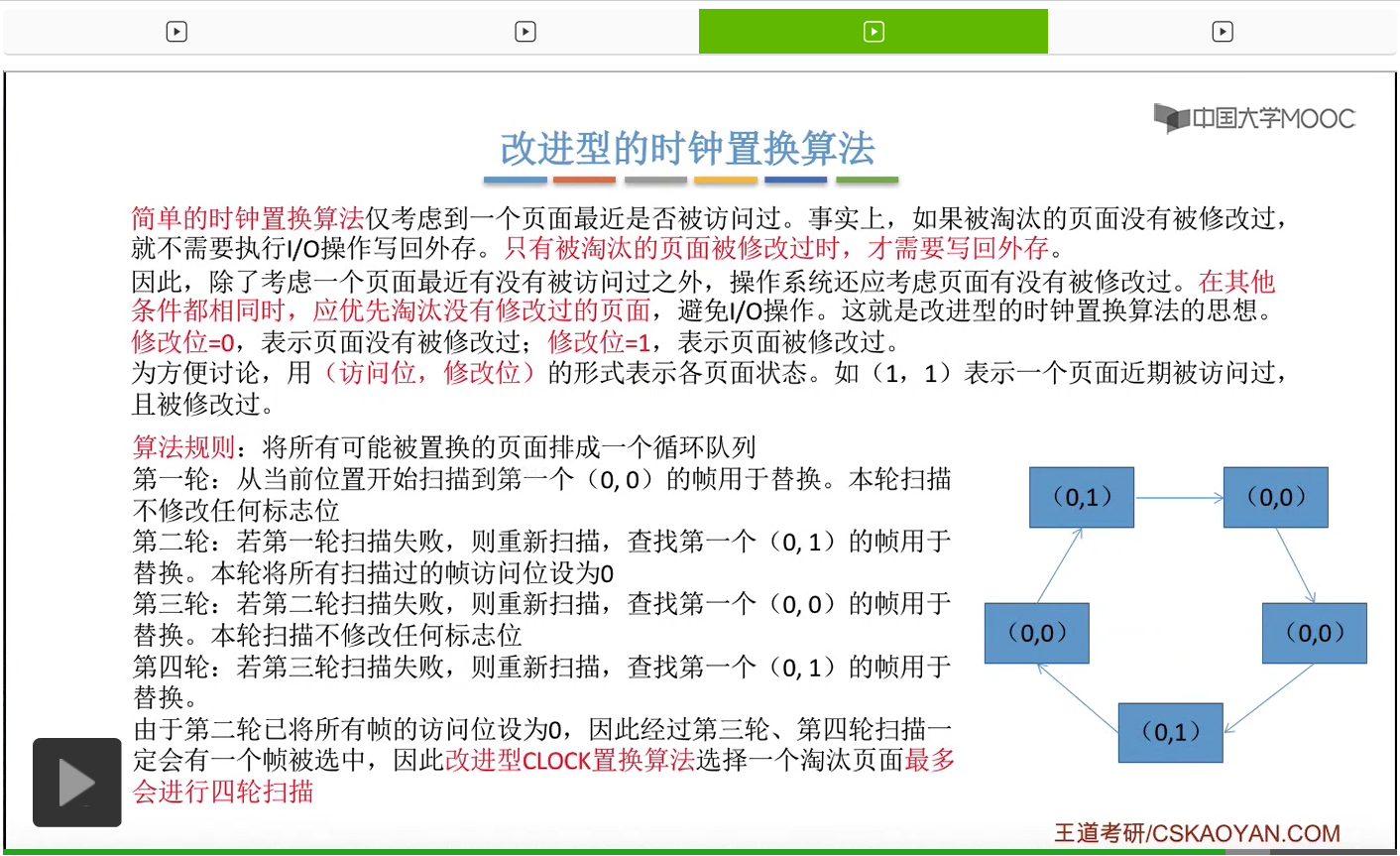
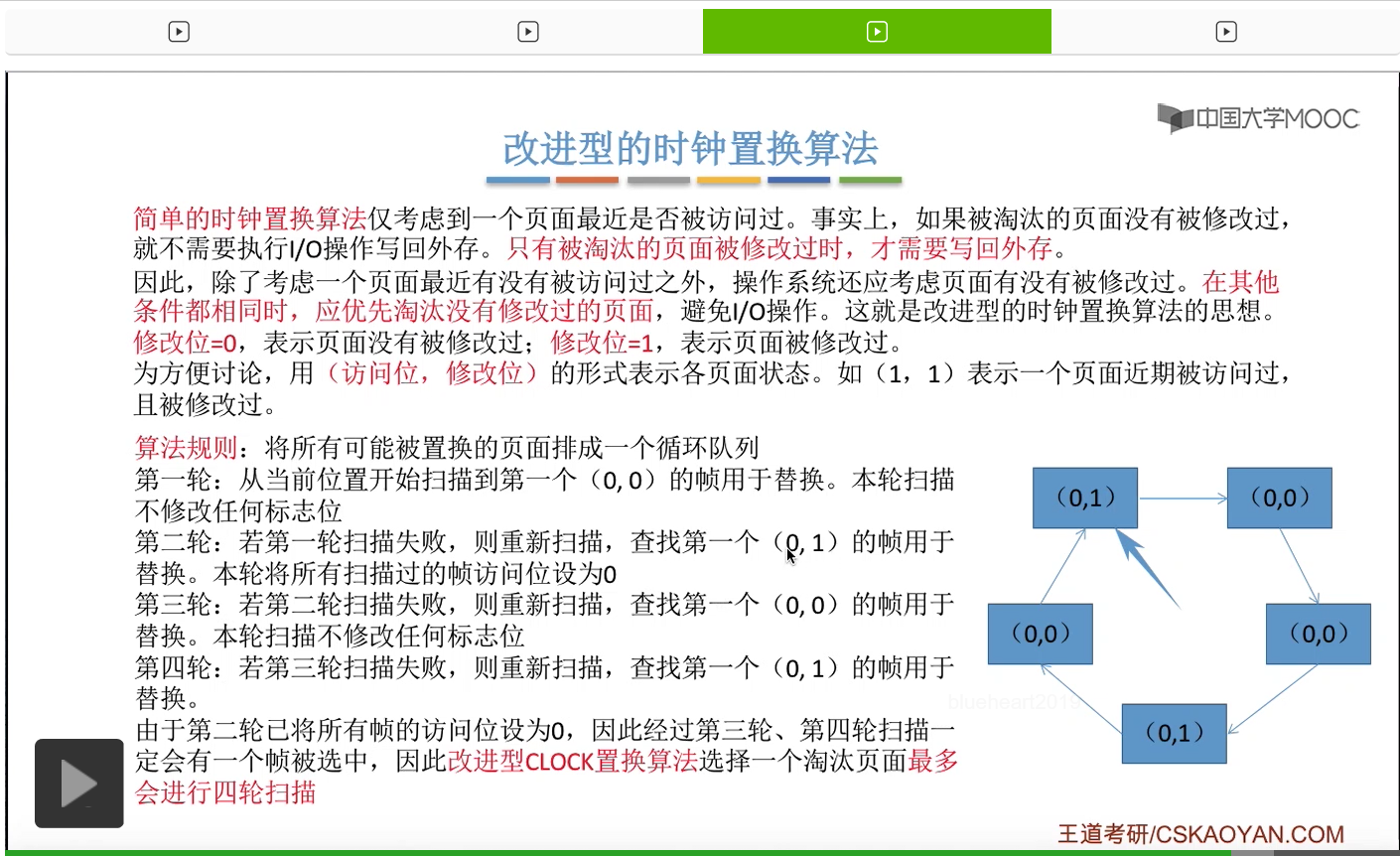
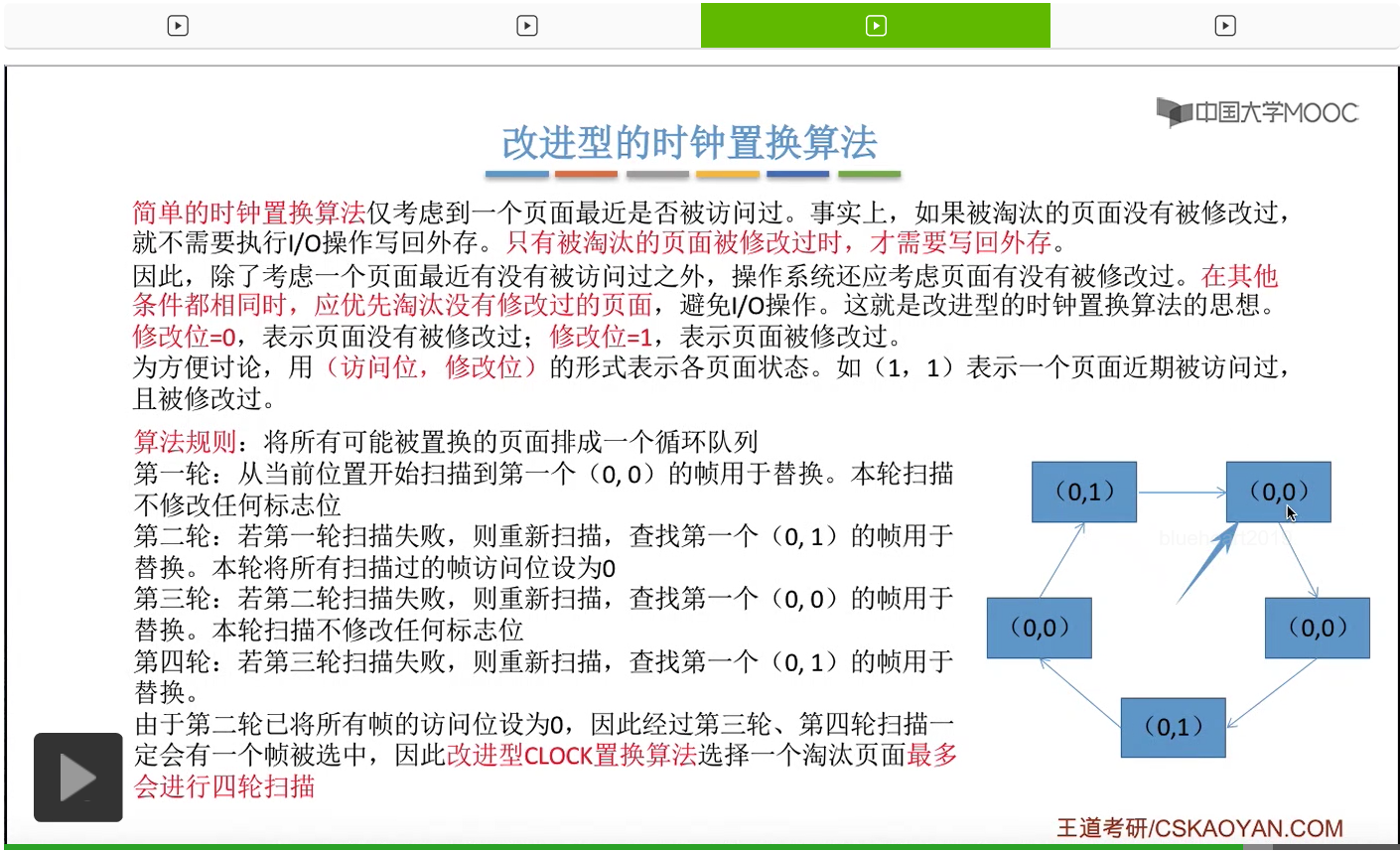
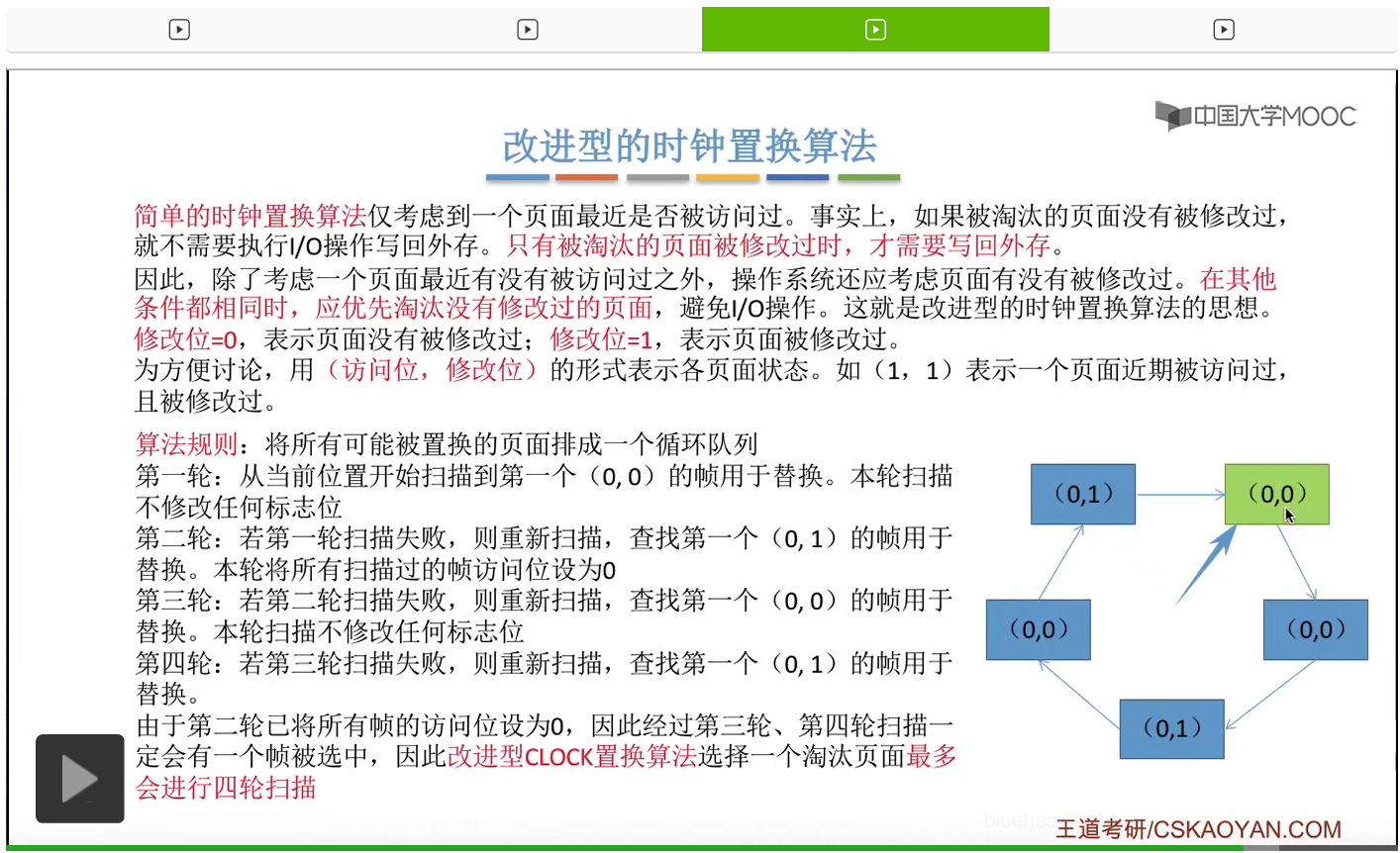
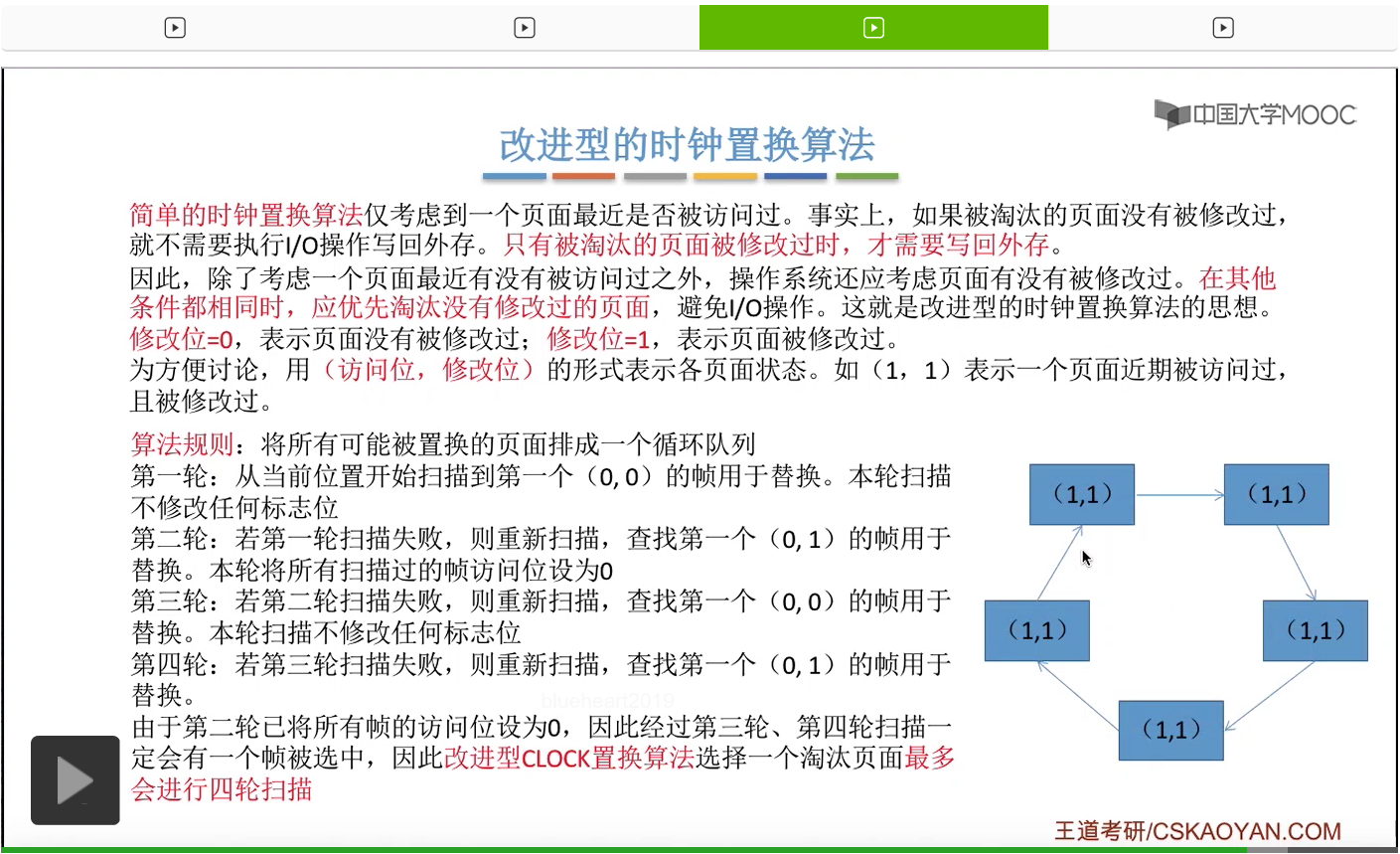
