逻辑回归会生成一个介于 0 到 1 之间(不包括 0 和 1)的概率值,而不是确切地预测结果是 0 还是 1。以用于检测垃圾邮件的逻辑回归模型为例。如果此模型推断某一特定电子邮件的值为 0.932,则意味着该电子邮件是垃圾邮件的概率为 93.2%。更准确地说,这意味着在无限训练样本的极限情况下,模型预测其值为 0.932 的这组样本实际上有 93.2% 是垃圾邮件,其余的 6.8% 不是垃圾邮件。
逻辑回归 (Logistic Regression)
许多问题需要将概率估算值作为输出。逻辑回归是一种极其高效的概率计算机制。实际上,您可以通过下两种方式之一使用返回的概率:
- 按原样
- 转换成二元类别。
我们来了解一下如何“按原样”使用概率。假设我们创建一个逻辑回归模型来预测狗在半夜发出叫声的概率。我们将此概率称为 p(bark | night),如果逻辑回归模型预测 p(bark | night) 的值为 0.05,那么一年内,狗的主人应该被惊醒约 18 次:
startled = p(bark | night) * nights
18 ~= 0.05 * 365
在很多情况下,您会将逻辑回归输出映射到二元分类问题的解决方案,该二元分类问题的目标是正确预测两个可能的标签(例如,“垃圾邮件”或“非垃圾邮件”)中的一个。之后的单元会重点介绍这一内容。您可能想知道逻辑回归模型如何确保输出值始终落在 0 和 1 之间。巧合的是,S 型函数生成的输出值正好具有这些特性,其定义如下:
S 型函数会产生以下曲线图:
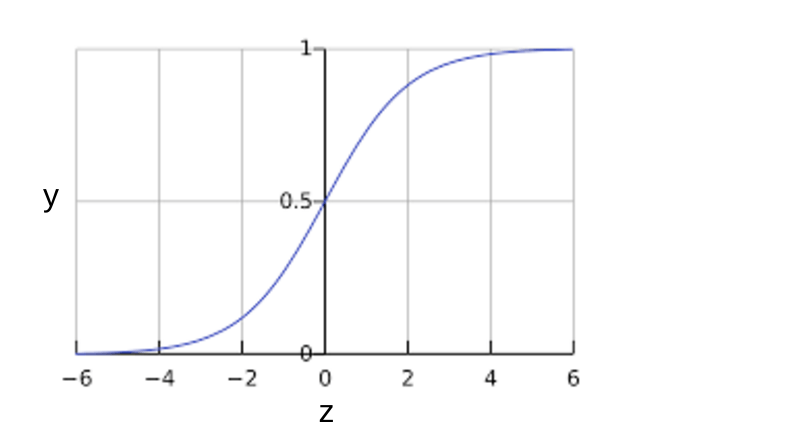
如果 z 表示使用逻辑回归训练的模型的线性层的输出,则 S 型(z) 函数会生成一个介于 0 和 1 之间的值(概率)。用数学方法表示为:
其中:
- (yprime)是逻辑回归模型针对特定样本的输出。
- (z)是 (b + w_1x_1 + w_2x_2 + dots + w_Nx_N)
- (w) 的值是该模型学习的权重,(b) 是偏差。
- (x) 的值是特定样本的特征值。
请注意,z 也称为对数几率,因为 S 型函数的反函数表明,z 可定义为标签“1”(例如“狗叫”)的概率除以标签“0”(例如“狗不叫”)的概率得出的值的对数:
以下是具有机器学习标签的 S 型函数:
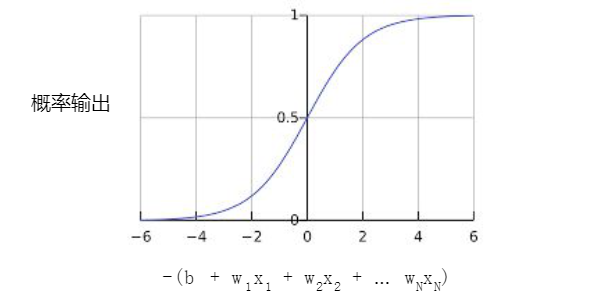
逻辑回归 (Logistic Regression):模型训练
逻辑回归的损失函数
线性回归的损失函数是平方损失。逻辑回归的损失函数是对数损失函数,定义如下:
其中:
- ((x,y) in D) 是包含很多有标签样本 ((x,y)) 的数据集。
- (y)是有标签样本中的标签。由于这是逻辑回归,因此(y)的每个值必须是 0 或 1。
- (yprime)是对于特征集(x)的预测值(介于 0 和 1 之间)。
对数损失函数的方程式与 Shannon 信息论中的熵测量密切相关。它也是似然函数的负对数(假设“y”属于伯努利分布)。实际上,最大限度地降低损失函数的值会生成最大的似然估计值。
