两个hadoop集群之间同步数据
实例为dws的 store_wt_d表
一 文件拷贝
hadoop distcp -update -skipcrccheck hdfs://10.8.31.14:8020/user/hive/warehouse/dws.db/store_wt_d/ hdfs://10.8.22.40:8020/user/hive/warehouse/dws.db/store_wt_d/
-skipcrccheck 跳过检验
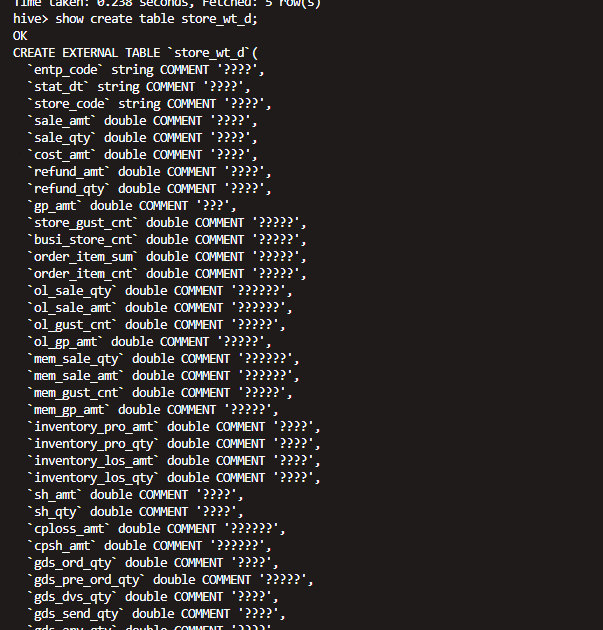
二 找到源地址对应的文件的数据库以及表的结构
use dws
show create table store_wt_d;
三 在新的集群上面创建对应的库表
辅助刚刚那台语句 修改对应集群的存储地址
CREATE EXTERNAL TABLE `store_wt_d`(
`entp_code` string COMMENT '????',
`stat_dt` string COMMENT '????',
`store_code` string COMMENT '????',
`sale_amt` double COMMENT '????',
`sale_qty` double COMMENT '????',
`cost_amt` double COMMENT '????',
`refund_amt` double COMMENT '????',
`refund_qty` double COMMENT '????',
`gp_amt` double COMMENT '???',
`store_gust_cnt` double COMMENT '?????',
`busi_store_cnt` double COMMENT '?????',
`order_item_sum` double COMMENT '?????',
`order_item_cnt` double COMMENT '?????',
`ol_sale_qty` double COMMENT '??????',
`ol_sale_amt` double COMMENT '??????',
`ol_gust_cnt` double COMMENT '?????',
`ol_gp_amt` double COMMENT '?????',
`mem_sale_qty` double COMMENT '??????',
`mem_sale_amt` double COMMENT '??????',
`mem_gust_cnt` double COMMENT '?????',
`mem_gp_amt` double COMMENT '?????',
`inventory_pro_amt` double COMMENT '????',
`inventory_pro_qty` double COMMENT '????',
`inventory_los_amt` double COMMENT '????',
`inventory_los_qty` double COMMENT '????',
`sh_amt` double COMMENT '????',
`sh_qty` double COMMENT '????',
`cploss_amt` double COMMENT '??????',
`cpsh_amt` double COMMENT '??????',
`gds_ord_qty` double COMMENT '????',
`gds_pre_ord_qty` double COMMENT '?????',
`gds_dvs_qty` double COMMENT '????',
`gds_send_qty` double COMMENT '????',
`gds_arv_qty` double COMMENT '????',
`gds_arv_amt` double COMMENT '????',
`gds_take_qty` double COMMENT '????',
`rtn_bk_ps_qty` double COMMENT '??????',
`gds_need_qty` double COMMENT '????',
`stk_amt` double COMMENT '????',
`stk_qty` double COMMENT '????',
`ini_stk_qty` double COMMENT '??????',
`ini_stk_amt` double COMMENT '??????',
`fnl_stk_qty` double COMMENT '??????',
`fnl_stk_amt` double COMMENT '??????',
`iwh_as_qty` double COMMENT '????????',
`iwh_as_amt` double COMMENT '????????',
`iwh_as_gp_amt` double COMMENT '?????????',
`gds_arv_iwh_qty` double COMMENT '??????',
`gds_arv_iwh_amt` double COMMENT '??????',
`gds_arv_iwh_gp_amt` double COMMENT '???????',
`transfer_iwh_qty` double COMMENT '??????',
`transfer_iwh_amt` double COMMENT '??????',
`transfer_iwh_gp_amt` double COMMENT '???????',
`iwh_io_qty` double COMMENT '??????',
`iwh_io_amt` double COMMENT '??????',
`iwh_io_gp_amt` double COMMENT '???????',
`iwh_tot_sum_qty` double COMMENT '???????',
`iwh_tot_sum_amt` double COMMENT '???????',
`iwh_tot_sum_gp_amt` double COMMENT '????????',
`owh_as_qty` double COMMENT '????????',
`owh_as_amt` double COMMENT '????????',
`owh_as_gp_amt` double COMMENT '?????????',
`stk_bs_qty` double COMMENT '??????',
`stk_bs_amt` double COMMENT '??????',
`stk_bs_gp_amt` double COMMENT '???????',
`owh_pos_qty` double COMMENT '??????',
`owh_pos_amt` double COMMENT '??????',
`owh_pos_gp_amt` double COMMENT '???????',
`owh_rs_qty` double COMMENT '????????',
`owh_rs_amt` double COMMENT '????????',
`owh_rs_gp_amt` double COMMENT '?????????',
`transfer_owh_qty` double COMMENT '??????',
`transfer_owh_amt` double COMMENT '??????',
`transfer_owh_gp_amt` double COMMENT '???????',
`owh_ly_qty` double COMMENT '??????',
`owh_ly_amt` double COMMENT '??????',
`owh_ly_gp_amt` double COMMENT '???????',
`owh_sc_qty` double COMMENT '??????',
`owh_sc_amt` double COMMENT '??????',
`owh_sc_gp_amt` double COMMENT '???????',
`owh_tot_sum_qty` double COMMENT '???????',
`owh_tot_sum_amt` double COMMENT '???????',
`owh_tot_sum_gp_amt` double COMMENT '????????',
`pk_qty` double COMMENT '????',
`pk_amt` double COMMENT '????',
`pk_gp_amt` double COMMENT '?????',
`pk_tot_sum_qty` double COMMENT '???????',
`pk_tot_sum_amt` double COMMENT '???????',
`pk_tot_sum_gp_amt` double COMMENT '????????',
`stk_item_cnt` double COMMENT '?????',
`unsold_gds_cnt` double COMMENT '?????',
`trgt_sale_amt` double COMMENT '??????',
`trgt_gust_cnt` double COMMENT '?????',
`trgt_gp_amt` double COMMENT '?????',
`synctime` string COMMENT '????')
PARTITIONED BY (
`part_date` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'field.delim'='-128',
'line.delim'=' ',
'serialization.format'='-128')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://10.8.22.40:8020/user/hive/warehouse/dws.db/store_wt_d'
四 修复表
msck repair table store_wt_d;
五 查看表情况
正常
hive--hdfs存储格式测试
hive默认的存储格式是text
测试 如果一个parquet格式的hive表数据导入到一个text的表之后会有什么情况
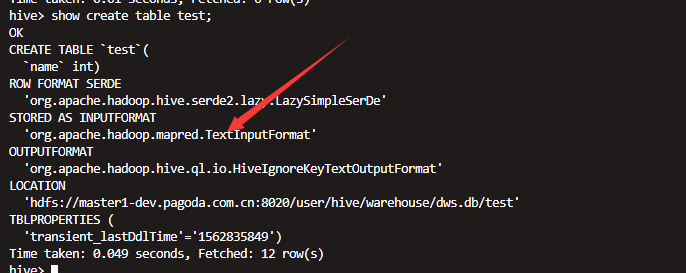
创建外表,默认为text格式 但是导入的数据为parquet格式