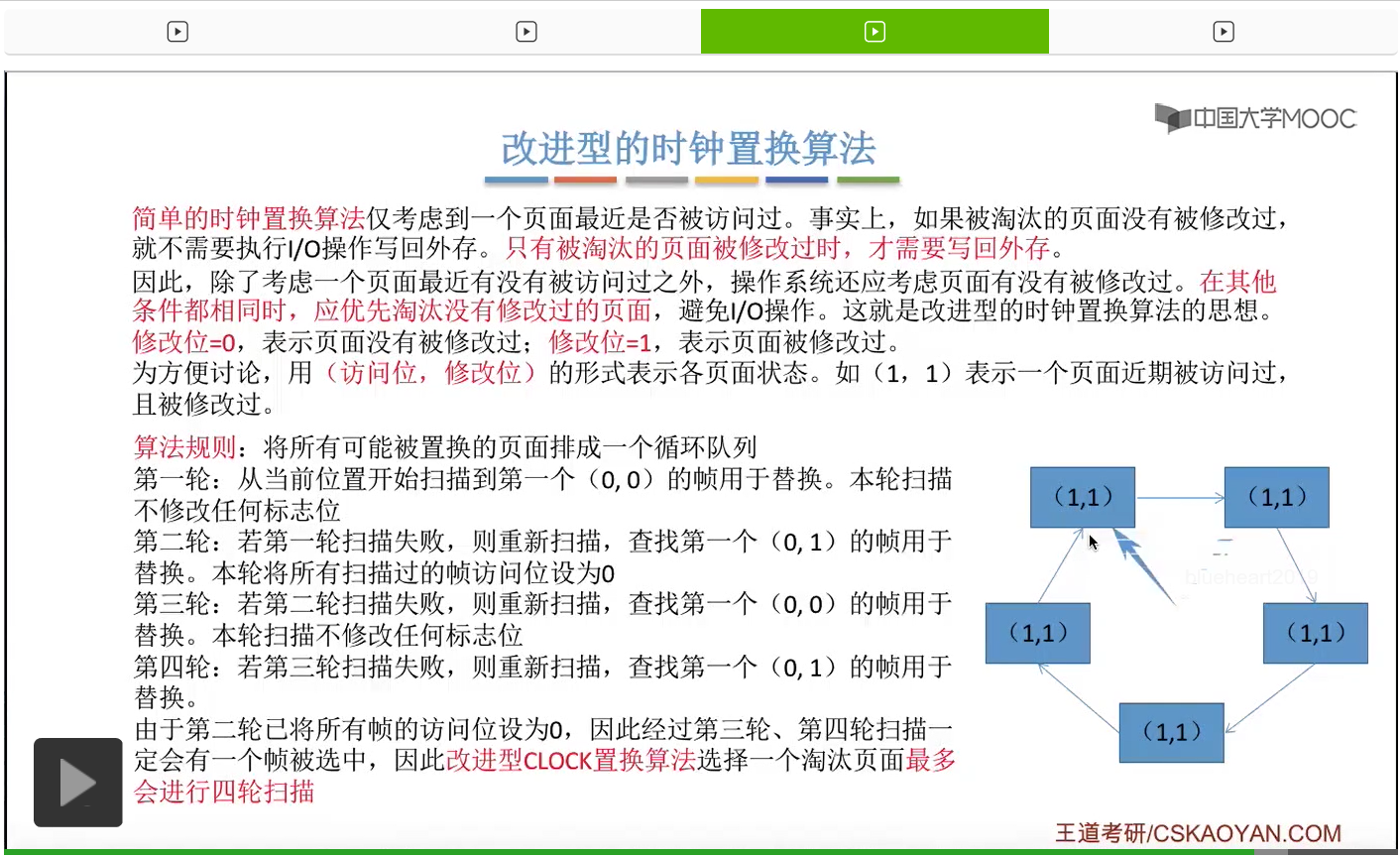
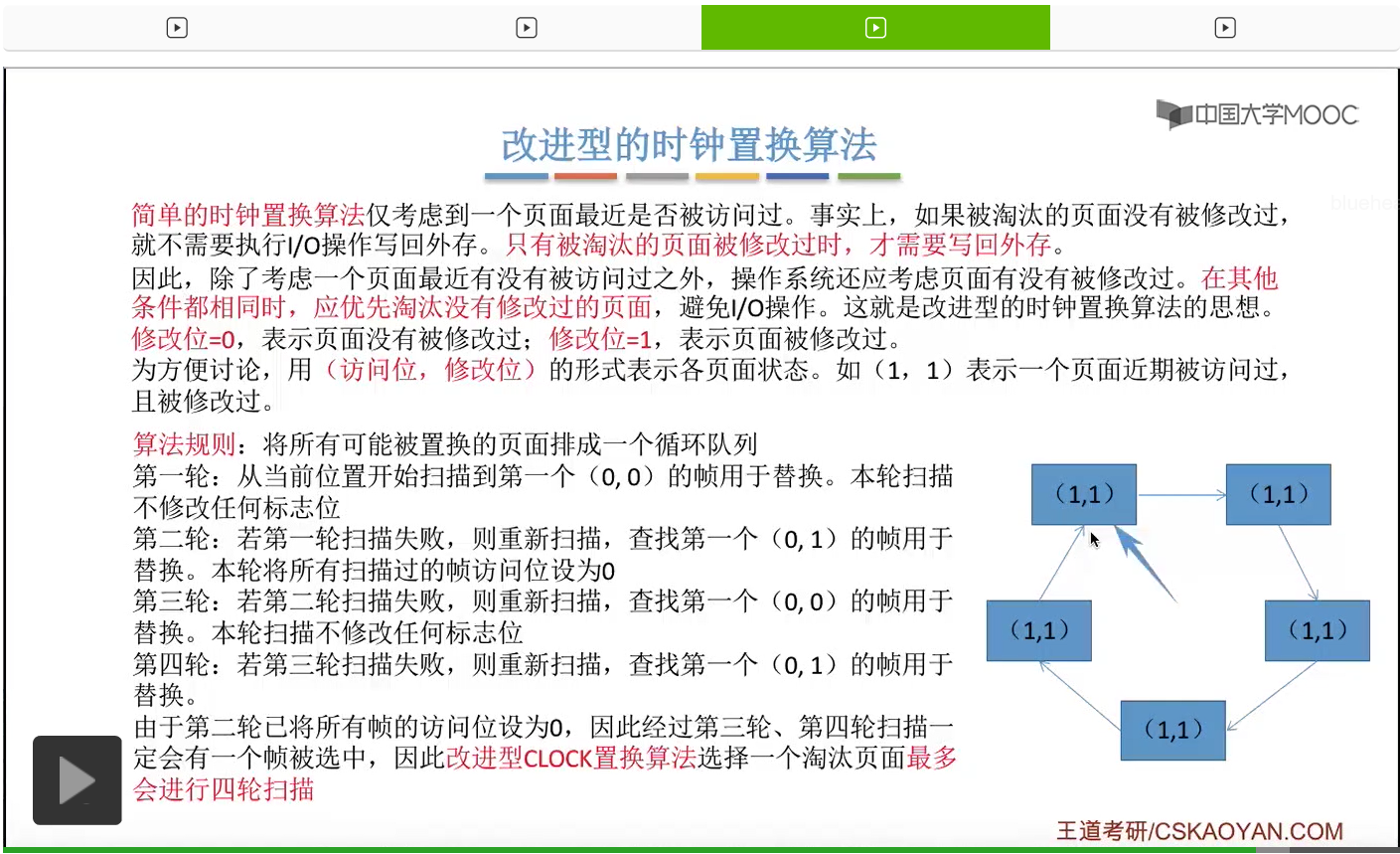
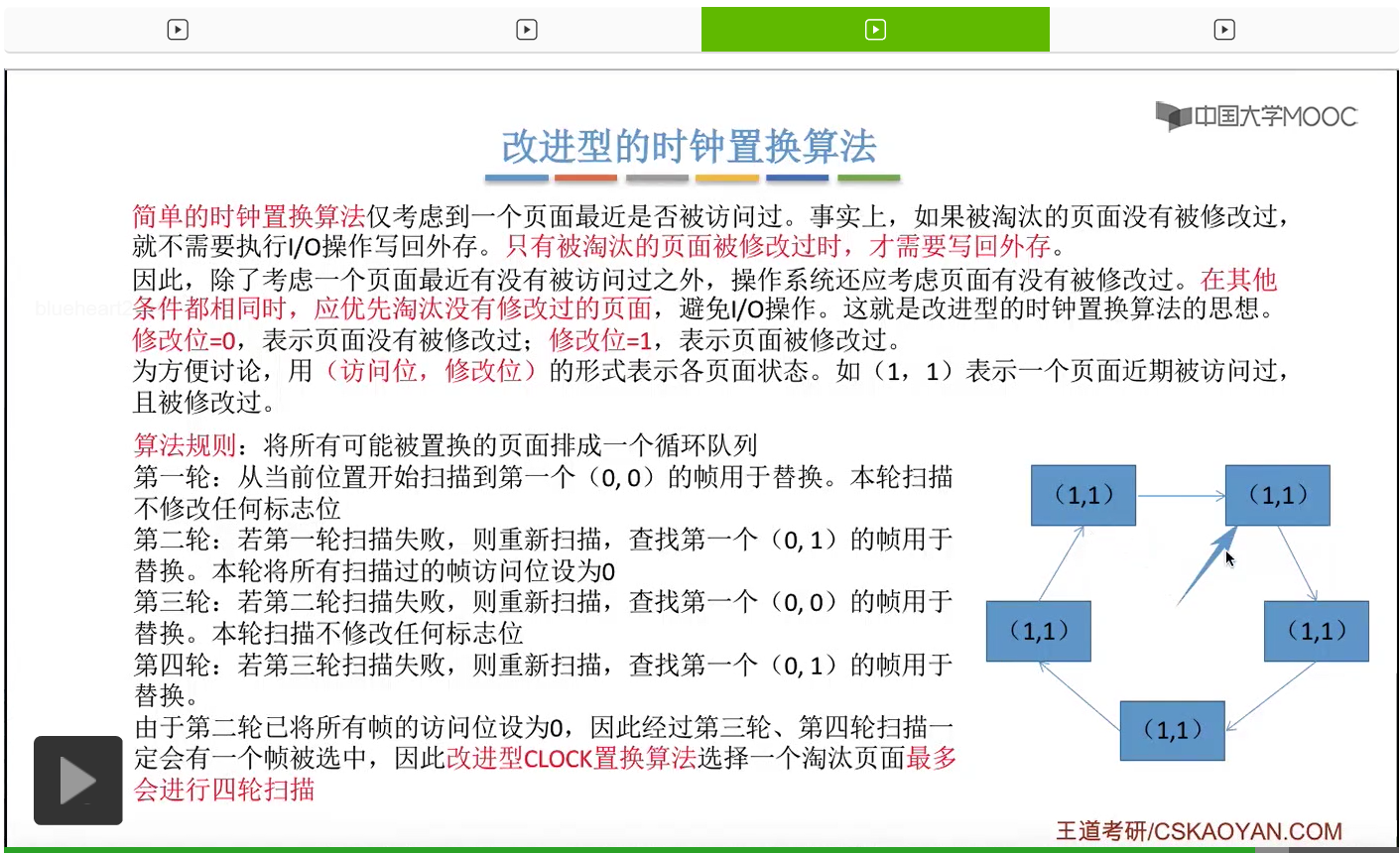
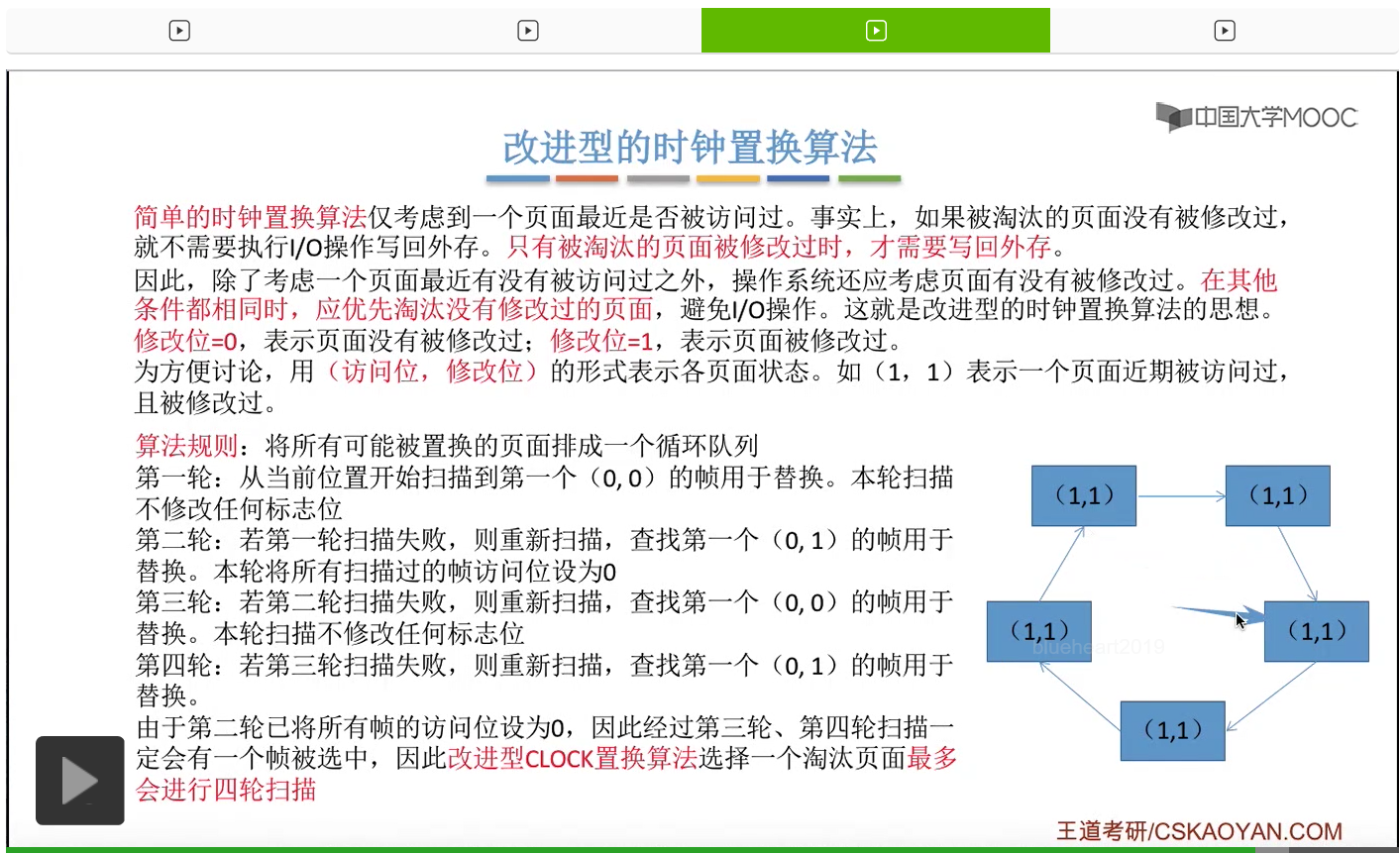
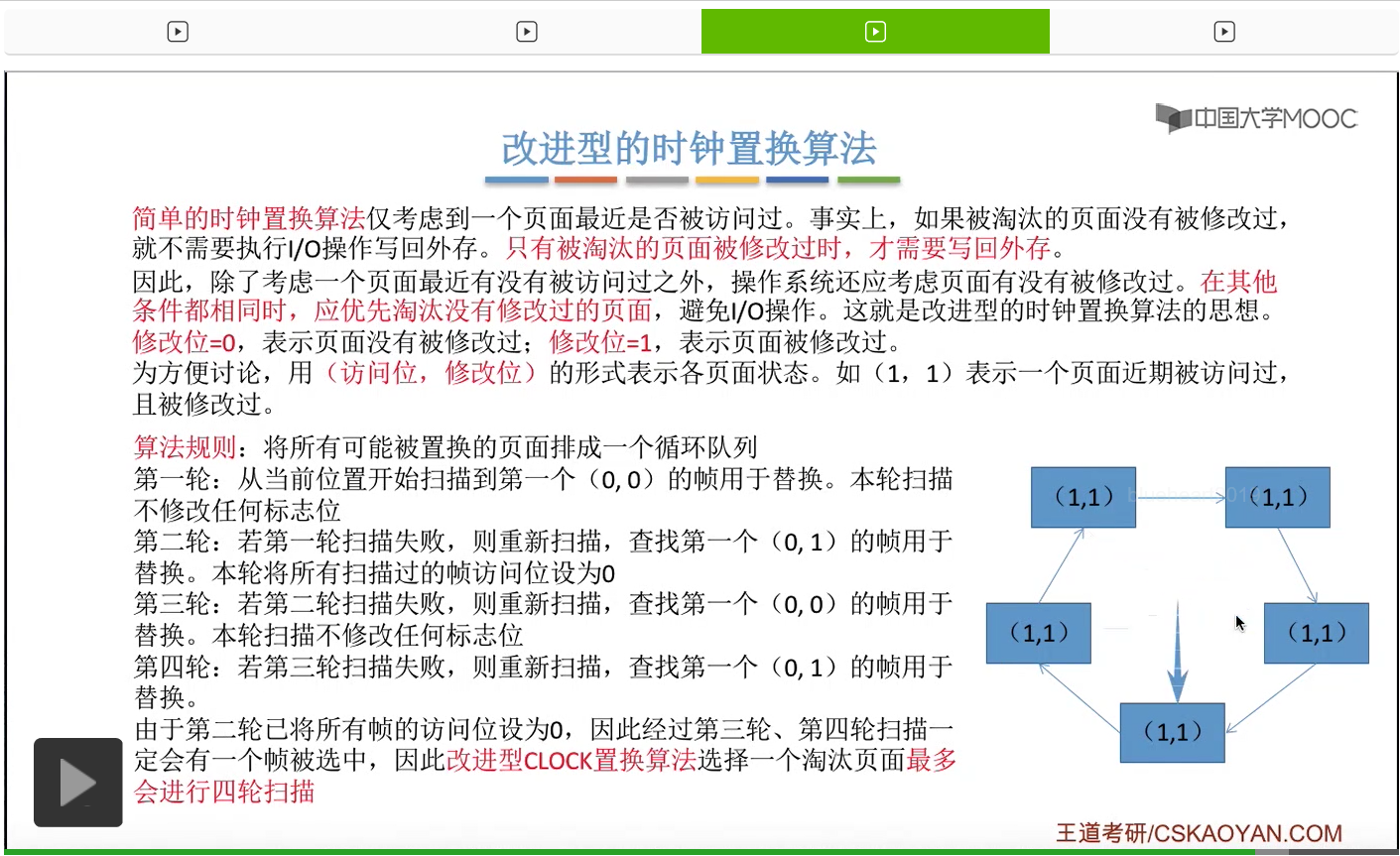



