selenium 模拟登陆豆瓣,爬去武林外传的短评:
在最开始写爬虫的时候,抓取豆瓣评论,我们从F12里面是可以直接发现接口的,但是最近豆瓣更新,数据是JS异步加载的,所以没有找到合适的方法爬去,于是采用了selenium来模拟浏览器爬取。
豆瓣登陆也是改了样式,我们可以发现登陆页面是在另一个frame里面
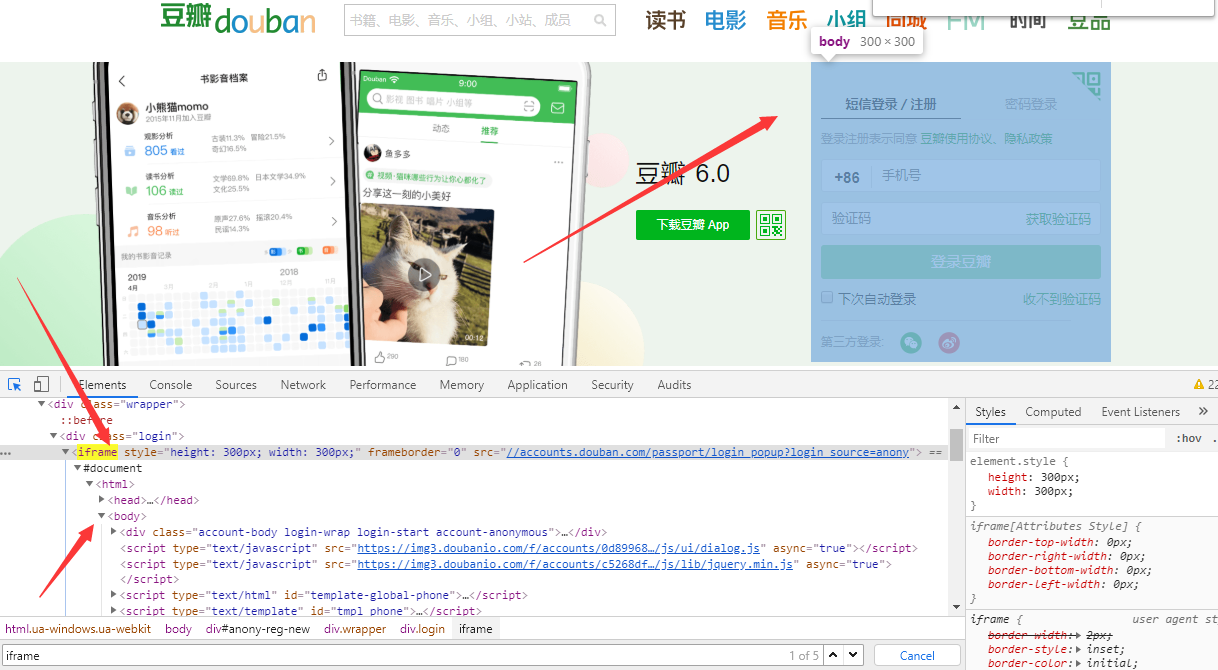
所以代码如下:
# -*- coding:utf-8 -*-
# 导包
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# 创建chrome参数对象
opt = webdriver.ChromeOptions()
# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数
opt.set_headless()
# 用的是谷歌浏览器
driver = webdriver.Chrome(options=opt)
driver=webdriver.Chrome()
# 登录豆瓣网
driver.get("http://www.douban.com/")
# 切换到登录框架中来
driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0])
# 点击"密码登录"
bottom1 = driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]')
bottom1.click()
# # 输入密码账号
input1 = driver.find_element_by_xpath('//*[@id="username"]')
input1.clear()
input1.send_keys("xxxxx")
input2 = driver.find_element_by_xpath('//*[@id="password"]')
input2.clear()
input2.send_keys("xxxxx")
# 登录
bottom = driver.find_element_by_class_name('account-form-field-submit ')
bottom.click()
然后跳转到评论界面 https://movie.douban.com/subject/3882715/comments?sort=new_score
点击下一页发现url变化 https://movie.douban.com/subject/3882715/comments?start=20&limit=20&sort=new_score 所以我们观察到变化后可以直接写循环
获取用户的姓名
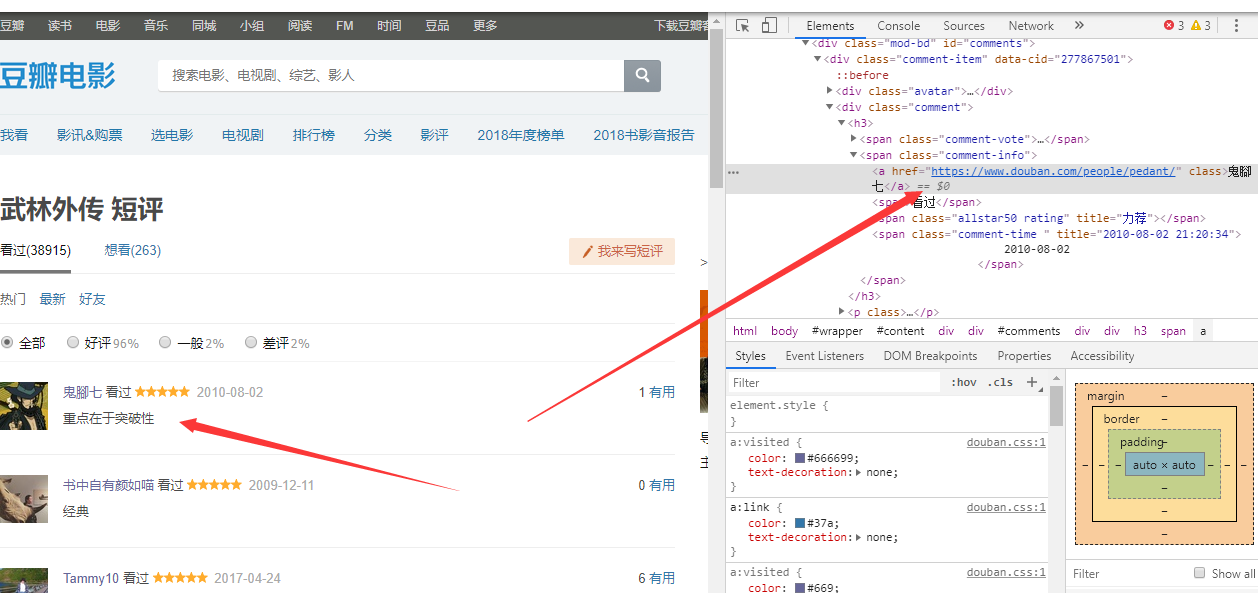
driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).text
用户的评论
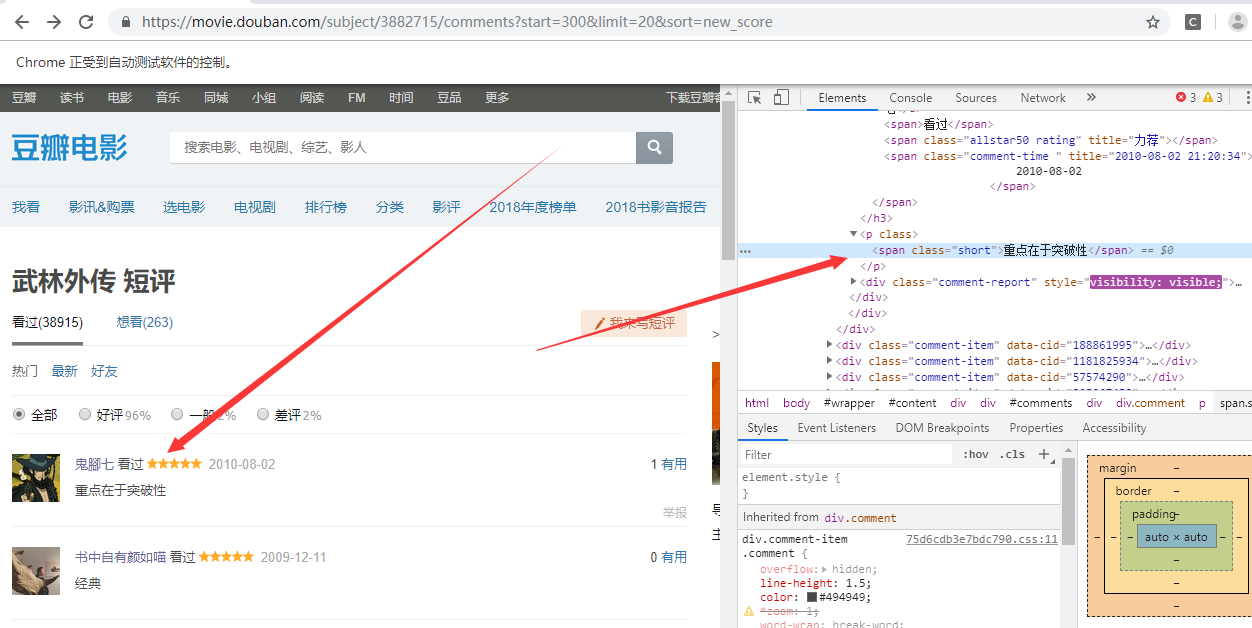
driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/p/span'.format(str(i))).text
然后我们想要知道用户的居住地:
1 #获取用户的url然后点击url获取居住地 2 userInfo=driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).get_attribute('href') 3 driver.get(userInfo) 4 try: 5 userLocation = driver.find_element_by_xpath('//*[@id="profile"]/div/div[2]/div[1]/div/a').text 6 print("用户的居之地是: ") 7 print(userLocation) 8 except Exception as e: 9 print(e)
这里要注意有些用户没有写居住地,所以必须要捕获异常
完整代码
# -*- coding:utf-8 -*- # 导包 import time from selenium import webdriver from selenium.webdriver.common.keys import Keys class doubanwlwz_spider(): def __init__(self): # 创建chrome参数对象 opt = webdriver.ChromeOptions() # 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数 opt.set_headless() # 用的是谷歌浏览器 driver = webdriver.Chrome(options=opt) driver=webdriver.Chrome() self.getInfo(driver) def getInfo(self,driver): # 切换到登录框架中来 # 登录豆瓣网 driver = driver driver.get("http://www.douban.com/") driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0]) # 点击"密码登录" bottom1 = driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]') bottom1.click() # # 