查看数据发现是乱码
另外如果数据的存储格式是parquet 直接去hdfs上查看也会乱码

如果是text格式存储的
正常

不同格式的相同数据之间的存储对比
上面为parquet压缩的,后面的为没有压缩的(text格式的)
使用压缩
CREATE TABLE `store_wt_d2` STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY') as select * from store_wt_d
再次查看 发现确实量小了不少
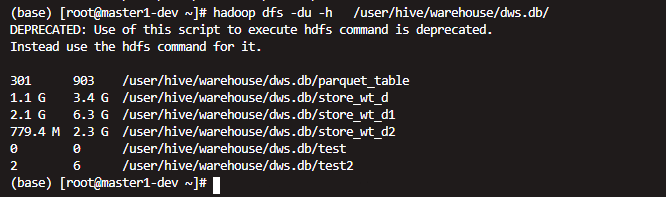
但是时间也明显更长了

创建parquet table :
create table mytable(a int,b int) STORED AS PARQUET;
创建带压缩的parquet table:
create table mytable(a int,b int) STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
如果原来创建表的时候没有指定压缩,后续可以通过修改表属性的方式添加压缩:
ALTER TABLE mytable SET TBLPROPERTIES ('parquet.compression'='SNAPPY');
或者在写入的时候set parquet.compression=SNAPPY;
不过只会影响后续入库的数据,原来的数据不会被压缩,需要重跑原来的数据。
采用压缩之后大概可以降低1/3的存储大小。