逻辑回归中的正则化
正则化在逻辑回归建模中极其重要。如果没有正则化,逻辑回归的渐近性会不断促使损失在高维度空间内达到 0。因此,大多数逻辑回归模型会使用以下两个策略之一来降低模型复杂性:
- L2 正则化。
- 早停法,即,限制训练步数或学习速率。
假设您向每个样本分配一个唯一 ID,且将每个 ID 映射到其自己的特征。如果您未指定正则化函数,模型会变得完全过拟合。这是因为模型会尝试促使所有样本的损失达到 0 但始终达不到,从而使每个指示器特征的权重接近正无穷或负无穷。当有大量罕见的特征组合且每个样本中仅一个时,包含特征组合的高维度数据会出现这种情况。幸运的是,使用 L2 或早停法可以防止出现此类问题。
逻辑回归模型会生成概率。
对数损失函数是逻辑回归的损失函数。
逻辑回归被很多从业者广泛使用。
分类 (Classification):指定阈值
逻辑回归返回的是概率。您可以“原样”使用返回的概率(例如,用户点击此广告的概率为 0.00023),也可以将返回的概率转换成二元值(例如,这封电子邮件是垃圾邮件)。如果某个逻辑回归模型对某封电子邮件进行预测时返回的概率为 0.9995,则表示该模型预测这封邮件非常可能是垃圾邮件。相反,在同一个逻辑回归模型中预测分数为 0.0003 的另一封电子邮件很可能不是垃圾邮件。可如果某封电子邮件的预测分数为 0.6 呢?为了将逻辑回归值映射到二元类别,您必须指定分类阈值(也称为判定阈值)。如果值高于该阈值,则表示“垃圾邮件”;如果值低于该阈值,则表示“非垃圾邮件”。人们往往会认为分类阈值应始终为 0.5,但阈值取决于具体问题,因此您必须对其进行调整。
注意:“调整”逻辑回归的阈值不同于调整学习速率等超参数。在选择阈值时,需要评估您将因犯错而承担多大的后果。例如,将非垃圾邮件误标记为垃圾邮件会非常糟糕。不过,虽然将垃圾邮件误标记为非垃圾邮件会令人不快,但应该不会让您丢掉工作。
分类 (Classification):真与假以及正类别与负类别
在本部分,我们将定义用于评估分类模型的指标的主要组成部分。不过,我们先来看一则寓言故事:
伊索寓言:狼来了(精简版)
有一位牧童要照看镇上的羊群,但是他开始厌烦这份工作。为了找点乐子,他大喊道:“狼来了!”其实根本一头狼也没有出现。村民们迅速跑来保护羊群,但他们发现这个牧童是在开玩笑后非常生气。
[ 这样的情形重复出现了很多次。]
一天晚上,牧童看到真的有一头狼靠近羊群,他大声喊道:“狼来了!”村民们不想再被他捉弄,都待在家里不出来。这头饥饿的狼对羊群大开杀戒,美美饱餐了一顿。这下子,整个镇子都揭不开锅了。恐慌也随之而来。
我们做出以下定义:
- “狼来了”是正类别。
- “没有狼”是负类别。
我们可以使用一个 2x2 混淆矩阵来总结我们的“狼预测”模型,该矩阵描述了所有可能出现的结果(共四种):
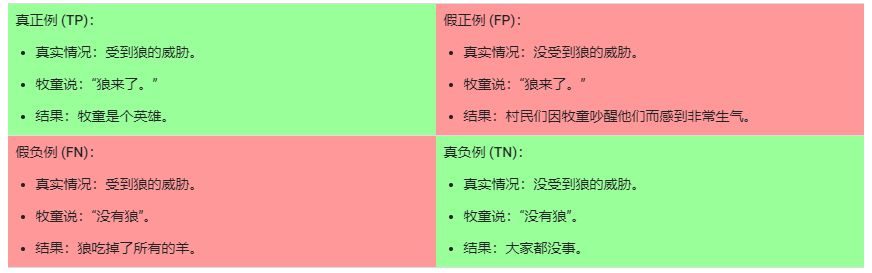
真正例是指模型将正类别样本正确地预测为正类别。同样,真负例是指模型将负类别样本正确地预测为负类别。假正例是指模型将负类别样本错误地预测为正类别,而假负例是指模型将正类别样本错误地预测为负类别。在后面的部分中,我们将介绍如何使用从这四种结果中衍生出的指标来评估分类模型。