输入密码账号 input1 = driver.find_element_by_xpath('//*[@id="username"]') input1.clear() input1.send_keys("ZZZ2") input2 = driver.find_element_by_xpath('//*[@id="password"]') input2.clear() input2.send_keys("ZZZ") # 登录 bottom = driver.find_element_by_class_name('account-form-field-submit ') bottom.click() time.sleep(1) driver.get('https://movie.douban.com/subject/3882715/comments?start=300&limit=20&sort=new_score') search_window = driver.current_window_handle # pageSource=driver.page_source # print(pageSource) #获取用户的名字 每页20个 for i in range(1,21): print("用户的评论是: ") print(driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).text) # 获取用户的评论 # print(driver.find_element_by_xpath('//*[@id="comments"]/div[1]/div[2]/p/span').text) print("用户的名字是: ") print(driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/p/span'.format(str(i))).text) #获取用户的url然后点击url获取居住地 userInfo=driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).get_attribute('href') driver.get(userInfo) try: userLocation = driver.find_element_by_xpath('//*[@id="profile"]/div/div[2]/div[1]/div/a').text print("用户的居之地是: ") print(userLocation) except Exception as e: print(e) driver.back() pageNum=int(input("请输入您想要爬去的步行街的页数: ")) AAA=doubanwlwz_spider()