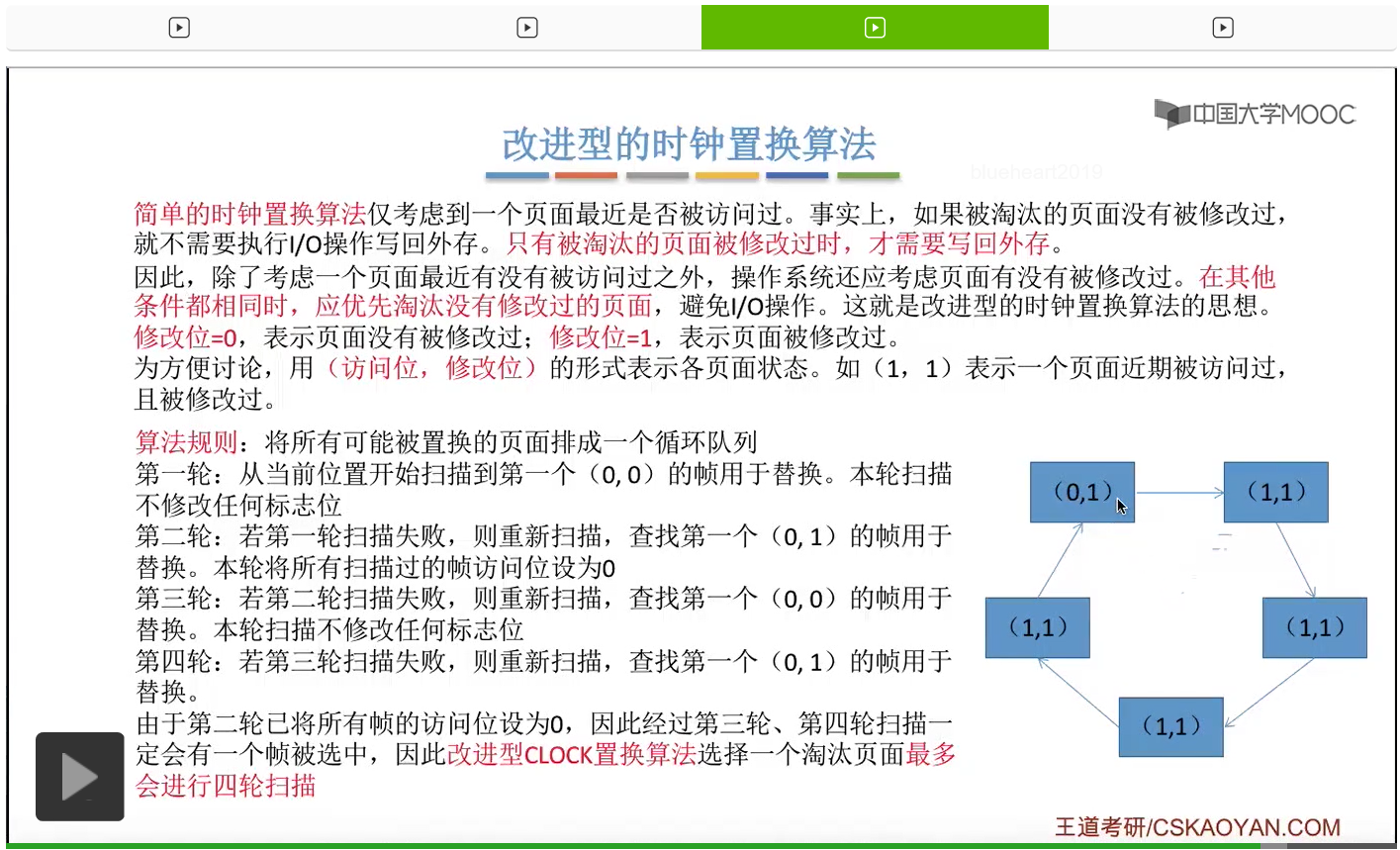


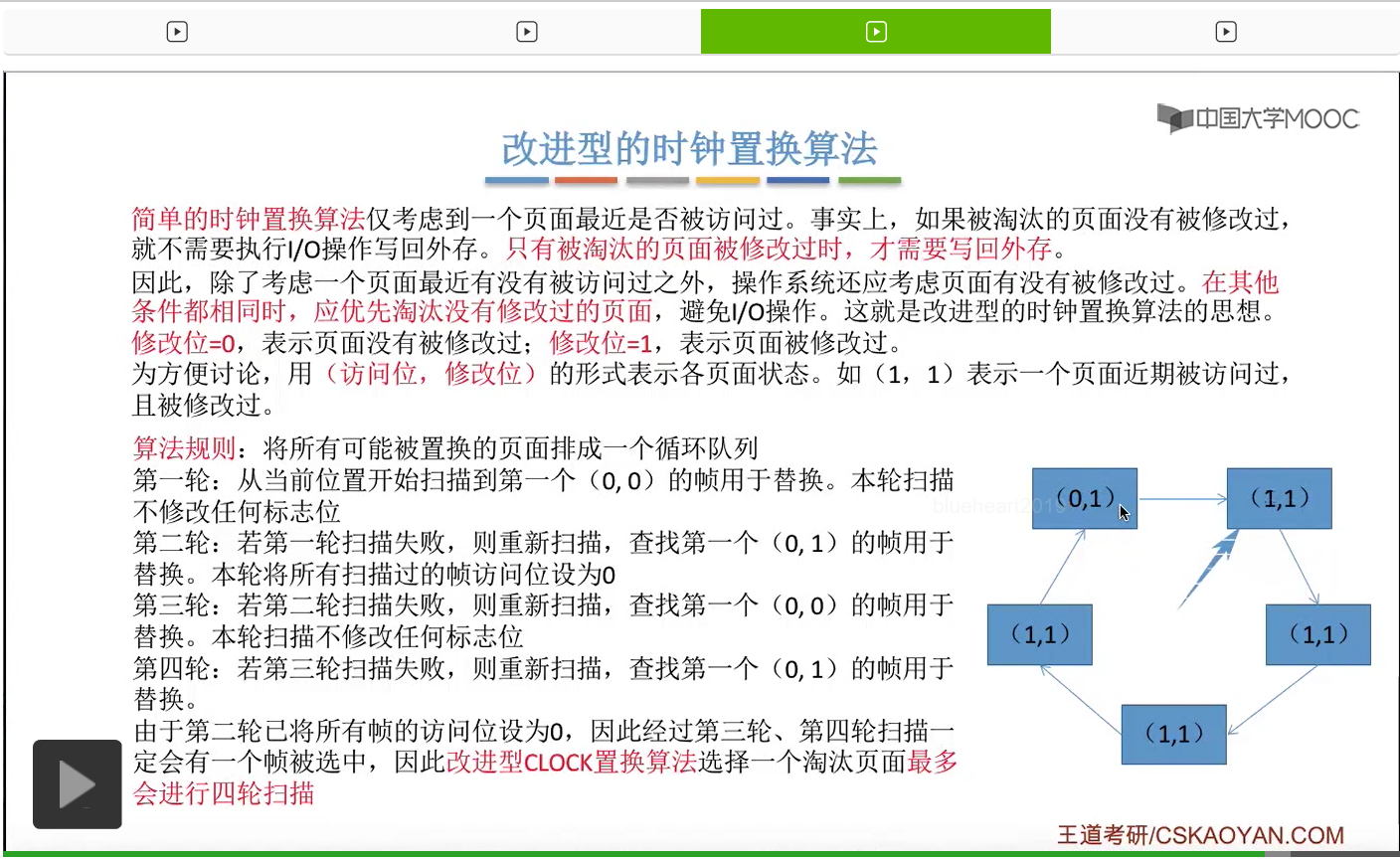

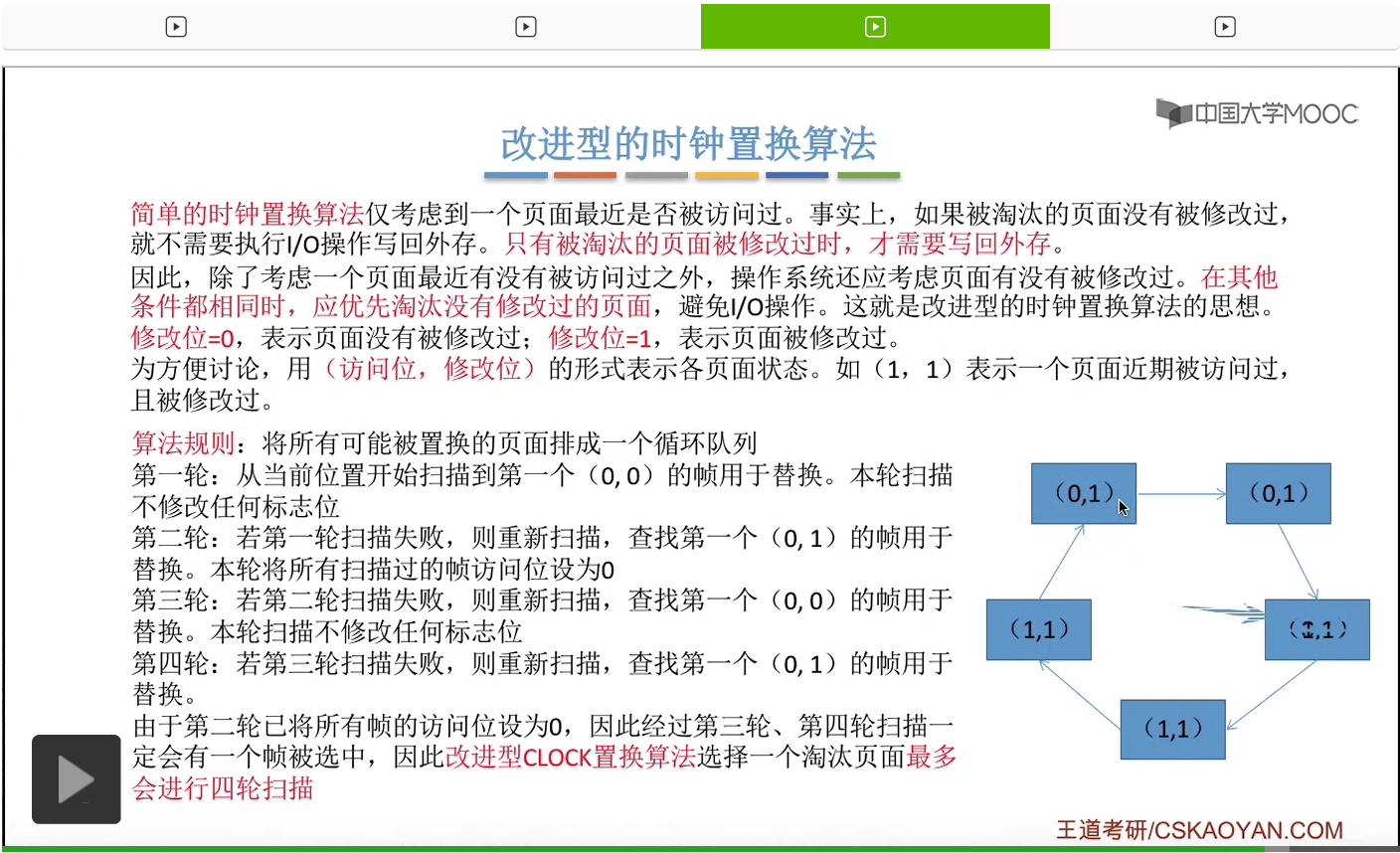
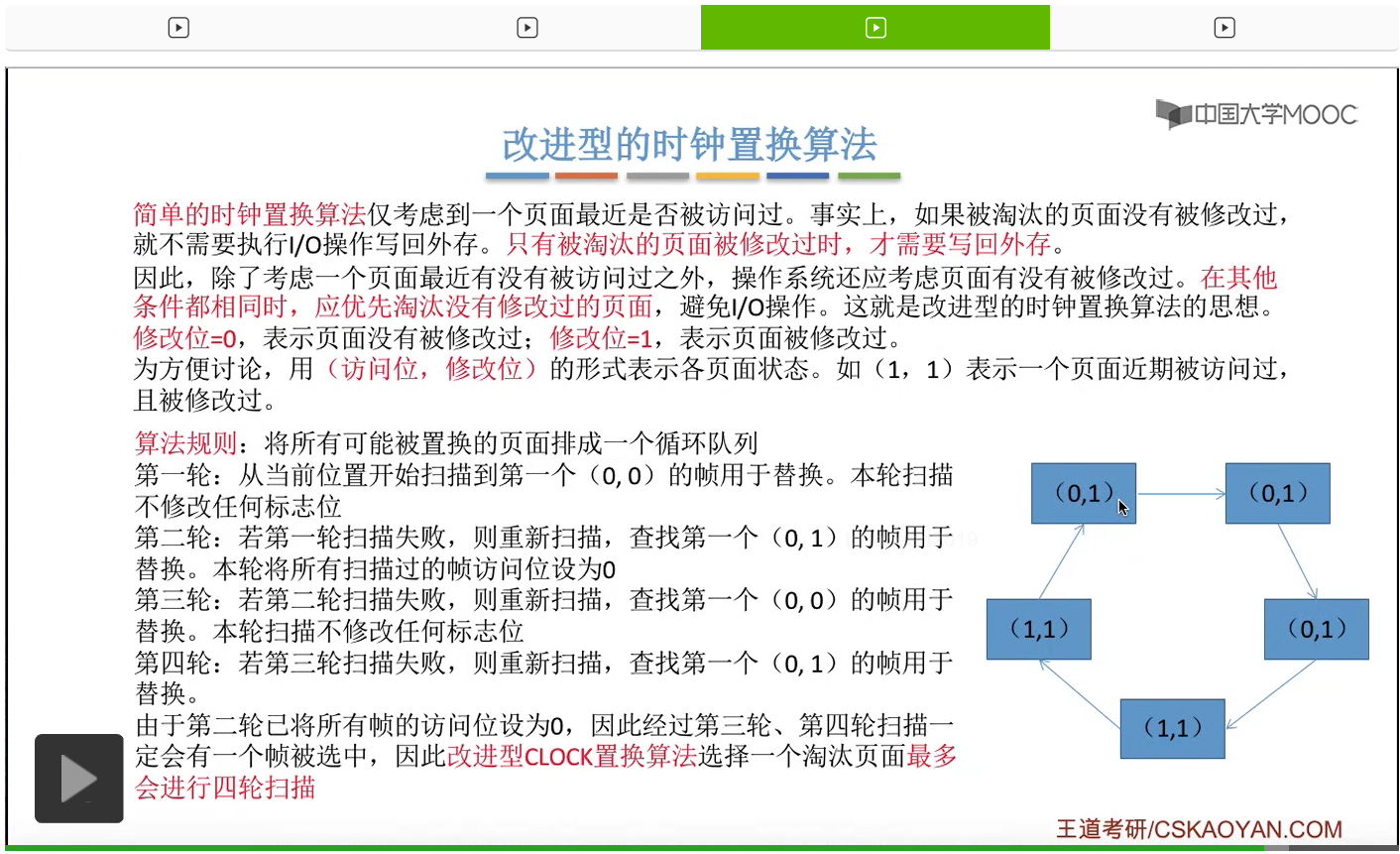

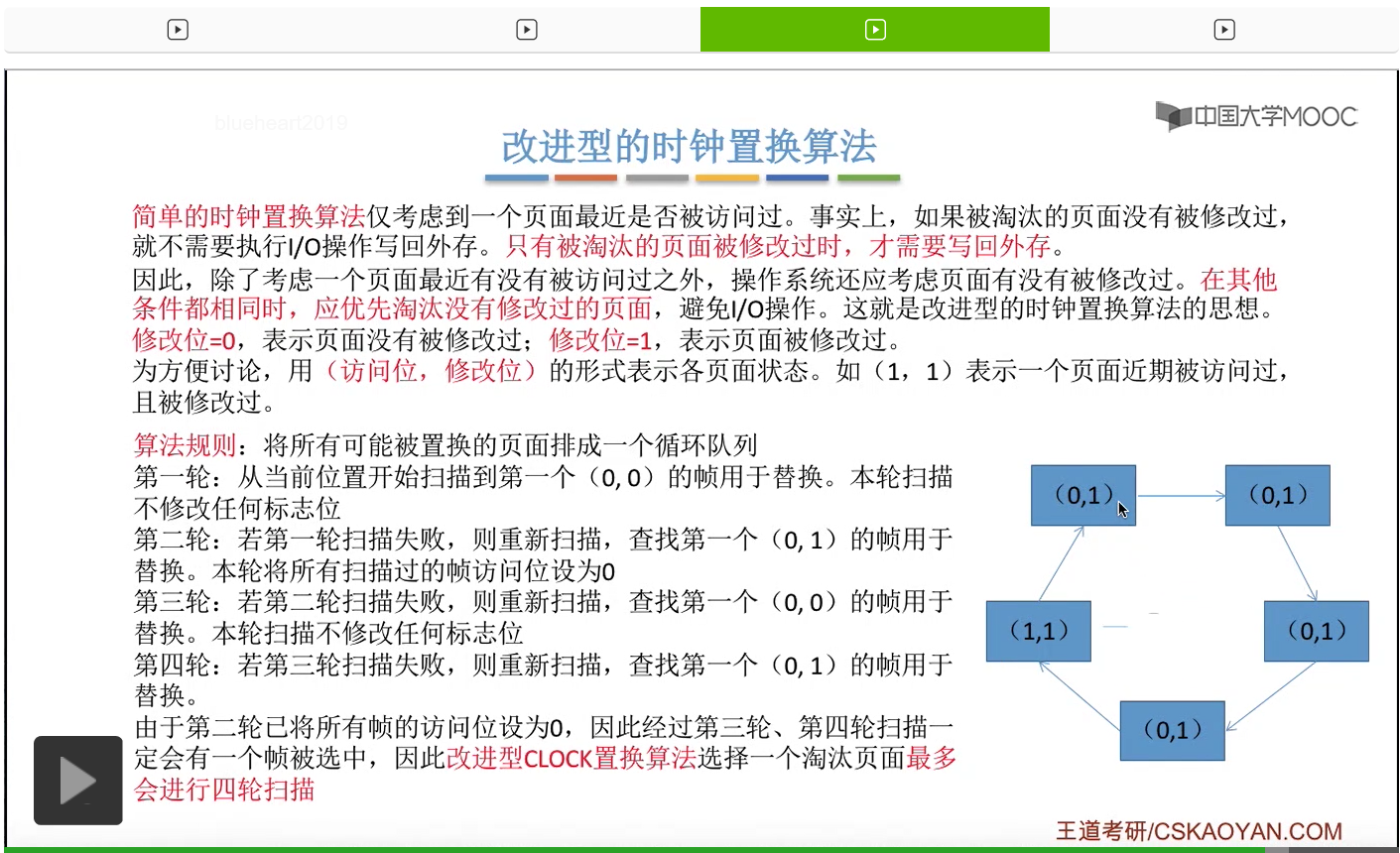
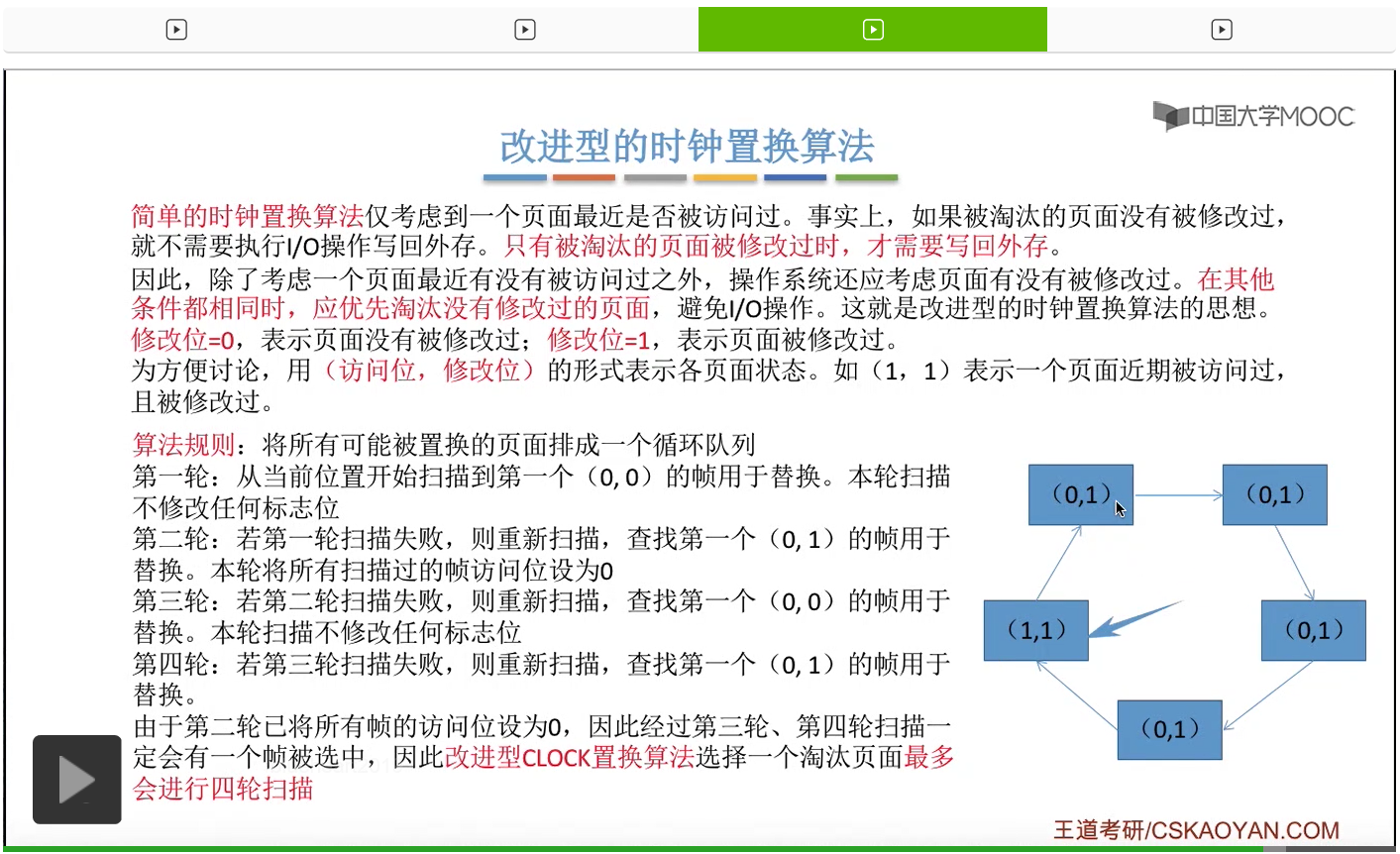
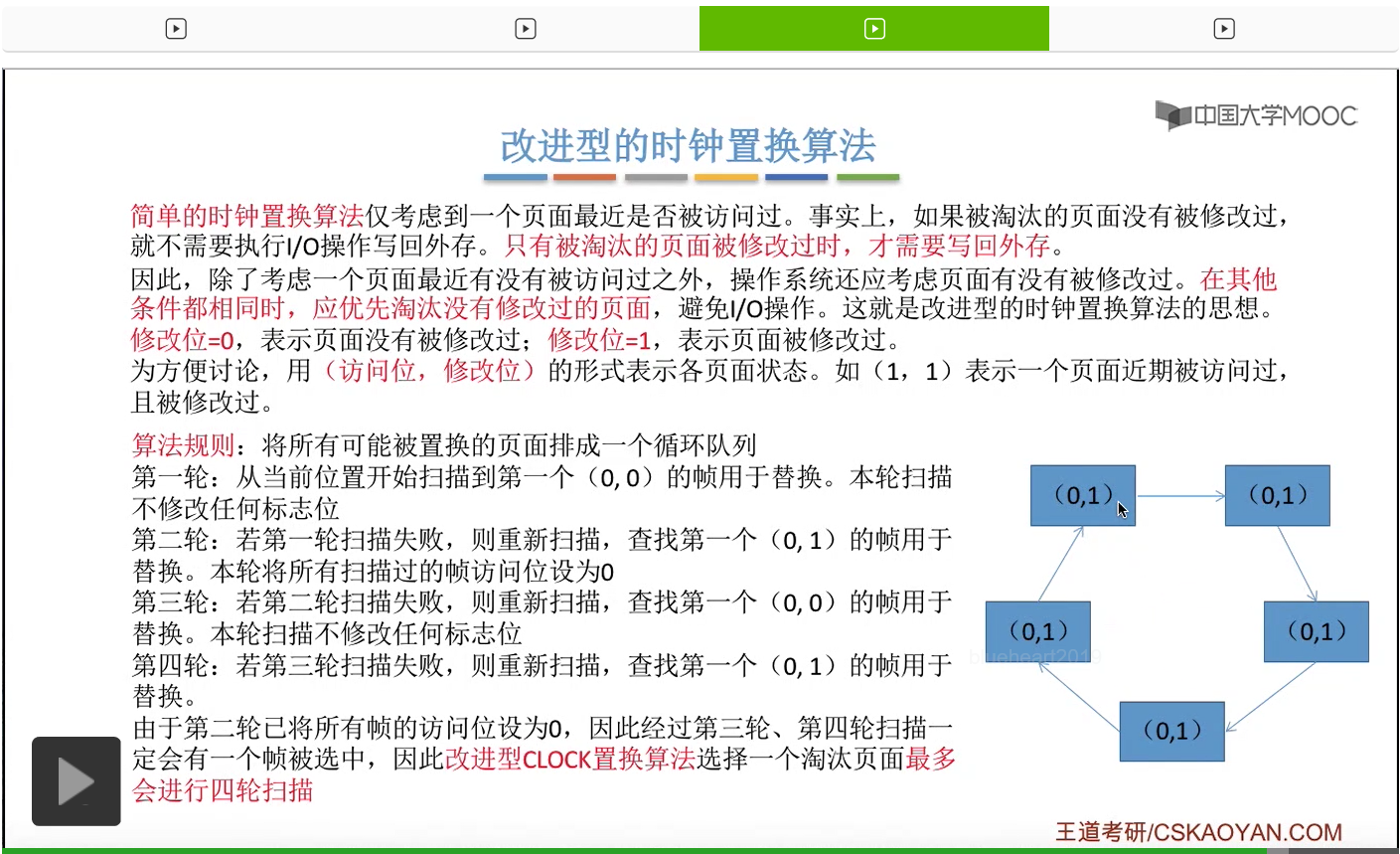