分类 (Classification):准确率
准确率是一个用于评估分类模型的指标。通俗来说,准确率是指我们的模型预测正确的结果所占的比例。正式点说,准确率的定义如下:
对于二元分类,也可以根据正类别和负类别按如下方式计算准确率:
其中,TP = 真正例,TN = 真负例,FP = 假正例,FN = 假负例。让我们来试着计算一下以下模型的准确率,该模型将 100 个肿瘤分为恶性 (正类别)或良性(负类别):

准确率为 0.91,即 91%(总共 100 个样本中有 91 个预测正确)。这表示我们的肿瘤分类器在识别恶性肿瘤方面表现得非常出色,对吧?实际上,只要我们仔细分析一下正类别和负类别,就可以更好地了解我们模型的效果。
在 100 个肿瘤样本中,91 个为良性(90 个 TN 和 1 个 FP),9 个为恶性(1 个 TP 和 8 个 FN)。
在 91 个良性肿瘤中,该模型将 90 个正确识别为良性。这很好。不过,在 9 个恶性肿瘤中,该模型仅将 1 个正确识别为恶性。这是多么可怕的结果!9 个恶性肿瘤中有 8 个未被诊断出来!
虽然 91% 的准确率可能乍一看还不错,但如果另一个肿瘤分类器模型总是预测良性,那么这个模型使用我们的样本进行预测也会实现相同的准确率(100 个中有 91 个预测正确)。换言之,我们的模型与那些没有预测能力来区分恶性肿瘤和良性肿瘤的模型差不多。
当您使用分类不平衡的数据集(比如正类别标签和负类别标签的数量之间存在明显差异)时,单单准确率一项并不能反映全面情况。
分类 (Classification):精确率和召回率
精确率
精确率指标尝试回答以下问题:在被识别为正类别的样本中,确实为正类别的比例是多少?
精确率的定义如下:
注意:如果模型的预测结果中没有假正例,则模型的精确率为 1.0。
让我们来计算一下上一部分中用于分析肿瘤的机器学习模型的精确率:

(精确率 = frac{TP}{TP + FP} = frac{1}{1 + 1} = 0.5)
该模型的精确率为 0.5,也就是说,该模型在预测恶性肿瘤方面的正确率是 50%。
召回率
召回率尝试回答以下问题:在所有正类别样本中,被正确识别为正类别的比例是多少?
从数学上讲,召回率的定义如下:
注意:如果模型的预测结果中没有假负例,则模型的召回率为 1.0。
让我们来计算一下肿瘤分类器的召回率:
(召回率 = frac{TP}{TP + FN} = frac{1}{1 + 8} = 0.11)
该模型的召回率是 0.11,也就是说,该模型能够正确识别出所有恶性肿瘤的百分比是 11%。

精确率和召回率:一场拔河比赛
要全面评估模型的有效性,必须同时检查精确率和召回率。遗憾的是,精确率和召回率往往是此消彼长的情况。也就是说,提高精确率通常会降低召回率值,反之亦然。请观察下图来了解这一概念,该图显示了电子邮件分类模型做出的 30 项预测。分类阈值右侧的被归类为“垃圾邮件”,左侧的则被归类为“非垃圾邮件”。