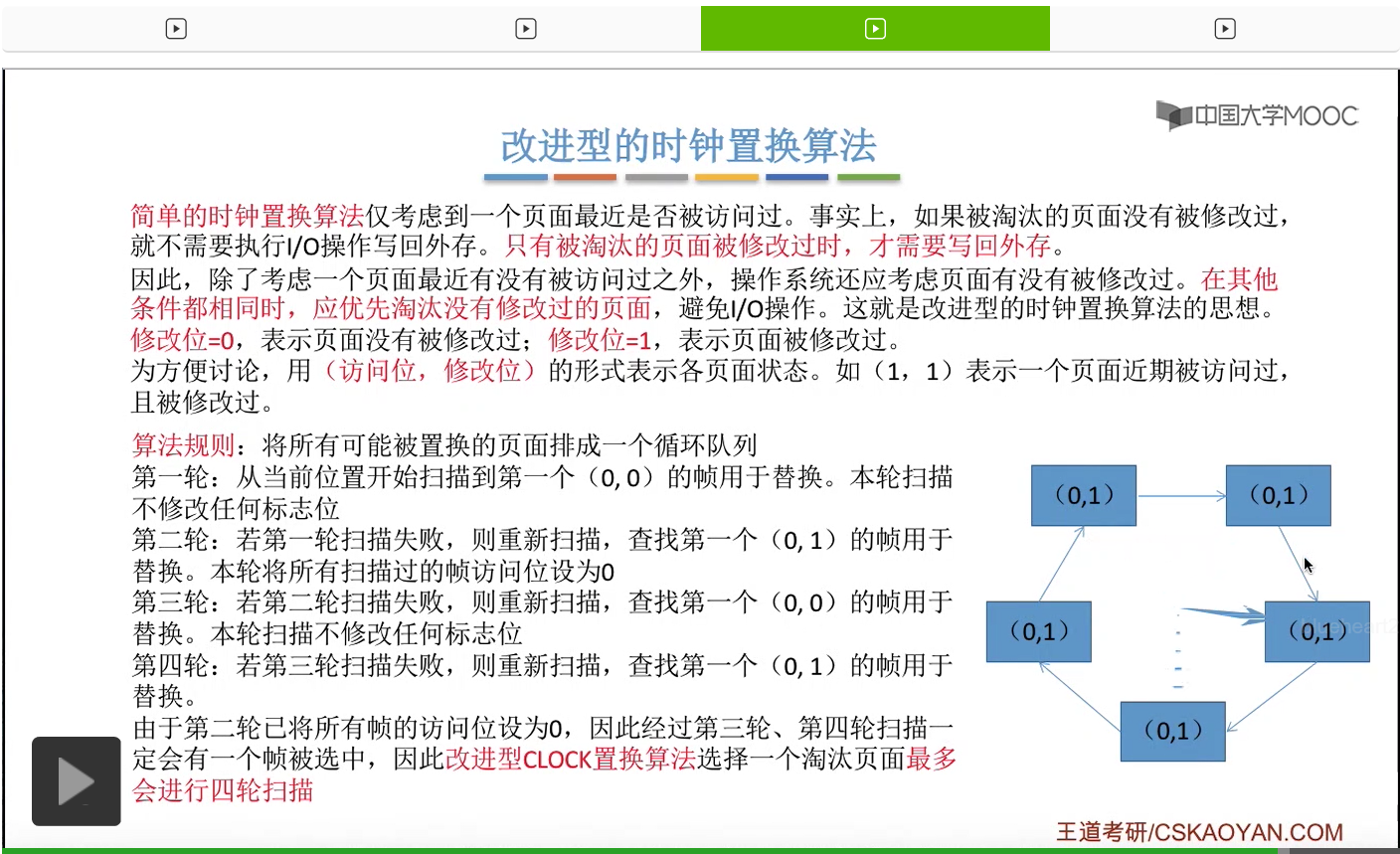
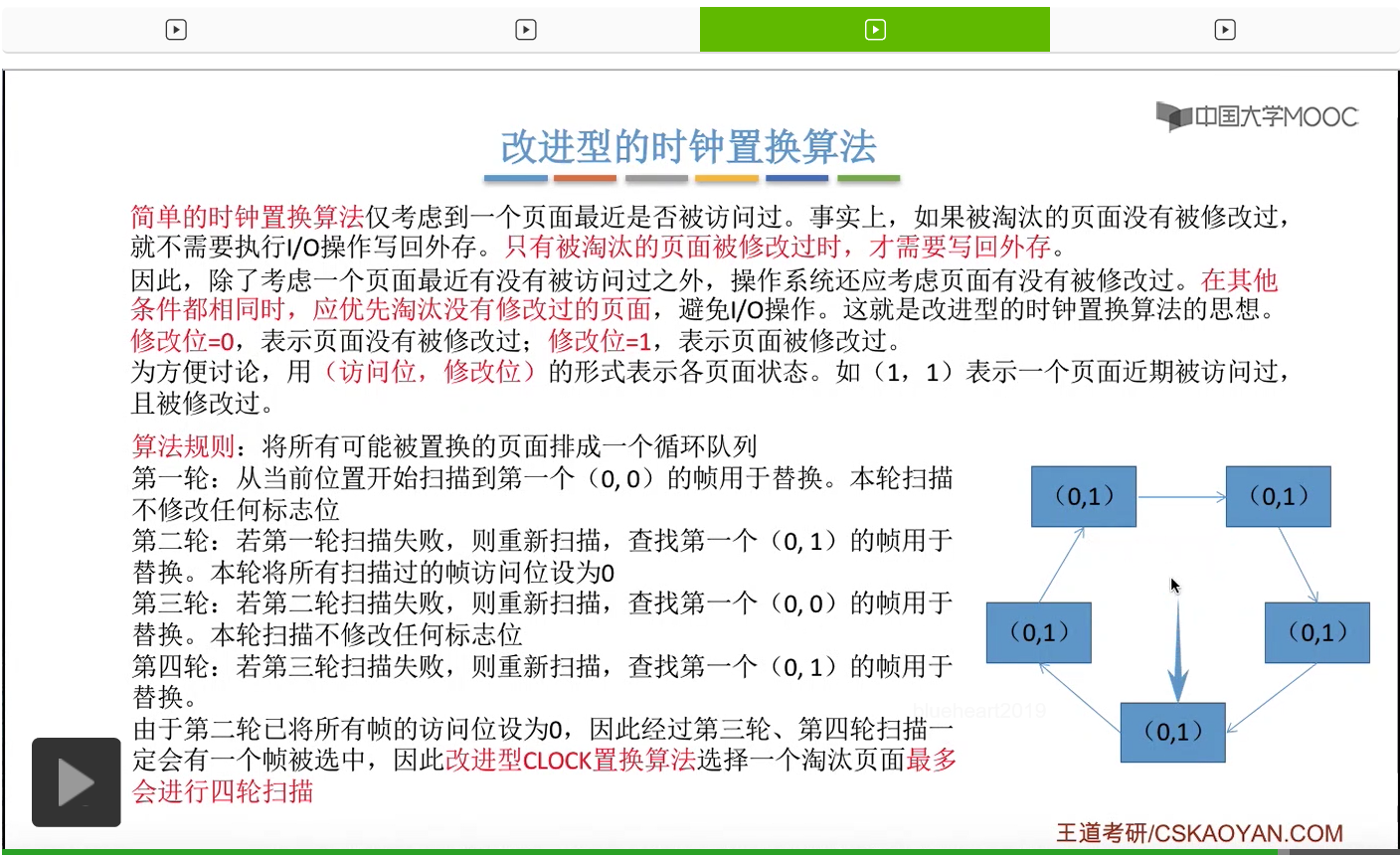

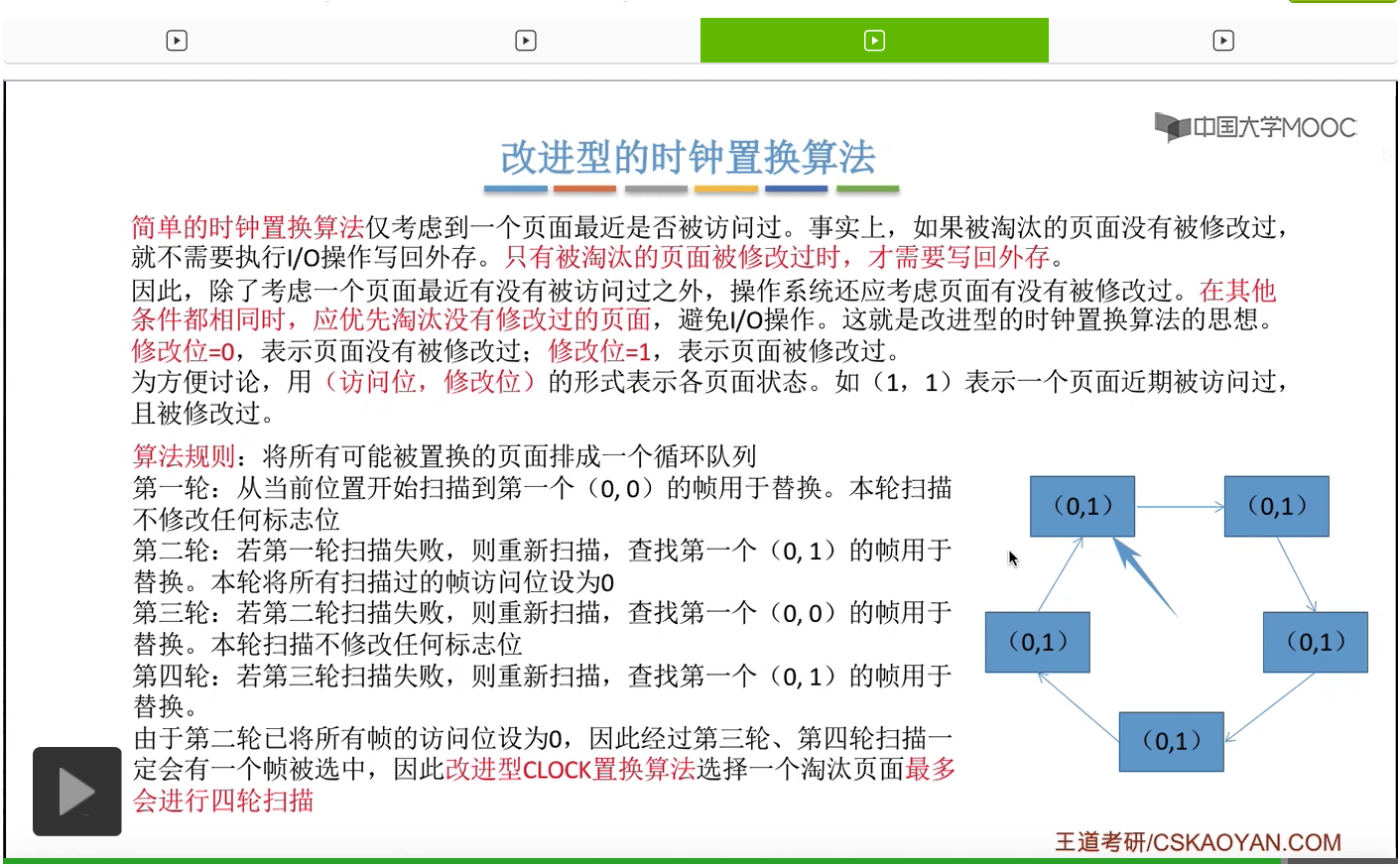

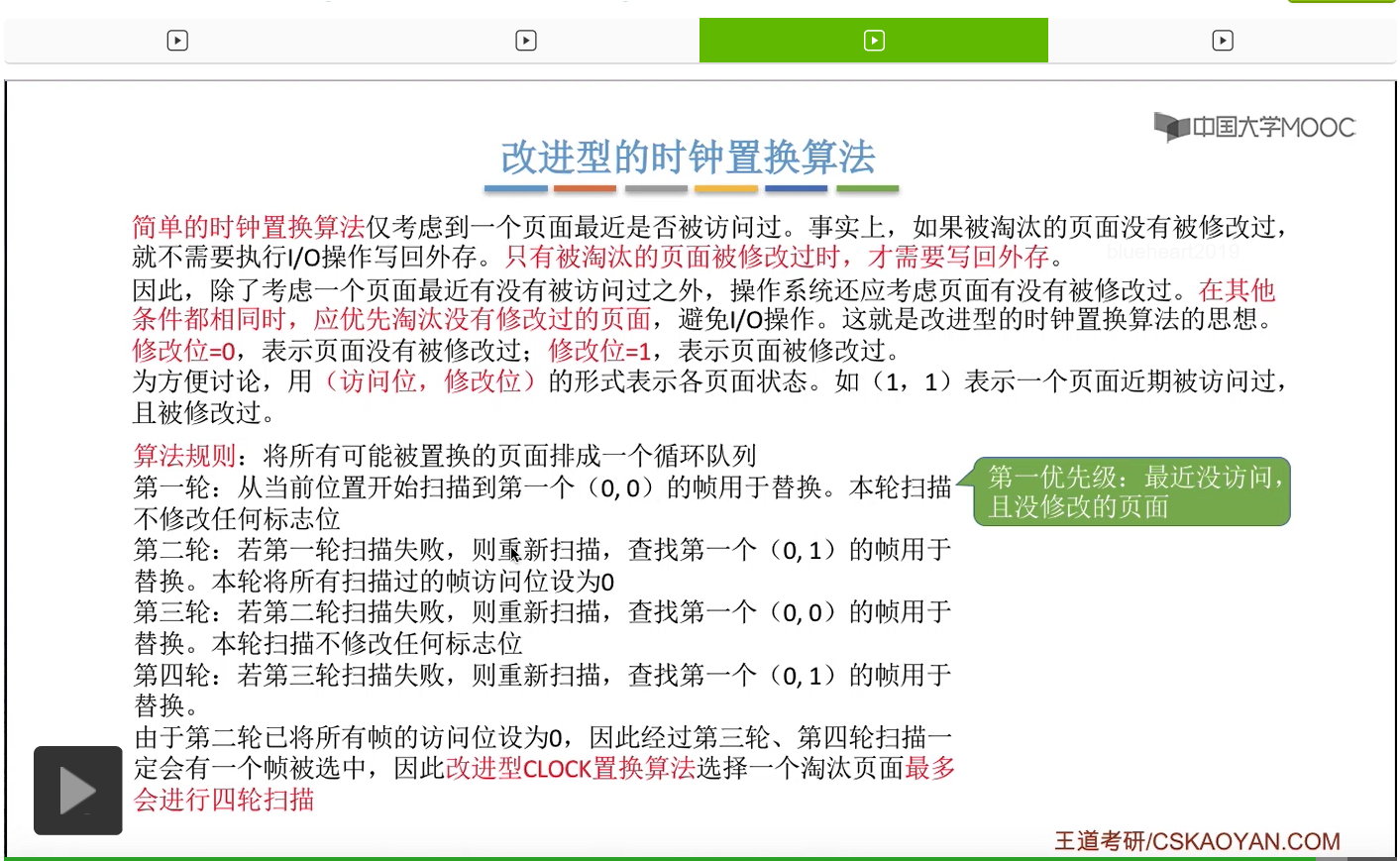
改进型的时钟置换算法在选择一个淘汰页面的时候最多会进行四轮扫描,而简单的时钟置换算法在淘汰一个页面的时候最多只会进行两轮扫描。

这个小节我们介绍了五种页面置换算法,分别是最佳置换OPT、先进先出FIFO、最近最久未使用LRU、简单型的时钟置换(最近未用)NRU、改进型的时钟置换(最近未用)NRU。那这个小节的内容重点需要理解各个算法的算法规则,如果题目中给出一个页面的访问序列,那需要自己能够用手动的方式来模拟各个算法运行的一个过程。那除了算法规则之外,各个算法的优缺点有可能在选择题当中进行考查。那需要重点注意的是,最佳置换算法在现实当中是无法实现的,然后先进先出算法它的性能差,并且是唯一一个有可能出现Belady异常的算法。

在这个小节中我们会学习页面分配策略相关的一系列知识点。
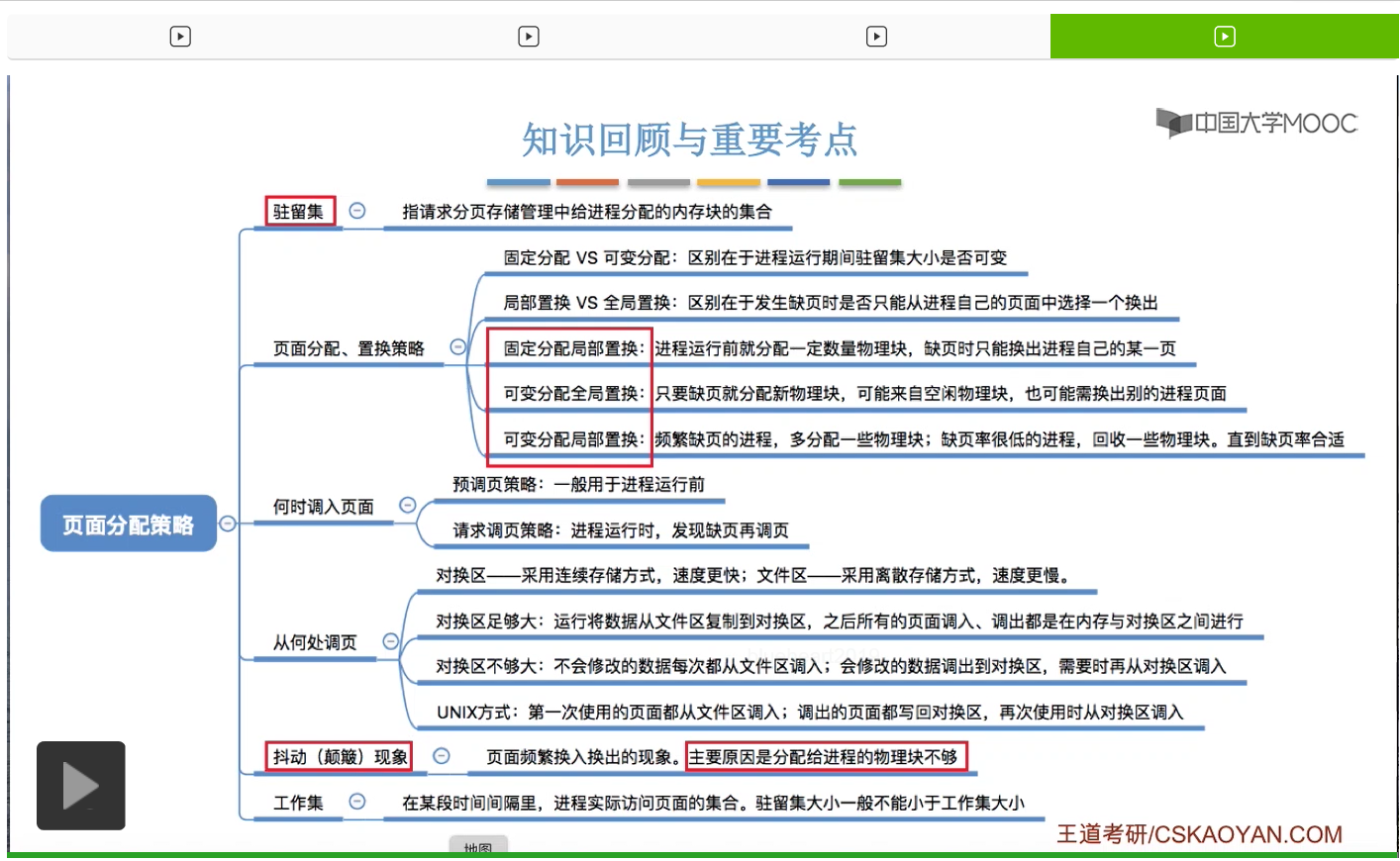
什么是驻留集。考试中需要掌握的三种页面分配、置换的策略。另外,页面应该在什么时候被调入,应该从什么地方调入,应该调出到什么位置,这些也是我们之后会探讨的问题。什么是进程抖动(进程颠簸)这种现象,那为了解决进程抖动(进程颠簸)现象,又引入了工作集这个概念,那我们会按照从上至下的顺序依次讲解。

驻留集是指请求分页存储管理当中给进程分配的物理块(内存块、页框、页帧)的集合。那在采用了虚拟存储技术的系统当中,为了从逻辑上提升内存,并且提高内存的利用率,那驻留集的大小一般是要小于进程的总大小的。
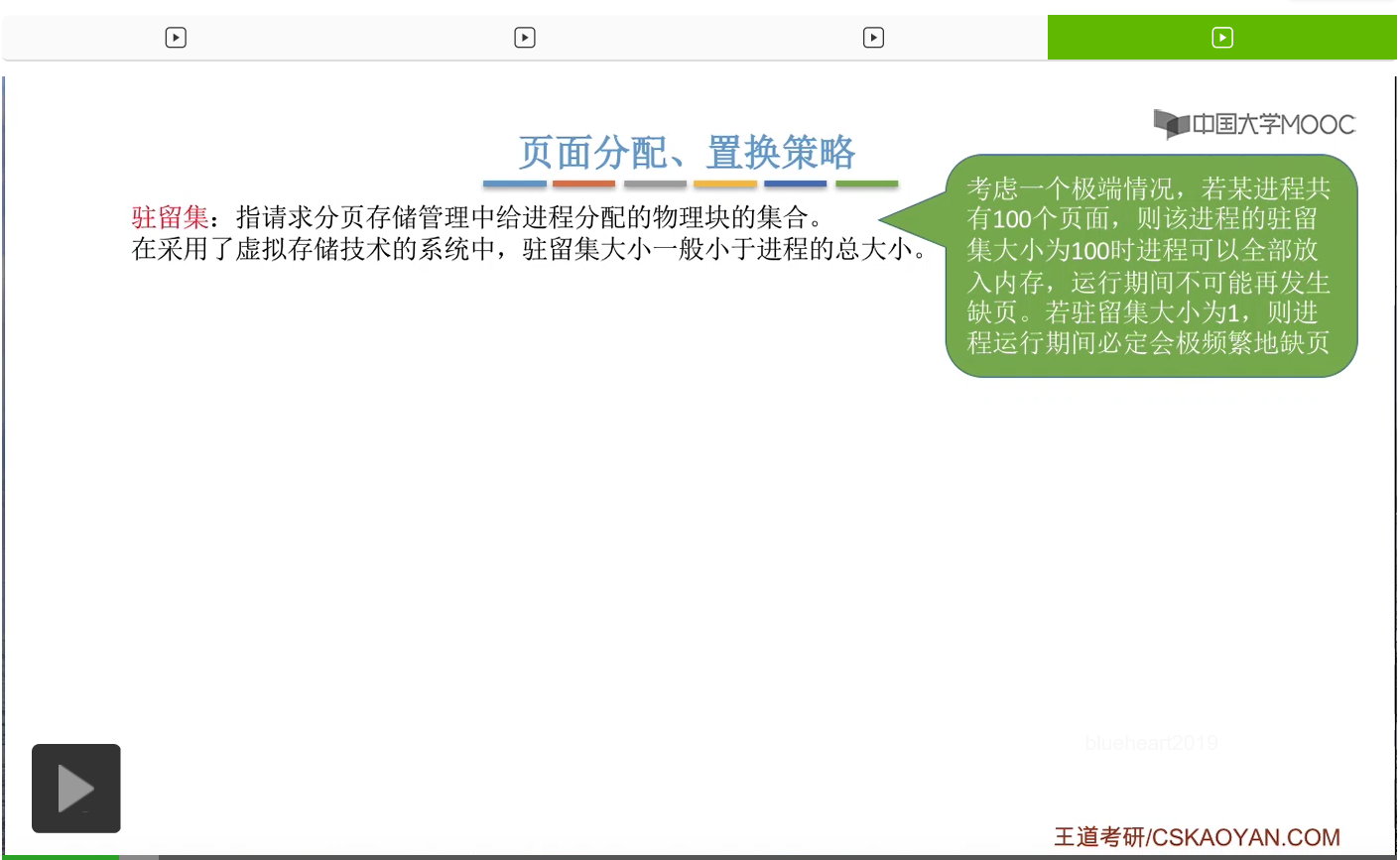
驻留集太小导致进程缺页频繁,系统就需要花大量的时间处理缺页,而实际用于进程推进、进程运行的时间又很少。驻留集太大,导致多道程序并发度下降,使系统的某些资源利用率不高。像系统的CPU和I/O设备这两种资源,理论上是可以并行地工作的。那如果多道程序并发度下降,就意味着CPU和I/O设备这两种资源并行工作的几率就会小很多,所以资源的利用率当然就会降低。所以系统应该为进程选择一个合适的驻留集大小。
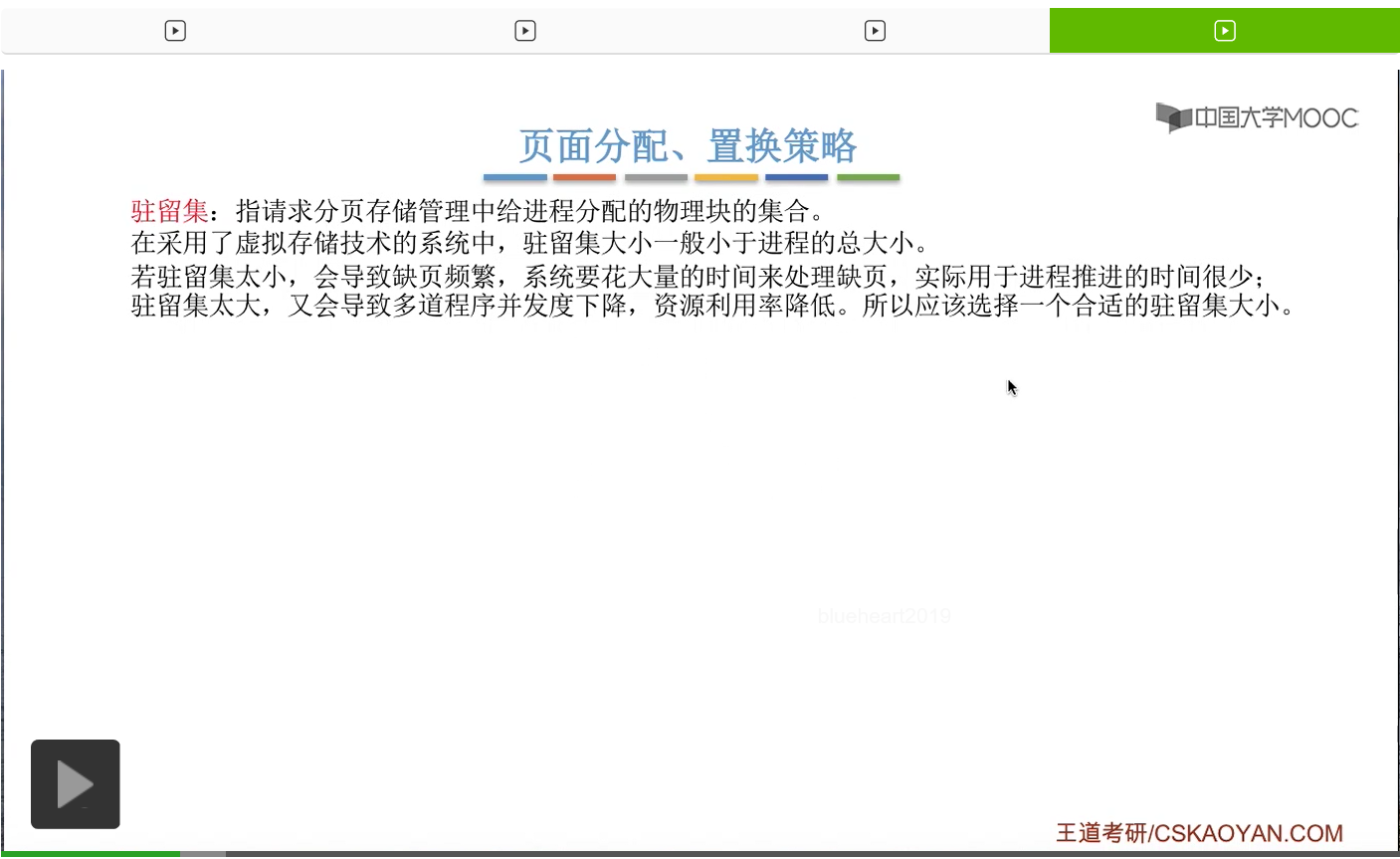
那针对于驻留集的大小是否可变这个问题,人们提出了固定分配和可变分配这两种分配策略。固定分配指驻留集的大小是刚开始就决定了,之后就不再改变了。可变分配其实指的就是驻留集的大小是可以动态地改变,可以调整的。
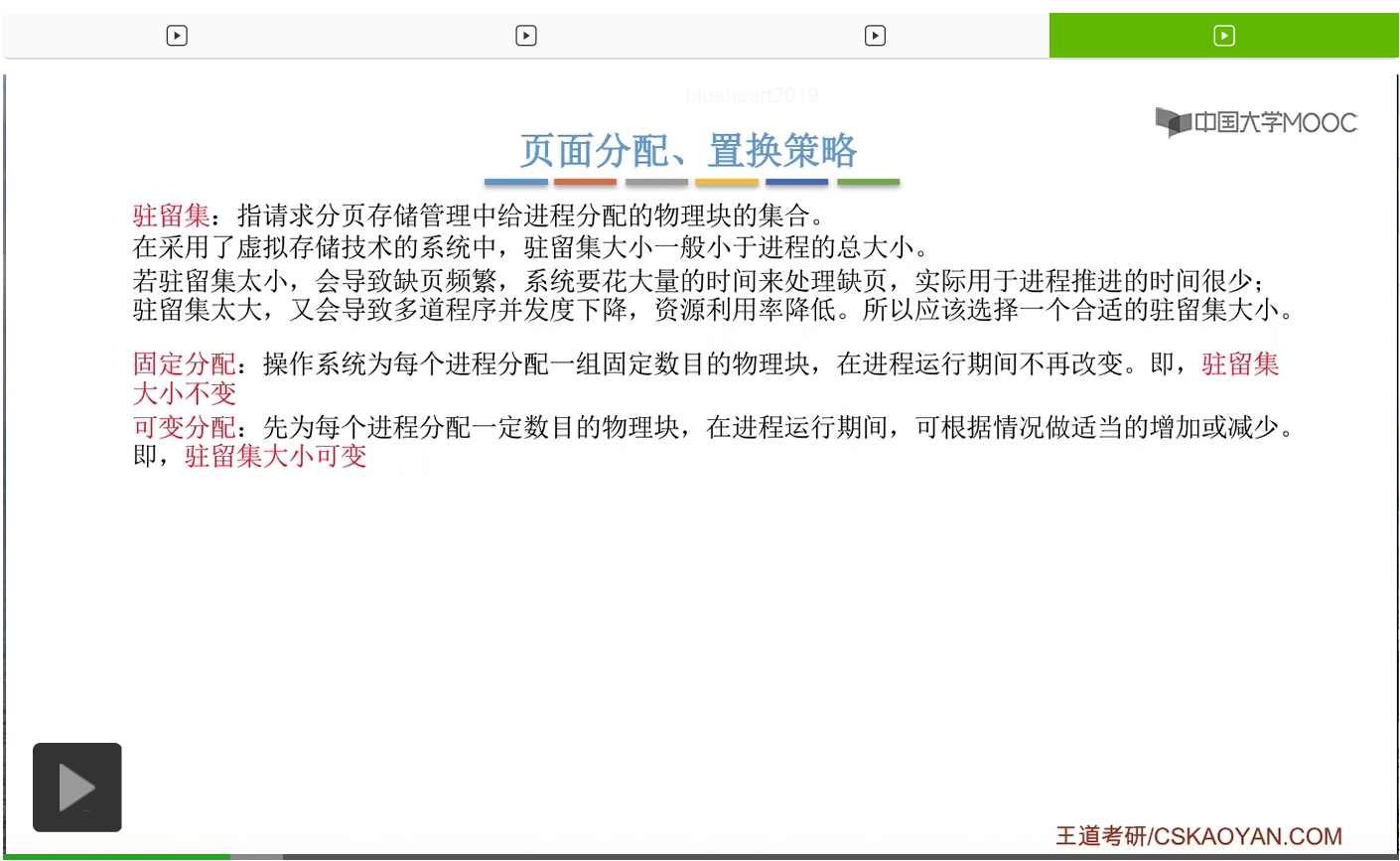
另外,当页面置换的时候,置换的范围应该是什么?根据这个问题,人们又提出了局部置换和全局置换这两种置换范围的策略。所以局部置换和全局置换的区别就在于,当某个进程发生缺页,并且需要置换出某个页面的时候,那这个置换出的页面是不是只能是自己了。
那把这两种分配和置换的策略两两结合,可以得到这样的三种分配和置换的策略。分别是固定分配-局部置换,可变分配-局部置换和可变分配-全局置换。
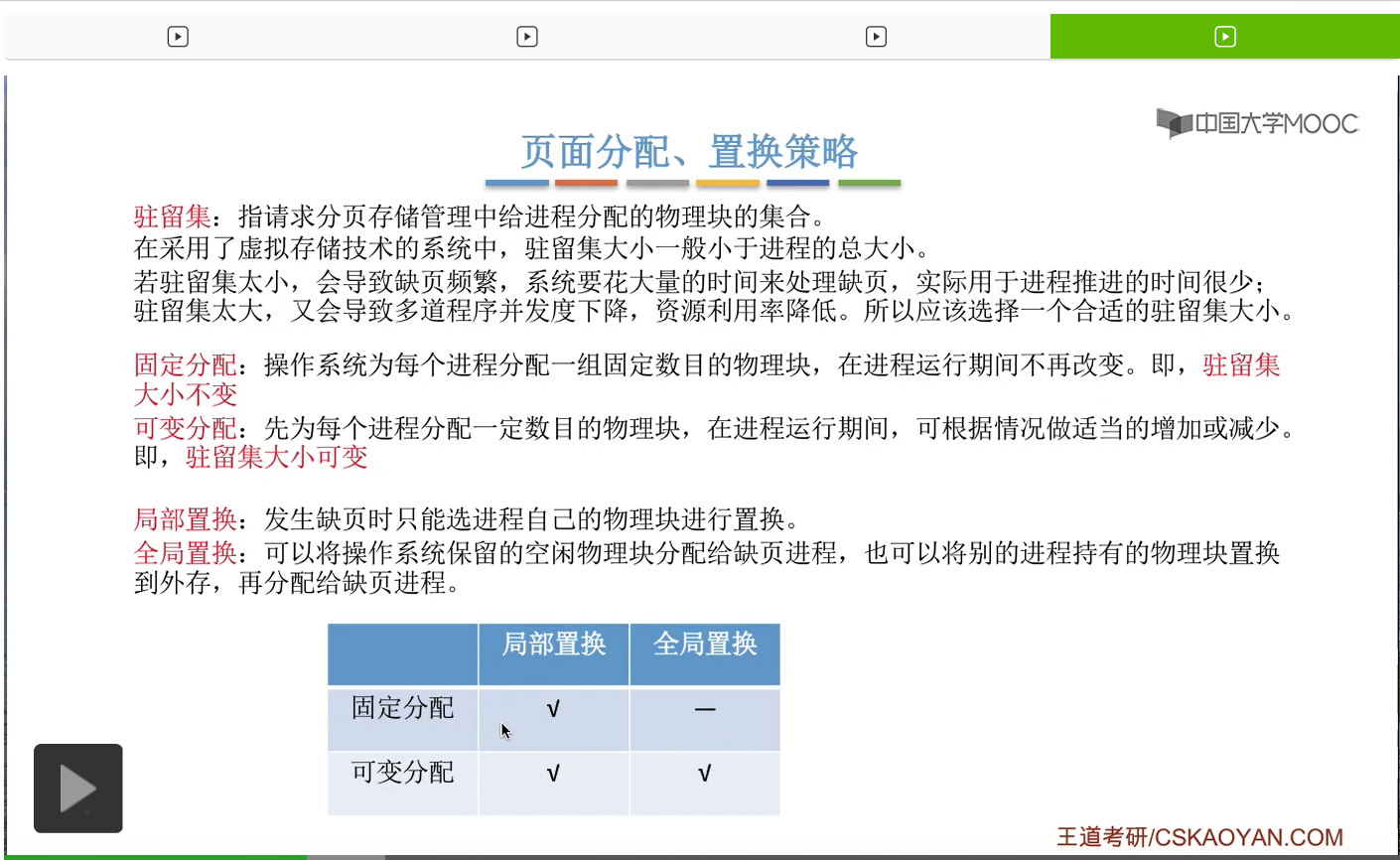
那大家会发现,其实并不存在固定分配-全局置换这种策略。因为从全局置换的这个规则我们也可以知道,如果使用的是全局置换的话,就意味着一个进程所拥有的物理块是必然会改变的。而固定分配又规定着进程的驻留集大小不变,也就是进程所拥有的物理块数是不能改变的。所以固定分配-全局置换这种分配置换策略是不存在的,那接下来我们依次介绍存在的这三种分配和置换的策略。
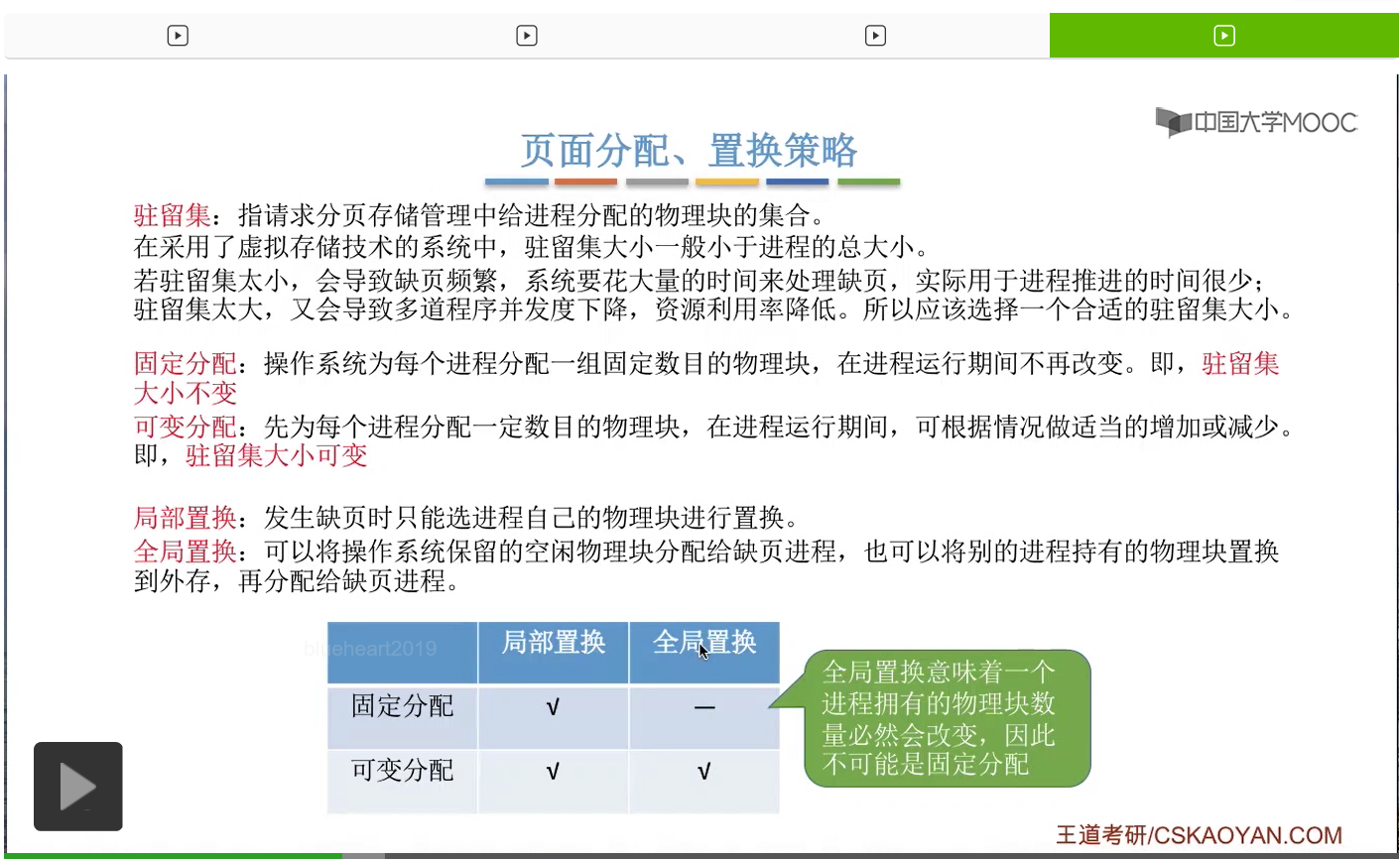
不过在实际应用中,一般如果说采用这种固定分配-局部置换策略的系统,它会根据进程大小、进程优先级或者是程序员提出的一些参数来确定到底要给每个进程分配多少个物理块,不过这个数量一般来说是不太合理的。那因为驻留集的大小不可变,所以固定分配局部置换这种策略的灵活性相对来说是比较低的。

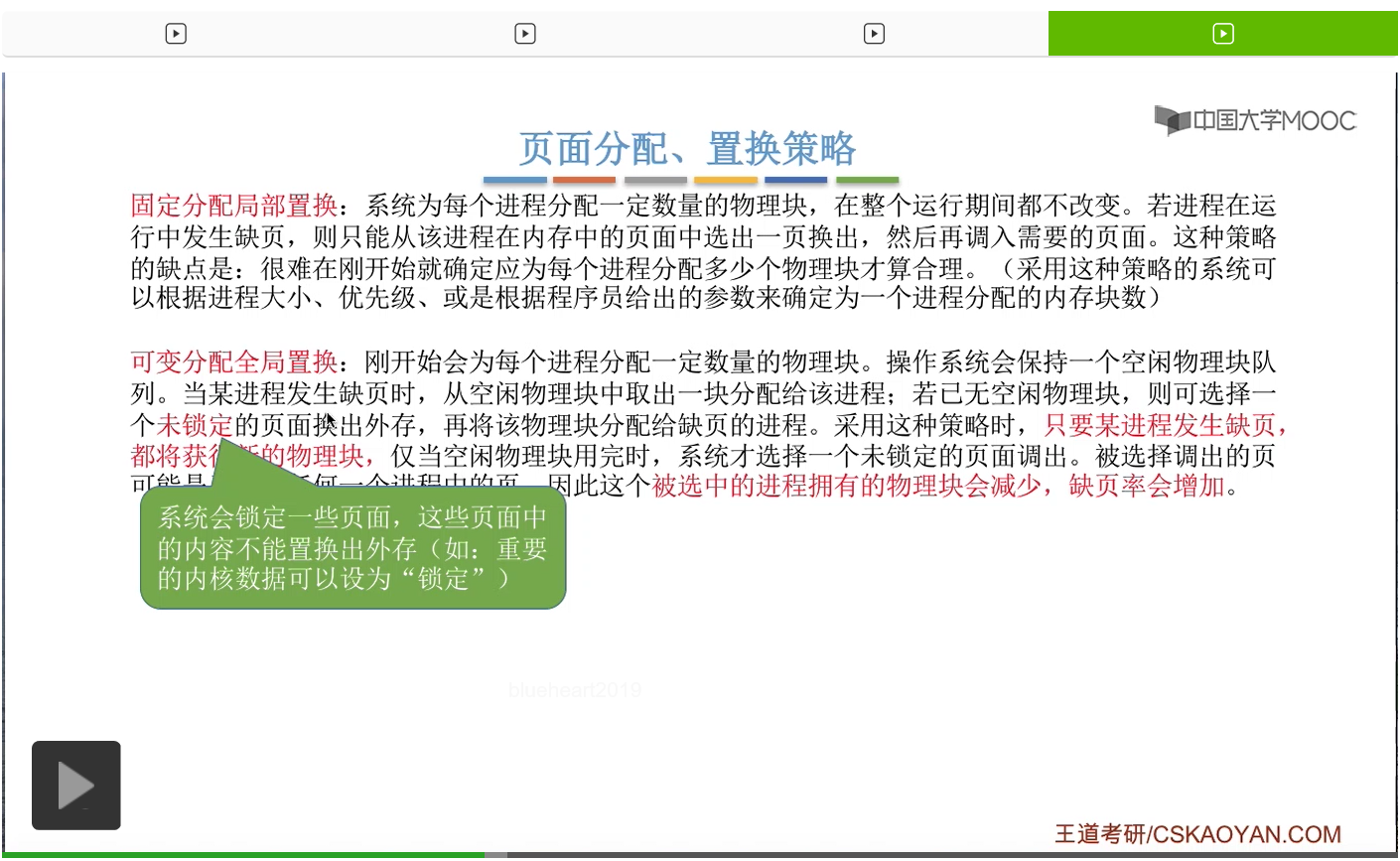
那第二种叫做可变分配全局置换。因为是可变分配,所以说系统刚开始会为进程分配一定数量的物理块,但是之后在进程运行期间,这个物理块的数量是可以改变的,那操作系统会保持一个空闲物理块的队列。如果说一个进程发生缺页的时候,就会从这个空闲物理块当中取出一个分配给进程。那如果说此时这个空闲物理块都已经用完了,那就可以选择一个系统当中未锁定的页面换出外存,再把这个物理块分配给缺页的这个进程。
那这个地方所谓的未锁定的页面指的是什么呢?其实系统会锁定一些很重要的就是不允许被换出外存、需要常驻内存的页面,比如说系统当中的某些很重要的内核数据,就有可能是被锁定的。那另外一些可以被置换出外存的页面,就是所谓的“未锁定”的页面。当然这个地方只是做一个拓展,在考试当中应该不会考查。
那通过刚才对这个策略的描述大家也会发现,在这种策略当中,只要进程发生缺页的话,那它必定会获得一个新的物理块。如果说空闲物理块没有用完,那这个新的物理块就会从空闲物理块队列当中选择一个给它分配。那如果说空闲物理块用完了,系统才会选择一个未锁定的页面换出外存,但这个未锁定的页面有可能是任何一个进程的页面。所以这个进程的页面被换出的话,那么它所拥有的物理块就会减少,它的缺页率就会有所增加。那显然,只要进程发生了缺页,就给它分配一个新的物理块,这种方式其实也是不太合理的。
所以之后人们又提出了可变分配局部置换的策略。那在刚开始会给进程分配一定数量的物理块,因为是可变分配,所以之后这个物理块的数量也是会改变的。那由于是局部置换,所以当进程发生缺页的时候,只允许这个进程从自己的物理块当中选出一个进行换出。那如果说操作系统在进程运行的过程中发现它频繁地缺页,那就会给这个进程多分配几个物理块,直到这个进程的缺页率回到一个适当的程度。那相反的,如果一个进程在运行当中缺页率特别低的话,那系统会适当地减少给这个进程所分配的物理块。那这样的话,就可以让系统的多道程序并发度也保持在一个相对理想的位置。