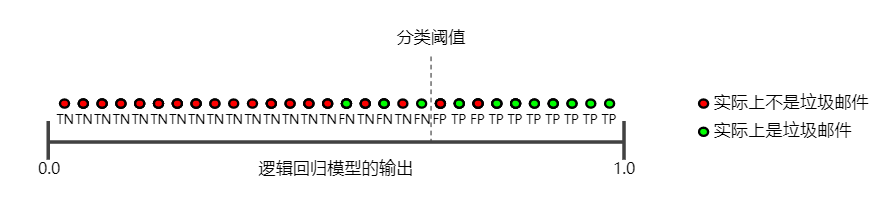
我们根据图 1 所示的结果来计算精确率和召回率值:

精确率指的是被标记为垃圾邮件的电子邮件中正确分类的电子邮件所占的百分比,即图 1 中阈值线右侧的绿点所占的百分比:
召回率指的是实际垃圾邮件中正确分类的电子邮件所占的百分比,即图 1 中阈值线右侧的绿点所占的百分比:
下图显示了提高分类阈值产生的效果。
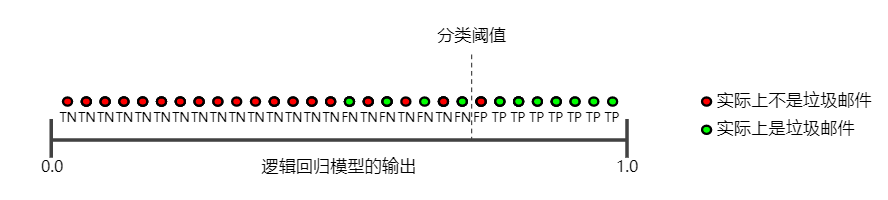
假正例数量会减少,但假负例数量会相应地增加。结果,精确率有所提高,而召回率则有所降低:

相反,下图显示了降低分类阈值(从图 1 中的初始位置开始)产生的效果。
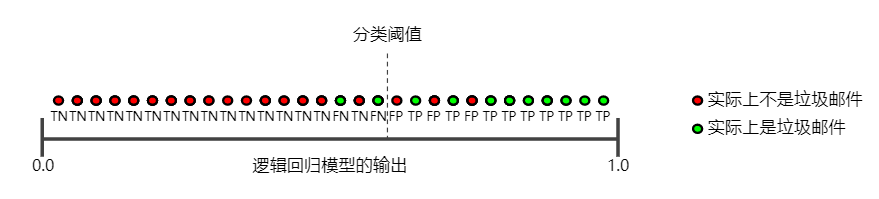
假正例数量会增加,而假负例数量会减少。结果这一次,精确率有所降低,而召回率则有所提高:

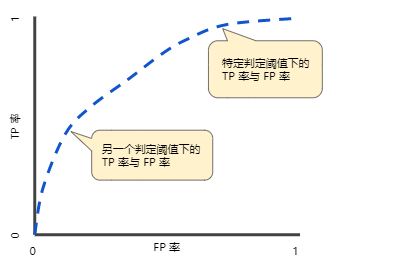
ROC 曲线
ROC 曲线(接收者操作特征曲线)是一种显示分类模型在所有分类阈值下的效果的图表。该曲线绘制了以下两个参数:
- 真正例率
- 假TPR正例率
真正例率 (TPR) 是召回率的同义词,因此定义如下:
假正例率 (FPR) 的定义如下:
ROC 曲线用于绘制采用不同分类阈值时的 TPR 与 FPR。降低分类阈值会导致将更多样本归为正类别,从而增加假正例和真正例的个数。下图显示了一个典型的 ROC 曲线。
为了计算 ROC 曲线上的点,我们可以使用不同的分类阈值多次评估逻辑回归模型,但这样做效率非常低。幸运的是,有一种基于排序的高效算法可以为我们提供此类信息,这种算法称为曲线下面积。
曲线下面积:ROC 曲线下面积
曲线下面积表示“ROC 曲线下面积”。也就是说,曲线下面积测量的是从 (0,0) 到 (1,1) 之间整个 ROC 曲线以下的整个二维面积(参考积分学)。
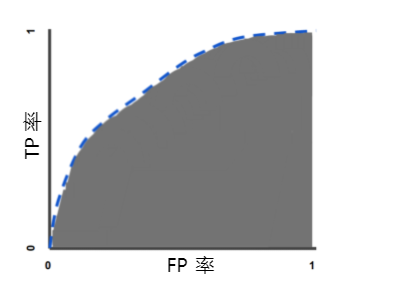
曲线下面积对所有可能的分类阈值的效果进行综合衡量。曲线下面积的一种解读方式是看作模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。以下面的样本为例,逻辑回归预测从左到右以升序排列:

曲线下面积表示随机正类别(绿色)样本位于随机负类别(红色)样本右侧的概率。
曲线下面积的取值范围为 0-1。预测结果 100% 错误的模型的曲线下面积为 0.0;而预测结果 100% 正确的模型的曲线下面积为 1.0。
曲线下面积因以下两个原因而比较实用:
- 曲线下面积的尺度不变。它测量预测的排名情况,而不是测量其绝对值。
- 曲线下面积的分类阈值不变。它测量模型预测的质量,而不考虑所选的分类阈值。
不过,这两个原因都有各自的局限性,这可能会导致曲线下面积在某些用例中不太实用:
- 并非总是希望尺度不变。 例如,有时我们非常需要被良好校准的概率输出,而曲线下面积无法告诉我们这一结果。