那这三种策略当中,最难分辨的是可变分配全局置换和可变分配局部置换。大家需要抓住它们俩最大的一个区别,如果采用的是全局置换策略的话,那么只要缺页就会给这个进程分配新的物理块。那如果说采用的是这种局部置换的策略的话,系统会根据缺页的频率来动态地增加或者减少一个进程所拥有的物理块。那这是三种我们需要掌握的页面分配策略,有可能在选择题当中进行考查。
那接下来我们再来讨论下一个问题。我们应该在什么时候调入所需要的页面呢?那一般来说有这样的两种策略。第一种叫做预调页策略。
根据我们之前学习的局部性原理,特别是空间局部性的原理。我们知道,如果说当前访问了某一个内存单元的话,那么很有可能在之后不久的将来会接着访问与这个内存单元相邻的那些内存单元。所以根据这个思想我们自然而然的也会想到,如果说我们访问了某一个页面的话,那么是不是在不久的之后就也有可能会访问与它相邻的那些页面呢?因此,基于这个方面的考虑,如果我们能够一次调入若干个相邻的页面,那么可能会比一次调入一个页面会更加高效。因为我们一次调入一堆页面的话,那么我们启动磁盘I/O的次数肯定就会少很多,这样的话就可以提升调页的效率。不过另一个方面,如果说我们提前调入的这些页面在之后没有被访问过的话,那么这个预调页就是一种很低效的行为。所以我们可以用某种方法预测不久之后可能会访问到的页面,将这些页面预先地调入内存。当然目前预测的成功率不高,只有50%左右。所以在实际应用当中,预调页策略主要是用于进程首次调入的时候,由程序员指出哪些部分应该是先调入内存的。
比如说我可以告诉系统把main函数相关的那些部分先调入内存,所以预调页策略是在进程运行前就进行调入的一种策略。
那第二种就是请求调页策略,这也是咱们之前一直在学习的请求调页方式。只有在进程期间发现缺页的时候,才会把所缺的页面调入内存。所以这种策略其实在进程运行期间才进行页面的调入。并且被调入的页面肯定在之后是会被访问到的。但是每次只能调入一个页面,所以每次调页都要启动磁盘I/O操作,因此I/O开销是比较大的。那在实际应用当中,预调页策略和请求调页策略都会结合着来使用。预调页用于运行前的调入,而请求调页策略是在进程运行期间使用的。那这是调入页面的实际问题。
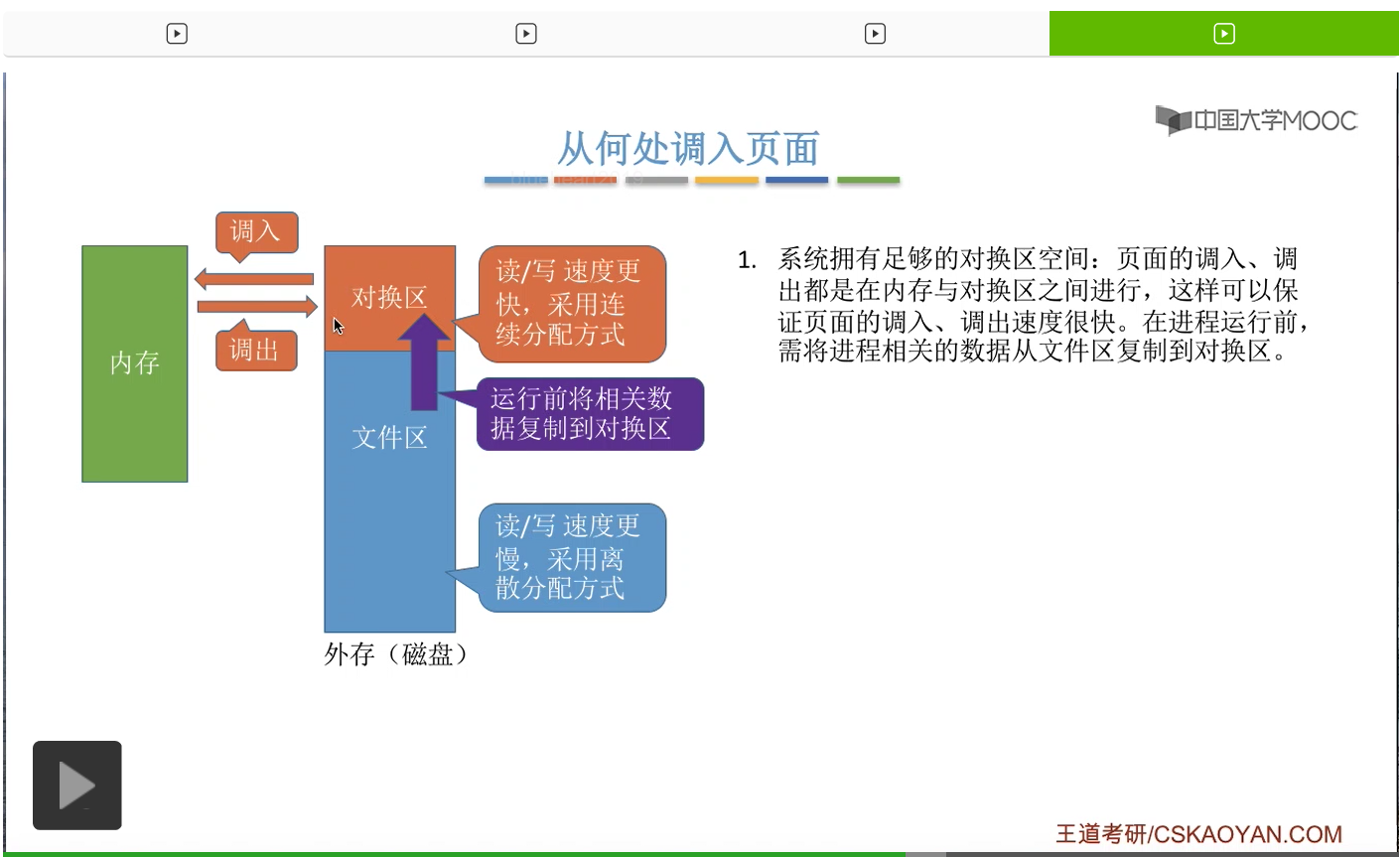
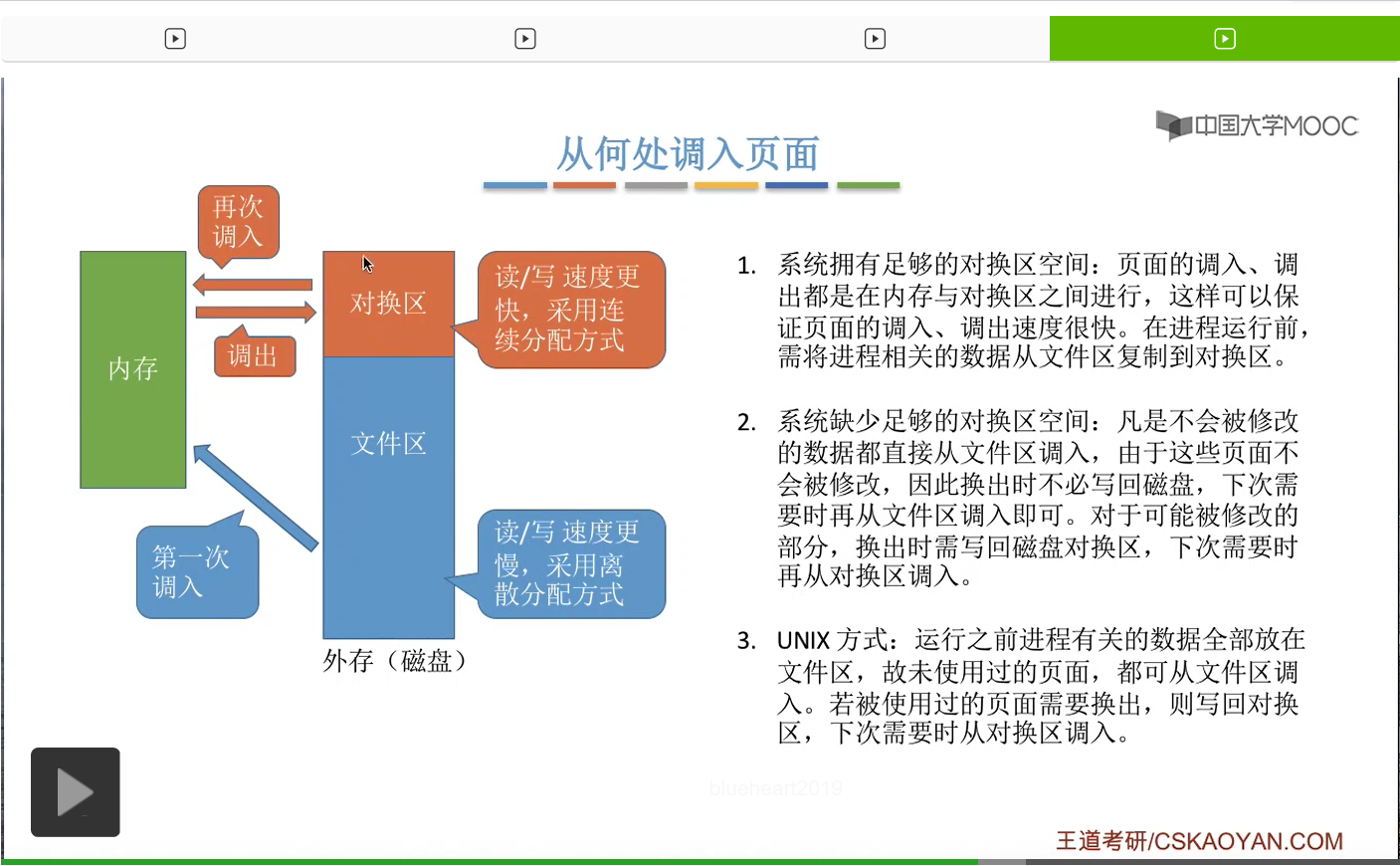
那接下来我们再来看一下我们应该从什么地方调入页面。之前我们有简单地介绍过,磁盘当中的存储区域分为对换区和文件区这样两个部分。其中对换区采用的是连续分配的方式,读写的速度更快,而文件区的读写速度是更慢的,它采用的是离散分配的方式。那什么是离散分配什么是连续分配,这个是咱们在之后的章节会学习的内容,这个地方先不用管,有个印象就可以。在本章中,大家只需要知道对换区的读写速度更快,而文件区的读写速度更慢就可以了。那一般来说文件区的大小要比对换区要更大,那平时我们指的程序在没有运行的时候,相关的数据都是存放在文件区的。