- 并非总是希望分类阈值不变。 在假负例与假正例的代价存在较大差异的情况下,尽量减少一种类型的分类错误可能至关重要。例如,在进行垃圾邮件检测时,您可能希望优先考虑尽量减少假正例(即使这会导致假负例大幅增加)。对于此类优化,曲线下面积并非一个实用的指标。
分类 (Classification):预测偏差
逻辑回归预测应当无偏差。即:“预测平均值”应当约等于“观察平均值”。
预测偏差指的是这两个平均值之间的差值。即:
(预测偏差 = 预测平均值 - 数据集中相应标签的平均值)
注意:“预测偏差”与偏差(“wx + b”中的“b”)不是一回事。
如果出现非常高的非零预测偏差,则说明模型某处存在错误,因为这表明模型对正类别标签的出现频率预测有误。例如,假设我们知道,所有电子邮件中平均有 1% 的邮件是垃圾邮件。如果我们对某一封给定电子邮件一无所知,则预测它是垃圾邮件的可能性为 1%。同样,一个出色的垃圾邮件模型应该预测到电子邮件平均有 1% 的可能性是垃圾邮件。(换言之,如果我们计算单个电子邮件是垃圾邮件的预测可能性的平均值,则结果应该是 1%。)然而,如果该模型预测电子邮件是垃圾邮件的平均可能性为 20%,那么我们可以得出结论,该模型出现了预测偏差。
造成预测偏差的可能原因包括:
- 特征集不完整
- 数据集混乱
- 模型实现流水线中有错误?
- 训练样本有偏差
- 正则化过强
您可能会通过对学习模型进行后期处理来纠正预测偏差,即通过添加校准层来调整模型的输出,从而减小预测偏差。例如,如果您的模型存在 3% 以上的偏差,则可以添加一个校准层,将平均预测偏差降低 3%。但是,添加校准层并非良策,具体原因如下:
- 您修复的是症状,而不是原因。
- 您建立了一个更脆弱的系统,并且必须持续更新。
如果可能的话,请避免添加校准层。使用校准层的项目往往会对其产生依赖 - 使用校准层来修复模型的所有错误。最终,维护校准层可能会令人苦不堪言。
注意:出色模型的偏差通常接近于零。即便如此,预测偏差低并不能证明您的模型比较出色。特别糟糕的模型的预测偏差也有可能为零。例如,只能预测所有样本平均值的模型是糟糕的模型,尽管其预测偏差为零。
分桶偏差和预测偏差
逻辑回归可预测 0 到 1 之间的值。不过,所有带标签样本都正好是 0(例如,0 表示“非垃圾邮件”)或 1(例如,1 表示“垃圾邮件”)。因此,在检查预测偏差时,您无法仅根据一个样本准确地确定预测偏差;您必须在“一大桶”样本中检查预测偏差。也就是说,只有将足够的样本组合在一起以便能够比较预测值(例如 0.392)与观察值(例如 0.394),逻辑回归的预测偏差才有意义。
您可以通过以下方式构建桶:
- 以线性方式分解目标预测。
- 构建分位数。
请查看以下某个特定模型的校准曲线。每个点表示包含 1000 个值的分桶。两个轴具有以下含义:
- x 轴表示模型针对该桶预测的平均值。
- y 轴表示该桶的数据集中的实际平均值。
两个轴均采用对数尺度。
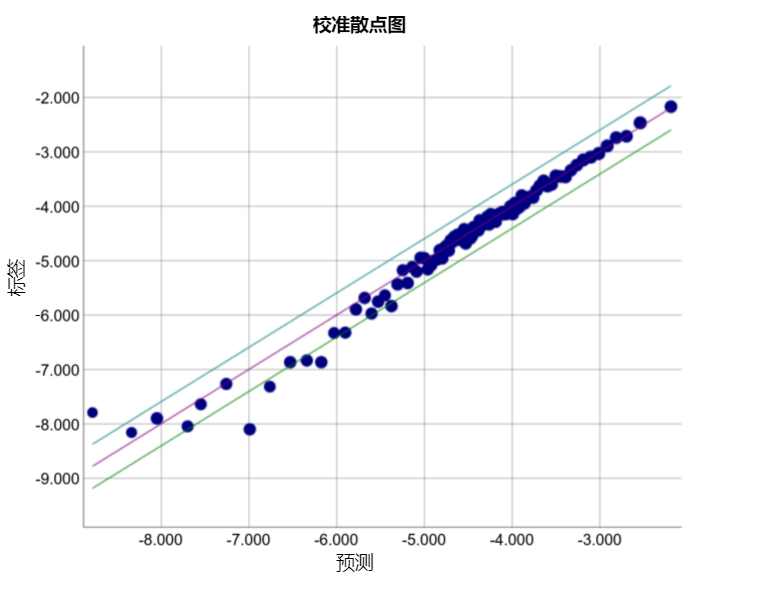
为什么只有模型的某些部分所做的预测如此糟糕?以下是几种可能性:
- 训练集不能充分表示数据空间的某些子集。