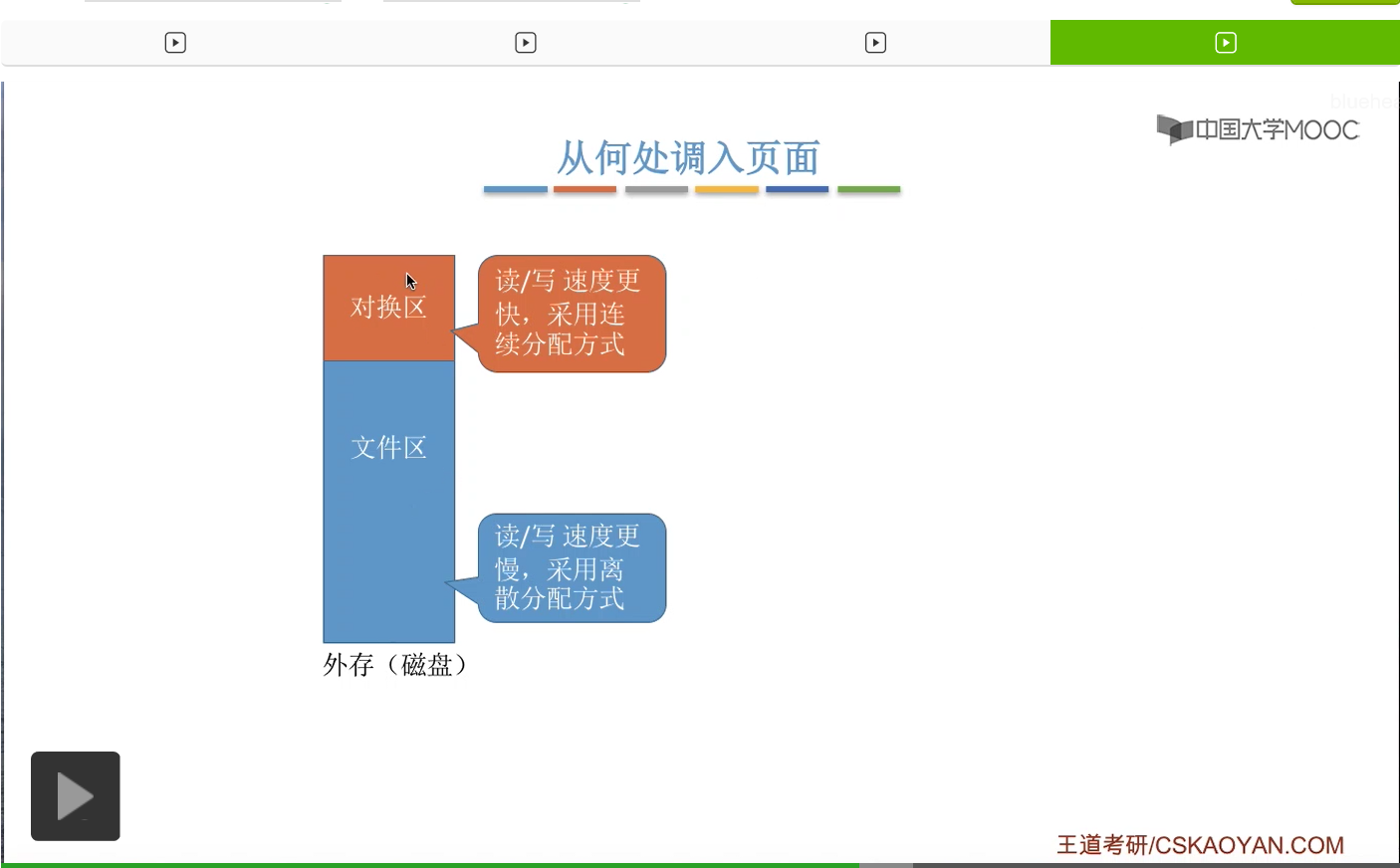
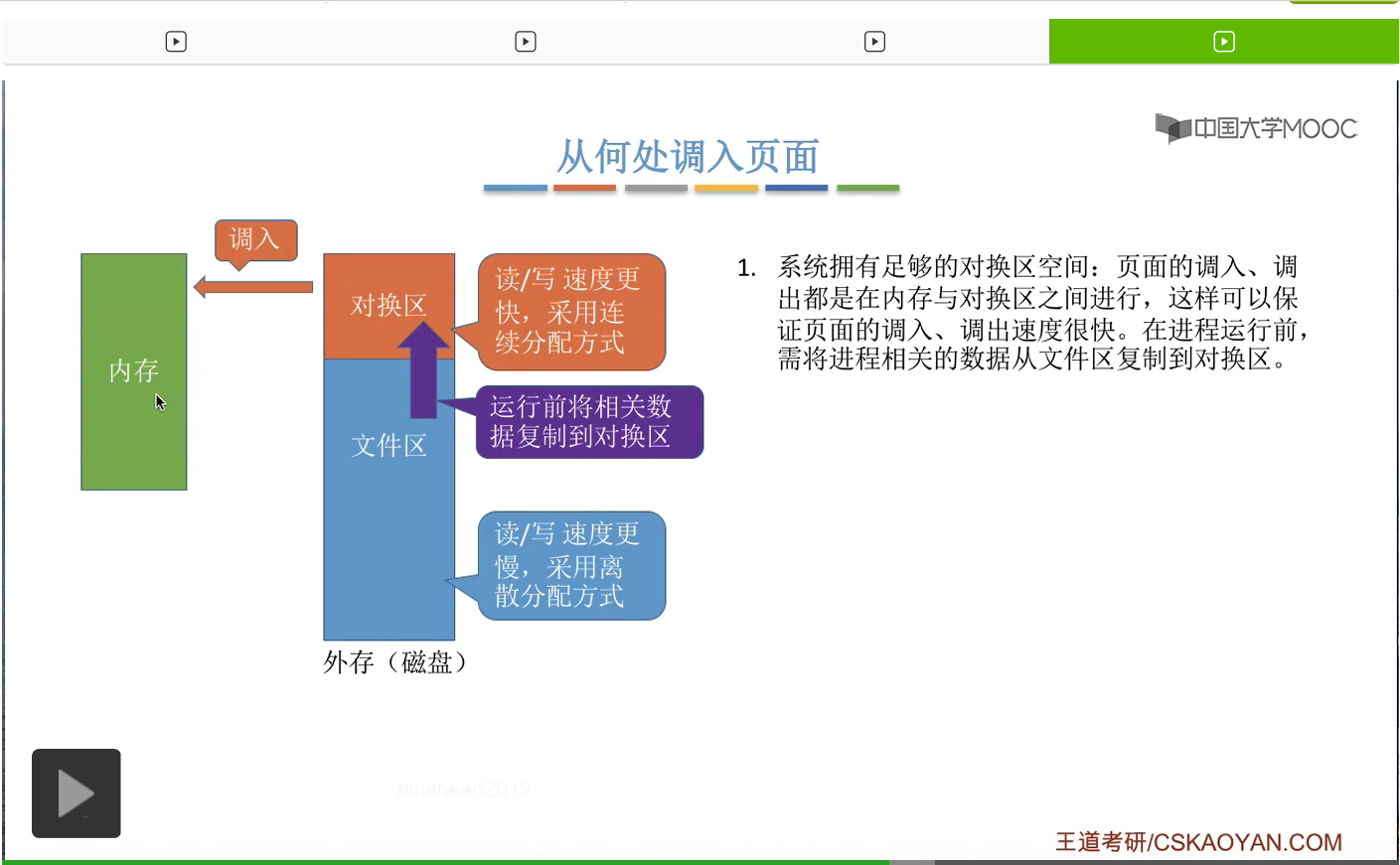
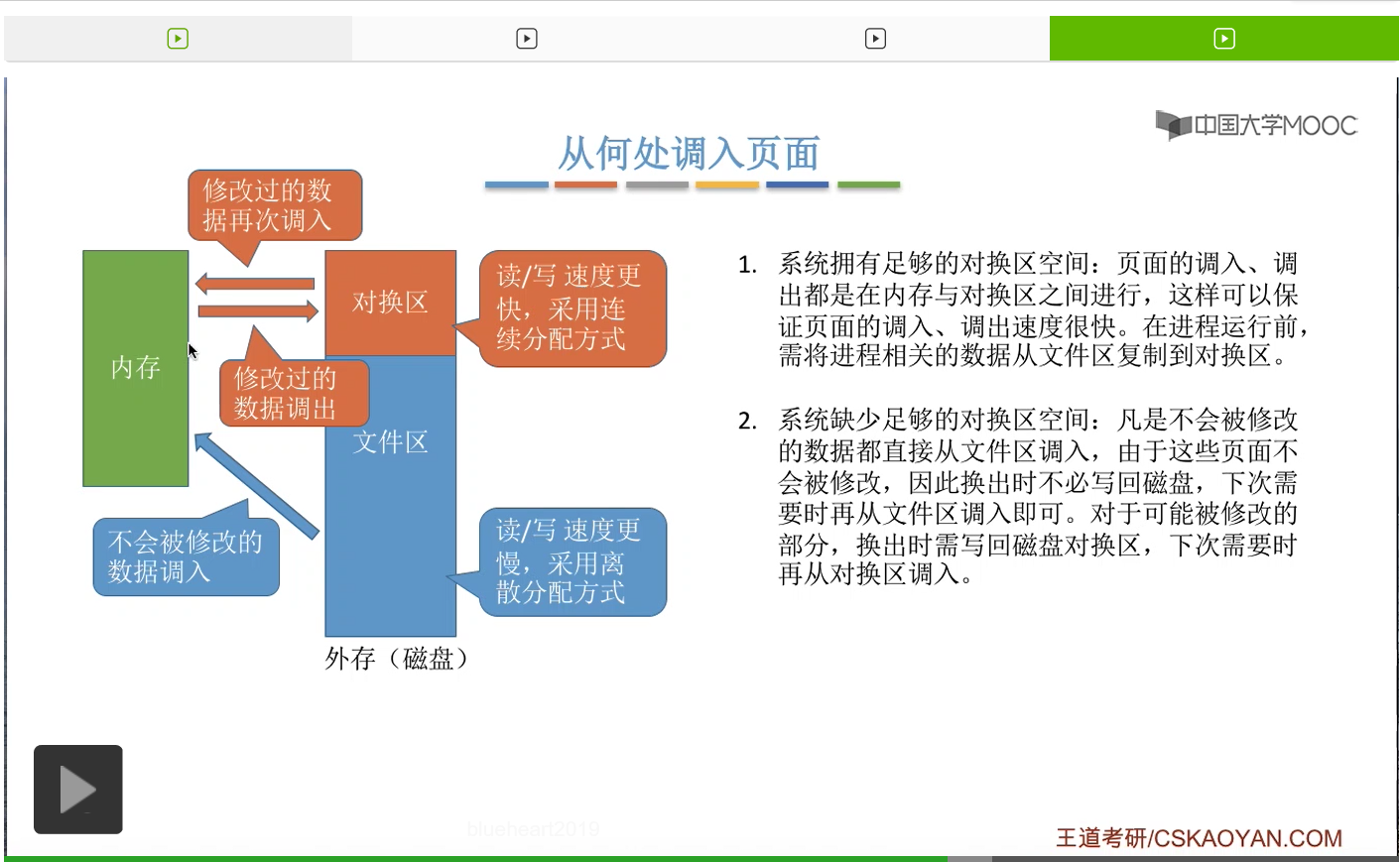
那由于对换区的读写速度更快,所以如果说系统拥有足够的对换区空间的话,那么页面的调入调出都是内存与对换区之间进行的。
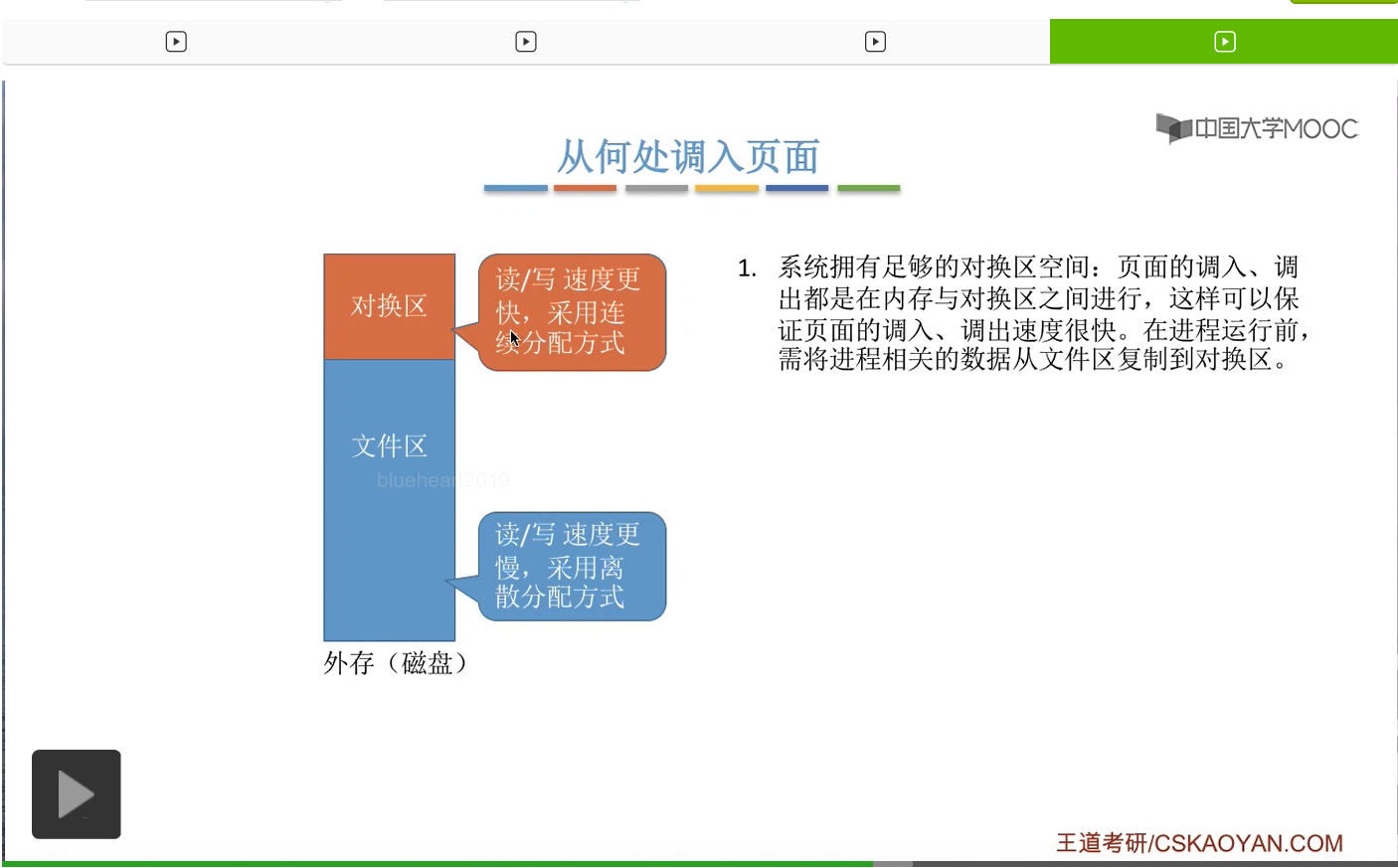
所以系统中如果有足够的对换区空间,那刚开始在运行之前会把我们的进程相关的那些数据从文件区先复制到对换区,
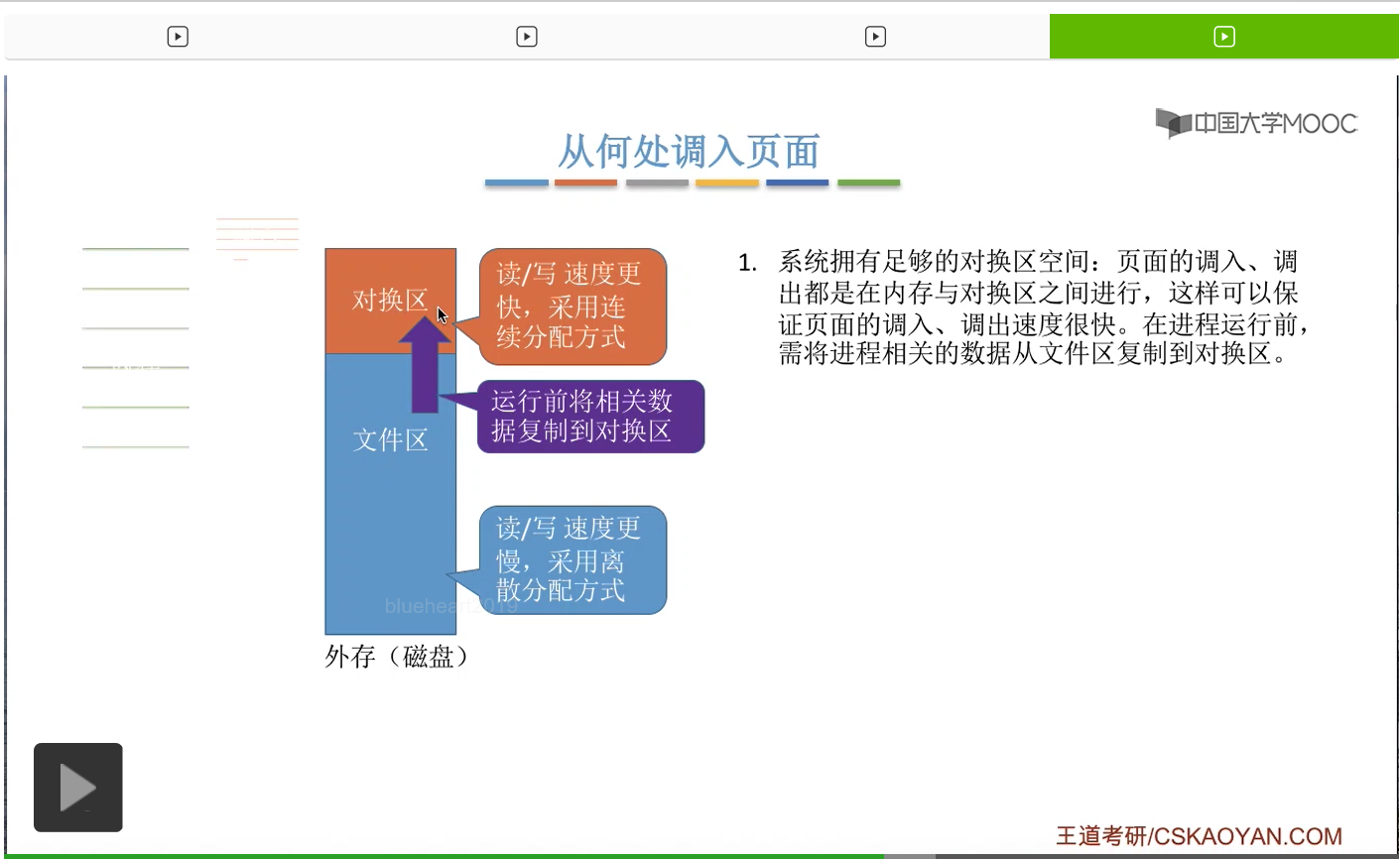
之后把这些需要的页面从对换区调入内存。
那相应的,如果内存空间不够的话,可以把内存中的某些页面调出到对换区当中。页面的调入调出都是内存和对换区这个更高速的区域进行的。那这是在对换区大小足够的情况下使用的一种方案。
那如果说系统中缺少足够的对换区空间的话,凡是不会被修改的数据都会从文件区直接调入内存。那由于这些数据是不会被修改的,所以当调出这些数据的时候并不需要重新写回磁盘。
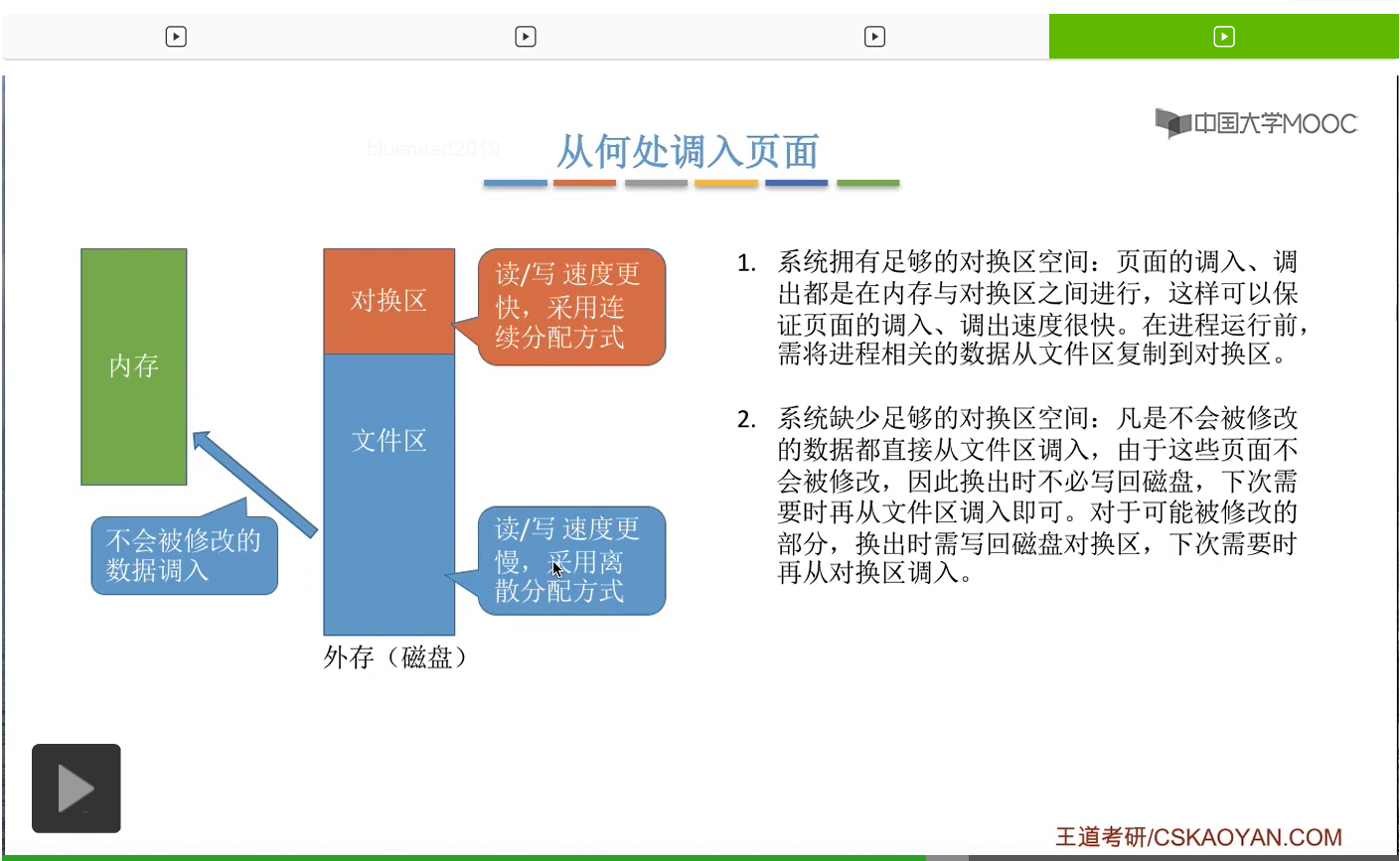
那如果说某些页面被修改过的话,把它调出的时候就需要写回到对换区,而不是写回到文件区,因为文件区的读写速度更慢。
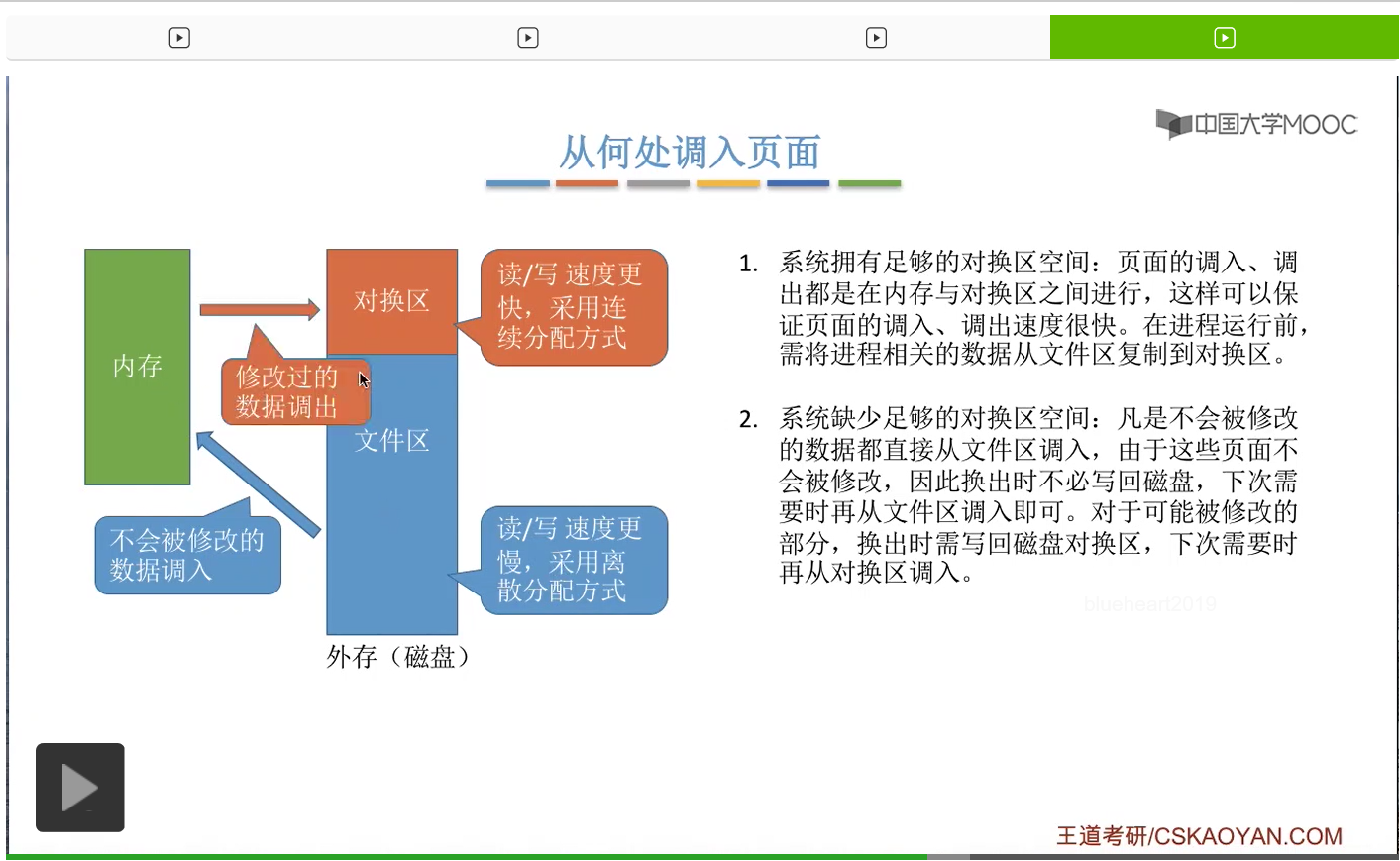
那相应的,如果之后还需要再使用到这些被修改的页面的话,那就从对换区再换入内存。
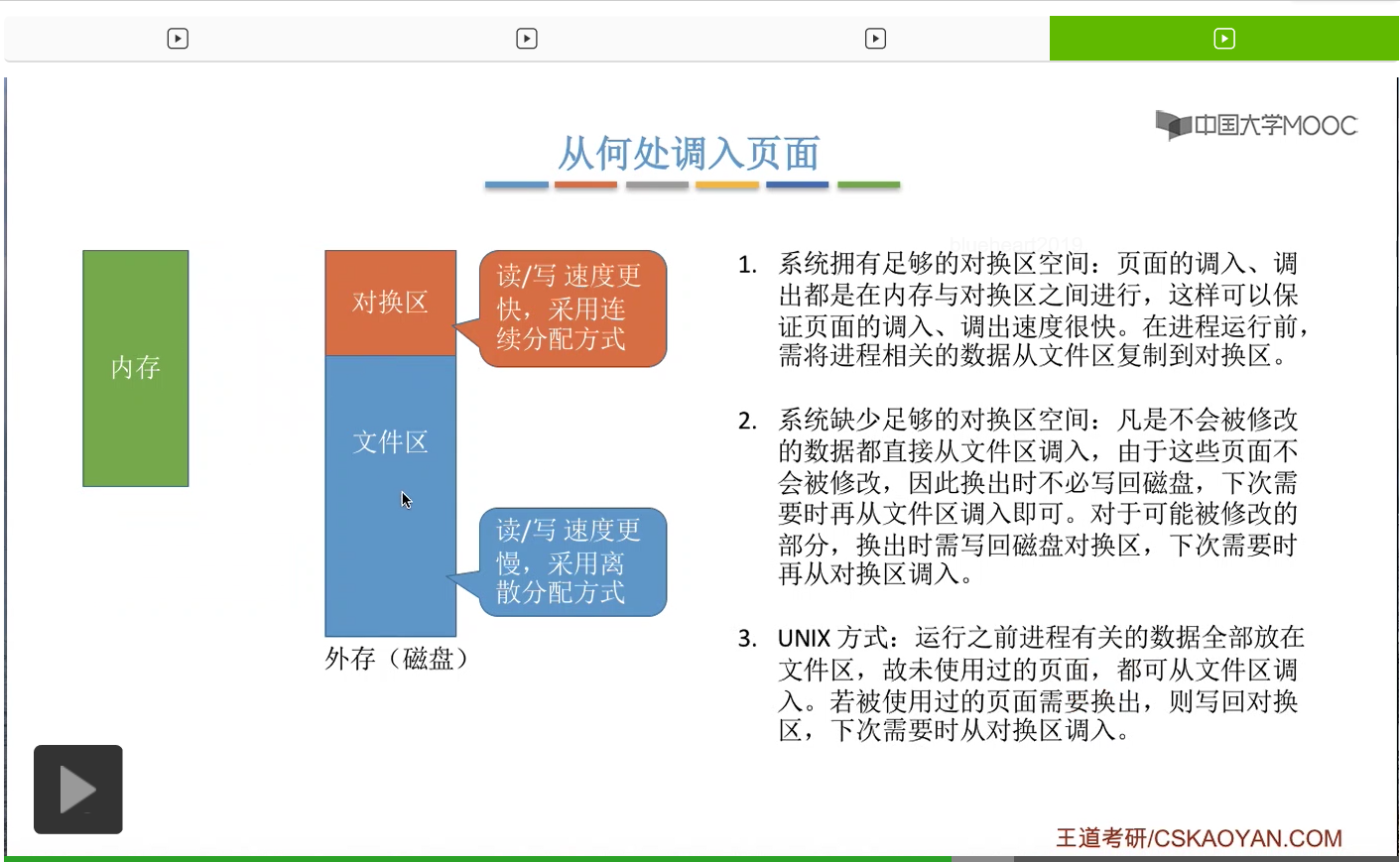
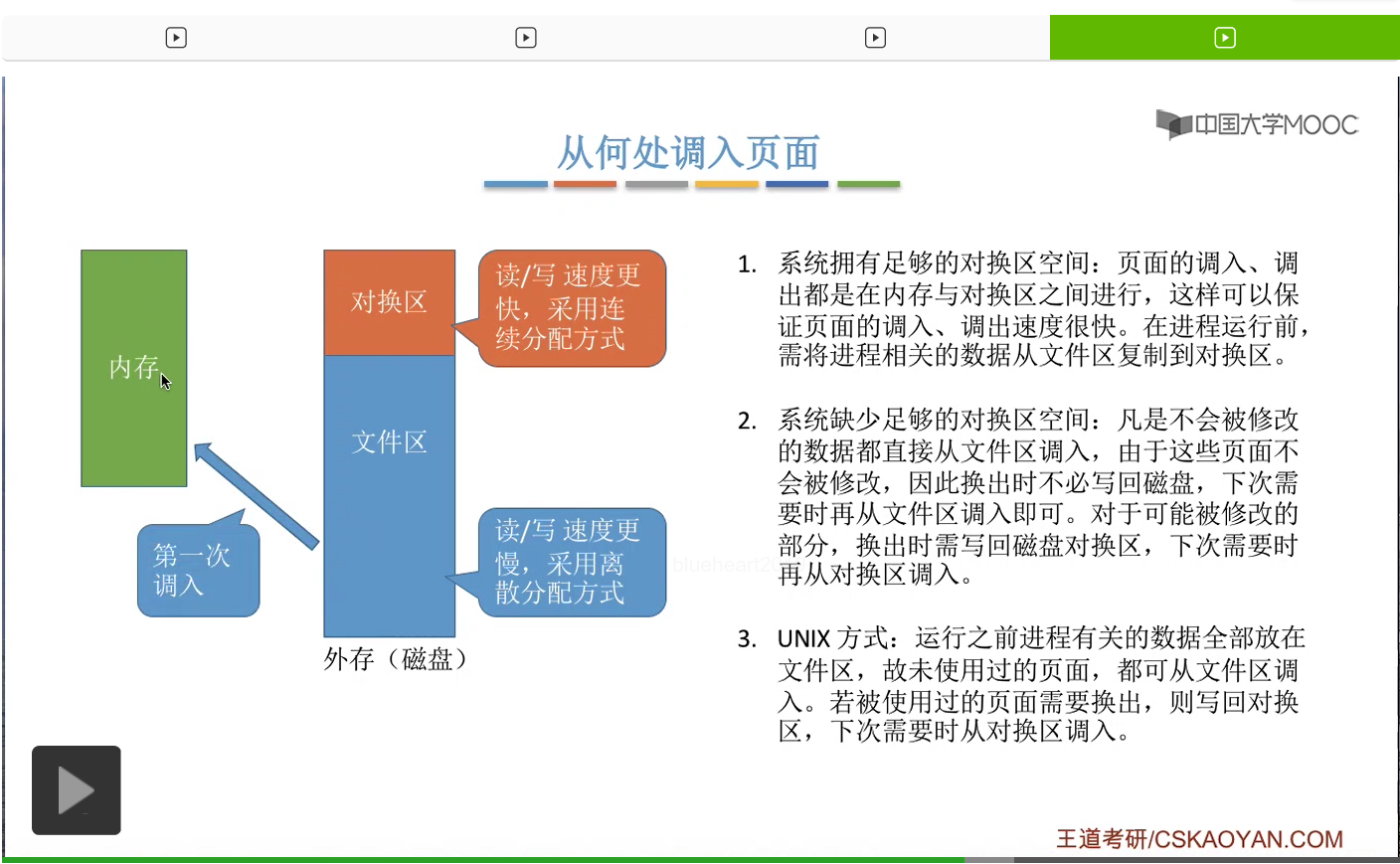
第三种,UNIX使用的是这样的一种方式。如果说一个页面还没有被使用过,也就是这个页面第一次被使用的话,
那么它是从文件区直接调入内存。
那之后如果内存空间不够,需要把某些页面换出外存的话,那么是换出到这个对换区当中。
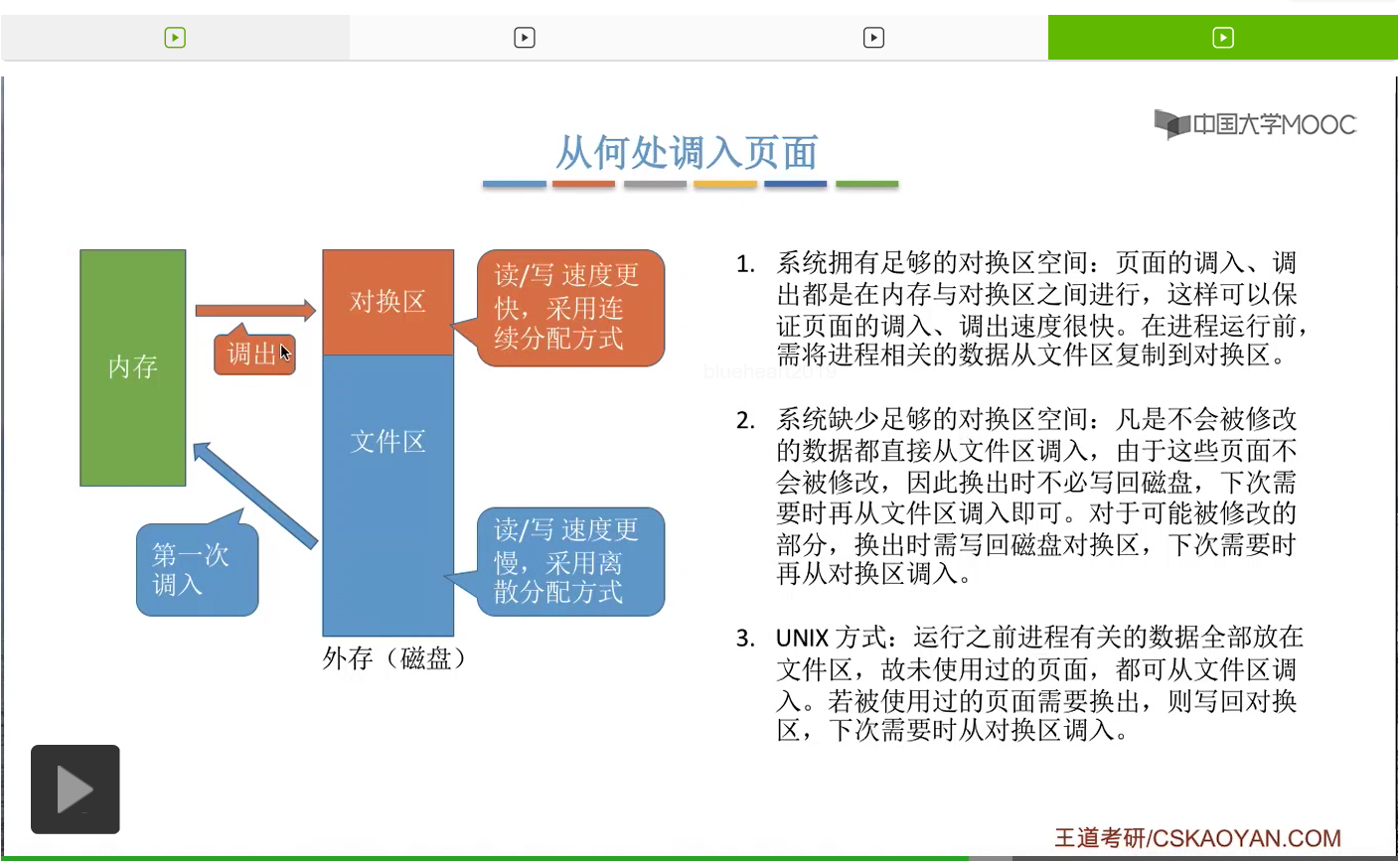
那如果这个页面需要再次被使用的话,就是要从对换区再换回内存。这是UNIX系统采用的一种方式。
那接下来我们再来介绍一个很常考的一个概念,叫做抖动(或者叫颠簸)现象。那如果说发生了抖动现象的话,系统会用大量的时间来处理这个进程页面的换入换出。而实际用于进程执行的时间就变得很少,所以我们要尽量避免抖动现象的发生。
那为了防止抖动的发生,就需要为进程分配足够的物理块。但如果说物理块分配的太多的话,又会降低系统整体的并发度,降低某些资源的利用率。

所以为了研究应该为每个进程分配多少个物理块,有的科学家在196几年提出了进程工作集的概念。

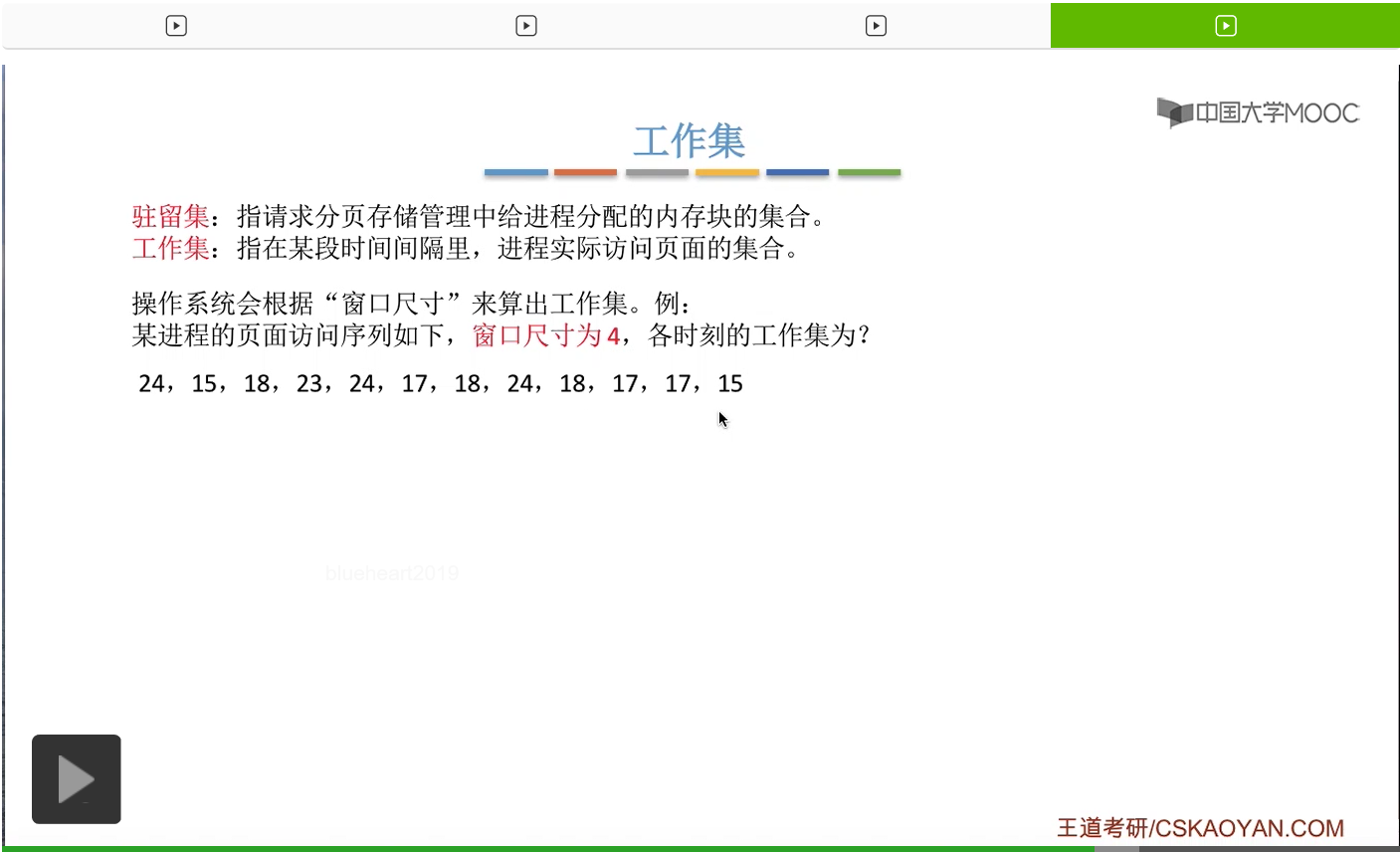
工作集和驻留集其实是有区别的。驻留集是指在请求分页存储管理当中,给进程分配的内存块的集合。

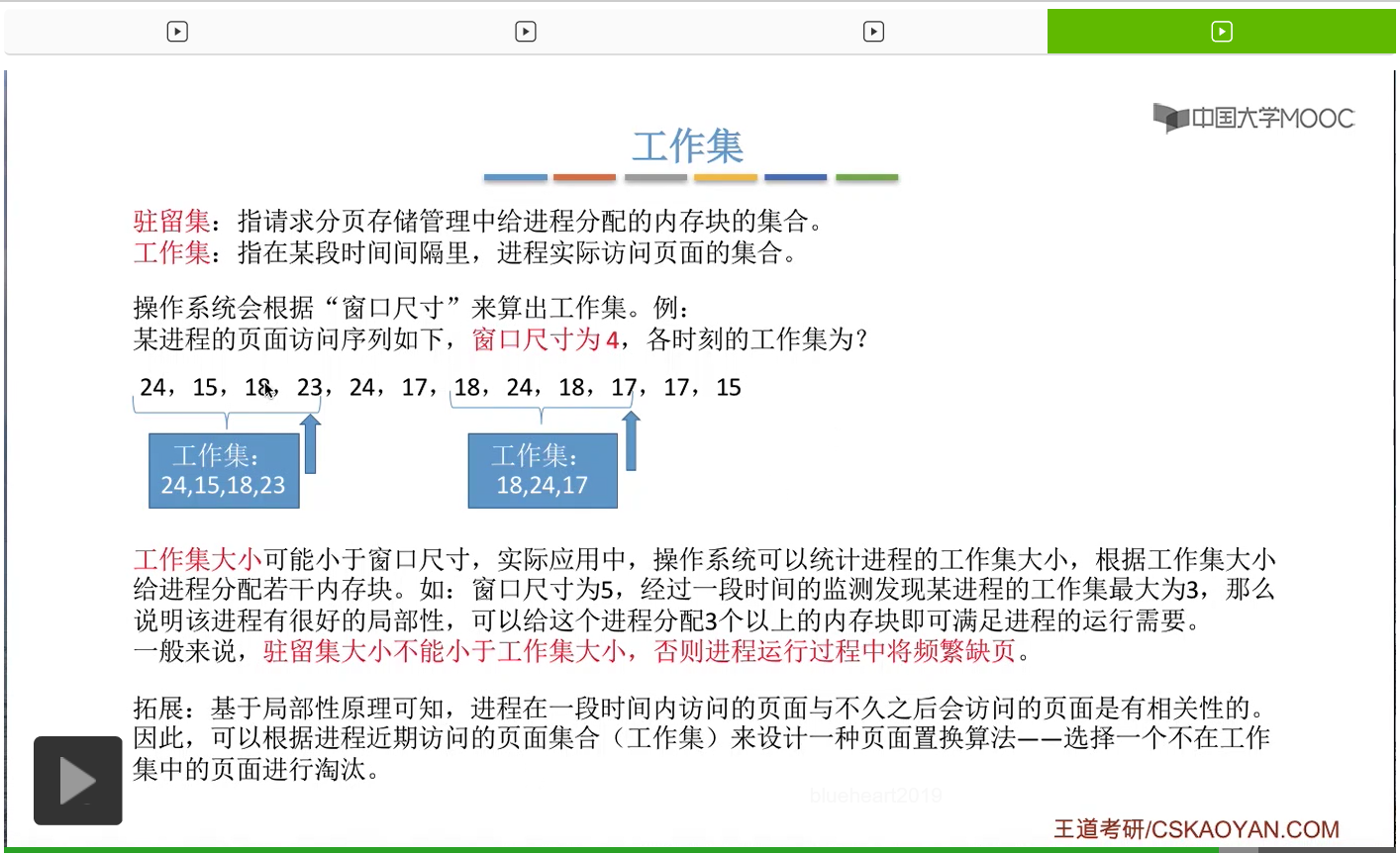
我们直接来看一个例子。一般来说操作系统会设置一个所谓的“窗口尺寸”来算出工作集。那假设一个进程对页面的访问序列是这样的一个序列。



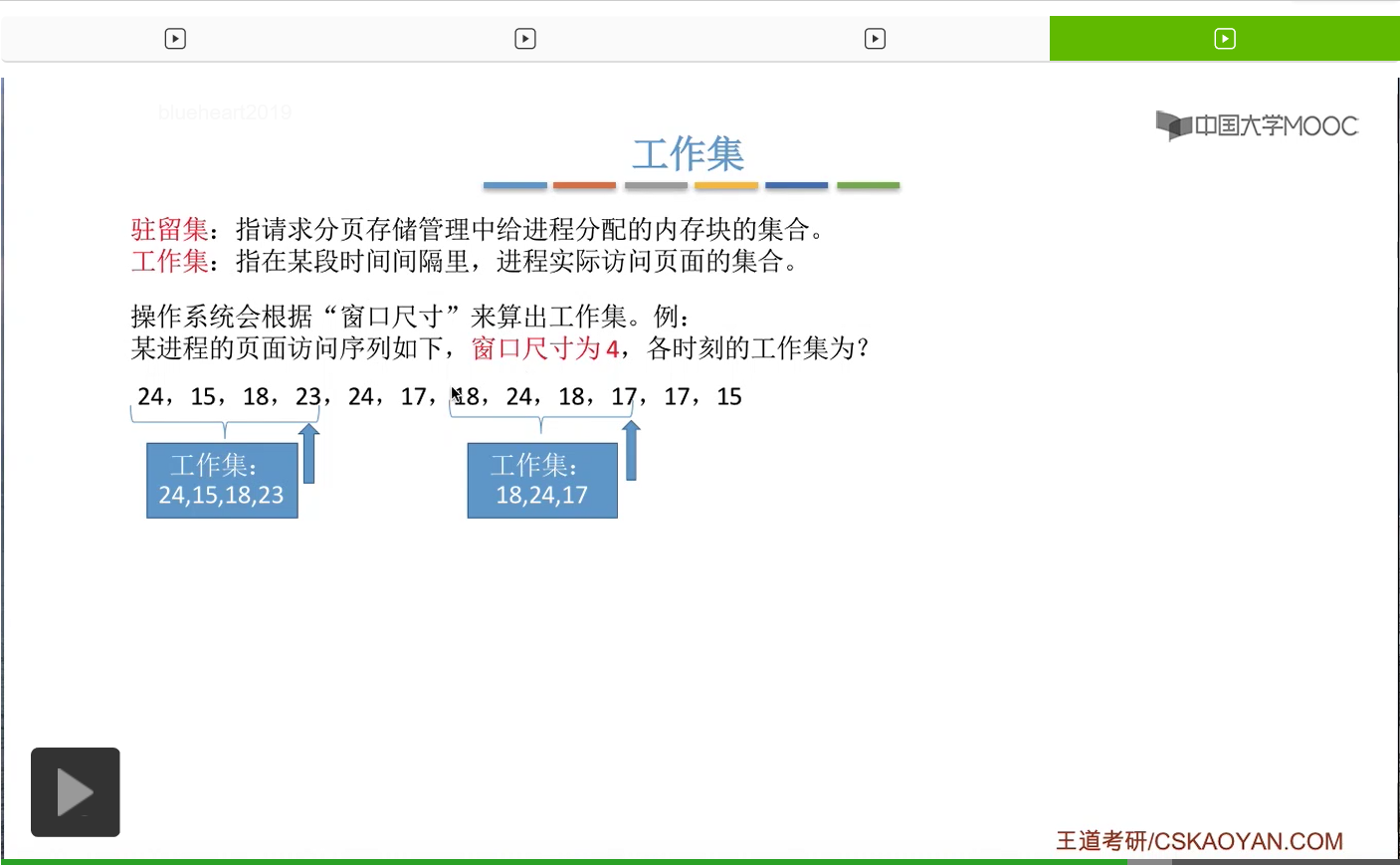
工作集的大小可能会小于窗口的尺寸。在实际应用当中,窗口尺寸一般会设置的更大一些,比如说设置10、50、100这样的数字。那对于一些局部性很好的进程来说,工作集的大小一般是要比窗口尺寸的大小要更小的。所以系统可以根据检测工作集的大小来决定到底要给这个进程分配多少个内存块。换一个说法就是,根据工作集的大小,来确定驻留集的大小是多少。

那一般来说,驻留集的大小不能小于工作集的大小。如果说更小的话,那就有可能会发生频繁的缺页,也就是发生抖动现象。
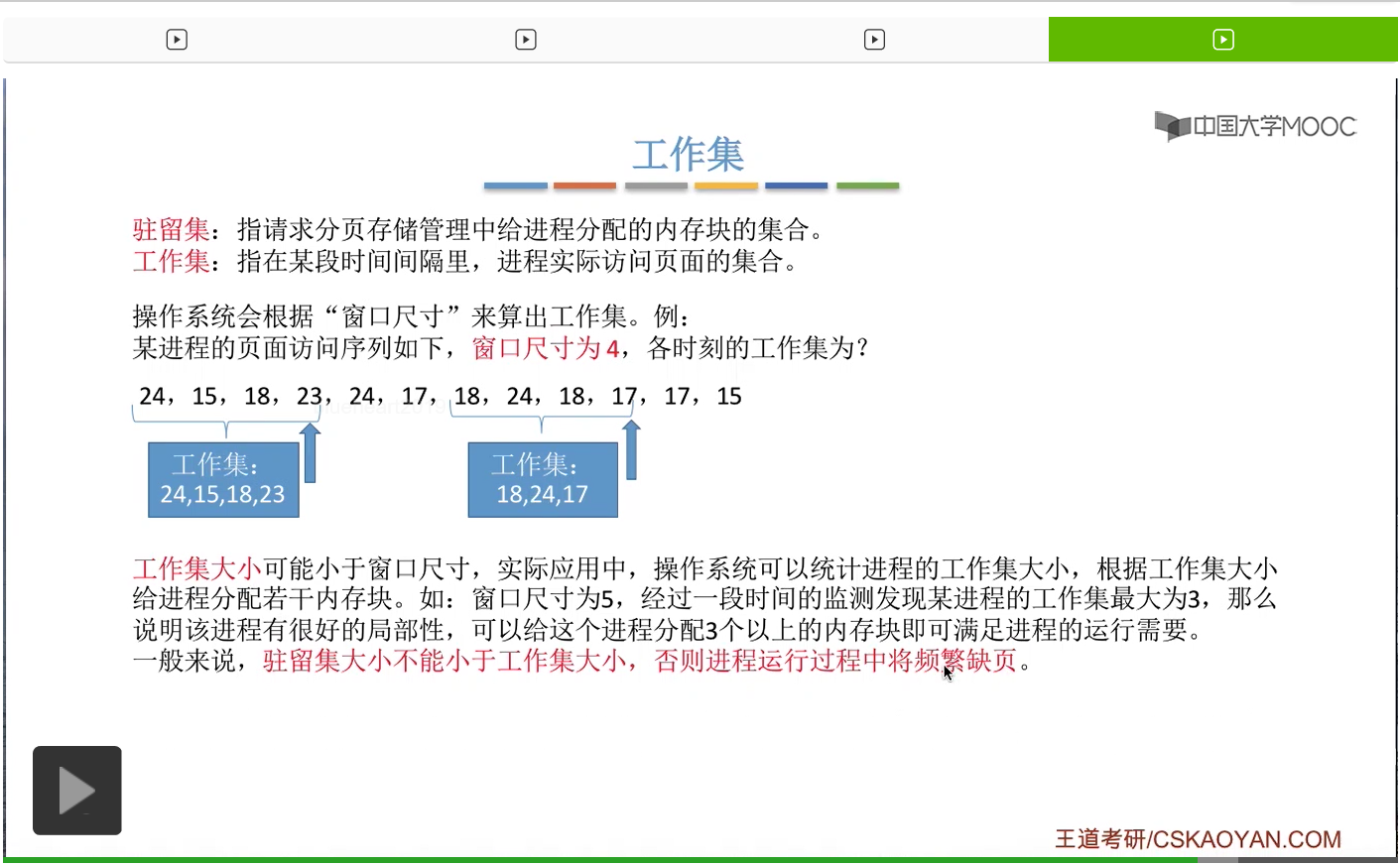
另外,在有的系统当中,也会根据工作集的概念来设计一种页面置换算法。比如说如果说这个进程需要置换出某个页面的话,那完全就可以选择一个不在工作集当中的页面进行淘汰。那这些知识点只是作为一个拓展,大家只要有个印象就可以了。
需要特别注意驻留集这个概念。在之前咱们讲过的那些内容当中,经常会遇到某些题目告诉我们一个条件就是说,系统为某个进程分配了N个物理块,那这种说法其实也可以改变一种等价的表述方式,就是也可以说成是某个进程的驻留集大小是N。那如果说题目中的条件是用驻留集大小这种方式给出的话,大家也需要知道它所表述的到底是什么意思。那另外大家需要注意这三种分配置换策略在真题当中是进行考查过的。并且在有的大题当中有可能会告诉大家,一个进程采用固定分配局部置换的策略,那这个条件就是为了告诉大家,系统为一个进程分配的物理块数是不会改变的,大家在做课后习题的时候可以注意一下,很多大题都会给出这样的一个条件。那我们需要知道这个条件背后隐含的一系列的信息。那这个地方还需要注意,并不存在固定分配全局置换这种策略。因为全局置换意味着一个进程所拥有的物理块数肯定是会改变的,而固定分配又要求一个进程拥有的物理块数是不能改变的。所以固定分配和全局置换这两个条件本身就是相互矛盾的,因此并不存在固定分配全局置换这种方式。那之后介绍的内容,何时调入页面,应该给从何处调入页面能有个印象就可以了。最后大家还需要重点关注抖动(颠簸)这个现象。那产生抖动的主要原因是分配给进程的物理块不够,所以如果要解决抖动问题的话,那么肯定就是用某种方法给这个进程分配更多的物理块。那这一点在咱们的课后习题当中也会遇到。那我们还对工作集的概念做了一系列的拓展,不过一般来说工作集这个概念不太容易进行考查。但是大家需要注意的是驻留集大小一般来说不能小于工作集的大小,如果更小的话那就会产生抖动现象。那这个小节的内容一般来说只会在选择题当中进行考查。但是在考试当中也有可能会用某些概念作为大题当中的一个条件进行给出,所以大家还需要通过课后习题进行进一步的巩固。