- 数据集的某些子集比其他子集更混乱。
- 该模型过于正则化。(不妨减小 lambda 的值。)
稀疏性正则化 (Regularization for Sparsity):L₁ 正则化
稀疏矢量通常包含许多维度。创建特征组合会导致包含更多维度。由于使用此类高维度特征矢量,因此模型可能会非常庞大,并且需要大量的 RAM。
在高维度稀疏矢量中,最好尽可能使权重正好降至 0。正好为 0 的权重基本上会使相应特征从模型中移除。 将特征设为 0 可节省 RAM 空间,且可以减少模型中的噪点。
以一个涵盖全球地区(不仅仅只是涵盖加利福尼亚州)的住房数据集为例。如果按分(每度为 60 分)对全球纬度进行分桶,则在一次稀疏编码过程中会产生大约 1 万个维度;如果按分对全球经度进行分桶,则在一次稀疏编码过程中会产生大约 2 万个维度。这两种特征的特征组合会产生大约 2 亿个维度。这 2 亿个维度中的很多维度代表非常有限的居住区域(例如海洋里),很难使用这些数据进行有效泛化。 若为这些不需要的维度支付 RAM 存储费用就太不明智了。 因此,最好是使无意义维度的权重正好降至 0,这样我们就可以避免在推理时支付这些模型系数的存储费用。
我们或许可以添加适当选择的正则化项,将这种想法变成在训练期间解决的优化问题。
L2 正则化能完成此任务吗?遗憾的是,不能。 L2 正则化可以使权重变小,但是并不能使它们正好为 0.0。
另一种方法是尝试创建一个正则化项,减少模型中的非零系数值的计数。只有在模型能够与数据拟合时增加此计数才有意义。 遗憾的是,虽然这种基于计数的方法看起来很有吸引力,但它会将我们的凸优化问题变为非凸优化问题,即 NP 困难。 (如果您仔细观察,便会发现它与背包问题关联。) 因此,L0 正则化这种想法在实践中并不是一种有效的方法。
不过,L1 正则化这种正则化项的作用类似 L0,但它具有凸优化的优势,可有效进行计算。因此,我们可以使用 L1 正则化使模型中很多信息缺乏的系数正好为 0,从而在推理时节省 RAM。
L1 和 L2 正则化
L2 和 L1 采用不同的方式降低权重:
- L2 会降低(权重^2)。
- L1 会降低(lvert权重 vert)
因此,L2 和 L1 具有不同的导数:
- L2 的导数为 2 * 权重。
- L1 的导数为 k(一个常数,其值与权重无关)。
您可以将 L2 的导数的作用理解为每次移除权重的 x%。如 Zeno 所知,对于任意数字,即使按每次减去 x% 的幅度执行数十亿次减法计算,最后得出的值也绝不会正好为 0。(Zeno 不太熟悉浮点精度限制,它可能会使结果正好为 0。)总而言之,L2 通常不会使权重变为 0。
您可以将 L1 的导数的作用理解为每次从权重中减去一个常数。不过,由于减去的是绝对值,L1 在 0 处具有不连续性,这会导致与 0 相交的减法结果变为 0。例如,如果减法使权重从 +0.1 变为 -0.2,L1 便会将权重设为 0。就这样,L1 使权重变为 0 了。
L1 正则化 - 减少所有权重的绝对值 - 证明对宽度模型非常有效。
请注意,该说明适用于一维模型。